Oder die gute alte dynamische Programmierung ohne diese Ihrer neuronalen Netze.Vor anderthalb Jahren nahm ich zufällig an einem Unternehmenswettbewerb (zum Zwecke der Unterhaltung) teil, um einen Bot für das Spiel Lode Runner zu schreiben. Vor 20 Jahren habe ich alle Probleme der dynamischen Programmierung im entsprechenden Kurs fleißig gelöst, aber so ziemlich alles vergessen und keine Erfahrung in der Programmierung von Game Bots. Ich musste mich daran erinnern, dass wenig Zeit zur Verfügung stand, um unterwegs zu experimentieren und selbständig auf den Rechen zu treten. Aber plötzlich hat alles sehr gut geklappt, also habe ich beschlossen, das Material irgendwie zu systematisieren und den Leser nicht mit Matan zu ertränken.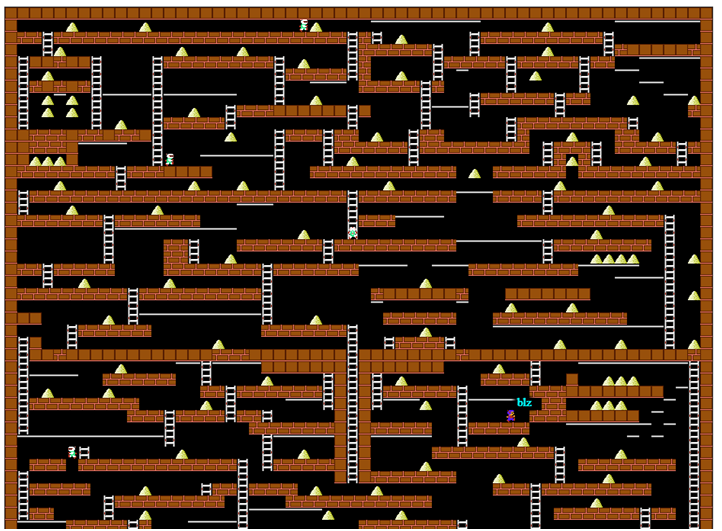 Spielbildschirm vom Codenjoy-ProjektserverZunächst werden wir die Spielregeln ein wenig beschreiben : Der Spieler bewegt sich horizontal entlang des Bodens oder durch Rohre, weiß, wie man Treppen hoch und runter klettert, fällt, wenn sich kein Boden unter ihm befindet. Er kann auch links oder rechts von sich selbst ein Loch schneiden, aber nicht jede Oberfläche kann durchgeschnitten werden - bedingt ist ein „Holzboden“ möglich und Beton - nicht.Monster rennen dem Spieler hinterher, fallen in die geschnittenen Löcher und sterben darin. Vor allem aber muss der Spieler Gold sammeln, für das erste gesammelte Gold erhält er 1 Gewinnpunkt, für das N-te erhält er N Punkte. Nach dem Tod bleibt der Gesamtgewinn, aber für das erste Gold geben sie wieder 1 Punkt. Dies deutet darauf hin, dass die Hauptsache darin besteht, so lange wie möglich am Leben zu bleiben und Gold zu sammeln, ist irgendwie zweitrangig.Da es Orte auf der Karte gibt, an denen der Spieler nicht aus sich herauskommen kann, wurde ein freier Selbstmord in das Spiel eingeführt, der den Spieler zufällig irgendwohin brachte, aber tatsächlich das ganze Spiel brach - Selbstmord hat das Wachstum des gefundenen Goldwerts nicht unterbrochen. Wir werden diese Funktion jedoch nicht missbrauchen.Alle Beispiele aus dem Spiel werden in einer vereinfachten Anzeige angezeigt, die in den Programmprotokollen verwendet wurde:
Spielbildschirm vom Codenjoy-ProjektserverZunächst werden wir die Spielregeln ein wenig beschreiben : Der Spieler bewegt sich horizontal entlang des Bodens oder durch Rohre, weiß, wie man Treppen hoch und runter klettert, fällt, wenn sich kein Boden unter ihm befindet. Er kann auch links oder rechts von sich selbst ein Loch schneiden, aber nicht jede Oberfläche kann durchgeschnitten werden - bedingt ist ein „Holzboden“ möglich und Beton - nicht.Monster rennen dem Spieler hinterher, fallen in die geschnittenen Löcher und sterben darin. Vor allem aber muss der Spieler Gold sammeln, für das erste gesammelte Gold erhält er 1 Gewinnpunkt, für das N-te erhält er N Punkte. Nach dem Tod bleibt der Gesamtgewinn, aber für das erste Gold geben sie wieder 1 Punkt. Dies deutet darauf hin, dass die Hauptsache darin besteht, so lange wie möglich am Leben zu bleiben und Gold zu sammeln, ist irgendwie zweitrangig.Da es Orte auf der Karte gibt, an denen der Spieler nicht aus sich herauskommen kann, wurde ein freier Selbstmord in das Spiel eingeführt, der den Spieler zufällig irgendwohin brachte, aber tatsächlich das ganze Spiel brach - Selbstmord hat das Wachstum des gefundenen Goldwerts nicht unterbrochen. Wir werden diese Funktion jedoch nicht missbrauchen.Alle Beispiele aus dem Spiel werden in einer vereinfachten Anzeige angezeigt, die in den Programmprotokollen verwendet wurde: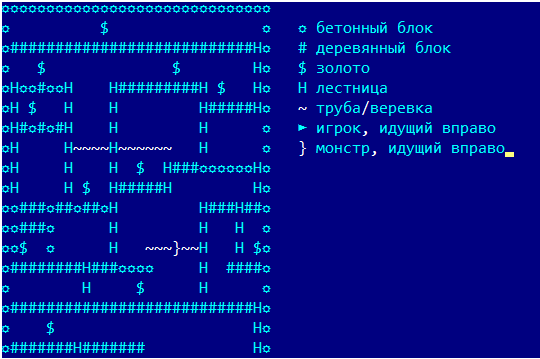
