 Hallo habrozhiteli! Paul und Harvey Daytels bieten einen neuen Blick auf Python und verwenden einen einzigartigen Ansatz, um die Probleme moderner IT-Mitarbeiter schnell zu lösen.Zu Ihrer Verfügung stehen mehr als fünfhundert reale Aufgaben - von Fragmenten bis zu 40 großen Szenarien und Beispielen mit vollständiger Implementierung. Mit IPython mit Jupyter Notebooks können Sie schnell moderne Python-Programmiersprachen lernen. Die Kapitel 1–5 und Fragmente der Kapitel 6–7 enthalten klare Beispiele für die Lösung von Problemen mit künstlicher Intelligenz aus den Kapiteln 11–16. Sie lernen die Verarbeitung natürlicher Sprache, Emotionsanalyse auf Twitter, kognitives Computing von IBM Watson, maschinelles Lernen mit einem Lehrer in Klassifizierungs- und Regressionsproblemen, maschinelles Lernen ohne Lehrer in Clustering, Mustererkennung mit tiefem Lernen und Faltungs-Neuronalen Netzen, wiederkehrende neuronale Netze, groß Daten von Hadoop, Spark und NoSQL, IoT und mehr. Sie arbeiten (direkt oder indirekt) mit Cloud-Diensten wie Twitter, Google Translate, IBM Watson,Microsoft Azure, OpenMapQuest, PubNub usw.
Hallo habrozhiteli! Paul und Harvey Daytels bieten einen neuen Blick auf Python und verwenden einen einzigartigen Ansatz, um die Probleme moderner IT-Mitarbeiter schnell zu lösen.Zu Ihrer Verfügung stehen mehr als fünfhundert reale Aufgaben - von Fragmenten bis zu 40 großen Szenarien und Beispielen mit vollständiger Implementierung. Mit IPython mit Jupyter Notebooks können Sie schnell moderne Python-Programmiersprachen lernen. Die Kapitel 1–5 und Fragmente der Kapitel 6–7 enthalten klare Beispiele für die Lösung von Problemen mit künstlicher Intelligenz aus den Kapiteln 11–16. Sie lernen die Verarbeitung natürlicher Sprache, Emotionsanalyse auf Twitter, kognitives Computing von IBM Watson, maschinelles Lernen mit einem Lehrer in Klassifizierungs- und Regressionsproblemen, maschinelles Lernen ohne Lehrer in Clustering, Mustererkennung mit tiefem Lernen und Faltungs-Neuronalen Netzen, wiederkehrende neuronale Netze, groß Daten von Hadoop, Spark und NoSQL, IoT und mehr. Sie arbeiten (direkt oder indirekt) mit Cloud-Diensten wie Twitter, Google Translate, IBM Watson,Microsoft Azure, OpenMapQuest, PubNub usw.9.12.2. Lesen von CSV-Dateien in der DataFrame-Sammlung der Pandas-Bibliothek
In den Abschnitten „Einführung in die Datenwissenschaft“ der beiden vorherigen Kapitel wurden die Grundlagen der Arbeit mit Pandas vorgestellt. Jetzt werden wir die Pandas-Tools zum Herunterladen von CSV-Dateien demonstrieren und dann die grundlegenden Datenanalysevorgänge durchführen.Datensätze
In praktischen datenwissenschaftlichen Beispielen werden verschiedene freie und offene Datensätze verwendet, um die Konzepte des maschinellen Lernens und der Verarbeitung natürlicher Sprache zu demonstrieren. Im Internet steht eine Vielzahl kostenloser Datensätze zur Verfügung. Das beliebte Rdatasets-Repository enthält Links zu über 1.100 kostenlosen CSV-Datensätzen. Diese Kits wurden ursprünglich mit der Programmiersprache R ausgeliefert, um das Studium und die Entwicklung statistischer Programme zu vereinfachen. Sie beziehen sich jedoch nicht auf die R-Sprache. Diese Kits sind jetzt auf GitHub unter folgender Adresse verfügbar:https://vincentarelbundock.imtqy.com/Rdatasets/ Datasets.htmlDieses Repository ist so beliebt, dass es ein Pydataset-Modul gibt, das speziell für den Zugriff auf Rdatasets entwickelt wurde. Anweisungen zum Installieren von pydataset und zum Zugreifen auf Datasets finden Sie unter:https://github.com/iamaziz/PyDataset
