 In den letzten Jahren in meiner Freizeit habe ich Triathlon gespielt. Dieser Sport ist in vielen Ländern der Welt sehr beliebt, insbesondere in den USA, Australien und Europa. Derzeit gewinnt es in Russland und den GUS-Ländern rasch an Popularität. Es geht darum, Amateure einzubeziehen, keine Profis. Im Gegensatz zum morgendlichen Schwimmen im Pool, Radfahren und Joggen beinhaltet der Triathlon die Teilnahme an Wettkämpfen und die systematische Vorbereitung darauf, auch ohne ein Profi zu sein. Sicherlich gibt es unter Ihren Freunden bereits mindestens einen „Eisenmann“ oder jemanden, der vorhat, einer zu werden. Massivität, eine Vielzahl von Entfernungen und Bedingungen, drei Sportarten in einer - all dies hat das Potenzial, eine große Datenmenge zu bilden. Jedes Jahr finden weltweit mehrere hundert Triathlon-Wettbewerbe statt, an denen mehrere hunderttausend Menschen teilnehmen.Die Wettbewerbe werden von mehreren Veranstaltern durchgeführt. Jeder von ihnen veröffentlicht die Ergebnisse natürlich für sich. Aber für Athleten aus Russland und einigen GUS-Ländern ist das Teamtristats.ru sammelt alle Ergebnisse an einem Ort - auf seiner gleichnamigen Website. Dies macht es sehr bequem, nach Ergebnissen zu suchen, sowohl nach Ihren als auch nach Ihren Freunden und Rivalen oder sogar nach Ihren Idolen. Für mich gab es aber auch die Möglichkeit, eine Vielzahl von Ergebnissen programmatisch zu analysieren. Auf trilife veröffentlichte Ergebnisse: lesen .Dies war mein erstes Projekt dieser Art, da ich erst vor kurzem im Prinzip mit der Datenanalyse und der Verwendung von Python begonnen habe. Daher möchte ich Sie über die technische Umsetzung dieser Arbeit informieren, zumal dabei verschiedene Nuancen aufgetaucht sind, die manchmal einen besonderen Ansatz erfordern. Es geht um Verschrotten, Parsen, Casting von Typen und Formaten, Wiederherstellen unvollständiger Daten, Erstellen einer repräsentativen Stichprobe, Visualisierung, Vektorisierung und sogar paralleles Rechnen.Die Lautstärke stellte sich als groß heraus, so dass ich alles in fünf Teile zerlegte, damit ich die Informationen dosieren und mich daran erinnern konnte, wo ich nach der Pause anfangen sollte.Bevor Sie fortfahren, ist es besser, zuerst meinen Artikel mit den Ergebnissen der Studie zu lesen, da hier im Wesentlichen die Küche für ihre Erstellung beschrieben wurde. Es dauert 10-15 Minuten.Hast du gelesen? Dann lass uns gehen!
In den letzten Jahren in meiner Freizeit habe ich Triathlon gespielt. Dieser Sport ist in vielen Ländern der Welt sehr beliebt, insbesondere in den USA, Australien und Europa. Derzeit gewinnt es in Russland und den GUS-Ländern rasch an Popularität. Es geht darum, Amateure einzubeziehen, keine Profis. Im Gegensatz zum morgendlichen Schwimmen im Pool, Radfahren und Joggen beinhaltet der Triathlon die Teilnahme an Wettkämpfen und die systematische Vorbereitung darauf, auch ohne ein Profi zu sein. Sicherlich gibt es unter Ihren Freunden bereits mindestens einen „Eisenmann“ oder jemanden, der vorhat, einer zu werden. Massivität, eine Vielzahl von Entfernungen und Bedingungen, drei Sportarten in einer - all dies hat das Potenzial, eine große Datenmenge zu bilden. Jedes Jahr finden weltweit mehrere hundert Triathlon-Wettbewerbe statt, an denen mehrere hunderttausend Menschen teilnehmen.Die Wettbewerbe werden von mehreren Veranstaltern durchgeführt. Jeder von ihnen veröffentlicht die Ergebnisse natürlich für sich. Aber für Athleten aus Russland und einigen GUS-Ländern ist das Teamtristats.ru sammelt alle Ergebnisse an einem Ort - auf seiner gleichnamigen Website. Dies macht es sehr bequem, nach Ergebnissen zu suchen, sowohl nach Ihren als auch nach Ihren Freunden und Rivalen oder sogar nach Ihren Idolen. Für mich gab es aber auch die Möglichkeit, eine Vielzahl von Ergebnissen programmatisch zu analysieren. Auf trilife veröffentlichte Ergebnisse: lesen .Dies war mein erstes Projekt dieser Art, da ich erst vor kurzem im Prinzip mit der Datenanalyse und der Verwendung von Python begonnen habe. Daher möchte ich Sie über die technische Umsetzung dieser Arbeit informieren, zumal dabei verschiedene Nuancen aufgetaucht sind, die manchmal einen besonderen Ansatz erfordern. Es geht um Verschrotten, Parsen, Casting von Typen und Formaten, Wiederherstellen unvollständiger Daten, Erstellen einer repräsentativen Stichprobe, Visualisierung, Vektorisierung und sogar paralleles Rechnen.Die Lautstärke stellte sich als groß heraus, so dass ich alles in fünf Teile zerlegte, damit ich die Informationen dosieren und mich daran erinnern konnte, wo ich nach der Pause anfangen sollte.Bevor Sie fortfahren, ist es besser, zuerst meinen Artikel mit den Ergebnissen der Studie zu lesen, da hier im Wesentlichen die Küche für ihre Erstellung beschrieben wurde. Es dauert 10-15 Minuten.Hast du gelesen? Dann lass uns gehen!Teil 1. Scraping und Parsing
Gegeben: Website tristats.ru . Es gibt zwei Arten von Tabellen, die uns interessieren. Dies ist eigentlich eine Übersichtstabelle aller Rennen und ein Protokoll der Ergebnisse der einzelnen Rennen.
 Die Hauptaufgabe bestand darin, diese Daten programmgesteuert abzurufen und zur weiteren Verarbeitung zu speichern. So kam es, dass ich zu dieser Zeit noch keine Erfahrung mit Webtechnologien hatte und daher nicht sofort wusste, wie das geht. Ich habe dementsprechend mit dem begonnen, was ich wusste - schauen Sie sich den Seitencode an. Dies kann mit der rechten Maustaste oder der Taste F12 erfolgen .
Die Hauptaufgabe bestand darin, diese Daten programmgesteuert abzurufen und zur weiteren Verarbeitung zu speichern. So kam es, dass ich zu dieser Zeit noch keine Erfahrung mit Webtechnologien hatte und daher nicht sofort wusste, wie das geht. Ich habe dementsprechend mit dem begonnen, was ich wusste - schauen Sie sich den Seitencode an. Dies kann mit der rechten Maustaste oder der Taste F12 erfolgen . Das Menü in Chrome enthält zwei Optionen: Seitencode anzeigen und Code anzeigen . Nicht die offensichtlichste Trennung. Natürlich geben sie unterschiedliche Ergebnisse. Derjenige, der den Code anzeigt, es ist genau das gleiche wie F12 - die direkt textuelle HTML- Darstellung dessen, was im Browser angezeigt wird, ist elementweise.
Das Menü in Chrome enthält zwei Optionen: Seitencode anzeigen und Code anzeigen . Nicht die offensichtlichste Trennung. Natürlich geben sie unterschiedliche Ergebnisse. Derjenige, der den Code anzeigt, es ist genau das gleiche wie F12 - die direkt textuelle HTML- Darstellung dessen, was im Browser angezeigt wird, ist elementweise.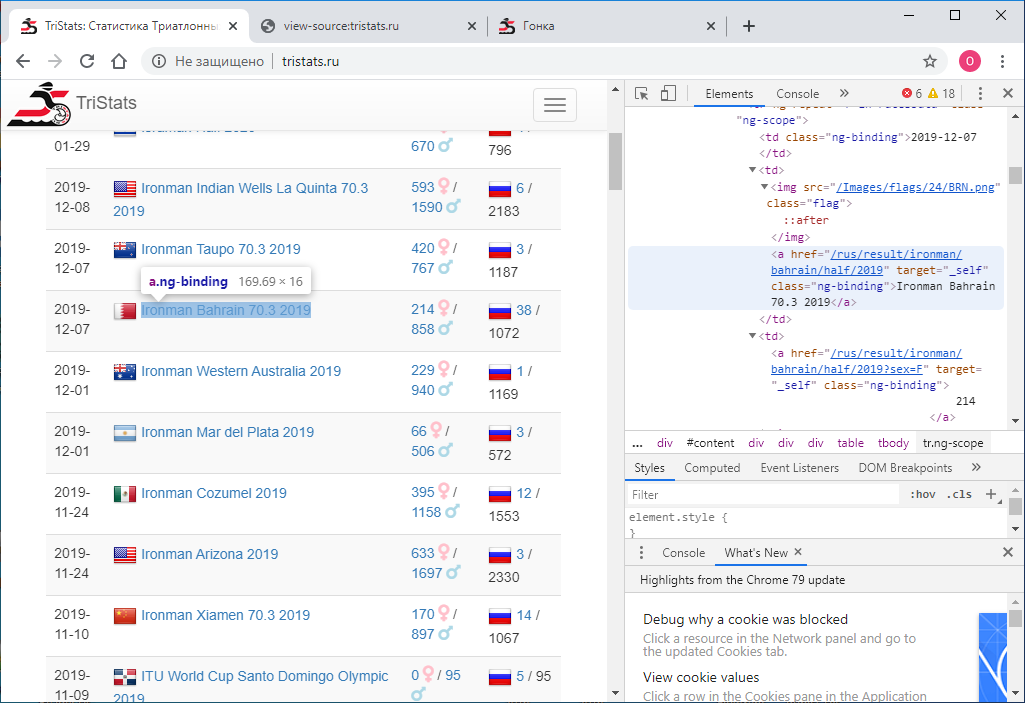 Das Anzeigen des Seitencodes gibt wiederum den Quellcode der Seite an. Auch HTML , aber es gibt dort keine Daten, nur die Namen der JS-Skripte, die sie entladen. Okay.
Das Anzeigen des Seitencodes gibt wiederum den Quellcode der Seite an. Auch HTML , aber es gibt dort keine Daten, nur die Namen der JS-Skripte, die sie entladen. Okay. Jetzt müssen wir verstehen, wie man Python verwendet, um den Code jeder Seite als separate Textdatei zu speichern. Ich versuche das:
Jetzt müssen wir verstehen, wie man Python verwendet, um den Code jeder Seite als separate Textdatei zu speichern. Ich versuche das:import requests
r = requests.get(url='http://tristats.ru/')
print(r.content)
Und ich bekomme ... den Quellcode. Aber ich brauche das Ergebnis seiner Ausführung. Nachdem ich studiert, gesucht und nachgefragt hatte, stellte ich fest, dass ich ein Tool zur Automatisierung von Browseraktionen brauchte, zum Beispiel Selen . Ich habe es gesagt. Und auch ChromeDriver für die Arbeit mit Google Chrome . Dann habe ich es wie folgt benutzt:from selenium import webdriver
from selenium.webdriver.chrome.service import Service
service = Service(r'C:\ChromeDriver\chromedriver.exe')
service.start()
driver = webdriver.Remote(service.service_url)
driver.get('http://www.tristats.ru/')
print(driver.page_source)
driver.quit()
Dieser Code öffnet ein Browserfenster und öffnet eine Seite mit der angegebenen URL. Als Ergebnis erhalten wir bereits HTML- Code mit den gewünschten Daten. Aber es gibt einen Haken. Das Ergebnis sind nur 100 Einsendungen und die Gesamtzahl der Rennen beträgt fast 2000. Wie? Tatsache ist, dass zunächst nur die ersten 100 Einträge im Browser angezeigt werden und nur dann, wenn Sie zum Ende der Seite scrollen, die nächsten 100 geladen werden und so weiter. Daher ist es notwendig, das Scrollen programmgesteuert zu implementieren. Verwenden Sie dazu den folgenden Befehl:driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
Und bei jedem Bildlauf prüfen wir, ob sich der Code der geladenen Seite geändert hat oder nicht. Wenn es sich nicht geändert hat, überprüfen wir mehrmals die Zuverlässigkeit, z. B. 10, dann wird die gesamte Seite geladen und Sie können anhalten. Zwischen den Schriftrollen setzen wir das Zeitlimit auf eine Sekunde, damit die Seite Zeit zum Laden hat. (Auch wenn sie keine Zeit hat, haben wir eine Reserve - weitere neun Sekunden)Und der vollständige Code sieht folgendermaßen aus:from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
service = Service(r'C:\ChromeDriver\chromedriver.exe')
service.start()
driver = webdriver.Remote(service.service_url)
driver.get('http://www.tristats.ru/')
prev_html = ''
scroll_attempt = 0
while scroll_attempt < 10:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1)
if prev_html == driver.page_source:
scroll_attempt += 1
else:
prev_html = driver.page_source
scroll_attempt = 0
with open(r'D:\tri\summary.txt', 'w') as f:
f.write(prev_html)
driver.quit()
Wir haben also eine HTML- Datei mit einer Übersichtstabelle aller Rennen. Müssen es analysieren. Verwenden Sie dazu die lxml- Bibliothek .from lxml import html
Zuerst finden wir alle Zeilen der Tabelle. Um das Vorzeichen einer Zeichenfolge zu bestimmen, sehen Sie sich einfach die HTML- Datei in einem Texteditor an. Dies kann beispielsweise "tr ng-repeat = 'r in RaceData' class = 'ng-scope'" oder ein Fragment sein, das in keinem Tag mehr gefunden werden kann.
kann beispielsweise "tr ng-repeat = 'r in RaceData' class = 'ng-scope'" oder ein Fragment sein, das in keinem Tag mehr gefunden werden kann.with open(r'D:\tri\summary.txt', 'r') as f:
sum_html = f.read()
tree = html.fromstring(sum_html)
rows = tree.findall(".//*[@ng-repeat='r in racesData']")
Dann starten wir den Pandas-Datenrahmen und jedes Element jeder Zeile der Tabelle wird in diesen Datenrahmen geschrieben.import pandas as pd
rs = pd.DataFrame(columns=['date','name','link','males','females','rus','total'], index=range(len(rows)))
Um herauszufinden, wo jedes einzelne Element versteckt ist, müssen Sie nur den HTML- Code eines der Elemente unserer Zeilen im selben Texteditor anzeigen.<tr ng-repeat="r in racesData" class="ng-scope">
<td class="ng-binding">2015-04-26</td>
<td>
<img src="/Images/flags/24/USA.png" class="flag">
<a href="/rus/result/ironman/texas/half/2015" target="_self" class="ng-binding">Ironman Texas 70.3 2015</a>
</td>
<td>
<a href="/rus/result/ironman/texas/half/2015?sex=F" target="_self" class="ng-binding">605</a>
<i class="fas fa-venus fa-lg" style="color:Pink"></i>
/
<a href="/rus/result/ironman/texas/half/2015?sex=M" target="_self" class="ng-binding">1539</a>
<i class="fas fa-mars fa-lg" style="color:LightBlue"></i>
</td>
<td class="ng-binding">
<img src="/Images/flags/24/rus.png" class="flag">
<a ng-if="r.CountryCount > 0" href="/rus/result/ironman/texas/half/2015?country=rus" target="_self" class="ng-binding ng-scope">2</a>
/ 2144
</td>
</tr>
Der einfachste Weg zur Hardcode-Navigation für Kinder ist, dass es nicht viele von ihnen gibt.for i in range(len(rows)):
rs.loc[i,'date'] = rows[i].getchildren()[0].text.strip()
rs.loc[i,'name'] = rows[i].getchildren()[1].getchildren()[1].text.strip()
rs.loc[i,'link'] = rows[i].getchildren()[1].getchildren()[1].attrib['href'].strip()
rs.loc[i,'males'] = rows[i].getchildren()[2].getchildren()[2].text.strip()
rs.loc[i,'females'] = rows[i].getchildren()[2].getchildren()[0].text.strip()
rs.loc[i,'rus'] = rows[i].getchildren()[3].getchildren()[3].text.strip()
rs.loc[i,'total'] = rows[i].getchildren()[3].text_content().split('/')[1].strip()
Hier ist das Ergebnis: Speichern Sie diesen Datenrahmen in einer Datei. Ich benutze Gurke , aber es könnte CSV oder etwas anderes sein.import pickle as pkl
with open(r'D:\tri\summary.pkl', 'wb') as f:
pkl.dump(df,f)
Zu diesem Zeitpunkt sind alle Daten vom Typ einer Zeichenfolge. Wir werden später konvertieren. Das Wichtigste, was wir jetzt brauchen, sind Links. Wir werden sie zum Scraping von Protokollen aller Rassen verwenden. Wir machen es nach dem Bild und der Ähnlichkeit, wie es für den Pivot-Tisch gemacht wurde. Im Zyklus für alle Rennen für jedes Rennen öffnen wir die Seite als Referenz, scrollen und erhalten den Seitencode. In der Übersichtstabelle finden Sie Informationen zur Gesamtzahl der Teilnehmer am Rennen - insgesamtWir werden es verwenden, um zu verstehen, bis zu welchem Punkt Sie weiter scrollen müssen. Zu diesem Zweck ermitteln wir beim Scraping jeder Seite direkt die Anzahl der Datensätze in der Tabelle und vergleichen sie mit dem erwarteten Gesamtwert. Sobald es gleich ist, haben wir bis zum Ende gescrollt und Sie können mit dem nächsten Rennen fortfahren. Wir haben auch eine Zeitüberschreitung von 60 Sekunden eingestellt. Aß während dieser Zeit, wir kommen nicht zur Summe , gehen zum nächsten Rennen. Der Seitencode wird in einer Datei gespeichert. Wir speichern die Dateien aller Rennen in einem Ordner und benennen sie nach dem Namen der Rennen, dh nach dem Wert in der Ereignisspalte in der Übersichtstabelle. Um einen Namenskonflikt zu vermeiden, müssen alle Rassen unterschiedliche Namen in der Pivot-Tabelle haben. Überprüfen Sie dies:df[df.duplicated(subset = 'event', keep=False)]
service.start()
driver = webdriver.Remote(service.service_url)
timeout = 60
for index, row in df.iterrows():
try:
driver.get('http://www.tristats.ru' + row['link'])
start = time.time()
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1)
race_html = driver.page_source
tree = html.fromstring(race_html)
race_rows = tree.findall(".//*[@ng-repeat='r in resultsData']")
if len(race_rows) == int(row['total']):
break
if time.time() - start > timeout:
print('timeout')
break
with open(os.path.join(r'D:\tri\races', row['event'] + '.txt'), 'w') as f:
f.write(race_html)
except:
traceback.print_exc()
time.sleep(1)
driver.quit()
Dies ist ein langer Prozess. Aber wenn alles eingerichtet ist und sich dieser schwere Mechanismus dreht und nacheinander Datendateien hinzufügt, entsteht ein Gefühl angenehmer Aufregung. Pro Minute werden nur etwa drei Protokolle sehr langsam geladen. Links für die Nacht drehen. Es dauerte ungefähr 10 Stunden. Am Morgen wurden die meisten Protokolle hochgeladen. Wie es normalerweise bei der Arbeit mit einem Netzwerk der Fall ist, schlagen einige fehl. Fuhr schnell mit einem zweiten Versuch fort. Wir haben also 1.922 Dateien mit einer Gesamtkapazität von fast 3 GB. Cool! Das Handling von fast 300 Rennen endete jedoch mit einer Auszeit. Was ist da los? Bei selektiver Überprüfung stellt sich heraus, dass der Gesamtwert aus der Pivot-Tabelle und die Anzahl der von uns überprüften Einträge im Rennprotokoll möglicherweise nicht übereinstimmen. Das ist traurig, weil nicht klar ist, was der Grund für diese Diskrepanz ist. Entweder liegt dies an der Tatsache, dass nicht jeder fertig wird, oder an einem Fehler in der Datenbank. Im Allgemeinen ist das erste Signal der Datenunvollkommenheit. In jedem Fall überprüfen wir diejenigen, bei denen die Anzahl der Einträge 100 oder 0 beträgt. Dies sind die verdächtigsten Kandidaten. Es waren acht von ihnen. Laden Sie sie erneut unter Kontrolle herunter. Übrigens gibt es in zwei von ihnen tatsächlich 100 Einträge.Nun, wir haben alle Daten. Wir gehen zum Parsen über. Wieder werden wir in einem Zyklus jedes Rennen durchlaufen, die Datei lesen und den Inhalt in einem Pandas DataFrame speichern . Wir werden diese Datenrahmen zu einem Diktat kombinieren , in dem die Namen der Rennen die Schlüssel sind - das heißt, die Ereigniswerte aus der Pivot-Tabelle oder die Namen der Dateien mit dem HTML- Code der Rennseiten stimmen überein.