Ein bisschen Theorie
Um den Bot mithilfe einer Art Mathematik zu implementieren, müssen wir eine objektive Funktion festlegen, die die Leistungen des Bots beschreibt, und Aktionen finden, die ihn maximieren. Zum Beispiel erhalten wir für das Sammeln von Gold +100, für den Tod -100500, sodass keine Sammlung von Gold den möglichen Tod tötet.Eine separate Frage, und worauf genau bestimmen wir die Zielfunktion, d.h. Wie ist der Stand des Spiels? Im einfachsten Fall reichen die Koordinaten des Spielers aus, aber bei uns ist alles viel komplizierter:- Spielerkoordinaten
- die Koordinaten aller von allen Spielern durchbohrten Löcher
- die Koordinaten des gesamten Goldes auf der Karte (oder die Koordinaten des kürzlich verzehrten Goldes)
- Koordinaten aller anderen Spieler
Es sieht beängstigend aus. Vereinfachen wir daher die Aufgabe ein wenig und bis wir uns an das Gold erinnern, das wir essen (wir werden später darauf zurückkommen), werden wir uns auch nicht an die Koordinaten anderer Spieler und Monster erinnern.Der aktuelle Stand des Spiels ist also:- Spielerkoordinaten
- Koordinaten aller Gruben
Spieleraktionen ändern den Status auf verständliche Weise:- Bewegungsbefehle ändern eine der entsprechenden Koordinaten
- Das Grubenteam fügt eine neue Grube hinzu
- Wenn ein Spieler ohne Unterstützung fällt, wird die vertikale Koordinate verringert
- Die Untätigkeit des Spielers, der auf der Unterstützung steht, ändert nichts am Zustand
Jetzt müssen wir verstehen, wie die Funktion selbst maximiert werden kann. Eine der ehrwürdigen klassischen Methoden zur Berechnung des Spiels, das N vorantreibt, ist die dynamische Programmierung. Es ist unmöglich, auf Formeln zu verzichten, daher werde ich sie in vereinfachter Form geben. Sie müssen zuerst viel Notation einführen.Der Einfachheit halber behalten wir den Zeitbericht von der aktuellen Bewegung bei, d. H. Die aktuelle Bewegung ist t = 0.Wir bezeichnen den Stand des Spiels im Laufe von t durch.Viele bezeichnet alle gültigen Aktionen des Bots (in einem bestimmten Zustand, aber der Einfachheit halber schreiben wir den Zustandsindex nicht) durch Wir bezeichnen eine bestimmte Aktion auf dem Kurs t (wir lassen den Index weg).Bedingung Unter dem Einfluss geht in den Zustand .Gewinnen Sie, wenn Aktion a aktiviert ist wir bezeichnen es als . Bei der Berechnung nehmen wir an, dass wenn wir Gold gegessen haben, es gleich G = 100 ist, wenn sie gestorben sind, dann D = -100500, sonst 0.SeiDies ist die Auszahlungsfunktion für das optimale Spiel eines Bots, der sich zum Zeitpunkt t im Zustand x befindet. Dann müssen wir nur noch eine Aktion finden, die maximiert.Jetzt schreiben wir die erste Formel, die sehr wichtig und gleichzeitig fast richtig ist:
Oder für einen beliebigen Zeitpunkt
