Hallo Habr! Heute werden wir in einer so scheinbar einfachen Operation ausführlich über nicht offensichtliche Punkte sprechen: die Korrektur projektiver Verzerrungen im Bild. Wie so oft im Leben mussten wir uns entscheiden, was wichtiger ist: Qualität oder Geschwindigkeit. Um ein gewisses Gleichgewicht zu erreichen, haben wir uns an die Algorithmen erinnert, die wir in den 80-90er Jahren im Rahmen der Aufgabe des Renderns von Strukturen aktiv untersucht haben, und seitdem haben wir uns im Kontext der Bildverarbeitung selten daran erinnert. Bei Interesse unter die Katze schauen! Das Lochkameramodell, das in der Praxis auch Nahaufnahmen von Mobiltelefonen recht gut liefert, sagt uns, dass beim Drehen der Kamera Bilder eines flachen Objekts durch projektive Transformation miteinander verbunden werden. Die allgemeine Ansicht der projektiven Transformation lautet wie folgt:
Das Lochkameramodell, das in der Praxis auch Nahaufnahmen von Mobiltelefonen recht gut liefert, sagt uns, dass beim Drehen der Kamera Bilder eines flachen Objekts durch projektive Transformation miteinander verbunden werden. Die allgemeine Ansicht der projektiven Transformation lautet wie folgt:
Wo projektive Transformationsmatrix, und Koordinaten auf der Quelle und konvertierte Bilder.Geometrische Bildkonvertierung
Die projektive Bildtransformation ist eine der möglichen geometrischen Transformationen von Bildern (solche Transformationen, bei denen die Punkte des Originalbildes nach einem bestimmten Gesetz zu den Punkten des endgültigen Bildes gehen).Um zu verstehen, wie das Problem der geometrischen Transformation eines digitalen Bildes gelöst werden kann, müssen Sie das Modell seiner Entstehung aus einem optischen Bild auf der Kameramatrix betrachten. Nach G. Wahlberg [1] sollte unser Algorithmus den folgenden Prozess approximieren:- Stellen Sie das optische Bild von digital wieder her.
- Geometrische Transformation des optischen Bildes.
- Abtastung des konvertierten Bildes.
Ein optisches Bild ist eine Funktion von zwei Variablen, die auf einem kontinuierlichen Satz von Punkten definiert sind. Dieser Prozess ist schwer direkt zu reproduzieren, da wir den Typ des optischen Bildes analytisch einstellen und verarbeiten müssen. Um diesen Prozess zu vereinfachen, wird normalerweise die umgekehrte Zuordnungsmethode verwendet:- In der Ebene des endgültigen Bildes wird ein Abtastgitter ausgewählt - die Punkte, anhand derer wir die Pixelwerte des endgültigen Bildes auswerten (dies kann die Mitte jedes Pixels sein oder einige Punkte pro Pixel).
- Mit der inversen geometrischen Transformation wird dieses Raster in den Raum des Originalbilds übertragen.
- Für jede Gitterprobe wird ihr Wert geschätzt. Da es nicht unbedingt an einem Punkt mit ganzzahligen Koordinaten erscheint, benötigen wir eine Interpolation des Bildwerts, beispielsweise eine Interpolation durch benachbarte Pixel.
- Gemäß den Rasterberichten schätzen wir die Pixelwerte des endgültigen Bildes.
Hier entspricht Schritt 3 der Wiederherstellung des optischen Bildes, und die Schritte 1 und 4 entsprechen der Abtastung.Interpolation
Hier werden nur einfache Arten der Interpolation betrachtet - solche, die als Faltung des Bildes mit dem Interpolationskern dargestellt werden können. Im Kontext der Bildverarbeitung wären adaptive Interpolationsalgorithmen, die klare Grenzen von Objekten beibehalten, besser, aber ihre Rechenkomplexität ist viel höher und daher sind wir nicht interessiert.Wir werden die folgenden Interpolationsmethoden betrachten:- um das nächste Pixel
- bilinear
- bikubisch
- kubischer B-Spline
- kubischer Einsiedler-Spline, 36 Punkte.
