Es kommt vor, dass Systeme fehlerhaft sind, langsamer werden, ausfallen. Je größer das System ist, desto schwieriger ist es, die Ursache zu finden. Um herauszufinden, warum etwas nicht wie erwartet funktioniert, um zukünftige Probleme zu beheben oder zu verhindern, müssen Sie nach innen schauen. Dazu müssen Systeme die Eigenschaft der Beobachtbarkeit besitzen , die durch Instrumentierung im weiteren Sinne des Wortes erreicht wird.Bei HighLoad ++ überprüfte Peter Zaitsev (Percona) die verfügbare Infrastruktur für die Ablaufverfolgung unter Linux und sprach über bpfTrace, das (wie der Name schon sagt) viele Vorteile bietet. Wir haben eine Textversion des Berichts erstellt, damit Sie die Details bequem überprüfen können und zusätzliche Materialien immer zur Hand sind.Die Instrumentierung kann in zwei große Blöcke unterteilt werden:- Statisch , wenn die Sammlung von Informationen in Code eingebunden ist: Aufzeichnen von Protokollen, Zählern, Zeit usw.
- Dynamisch , wenn der Code nicht selbst instrumentiert ist, es aber bei Bedarf möglich ist.
Eine weitere Klassifizierungsoption basiert auf dem Ansatz zur Datenerfassung:- Ablaufverfolgung - Ereignisse werden generiert, wenn ein bestimmter Code funktioniert hat.
- Abtastung - Der Status des Systems wird beispielsweise 100 Mal pro Sekunde überprüft und bestimmt, was darin geschieht.
Statische Instrumente existieren seit vielen Jahren und sind in fast allem enthalten. Unter Linux verwenden es viele Standardtools wie Vmstat oder Top. Sie lesen Daten aus procfs, wobei grob gesagt verschiedene Timer und Zähler aus dem Kernel-Code geschrieben werden.Sie können jedoch nicht zu viele dieser Zähler einfügen und nicht alles auf der Welt damit abdecken. Daher kann eine dynamische Instrumentierung hilfreich sein, mit der Sie genau das sehen können, was Sie benötigen. Wenn beispielsweise Probleme mit dem TCP / IP-Stack auftreten, können Sie sehr tief gehen und bestimmte Details anweisen.
Dtrace
DTrace ist eines der ersten bekannten dynamischen Tracing-Frameworks, die von Sun Microsystems erstellt wurden. Es wurde bereits 2001 hergestellt und 2005 erstmals in Solaris 10 veröffentlicht. Der Ansatz erwies sich als sehr beliebt und ging später in viele andere Distributionen über.Interessanterweise können Sie mit DTrace sowohl den Kernel- als auch den Benutzerbereich instrumentieren. Sie können jedem Funktionsaufruf Traces hinzufügen und Programme speziell anweisen: Führen Sie spezielle DTrace-Tracepoints ein, die für Benutzer verständlicher sein können als die Funktionsnamen.Dies war besonders wichtig für Solaris, da es sich nicht um ein offenes Betriebssystem handelt. Es war nicht möglich, nur in den Code zu schauen und zu verstehen, dass Tracepoint auf eine solche Funktion gesetzt werden muss, wie dies jetzt in der neuen Open-Source-Linux-Software möglich ist.Eine der einzigartigen Funktionen von DTrace ist, dass die Ablaufverfolgung zwar nicht aktiviert ist, aber nichts kostet . Es funktioniert so, dass es einfach einige CPU-Anweisungen durch einen DTrace-Aufruf ersetzt, der diese