In komplexen ERP-Systemen haben viele Entitäten einen hierarchischen Charakter , wenn homogene Objekte in einem Beziehungsbaum zwischen Vorfahren und Nachkommen angeordnet sind. Dies ist die Organisationsstruktur des Unternehmens (all diese Zweige, Abteilungen und Arbeitsgruppen) sowie der Produktkatalog, die Arbeitsbereiche und die Geografie Verkaufsstellen, ... Tatsächlich gibt es keinen einzigen Bereich der Geschäftsautomatisierung, in dem zumindest eine gewisse Hierarchie nicht das Ergebnis wäre. Aber selbst wenn Sie nicht „geschäftlich“ arbeiten, können Sie leicht auf hierarchische Beziehungen stoßen. Selbst Ihr Stammbaum oder Grundriss der Räumlichkeiten im Einkaufszentrum hat dieselbe Struktur. Es gibt viele Möglichkeiten, einen solchen Baum in einem DBMS zu speichern, aber heute konzentrieren wir uns nur auf eine Option:
CREATE TABLE hier(
id
integer
PRIMARY KEY
, pid
integer
REFERENCES hier
, data
json
);
CREATE INDEX ON hier(pid);
Und während Sie in die Tiefen der Hierarchie blicken, wartet sie geduldig darauf, wie [nicht] effektiv Ihre "naiven" Arbeitsweisen mit einer solchen Struktur ausfallen werden.Lassen Sie uns die typischen neuen Aufgaben und ihre Implementierung in SQL analysieren und versuchen, ihre Leistung zu verbessern.# 1. Wie tief ist das Kaninchenloch?
Nehmen wir an, dass diese Struktur die Unterordnung der Abteilungen in die Struktur der Organisation widerspiegelt: Abteilungen, Abteilungen, Sektoren, Zweige, Arbeitsgruppen ... wie auch immer Sie sie nennen.Zuerst generieren wir unseren 'Baum' aus 10K-ElementenINSERT INTO hier
WITH RECURSIVE T AS (
SELECT
1::integer id
, '{1}'::integer[] pids
UNION ALL
SELECT
id + 1
, pids[1:(random() * array_length(pids, 1))::integer] || (id + 1)
FROM
T
WHERE
id < 10000
)
SELECT
pids[array_length(pids, 1)] id
, pids[array_length(pids, 1) - 1] pid
FROM
T;
Beginnen wir mit der einfachsten Aufgabe - alle Mitarbeiter zu finden, die in einem bestimmten Sektor oder in einer Hierarchie arbeiten -, um alle Nachkommen eines Knotens zu finden . Es wäre auch schön, die „Tiefe“ des Nachkommen zu ermitteln ... All dies kann beispielsweise erforderlich sein, um eine komplexe Auswahl aus der Liste der IDs dieser Mitarbeiter zu erstellen .Alles wäre in Ordnung, wenn es nur ein paar Ebenen dieser Nachkommen gibt und quantitativ innerhalb eines Dutzend, aber wenn es mehr als 5 Ebenen gibt und es bereits Dutzende von Nachkommen gibt, kann es Probleme geben. Mal sehen, wie die traditionellen Suchoptionen "down the tree" geschrieben sind (und funktionieren). Aber zuerst bestimmen wir, welcher der Knoten für unsere Forschung am interessantesten ist.Die "tiefsten" Teilbäume:WITH RECURSIVE T AS (
SELECT
id
, pid
, ARRAY[id] path
FROM
hier
WHERE
pid IS NULL
UNION ALL
SELECT
hier.id
, hier.pid
, T.path || hier.id
FROM
T
JOIN
hier
ON hier.pid = T.id
)
TABLE T ORDER BY array_length(path, 1) DESC;
id | pid | path
---------------------------------------------
7624 | 7623 | {7615,7620,7621,7622,7623,7624}
4995 | 4994 | {4983,4985,4988,4993,4994,4995}
4991 | 4990 | {4983,4985,4988,4989,4990,4991}
...
Die "breitesten" Teilbäume:...