Die Interpolation hat auch einen so wichtigen Parameter wie die Genauigkeit. Wenn wir annehmen, dass das digitale Bild mit der optischen Methode durch Punktabtastung in der Mitte des Pixels erhalten wurde und glauben, dass das Originalbild kontinuierlich war, ist das Tiefpassfilter mit einer Frequenz von ½ eine ideale Rekonstruktionsfunktion (siehe Kotelnikovs Theorem ).Daher vergleichen wir die Fourier-Spektren unserer Interpolationskerne mit einem Tiefpassfilter (in den Abbildungen ist der eindimensionale Fall dargestellt).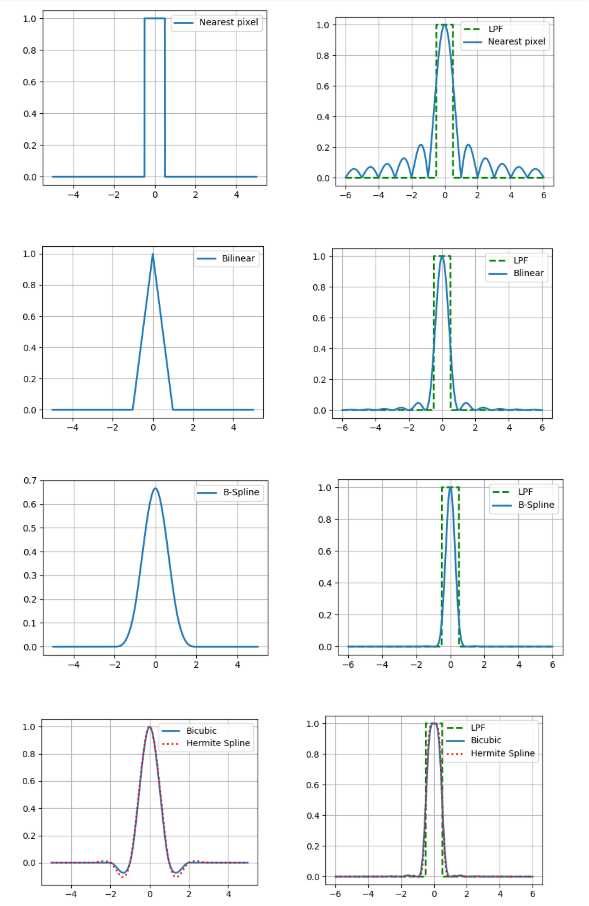 Und was, Sie können einfach einen Kernel mit einem ziemlich guten Spektrum nehmen und relativ genaue Ergebnisse erhalten? Eigentlich nicht, weil wir oben zwei Annahmen getroffen haben: dass es einen Pixelwert des Bildes gibt und dass das Bild kontinuierlich ist. Gleichzeitig ist weder das eine noch das andere Teil eines guten Modells der Bilderzeugung, da die Sensoren auf der Kameramatrix nicht punktförmig sind und auf dem Bild viele Informationen die Grenzen von Objekten tragen - Lücken. Daher sollte leider verstanden werden, dass sich das Ergebnis der Interpolation immer vom ursprünglichen optischen Bild unterscheidet.Sie müssen jedoch noch etwas tun, daher werden wir die Vor- und Nachteile jeder der betrachteten Methoden aus praktischer Sicht kurz beschreiben. Dies lässt sich am einfachsten erkennen, wenn Sie das Bild vergrößern (in diesem Beispiel zehnmal).
Und was, Sie können einfach einen Kernel mit einem ziemlich guten Spektrum nehmen und relativ genaue Ergebnisse erhalten? Eigentlich nicht, weil wir oben zwei Annahmen getroffen haben: dass es einen Pixelwert des Bildes gibt und dass das Bild kontinuierlich ist. Gleichzeitig ist weder das eine noch das andere Teil eines guten Modells der Bilderzeugung, da die Sensoren auf der Kameramatrix nicht punktförmig sind und auf dem Bild viele Informationen die Grenzen von Objekten tragen - Lücken. Daher sollte leider verstanden werden, dass sich das Ergebnis der Interpolation immer vom ursprünglichen optischen Bild unterscheidet.Sie müssen jedoch noch etwas tun, daher werden wir die Vor- und Nachteile jeder der betrachteten Methoden aus praktischer Sicht kurz beschreiben. Dies lässt sich am einfachsten erkennen, wenn Sie das Bild vergrößern (in diesem Beispiel zehnmal).Nächste Pixelinterpolation
Am einfachsten und schnellsten führt es jedoch zu starken Artefakten.Bilineare Interpolation
Bessere Qualität, erfordert jedoch mehr Rechenaufwand und verwischt zusätzlich die Grenzen von Objekten.Bikubische Interpolation
Noch besser in durchgehenden Bereichen, aber am Rand gibt es einen Halo-Effekt (ein dunklerer Streifen am dunklen Rand des Randes und ein heller am Licht). Um diesen Effekt zu vermeiden, müssen Sie einen nicht negativen Faltungskern wie einen kubischen B-Spline verwenden.B-Spline-Interpolation
Der B-Spline hat ein sehr enges Spektrum, was ein starkes "Unschärfe" -Bild bedeutet (aber auch eine gute Rauschunterdrückung, was nützlich sein kann).Interpolation basierend auf einem kubischen Hermite-Spline
Ein solcher Spline erfordert eine Schätzung der partiellen Ableitungen in jedem Pixel des Bildes. Wenn wir zur Annäherung ein 2-Punkt-Differenzschema wählen, erhalten wir den Kern der bikubischen Interpolation, also verwenden wir hier 4-Punkt.Wir vergleichen diese Methoden auch hinsichtlich der Anzahl der Speicherzugriffe (die Anzahl der Pixel des Originalbilds für die Interpolation an einem Punkt) und der Anzahl der Multiplikationen mit Punkten.Es ist ersichtlich, dass die letzten 3 Methoden wesentlich rechenintensiver sind als die ersten 2.Probenahme
