Hallo alle zusammen! Wie Sie bereits wissen, beschäftigen wir uns bei SE (und nicht nur) mit der Texterkennung verschiedener Dokumente. Heute möchten wir über ein weiteres Problem beim Erkennen von Text auf komplexen Hintergründen sprechen - über das Erkennen von Leerzeichen. Im Allgemeinen werden wir über den Namen auf Bankkarten sprechen, aber zuerst ein Beispiel mit einem „Geist“ des Buchstabens. Wie Sie hier rechts von D sehen können, bildeten die Verzerrungen und der Hintergrund ein ziemlich klares Bild. Wenn Sie diese Zelle außerdem getrennt von allem anderen zeigen, die Person (oder neuronales Netzwerk) wird sicherlich sagen, dass es einen Buchstaben gibt.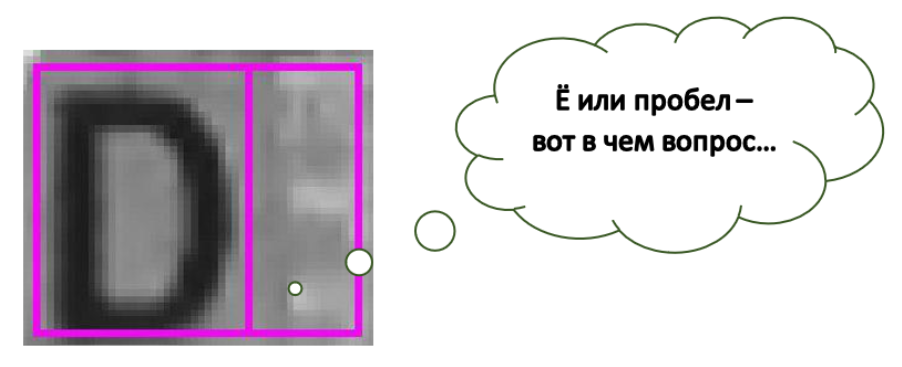 Wie Sie auf dem Bild sehen können, arbeiten wir an dem Originalbild mit komplexen Hintergründen, sodass unsere Räume sehr unterschiedlich sind. Sie kommen in Mustern, Logos und manchmal Text. Zum Beispiel VISA oder MAESTRO auf Karten. Und wir interessieren uns für solche „komplexen Räume“ und nicht nur für weiße Rechtecke. Und in unseren Systemen betrachten wir genau getrennt geschnittene Rechtecke von Symbolen [1].
Wie Sie auf dem Bild sehen können, arbeiten wir an dem Originalbild mit komplexen Hintergründen, sodass unsere Räume sehr unterschiedlich sind. Sie kommen in Mustern, Logos und manchmal Text. Zum Beispiel VISA oder MAESTRO auf Karten. Und wir interessieren uns für solche „komplexen Räume“ und nicht nur für weiße Rechtecke. Und in unseren Systemen betrachten wir genau getrennt geschnittene Rechtecke von Symbolen [1].Und was ist die Schwierigkeit?
Ein Leerzeichen ist ein Symbol ohne Sonderzeichen. Auf komplexen Hintergründen, wie z. B. in einem Bild, kann es schwierig sein, einen separat ausgeschnittenen Raum selbst für eine Person zu unterscheiden.Andererseits unterscheidet sich ein Leerzeichen im Wesentlichen von anderen Zeichen. Wenn ABIA im Namen anstelle von ASIA erkannt wird, besteht die Möglichkeit, dies durch Nachbearbeitung zu beheben. Wenn dort jedoch eine Folgenabschätzung auftritt, ist es unwahrscheinlich, dass etwas hilft.Von uns nicht verwendete Methoden
Oft werden Leerzeichen mithilfe von Statistiken gefiltert, die aus dem Bild berechnet werden. Beispielsweise berücksichtigen sie den durchschnittlichen absoluten Wert des Gradienten im Bild oder die Varianz der Intensitäten der Pixel und teilen die Bilder durch den Schwellenwert in Leerzeichen und Buchstaben. Wie aus den Grafiken ersichtlich ist, sind solche Methoden jedoch nicht für graue Bilder mit komplexem Hintergrund geeignet. Und aufgrund der expliziten Korrelation von Werten funktioniert auch eine Kombination dieser Methoden nicht.Auch hier hilft die bevorzugte Binärisierung aller nicht. Zum Beispiel in diesem Bild:Wie kann die Erkennung verbessert werden?