Eine weitere großartige Quelle für Datasets:https://github.com/awesomedata/awesome-public-datasetsEin häufig verwendeter Datensatz für maschinelles Lernen für Anfänger ist der Titanic-Crash-Datensatz, in dem alle Passagiere aufgelistet sind und ob sie überlebt haben, als die Titanic mit einem Eisberg kollidierte und vom 14. bis 15. April 1912 sank. Wir werden diesen Satz verwenden, um zu zeigen, wie ein Datensatz geladen, seine Daten angezeigt und beschreibende Statistiken abgeleitet werden. Weitere beliebte Datensätze werden in den Beispielkapiteln zu Data Science weiter unten in diesem Buch erläutert.Arbeiten mit lokalen CSV-DateienUm ein CSV-Dataset in einen DataFrame zu laden, können Sie die Funktion read_csv der Pandas-Bibliothek verwenden. Mit dem folgenden Snippet wird die zuvor in diesem Kapitel erstellte Datei CSV accounts.csv heruntergeladen und angezeigt:In [1]: import pandas as pd
In [2]: df = pd.read_csv('accounts.csv',
...: names=['account', 'name', 'balance'])
...:
In [3]: df
Out[3]:
account name balance
0 100 Jones 24.98
1 200 Doe 345.67
2 300 White 0.00
3 400 Stone -42.16
4 500 Rich 224.62
Das Argument names gibt die Spaltennamen des DataFrame an. Ohne dieses Argument betrachtet read_csv die erste Zeile der CSV-Datei als durch Kommas getrennte Liste von Spaltennamen.Rufen Sie zum Speichern der DataFrame-Daten in einer CSV-Datei die Methode to_csv der DataFrame-Auflistung auf:In [4]: df.to_csv('accounts_from_dataframe.csv', index=False)
Das Schlüsselargument index = False bedeutet, dass die Zeilennamen (0–4 auf der linken Seite der DataFrame-Ausgabe in Fragment [3]) nicht in die Datei geschrieben werden sollten. Die erste Zeile der resultierenden Datei enthält die Spaltennamen:account,name,balance
100,Jones,24.98
200,Doe,345.67
300,White,0.0
400,Stone,-42.16
500,Rich,224.62
9.12.3. Lesen des Titanic Disaster Dataset
Der Titanic-Katastrophen-Datensatz ist einer der beliebtesten Datensätze für maschinelles Lernen und in vielen Formaten verfügbar, einschließlich CSV.Laden Sie den Titanic Disaster Dataset unter der URL herunter
Wenn Sie eine URL haben, die ein Dataset im CSV-Format darstellt, können Sie es mit der Funktion read_csv in einen DataFrame laden - sagen wir von GitHub:In [1]: import pandas as pd
In [2]: titanic = pd.read_csv('https://vincentarelbundock.imtqy.com/' +
...: 'Rdatasets/csv/carData/TitanicSurvival.csv')
...:
Anzeigen einiger Zeilen des Titanic-Katastrophen-Datensatzes Der Datensatzenthält über 1300 Zeilen, wobei jede Zeile einen Passagier darstellt. Laut Wikipedia befanden sich ungefähr 1317 Passagiere an Bord, von denen 815 starben1. Bei großen Datenmengen werden bei der Ausgabe des DataFrame nur die ersten 30 Zeilen angezeigt, dann werden die Auslassungspunkte "..." und die letzten 30 Zeilen angezeigt. Um Platz zu sparen, überprüfen wir die ersten und letzten fünf Zeilen mit den Head- und Tail-Methoden der DataFrame-Auflistung. Beide Methoden geben standardmäßig fünf Zeilen zurück, aber die Anzahl der angezeigten Zeilen kann im Argument übergeben werden:In [3]: pd.set_option ('Genauigkeit', 2) # Format für GleitkommawerteBitte beachten Sie: Pandas passt die Breite jeder Spalte basierend auf dem breitesten Wert in der Spalte oder dem Spaltennamen an (je nachdem, welcher die größte Breite hat). In der Altersspalte der Zeile 1305 steht NaN - ein Zeichen für einen fehlenden Wert im Datensatz.Spaltennamen festlegenDer Name der ersten Spalte im Dataset sieht ziemlich seltsam aus ('Unbenannt: 0'). Dieses Problem kann durch Anpassen der Spaltennamen behoben werden. Ersetzen Sie 'Unbenannt: 0' durch 'Name' und reduzieren Sie 'Passagierklasse' auf 'Klasse':

9.12.4. Einfache Datenanalyse am Beispiel des Titanic-Katastrophen-Datensatzes