Dies ist genau der Schritt, dem in letzter Zeit zu Unrecht wenig Beachtung geschenkt wurde. Der einfachste Weg, eine projektive Bildtransformation durchzuführen, besteht darin, den Wert jedes Pixels des endgültigen Bildes anhand des Werts zu bewerten, der durch Invertieren seiner Mitte in die Ebene des Originalbilds (unter Berücksichtigung der ausgewählten Interpolationsmethode) erhalten wird. Wir nennen diesen Ansatz Pixel für Pixel Diskretisierung . In Bereichen, in denen das Bild komprimiert ist, kann dies jedoch zu signifikanten Artefakten führen, die durch das Problem der Überlappung von Spektren bei einer unzureichenden Abtastfrequenz verursacht werden.Wir werden die Komprimierungsartefakte an der Stichprobe des russischen Passes und seines individuellen Feldes - Geburtsort (Stadt Archangelsk)) deutlich demonstrieren, die mithilfe einer pixelweisen Stichprobe oder des FAST-Algorithmus komprimiert wurde, den wir unten betrachten werden.Es ist zu sehen, dass der Text im linken Bild nicht mehr lesbar ist. Das ist richtig, denn wir nehmen nur einen Punkt aus einer ganzen Region des Quellbildes!Da wir nicht in der Lage waren, ein Pixel zu schätzen, warum nicht mehr Abtastwerte pro Pixel auswählen und die erhaltenen Werte mitteln? Dieser Ansatz wird als Supersampling bezeichnet . Es erhöht wirklich die Qualität, aber gleichzeitig nimmt die Rechenkomplexität proportional zur Anzahl der Abtastungen pro Pixel zu.Ende des letzten Jahrhunderts wurden rechnerisch effizientere Methoden erfunden, als die Computergrafik das Problem des Renderns von Texturen auf flachen Objekten löste. Eine dieser Methoden ist die Konvertierung mit mip-mapStruktur. Mip-Map ist eine Pyramide von Bildern, die aus dem Originalbild selbst sowie den um 2, 4, 8 usw. reduzierten Kopien besteht. Für jedes Pixel bewerten wir den Grad der Komprimierungscharakteristik und wählen entsprechend diesem Grad den gewünschten Pegel aus der Pyramide als Quellbild aus. Es gibt verschiedene Möglichkeiten, die entsprechende Ebene der Mip-Map zu bewerten (siehe Details [2]). Hier verwenden wir die Methode, die auf der Schätzung partieller Ableitungen in Bezug auf die bekannte projektive Transformationsmatrix basiert. Um jedoch Artefakte in Bereichen des endgültigen Bildes zu vermeiden, in denen eine Ebene der Mip-Map-Struktur zu einer anderen geht, wird normalerweise eine lineare Interpolation zwischen zwei benachbarten Ebenen der Pyramide verwendet (dies erhöht den Rechenaufwand nicht wesentlich, da die Koordinaten der Punkte auf benachbarten Ebenen eindeutig verbunden sind).Die Mip-Map berücksichtigt jedoch nicht die Tatsache, dass die Bildkomprimierung anisotrop sein kann (entlang einer bestimmten Richtung verlängert). Dieses Problem kann teilweise durch Rip-Map gelöst werden . Eine Struktur, in der Bilder komprimiert werden mal horizontal und mal vertikal. In diesem Fall wird nach dem Bestimmen der horizontalen und vertikalen Komprimierungskoeffizienten an einem bestimmten Punkt im endgültigen Bild eine Interpolation zwischen den Ergebnissen von 4 durchgeführt, die auf die gewünschte Anzahl von Kopien des Originalbilds komprimiert wurden. Diese Methode ist jedoch nicht ideal, da sie nicht berücksichtigt, dass sich die Richtung der Anisotropie von den Richtungen parallel zu den Grenzen des Originalbilds unterscheidet.Zum Teil kann dieses Problem durch den FAST- Algorithmus (Footprint Area Sampled Texturing) gelöst werden [3]. Es kombiniert die Ideen von Mip-Map und Supersampling. Wir schätzen den Kompressionsgrad basierend auf der Achse der geringsten Anisotropie und wählen die Anzahl der Proben proportional zum Verhältnis der Längen der kleinsten zur größten Achse.Bevor wir diese Ansätze im Hinblick auf die Komplexität der Berechnungen vergleichen, machen wir uns den Vorbehalt, dass es rational ist, die folgende Änderung vorzunehmen, um die Berechnung der inversen projektiven Transformation zu beschleunigen:Wo , Ist die Matrix der inversen projektiven Transformation. Als und Funktionen eines Arguments können wir sie für eine Zeit vorberechnen, die proportional zur linearen Größe des Bildes ist. Berechnen Sie dann die Koordinaten des inversen Bildes eines Punktes des endgültigen BildesEs sind nur 1 Division und 2 Multiplikationen erforderlich. Ein ähnlicher Trick kann mit partiellen Ableitungen durchgeführt werden, mit denen der Pegel in der Mip-Map- oder Rip-Map-Struktur bestimmt wird.Jetzt sind wir bereit, die Ergebnisse hinsichtlich der Komplexität der Berechnungen zu vergleichen.Und visuell vergleichen (Pixel-für-Pixel-Abtastung von links nach rechts, 49 Abtastungen Super-Abtastung, Mip-Map, Rip-Map, FAST).