Wir haben also 1.922 Dateien mit einer Gesamtkapazität von fast 3 GB. Cool! Das Handling von fast 300 Rennen endete jedoch mit einer Auszeit. Was ist da los? Bei selektiver Überprüfung stellt sich heraus, dass der Gesamtwert aus der Pivot-Tabelle und die Anzahl der von uns überprüften Einträge im Rennprotokoll möglicherweise nicht übereinstimmen. Das ist traurig, weil nicht klar ist, was der Grund für diese Diskrepanz ist. Entweder liegt dies an der Tatsache, dass nicht jeder fertig wird, oder an einem Fehler in der Datenbank. Im Allgemeinen ist das erste Signal der Datenunvollkommenheit. In jedem Fall überprüfen wir diejenigen, bei denen die Anzahl der Einträge 100 oder 0 beträgt. Dies sind die verdächtigsten Kandidaten. Es waren acht von ihnen. Laden Sie sie erneut unter Kontrolle herunter. Übrigens gibt es in zwei von ihnen tatsächlich 100 Einträge.Nun, wir haben alle Daten. Wir gehen zum Parsen über. Wieder werden wir in einem Zyklus jedes Rennen durchlaufen, die Datei lesen und den Inhalt in einem Pandas DataFrame speichern . Wir werden diese Datenrahmen zu einem Diktat kombinieren , in dem die Namen der Rennen die Schlüssel sind - das heißt, die Ereigniswerte aus der Pivot-Tabelle oder die Namen der Dateien mit dem HTML- Code der Rennseiten stimmen überein.rd = {}
for e in rs['event']:
place = []
... sex = [], name=..., country, group, place_in_group, swim, t1, bike, t2, run
result = []
with open(os.path.join(r'D:\tri\races', e + '.txt'), 'r')
race_html = f.read()
tree = html.fromstring(race_html)
rows = tree.findall(".//*[@ng-repeat='r in resultsData']")
for j in range(len(rows)):
row = rows[j]
parts = row.text_content().split('\n')
parts = [r.strip() for r in parts if r.strip() != '']
place.append(parts[0])
if len([a for a in row.findall('.//i')]) > 0:
sex.append([a for a in row.findall('.//i')][0].attrib['ng-if'][10:-1])
else:
sex.append('')
name.append(parts[1])
if len(parts) > 10:
country.append(parts[2].strip())
k=0
else:
country.append('')
k=1
group.append(parts[3-k])
... place_in_group.append(...), swim.append ..., t1, bike, t2, run
result.append(parts[10-k])
race = pd.DataFrame()
race['place'] = place
... race['sex'] = sex, race['name'] = ..., 'country', 'group', 'place_in_group', 'swim', ' t1', 'bike', 't2', 'run'
race['result'] = result
rd[e] = race
with open(r'D:\tri\details.pkl', 'wb') as f:
pkl.dump(rd,f)
for index, row in rs.iterrows():
e = row['event']
with open(os.path.join(r'D:\tri\races', e + '.txt'), 'r') as f:
race_html = f.read()
tree = html.fromstring(race_html)
header_elem = [tb for tb in tree.findall('.//tbody') if tb.getchildren()[0].getchildren()[0].text == ''][0]
location = header_elem.getchildren()[1].getchildren()[1].text.strip()
rs.loc[index, 'loc'] = location
with open(r'D:\tri\summary1.pkl', 'wb') as f:
pkl.dump(df,f)
Teil 2. Geben Sie Casting und Formatierung ein
Also haben wir alle Daten heruntergeladen und in die Datenrahmen eingefügt. Alle Werte sind jedoch vom Typ str . Dies gilt für das Datum, die Ergebnisse, den Ort und alle anderen Parameter. Alle Parameter müssen in die entsprechenden Typen konvertiert werden.Beginnen wir mit der Pivot-Tabelle.Datum (und Uhrzeit
Ereignis , Ort und Link bleiben unverändert . Datum Konvertit Pandas datetime wie folgt:rs['date'] = pd.to_datetime(rs['date'])
Der Rest wird in einen ganzzahligen Typ umgewandelt:cols = ['males', 'females', 'rus', 'total']
rs[cols] = rs[cols].astype(int)
Alles verlief reibungslos, es traten keine Fehler auf. Also alles in Ordnung - speichern:with open(r'D:\tri\summary2.pkl', 'wb') as f:
pkl.dump(rs, f)
Jetzt Rennen Datenrahmen. Da alle Rennen bequemer und schneller auf einmal und nicht einzeln verarbeitet werden können, werden sie mithilfe der concat- Methode in einem großen ar- Datenrahmen (kurz für alle Datensätze ) zusammengefasst .ar = pd.concat(rd)
ar enthält 1.416.365 Einträge.Konvertieren Sie nun place und place in group in einen ganzzahligen Wert.ar[['place', 'place in group']] = ar[['place', 'place in group']].astype(int))
Als nächstes verarbeiten wir die Spalten mit temporären Werten. Wir werden sie in der Art Timedelta von Pandas gießen . Damit die Konvertierung jedoch erfolgreich ist, müssen Sie die Daten ordnungsgemäß vorbereiten. Sie können sehen, dass einige Werte, die weniger als eine Stunde betragen, ohne Angabe des Tippes vergehen. Müssen Sie es hinzufügen.for col in ['swim', 't1', 'bike', 't2', 'run', 'result']:
strlen = ar[col].str.len()
ar.loc[strlen==5, col] = '0:' + ar.loc[strlen==5, col]
ar.loc[strlen==4, col] = '0:0' + ar.loc[strlen==4, col]
Jetzt sehen die verbleibenden Zeichenfolgen folgendermaßen aus : In Timedelta konvertieren :for col in ['swim', 't1', 'bike', 't2', 'run', 'result']:
ar[col] = pd.to_timedelta(ar[col])
Fußboden
Mach weiter. Überprüfen Sie, ob in der Spalte Geschlecht nur die Werte von M und F angegeben sind :ar['sex'].unique()
Out: ['M', 'F', '']
Tatsächlich gibt es immer noch eine leere Zeichenfolge, dh das Geschlecht ist nicht angegeben. Mal sehen, wie viele solcher Fälle:len(ar[ar['sex'] == ''])
Out: 2538
Nicht so viel ist gut. In Zukunft werden wir versuchen, diesen Wert weiter zu reduzieren. Lassen Sie in der Zwischenzeit die Geschlechtsspalte in Form von Linien. Wir werden das Ergebnis speichern, bevor wir zu ernsthafteren und riskanteren Transformationen übergehen. Um die Kontinuität zwischen den Dateien aufrechtzuerhalten, transformieren wir den kombinierten Datenrahmen ar zurück in das Wörterbuch der Datenrahmen rd :for event in ar.index.get_level_values(0).unique():
rd[event] = ar.loc[event]
with open(r'D:\tri\details1.pkl', 'wb') as f:
pkl.dump(rd,f)
Übrigens verringerten sich die Dateigrößen aufgrund der Konvertierung der Typen einiger Spalten von 367 KB auf 295 KB für die Pivot-Tabelle und von 251 MB auf 168 MB für Rennprotokolle.Landesvorwahl
Jetzt schauen wir uns das Land an.ar['country'].unique()
Out: ['CRO', 'CZE', 'SLO', 'SRB', 'BUL', 'SVK', 'SWE', 'BIH', 'POL', 'MK', 'ROU', 'GRE', 'FRA', 'HUN', 'NOR', 'AUT', 'MNE', 'GBR', 'RUS', 'UAE', 'USA', 'GER', 'URU', 'CRC', 'ITA', 'DEN', 'TUR', 'SUI', 'MEX', 'BLR', 'EST', 'NED', 'AUS', 'BGI', 'BEL', 'ESP', 'POR', 'UKR', 'CAN', 'IRL', 'JPN', 'HKG', 'JEY', 'SGP', 'BRA', 'QAT', 'LUX', 'RSA', 'NZL', 'LAT', 'PHI', 'KSA', 'SEY', 'MAS', 'OMA', 'ARG', 'ECU', 'THA', 'JOR', 'BRN', 'CIV', 'FIN', 'IRN', 'BER', 'LBA', 'KUW', 'LTU', 'SRI', 'HON', 'INA', 'LBN', 'PAN', 'EGY', 'MLT', 'WAL', 'ISL', 'CYP', 'DOM', 'IND', 'VIE', 'MRI', 'AZE', 'MLD', 'LIE', 'VEN', 'ALG', 'SYR', 'MAR', 'KZK', 'PER', 'COL', 'IRQ', 'PAK', 'CZK', 'KAZ', 'CHN', 'NEP', 'ISR', 'MKD', 'FRO', 'BAN', 'ARU', 'CPV', 'ALB', 'BIZ', 'TPE', 'KGZ', 'BNN', 'CUB', 'SNG', 'VTN', 'THI', 'PRG', 'KOR', 'RE', 'TW', 'VN', 'MOL', 'FRE', 'AND', 'MDV', 'GUA', 'MON', 'ARM', 'F.I.TRI.', 'BAHREIN', 'SUECIA', 'REPUBLICA CHECA', 'BRASIL', 'CHI', 'MDA', 'TUN', 'NDL', 'Danish(Dane)', 'Welsh', 'Austrian', 'Unknown', 'AFG', 'Argentinean', 'Pitcairn', 'South African', 'Greenland', 'ESTADOS UNIDOS', 'LUXEMBURGO', 'SUDAFRICA', 'NUEVA ZELANDA', 'RUMANIA', 'PM', 'BAH', 'LTV', 'ESA', 'LAB', 'GIB', 'GUT', 'SAR', 'ita', 'aut', 'ger', 'esp', 'gbr', 'hun', 'den', 'usa', 'sui', 'slo', 'cze', 'svk', 'fra', 'fin', 'isr', 'irn', 'irl', 'bel', 'ned', 'sco', 'pol', 'SMR', 'mex', 'STEEL T BG', 'KINO MANA', 'IVB', 'TCH', 'SCO', 'KEN', 'BAS', 'ZIM', 'Joe', 'PUR', 'SWZ', 'Mark', 'WLS', 'MYA', 'BOT', 'REU', 'NAM', 'NCL', 'BOL', 'GGY', 'ISV', 'TWN', 'GUM', 'FIJ', 'COK', 'NGR', 'IRI', 'GAB', 'ANT', 'GEO', 'COG', 'sue', 'SUD', 'BAR', 'CAY', 'BO', 'VE', 'AX', 'MD', 'PAR', 'UM', 'SEN', 'NIG', 'RWA', 'YEM', 'PLE', 'GHA', 'ITU', 'UZB', 'MGL', 'MAC', 'DMA', 'TAH', 'TTO', 'AHO', 'JAM', 'SKN', 'GRN', 'PRK', 'NFK', 'SOL', 'Sandy', 'SAM', 'PNG', 'SGS', 'Suchy, Jorg', 'SOG', 'GEQ', 'BVT', 'DJI', 'CHA', 'ANG', 'YUG', 'IOT', 'HAI', 'SJM', 'CUW', 'BHU', 'ERI', 'FLK', 'HMD', 'GUF', 'ESH', 'sandy', 'UMI', 'selsmark, 'Alise', 'Eddie', '31/3, Colin', 'CC', '', '', '', '', '', ' ', '', '', '', '-', '', 'GRL', 'UGA', 'VAT', 'ETH', 'ASA', 'PYF', 'ATA', 'ALA', 'MTQ', 'ZZ', 'CXR', 'AIA', 'TJK', 'GUY', 'KR', 'PF', 'BN', 'MO', 'LA', 'CAM', 'NCA', 'ZAM', 'MAD', 'TOG', 'VIR', 'ATF', 'VAN', 'SLE', 'GLP', 'SCG', 'LAO', 'IMN', 'BUR', 'IR', 'SY', 'CMR', 'GBS', 'SUR', 'MOZ', 'BLM', 'MSR', 'CAF', 'BEN', 'COD', 'CCK', 'TUV', 'TGA', 'GI', 'XKX', 'NRU', 'NC', 'LBR', 'TAN', 'VIN', 'SSD', 'GP', 'PS', 'IM', 'JE', '', 'MLI', 'FSM', 'LCA', 'GMB', 'MHL', 'NH', 'FL', 'CT', 'UT', 'AQ', 'Korea', 'Taiwan', 'NewCaledonia', 'Czech Republic', 'PLW', 'BRU', 'RUN', 'NIU', 'KIR', 'SOM', 'TKM', 'SPM', 'BDI', 'COM', 'TCA', 'SHN', 'DO2', 'DCF', 'PCN', 'MNP', 'MYT', 'SXM', 'MAF', 'GUI', 'AN', 'Slovak republic', 'Channel Islands', 'Reunion', 'Wales', 'Scotland', 'ica', 'WLF', 'D', 'F', 'I', 'B', 'L', 'E', 'A', 'S', 'N', 'H', 'R', 'NU', 'BES', 'Bavaria', 'TLS', 'J', 'TKL', 'Tirol"', 'P', '?????', 'EU', 'ES-IB', 'ES-CT', '', 'SOO', 'LZE', '', '', '', '', '', '']
412 eindeutige Werte.Grundsätzlich wird ein Land durch einen dreistelligen Buchstabencode in Großbuchstaben angegeben. Aber anscheinend nicht immer. Tatsächlich gibt es eine internationale Norm ISO 3166 , in der für alle Länder, auch für diejenigen, die nicht mehr existieren, die entsprechenden dreistelligen und zweistelligen Codes vorgeschrieben sind. Für Python befindet sich eine der Implementierungen dieses Standards im Pycountry- Paket . So funktioniert das:import pycountry as pyco
pyco.countries.get(alpha_3 = 'RUS')
Out: Country(alpha_2='RU', alpha_3='RUS', name='Russian Federation', numeric='643')
Daher werden wir alle dreistelligen Codes überprüfen, die zu Großbuchstaben führen und eine Antwort in Ländern.get (...) und historischem_Land.get (...) geben :valid_a3 = [c for c in ar['country'].unique() if pyco.countries.get(alpha_3 = c.upper()) != None or pyco.historic_countries.get(alpha_3 = c.upper()) != None])
Es gab 190 von 412 von ihnen, das heißt weniger als die Hälfte.Für den restlichen 222 (wir ihre Liste bezeichnen Tofix ), werden wir einen erstellen fix passenden Wörterbuch , in dem der Schlüssel wird der ursprüngliche Name, und den Wert ist ein dreistelliger Code gemäß der ISO - Norm.tofix = list(set(ar['country'].unique()) - set(valid_a3))
Überprüfen Sie zunächst die zweistelligen Codes mit pycountry.countries.get (alpha_2 = ...) , was zu Großbuchstaben führt:for icc in tofix:
if pyco.countries.get(alpha_2 = icc.upper()) != None:
fix[icc] = pyco.countries.get(alpha_2 = icc.upper()).alpha_3
else:
if pyco.historic_countries.get(alpha_2 = icc.upper()) != None:
fix[icc] = pyco.historic_countries.get(alpha_2 = icc.upper()).alpha_3
Dann die vollständigen Namen durch pycountry.countries.get (name = ...), pycountry.countries.get (common_name = ...) und führen sie zur Form str.title () :for icc in tofix:
if pyco.countries.get(common_name = icc.title()) != None:
fix[icc] = pyco.countries.get(common_name = icc.title()).alpha_3
else:
if pyco.countries.get(name = icc.title()) != None:
fix[icc] = pyco.countries.get(name = icc.title()).alpha_3
else:
if pyco.historic_countries.get(name = icc.title()) != None:
fix[icc] = pyco.historic_countries.get(name = icc.title()).alpha_3
Daher reduzieren wir die Anzahl der nicht erkannten Werte auf 190. Immer noch ziemlich viel: Sie werden feststellen, dass es unter ihnen immer noch viele dreistellige Codes gibt, aber dies ist keine ISO. Was dann? Es stellt sich heraus, dass es einen anderen Standard gibt - Olympia . Leider ist seine Implementierung nicht in Pycountry enthalten und Sie müssen nach etwas anderem suchen. Die Lösung wurde in Form einer CSV- Datei auf datahub.io gefunden . Platzieren Sie den Inhalt dieser Datei in einem Pandas DataFrame namens cdf . ioc - Internationales Olympisches Komitee (IOC)['URU', '', 'PAR', 'SUECIA', 'KUW', 'South African', '', 'Austrian', 'ISV', 'H', 'SCO', 'ES-CT', ', 'GUI', 'BOT', 'SEY', 'BIZ', 'LAB', 'PUR', ' ', 'Scotland', '', '', 'TCH', 'TGA', 'UT', 'BAH', 'GEQ', 'NEP', 'TAH', 'ica', 'FRE', 'E', 'TOG', 'MYA', '', 'Danish (Dane)', 'SAM', 'TPE', 'MON', 'ger', 'Unknown', 'sui', 'R', 'SUI', 'A', 'GRN', 'KZK', 'Wales', '', 'GBS', 'ESA', 'Bavaria', 'Czech Republic', '31/3, Colin', 'SOL', 'SKN', '', 'MGL', 'XKX', 'WLS', 'MOL', 'FIJ', 'CAY', 'ES-IB', 'BER', 'PLE', 'MRI', 'B', 'KSA', '', '', 'LAT', 'GRE', 'ARU', '', 'THI', 'NGR', 'MAD', 'SOG', 'MLD', '?????', 'AHO', 'sco', 'UAE', 'RUMANIA', 'CRO', 'RSA', 'NUEVA ZELANDA', 'KINO MANA', 'PHI', 'sue', 'Tirol"', 'IRI', 'POR', 'CZK', 'SAR', 'D', 'BRASIL', 'DCF', 'HAI', 'ned', 'N', 'BAHREIN', 'VTN', 'EU', 'CAM', 'Mark', 'BUL', 'Welsh', 'VIN', 'HON', 'ESTADOS UNIDOS', 'I', 'GUA', 'OMA', 'CRC', 'PRG', 'NIG', 'BHU', 'Joe', 'GER', 'RUN', 'ALG', '', 'Channel Islands', 'Reunion', 'REPUBLICA CHECA', 'slo', 'ANG', 'NewCaledonia', 'GUT', 'VIE', 'ASA', 'BAR', 'SRI', 'L', '', 'J', 'BAS', 'LUXEMBURGO', 'S', 'CHI', 'SNG', 'BNN', 'den', 'F.I.TRI.', 'STEEL T BG', 'NCA', 'Slovak republic', 'MAS', 'LZE', '-', 'F', 'BRU', '', 'LBA', 'NDL', 'DEN', 'IVB', 'BAN', 'Sandy', 'ZAM', 'sandy', 'Korea', 'SOO', 'BGI', '', 'LTV', 'selsmark, Alise', 'TAN', 'NED', '', 'Suchy, Jorg', 'SLO', 'SUDAFRICA', 'ZIM', 'Eddie', 'INA', '', 'SUD', 'VAN', 'FL', 'P', 'ITU', 'ZZ', 'Argentinean', 'CHA', 'DO2', 'WAL']
len(([x for x in tofix if x.upper() in list(cdf['ioc'])]))
Out: 82
Unter den dreistelligen Codes von tofix wurden 82 entsprechende IOCs gefunden. Fügen Sie sie unserem passenden Wörterbuch hinzu.for icc in tofix:
if icc.upper() in list(cdf['ioc']):
ind = cdf[cdf['ioc'] == icc.upper()].index[0]
fix[icc] = cdf.loc[ind, 'iso3']