Es sieht ziemlich ungeschickt aus, aber die Bedeutung ist einfach - die optimale Lösung für den aktuellen Zug besteht aus der optimalen Lösung für den nächsten Zug und dem Gewinn im aktuellen Zug. Dies ist Bellmans schief formuliertes Optimalitätsprinzip. Wir wissen nichts über die optimalen Werte in Schritt 1, aber wenn wir sie kennen würden, würden wir eine Aktion finden, die die Funktion maximiert, indem wir einfach alle Aktionen des Bots durchlaufen. Das Schöne an wiederkehrenden Beziehungen ist, dass wir sie finden können, wendet das Optimalitätsprinzip darauf an und drückt es in genau der gleichen Formel durch . Wir können die Auszahlungsfunktion auch bei jedem Schritt leicht ausdrücken.Es scheint, dass das Problem gelöst ist, aber hier stehen wir vor dem Problem, dass wir, wenn wir bei jedem Schritt 6 Spieleraktionen sortieren müssten, beim N-Rekursionsschritt 6 ^ N Optionen sortieren müssten, was für N = 8 bereits eine ziemlich anständige Zahl ~ 1,6 ist Millionen Fälle. Auf der anderen Seite haben wir Gigahertz-Mikroprozessoren, die nichts zu tun haben, und es scheint, dass sie die Aufgabe vollständig bewältigen werden, und wir werden die Suchtiefe mit genau 8 Zügen auf sie beschränken.Unser Planungshorizont beträgt also 8 Züge, aber wo erhalten wir die Werte?? Und hier kommen wir nur auf die Idee, dass wir in der Lage sind, die Aussichten der Position irgendwie zu analysieren und ihr einen Wert zuzuweisen, der auf ihren höchsten Überlegungen basiert. Lassenwo Dies ist eine Funktion der Strategie. In der einfachsten Version ist es nur eine Matrix, aus der wir den Wert gemäß den geometrischen Koordinaten des Bots auswählen. Wir können sagen, dass die ersten 8 Züge eine Taktik waren, und dann beginnt die Strategie. Tatsächlich schränkt uns niemand bei der Auswahl einer Strategie ein, und wir werden uns später damit befassen. Um jedoch nicht wie eine Eule aus einer Anekdote über Hasen und Igel zu werden, gehen wir zur Taktik über.Allgemeines Schema
Also haben wir uns für den Algorithmus entschieden. Bei jedem Schritt lösen wir das Optimierungsproblem, finden die optimale Aktion für den Schritt, schließen sie ab und fahren mit dem nächsten Schritt fort.Es ist notwendig, bei jedem Schritt ein neues Problem zu lösen, denn mit jedem Spielverlauf ändert sich die Aufgabe ein wenig, neues Gold erscheint, jemand isst jemanden, die Spieler bewegen sich ...Aber denken Sie nicht, dass unser genialer Algorithmus für alles sorgen kann. Nachdem Sie das Optimierungsproblem gelöst haben, müssen Sie auf jeden Fall einen Handler hinzufügen, der nach unangenehmen Situationen sucht:- Stehender Bot für lange Zeit an Ort und Stelle
- Kontinuierliches Gehen von links nach rechts
- Mangel an Einkommen zu lange
All dies kann eine radikale Änderung der Strategie, Selbstmord oder eine andere Aktion außerhalb des Rahmens des Optimierungsalgorithmus erfordern. Die Art dieser Situationen kann unterschiedlich sein. Manchmal führen die Widersprüche zwischen Strategie und Taktik dazu, dass der Bot an einem Punkt einfriert, den er für strategisch wichtig hält, was von alten Botanikern namens Buridanov Donkey entdeckt wurde. Ihre Gegner können Ihren kurzen Weg zum begehrten Gold einfrieren und sperren - wir werden uns später darum kümmern.