Anweisungen bei der Rückkehr ausführt.In DTrace wird die Instrumentierung in einer speziellen D-Sprache geschrieben, ähnlich wie C und Awk.Später erschien DTrace fast überall außer unter Linux: unter MacOS im Jahr 2007, unter FreeBSD im Jahr 2008 und unter NetBSD im Jahr 2010. Oracle im Jahr 2011 enthielt DTrace in Oracle Unbreakable Linux. Aber nur wenige Leute verwenden Oracle Linux, und DTrace hat das Haupt-Linux nie betreten.Interessanterweise hat Oracle DTrace 2017 schließlich unter GPLv2 lizenziert, was es im Prinzip ermöglichte, es ohne Lizenzierungsschwierigkeiten in Mainline-Linux aufzunehmen, aber es war bereits zu spät. Zu dieser Zeit hatte Linux eine gute BPF, die hauptsächlich zur Standardisierung verwendet wurde.DTrace wird sogar in Windows enthalten sein, jetzt ist es in einigen Testversionen verfügbar.Linux-Tracing
Was ist in Linux anstelle von DTrace? Tatsächlich gibt es unter Linux viele Dinge in der besten (oder schlechtesten) Manifestation des Open-Source-Geistes. In dieser Zeit haben sich eine Reihe verschiedener Tracing-Frameworks angesammelt. Finden Sie daher heraus, was nicht so einfach ist.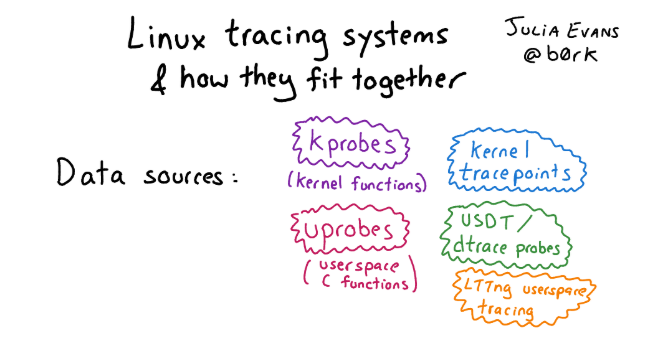 Wenn Sie sich mit dieser Vielfalt vertraut machen möchten und sich für Geschichte interessieren, lesen Sie den Artikel mit Bildern und einer detaillierten Beschreibung der Ansätze zur Ablaufverfolgung unter Linux.Wenn wir über die Infrastruktur für die Ablaufverfolgung unter Linux im Allgemeinen sprechen, gibt es drei Ebenen:
Wenn Sie sich mit dieser Vielfalt vertraut machen möchten und sich für Geschichte interessieren, lesen Sie den Artikel mit Bildern und einer detaillierten Beschreibung der Ansätze zur Ablaufverfolgung unter Linux.Wenn wir über die Infrastruktur für die Ablaufverfolgung unter Linux im Allgemeinen sprechen, gibt es drei Ebenen:- Schnittstelle für die Kernel-Instrumentierung: Kprobe, Uprobe, Dtrace-Sonde usw.
- «», . , probe, , user space . : , user space, Kernel Module, - , eBPF.
- -, , : Perf, SystemTap, SysDig, BCC .. bpfTtrace , , .
eBPF — Linux
Mit all diesen Frameworks ist eBPF in den letzten Jahren zum Standard unter Linux geworden. Dies ist ein fortschrittlicheres, hochflexibles und effektives Werkzeug, das fast alles ermöglicht.Was ist eBPF und woher kommt es? Tatsächlich ist eBPF ein erweiterter Berkeley-Paketfilter, und BPF wurde 1992 als virtuelle Maschine für eine effiziente Paketfilterung durch eine Firewall entwickelt. Anfangs hatte er keinen Bezug zu Überwachung, Beobachtbarkeit oder Rückverfolgung.In moderneren Versionen wurde eBPF als gemeinsamer Rahmen für die Behandlung von Ereignissen erweitert (daher das Wort erweitert) . Aktuelle Versionen sind für mehr Effizienz in den JIT-Compiler integriert.Unterschiede von eBPF zu klassischem BPF:- Register hinzugefügt;
- ein Stapel ist erschienen;
- Es gibt zusätzliche Datenstrukturen (Karten).