SELECT
path[1] id
, count(*)
FROM
T
GROUP BY
1
ORDER BY
2 DESC;
id | count
------------
5300 | 30
450 | 28
1239 | 27
1573 | 25
Für diese Abfragen haben wir ein typisches rekursives JOIN verwendet :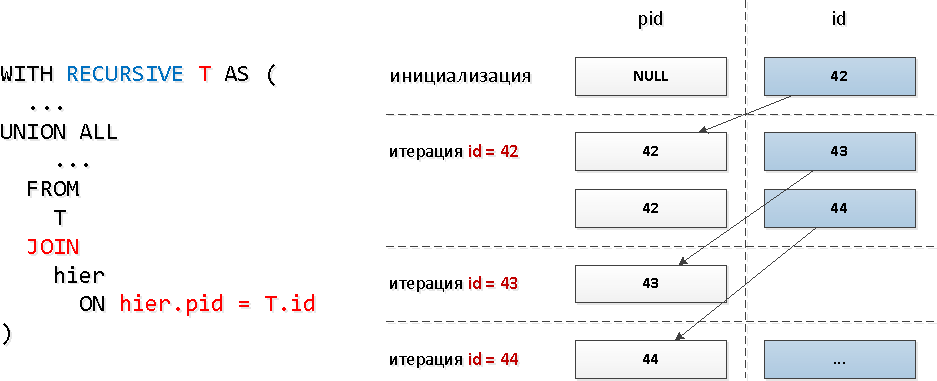 Bei diesem Abfragemodell stimmt die Anzahl der Iterationen natürlich mit der Gesamtzahl der Nachkommen überein (und es gibt mehrere Dutzend davon). Dies kann erhebliche Ressourcen und damit Zeit in Anspruch nehmen.Schauen wir uns den "breitesten" Teilbaum an:
Bei diesem Abfragemodell stimmt die Anzahl der Iterationen natürlich mit der Gesamtzahl der Nachkommen überein (und es gibt mehrere Dutzend davon). Dies kann erhebliche Ressourcen und damit Zeit in Anspruch nehmen.Schauen wir uns den "breitesten" Teilbaum an:WITH RECURSIVE T AS (
SELECT
id
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
hier.id
FROM
T
JOIN
hier
ON hier.pid = T.id
)
TABLE T;
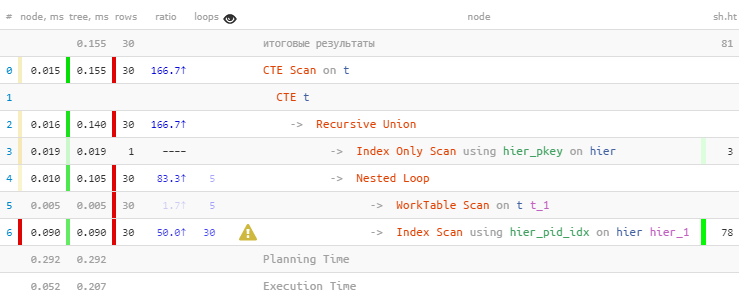 [siehe EXPLAIN.tensor.ru]Wie erwartet haben wir alle 30 Einträge gefunden. Aber sie haben 60% der gesamten Zeit damit verbracht - weil sie 30 Suchanfragen im Index durchgeführt haben. Und weniger - ist es möglich?
[siehe EXPLAIN.tensor.ru]Wie erwartet haben wir alle 30 Einträge gefunden. Aber sie haben 60% der gesamten Zeit damit verbracht - weil sie 30 Suchanfragen im Index durchgeführt haben. Und weniger - ist es möglich?Massendes Korrekturlesen nach Index
Und müssen wir für jeden Knoten eine separate Indexanforderung stellen? Es stellt sich heraus, dass nein - wir können mit einem Aufruf mehrere Schlüssel gleichzeitig aus dem Index lesen = ANY(array).Und in jeder solchen Gruppe von Bezeichnern können wir alle im vorherigen Schritt gefundenen IDs von "Knoten" übernehmen. Das heißt, bei jedem nächsten Schritt werden wir sofort nach allen Nachkommen eines bestimmten Levels gleichzeitig suchen .Es ist jedoch ein Pech, dass Sie in einer rekursiven Auswahl nicht in einer Unterabfrage auf sich selbst verweisen können , sondern nur irgendwie genau auswählen müssen, was auf der vorherigen Ebene gefunden wurde. Es stellt sich heraus, dass Sie keine Unterabfrage für die gesamte Stichprobe, sondern für das jeweilige Feld durchführen können. kann. Und dieses Feld kann auch ein Array sein - was wir verwenden müssenANY.Es klingt ein bisschen wild, aber auf dem Diagramm - alles ist einfach.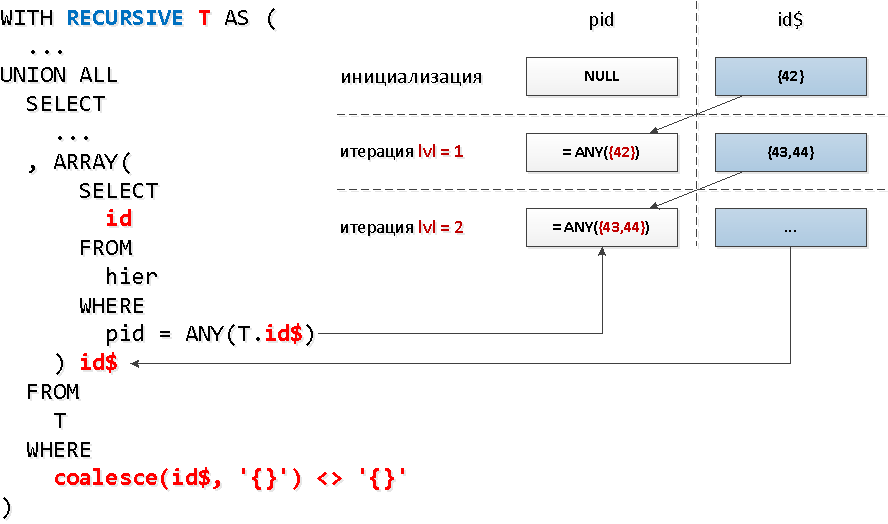