Jetzt werden wir Pandas verwenden, um eine einfache Datenanalyse am Beispiel einiger Merkmale der deskriptiven Statistik durchzuführen. Wenn Sie "Beschreiben" für eine DataFrame-Auflistung aufrufen, die sowohl numerische als auch nicht numerische Spalten enthält, berechnet "Beschreiben" statistische Merkmale nur für numerische Spalten - in diesem Fall nur für die Altersspalte: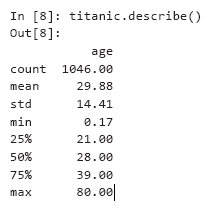 Beachten Sie die Unterschiede in der Anzahl (1046) und der Anzahl der Datenzeilen im Dataset (1309 - beim Aufrufen von tail betrug der Index der letzten Zeile 1308). Nur 1046 Datenzeilen (Zählwert) enthielten einen Alterswert. Die verbleibenden Ergebnisse fehlten und wurden wie in Zeile 1305 mit NaN markiert. Bei der Durchführung von Berechnungen ignoriert die Pandas-Bibliothek standardmäßig fehlende Daten (NaN). Für 1046 Passagiere mit einem gültigen Alter betrug das Durchschnittsalter (Erwartung) 29,88 Jahre. Der jüngste Passagier (min) war nur zwei Monate alt (0,17 * 12 ergibt 2,04), und der älteste (max) war 80 Jahre alt. Das Durchschnittsalter betrug 28 Jahre (angezeigt durch ein 50-prozentiges Quartil). Das 25-Prozent-Quartil beschreibt das Durchschnittsalter in der ersten Hälfte der Passagiere (nach Alter geordnet).und das 75-Prozent-Quartil ist der Median in der zweiten Hälfte der Passagiere.Angenommen, Sie möchten Statistiken über überlebende Passagiere berechnen. Wir können die überlebte Spalte mit dem Wert 'yes' vergleichen, um eine neue Series-Sammlung mit True / False-Werten zu erhalten, und dann mit description die Ergebnisse beschreiben:
Beachten Sie die Unterschiede in der Anzahl (1046) und der Anzahl der Datenzeilen im Dataset (1309 - beim Aufrufen von tail betrug der Index der letzten Zeile 1308). Nur 1046 Datenzeilen (Zählwert) enthielten einen Alterswert. Die verbleibenden Ergebnisse fehlten und wurden wie in Zeile 1305 mit NaN markiert. Bei der Durchführung von Berechnungen ignoriert die Pandas-Bibliothek standardmäßig fehlende Daten (NaN). Für 1046 Passagiere mit einem gültigen Alter betrug das Durchschnittsalter (Erwartung) 29,88 Jahre. Der jüngste Passagier (min) war nur zwei Monate alt (0,17 * 12 ergibt 2,04), und der älteste (max) war 80 Jahre alt. Das Durchschnittsalter betrug 28 Jahre (angezeigt durch ein 50-prozentiges Quartil). Das 25-Prozent-Quartil beschreibt das Durchschnittsalter in der ersten Hälfte der Passagiere (nach Alter geordnet).und das 75-Prozent-Quartil ist der Median in der zweiten Hälfte der Passagiere.Angenommen, Sie möchten Statistiken über überlebende Passagiere berechnen. Wir können die überlebte Spalte mit dem Wert 'yes' vergleichen, um eine neue Series-Sammlung mit True / False-Werten zu erhalten, und dann mit description die Ergebnisse beschreiben:In [9]: (titanic.survived == 'yes').describe()
Out[9]:
count 1309
unique 2
top False
freq 809
Name: survived, dtype: object
Beschreiben Sie für nicht numerische Daten verschiedene Merkmale der beschreibenden Statistik:- count - die Gesamtzahl der Elemente im Ergebnis;
- eindeutig - die Anzahl der eindeutigen Werte (2) als Ergebnis - Richtig (der Passagier hat überlebt) oder Falsch (der Passagier ist gestorben);
- top - der Wert, der als Ergebnis am häufigsten angetroffen wird;
- freq - die Anzahl der Vorkommen des Werts top.
9.12.5. Balkendiagramm des Passagieralters
Visualisierung ist ein guter Weg, um die Daten besser kennenzulernen. Pandas enthält viele integrierte Visualisierungstools, die auf Matplotlib basieren. Um sie zu verwenden, aktivieren Sie zuerst die Matplotlib-Unterstützung in IPython:In [10]: %matplotlib
Das Histogramm zeigt deutlich die Verteilung der numerischen Daten über einen Wertebereich. Die hist-Methode der DataFrame-Sammlung analysiert automatisch die Daten jeder numerischen Spalte und erstellt das entsprechende Histogramm. Um die Histogramme für jede numerische Datenspalte anzuzeigen, rufen Sie hist für Ihre DataFrame-Sammlung auf:In [11]: histogram = titanic.hist()
Der Titanic-Katastrophen-Datensatz enthält nur eine numerische Datenspalte, sodass das Diagramm ein Histogramm für die Altersverteilung zeigt. Für Datensätze mit mehreren numerischen Spalten erstellt hist für jede numerische Spalte ein separates Histogramm.»Weitere Informationen zum Buch finden Sie auf der Website des Herausgebers.» Inhalt» Auszugfür Khabrozhiteley 25% Rabatt auf den Gutschein - PythonNach Zahlung der Papierversion des Buches (Erscheinungsdatum - 5. Juni ) wird ein E-Book gesendet.