 Jetzt vergessen die Leute meistens, dass es einen alten BPF gab, und eBPF wird einfach BPF genannt. In den meisten modernen Ausdrücken sind eBPF und BPF ein und dasselbe. Daher heißt das Tool bpfTrace, nicht eBpfTrace.eBPF ist seit 2014 in Mainline-Linux enthalten und wird schrittweise in vielen Linux-Tools enthalten, darunter Perf, SystemTap und SysDig. Es gibt eine Standardisierung.Interessanterweise ist die Entwicklung noch im Gange. Moderne Kernel unterstützen eBPF immer besser.
Jetzt vergessen die Leute meistens, dass es einen alten BPF gab, und eBPF wird einfach BPF genannt. In den meisten modernen Ausdrücken sind eBPF und BPF ein und dasselbe. Daher heißt das Tool bpfTrace, nicht eBpfTrace.eBPF ist seit 2014 in Mainline-Linux enthalten und wird schrittweise in vielen Linux-Tools enthalten, darunter Perf, SystemTap und SysDig. Es gibt eine Standardisierung.Interessanterweise ist die Entwicklung noch im Gange. Moderne Kernel unterstützen eBPF immer besser.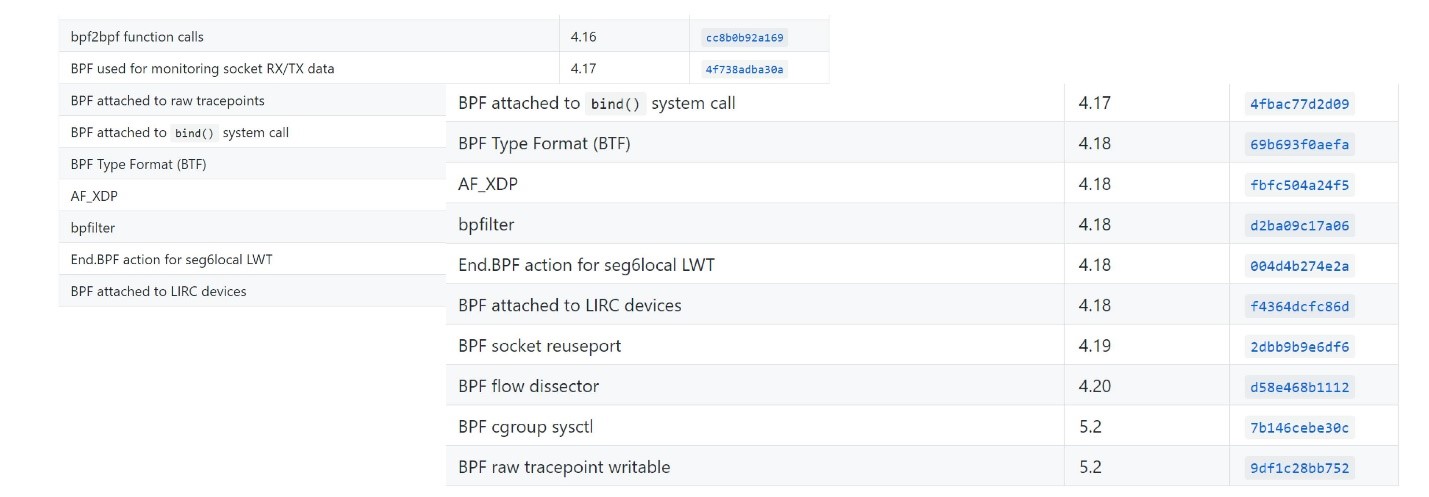 Hier können Sie sehen, welche modernen Kernel-Versionen erschienen sind .
Hier können Sie sehen, welche modernen Kernel-Versionen erschienen sind .EBPF-Programme
Was ist eBPF und warum ist es interessant?eBPF ist ein Programm in seinem speziellen Bytecode , das direkt im Kernel enthalten ist und die Verarbeitung von Trace-Ereignissen durchführt. Darüber hinaus ermöglicht die Tatsache, dass es in einem speziellen Bytecode erstellt wurde, dem Kernel, eine bestimmte Überprüfung durchzuführen, ob der Code ziemlich sicher ist. Stellen Sie beispielsweise sicher, dass keine Schleifen verwendet werden, da die Schleife im kritischen Abschnitt des Kernels das gesamte System hängen kann.Dies erlaubt jedoch keine vollständige Sicherheit. Wenn Sie beispielsweise ein sehr komplexes eBPF-Programm schreiben und es in ein Ereignis im Kernel einfügen, das 10 Millionen Mal pro Sekunde auftritt, kann sich alles sehr verlangsamen. Gleichzeitig ist eBPF viel sicherer als der alte Ansatz, als nur einige Kernel-Module über insmod eingefügt wurden und alles in diesen Modulen enthalten sein könnte. Wenn jemand einen Fehler gemacht hat oder einfach wegen einer binären Inkompatibilität, könnte der gesamte Kern fallen.Der eBPF-Code kann von LLVM Clang kompiliert werden, dh im Großen und Ganzen wird eine Teilmenge von C zum Erstellen von eBPF-Programmen verwendet, was natürlich ziemlich kompliziert ist. Und es ist wichtig, dass die Kompilierung vom Kernel abhängt: Header werden verwendet, um zu verstehen, welche Strukturen verwendet werden und wofür sie verwendet werden usw. Dies ist nicht sehr praktisch in dem Sinne, dass entweder einige Module, die sich auf einen bestimmten Kern beziehen, immer geliefert werden oder neu kompiliert werden müssen.Das Diagramm zeigt, wie eBPF funktioniert. http://www.brendangregg.com/ebpf.htmlDer Benutzer erstellt ein eBPF-Programm. Außerdem überprüft und lädt der Kernel ihn. Danach kann eBPF eine Verbindung zu verschiedenen Tools für Traces herstellen, Informationen verarbeiten und in Karten speichern (Datenstruktur für die temporäre Speicherung). Dann kann das Anwenderprogramm Statistiken lesen, Perf-Ereignisse empfangen usw.Es zeigt, welche eBPF-Funktionen in welchen Versionen von Linux-Kerneln enthalten sind.