108 Rohwerte übrig. Sie werden manuell beendet und wenden sich manchmal an Google, um Hilfe zu erhalten. Aber selbst die manuelle Steuerung löst das Problem nicht vollständig. Es bleiben 49 Werte übrig, die bereits nicht zu interpretieren sind. Die meisten dieser Werte sind wahrscheinlich nur Datenfehler.{'BGI': 'BRB', 'WAL': 'GBR', 'MLD': 'MDA', 'KZK': 'KAZ', 'CZK': 'CZE', 'BNN': 'BEN', 'SNG': 'SGP', 'VTN': 'VNM', 'THI': 'THA', 'PRG': 'PRT', 'MOL': 'MDA', 'FRE': 'FRA', 'F.I.TRI.': 'ITA', 'BAHREIN': 'BHR', 'SUECIA': 'SWE', 'REPUBLICA CHECA': 'CZE', 'BRASIL': 'BRA', 'NDL': 'NLD', 'Danish (Dane)': 'DNK', 'Welsh': 'GBR', 'Austrian': 'AUT', 'Argentinean': 'ARG', 'South African': 'ZAF', 'ESTADOS UNIDOS': 'USA', 'LUXEMBURGO': 'LUX', 'SUDAFRICA': 'ZAF', 'NUEVA ZELANDA': 'NZL', 'RUMANIA': 'ROU', 'sco': 'GBR', 'SCO': 'GBR', 'WLS': 'GBR', '': 'IND', '': 'IRL', '': 'ARM', '': 'BGR', '': 'SRB', ' ': 'BLR', '': 'GBR', '': 'FRA', '': 'HND', '-': 'CRI', '': 'AZE', 'Korea': 'KOR', 'NewCaledonia': 'FRA', 'Czech Republic': 'CZE', 'Slovak republic': 'SVK', 'Channel Islands': 'FRA', 'Reunion': 'FRA', 'Wales': 'GBR', 'Scotland': 'GBR', 'Bavaria': 'DEU', 'Tirol"': 'AUT', '': 'KGZ', '': 'BLR', '': 'BLR', '': 'BLR', '': 'RUS', '': 'BLR', '': 'RUS'}
unfixed = [x for x in tofix if x not in fix.keys()]
Out: ['', 'H', 'ES-CT', 'LAB', 'TCH', 'UT', 'TAH', 'ica', 'E', 'Unknown', 'R', 'A', '31/3, Colin', 'XKX', 'ES-IB','B','SOG','?????','KINO MANA','sue','SAR','D', 'DCF', 'N', 'EU', 'Mark', 'I', 'Joe', 'RUN', 'GUT', 'L', 'J', 'BAS', 'S', 'STEEL T BG', 'LZE', 'F', 'Sandy', 'DO2', 'sandy', 'SOO', 'LTV', 'selsmark, Alise', 'Suchy, Jorg' 'Eddie', 'FL', 'P', 'ITU', 'ZZ']
Diese Schlüssel haben eine leere Zeichenfolge im passenden Wörterbuch.for cc in unfixed:
fix[cc] = ''
Schließlich fügen wir den passenden Wörterbuchcodes hinzu, die gültig, aber in Kleinbuchstaben geschrieben sind.for cc in valid_a3:
if cc.upper() != cc:
fix[cc] = cc.upper()
Jetzt ist es Zeit, die gefundenen Ersetzungen anzuwenden. Um die anfänglichen Daten für einen weiteren Vergleich zu speichern, kopieren Sie die Länderspalte in das Land "raw" . Anschließend korrigieren wir mithilfe des erstellten übereinstimmenden Wörterbuchs die Werte in der Länderspalte , die nicht der ISO entsprechen.for cc in fix:
ind = ar[ar['country'] == cc].index
ar.loc[ind,'country'] = fix[cc]
Hier kann man natürlich nicht auf Vektorisierung verzichten, die Tabelle hat fast eineinhalb Millionen Zeilen. Aber laut Wörterbuch machen wir einen Zyklus, aber wie sonst? Überprüfen Sie, wie viele Datensätze geändert wurden:len(ar[ar['country'] != ar['country raw']])
Out: 315955
das sind mehr als 20% der Gesamtmenge.ar[ar['country'] != ar['country raw']].sample(10)
len(ar[ar['country'] == ''])
Out: 3221
Dies ist die Anzahl der Datensätze ohne Land oder mit einem informellen Land. Die Anzahl der einzelnen Länder ist von 412 auf 250 gesunken. Hier sind sie: Jetzt gibt es keine Abweichungen mehr. Wir speichern das Ergebnis in einer neuen Datei details2.pkl , nachdem wir den kombinierten Datenrahmen wie zuvor wieder in ein Wörterbuch mit Datenrahmen konvertiert haben.['', 'ABW', 'AFG', 'AGO', 'AIA', 'ALA', 'ALB', 'AND', 'ANT', 'ARE', 'ARG', 'ARM', 'ASM', 'ATA', 'ATF', 'AUS', 'AUT', 'AZE', 'BDI', 'BEL', 'BEN', 'BES', 'BGD', 'BGR', 'BHR', 'BHS', 'BIH', 'BLM', 'BLR', 'BLZ', 'BMU', 'BOL', 'BRA', 'BRB', 'BRN', 'BTN', 'BUR', 'BVT', 'BWA', 'CAF', 'CAN', 'CCK', 'CHE', 'CHL', 'CHN', 'CIV', 'CMR', 'COD', 'COG', 'COK', 'COL', 'COM', 'CPV', 'CRI', 'CTE', 'CUB', 'CUW', 'CXR', 'CYM', 'CYP', 'CZE', 'DEU', 'DJI', 'DMA', 'DNK', 'DOM', 'DZA', 'ECU', 'EGY', 'ERI', 'ESH', 'ESP', 'EST', 'ETH', 'FIN', 'FJI', 'FLK', 'FRA', 'FRO', 'FSM', 'GAB', 'GBR', 'GEO', 'GGY', 'GHA', 'GIB', 'GIN', 'GLP', 'GMB', 'GNB', 'GNQ', 'GRC', 'GRD', 'GRL', 'GTM', 'GUF', 'GUM', 'GUY', 'HKG', 'HMD', 'HND', 'HRV', 'HTI', 'HUN', 'IDN', 'IMN', 'IND', 'IOT', 'IRL', 'IRN', 'IRQ', 'ISL', 'ISR', 'ITA', 'JAM', 'JEY', 'JOR', 'JPN', 'KAZ', 'KEN', 'KGZ', 'KHM', 'KIR', 'KNA', 'KOR', 'KWT', 'LAO', 'LBN', 'LBR', 'LBY', 'LCA', 'LIE', 'LKA', 'LTU', 'LUX', 'LVA', 'MAC', 'MAF', 'MAR', 'MCO', 'MDA', 'MDG', 'MDV', 'MEX', 'MHL', 'MKD', 'MLI', 'MLT', 'MMR', 'MNE', 'MNG', 'MNP', 'MOZ', 'MSR', 'MTQ', 'MUS', 'MYS', 'MYT', 'NAM', 'NCL', 'NER', 'NFK', 'NGA', 'NHB', 'NIC', 'NIU', 'NLD', 'NOR', 'NPL', 'NRU', 'NZL', 'OMN', 'PAK', 'PAN', 'PCN', 'PER', 'PHL', 'PLW', 'PNG', 'POL', 'PRI', 'PRK', 'PRT', 'PRY', 'PSE', 'PYF', 'QAT', 'REU', 'ROU', 'RUS', 'RWA', 'SAU', 'SCG', 'SDN', 'SEN', 'SGP', 'SGS', 'SHN', 'SJM', 'SLB', 'SLE', 'SLV', 'SMR', 'SOM', 'SPM', 'SRB', 'SSD', 'SUR', 'SVK', 'SVN', 'SWE', 'SWZ', 'SXM', 'SYC', 'SYR', 'TCA', 'TCD', 'TGO', 'THA', 'TJK', 'TKL', 'TKM', 'TLS', 'TON', 'TTO', 'TUN', 'TUR', 'TUV', 'TWN', 'TZA', 'UGA', 'UKR', 'UMI', 'URY', 'USA', 'UZB', 'VAT', 'VCT', 'VEN', 'VGB', 'VIR', 'VNM', 'VUT', 'WLF', 'WSM', 'YEM', 'YUG', 'ZAF', 'ZMB', 'ZWE']
Standort
Denken Sie nun daran, dass die Erwähnung von Ländern auch in der Pivot-Tabelle in der Spalte loc enthalten ist . Es muss auch zu einem Standard-Look gebracht werden. Hier ist eine etwas andere Geschichte: Weder ISO- noch Olympia-Codes sind sichtbar. Alles wird in einer ziemlich freien Form beschrieben. Die Stadt, das Land und andere Komponenten der Adresse werden mit einem Komma und in zufälliger Reihenfolge aufgelistet. Irgendwo an erster Stelle, irgendwo an letzter Stelle. pycountry wird hier nicht helfen. Und es gibt viele Rekorde - für das Rennen 1922 525 einzigartige Orte (in seiner ursprünglichen Form). Aber hier wurde ein geeignetes Werkzeug gefunden. Dies ist Geopy , nämlich der Geolocator Nominatim . Es funktioniert so:from geopy.geocoders import Nominatim
geolocator = Nominatim(user_agent='triathlon results researcher')
geolocator.geocode(' , , ', language='en')
Out: Location( , – , , Altaysky District, Altai Krai, Siberian Federal District, Russia, (51.78897945, 85.73956296106752, 0.0))
Auf Anfrage gibt es in zufälliger Form eine strukturierte Antwortadresse und Koordinaten. Wenn Sie die Sprache wie hier einstellen - Englisch, was es kann - wird übersetzt. Zunächst benötigen wir den Standardnamen des Landes für die spätere Übersetzung in den ISO-Code. Es nimmt nur den letzten Platz in der Adresseigenschaft ein . Da Geolocator jedes Mal eine Anfrage an den Server sendet, ist dieser Vorgang nicht schnell und dauert 500 Minuten für 500 Datensätze. Außerdem kommt es vor, dass die Antwort nicht kommt. In diesem Fall hilft manchmal eine zweite Anfrage. In meiner ersten Antwort kamen nicht zu 130 Anfragen. Die meisten von ihnen wurden mit zwei Wiederholungsversuchen verarbeitet. 34 Namen wurden jedoch auch bei mehreren weiteren Versuchen nicht verarbeitet. Hier sind sie:['Tongyeong, Korea, Korea, South', 'Constanta, Mamaia, Romania, Romania', 'Weihai, China, China', '. , .', 'Odaiba Marin Park, Tokyo, Japan, Japan', 'Sweden, Smaland, Kalmar', 'Cholpon-Ata city, Resort Center "Kapriz", Kyrgyzstan', 'Luxembourg, Region Moselle, Moselle', 'Chita Peninsula, Japan', 'Kraichgau Region, Germany', 'Jintang, Chengdu, Sichuan Province, China, China', 'Madrid, Spain, Spain', 'North American Pro Championship, St. George, Utah, USA', 'Milan Idroscalo Linate, Italy', 'Dexing, Jiangxi Province, China, China', 'Mooloolaba, Australia, Australia', 'Nathan Benderson Park (NBP), 5851 Nathan Benderson Circle, Sarasota, FL 34235., United States', 'Strathclyde Country Park, North Lanarkshire, Glasgow, Great Britain', 'Quijing, China', 'United States of America , Hawaii, Kohala Coast', 'Buffalo City, East London, South Africa', 'Spain, Vall de Cardener', ', . ', 'Asian TriClub Championship, Hefei, China', 'Taizhou, Jiangsu Province, China, China', ', , «»', 'Buffalo, Gallagher Beach, Furhmann Blvd, United States', 'North American Pro Championship | St. George, Utah, USA', 'Weihai, Shandong, China, China', 'Tarzo - Revine Lago, Italy', 'Lausanee, Switzerland', 'Queenstown, New Zealand, New Zealand', 'Makuhari, Japan, Japan', 'Szombathlely, Hungary']
Es ist zu sehen, dass in vielen Ländern das Land doppelt erwähnt wird, und dies stört tatsächlich. Im Allgemeinen musste ich diese verbleibenden Namen manuell verarbeiten und Standardadressen wurden für alle erhalten. Außerdem habe ich aus diesen Adressen ein Land ausgewählt und dieses Land in eine neue Spalte in der Pivot-Tabelle geschrieben. Da die Arbeit mit Geopy , wie gesagt, nicht schnell ist, habe ich beschlossen, die Standortkoordinaten - Längen- und Breitengrad - sofort zu speichern. Sie werden später zur Visualisierung auf der Karte nützlich sein. Danach suchte Alpha_3 mit pyco.countries.get (name = '...') nach dem Land nach Namen und wies ihm einen dreistelligen Code zu.Entfernung
Eine weitere wichtige Aktion, die am Pivot-Tisch ausgeführt werden muss, ist die Bestimmung der Distanz für jedes Rennen. Dies ist für uns nützlich, um zukünftige Geschwindigkeiten zu berechnen. Beim Triathlon gibt es vier Hauptdistanzen - Sprint, Olympia, Halbeisen und Eisen. Sie können sehen, dass in den Namen der Rennen normalerweise ein Hinweis auf die Entfernung angegeben ist - dies sind Sprint , Olympic , Half , Full Words . Darüber hinaus haben verschiedene Organisatoren ihre eigenen Entfernungsbezeichnungen. Die Hälfte von Ironman wird zum Beispiel als 70,3 bezeichnet - durch die Anzahl der Meilen in der Ferne, die olympische - 5150 durch die Anzahl der Kilometer (51,5), und das Eisen kann als voll bezeichnet werdenoder im Allgemeinen als Mangel an Erklärung - zum Beispiel Ironman Arizona 2019 . Ironman - er ist Eisen! In der Herausforderung wird die Eisenentfernung als lang und die Halbeisenentfernung als mittel bezeichnet . Unser russischer IronStar bedeutet voll wie 226 und halb so groß wie 113 - gemessen an der Anzahl der Kilometer, aber normalerweise sind auch die Wörter Full und Half vorhanden. Wenden Sie nun all dieses Wissen an und markieren Sie alle Rassen gemäß den in den Namen enthaltenen Schlüsselwörtern.sprints = rs.loc[[i for i in rs.index if 'sprint' in rs.loc[i, 'event'].lower()]]
olympics1 = rs.loc[[i for i in rs.index if 'olympic' in rs.loc[i, 'event'].lower()]]
olympics2 = rs.loc[[i for i in rs.index if '5150' in rs.loc[i, 'event'].lower()]]
olympics = pd.concat([olympics1, olympics2])
rsd = pd.concat([sprints, olympics, halfs, fulls])
In rsd stellte sich heraus, dass es 1 925 Rekorde gab, dh drei mehr als die Gesamtzahl der Rennen, so dass einige unter zwei Kriterien fielen. Schauen wir sie uns an:rsd[rsd.duplicated(keep=False)]['event'].sort_index()
olympics.drop(65)
Wir werden dasselbe mit dem sich kreuzenden Ironman Dun Laoghaire Full Swim 70.3 2019 tun. Hier ist die beste Zeit 4:00. Dies ist typisch für die Hälfte. Löschen Sie den Datensatz mit dem Index 85 aus den vollständigen Werten .fulls.drop(85)
Jetzt schreiben wir die Entfernungsinformationen in den Hauptdatenrahmen und sehen, was passiert ist:rs['dist'] = ''
rs.loc[sprints.index,'dist'] = 'sprint'
rs.loc[olympics.index,'dist'] = 'olympic'
rs.loc[halfs.index,'dist'] = 'half'
rs.loc[fulls.index,'dist'] = 'full'
rs.sample(10)
len(rs[rs['dist'] == ''])
Out: 0
Und schauen Sie sich unsere problematischen, mehrdeutigen an:rs.loc[[38,65,82],['event','dist']]
pkl.dump(rs, open(r'D:\tri\summary5.pkl', 'wb'))
Altersgruppen
Nun zurück zu den Rennprotokollen.Wir haben bereits Geschlecht, Land und Ergebnisse des Teilnehmers analysiert und auf eine Standardform gebracht. Es blieben jedoch zwei weitere Spalten übrig - die Gruppe und tatsächlich der Name selbst. Beginnen wir mit den Gruppen. Beim Triathlon ist es üblich, die Teilnehmer nach Altersgruppen zu unterteilen. Oft fällt auch eine Gruppe von Fachleuten auf. Tatsächlich ist der Versatz in jeder dieser Gruppen separat - die ersten drei Plätze in jeder Gruppe werden vergeben. In Gruppen wird die Qualifikation für Meisterschaften ausgewählt, zum Beispiel auf Konu.Kombinieren Sie alle Datensätze und sehen Sie, welche Gruppen im Allgemeinen existieren.rd = pkl.load(open(r'D:\tri\details2.pkl', 'rb'))
ar = pd.concat(rd)
ar['group'].unique()
Es stellte sich heraus, dass es eine große Anzahl von Gruppen gab - 581. Hundert zufällig ausgewählte Gruppen sehen folgendermaßen aus: Mal sehen, welche von ihnen die zahlreichsten sind:['MSenior', 'FAmat.', 'M20', 'M65-59', 'F25-29', 'F18-22', 'M75-59', 'MPro', 'F24', 'MCORP M', 'F21-30', 'MSenior 4', 'M40-50', 'FAWAD', 'M16-29', 'MK40-49', 'F65-70', 'F65-70', 'M12-15', 'MK18-29', 'M50up', 'FSEMIFINAL 2 PRO', 'F16', 'MWhite', 'MOpen 25-29', 'F', 'MPT TRI-2', 'M16-24', 'FQUALIFIER 1 PRO', 'F15-17', 'FSEMIFINAL 2 JUNIOR', 'FOpen 60-64', 'M75-80', 'F60-69', 'FJUNIOR A', 'F17-18', 'FAWAD BLIND', 'M75-79', 'M18-29', 'MJUN19-23', 'M60-up', 'M70', 'MPTS5', 'F35-40', "M'S PT1", 'M50-54', 'F65-69', 'F17-20', 'MP4', 'M16-29', 'F18up', 'MJU', 'MPT4', 'MPT TRI-3', 'MU24-39', 'MK35-39', 'F18-20', "M'S", 'F50-55', 'M75-80', 'MXTRI', 'F40-45', 'MJUNIOR B', 'F15', 'F18-19', 'M20-29', 'MAWAD PC4', 'M30-37', 'F21-30', 'Mpro', 'MSEMIFINAL 1 JUNIOR', 'M25-34', 'MAmat.', 'FAWAD PC5', 'FA', 'F50-60', 'FSenior 1', 'M80-84', 'FK45-49', 'F75-79', 'M<23', 'MPTS3', 'M70-75', 'M50-60', 'FQUALIFIER 3 PRO', 'M9', 'F31-40', 'MJUN16-19', 'F18-19', 'M PARA', 'F35-44', 'MParaathlete', 'F18-34', 'FA', 'FAWAD PC2', 'FAll Ages', 'M PARA', 'F31-40', 'MM85', 'M25-39']
ar['group'].value_counts()[:30]
Out:
M40-44 199157
M35-39 183738
M45-49 166796
M30-34 154732
M50-54 107307
M25-29 88980
M55-59 50659
F40-44 48036
F35-39 47414
F30-34 45838
F45-49 39618
MPRO 38445
F25-29 31718
F50-54 26253
M18-24 24534
FPRO 23810
M60-64 20773
M 12799
F55-59 12470
M65-69 8039
F18-24 7772
MJUNIOR 6605
F60-64 5067
M20-24 4580
FJUNIOR 4105
M30-39 3964
M40-49 3319
F 3306
M70-74 3072
F20-24 2522
Sie können sehen, dass dies Gruppen von fünf Jahren sind, getrennt für Männer und getrennt für Frauen, sowie Berufsgruppen MPRO und FPRO .Unser Standard wird also sein:ag = ['MPRO', 'M18-24', 'M25-29', 'M30-34', 'M35-39', 'M40-44', 'M45-49', 'M50-54', 'M55-59', 'M60-64', 'M65-69', 'M70-74', 'M75-79', 'M80-84', 'M85-90', 'FPRO', 'F18-24', 'F25-29', 'F30-34', 'F35-39', 'F40-44', 'F45-49', 'F50-54', 'F55-59', 'F60-64', 'F65-69', 'F70-74', 'F75-79', 'F80-84', 'F85-90']