WITH RECURSIVE T AS (
SELECT
ARRAY[id] id$
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
ARRAY(
SELECT
id
FROM
hier
WHERE
pid = ANY(T.id$)
) id$
FROM
T
WHERE
coalesce(id$, '{}') <> '{}'
)
SELECT
unnest(id$) id
FROM
T;
 [siehe EXPLAIN.tensor.ru]Und hier ist das Wichtigste, nicht einmal 1,5 Mal in der Zeit zu gewinnen , sondern dass wir weniger Puffer abgezogen haben, da wir nur 5 Aufrufe des Index anstelle von 30 haben!Ein zusätzlicher Bonus ist die Tatsache, dass nach den letzten unnest Identifiers nach "Levels" geordnet bleiben.
[siehe EXPLAIN.tensor.ru]Und hier ist das Wichtigste, nicht einmal 1,5 Mal in der Zeit zu gewinnen , sondern dass wir weniger Puffer abgezogen haben, da wir nur 5 Aufrufe des Index anstelle von 30 haben!Ein zusätzlicher Bonus ist die Tatsache, dass nach den letzten unnest Identifiers nach "Levels" geordnet bleiben.Knoten-Tag
Die nächste Überlegung, die zur Verbesserung der Produktivität beiträgt, ist, dass „Blätter“ keine Kinder haben können , das heißt, sie müssen nicht nach etwas suchen. Bei der Formulierung unserer Aufgabe bedeutet dies, dass wir nicht weiter in dieser Branche suchen müssen, wenn wir entlang der Abteilungskette gegangen sind und den Mitarbeiter erreicht haben.Lassen Sie uns ein zusätzliches booleanFeld in unsere Tabelle einfügen , das uns sofort sagt, ob dieser bestimmte Eintrag in unserem Baum ein „Knoten“ ist - das heißt , wenn er überhaupt Kinder haben kann.ALTER TABLE hier
ADD COLUMN branch boolean;
UPDATE
hier T
SET
branch = TRUE
WHERE
EXISTS(
SELECT
NULL
FROM
hier
WHERE
pid = T.id
LIMIT 1
);
Fein! Es stellt sich heraus, dass nur etwas mehr als 30% aller Baumelemente Nachkommen haben.Jetzt wenden LATERALwir eine etwas andere Mechanik an - die Verbindung zum rekursiven Teil durch , die es uns ermöglicht, sofort auf die Felder der rekursiven "Tabelle" zuzugreifen und die Aggregatfunktion mit der Filterbedingung basierend auf dem Knoten zu verwenden, um den Schlüsselsatz zu reduzieren: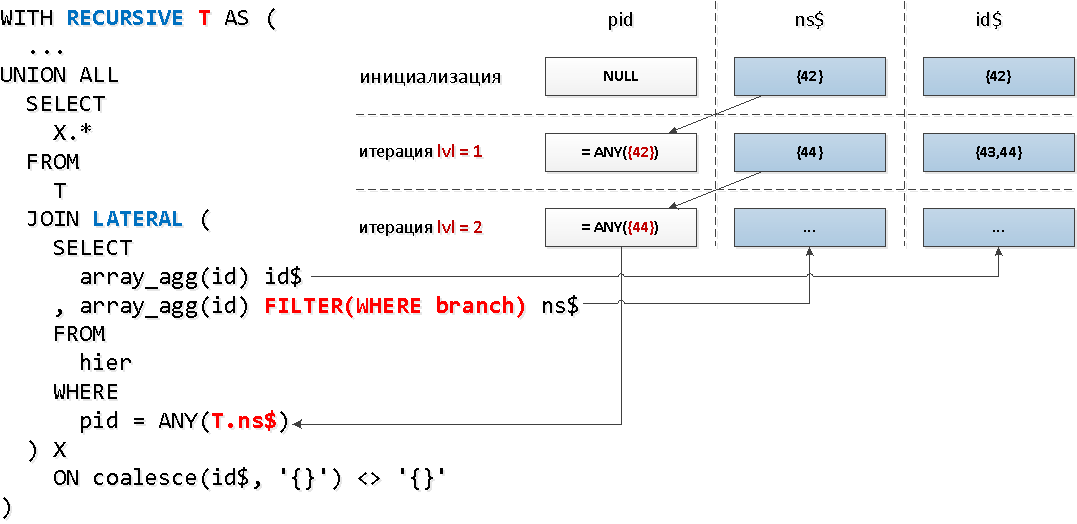
WITH RECURSIVE T AS (
SELECT
array_agg(id) id$
, array_agg(id) FILTER(WHERE branch) ns$
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
X.*
FROM
T
JOIN LATERAL (
SELECT
array_agg(id) id$
, array_agg(id) FILTER(WHERE branch) ns$
FROM
hier
WHERE
pid = ANY(T.ns$)
) X
ON coalesce(T.ns$, '{}') <> '{}'
)