http://www.brendangregg.com/ebpf.htmlDer Benutzer erstellt ein eBPF-Programm. Außerdem überprüft und lädt der Kernel ihn. Danach kann eBPF eine Verbindung zu verschiedenen Tools für Traces herstellen, Informationen verarbeiten und in Karten speichern (Datenstruktur für die temporäre Speicherung). Dann kann das Anwenderprogramm Statistiken lesen, Perf-Ereignisse empfangen usw.Es zeigt, welche eBPF-Funktionen in welchen Versionen von Linux-Kerneln enthalten sind.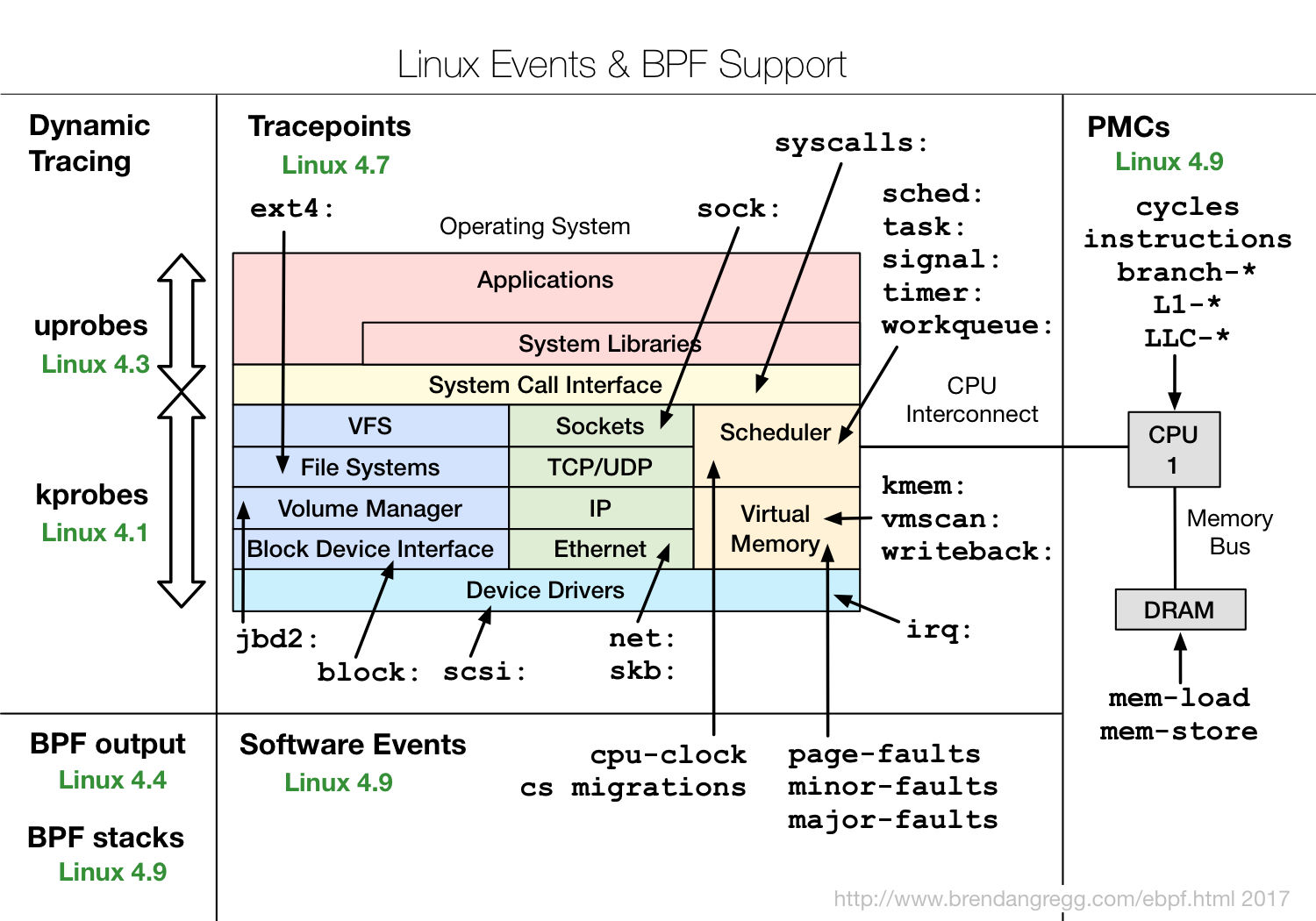 Es ist ersichtlich, dass fast alle Subsysteme des Linux-Kernels abgedeckt sind, und es gibt eine gute Integration mit Hardwaredaten, eBPF hat Zugriff auf alle Arten von Cache-Miss- oder Branch-Miss-Vorhersagen usw.Wenn Sie an eBPF interessiert sind, schauen Sie sich das IO Visor- Projekt anenthält es die meisten Werkzeuge. Die Firma IO Visor ist an ihrer Entwicklung beteiligt. Sie wird über die neuesten Versionen und eine sehr gute Dokumentation verfügen. Immer mehr eBPF-Tools werden auf Linux-Distributionen angezeigt. Ich würde daher empfehlen, immer die neuesten verfügbaren Versionen zu verwenden.