Ihre Gegner können Ihren kurzen Weg zum begehrten Gold einfrieren und sperren - wir werden uns später darum kümmern.Der Kampf gegen den Aufschub
Betrachten Sie den einfachen Fall, in dem sich ein Gold rechts vom Bot befindet und sich in einem Radius von 8 keine Goldzellen mehr befinden. Welchen Schritt wird der Bot nach unserer Formel unternehmen? In der Tat - absolut keine. Zum Beispiel liefern alle diese Lösungen auch für drei Züge genau das gleiche Ergebnis:- Schritt nach links - Schritt nach rechts - Schritt nach rechts
- Schritt nach rechts - Untätigkeit - Untätigkeit
- Untätigkeit - Untätigkeit - Schritt nach rechts
Alle drei Optionen ergeben einen Gewinn von 100, der Bot kann die Option mit Untätigkeit auswählen, im nächsten Schritt das gleiche Problem erneut lösen, die Untätigkeit erneut auswählen ... und für immer stillstehen. Wir müssen die Formel zur Berechnung der Gewinne ändern, um den Bot zu stimulieren, so früh wie möglich zu handeln:
Wir haben den zukünftigen Gewinn im nächsten Schritt mit dem „Inflationskoeffizienten“ E multipliziert, der kleiner als 1 gewählt werden muss. Wir können sicher mit Werten von 0,95 oder 0,9 experimentieren. Aber wählen Sie es nicht zu klein, zum Beispiel mit einem Wert von E = 0,5, das Gold, das im 8. Zug gegessen wird, bringt nur 0,39 Punkte.Und so haben wir das Prinzip "Verschieben Sie nicht bis morgen, was Sie heute essen können" wiederentdeckt.Sicherheit
Gold zu sammeln ist sicherlich gut, aber Sie müssen immer noch über Sicherheit nachdenken. Wir haben zwei Aufgaben:- Bringe dem Bot bei, Löcher zu graben, wenn sich das Monster in einer geeigneten Position befindet
- Bringe dem Bot bei, vor Monstern davonzulaufen
Wir sagen dem Bot jedoch nicht, was er tun soll, sondern legen den Wert der Gewinnfunktion fest und der Optimierungsalgorithmus wählt die entsprechenden Schritte aus. Ein separates Problem ist, dass wir nicht genau berechnen, wo sich ein Monster in einer bestimmten Bewegung befinden kann. Der Einfachheit halber nehmen wir daher an, dass die Monster an Ort und Stelle sind, und wir müssen uns ihnen einfach nicht nähern.Wenn sie sich uns nähern, wird der Bot selbst vor ihnen davonlaufen, weil er dafür bestraft wird, dass er ihnen zu nahe ist (eine Art Selbstisolation). Und so führen wir zwei Regeln ein:- Wenn wir in einem Abstand d und d <= 3 zum Monster kommen, wird uns eine Geldstrafe von 100.500 * (4-d) / 4 auferlegt
- Wenn das Monster nahe genug gekommen ist, mit uns auf der gleichen Linie ist und es ein Loch zwischen uns gibt, dann bekommen wir etwas Gewinn P.
Das Konzept "näherte sich dem Monster in einer Entfernung d" werden wir etwas später eröffnen, aber jetzt wollen wir zur Strategie übergehen.Wir gehen um die Grafiken herum
Mathematisch gesehen ist das Problem der optimalen Goldumgehung ein seit langem gelöstes Problem eines reisenden Verkäufers, dessen Lösung kein Vergnügen ist. Bevor Sie solche Probleme lösen, müssen Sie sich eine einfache Frage überlegen - aber wie finden Sie den Abstand zwischen zwei Punkten im Spiel? Oder in einer etwas nützlicheren Form: Finden Sie für ein bestimmtes Gold und für jeden Punkt auf der Karte die Mindestanzahl von Zügen, für die der Spieler den Punkt aus Gold erreicht. Für einige Zeit werden wir vergessen, Löcher zu graben und in sie zu springen, wir werden nur natürliche Bewegungen pro 1 Zelle lassen. Nur wir werden in die entgegengesetzte Richtung gehen - von Gold und über die Karte.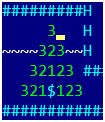 Im ersten Schritt wählen wir alle Zellen aus, aus denen wir in einem Zug Gold gewinnen können, und weisen sie 1 zu. Im zweiten Schritt wählen wir alle Zellen, aus denen wir in einem Schritt in diejenigen fallen, aus und weisen sie 2 zu. Das Bild zeigt den Fall für 3 Schritte. Versuchen wir nun, alles formal in einer für die Programmierung geeigneten Form aufzuschreiben.Wir brauchen:
Im ersten Schritt wählen wir alle Zellen aus, aus denen wir in einem Zug Gold gewinnen können, und weisen sie 1 zu. Im zweiten Schritt wählen wir alle Zellen, aus denen wir in einem Schritt in diejenigen fallen, aus und weisen sie 2 zu. Das Bild zeigt den Fall für 3 Schritte. Versuchen wir nun, alles formal in einer für die Programmierung geeigneten Form aufzuschreiben.Wir brauchen:- Der zweidimensionale numerische Array-Abstand [x, y], in dem das Ergebnis gespeichert wird. Für Goldkoordinaten enthält es zunächst 0 für die verbleibenden Punkte -1.