Dieses Set deckt fast 95% aller Finisher ab.Natürlich können wir nicht alle Gruppen auf diesen Standard bringen. Aber wir suchen nach denen, die ihnen ähnlich sind und geben zumindest einen Teil davon. Zuerst bringen wir die Großbuchstaben und entfernen die Leerzeichen. Folgendes ist passiert: Konvertieren Sie sie in unsere Standard-Modelle.['F25-29F', 'F30-34F', 'F30-34-34', 'F35-39F', 'F40-44F', 'F45-49F', 'F50-54F', 'F55-59F', 'FAG:FPRO', 'FK30-34', 'FK35-39', 'FK40-44', 'FK45-49', 'FOPEN50-54', 'FOPEN60-64', 'MAG:MPRO', 'MK30-34', 'MK30-39', 'MK35-39', 'MK40-44', 'MK40-49', 'MK50-59', 'M40-44', 'MM85-89', 'MOPEN25-29', 'MOPEN30-34', 'MOPEN35-39', 'MOPEN40-44', 'MOPEN45-49', 'MOPEN50-54', 'MOPEN70-74', 'MPRO:', 'MPROM', 'M0-44"']
fix = { 'F25-29F': 'F25-29', 'F30-34F' : 'F30-34', 'F30-34-34': 'F30-34', 'F35-39F': 'F35-39', 'F40-44F': 'F40-44', 'F45-49F': 'F45-49', 'F50-54F': 'F50-54', 'F55-59F': 'F55-59', 'FAG:FPRO': 'FPRO', 'FK30-34': 'F30-34', 'FK35-39': 'F35-39', 'FK40-44': 'F40-44', 'FK45-49': 'F45-49', 'FOPEN50-54': 'F50-54', 'FOPEN60-64': 'F60-64', 'MAG:MPRO': 'MPRO', 'MK30-34': 'M30-34', 'MK30-39': 'M30-39', 'MK35-39': 'M35-39', 'MK40-44': 'M40-44', 'MK40-49': 'M40-49', 'MK50-59': 'M50-59', 'M40-44': 'M40-44', 'MM85-89': 'M85-89', 'MOPEN25-29': 'M25-29', 'MOPEN30-34': 'M30-34', 'MOPEN35-39': 'M35-39', 'MOPEN40-44': 'M40-44', 'MOPEN45-49': 'M45-49', 'MOPEN50-54': 'M50-54', 'MOPEN70-74': 'M70- 74', 'MPRO:' :'MPRO', 'MPROM': 'MPRO', 'M0-44"' : 'M40-44'}
Jetzt wenden wir unsere Transformation auf den Hauptdatenrahmen ar an , speichern jedoch zuerst die ursprünglichen Gruppenwerte in der neuen Rohgruppe der Gruppe .ar['group raw'] = ar['group']
In der Gruppenspalte belassen wir nur die Werte, die unserem Standard entsprechen.Jetzt können wir unsere Bemühungen würdigen:len(ar[(ar['group'] != ar['group raw'])&(ar['group']!='')])
Out: 273
Nur ein bisschen auf dem Niveau von eineinhalb Millionen. Aber Sie werden es nicht wissen, bis Sie es versuchen.Ausgewählte 10 sehen folgendermaßen aus: Speichern Sie die neue Version des Datenrahmens, nachdem Sie ihn wieder in das dritte Wörterbuch konvertiert haben .pkl.dump(rd, open(r'D:\tri\details3.pkl', 'wb'))
Name
Nun kümmern wir uns um die Namen. Sehen wir uns selektiv 100 Namen aus verschiedenen Rassen an:list(ar['name'].sample(100))
Out: ['Case, Christine', 'Van der westhuizen, Wouter', 'Grace, Scott', 'Sader, Markus', 'Schuller, Gunnar', 'Juul-Andersen, Jeppe', 'Nelson, Matthew', ' ', 'Westman, Pehr', 'Becker, Christoph', 'Bolton, Jarrad', 'Coto, Ricardo', 'Davies, Luke', 'Daniltchev, Alexandre', 'Escobar Labastida, Emmanuelle', 'Idzikowski, Jacek', 'Fairaislova Iveta', 'Fisher, Kulani', 'Didenko, Viktor', 'Osborne, Jane', 'Kadralinov, Zhalgas', 'Perkins, Chad', 'Caddell, Martha', 'Lynaire PARISH', 'Busing, Lynn', 'Nikitin, Evgeny', 'ANSON MONZON, ROBERTO', 'Kaub, Bernd', 'Bank, Morten', 'Kennedy, Ian', 'Kahl, Stephen', 'Vossough, Andreas', 'Gale, Karen', 'Mullally, Kristin', 'Alex FRASER', 'Dierkes, Manuela', 'Gillett, David', 'Green, Erica', 'Cunnew, Elliott', 'Sukk, Gaspar', 'Markina Veronika', 'Thomas KVARICS', 'Wu, Lewen', 'Van Enk, W.J.J', 'Escobar, Rosario', 'Healey, Pat', 'Scheef, Heike', 'Ancheta, Marlon', 'Heck, Andreas', 'Vargas Iii, Raul', 'Seferoglou, Maria', 'chris GUZMAN', 'Casey, Timothy', 'Olshanikov Konstantin', 'Rasmus Nerrand', 'Lehmann Bence', 'Amacker, Kirby', 'Parks, Chris', 'Tom, Troy', 'Karlsson, Ulf', 'Halfkann, Dorothee', 'Szabo, Gergely', 'Antipov Mikhail', 'Von Alvensleben, Alvo', 'Gruber, Peter', 'Leblanc, Jean-Philippe', 'Bouchard, Jean-Francois', 'Marchiotto MASSIMO', 'Green, Molly', 'Alder, Christoph', 'Morris, Huw', 'Deceur, Marc', 'Queenan, Derek', 'Krause, Carolin', 'Cockings, Antony', 'Ziehmer Chris', 'Stiene, John', 'Chmet Daniela', 'Chris RIORDAN', 'Wintle, Mel', ' ', 'GASPARINI CHRISTIAN', 'Westbrook, Christohper', 'Martens, Wim', 'Papson, Chris', 'Burdess, Shaun', 'Proctor, Shane', 'Cruzinha, Pedro', 'Hamard, Jacques', 'Petersen, Brett', 'Sahyoun, Sebastien', "O'Connell, Keith", 'Symoshenko, Zhan', 'Luternauer, Jan', 'Coronado, Basil', 'Smith, Alex', 'Dittberner, Felix', 'N?sman, Henrik', 'King, Malisa', 'PUHLMANN Andre']
Alles ist schwierig. Es gibt eine Vielzahl von Optionen für Einträge: Vorname Nachname, Nachname Vorname, Nachname, Vorname, Nachname, Vorname usw. Das heißt, eine andere Reihenfolge, ein anderes Register, irgendwo gibt es ein Trennzeichen - ein Komma. Es gibt auch viele Protokolle, in denen Kyrillisch verwendet wird. Es gibt auch keine Einheitlichkeit, und solche Formate können gefunden werden: "Nachname Vorname", "Vorname Nachname", "Vorname Zweiter Vorname Nachname", "Nachname Vorname Zweiter Vorname". Obwohl in der Tat der zweite Vorname auch in der lateinischen Schreibweise gefunden wird. Und hier tritt übrigens ein weiteres Problem auf - die Transliteration. Es sollte auch beachtet werden, dass selbst wenn es keinen zweiten Vornamen gibt, der Datensatz möglicherweise nicht auf zwei Wörter beschränkt ist. Beispielsweise besteht für Hispanics der Name plus Nachname normalerweise aus drei oder vier Wörtern. Die Holländer haben das Präfix Van, die Chinesen und Koreaner haben auch zusammengesetzte Namen, die normalerweise aus drei Wörtern bestehen. Im Allgemeinen müssen Sie diesen gesamten Rebus irgendwie entwirren und auf das Maximum standardisieren. Innerhalb eines Rennens ist das Namensformat in der Regel für alle gleich, aber auch hier gibt es Fehler, die wir jedoch nicht behandeln werden. Beginnen wir mit dem Speichern der vorhandenen Werte im neuen Spaltennamen raw :ar['name raw'] = ar['name']
Die überwiegende Mehrheit der Protokolle ist in Latein, daher möchte ich als erstes transliterieren. Mal sehen, welche Zeichen im Namen des Teilnehmers enthalten sein können.set( ''.join(ar['name'].unique()))
Out: [' ', '!', '"', '#', '&', "'", '(', ')', '*', '+', ',', '-', '.', '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', ';', '>', '?', '@', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '[', '\\', ']', '^', '_', '`', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '|', '\x7f', '\xa0', '¤', '¦', '§', '', '«', '\xad', '', '°', '±', 'µ', '¶', '·', '»', '', 'І', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', 'є', 'і', 'ў', '–', '—', '‘', '’', '‚', '“', '”', '„', '†', '‡', '…', '‰', '›', '']
Was gibt es nur! Zusätzlich zu den tatsächlichen Buchstaben und Leerzeichen gibt es noch eine Reihe verschiedener ausgefallener Charaktere. Von diesen können der Punkt '.', Der Bindestrich '-' und der Apostroph '' 'als gültig angesehen werden, dh nicht versehentlich vorhanden sein. Außerdem wurde festgestellt, dass in vielen deutschen und norwegischen Vor- und Nachnamen ein Fragezeichen "?" Sie ersetzen anscheinend die Zeichen aus dem erweiterten lateinischen Alphabet - '?', 'A', 'o', 'u' ,? und andere. Hier einige Beispiele: Das Komma ist, obwohl es sehr häufig vorkommt, nur ein Trennzeichen, das bei bestimmten Rassen verwendet wird, sodass es auch in die Kategorie der inakzeptablen fällt. Zahlen sollten auch nicht in Namen erscheinen.Pierre-Alexandre Petit, Jean-louis Lafontaine, Faris Al-Sultan, Jean-Francois Evrard, Paul O'Mahony, Aidan O'Farrell, John O'Neill, Nick D'Alton, Ward D'Hulster, Hans P.J. Cami, Luis E. Benavides, Maximo Jr. Rueda, Prof. Dr. Tim-Nicolas Korf, Dr. Boris Scharlowsk, Eberhard Gro?mann, Magdalena Wei?, Gro?er Axel, Meyer-Szary Krystian, Morten Halkj?r, RASMUSSEN S?ren Balle
bs = [s for s in symbols if not (s.isalpha() or s in " . - ' ? ,")]
bs
Out: ['!', '"', '#', '&', '(', ')', '*', '+', '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', ';', '>', '@', '[', '\\', ']', '^', '_', '`', '|', '\x7f', '\xa0', '¤', '¦', '§', '', '«', '\xad', '', '°', '±', '¶', '·', '»', '–', '—', '‘', '’', '‚', '“', '”', '„', '†', '‡', '…', '‰', '›', '']
Wir werden alle diese Zeichen vorübergehend entfernen, um herauszufinden, wie viele Einträge vorhanden sind:for s in bs:
ar['name'] = ar['name'].str.replace(s, '')
corr = ar[ar['name'] != ar['name raw']]
Es gibt 2.184 solcher Datensätze, das sind nur 0,15% der Gesamtzahl - sehr wenige. Schauen wir uns 100 davon an:list(corr['name raw'].sample(100))
Out: ['Scha¶ffl, Ga?nter', 'Howard, Brian &', 'Chapiewski, Guilherme (Gc)', 'Derkach 1svd_mail_ru', 'Parker H1 Lauren', 'Leal le?n, Yaneri', 'TencA, David', 'Cortas La?pez, Alejandro', 'Strid, Bja¶rn', '(Crutchfield) Horan, Katie', 'Vigneron, Jean-Michel.Vigneron@gmail.Com', '\xa0', 'Telahr, J†rgen', 'St”rmer, Melanie', 'Nagai B1 Keiji', 'Rinc?n, Mariano', 'Arkalaki, Angela (Evangelia)', 'Barbaro B1 Bonin Anna G:Charlotte', 'Ra?esch, Ja¶rg', "CAVAZZI NICCOLO\\'", 'D„nzel, Thomas', 'Ziska, Steffen (Gerhard)', 'Kobilica B1 Alen', 'Mittelholcz, Bala', 'Jimanez Aguilar, Juan Antonio', 'Achenza H1 Giovanni', 'Reppe H2 Christiane', 'Filipovic B2 Lazar', 'Machuca Ka?hnel, Ruban Alejandro', 'Gellert (Silberprinz), Christian', 'Smith (Guide), Matt', 'Lenatz H1 Benjamin', 'Da¶llinger, Christian', 'Mc Carthy B1 Patrick Donnacha G:Bryan', 'Fa¶llmer, Chris', 'Warner (Rivera), Lisa', 'Wang, Ruijia (Ray)', 'Mc Carthy B1 Donnacha', 'Jones, Nige (Paddy)', 'Sch”ler, Christoph', '\xa0', 'Holthaus, Adelhard (Allard)', 'Mi;Arro, Ana', 'Dr: Koch Stefan', '\xa0', '\xa0', 'Ziska, Steffen (Gerhard)', 'Albarraca\xadn Gonza?lez, Juan Francisco', 'Ha¶fling, Imke', 'Johnston, Eddie (Edwin)', 'Mulcahy, Bob (James)', 'Gottschalk, Bj”rn', '\xa0', 'Gretsch H2 Kendall', 'Scorse, Christopher (Chris)', 'Kiel‚basa, Pawel', 'Kalan, Magnus', 'Roderick "eric" SIMBULAN', 'Russell;, Mark', 'ROPES AND GRAY TEAM 3', 'Andrade, H?¦CTOR DANIEL', 'Landmann H2 Joshua', 'Reyes Rodra\xadguez, Aithami', 'Ziska, Steffen (Gerhard)', 'Ziska, Steffen (Gerhard)', 'Heuza, Pierre', 'Snyder B1 Riley Brad G:Colin', 'Feldmann, Ja¶rg', 'Beveridge H1 Nic', 'FAGES`, perrine', 'Frank", Dieter', 'Saarema¤el, Indrek', 'Betancort Morales, Arida–y', 'Ridderberg, Marie_Louise', '\xa0', 'Ka¶nig, Johannes', 'W Van(der Klugt', 'Ziska, Steffen (Gerhard)', 'Johnson, Nick26', 'Heinz JOHNER03', 'Ga¶rg, Andra', 'Maruo B2 Atsuko', 'Moral Pedrero H1 Eva Maria', '\xa0', 'MATUS SANTIAGO Osc1r', 'Stenbrink, Bja¶rn', 'Wangkhan, Sm1.Thaworn', 'Pullerits, Ta¶nu', 'Clausner, 8588294149', 'Castro Miranda, Josa Ignacio', 'La¶fgren, Pontuz', 'Brown, Jann ( Janine )', 'Ziska, Steffen (Gerhard)', 'Koay, Sa¶ren', 'Ba¶hm, Heiko', 'Oleksiuk B2 Vita', 'G Van(de Grift', 'Scha¶neborn, Guido', 'Mandez, A?lvaro', 'Garca\xada Fla?rez, Daniel']
Nach langem Nachforschen wurde beschlossen, alle alphabetischen Zeichen sowie ein Leerzeichen, einen Bindestrich, einen Apostroph und ein Fragezeichen durch ein Komma, einen Punkt und ein Symbol '\ xa0' zu ersetzen und alle anderen Zeichen durch eine leere Zeichenfolge zu ersetzen. das heißt, einfach löschen.ar['name'] = ar['name raw']
for s in symbols:
if s.isalpha() or s in " - ? '":
continue
if s in ".,\xa0":
ar['name'] = ar['name'].str.replace(s, ' ')
else:
ar['name'] = ar['name'].str.replace(s, '')
Dann entfernen Sie zusätzliche Leerzeichen:ar['name'] = ar['name'].str.split().str.join(' ')
ar['name'] = ar['name'].str.strip()
Lass uns nachsehen, was passiert ist:ar.loc[corr.index].sample(10)
qmon = ar[(ar['name'].str.replace('?', '').str.strip() == '')&(ar['name']!='')]
Es gibt 3.429 davon. Es sieht ungefähr so aus: Unser Ziel, Namen auf den gleichen Standard zu bringen, ist es, dass dieselben Namen gleich aussehen, aber auf unterschiedliche Weise unterschiedlich sind. Bei Namen, die nur aus Fragezeichen bestehen, unterscheiden sie sich nur in der Anzahl der Zeichen. Dies gibt jedoch nicht die volle Sicherheit, dass Namen mit derselben Nummer wirklich gleich sind. Daher ersetzen wir sie alle durch eine leere Zeichenfolge und werden in Zukunft nicht mehr berücksichtigt.ar.loc[qmon.index, 'name'] = ''
Die Gesamtzahl der Einträge, bei denen der Name die leere Zeichenfolge ist, beträgt 3.454. Nicht so sehr - wir werden überleben. Nachdem wir unnötige Zeichen entfernt haben, können wir mit der Transliteration fortfahren. Um dies zu tun, bringen Sie zuerst alles in Kleinbuchstaben, um nicht doppelt zu arbeiten.ar['name'] = ar['name'].str.lower()
Erstellen Sie als Nächstes ein Wörterbuch:trans = {'':'a', '':'b', '':'v', '':'g', '':'d', '':'e', '':'e', '':'zh', '':'z', '':'i', '':'y', '':'k', '':'l', '':'m', '':'n', '':'o', '':'p', '':'r', '':'s', '':'t', '':'u', '':'f', '':'kh', '':'ts', '':'ch', '':'sh', '':'shch', '':'', '':'y', '':'', '':'e', '':'yu', '':'ya', 'є':'e', 'і': 'i','ў':'w','µ':'m'}
Es enthielt auch Buchstaben aus dem sogenannten erweiterten kyrillischen Alphabet - 'є', 'і', 'ў' , die in den belarussischen und ukrainischen Sprachen verwendet werden, sowie den griechischen Buchstaben 'µ' . Wenden Sie die Transformation an:for s in trans:
ar['name'] = ar['name'].str.replace(s, trans[s])
Aus dem funktionierenden Kleinbuchstaben übersetzen wir nun alles in das vertraute Format, wobei der Vor- und Nachname mit einem Großbuchstaben beginnt:ar['name'] = ar['name'].str.title()
Lass uns nachsehen, was passiert ist.ar[ar['name raw'].str.lower().str[0].isin(trans.keys())].sample(10)
set( ''.join(ar['name'].unique()))
Out: [' ', "'", '-', '?', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J','K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
Alles ist richtig. Infolgedessen betrafen die Korrekturen 1.253.882 oder 89% der Datensätze. Die Anzahl der eindeutigen Namen verringerte sich von 660.207 auf 599.186, dh um 61.000 oder fast 10%. Beeindruckend! Speichern Sie in einer neuen Datei, nachdem Sie die Vereinigung der ar-Datensätze wieder in das rd- Protokollwörterbuch übersetzt haben .pkl.dump(rd, open(r'D:\tri\details4.pkl', 'wb'))