Es ist ersichtlich, dass fast alle Subsysteme des Linux-Kernels abgedeckt sind, und es gibt eine gute Integration mit Hardwaredaten, eBPF hat Zugriff auf alle Arten von Cache-Miss- oder Branch-Miss-Vorhersagen usw.Wenn Sie an eBPF interessiert sind, schauen Sie sich das IO Visor- Projekt anenthält es die meisten Werkzeuge. Die Firma IO Visor ist an ihrer Entwicklung beteiligt. Sie wird über die neuesten Versionen und eine sehr gute Dokumentation verfügen. Immer mehr eBPF-Tools werden auf Linux-Distributionen angezeigt. Ich würde daher empfehlen, immer die neuesten verfügbaren Versionen zu verwenden.EBPF-Leistung
In Bezug auf die Leistung ist eBPF sehr effektiv. Um zu verstehen, wie viel und ob Overhead vorhanden ist, können Sie eine Sonde hinzufügen, die mehrmals pro Sekunde zuckt, und überprüfen, wie lange die Ausführung dauert.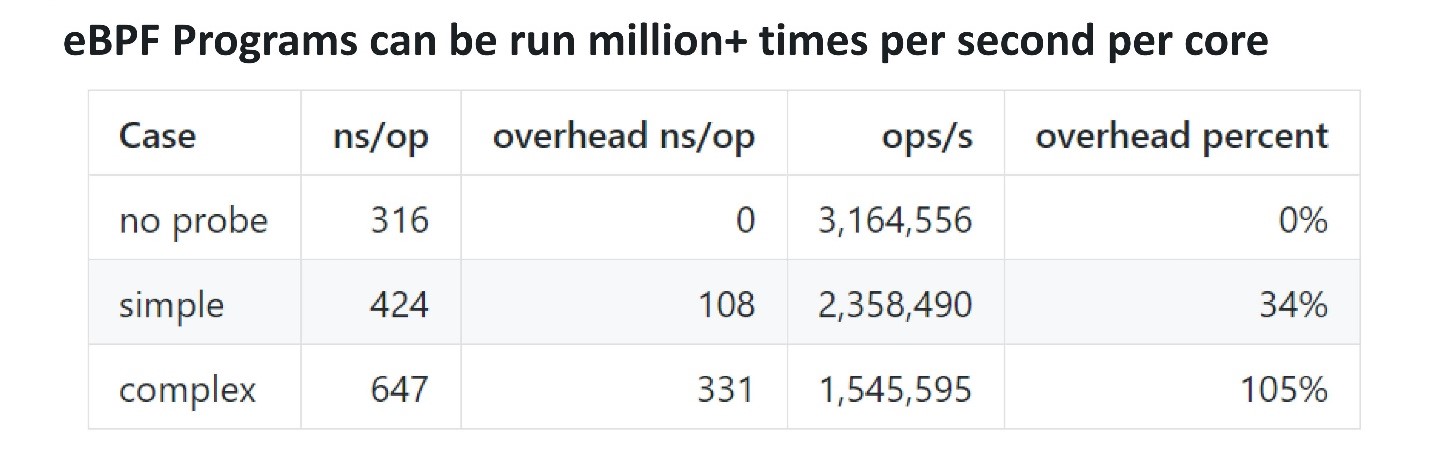 Die Jungs von Cloudflare haben einen Benchmark gemacht . Eine einfache eBPF-Sonde benötigte ungefähr 100 ns, während eine komplexere 300 ns benötigte. Dies bedeutet, dass sogar eine komplexe Sonde etwa 3 Millionen Mal pro Sekunde auf einem einzelnen Kern aufgerufen werden kann. Wenn die Sonde auf einem Mehrkernprozessor 100.000 oder eine Million Mal pro Sekunde ruckelt, wirkt sich dies nicht zu stark auf die Leistung aus.
Die Jungs von Cloudflare haben einen Benchmark gemacht . Eine einfache eBPF-Sonde benötigte ungefähr 100 ns, während eine komplexere 300 ns benötigte. Dies bedeutet, dass sogar eine komplexe Sonde etwa 3 Millionen Mal pro Sekunde auf einem einzelnen Kern aufgerufen werden kann. Wenn die Sonde auf einem Mehrkernprozessor 100.000 oder eine Million Mal pro Sekunde ruckelt, wirkt sich dies nicht zu stark auf die Leistung aus.Frontend für eBPF
Wenn Sie sich für eBPF und das Thema Beobachtbarkeit im Allgemeinen interessieren, haben Sie wahrscheinlich von Brendan Gregg gehört. Er schreibt und spricht viel darüber und hat ein so schönes Bild gemacht, das Werkzeuge für eBPF zeigt. Hier können Sie sehen, dass Sie beispielsweise Raw BPF verwenden können - schreiben Sie einfach Bytecode - dies bietet eine vollständige Palette von Funktionen, aber es wird sehr schwierig sein, damit zu arbeiten. Bei Raw BPF geht es darum, wie eine Webanwendung in Assembler geschrieben wird - im Prinzip ist dies möglich, ohne dass dies erforderlich ist.Interessanterweise können Sie mit bpfTrace einerseits fast alles von BCC und rohem BPF erhalten, aber es ist viel einfacher zu verwenden.Meiner Meinung nach sind zwei Tools am nützlichsten:
Hier können Sie sehen, dass Sie beispielsweise Raw BPF verwenden können - schreiben Sie einfach Bytecode - dies bietet eine vollständige Palette von Funktionen, aber es wird sehr schwierig sein, damit zu arbeiten. Bei Raw BPF geht es darum, wie eine Webanwendung in Assembler geschrieben wird - im Prinzip ist dies möglich, ohne dass dies erforderlich ist.Interessanterweise können Sie mit bpfTrace einerseits fast alles von BCC und rohem BPF erhalten, aber es ist viel einfacher zu verwenden.Meiner Meinung nach sind zwei Tools am nützlichsten:- BCC. Trotz der Tatsache, dass BCC nach Greggs Schema komplex ist, enthält es viele vorgefertigte Funktionen , die einfach über die Befehlszeile gestartet werden können.