SELECT
unnest(id$) id
FROM
T;
 [siehe EXPLAIN.tensor.ru]Wir konnten eine weitere Attraktivität des Index reduzieren und haben mehr als zweimal in Bezug auf den abgezogenen Betrag gewonnen .
[siehe EXPLAIN.tensor.ru]Wir konnten eine weitere Attraktivität des Index reduzieren und haben mehr als zweimal in Bezug auf den abgezogenen Betrag gewonnen .# 2 Zurück zu den Wurzeln
Dieser Algorithmus ist nützlich, wenn Sie Datensätze für alle Elemente „im Baum“ sammeln müssen, während Sie Informationen darüber beibehalten, welches Quellblatt (und mit welchen Indikatoren) dazu geführt hat, dass es in die Stichprobe fällt - beispielsweise um einen zusammenfassenden Bericht mit Aggregation zu Knoten zu erstellen.Das weitere sollte ausschließlich als Proof-of-Concept angesehen werden, da die Anfrage sehr umständlich ist. Wenn es jedoch Ihre Datenbank dominiert, sollten Sie die Verwendung solcher Techniken in Betracht ziehen.Beginnen wir mit ein paar einfachen Aussagen:- Es ist besser, denselben Datensatz nur einmal aus der Datenbank zu lesen .
- Einträge aus der Datenbank werden in einem "Bundle" effizienter gelesen als einzeln.
Versuchen wir nun, die Abfrage zu entwerfen, die wir benötigen.Schritt 1
Offensichtlich müssen wir bei der Initialisierung der Rekursion (wo ohne sie!) Die Aufzeichnungen der Blätter selbst von der Menge der Quellkennungen subtrahieren:WITH RECURSIVE tree AS (
SELECT
rec
, id::text chld
FROM
hier rec
WHERE
id = ANY('{1,2,4,8,16,32,64,128,256,512,1024,2048,4096,8192}'::integer[])
UNION ALL
...
Wenn es jemandem seltsam erschien, dass das „Set“ in einer Zeichenfolge und nicht in einem Array gespeichert ist, gibt es eine einfache Erklärung. Für Strings gibt es eine eingebaute aggregierende "Klebe" -Funktion string_agg, für Arrays jedoch nein. Obwohl es nicht schwierig ist, es selbst zu implementieren .Schritt 2
Jetzt würden wir eine Reihe von Abschnitts-IDs erhalten, die weiter subtrahiert werden müssen. Fast immer werden sie in verschiedenen Datensätzen des Quellensatzes dupliziert - daher würden wir sie gruppieren und gleichzeitig Informationen über die Quellblätter beibehalten.Aber hier erwarten uns drei Probleme:- Der „sub-rekursive“ Teil einer Abfrage kann keine Aggregatfunktionen c enthalten
GROUP BY. - Ein Aufruf einer rekursiven "Tabelle" kann nicht in einer verschachtelten Unterabfrage erfolgen.