Jetzt müssen wir die Ordnung wiederherstellen. Das heißt, dass alle Datensätze wie folgt aussehen würden: Vorname Nachname oder Nachname Vorname . Welches ist zu bestimmen. Zwar enthalten einige Protokolle neben Vor- und Nachnamen auch Zweitnamen. Und es kann vorkommen, dass dieselbe Person in verschiedenen Protokollen unterschiedlich geschrieben ist - irgendwo mit einem zweiten Vornamen, irgendwo ohne. Dies beeinträchtigt seine Identifizierung. Versuchen Sie daher, den zweiten Vornamen zu entfernen. Patronymie für Männer hat normalerweise die Endung "hiv" und für Frauen "vna" . Es gibt jedoch Ausnahmen. Zum Beispiel - Ilyich, Ilyinichna, Nikitich, Nikitichna. Es stimmt, es gibt nur sehr wenige solcher Ausnahmen. Wie bereits erwähnt, kann das Format von Namen innerhalb eines Protokolls als permanent angesehen werden. Um Patronymie loszuwerden, müssen Sie daher die Rasse finden, in der sie vorhanden sind. Dazu finden die Gesamtzahl der Fragmente „vich“ und „vna“ in der Spalte Nameund vergleichen Sie sie mit der Gesamtzahl der Einträge in jedem Protokoll. Wenn diese Zahlen nahe beieinander liegen, gibt es einen zweiten Vornamen, andernfalls nicht. Es ist unvernünftig, nach einem strengen Spiel zu suchen, weil Selbst bei Rennen, bei denen beispielsweise Zweitnamen aufgezeichnet werden, können Ausländer teilnehmen, und sie werden ohne ihn aufgezeichnet. Es kommt auch vor, dass der Teilnehmer seinen zweiten Vornamen vergessen hat oder nicht angeben wollte. Andererseits gibt es auch Nachnamen, die auf "vich" enden, viele davon in Belarus und anderen Ländern mit den Sprachen der slawischen Gruppe. Außerdem haben wir Transliteration durchgeführt. Es war möglich, diese Analyse vor der Transliteration durchzuführen, aber dann besteht die Möglichkeit, dass ein Protokoll übersehen wird, in dem es Vornamen gibt, das jedoch zunächst bereits in lateinischer Sprache vorliegt. Also ist alles in Ordnung.Wir werden also nach allen Protokollen suchen, in denen die Anzahl der Fragmente "vich" und "vna" in der Spalte angegeben istDer Name macht mehr als 50% der Gesamtzahl der Einträge im Protokoll aus.wp = {}
for e in rd:
nvich = (''.join(rd[e]['name'])).count('vich')
nvna = (''.join(rd[e]['name'])).count('vna')
if nvich + nvna > 0.5*len(rd[e]):
wp[e] = rd[e]
Es gibt 29 solcher Protokolle. Eines davon ist: Und es ist interessant, dass wenn sich anstelle von 50% 20% oder umgekehrt 70% nehmen, sich das Ergebnis nicht ändert, es das gleiche 29 gibt. Also haben wir die richtige Wahl getroffen. Dementsprechend weniger als 20% - die Auswirkung von Nachnamen, mehr als 70% - die Auswirkung einzelner Datensätze ohne Zweitnamen. Nachdem das Land mit Hilfe eines Pivot-Tisches überprüft worden war, stellte sich heraus, dass 25 von ihnen in Russland und 4 in Abchasien waren. Weitermachen. Wir werden nur Datensätze mit drei Komponenten verarbeiten, dh solchen, bei denen (vermutlich) ein Nachname, ein Name oder ein zweiter Vorname vorhanden ist.sum_n3w = 0
sum_nnot3w = 0
for e in wp:
sum_n3w += len([n for n in wp[e]['name'] if len(n.split()) == 3])
sum_nnot3w += len(wp[e]) - n3w
Die Mehrheit dieser Aufzeichnungen liegt bei 86%. Nun diejenigen, in denen die drei Komponenten in die Spalten name0, name1, name2 unterteilt sind :for e in wp:
ind3 = [i for i in rd[e].index if len(rd[e].loc[i,'name'].split()) == 3]
rd[e]['name0'] = ''
rd[e]['name1'] = ''
rd[e]['name2'] = ''
rd[e].loc[ind3, 'name0'] = rd[e].loc[ind3,'name'].str.split().str[0]
rd[e].loc[ind3, 'name1'] = rd[e].loc[ind3,'name'].str.split().str[1]
rd[e].loc[ind3, 'name2'] = rd[e].loc[ind3,'name'].str.split().str[2]
So sieht eines der Protokolle aus: Insbesondere hier ist klar, dass die Aufzeichnung der beiden Komponenten nicht verarbeitet wurde. Jetzt müssen Sie für jedes Protokoll bestimmen, welche Spalte einen zweiten Vornamen hat. Es gibt nur zwei Optionen - Name1, Name2 , da dies nicht an erster Stelle stehen kann. Einmal festgelegt, werden wir einen neuen Namen bereits ohne ihn sammeln.for e in wp:
n1=(''.join(rd[e]['name1'])).count('vich')+(''.join(rd[e]['name1'])).count('vna')
n2=(''.join(rd[e]['name2'])).count('vich')+(''.join(rd[e]['name2'])).count('vna')
if (n1 > n2):
rd[e]['new name'] = rd[e]['name0'] + ' ' + rd[e]['name2']
else:
rd[e]['new name'] = rd[e]['name0'] + ' ' + rd[e]['name1']
for e in wp:
ind = rd[e][rd[e]['new name'].str.strip() != ''].index
rd[e].loc[ind, 'name'] = rd[e].loc[ind, 'new name']
rd[e] = rd[e].drop(columns = ['name0','name1','name2','new name'])
pkl.dump(rd, open(r'D:\tri\details5.pkl', 'wb'))
Jetzt müssen Sie die Namen in die gleiche Reihenfolge bringen. Das heißt, es ist erforderlich, dass in allen Protokollen der Name zuerst gefolgt vom Nachnamen oder umgekehrt - zuerst der Nachname, dann der Vorname, auch in allen Protokollen. Kommt darauf an was mehr, jetzt werden wir es herausfinden. Die Situation wird etwas kompliziert durch die Tatsache, dass der vollständige Name aus mehr als zwei Wörtern bestehen kann, selbst nachdem wir den zweiten Vornamen entfernt haben.ar['nwin'] = ar['name'].str.count(' ') + 1
ar.loc[ar['name'] == '','nwin'] = 0
100*ar['nwin'].value_counts()/len(ar)
Anzahl der Wörter in einem Namen Anzahl der Datensätze Anteil der Datensätze (%) Natürlich besteht die überwiegende Mehrheit (91%) aus zwei Wörtern - nur einem Namen und einem Nachnamen. Es gibt aber auch sehr viele Einträge mit drei und vier Wörtern. Schauen wir uns die Nationalität solcher Aufzeichnungen an:ar[ar['nwin'] >= 3]['country'].value_counts()[:12]
Out:
ESP 28435
MEX 10561
USA 7608
DNK 7178
BRA 6321
NLD 5748
DEU 4310
PHL 3941
ZAF 3862
ITA 3691
BEL 3596
FRA 3323
Nun, an erster Stelle steht Spanien, an zweiter Stelle - Mexiko, ein hispanisches Land, weiter als die Vereinigten Staaten, wo es auch historisch viele Hispanics gibt. Brasilien und die Philippinen sind ebenfalls spanische (und portugiesische) Namen. Dänemark, die Niederlande, Deutschland, Südafrika, Italien, Belgien und Frankreich sind eine andere Sache. Manchmal kommt dem Nachnamen einfach eine Art Präfix vor, daher gibt es mehr als zwei Wörter. In all diesen Fällen besteht der Name jedoch normalerweise aus einem Wort und der Nachname aus zwei, drei. Natürlich gibt es Ausnahmen von dieser Regel, aber wir werden sie nicht mehr verarbeiten. Zunächst müssen Sie für jedes Protokoll bestimmen, welche Art von Reihenfolge es gibt: Name-Nachname oder umgekehrt. Wie kann man das machen? Die folgende Idee kam mir: Erstens ist die Vielfalt der Nachnamen normalerweise viel größer als die Vielfalt der Namen. Dies sollte auch im Rahmen eines Protokolls der Fall sein. Zweitens,Die Länge des Namens ist normalerweise kleiner als die Länge des Nachnamens (auch bei nicht zusammengesetzten Nachnamen). Wir werden eine Kombination dieser Kriterien verwenden, um die vorläufige Bestellung zu bestimmen.Wählen Sie das erste und das letzte Wort im vollständigen Namen aus:ar['new name'] = ar['name']
ind = ar[ar['nwin'] < 2].index
ar.loc[ind, 'new name'] = '. .'
ar['wfin'] = ar['new name'].str.split().str[0]
ar['lwin'] = ar['new name'].str.split().str[-1]
Konvertieren Sie den kombinierten ar- Datenrahmen zurück in das rd- Wörterbuch, sodass die neuen Spalten nwin, ns0, ns in den Datenrahmen jedes Rennens fallen. Als nächstes bestimmen wir die Anzahl der Protokolle mit der Reihenfolge „Vorname Nachname“ und die Anzahl der Protokolle mit der umgekehrten Reihenfolge gemäß unserem Kriterium. Wir werden nur Einträge betrachten, bei denen der vollständige Name aus zwei Wörtern besteht. Speichern Sie gleichzeitig den Namen (Vornamen) in einer neuen Spalte:name_surname = {}
surname_name = {}
for e in rd:
d = rd[e][rd[e]['nwin'] == 2]
if len(d['fwin'].unique()) < len(d['lwin'].unique()) and len(''.join(d['fwin'])) < len(''.join(d['lwin'])):
name_surname[e] = d
rd[e]['first name'] = rd[e]['fwin']
if len(d['fwin'].unique()) > len(d['lwin'].unique()) and len(''.join(d['fwin'])) > len(''.join(d['lwin'])):
surname_name[e] = d
rd[e]['first name'] = rd[e]['lwin']
Es stellte sich Folgendes heraus: die Reihenfolge Vorname Nachname - 244 Protokolle, die Reihenfolge Nachname Vorname - 1.508 Protokolle.Dementsprechend werden wir zu dem Format führen, das üblicher ist. Es stellte sich heraus, dass die Summe geringer war als der Gesamtbetrag, da wir gleichzeitig und mit strikter Ungleichheit die Erfüllung von zwei Kriterien überprüft haben. Es gibt Protokolle, in denen nur eines der Kriterien erfüllt ist oder vielleicht, aber es ist unwahrscheinlich, dass Gleichheit auftritt. Dies ist jedoch völlig unwichtig, da das Format definiert ist.Unter der Annahme, dass wir die Reihenfolge mit ausreichend hoher Genauigkeit bestimmt haben, ohne zu vergessen, dass sie nicht 100% genau ist, werden wir diese Informationen verwenden. Suchen Sie die beliebtesten Namen in der Spalte mit den Vornamen :vc = ar['first name'].value_counts()
Nehmen Sie diejenigen, die sich mehr als hundert Mal getroffen haben:pfn=vc[vc>100]
Es gab 1.673 von ihnen. Hier sind die ersten hundert von ihnen, in absteigender Reihenfolge der Beliebtheit angeordnet: Anhand dieser Liste werden wir nun alle Protokolle durchgehen und vergleichen, wo es mehr Übereinstimmungen gibt - im ersten Wort des Namens oder im letzten. Wir werden nur Namen mit zwei Wörtern betrachten. Wenn es mehr Übereinstimmungen mit dem letzten Wort gibt, ist die Reihenfolge korrekt, wenn mit dem ersten das Gegenteil der Fall ist. Und hier sind wir sicherer, das heißt, Sie können dieses Wissen nutzen, und wir werden mit jedem Durchgang eine Liste der Namen ihres nächsten Protokolls zur anfänglichen Liste der populären Namen hinzufügen. Wir sortieren die Protokolle nach der Häufigkeit des Auftretens von Namen aus der Anfangsliste vor, um zufällige Fehler zu vermeiden, und erstellen eine umfangreichere Liste für die Protokolle, bei denen es nur wenige Übereinstimmungen gibt und die gegen Ende des Zyklus verarbeitet werden.['Michael', 'David', 'Thomas', 'John', 'Daniel', 'Mark', 'Peter', 'Paul', 'Christian', 'Robert', 'Martin', 'James', 'Andrew', 'Chris', 'Richard', 'Andreas', 'Matthew', 'Brian', 'Patrick', 'Scott', 'Kevin', 'Stefan', 'Jason', 'Eric', 'Christopher', 'Alexander', 'Simon', 'Mike', 'Tim', 'Frank', 'Stephen', 'Steve', 'Andrea', 'Jonathan', 'Markus', 'Marco', 'Adam', 'Ryan', 'Jan', 'Tom', 'Marc', 'Carlos', 'Jennifer', 'Matt', 'Steven', 'Jeff', 'Sergey', 'William', 'Aleksandr', 'Sarah', 'Alex', 'Jose', 'Andrey', 'Benjamin', 'Sebastian', 'Ian', 'Anthony', 'Ben', 'Oliver', 'Antonio', 'Ivan', 'Sean', 'Manuel', 'Matthias', 'Nicolas', 'Dan', 'Craig', 'Dmitriy', 'Laura', 'Luis', 'Lisa', 'Kim', 'Anna', 'Nick', 'Rob', 'Maria', 'Greg', 'Aleksey', 'Javier', 'Michelle', 'Andre', 'Mario', 'Joseph', 'Christoph', 'Justin', 'Jim', 'Gary', 'Erik', 'Andy', 'Joe', 'Alberto', 'Roberto', 'Jens', 'Tobias', 'Lee', 'Nicholas', 'Dave', 'Tony', 'Olivier', 'Philippe']
sbpn = pd.DataFrame(columns = ['event', 'num pop names'], index=range(len(rd)))
for i in range(len(rd)):
e = list(rd.keys())[i]
sbpn.loc[i, 'event'] = e
sbpn.loc[i, 'num pop names'] = len(set(pfn).intersection(rd[e]['first name']))
sbnp=sbnp.sort_values(by = 'num pop names',ascending=False)
sbnp = sbnp.reset_index(drop=True)
tofix = []
for i in range(len(rd)):
e = sbpn.loc[i, 'event']
if len(set(list(rd[e]['fwin'])).intersection(pfn)) > len(set(list(rd[e]['lwin'])).intersection(pfn)):
tofix.append(e)
pfn = list(set(pfn + list(rd[e]['fwin'])))
else:
pfn = list(set(pfn + list(rd[e]['lwin'])))
Es gab 235 Protokolle. Das ist ungefähr das Gleiche wie in erster Näherung (244). Um sicherzugehen, habe ich mir die ersten drei Datensätze von jedem selektiv angesehen und sichergestellt, dass alles korrekt war. Prüfen Sie auch , dass die erste Stufe der Sortier gab 36 falsche Einträge aus der Klasse Namen Nachnamen und 2 falsch aus Class Namen Namen . Ich habe mir die ersten drei Platten von jeder angesehen, tatsächlich hat die zweite Stufe perfekt funktioniert. Nun müssen tatsächlich die Protokolle repariert werden, bei denen die falsche Reihenfolge gefunden wird:for e in tofix:
ind = rd[e][rd[e]['nwin'] > 1].index
rd[e].loc[ind,'name'] = rd[e].loc[ind,'name'].str.split(n=1).str[1] + ' ' + rd[e].loc[ind,'name'].str.split(n=1).str[0]
Hier in der Aufteilung haben wir die Anzahl der Teile mit dem Parameter n begrenzt . Die Logik lautet wie folgt: Ein Name ist ein Wort, das erste in einem vollständigen Namen. Alles andere ist ein Nachname (kann aus mehreren Wörtern bestehen). Tauschen Sie sie einfach aus.Jetzt werden unnötige Spalten entfernt und gespeichert:for e in rd:
rd[e] = rd[e].drop(columns = ['new name', 'first name', 'fwin','lwin', 'nwin'])
pkl.dump(rd, open(r'D:\tri\details6.pkl', 'wb'))
Überprüfen Sie das Ergebnis. Ein zufälliges Dutzend fester Datensätze: Insgesamt wurden 108.000 Datensätze repariert. Die Anzahl der eindeutigen vollständigen Namen verringerte sich von 598 auf 547 Tausend. Fein! Mit der Formatierung fertig.Teil 3. Wiederherstellung unvollständiger Daten
Fahren Sie nun mit der Wiederherstellung der fehlenden Daten fort. Und es gibt solche.Land
Beginnen wir mit dem Land. Finden Sie alle Datensätze, in denen das Land nicht angegeben ist:arnc = ar[ar['country'] == '']
Es gibt 3.221 von ihnen. Hier sind 10 zufällige:nnc = arnc['name'].unique()
Die Anzahl der eindeutigen Namen unter Datensätzen ohne Land beträgt 3 051. Mal sehen, ob diese Anzahl reduziert werden kann.Tatsache ist, dass sich die Leute beim Triathlon selten auf nur ein Rennen beschränken, sondern in der Regel regelmäßig, mehrmals pro Saison, von Jahr zu Jahr an Wettbewerben teilnehmen und ständig trainieren. Daher gibt es für viele Namen in den Daten höchstwahrscheinlich mehr als einen Datensatz. Versuchen Sie zum Wiederherstellen von Informationen über das Land, Datensätze mit demselben Namen unter den Datensätzen zu finden, in denen das Land angegeben ist.arwc = ar[ar['country'] != '']
nwc = arwc['name'].unique()
tofix = set(nnc).intersection(nwc)