Da eine Person eine Umgebung eines Raums benötigt, um sie zu sehen, ist es logisch, dass das Netzwerk mindestens zwei benachbarte Zeichen anzeigt. Wir wollen den Input des Erkennungsnetzwerks nicht erhöhen, was im Allgemeinen gut funktioniert (und viele Lücken erkennt). So bekommen wir ein anderes Netzwerk - einfacher. Das neue Netzwerk sagt voraus, was auf dem Bild zu sehen ist: zwei Leerzeichen, zwei Buchstaben, ein Leerzeichen und ein Buchstabe oder ein Buchstabe und ein Leerzeichen. Dementsprechend wird ein solches Netzwerk in Verbindung mit einem Erkennungsnetzwerk verwendet. Das Bild zeigt die verwendeten Architekturen: Links die Architektur des erkennenden Netzwerks, rechts die Architektur des vorgeschlagenen Netzwerks. Das Erkennungsnetzwerk bearbeitet ein Bild mit einem Zeichen, und das neue arbeitet mit einem Bild mit doppelter Breite, das zwei benachbarte Zeichen enthält.Ein Test?
Zum Testen hatten wir 4320 Zeilen mit Namen, die 130.149 Zeichen enthielten, davon 68.246 Leerzeichen. Für den Anfang haben wir zwei Methoden. Die grundlegende Methode: Wir schneiden eine Zeichenfolge in Zeichen und erkennen jedes Zeichen einzeln. Neue Methode: Wir schneiden auch eine Zeichenfolge, finden alle Leerzeichen in einem neuen Netzwerk und erkennen die verbleibenden Zeichen als normal. Die Tabelle zeigt, dass die Qualität der Erkennung von Räumen sowie die Gesamtqualität zunimmt, die Qualität der Erkennung von Buchstaben jedoch leicht abnimmt.Unser Kernnetz erkennt jedoch auch Räume (wenn auch schlechter als wir möchten). Und wir können versuchen, dies auszunutzen. Schauen wir uns die Fehler beider Methoden an. Und auch - zur Qualität der neuen Methode aufgrund grundlegender Fehler und umgekehrt.Für die Basismethode:Für die neue Methode:Aus den letzten drei Tabellen geht hervor, dass es sich zur Verbesserung des Systems lohnt, eine ausgewogene Kombination von Netzwerkbewertungen zu verwenden. Gleichzeitig ist die Qualität von Zeichen zu Zeichen interessant, aber Zeile für Zeile ist interessanter.Fazit
Leerzeichen - ein großes Problem auf dem Weg zu einer 100% igen Qualität der Erkennung von Dokumenten =) Das Beispiel von Leerzeichen zeigt deutlich, wie wichtig es ist, nicht nur einzelne Zeichen, sondern auch deren Kombinationen zu betrachten. Ergreifen Sie jedoch nicht sofort schwere Artillerie und lernen Sie riesige Netzwerke, die ganze Saiten verarbeiten. Manchmal reicht schon ein anderes kleines Netzwerk.Dieser Beitrag wurde unter Verwendung von Materialien aus einem Bericht der Europäischen Modellierungskonferenz ECMS 2015 (Bulgarien, Varna) erstellt: Sheshkus, A. & Arlazarov, VL (2015). Raumsymbolerkennung auf komplexem Hintergrund unter Verwendung des visuellen Kontexts.Liste der verwendeten Quellen1. YS Chernyshova, AV Sheshkus und VV Arlazarov, „Zweistufiges CNN-Framework für die Erkennung von Textzeilen in von der Kamera aufgenommenen Bildern“, IEEE Access, vol. 8, pp. 32587-32600, 2020, DOI: 10.1109 / ACCESS.2020.2974051.