- Das oldBorder-Array, in dem wir die Punkte speichern, von denen aus wir uns bewegen, hat zunächst einen Punkt mit Goldkoordinaten
- Array newBorder, in dem die im aktuellen Schritt gefundenen Punkte gespeichert werden
- Für jeden Punkt p von oldBorder finden wir alle Punkte p_a, von denen aus wir p in einem Schritt erreichen können (genauer gesagt, wir machen einfach alle möglichen Schritte von p in die entgegengesetzte Richtung, z. B. ohne Unterstützung nach oben fliegen) und Entfernung [p_a] = - 1
- Wir platzieren jeden solchen Punkt p_a im Array newBorder, in der Entfernung [p_a] schreiben wir die Iterationsnummer
- Nachdem alle Punkte abgeschlossen sind:
- Tauschen Sie die Arrays von oldBorder und newBorder aus. Danach löschen wir newBorder
- Wenn oldBorder leer ist, beenden Sie den Algorithmus, andernfalls fahren Sie mit Schritt 1 fort.
Gleiches im Pseudocode:iter=1;
newBorder.clear();
distance.fill(-1);
distance[gold]=0;
oldBorder.push(gold);
while(oldBorder.isNotEmpty()) {
for (p: oldBorder){
for (p_a: backMove(p)) {
if (distance[p_a]==-1) {
newBorder.push(p_a);
distance[p_a]=iter;
}
}
}
Swap(newBorder, oldBorder);
newBorder.clear();
iter++;
}
Am Ausgang des Algorithmus haben wir eine Entfernungskarte mit dem Wert der Entfernung von jedem Punkt des gesamten Feldes des Spiels zu Gold. Für Punkte, von denen aus Gold nicht erreichbar ist, beträgt der Abstandswert -1. Mathematiker nennen einen solchen Spaziergang um das Spielfeld (der ein Diagramm mit Scheitelpunkten an Punkten im Feld und Kanten bildet, die die in einem Zug zugänglichen Scheitelpunkte verbinden) „Gehen Sie das Diagramm in der Breite“. Wenn wir eine Rekursion anstelle von zwei Rahmenarrays implementieren würden, würde dies als "Umgehen des Graphen in der Tiefe" bezeichnet. Da die Tiefe jedoch sehr groß sein kann (mehrere hundert), empfehle ich Ihnen, beim Durchlaufen von Graphen rekursive Algorithmen zu vermeiden.Der eigentliche Algorithmus wird etwas komplizierter sein, da ein Loch gegraben und hineingesprungen wird. Es stellt sich heraus, dass wir in 4 Zügen eine Zelle seitwärts und zwei nach unten bewegen (da wir uns in die entgegengesetzte Richtung und dann nach oben bewegen), aber eine leichte Modifikation des Algorithmus löst das Problem.Ich ergänzte das Bild mit Zahlen, einschließlich der Berücksichtigung, ein Loch zu graben und hinein zu springen: Woran erinnert uns das?