Out: ['Kleber-Schad Ute Cathrin', 'Sellner Peter', 'Pfeiffer Christian', 'Scholl Thomas', 'Petersohn Sandra', 'Marchand Kurt', 'Janneck Britta', 'Angheben Riccardo', 'Thiele Yvonne', 'Kie?Wetter Martin', 'Schymik Gerhard', 'Clark Donald', 'Berod Brigitte', 'Theile Markus', 'Giuliattini Burbui Margherita', 'Wehrum Alexander', 'Kenny Oisin', 'Schwieger Peter', 'Grosse Bianca', 'Schafter Carsten', 'Breck Dirk', 'Mautes Christoph', 'Herrmann Andreas', 'Gilbert Kai', 'Steger Peter', 'Jirouskova Jana', 'Jehrke Michael', 'Valentine David', 'Reis Michael', 'Wanka Michael', 'Schomburg Jonas', 'Giehl Caprice', 'Zinser Carsten', 'Schumann Marcus', 'Magoni Livio', 'Lauden Yann', 'Mayer Dieter', 'Krisa Stefan', 'Haberecht Bernd', 'Schneider Achim', 'Gibanel Curto Antonio', 'Miranda Antonio', 'Juarez Pedro', 'Prelle Gerrit', 'Wuste Kay', 'Bullock Graeme', 'Hahner Martin', 'Kahl Maik', 'Schubnell Frank', 'Hastenteufel Marco', …]
Es gab 2.236 von ihnen, das sind fast drei Viertel. Jetzt müssen Sie für jeden Namen aus dieser Liste das Land anhand der Datensätze bestimmen, in denen es sich befindet. Es kommt jedoch vor, dass derselbe Name in mehreren Datensätzen und in verschiedenen Ländern vorkommt. Dies ist entweder der Namensvetter oder vielleicht die Person, die sich bewegt hat. Deshalb verarbeiten wir zuerst diejenigen, bei denen alles einzigartig ist.fix = {}
for n in tofix:
nr = arwc[arwc['name'] == n]
if len(nr['country'].unique()) == 1:
fix[n] = nr['country'].iloc[0]
In einer Schleife gemacht. Aber ehrlich gesagt klappt es schon lange - ungefähr drei Minuten. Wenn es eine Größenordnung mehr Einträge gäbe, müssten Sie wahrscheinlich eine Vektorimplementierung entwickeln. Es gab 2.013 Einträge oder 90% des Potenzials.Namen, für die verschiedene Länder in unterschiedlichen Datensätzen vorkommen können, beziehen sich auf das Land, das am häufigsten vorkommt.if n not in fix:
nr = arwc[arwc['name'] == n]
vc = nr['country'].value_counts()
if vc[0] > vc[1]:
fix[n] = vc.index[0]
So wurden Übereinstimmungen für 2.208 Namen oder 99% aller potenziellen Namen gefunden. Wir wenden diese Entsprechungen an:{'Kleber-Schad Ute Cathrin': 'DEU', 'Sellner Peter': 'AUT', 'Pfeiffer Christian': 'AUT', 'Scholl Thomas': 'DEU', 'Petersohn Sandra': 'DEU', 'Marchand Kurt': 'BEL', 'Janneck Britta': 'DEU', 'Angheben Riccardo': 'ITA', 'Thiele Yvonne': 'DEU', 'Kie?Wetter Martin': 'DEU', 'Clark Donald': 'GBR', 'Berod Brigitte': 'FRA', 'Theile Markus': 'DEU', 'Giuliattini Burbui Margherita': 'ITA', 'Wehrum Alexander': 'DEU', 'Kenny Oisin': 'IRL', 'Schwieger Peter': 'DEU', 'Schafter Carsten': 'DEU', 'Breck Dirk': 'DEU', 'Mautes Christoph': 'DEU', 'Herrmann Andreas': 'DEU', 'Gilbert Kai': 'DEU', 'Steger Peter': 'AUT', 'Jirouskova Jana': 'CZE', 'Jehrke Michael': 'DEU', 'Wanka Michael': 'DEU', 'Giehl Caprice': 'DEU', 'Zinser Carsten': 'DEU', 'Schumann Marcus': 'DEU', 'Magoni Livio': 'ITA', 'Lauden Yann': 'FRA', 'Mayer Dieter': 'DEU', 'Krisa Stefan': 'DEU', 'Haberecht Bernd': 'DEU', 'Schneider Achim': 'DEU', 'Gibanel Curto Antonio': 'ESP', 'Juarez Pedro': 'ESP', 'Prelle Gerrit': 'DEU', 'Wuste Kay': 'DEU', 'Bullock Graeme': 'GBR', 'Hahner Martin': 'DEU', 'Kahl Maik': 'DEU', 'Schubnell Frank': 'DEU', 'Hastenteufel Marco': 'DEU', 'Tedde Roberto': 'ITA', 'Minervini Domenico': 'ITA', 'Respondek Markus': 'DEU', 'Kramer Arne': 'DEU', 'Schreck Alex': 'DEU', 'Bichler Matthias': 'DEU', …}
for n in fix:
ind = arnc[arnc['name'] == n].index
ar.loc[ind, 'country'] = fix[n]
pkl.dump(rd, open(r'D:\tri\details7.pkl', 'wb'))
Fußboden
Wie in den Ländern gibt es Aufzeichnungen, in denen das Geschlecht des Teilnehmers nicht angegeben ist.ar[ar['sex'] == '']
Es gibt 2.538 von ihnen. Relativ wenige, aber wir werden wieder versuchen, noch weniger zu machen. Speichern Sie die ursprünglichen Werte in einer neuen Spalte.ar['sex raw'] =ar['sex']
Im Gegensatz zu Ländern, in denen wir Informationen namentlich aus anderen Protokollen abgerufen haben, ist hier alles etwas komplizierter. Tatsache ist, dass die Daten voller Fehler sind und es viele Namen (insgesamt 2 101) gibt, die mit Markierungen beider Geschlechter gefunden werden.arws = ar[(ar['sex'] != '')&(ar['name'] != '')]
snds = arws[arws.duplicated(subset='name',keep=False)]
snds = snds.drop_duplicates(subset=['name','sex'], keep = 'first')
snds = snds.sort_values(by='name')
snds = snds[snds.duplicated(subset = 'name', keep=False)]
snds
rss = [rd[e] for e in rd if len(rd[e][rd[e]['sex'] != '']['sex'].unique()) == 1]
Es gibt 633 von ihnen. Es scheint, dass dies durchaus möglich ist, nur ein Protokoll separat für Frauen, separat für Männer. Tatsache ist jedoch, dass fast alle diese Protokolle Altersgruppen beider Geschlechter enthalten (männliche Altersgruppen beginnen mit dem Buchstaben M , weiblich - mit dem Buchstaben F ). Beispiel: Der Name der Altersgruppe beginnt voraussichtlich mit dem Buchstaben M für Männer und dem Buchstaben F für Frauen. In den beiden vorherigen Beispielen trotz der Fehler in der Spalte Geschlecht'ITU World Cup Tiszaujvaros Olympic 2002'
Der Name der Gruppe schien das Geschlecht des Mitglieds immer noch richtig zu beschreiben. Anhand mehrerer Beispielbeispiele gehen wir davon aus, dass die Gruppe korrekt angegeben ist und das Geschlecht möglicherweise falsch angegeben ist. Suchen Sie alle Einträge, bei denen der erste Buchstabe im Gruppennamen nicht mit dem Geschlecht übereinstimmt. Wir werden den ursprünglichen Namen der Gruppengruppe roh nehmen , da während der Standardisierung viele Datensätze ohne Gruppe belassen wurden, aber jetzt nur noch den ersten Buchstaben benötigen, sodass der Standard nicht wichtig ist.ar['grflc'] = ar['group raw'].str.upper().str[0]
grncs = ar[(ar['grflc'].isin(['M','F']))&(ar['sex']!=ar['grflc'])]
Es gibt 26 161 solcher Aufzeichnungen. Korrigieren wir das Geschlecht entsprechend dem Namen der Altersgruppe:ar.loc[grncs.index, 'sex'] = grncs['grflc']
Schauen wir uns das Ergebnis an: Gut. Wie viele Datensätze sind jetzt ohne Geschlecht?ar[(ar['sex'] == '')&(ar['name'] != '')]
Es stellt sich genau eins heraus! Nun, die Gruppe ist nicht wirklich angegeben, aber anscheinend ist dies eine Frau. Emily ist ein weiblicher Name, außerdem ist diese Teilnehmerin (oder ihr Namensvetter) ein Jahr zuvor fertig geworden, und in diesem Protokoll sind Geschlecht und Gruppe angegeben. Hier manuell wiederherstellen * und weitermachen.ar.loc[arns.index, 'sex'] = 'F'
Jetzt sind alle Aufzeichnungen nach Geschlecht.* Im Allgemeinen ist es natürlich falsch, dies zu tun. Wenn sich bei wiederholten Durchläufen etwas in der Kette ändert, z. B. bei der Namenskonvertierung, gibt es möglicherweise mehr als einen Datensatz ohne Geschlecht, und nicht alle sind weiblich. Es tritt ein Fehler auf. Daher müssen Sie entweder eine umfangreiche Logik einfügen, um in anderen Protokollen nach einem Teilnehmer mit demselben Namen und Geschlecht zu suchen, z. B. um ein Land wiederherzustellen, und um es zu testen, oder um diese Logik nicht unnötig zu komplizieren, eine Überprüfung hinzuzufügen, dass nur ein Datensatz gefunden wird und der Name ist so und so, andernfalls wird eine Ausnahme ausgelöst, die den gesamten Laptop stoppt. Sie können eine Abweichung vom Plan feststellen und eingreifen.if len(arns) == 1 and arns['name'].iloc[0] == 'Stather Emily':
ar.loc[arns.index, 'sex'] = 'F'
else:
raise Exception('Different scenario!')
Es scheint, dass sich dies beruhigen kann. Tatsache ist jedoch, dass Korrekturen auf der Annahme beruhen, dass die Gruppe korrekt angegeben ist. Und tatsächlich ist es so. Fast immer. Fast. Trotzdem wurden versehentlich mehrere Inkonsistenzen festgestellt. Lassen Sie uns nun versuchen, alle zu ermitteln, gut oder so weit wie möglich. Wie bereits erwähnt, war es im ersten Beispiel genau die Tatsache, dass das Geschlecht aufgrund seiner eigenen Vorstellungen über männliche und weibliche Namen, die uns bewachten, nicht dem Namen entsprach.Finden Sie alle Namen in den männlichen und weiblichen Aufzeichnungen. Hier wird der Name als Name verstanden und nicht als vollständiger Name, dh ohne Nachnamen, was auf Englisch als Vorname bezeichnet wird .ar['fn'] = ar['name'].str.split().str[-1]
mfn = list(ar[ar['sex'] == 'M']['fn'].unique())
Insgesamt sind 32.508 männliche Namen aufgeführt. Hier sind die 50 beliebtesten:['Michael', 'David', 'Thomas', 'John', 'Daniel', 'Mark', 'Peter', 'Paul', 'Christian', 'Robert', 'Martin', 'James', 'Andrew', 'Chris', 'Richard', 'Andreas', 'Matthew', 'Brian', 'Kevin', 'Patrick', 'Scott', 'Stefan', 'Jason', 'Eric', 'Alexander', 'Christopher', 'Simon', 'Mike', 'Tim', 'Frank', 'Stephen', 'Steve', 'Jonathan', 'Marco', 'Markus', 'Adam', 'Ryan', 'Tom', 'Jan', 'Marc', 'Carlos', 'Matt', 'Steven', 'Jeff', 'Sergey', 'William', 'Aleksandr', 'Andrey', 'Benjamin', 'Jose']
ffn = list(ar[ar['sex'] == 'F']['fn'].unique())
Weniger Frauen - 14 423. Am beliebtesten: Gut, es scheint logisch auszusehen. Mal sehen, ob es Kreuzungen gibt.['Jennifer', 'Sarah', 'Laura', 'Lisa', 'Anna', 'Michelle', 'Maria', 'Andrea', 'Nicole', 'Jessica', 'Julie', 'Elizabeth', 'Stephanie', 'Karen', 'Christine', 'Amy', 'Rebecca', 'Susan', 'Rachel', 'Anne', 'Heather', 'Kelly', 'Barbara', 'Claudia', 'Amanda', 'Sandra', 'Julia', 'Lauren', 'Melissa', 'Emma', 'Sara', 'Katie', 'Melanie', 'Kim', 'Caroline', 'Erin', 'Kate', 'Linda', 'Mary', 'Alexandra', 'Christina', 'Emily', 'Angela', 'Catherine', 'Claire', 'Elena', 'Patricia', 'Charlotte', 'Megan', 'Daniela']
mffn = set(mfn).intersection(ffn)
Es gibt. Und es gibt 2.811 von ihnen. Schauen wir sie uns genauer an. Zunächst finden wir heraus, wie viele Datensätze diese Namen haben:armfn = ar[ar['fn'].isin(mffn)]
Es gibt 725 562. Das ist die Hälfte! Das ist erstaunlich! Es gibt fast 37.000 eindeutige Namen, aber die Hälfte der Datensätze hat insgesamt 2.800. Mal sehen, welche Namen am beliebtesten sind. Erstellen Sie dazu einen neuen Datenrahmen, in dem diese Namen Indizes sind:df = pd.DataFrame(armfn['fn'].value_counts())
df = df.rename(columns={'fn':'total'})
Wir berechnen, wie viele männliche und weibliche Datensätze mit jedem von ihnen.df['M'] = armfn[armfn['sex'] == 'M']['fn'].value_counts()
df['F'] = armfn[armfn['sex'] == 'F']['fn'].value_counts()
df.sort_values(by = 'F', ascending=False)
import gender_guesser.detector as gg
d = gg.Detector()
d.get_gender(u'Oleg')
Out: 'male'
d.get_gender(u'Evgeniya')
Out: 'female'
Alles ist in Ordnung. Aber wenn Sie den Namen Andrea überprüfen , dann gibt er auch weiblich aus , was nicht ganz richtig ist. Es stimmt, es gibt einen Ausweg. Wenn Sie sich die Eigenschaft names des Detektors ansehen , wird dort die gesamte Mehrdeutigkeit sichtbar.d.names['Andrea']
Out: {'female': ' 4 4 3 4788 64 579 34 1 7 ',
'mostly_female': '5 6 7 ',
'male': ' 7 '}
Ja, das heißt, get_gender bietet Ihnen nur die wahrscheinlichste Option, aber in Wirklichkeit kann es viel komplizierter sein. Überprüfen Sie andere Namen:d.names['Maria']
Out: {'female': '686 6 A 85986 A BA 3B98A75457 6 ',
'mostly_female': ' BBC A 678A9 '}
d.names['Oleg']
Out: {'male': ' 6 2 99894737 3 '}
Das heißt, die Liste der Namen für jeden Namen entspricht einem oder mehreren Schlüssel-Wert-Paaren, wobei der Schlüssel - es ist Geschlecht: männlich, WEIBLICH, meistens männlich, meistens weiblich, andy , und der Wert - die Liste der Werte des entsprechenden Landes: 1,2,3 ... .. 9ABC . Die Länder sind:d.COUNTRIES
Out: ['great_britain', 'ireland', 'usa', 'italy', 'malta', 'portugal', 'spain', 'france', 'belgium', 'luxembourg', 'the_netherlands', 'east_frisia', 'germany', 'austria', 'swiss', 'iceland', 'denmark', 'norway', 'sweden', 'finland', 'estonia', 'latvia', 'lithuania', 'poland', 'czech_republic', 'slovakia', 'hungary', 'romania', 'bulgaria', 'bosniaand', 'croatia', 'kosovo', 'macedonia', 'montenegro', 'serbia', 'slovenia', 'albania', 'greece', 'russia', 'belarus', 'moldova', 'ukraine', 'armenia', 'azerbaijan', 'georgia', 'the_stans', 'turkey', 'arabia', 'israel', 'china', 'india', 'japan', 'korea', 'vietnam', 'other_countries']
Ich habe nicht ganz verstanden, was die alphanumerischen Bedeutungen oder ihre Abwesenheit in der Liste konkret bedeuten. Dies war jedoch nicht wichtig, da ich mich darauf beschränkte, nur die Namen zu verwenden, die eine eindeutige Interpretation haben. Das heißt, für die es nur ein Schlüssel-Wert-Paar gibt und der Schlüssel entweder männlich oder weiblich ist . Schreiben Sie für jeden Namen aus unserem Datenrahmen die Interpretation des Gender-Guesser :df['sex from gg'] = ''
for n in df.index:
if n in list(d.names.keys()):
options = list(d.names[n].keys())
if len(options) == 1 and options[0] == 'male':
df.loc[n, 'sex from gg'] = 'M'
if len(options) == 1 and options[0] == 'female':
df.loc[n, 'sex from gg'] = 'F'
Es stellte sich heraus, 1.150 Namen. Hier sind die beliebtesten, die bereits oben besprochen wurden: Nun, nicht schlecht. Wenden Sie diese Logik nun auf alle Datensätze an.all_names = ar['fn'].unique()
male_names = []
female_names = []
for n in all_names:
if n in list(d.names.keys()):
options = list(d.names[n].keys())
if len(options) == 1:
if options[0] == 'male':
male_names.append(n)
if options[0] == 'female':
female_names.append(n)
Gefunden 7 091 männliche Namen und 5 054 weibliche. Wenden Sie die Transformation an:tofixm = ar[ar['fn'].isin(male_names)]
ar.loc[tofixm.index, 'sex'] = 'M'
tofixf = ar[ar['fn'].isin(female_names)]
ar.loc[tofixf.index, 'sex'] = 'F'
Wir schauen uns das Ergebnis an:ar[ar['sex']!=ar['sex raw']]
30.352 Einträge korrigiert (zusammen mit der Korrektur durch den Namen der Gruppe). Wie üblich 10 zufällige: Nachdem wir sicher sind, dass wir das Geschlecht korrekt identifiziert haben, werden wir auch Standardgruppen in Einklang bringen. Mal sehen, wo sie nicht übereinstimmen:ar['gfl'] = ar['group'].str[0]
gncws = ar[(ar['sex'] != ar['gfl']) & (ar['group']!='')]
4.248 Einträge. Ersetzen Sie den ersten Buchstaben:ar.loc[gncws.index, 'group'] = ar.loc[gncws.index, 'sex'] + ar.loc[gncws.index, 'group'].str[1:].index, 'sex']