Experiment
Vergleichen wir nun unsere Ergebnisse experimentell. Wir erstellen einen projektiven Transformationsalgorithmus, der jeweils 5 Interpolationsmethoden und 5 Diskretisierungsmethoden kombiniert (insgesamt 25 Optionen). Nehmen Sie 20 Bilder von Dokumenten auf, die auf 512 x 512 Pixel zugeschnitten sind, generieren Sie 10 Sätze mit 3 projektiven Transformationsmatrizen, sodass jeder Satz im Allgemeinen der identischen Transformation entspricht, und vergleichen Sie das PSNR zwischen dem Originalbild und dem konvertierten. Denken Sie daran, dass PSNR istwo Dies ist das Maximum im Originalbild. a - die Standardabweichung des Finales vom Original. Je mehr PSNR desto besser. Wir werden auch die Betriebszeit der projektiven Konvertierung auf ODROID-XU4 mit einem ARM Cortex-A15-Prozessor (2000 MHz und 2 GB RAM) messen.Monströse Tabelle mit den Ergebnissen:Welche Schlussfolgerungen können gezogen werden?
- Die Verwendung der Interpolation durch das nächste Pixel oder Pixel für Pixelabtastung führt zu einer schlechten Qualität (dies war selbst anhand der obigen Beispiele offensichtlich).
- 36 — .
- b- , , .
- Rip-map FAST , 9 ( , ?).
- mip-map b- PSNR , .
Wenn Sie eine gute Qualität mit nicht zu niedriger Geschwindigkeit wünschen, sollten Sie eine bilineare Interpolation in Kombination mit einer Diskretisierung mit Mip-Map oder FAST in Betracht ziehen. Wenn jedoch mit Sicherheit bekannt ist, dass die projektive Verzerrung sehr schwach ist, können Sie zur Erhöhung der Geschwindigkeit eine pixelweise Diskretisierung in Kombination mit einer bilinearen Interpolation oder sogar einer Interpolation um das nächste Pixel verwenden. Und wenn Sie eine hohe Qualität und eine nicht sehr begrenzte Laufzeit benötigen, können Sie eine bikubische oder adaptive Interpolation in Kombination mit einem moderaten Supersampling verwenden (z. B. auch adaptiv, abhängig vom lokalen Komprimierungsverhältnis).PS Die Veröffentlichung wurde auf der Grundlage des Berichts erstellt: A. Trusov und E. Limonova, „Die Analyse projektiver Transformationsalgorithmen zur Bilderkennung auf Mobilgeräten“, ICMV 2019, Hrsg. 11433, Wolfgang Osten, Dmitry Nikolaev, Jianhong Zhou, Hrsg., SPIE , Jan. 2020, vol. 11433, ISSN 0277-786X, ISBN 978-15-10636-43-9, vol. 11433, 11433 0Y, pp. 1-8, 2020, DOI: 10.1117 / 12.2559732.Liste der verwendeten Quellen- G. Wolberg, Digital image warping, vol. 10662, IEEE computer society press Los Alamitos, CA (1990).
- J. P. Ewins, M. D. Waller, M. White, and P. F. Lister, “Mip-map level selection for texture mapping,” IEEE Transactions on Visualization and Computer Graphics4(4), 317–329 (1998).
- B. Chen, F. Dachille, and A. E. Kaufman, “Footprint area sampled texturing,” IEEE Transactions on Visualizationand Computer Graphics10(2), 230–240 (2004).