Woran erinnert uns das? Der Geruch von Gold! Und unser Bot wird sich für diesen Geruch entscheiden, wie Rocky für Käse (aber gleichzeitig verliert er nicht sein Gehirn und weicht Monstern aus und gräbt sogar Löcher für sie). Machen wir ihn zu einer einfachen gierigen Strategie:
Der Geruch von Gold! Und unser Bot wird sich für diesen Geruch entscheiden, wie Rocky für Käse (aber gleichzeitig verliert er nicht sein Gehirn und weicht Monstern aus und gräbt sogar Löcher für sie). Machen wir ihn zu einer einfachen gierigen Strategie:- Für jedes Gold erstellen wir eine Entfernungskarte und ermitteln die Entfernung zum Spieler.
- Wählen Sie das Gold, das dem Spieler am nächsten liegt, und nehmen Sie seine Karte, um die Strategie zu berechnen
- Geben Sie für jede Zelle der Karte mit d den Abstand zu Gold und dann den strategischen Wert an
Wo Dies ist ein imaginärer Wert von Gold. Es ist wünschenswert, dass es um ein Vielfaches unter dem gegenwärtigen Wert liegt Dies ist ein Inflationskoeffizient <1, denn je weiter das imaginäre Gold entfernt ist, desto billiger ist es. Das Verhältnis der Koeffizienten E undstellt ein ungelöstes Problem des Jahrtausends dar und lässt Raum für Kreativität.Denken Sie nicht, dass unser Bot immer zum nächsten Gold läuft. Nehmen wir an, wir haben links ein Gold in einem Abstand von 5 Zellen und dann eine Leere und rechts zwei Gold in einem Abstand von 6 und 7. Da echtes Gold wertvoller ist als gedacht, geht der Bot nach rechts.Bevor wir zu interessanteren Strategien übergehen, werden wir eine weitere Verbesserung vornehmen. Im Spiel zieht die Schwerkraft den Spieler nach unten und er kann nur die Treppe hinaufgehen. Das höhere Gold sollte also höher bewertet werden. Wenn die Höhe von der obersten Zeile nach unten angegeben wird, können Sie den Wert von Gold (mit vertikaler y-Koordinate) mit multiplizieren. Für den Koeffizienten Der neue Begriff „vertikale Inflationsrate“ wurde geprägt, zumindest wird er von Ökonomen nicht verwendet und spiegelt das Wesentliche gut wider.Strategien komplizieren
Wenn ein Gold aussortiert ist, müssen Sie mit all dem Gold etwas anfangen, und ich möchte keine schwere Mathematik anziehen. Es gibt eine sehr elegante, einfache und falsche (im engeren Sinne) Lösung: Wenn ein Gold ein „Wertfeld“ um sich herum erzeugt, fügen wir einfach alle Wertefelder aus allen Zellen mit Gold zu einer Matrix hinzu und verwenden es als Strategie. Ja, dies ist keine optimale Lösung, aber mehrere Goldeinheiten in mittlerer Entfernung können wertvoller sein als eine nahe Einheit.Eine neue Lösung schafft jedoch neue Probleme - eine neue Wertematrix kann lokale Maxima enthalten, in deren Nähe kein Gold vorhanden ist. Da unser Bot in sie eindringen kann und nicht ausgehen möchte, müssen wir einen Handler hinzufügen, der überprüft, ob der Bot das lokale Maximum der Strategie erreicht und gemäß den Ergebnissen des Umzugs an Ort und Stelle bleibt. Und jetzt haben wir ein Werkzeug zur Bekämpfung von Einfrierungen - brechen Sie diese Strategie mit N Zügen ab und kehren Sie vorübergehend zur Strategie des nächsten Goldes zurück.Es ist ziemlich lustig zu sehen, wie ein festsitzender Bot seine Strategie ändert und kontinuierlich nach unten geht und das nächste Gold frisst. In den unteren Etagen der Karte kommt der Bot zur Besinnung und versucht aufzusteigen. Eine Art Dr. Jekyll und Mr. Hyde.Strategie widerspricht Taktik
Hier kommt unser Bot unter dem Boden zu Gold: Es fällt bereits in den Optimierungsalgorithmus, es bleibt 3 Schritte nach rechts zu machen, ein Loch rechts zu schneiden und hinein zu springen, und dann wird die Schwerkraft alles von selbst tun. Etwas wie das:
Es fällt bereits in den Optimierungsalgorithmus, es bleibt 3 Schritte nach rechts zu machen, ein Loch rechts zu schneiden und hinein zu springen, und dann wird die Schwerkraft alles von selbst tun. Etwas wie das: Aber der Bot friert ein. Das Debuggen zeigte, dass es keinen Fehler gab: Der Bot entschied, dass die optimale Strategie darin bestand, einen Zug abzuwarten und dann den angegebenen Weg zu gehen und beim letzten analysierten Schritt Gold zu nehmen. Im ersten Fall erhält es einen Gewinn aus dem empfangenen Gold und einen Gewinn aus imaginärem Gold (bei der letzten analysierten Iteration befindet es sich nur in der Zelle, in der sich das Gold befand) und im zweiten Fall - nur aus echtem Gold (obwohl eine Runde früher), aber den Gewinn Es gibt keine Strategie mehr, weil der Platz unter dem Gold faul und nicht vielversprechend ist. Nun, im nächsten Zug beschließt er erneut, eine Pause einzulegen. Wir haben solche Probleme bereits gelöst.Ich musste die Strategie ändern - da wir das gesamte Gold, das in der Phase der Analyse gegessen wurde, auswendig lernten und die Wertkarten des verzehrten Goldes von der Gesamtmatrix des strategischen Werts subtrahierten, berücksichtigte die Strategie das Erreichen der Taktik (es war möglich, den Wert anders zu berechnen - Matrizen nur für hinzuzufügen ganzes Gold, aber es ist rechnerisch komplizierter, weil es viel mehr Gold auf der Karte gibt, als wir in 8 Zügen essen können).Aber das hat unsere Qual nicht beendet. Angenommen, die Matrix des strategischen Werts hat ein lokales Maximum und der Bot nähert sich ihm für 7 Züge. Wird der Bot dorthin gehen, um einzufrieren? Nein, denn für jede Route, auf der der Bot in 8 Zügen das lokale Maximum erreicht, ist der Gewinn der gleiche. Guter alter Aufschub. Der Grund dafür ist, dass der strategische Gewinn nicht von dem Moment abhängt, in dem wir uns in der Zelle befinden. Das erste, was mir in den Sinn kommt, ist, den Bot für einen einfachen zu bestrafen, aber dies hilft in keiner Weise, wenn man sinnlos nach links / rechts geht. Es ist notwendig, die Grundursache zu behandeln - um den strategischen Gewinn in jeder Runde (als Differenz zwischen dem strategischen Wert des neuen und des aktuellen Zustands) zu berücksichtigen und ihn im Laufe der Zeit um einen Faktor zu reduzieren.Jene. Fügen Sie einen zusätzlichen Begriff in den Ausdruck für das Gewinnen ein:
Aber der Bot friert ein. Das Debuggen zeigte, dass es keinen Fehler gab: Der Bot entschied, dass die optimale Strategie darin bestand, einen Zug abzuwarten und dann den angegebenen Weg zu gehen und beim letzten analysierten Schritt Gold zu nehmen. Im ersten Fall erhält es einen Gewinn aus dem empfangenen Gold und einen Gewinn aus imaginärem Gold (bei der letzten analysierten Iteration befindet es sich nur in der Zelle, in der sich das Gold befand) und im zweiten Fall - nur aus echtem Gold (obwohl eine Runde früher), aber den Gewinn Es gibt keine Strategie mehr, weil der Platz unter dem Gold faul und nicht vielversprechend ist. Nun, im nächsten Zug beschließt er erneut, eine Pause einzulegen. Wir haben solche Probleme bereits gelöst.Ich musste die Strategie ändern - da wir das gesamte Gold, das in der Phase der Analyse gegessen wurde, auswendig lernten und die Wertkarten des verzehrten Goldes von der Gesamtmatrix des strategischen Werts subtrahierten, berücksichtigte die Strategie das Erreichen der Taktik (es war möglich, den Wert anders zu berechnen - Matrizen nur für hinzuzufügen ganzes Gold, aber es ist rechnerisch komplizierter, weil es viel mehr Gold auf der Karte gibt, als wir in 8 Zügen essen können).Aber das hat unsere Qual nicht beendet. Angenommen, die Matrix des strategischen Werts hat ein lokales Maximum und der Bot nähert sich ihm für 7 Züge. Wird der Bot dorthin gehen, um einzufrieren? Nein, denn für jede Route, auf der der Bot in 8 Zügen das lokale Maximum erreicht, ist der