pkl.dump(rd, open(r'D:\tri\details8.pkl', 'wb'))
Das ist alles mit der Wiederherstellung unvollständiger Daten.Bulletin Update
Die Übersichtstabelle muss noch mit aktualisierten Daten zur Anzahl der Männer und Frauen usw. aktualisiert werden.rs['total raw'] = rs['total']
rs['males raw'] = rs['males']
rs['females raw'] = rs['females']
rs['rus raw'] = rs['rus']
for i in rs.index:
e = rs.loc[i,'event']
rs.loc[i,'total'] = len(rd[e])
rs.loc[i,'males'] = len(rd[e][rd[e]['sex'] == 'M'])
rs.loc[i,'females'] = len(rd[e][rd[e]['sex'] == 'F'])
rs.loc[i,'rus'] = len(rd[e][rd[e]['country'] == 'RUS'])
len(rs[rs['total'] != rs['total raw']])
Out: 288
len(rs[rs['males'] != rs['males raw']])
Out:962
len(rs[rs['females'] != rs['females raw']])
Out: 836
len(rs[rs['rus'] != rs['rus raw']])
Out: 8
pkl.dump(rs, open(r'D:\tri\summary6.pkl', 'wb'))
Teil 4. Probenahme
Jetzt ist der Triathlon sehr beliebt. Während der Saison gibt es viele offene Wettkämpfe, an denen eine große Anzahl von Athleten, hauptsächlich Amateure, teilnehmen. Das war aber nicht immer so. Unsere Daten enthalten seit 1990 Aufzeichnungen. Beim Durchblättern von tristats.ru habe ich festgestellt, dass es in den letzten Jahren viel mehr Rennen gibt und in den ersten nur sehr wenige. Aber jetzt, da unsere Daten vorbereitet wurden, können Sie sie genauer betrachten.Zehn Jahre
Zählen Sie die Anzahl der Rennen und Finisher pro Jahr:rs['year'] = pd.DatetimeIndex(rs['date']).year
years = range(rs['year'].min(),rs['year'].max())
rsy = pd.DataFrame(columns = ['races', 'finishers', 'rus', 'RUS'], index = years)
for y in rsy.index:
rsy.loc[y,'races'] = len(rs[rs['year'] == y])
rsy.loc[y,'finishers'] = sum(rs[rs['year'] == y]['total'])
rsy.loc[y,'rus'] = sum(rs[rs['year'] == y]['rus'])
rsy.loc[y,'RUS'] = len(rs[(rs['year'] == y)&(rs['country'] == 'RUS')])
 Es ist ersichtlich, dass die Anzahl der Rennen und Teilnehmer zu Beginn und am Ende des Zeitraums einfach nicht vergleichbar ist. Ein deutlicher Anstieg der Gesamtzahl der Rennen beginnt im Jahr 2011, während die Anzahl der Starts in Russland ebenfalls zunimmt. Darüber hinaus ist bereits 2009 ein Anstieg der Teilnehmerzahl zu beobachten. Dies kann auf ein erhöhtes Interesse der Teilnehmer hinweisen, dh auf eine erhöhte Nachfrage, wonach zwei Jahre später das Angebot, dh die Anzahl der Starts, zunahm. Vergessen Sie jedoch nicht, dass die Daten möglicherweise nicht vollständig sind und einige und möglicherweise viele Rennen fehlen. Einschließlich aufgrund der Tatsache, dass das Projekt zur Erfassung dieser Daten erst im Jahr 2010 begann, was auch den bedeutenden Sprung in der Grafik in diesem Moment erklären kann. Daher habe ich mich zur weiteren Analyse entschlossen, die letzten 10 Jahre zu nehmen. Dies ist eine ziemlich lange Zeit,Um Trends über mehrere Jahre hinweg zu verfolgen, obwohl sie kurz genug sind, um nicht dorthin zu gelangen, hauptsächlich professionelle Wettbewerbe aus den 90er und frühen 2000er Jahren.
Es ist ersichtlich, dass die Anzahl der Rennen und Teilnehmer zu Beginn und am Ende des Zeitraums einfach nicht vergleichbar ist. Ein deutlicher Anstieg der Gesamtzahl der Rennen beginnt im Jahr 2011, während die Anzahl der Starts in Russland ebenfalls zunimmt. Darüber hinaus ist bereits 2009 ein Anstieg der Teilnehmerzahl zu beobachten. Dies kann auf ein erhöhtes Interesse der Teilnehmer hinweisen, dh auf eine erhöhte Nachfrage, wonach zwei Jahre später das Angebot, dh die Anzahl der Starts, zunahm. Vergessen Sie jedoch nicht, dass die Daten möglicherweise nicht vollständig sind und einige und möglicherweise viele Rennen fehlen. Einschließlich aufgrund der Tatsache, dass das Projekt zur Erfassung dieser Daten erst im Jahr 2010 begann, was auch den bedeutenden Sprung in der Grafik in diesem Moment erklären kann. Daher habe ich mich zur weiteren Analyse entschlossen, die letzten 10 Jahre zu nehmen. Dies ist eine ziemlich lange Zeit,Um Trends über mehrere Jahre hinweg zu verfolgen, obwohl sie kurz genug sind, um nicht dorthin zu gelangen, hauptsächlich professionelle Wettbewerbe aus den 90er und frühen 2000er Jahren.rs = rs[(rs['year']>=2010)&(rs['year']<= 2019)]
 Im ausgewählten Zeitraum fielen übrigens 84% der Rennen und 94% der Finisher.
Im ausgewählten Zeitraum fielen übrigens 84% der Rennen und 94% der Finisher.Amateur startet
Die überwiegende Mehrheit der Teilnehmer an den ausgewählten Starts sind Amateursportler, sodass gute Statistiken von ihnen erhalten werden können. Ehrlich gesagt war dies für mich von größtem Interesse, da ich selbst an solchen Starts teilnehme, aber im Level ist es sehr weit von den Olympiasiegern entfernt. Im ausgewählten Zeitraum fanden natürlich auch professionelle Wettbewerbe statt. Um die Indikatoren für Amateur- und Profirennen nicht zu mischen, wurde beschlossen, letztere nicht mehr zu berücksichtigen. Wie identifiziere ich sie? Nach Geschwindigkeit. Wir berechnen sie. In einer der ersten Phasen der Datenaufbereitung haben wir bereits festgestellt, welche Art von Distanz bei jedem Rennen vorhanden ist - Sprint, Olympia, Halb, Eisen. Für jeden von ihnen ist der Kilometerstand der Etappen klar definiert - Schwimmen, Radfahren und Laufen. Dies sind 0,75 + 20 + 5 für den Sprint, 1,5 + 40 + 10 für die Olympischen Spiele, 1,9 + 90 + 21,1 für die Hälfte und 3.8 + 180 + 42,2 für Eisen. Natürlich können die realen Zahlen für jeden Typ von Rennen zu Rennen bedingt bis zu einem Prozent variieren, aber es gibt keine Informationen darüber, daher gehen wir davon aus, dass alles korrekt war.rs['km'] = ''
rs.loc[rs['dist'] == 'sprint', 'km'] = 0.75+20+5
rs.loc[rs['dist'] == 'olympic', 'km'] = 1.5+40+10
rs.loc[rs['dist'] == 'half', 'km'] = 1.9+90+21.1
rs.loc[rs['dist'] == 'full', 'km'] = 3.8+180+42.2
Wir berechnen die Durchschnitts- und Höchstgeschwindigkeit für jedes Rennen. Das Maximum bezieht sich hier auf die Durchschnittsgeschwindigkeit des Athleten, der den ersten Platz gewonnen hat.for index, row in rs.iterrows():
e = row['event']
rd[e]['th'] = pd.TimedeltaIndex(rd[e]['result']).seconds/3600
rd[e]['v'] = rs.loc[i, 'km'] / rd[e]['th']
for index, row in rs.iterrows():
e = row['event']
rs.loc[index,'vmax'] = rd[e]['v'].max()
rs.loc[index,'vavg'] = rd[e]['v'].mean()
 Nun, Sie können sehen, dass der Großteil der Geschwindigkeiten in Haufen zwischen etwa 15 km / h und 30 km / h gesammelt wird, aber es gibt eine bestimmte Anzahl vollständig "kosmischer" Werte. Sortieren Sie nach Durchschnittsgeschwindigkeit und sehen Sie, wie viele davon:
Nun, Sie können sehen, dass der Großteil der Geschwindigkeiten in Haufen zwischen etwa 15 km / h und 30 km / h gesammelt wird, aber es gibt eine bestimmte Anzahl vollständig "kosmischer" Werte. Sortieren Sie nach Durchschnittsgeschwindigkeit und sehen Sie, wie viele davon:rs = rs.sort_values(by='vavg')
 Hier haben wir die Skala geändert und können den Bereich genauer abschätzen. Bei Durchschnittsgeschwindigkeiten liegt sie zwischen 17 km / h und 27 km / h, bei Höchstgeschwindigkeiten zwischen 18 km / h und 32 km / h. Außerdem gibt es „Schwänze“ mit sehr niedrigen und sehr hohen Durchschnittsgeschwindigkeiten. Niedrige Geschwindigkeiten entsprechen höchstwahrscheinlich extremen Wettkämpfen wie Norseman , und hohe Geschwindigkeiten können im Fall eines abgebrochenen Schwimmens auftreten, bei dem anstelle eines Sprints ein Supersprint stattfand oder einfach fehlerhafte Daten. Ein weiterer wichtiger Punkt ist der sanfte Schritt im 1200- Bereich entlang der X- Achseund höhere Werte der Durchschnittsgeschwindigkeit danach. Dort sehen Sie einen deutlich geringeren Unterschied zwischen Durchschnitts- und Höchstgeschwindigkeit als in den ersten zwei Dritteln des Diagramms. Anscheinend ist dies ein professioneller Wettbewerb. Um sie klarer zu unterscheiden, berechnen wir das Verhältnis von Höchstgeschwindigkeit zu Durchschnitt. Bei professionellen Wettbewerben, bei denen es keine zufälligen Personen gibt und alle Teilnehmer eine sehr hohe körperliche Fitness haben, sollte dieses Verhältnis minimal sein.
Hier haben wir die Skala geändert und können den Bereich genauer abschätzen. Bei Durchschnittsgeschwindigkeiten liegt sie zwischen 17 km / h und 27 km / h, bei Höchstgeschwindigkeiten zwischen 18 km / h und 32 km / h. Außerdem gibt es „Schwänze“ mit sehr niedrigen und sehr hohen Durchschnittsgeschwindigkeiten. Niedrige Geschwindigkeiten entsprechen höchstwahrscheinlich extremen Wettkämpfen wie Norseman , und hohe Geschwindigkeiten können im Fall eines abgebrochenen Schwimmens auftreten, bei dem anstelle eines Sprints ein Supersprint stattfand oder einfach fehlerhafte Daten. Ein weiterer wichtiger Punkt ist der sanfte Schritt im 1200- Bereich entlang der X- Achseund höhere Werte der Durchschnittsgeschwindigkeit danach. Dort sehen Sie einen deutlich geringeren Unterschied zwischen Durchschnitts- und Höchstgeschwindigkeit als in den ersten zwei Dritteln des Diagramms. Anscheinend ist dies ein professioneller Wettbewerb. Um sie klarer zu unterscheiden, berechnen wir das Verhältnis von Höchstgeschwindigkeit zu Durchschnitt. Bei professionellen Wettbewerben, bei denen es keine zufälligen Personen gibt und alle Teilnehmer eine sehr hohe körperliche Fitness haben, sollte dieses Verhältnis minimal sein.rs['vmdbva'] = rs['vmax']/rs['vavg']
rs = rs.sort_values(by='vmdbva')
 In dieser Grafik fällt das erste Quartal sehr deutlich auf: Das Verhältnis von Höchstgeschwindigkeit zu Durchschnitt ist klein, hohe Durchschnittsgeschwindigkeit, eine kleine Anzahl von Teilnehmern. Dies ist ein professioneller Wettbewerb. Der Schritt auf der grünen Kurve liegt irgendwo bei 1,2. Wir werden in unserer Stichprobe nur Datensätze mit einem Verhältniswert größer als 1,2 belassen.
In dieser Grafik fällt das erste Quartal sehr deutlich auf: Das Verhältnis von Höchstgeschwindigkeit zu Durchschnitt ist klein, hohe Durchschnittsgeschwindigkeit, eine kleine Anzahl von Teilnehmern. Dies ist ein professioneller Wettbewerb. Der Schritt auf der grünen Kurve liegt irgendwo bei 1,2. Wir werden in unserer Stichprobe nur Datensätze mit einem Verhältniswert größer als 1,2 belassen.rs = rs[rs['vmdbva'] > 1.2]
Wir entfernen auch Datensätze mit atypisch niedrigen und hohen Geschwindigkeiten. In Was sind die Triathlon-Weltrekorde für jede Distanz? veröffentlichte Rekordzeiten für das Überqueren verschiedener Entfernungen für 2019. Wenn Sie sie mit mittlerer Geschwindigkeit zählen, können Sie sehen, dass sie selbst für die schnellsten nicht höher als 33 km / h sein kann. Daher werden wir die Protokolle berücksichtigen, bei denen die Durchschnittsgeschwindigkeiten höher und ungültig sind, und sie aus der Betrachtung entfernen.rs = rs[(rs['vavg'] > 17)&(rs['vmax'] < 33)]
Folgendes bleibt:
 Jetzt sieht alles ziemlich homogen aus und wirft keine Fragen auf. Infolge all dieser Auswahl haben wir 777 der Protokolle von 1922 oder 40% verloren. Gleichzeitig ging die Gesamtzahl der Finisher nicht so stark zurück - nur um 13%.Es sind also noch 1.145 Rennen mit 1.231.772 Finishern übrig. Diese Probe wurde zum Material für meine Analyse und Visualisierung.
Jetzt sieht alles ziemlich homogen aus und wirft keine Fragen auf. Infolge all dieser Auswahl haben wir 777 der Protokolle von 1922 oder 40% verloren. Gleichzeitig ging die Gesamtzahl der Finisher nicht so stark zurück - nur um 13%.Es sind also noch 1.145 Rennen mit 1.231.772 Finishern übrig. Diese Probe wurde zum Material für meine Analyse und Visualisierung.Teil 5. Analyse und Visualisierung
In dieser Arbeit waren die eigentliche Analyse und Visualisierung die einfachsten Teile. Die Spitze des Eisbergs, dessen Unterwasserteil nur die Aufbereitung der Daten war. Die Analyse war in der Tat eine einfache arithmetische Operation für die Pandas-Reihe , Berechnung von Durchschnittswerten, Filterung - all dies wird von den elementaren Pandas- Werkzeugen durchgeführt, und der obige Code enthält viele Beispiele. Die Visualisierung erfolgte wiederum hauptsächlich mit der Standard-Matplotlib . Gebrauchte Handlung, Bar, Kuchen . An einigen Stellen musste ich jedoch bei Datumsangaben und Piktogrammen an den Signaturen der Achsen basteln, aber dies ist hier nicht eine detaillierte Beschreibung. Das einzige, worüber man sprechen sollte, ist die Präsentation von Geodaten. Zumindest ist es nichtmatplotlib .Geodaten
Für jedes Rennen haben wir Informationen über den Austragungsort. Zu Beginn haben wir mithilfe von Geopy die Koordinaten für jeden Standort berechnet. Viele Rennen finden jährlich am selben Ort statt. Ein sehr praktisches Werkzeug zum Rendern von Geodaten in Python ist Folium . So funktioniert das:import folium
m = folium.Map()
folium.Marker(['55.7522200', '37.6155600'], popup='').add_to(m)
Und wir erhalten eine interaktive Karte direkt im Jupiter-Laptop. Nun zu unseren Daten. Zunächst beginnen wir eine neue Spalte mit einer Kombination unserer Koordinaten:
Nun zu unseren Daten. Zunächst beginnen wir eine neue Spalte mit einer Kombination unserer Koordinaten:rs['coords'] = rs['latitude'].astype(str) + ', ' + rs['longitude'].astype(str)
Die einzigartigen Koordinaten Koordinaten sind 291. Und die einzigartigen Orte loc sind 324, was bedeutet , dass einige Namen geringfügig voneinander verschieden sind, während zur gleichen Zeit , die sie auf den gleichen Punkt entsprechen. Es ist nicht beängstigend, wir werden die Einzigartigkeit durch Koordinaten betrachten . Wir berechnen, wie viele Ereignisse über die gesamte Zeit an jedem Ort vergangen sind (mit eindeutigen Koordinaten):vc = rs['coords'].value_counts()
vc
Out:
43.7009358, 7.2683912 22
43.5854823, 39.723109 20
29.03970805, -13.636291 16
47.3723941, 8.5423328 16
59.3110918, 24.420907 15
51.0834196, 10.4234469 15
54.7585694, 38.8818137 14
20.4317585, -86.9202745 13
52.3727598, 4.8936041 12
41.6132925, 2.6576102 12
... ...