- BpfTrace . Sie können einfach Ihr eigenes Toolkit schreiben oder vorgefertigte Lösungen verwenden.
Sie können sich vorstellen, wie viel einfacher es ist, auf bpfTrace zu schreiben, wenn Sie sich den Code desselben Tools in zwei Versionen ansehen.
DTrace vs bpfTrace
Im Allgemeinen werden DTrace und bpfTrace für dasselbe verwendet. http://www.brendangregg.com/blog/2018-10-08/dtrace-for-linux-2018.htmlDer Unterschied besteht darin, dass es im BPF-Ökosystem auch ein BCC gibt, das für komplexe Tools verwendet werden kann. In DTrace gibt es kein BCC-Äquivalent. Verwenden Sie daher für die Erstellung komplexer Toolkits normalerweise das Shell + DTrace-Bundle.Beim Erstellen von bpfTrace gab es keine Aufgabe, DTrace vollständig zu emulieren. Das heißt, Sie können ein DTrace-Skript nicht auf bpfTrace ausführen. Dies macht jedoch wenig Sinn, da die Logik in den Tools der unteren Ebene recht einfach ist. In der Regel ist es wichtiger zu verstehen, zu welchen Tracepoints Sie eine Verbindung herstellen müssen, und die Namen der Systemaufrufe und deren direkte Ausführung auf niedriger Ebene unterscheiden sich in Linux, Solaris und FreeBSD. Hier entsteht der Unterschied.In diesem Fall wird bpfTrace 15 Jahre nach DTrace erstellt. Es hat einige zusätzliche Funktionen, die DTrace nicht hat. Zum Beispiel kann er Stapelspuren erstellen.Aber natürlich wird viel von DTrace geerbt. Beispielsweise sind Funktionsnamen und Syntax ähnlich , wenn auch nicht vollständig gleichwertig.Die Skripte DTrace und bpfTrace haben eine enge Codegröße und eine ähnliche Komplexität und Sprachfähigkeit.
http://www.brendangregg.com/blog/2018-10-08/dtrace-for-linux-2018.htmlDer Unterschied besteht darin, dass es im BPF-Ökosystem auch ein BCC gibt, das für komplexe Tools verwendet werden kann. In DTrace gibt es kein BCC-Äquivalent. Verwenden Sie daher für die Erstellung komplexer Toolkits normalerweise das Shell + DTrace-Bundle.Beim Erstellen von bpfTrace gab es keine Aufgabe, DTrace vollständig zu emulieren. Das heißt, Sie können ein DTrace-Skript nicht auf bpfTrace ausführen. Dies macht jedoch wenig Sinn, da die Logik in den Tools der unteren Ebene recht einfach ist. In der Regel ist es wichtiger zu verstehen, zu welchen Tracepoints Sie eine Verbindung herstellen müssen, und die Namen der Systemaufrufe und deren direkte Ausführung auf niedriger Ebene unterscheiden sich in Linux, Solaris und FreeBSD. Hier entsteht der Unterschied.In diesem Fall wird bpfTrace 15 Jahre nach DTrace erstellt. Es hat einige zusätzliche Funktionen, die DTrace nicht hat. Zum Beispiel kann er Stapelspuren erstellen.Aber natürlich wird viel von DTrace geerbt. Beispielsweise sind Funktionsnamen und Syntax ähnlich , wenn auch nicht vollständig gleichwertig.Die Skripte DTrace und bpfTrace haben eine enge Codegröße und eine ähnliche Komplexität und Sprachfähigkeit.
bpfTrace
Lassen Sie uns genauer sehen, was in bpfTrace enthalten ist, wie es verwendet werden kann und was dafür benötigt wird.Linux-Anforderungen für die Verwendung von bpfTrace: Um alle Funktionen nutzen zu können, benötigen Sie eine Version von mindestens 4.9. Mit BpfTrace können Sie viele verschiedene Sonden erstellen, beginnend mit uprobe zum Instrumentieren eines Funktionsaufrufs in einer Benutzeranwendung, Kernel-Sonden usw.