Gewinn der gleiche. Guter alter Aufschub. Der Grund dafür ist, dass der strategische Gewinn nicht von dem Moment abhängt, in dem wir uns in der Zelle befinden. Das erste, was mir in den Sinn kommt, ist, den Bot für einen einfachen zu bestrafen, aber dies hilft in keiner Weise, wenn man sinnlos nach links / rechts geht. Es ist notwendig, die Grundursache zu behandeln - um den strategischen Gewinn in jeder Runde (als Differenz zwischen dem strategischen Wert des neuen und des aktuellen Zustands) zu berücksichtigen und ihn im Laufe der Zeit um einen Faktor zu reduzieren.Jene. Fügen Sie einen zusätzlichen Begriff in den Ausdruck für das Gewinnen ein:
Der Wert der Zielfunktion für letztere wird im Allgemeinen als Null angenommen: . Da der Gewinn bei jeder Bewegung durch Multiplikation mit einem Koeffizienten abgeschrieben wird, gewinnt unser Bot schneller an strategischem Gewinn und beseitigt das beobachtete Problem.Ungetestete Strategie
Ich habe diese Strategie in der Praxis nicht getestet, aber sie sieht vielversprechend aus.- Da wir alle Abstände zwischen den Goldpunkten und die Abstände zwischen dem Gold und dem Spieler kennen, können wir die Spieler-N-Kette von Goldzellen (wobei N klein ist, zum Beispiel 5 oder 6) mit der kürzesten Länge finden. Schon die einfachste Suche nach Zeit reicht aus.
- Wählen Sie das erste Gold in dieser Kette aus und verwenden Sie das Wertefeld als Strategiematrix.
In diesem Fall ist es wünschenswert, die Kosten für reales und das imaginäre Gold nahe zu bringen, damit der Bot nicht in den Keller zum nächsten Gold stürzt.Letzte Verbesserungen
Nachdem wir gelernt haben, uns auf der Karte zu „ausbreiten“, machen wir eine ähnliche „Ausbreitung“ von jedem Monster für mehrere Züge und finden alle Zellen, in denen das Monster landen kann, zusammen mit der Anzahl der Züge, für die es es machen wird. Dadurch kann der Spieler völlig sicher durch das Rohr über den Kopf des Monsters kriechen.Und im letzten Moment - bei der Berechnung der Strategie und des imaginären Wertes von Gold haben wir die Position der anderen Spieler nicht berücksichtigt, sondern sie bei der Analyse der Karte einfach „gelöscht“. Es stellt sich heraus, dass einzelne hängende Schalen den Zugang zu ganzen Regionen blockieren können. Daher wurde ein zusätzlicher Handler hinzugefügt, um gefrorene Gegner zu verfolgen und sie während der Analyse durch Betonblöcke zu ersetzen.Implementierungsfunktionen
Da der Hauptalgorithmus rekursiv ist, müssen wir in der Lage sein, Statusobjekte schnell zu ändern und sie zur weiteren Änderung auf ihre ursprünglichen zurückzusetzen. Ich habe Java verwendet, eine Sprache mit Garbage Collection. Das Ausprobieren von Millionen von Änderungen im Zusammenhang mit dem Erstellen kurzlebiger Objekte kann in einer Spielrunde zu mehreren Garbage Collections führen, was in Bezug auf die Geschwindigkeit fatal sein kann. Daher muss man bei den verwendeten Datenstrukturen äußerst vorsichtig sein, ich habe nur Arrays und Listen verwendet. Oder nutzen Sie das Valgala-Projekt auf eigene Gefahr und Gefahr :)Quellcode und Spieleserver
Den Quellcode finden Sie hier auf dem Github . Beurteilen Sie nicht streng, es wurde viel in Eile getan. Der Codenjoy- Spieleserver bietet die Infrastruktur zum Starten von Bots und zum Überwachen des Spiels. Zum Zeitpunkt der Erstellung war die Revision relevant, Revision 1.0.26 wurde verwendet.Sie können den Server mit der folgenden Zeile starten:call mvn -DMAVEN_OPTS=-Xmx1024m -Dmaven.test.skip=true clean jetty:run-war -Dcontext=another-context -Ploderunner
Das Projekt selbst ist äußerst neugierig und bietet Spiele für jeden Geschmack.Fazit
Wenn Sie dies alles ohne vorbereitende Vorbereitung bis zum Ende gelesen und alles verstanden haben, dann sind Sie ein seltener Kerl.