- Eine Abfrage im rekursiven Teil darf keinen CTE enthalten.
Glücklicherweise lassen sich all diese Probleme leicht umgehen. Beginnen wir am Ende.CTE im rekursiven Teil
So funktioniert es nicht :WITH RECURSIVE tree AS (
...
UNION ALL
WITH T (...)
SELECT ...
)
Und so funktioniert es, Klammern entscheiden!WITH RECURSIVE tree AS (
...
UNION ALL
(
WITH T (...)
SELECT ...
)
)
Verschachtelte Abfrage für rekursive "Tabelle"
Hmm ... Ein Aufruf eines rekursiven CTE kann nicht in einer Unterabfrage erfolgen. Aber es kann innerhalb des CTE sein! Eine Unteranfrage kann bereits auf diesen CTE verweisen!GROUP BY innerhalb der Rekursion
Es ist unangenehm, aber ... Wir haben auch eine einfache Möglichkeit, GROUP BY mithilfe von DISTINCT ONFensterfunktionen zu simulieren !SELECT
(rec).pid id
, string_agg(chld::text, ',') chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
GROUP BY 1
Und so funktioniert es!SELECT DISTINCT ON((rec).pid)
(rec).pid id
, string_agg(chld::text, ',') OVER(PARTITION BY (rec).pid) chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
Jetzt sehen wir, warum die numerische ID in Text umgewandelt wurde - damit sie mit einem Komma zusammengeklebt werden können!Schritt 3
Für das Finale haben wir nichts mehr übrig:- Wir lesen Aufzeichnungen von "Abschnitten" auf einer Reihe von gruppierten IDs
- Ordnen Sie die subtrahierten Abschnitte den „Sätzen“ der Quellblätter zu
- Erweitern Sie die festgelegte Zeichenfolge mit
unnest(string_to_array(chld, ',')::integer[])
WITH RECURSIVE tree AS (
SELECT
rec
, id::text chld
FROM
hier rec
WHERE
id = ANY('{1,2,4,8,16,32,64,128,256,512,1024,2048,4096,8192}'::integer[])
UNION ALL
(
WITH prnt AS (
SELECT DISTINCT ON((rec).pid)
(rec).pid id
, string_agg(chld::text, ',') OVER(PARTITION BY (rec).pid) chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
)
, nodes AS (
SELECT
rec
FROM
hier rec
WHERE
id = ANY(ARRAY(
SELECT
id
FROM
prnt
))
)
SELECT
nodes.rec
, prnt.chld
FROM
prnt
JOIN
nodes
ON (nodes.rec).id = prnt.id
)
)
SELECT
unnest(string_to_array(chld, ',')::integer[]) leaf
, (rec).*
FROM
tree;
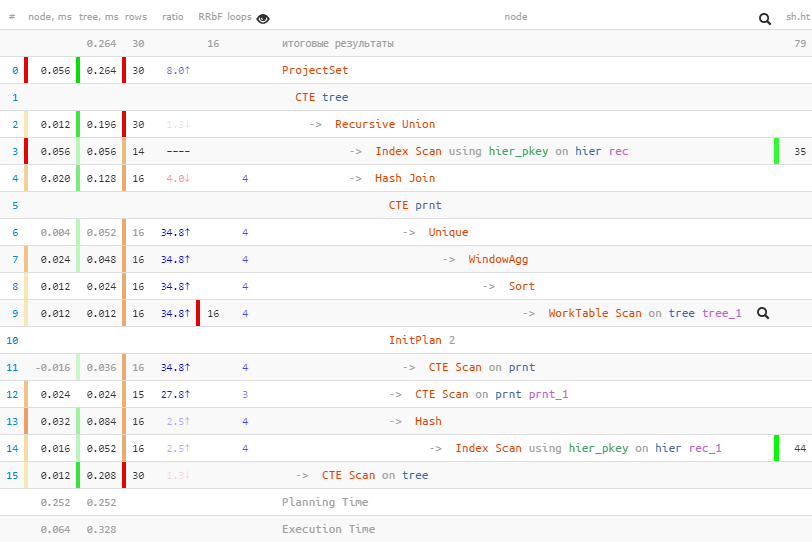 [ explain.tensor.ru]
[ explain.tensor.ru]