Um alle Funktionen nutzen zu können, benötigen Sie eine Version von mindestens 4.9. Mit BpfTrace können Sie viele verschiedene Sonden erstellen, beginnend mit uprobe zum Instrumentieren eines Funktionsaufrufs in einer Benutzeranwendung, Kernel-Sonden usw. Interessanterweise gibt es ein Uretprobe-Äquivalent für eine benutzerdefinierte Uprobe-Funktion. Für den Kernel ist das gleiche kprobe und kretprobe. Dies bedeutet, dass Sie im Tracing-Framework tatsächlich Ereignisse generieren können, wenn die Funktion aufgerufen wird und wenn diese Funktion abgeschlossen ist - dies wird häufig für das Timing verwendet. Oder Sie können die von der Funktion zurückgegebenen Werte analysieren und nach den Parametern gruppieren, mit denen die Funktion aufgerufen wurde. Wenn Sie einen Funktionsaufruf abfangen und von ihm zurückkehren, können Sie viele coole Dinge tun.In bpfTrace funktioniert das folgendermaßen: Wir schreiben ein bpf-Programm, das analysiert, in C konvertiert und dann über Clang verarbeitet wird. Dabei wird bpf-Bytecode generiert, wonach das Programm geladen wird.
Interessanterweise gibt es ein Uretprobe-Äquivalent für eine benutzerdefinierte Uprobe-Funktion. Für den Kernel ist das gleiche kprobe und kretprobe. Dies bedeutet, dass Sie im Tracing-Framework tatsächlich Ereignisse generieren können, wenn die Funktion aufgerufen wird und wenn diese Funktion abgeschlossen ist - dies wird häufig für das Timing verwendet. Oder Sie können die von der Funktion zurückgegebenen Werte analysieren und nach den Parametern gruppieren, mit denen die Funktion aufgerufen wurde. Wenn Sie einen Funktionsaufruf abfangen und von ihm zurückkehren, können Sie viele coole Dinge tun.In bpfTrace funktioniert das folgendermaßen: Wir schreiben ein bpf-Programm, das analysiert, in C konvertiert und dann über Clang verarbeitet wird. Dabei wird bpf-Bytecode generiert, wonach das Programm geladen wird. Der Prozess ist ziemlich schwierig, daher gibt es Einschränkungen. Auf leistungsstarken Servern funktioniert bpfTrace gut. Es ist jedoch keine gute Idee, Clang auf ein kleines eingebettetes Gerät zu ziehen, um herauszufinden, was los ist. Ply ist dafür geeignet . Es verfügt natürlich nicht über alle Funktionen von bpfTrace, generiert jedoch direkt Bytecode.
Der Prozess ist ziemlich schwierig, daher gibt es Einschränkungen. Auf leistungsstarken Servern funktioniert bpfTrace gut. Es ist jedoch keine gute Idee, Clang auf ein kleines eingebettetes Gerät zu ziehen, um herauszufinden, was los ist. Ply ist dafür geeignet . Es verfügt natürlich nicht über alle Funktionen von bpfTrace, generiert jedoch direkt Bytecode.Linux-Unterstützung
Eine stabile Version von bpfTrace wurde vor etwa einem Jahr veröffentlicht, sodass sie auf älteren Linux-Distributionen nicht verfügbar ist. Nehmen Sie am besten Pakete oder kompilieren Sie die neueste Version, die IO Visor verteilt.Interessanterweise verfügt das neueste Ubuntu LTS 18.04 nicht über bpfTrace, kann jedoch mit dem Snap-Paket geliefert werden. Dies ist einerseits praktisch, andererseits funktionieren aufgrund der Art und Weise, wie Snap-Pakete erstellt und isoliert werden, nicht alle Funktionen. Bei der Kernel-Ablaufverfolgung funktioniert ein Paket mit Snap gut, bei der Benutzer-Ablaufverfolgung funktioniert es möglicherweise nicht richtig.
Beispiel für die Prozessverfolgung
Betrachten Sie das einfachste Beispiel, mit dem Sie Statistiken zu E / A-Anforderungen abrufen können:bpftrace -e 'kprobe:vfs_read { @start[tid] = nsecs; }
kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); }'
Hier verbinden wir uns mit der Funktion vfs_read, sowohl kretprobe als auch kprobe. Ferner verfolgen wir für jede Thread-ID (tid), dh für jede Anforderung, den Beginn und das Ende ihrer Ausführung. Daten können nicht nur nach der Gesamtheit des gesamten Systems gruppiert werden, sondern auch nach verschiedenen Prozessen. Unten finden Sie die E / A-Ausgabe für MySQL. Die klassische bimodale E / A-Verteilung ist sichtbar. Eine große Anzahl schneller Anforderungen sind Daten, die aus dem Cache gelesen werden. Der zweite Peak ist das Lesen von Daten von der Festplatte, wo die Latenz viel höher ist.Sie können dies als Skript speichern (die bt-Erweiterung wird normalerweise verwendet), Kommentare schreiben, formatieren und einfach weiter verwenden
Die klassische bimodale E / A-Verteilung ist sichtbar. Eine große Anzahl schneller Anforderungen sind Daten, die aus dem Cache gelesen werden. Der zweite Peak ist das Lesen von Daten von der Festplatte, wo die Latenz viel höher ist.Sie können dies als Skript speichern (die bt-Erweiterung wird normalerweise verwendet), Kommentare schreiben, formatieren und einfach weiter verwenden #bpftrace read.bt.// read.bt file
tracepoint:syscalls:sys_enter_read
{
@start[tid] = nsecs;
}
tracepoint:syscalls:sys_exit_read / @start[tid]/
{
@times = hist(nsecs - @start[tid]);
delete(@start[tid]);
}
Das allgemeine Konzept der Sprache ist recht einfach.- Syntax: Wählen Sie die zu verbindende Sonde aus
probe[,probe,...] /filter/ { action }. - Filter: Geben Sie einen Filter an, z. B. nur Daten zu einem bestimmten Prozess einer bestimmten Pid.
- Aktion: Ein Miniprogramm, das direkt in ein bpf-Programm konvertiert und beim Aufruf von bpfTrace ausgeführt wird.
Weitere Details finden Sie hier .Bpftrace-Werkzeuge
BpfTrace hat auch eine Toolbox. Viele ziemlich einfache Tools für BCC sind jetzt auf bpfTrace implementiert. Die Sammlung ist noch klein, aber es gibt etwas, das nicht im BCC enthalten ist. Mit Killsnoop können Sie beispielsweise die durch kill () verursachten Signale verfolgen.Wenn Sie sich den bpf-Code ansehen möchten, können Sie in bpfTrace
Die Sammlung ist noch klein, aber es gibt etwas, das nicht im BCC enthalten ist. Mit Killsnoop können Sie beispielsweise die durch kill () verursachten Signale verfolgen.Wenn Sie sich den bpf-Code ansehen möchten, können Sie in bpfTrace -vden generierten Bytecode durchschauen . Dies ist nützlich, wenn Sie eine schwere Sonde verstehen möchten oder nicht. Wenn Sie sich den Code angesehen und nur seine Größe geschätzt haben (eine oder zwei Seiten), können Sie verstehen, wie kompliziert er ist.
Beispiel für eine MySQL-Ablaufverfolgung
Lassen Sie mich Ihnen ein Beispiel für MySQL zeigen, wie es funktioniert. MySQL hat eine Funktion, dispatch_commandin der alle MySQL-Abfrageausführungen stattfinden.bpftrace -e 'uprobe:/usr/sbin/mysqld:dispatch_command { printf("%s\n", str(arg2)); }'
failed to stat uprobe target file /usr/sbin/mysqld: No such file or directory
Ich wollte nur eine Garderobe anschließen, um den Text von Abfragen zu drucken, die zu MySQL kommen - eine primitive Aufgabe. Habe ein Problem - sagt, dass es keine solche Datei gibt. Wie nicht, wenn es hier ist:root@mysql1:/# ls -la /usr/sbin/mysqld
-rwxr-xr-x 1 root root 60718384 Oct 25 09:19 /usr/sbin/mysqld
Dies sind nur Überraschungen mit Schnappschuss. Wenn dies über Snap festgelegt wird, können Probleme auf Anwendungsebene auftreten.Dann habe ich über die apt-Version, ein neueres Ubuntu, wieder gestartet:root@mysql1:~# bpftrace -e 'uprobe:/usr/sbin/mysqld:dispatch_command { printf("%s\n", str(arg2)); }'
Attaching 1 probe...
Could not resolve symbol: /usr/sbin/mysqld:dispatch_command
"Es gibt kein solches Symbol" - wie nicht ?! Ich schaue durch, nmob es ein solches Symbol gibt oder nicht:root@mysql1:~# nm -D /usr/sbin/mysqld | grep dispatch_command
00000000005af770 T
_Z16dispatch_command19enum_server_commandP3THDPcjbb
root@localhost:~# bpftrace -e 'uprobe:/usr/sbin/mysqld:_Z16dispatch_command19enum_server_commandP3THDPcjbb { printf("%s\n", str(arg2)); }'
Attaching 1 probe...
select @@version_comment limit 1
select 1
Es gibt ein solches Symbol, aber da MySQL aus C ++ kompiliert wird, wird dort Mangeln verwendet. In der Tat ist der aktuelle Name der Funktion, die in diesem Befehl verwendet wird, der folgende : _Z16dispatch_command19enum_server_commandP3THDPcjbb. Wenn Sie es in einer Funktion verwenden, können Sie eine Verbindung herstellen und das Ergebnis abrufen. Im Perf-Ökosystem machen viele Tools das Entwirren automatisch und bpfTrace ist noch nicht in der Lage.Achten Sie auch auf die Flagge -Dfür nm. Dies ist wichtig, da MySQL und jetzt viele andere Pakete keine dynamischen Symbole (Debug-Symbole) enthalten - sie sind in anderen Paketen enthalten. Wenn Sie diese Zeichen verwenden möchten, benötigen Sie ein Flag -D, andernfalls werden sie von nm nicht angezeigt.: ++ 25–26 , . , , .
: ++ Online . 5 900 , , -.
: DevOpsConf 2019 HighLoad++ 2019 — , .
— , .