Erstellen Sie nun eine Karte und fügen Sie Markierungen in Form von Kreisen hinzu, deren Radius von der Anzahl der Ereignisse am Standort abhängt. Fügen Sie den Markierungen Markierungen mit Standortnamen hinzu.m = folium.Map(location=[25,10], zoom_start=2)
for c in rs['coords'].unique():
row = [r[1] for r in rs.iterrows() if r[1]['coords'] == c][0]
folium.Circle([row['latitude'], row['longitude']],
popup=(row['location']+'\n('+str(vc[c])+' races)'),
radius = 10000*int(vc[c]),
color='darkorange',
fill=True,
stroke=True,
weight=1).add_to(m)
Erledigt. Sie können das Ergebnis sehen:
Teilnehmer Fortschritt
Zusätzlich zur Anleitung war die Arbeit an einem weiteren Zeitplan nicht trivial. Dies ist das neueste Fortschrittsdiagramm der Teilnehmer. Hier ist es: Lassen Sie es uns analysieren, gleichzeitig werde ich den Code zum Rendern als Beispiel für die Verwendung von matplotlib geben :
Lassen Sie es uns analysieren, gleichzeitig werde ich den Code zum Rendern als Beispiel für die Verwendung von matplotlib geben :fig = plt.figure()
fig.set_size_inches(10, 6)
ax = fig.add_axes([0,0,1,1])
b = ax.bar(exp,numrecs, color = 'navajowhite')
ax1 = ax.twinx()
for i in range(len(exp_samp)):
ax1.plot(exp_samp[i], vproc_samp[i], '.')
p, = ax1.plot(exp, vpm, 'o-',markersize=8, linewidth=2, color='C0')
for i in range(len(exp)):
if i < len(exp)-1 and (vpm[i] < vpm[i+1]):
ax1.text(x = exp[i]+0.1, y = vpm[i]-0.2, s = '{0:3.1f}%'.format(vpm[i]),size=12)
else:
ax1.text(x = exp[i]+0.1, y = vpm[i]+0.1, s = '{0:3.1f}%'.format(vpm[i]),size=12)
ax.legend((b,p), (' ', ''),loc='center right')
ax.set_xlabel(' ')
ax.set_ylabel('')
ax1.set_ylabel('% ')
ax.set_xticks(np.arange(1, 11, step=1))
ax.set_yticks(np.arange(0, 230000, step=25000))
ax1.set_ylim(97.5,103.5)
ax.yaxis.set_label_position("right")
ax.yaxis.tick_right()
ax1.yaxis.set_label_position("left")
ax1.yaxis.tick_left()
plt.show()
Nun darüber, wie die Daten für ihn berechnet wurden. Zunächst mussten Sie die Namen der Teilnehmer auswählen, die mindestens zwei Rennen und in verschiedenen Kalenderjahren abgeschlossen haben und gleichzeitig keine Profis sind.Füllen Sie zunächst für jedes Protokoll eine neue Spalte mit dem Namen Datum aus , in der das Datum des Rennens angegeben ist. Wir werden auch ein Jahr ab diesem Zeitpunkt benötigen, werden wir die Säule machen Jahr . Da wir die Geschwindigkeit jedes Athleten im Verhältnis zur Durchschnittsgeschwindigkeit im Rennen analysieren werden, berechnen wir diese Geschwindigkeit sofort in der neuen Spalte vproc - die Geschwindigkeit als Prozentsatz des Durchschnitts.for index, row in rs.iterrows():
e = row['event']
rd[e]['date'] = row['date']
rd[e]['year'] = row['year']
rd[e]['vproc'] = 100 * rd[e]['v'] / rd[e]['v'].mean()
So sehen die Protokolle jetzt aus: Kombinieren Sie als Nächstes alle Protokolle in einem einzigen Datenrahmen.' Sprint 2019'ar = pd.concat(rd)
Für jeden Teilnehmer hinterlassen wir in jedem Kalenderjahr nur einen Eintrag:ar1 = ar.drop_duplicates(subset = ['name','year'], keep='first')
Als nächstes finden wir aus allen eindeutigen Namen dieser Einträge diejenigen, die mindestens zweimal vorkommen:nvc = ar1['name'].value_counts()
names = list(nvc[nvc > 1].index)
Es gibt 219.890 von ihnen. Entfernen wir die Namen von Profisportlern aus dieser Liste:pro_names = ar[ar['group'].isin(['MPRO','FPRO'])]['name'].unique()
names = list(set(names) - set(pro_names))
Sowie die Namen der Athleten, die vor 2010 mit dem Auftritt begonnen haben. Laden Sie dazu die Daten hoch, die vor der Stichprobe in den letzten 10 Jahren gespeichert wurden. Fügen Sie sie in die Objekte rsa ( Rassenübersicht alle) und rda ( Renndetails alle) ein.rdo = {}
for e in rda:
if rsa[rsa['event'] == e]['year'].iloc[0] < 2010:
rdo[e] = rda[e]
aro = pd.concat(rdo)
old_names = aro['name'].unique()
names = list(set(names) - set(old_names))
Und schließlich finden wir Namen, die mehr als einmal am selben Tag vorkommen. Daher minimieren wir das Vorhandensein vollständiger Namensvetter in unserer Stichprobe.namesakes = ar[ar.duplicated(subset = ['name','date'], keep = False)]['name'].unique()
names = list(set(names) - set(namesakes))
Es sind also noch 198.075 Namen übrig. Aus dem gesamten Datensatz wählen wir nur die Datensätze mit den gefundenen Namen aus:ars = ar[ar['name'].isin(names)]
Jetzt müssen Sie für jeden Rekord bestimmen, welchem Jahr in der Karriere des Athleten er entspricht - dem ersten, zweiten, dritten oder zehnten. Wir machen eine Schleife mit allen Namen und berechnen.ars['exp'] = ''
for n in names:
ind = ars[ars['name'] == n].index
yos = ars.loc[ind, 'year'].min()
ars.loc[ind, 'exp'] = ars.loc[ind, 'year'] - yos + 1
Hier ist ein Beispiel dafür, was passiert ist: Anscheinend sind die Namensvetter immer noch geblieben. Dies wird erwartet, ist aber nicht beängstigend, da wir alles mitteln werden und es nicht so viele geben sollte. Als nächstes erstellen wir Arrays für das Diagramm:exp = []
vpm = []
numrecs = []
for x in range(ars['exp'].min(), ars['exp'].max() + 1):
exp.append(x)
vpm.append(ars[ars['exp'] == x]['vproc'].mean())
numrecs.append(len(ars[ars['exp'] == x]))
Das war's, es gibt eine Basis: Um es nun mit Punkten zu dekorieren, die bestimmten Ergebnissen entsprechen, werden wir 1000 zufällige Namen auswählen und Arrays mit den Ergebnissen für sie erstellen.
Um es nun mit Punkten zu dekorieren, die bestimmten Ergebnissen entsprechen, werden wir 1000 zufällige Namen auswählen und Arrays mit den Ergebnissen für sie erstellen.names_samp = random.sample(names,1000)
ars_samp = ars[ars['name'].isin(names_samp)]
ars_samp = ars_samp.reset_index(drop = True)
exp_samp = []
vproc_samp = []
for n in names_samp:
nr = ars_samp[ars_samp['name'] == n]
nr = nr.sort_values('exp')
exp_samp.append(list(nr['exp']))
vproc_samp.append(list(nr['vproc']))
Fügen Sie eine Schleife hinzu, um Diagramme aus dieser Zufallsstichprobe zu erstellen.for i in range(len(exp_samp)):
ax1.plot(exp_samp[i], vproc_samp[i], '.')
Jetzt ist alles fertig: Im Allgemeinen ist es nicht schwierig. Es gibt jedoch ein Problem. Um die Exp- Erfahrung in einem Zyklus zu berechnen, benötigen alle Namen, die fast 200.000 sind, acht Stunden. Ich musste den Algorithmus für kleine Stichproben debuggen und dann die Berechnung für die Nacht ausführen. Im Prinzip kann dies einmal durchgeführt werden. Wenn Sie jedoch einen Fehler finden oder etwas ändern möchten und ihn erneut nachzählen müssen, beginnt er sich zu belasten. Als ich am Abend einen Bericht veröffentlichen wollte, stellte sich heraus, dass es wieder notwendig war, alles noch einmal zu erzählen. Das Warten bis zum Morgen war nicht Teil meiner Pläne, und ich suchte nach einer Möglichkeit, die Berechnung zu beschleunigen. Beschlossen zu parallelisieren.Ich habe irgendwo einen Weg gefunden, dies mit Multiprocessing zu tun. Um unter Windows arbeiten zu können, mussten wir die Hauptlogik jeder parallelen Aufgabe in einer separaten Datei worker.py ablegen :
Im Allgemeinen ist es nicht schwierig. Es gibt jedoch ein Problem. Um die Exp- Erfahrung in einem Zyklus zu berechnen, benötigen alle Namen, die fast 200.000 sind, acht Stunden. Ich musste den Algorithmus für kleine Stichproben debuggen und dann die Berechnung für die Nacht ausführen. Im Prinzip kann dies einmal durchgeführt werden. Wenn Sie jedoch einen Fehler finden oder etwas ändern möchten und ihn erneut nachzählen müssen, beginnt er sich zu belasten. Als ich am Abend einen Bericht veröffentlichen wollte, stellte sich heraus, dass es wieder notwendig war, alles noch einmal zu erzählen. Das Warten bis zum Morgen war nicht Teil meiner Pläne, und ich suchte nach einer Möglichkeit, die Berechnung zu beschleunigen. Beschlossen zu parallelisieren.Ich habe irgendwo einen Weg gefunden, dies mit Multiprocessing zu tun. Um unter Windows arbeiten zu können, mussten wir die Hauptlogik jeder parallelen Aufgabe in einer separaten Datei worker.py ablegen :import pickle as pkl
def worker(args):
names = args[0]
ars=args[1]
num=args[2]
ars = ars.sort_values(by='name')
ars = ars.reset_index(drop=True)
for n in names:
ind = ars[ars['name'] == n].index
yos = ars.loc[ind, 'year'].min()
ars.loc[ind, 'exp'] = ars.loc[ind, 'year'] - yos + 1
with open(r'D:\tri\par\prog' + str(num) + '.pkl', 'wb') as f:
pkl.dump(ars,f)
Das Verfahren auf einen Teil der Namen übertragen Namen , datafreyma Teil ar nur mit diesen Namen und die Seriennummer der parallelen Aufgaben - num . Berechnungen werden in den Datenrahmen geschrieben und am Ende wird der Datenrahmen in die Datei geschrieben. In dem Laptop, der diesen Worker aufruft , bereiten wir die Argumente entsprechend vor:num_proc = 8
args = []
for i in range(num_proc):
step = int(len(names_samp)/num_proc) + 1
names_i = names_samp[i*step:min((i+1)*step, len(names_samp))]
ars_i = ars[ars['name'].isin(names_i)]
args.append([names_i, ars_i, i])
Wir beginnen mit dem parallelen Rechnen:from multiprocessing import Pool
import workers
if __name__ == '__main__':
p=Pool(processes = num_proc)
p.map(workers.worker,args)
Und am Ende lesen wir die Ergebnisse aus den Dateien und sammeln die Teile wieder im gesamten Datenrahmen:ars=pd.DataFrame(columns = ars.columns)
for i in range(num_proc):
with open(r'D:\tri\par\prog'+str(i)+'.pkl', 'rb') as f:
arsi = pkl.load(f)
print(len(arsi))
ars = pd.concat([ars, arsi])
Somit war es möglich, eine Beschleunigung von 40 zu erhalten und anstelle von 8 Stunden die Berechnung in 11 Minuten abzuschließen und an diesem Abend einen Bericht zu veröffentlichen. Gleichzeitig habe ich gelernt, wie man in Python parallelisiert . Ich denke, das wird nützlich sein. Hier stellte sich heraus, dass die Beschleunigung mehr als das Achtfache der Anzahl der Kerne betrug, da für jede Aufgabe ein kleiner Datenrahmen verwendet wurde, was die Suche beschleunigt. Im Prinzip könnten sequentielle Berechnungen auf diese Weise beschleunigt werden, aber die Frage ist, wie raten Sie?Ich konnte mich jedoch nicht beruhigen und dachte auch nach der Veröffentlichung ständig darüber nach, wie die Berechnung mithilfe der Vektorisierung durchgeführt werden sollte, dh Operationen an ganzen Spalten des Datenrahmens der Pandas-Serie. Solche Berechnungen sind selbst auf einem Supercluster um eine Größenordnung schneller als alle parallelisierten Zyklen. Und kam mit. Es stellt sich heraus, dass es für jeden Namen im Gegenteil notwendig ist, das Jahr des Beginns einer Karriere zu finden - für jedes Jahr die Teilnehmer zu finden, die damit begonnen haben. Dazu müssen Sie zunächst alle Namen für das erste Jahr aus unserer Stichprobe ermitteln, dies ist 2010. Dementsprechend verarbeiten wir alle Datensätze mit diesen Namen in diesem Jahr. Als nächstes nehmen wir das nächste Jahr - 2011.Auch in diesem Jahr finden wir wieder alle Namen mit Einträgen, aber wir nehmen nur unverarbeitete Namen von ihnen, dh diejenigen, die 2010 nicht erfüllt wurden und 2011 mit ihnen verarbeitet werden. Und so weiter für den Rest des Jahres. Der gleiche Zyklus, aber nicht zweihunderttausend Iterationen, sondern insgesamt neun.for y in range(ars['year'].min(),ars['year'].max()):
arsynp = ars[(ars['exp'] == '') & (ars['year'] == y)]
namesy = arsynp['name'].unique()
ind = ars[ars['name'].isin(namesy)].index
ars.loc[ind, 'exp'] = ars.loc[ind,'year'] - y + 1
Dieser Zyklus dauert nur wenige Sekunden. Und der Code erwies sich als viel prägnanter.Fazit
Nun, endlich ist eine Menge Arbeit erledigt. Für mich war dies tatsächlich das erste Projekt dieser Art. Als ich es nahm, war das Hauptziel, die Verwendung von Python und seinen Bibliotheken zu üben. Diese Aufgabe ist mehr als abgeschlossen. Und die Ergebnisse selbst waren durchaus vorzeigbar. Welche Schlussfolgerungen habe ich nach Abschluss für mich gezogen?Erstens: Daten sind unvollständig. Dies gilt wahrscheinlich für fast jede Analyseaufgabe. Selbst wenn sie vollständig strukturiert sind und dies häufig anders geschieht, müssen Sie darauf vorbereitet sein, sie zu basteln, bevor Sie mit der Berechnung der Merkmale und der Suche nach Trends beginnen - Fehler, Ausreißer, Abweichungen von Standards usw. finden.Zweitens:Jede Aufgabe hat eine Lösung. Dies ist eher ein Slogan, aber oft ist es so. Es ist nur so, dass diese Lösung möglicherweise nicht so offensichtlich ist und nicht in den Daten selbst liegt, sondern sozusagen außerhalb des Rahmens. Als Beispiel - die Verarbeitung der Namen der oben beschriebenen Teilnehmer oder das Scraping der Website.Drittens: Domänenwissen ist entscheidend. Dies ermöglicht es, die Daten besser vorzubereiten, offensichtlich ungültige oder nicht standardmäßige Daten zu entfernen, Interpretationsfehler zu vermeiden, Informationen zu verwenden, die nicht in den Daten enthalten sind, z. B. Entfernungen in diesem Projekt, die Ergebnisse in der in der Community akzeptierten Form darzustellen und dumme, falsche Schlussfolgerungen zu vermeiden.Viertens: In Python arbeitenEs gibt eine Vielzahl von Werkzeugen. Manchmal scheint es wert zu sein, über etwas nachzudenken, man beginnt zu suchen - es existiert bereits. Das ist einfach toll! Vielen Dank an die Macher für diesen Beitrag, insbesondere für die Werkzeuge, die sich hier als nützlich erwiesen haben: Selen zum Schaben, Pycountry zur Bestimmung des Ländercodes gemäß ISO-Standard, Ländercodes (Datahub) für olympische Codes, Geopy zur Bestimmung der Koordinaten an der Adresse, Folium - zur Visualisierung von Geodaten, Gender-Guesser - zur Analyse von Namen, Multiprocessing - für Parallel Computing, Matplotlib , Numpy und natürlich Pandas - ohne sie gibt es keinen Ort , an den man gehen kann.Fünftens: Vektorisierung ist unser Alles. Es ist äußerst wichtig, die eingebauten Pandas- Tools verwenden zu können , es ist sehr effektiv. Ich nehme an, in den meisten Fällen, wenn die Anzahl der Datensätze ab Zehntausenden gemessen wird, wird diese Fähigkeit einfach notwendig.Sechste:Der Umgang mit Daten ist eine schlechte Idee. Es muss versucht werden, manuelle Eingriffe so gering wie möglich zu halten. Erstens wird nicht skaliert, dh wenn sich die Datenmenge mehrmals erhöht, erhöht sich die Zeit für die manuelle Verarbeitung auf inakzeptable Werte, und zweitens wird die Wiederholbarkeit schlecht sein. Sie werden etwas vergessen und irgendwo einen Fehler machen . Alles ist nur programmatisch, wenn etwas vom allgemeinen Standard für eine Softwarelösung abweicht, ist es in Ordnung, Sie können einen Teil der Daten opfern, es wird immer noch mehr Pluspunkte geben.Siebte:Der Code muss funktionsfähig bleiben. Es scheint, dass es offensichtlicher sein könnte! Wenn es um Code für den eigenen Gebrauch geht, dessen Zweck darin besteht, die Ergebnisse dieses Codes zu veröffentlichen, ist hier nicht alles so streng. Ich habe in Jupiter Notebooks gearbeitet, und diese Umgebung muss meiner Meinung nach keine integralen Softwareprodukte erstellen. Es ist für den zeilenweisen, stückweisen Start konfiguriert. Dies hat seine Vorteile - es ist schnell: Entwicklung, Debugging und Ausführung gleichzeitig. Aber oft besteht die Versuchung darin, nur eine Zeile zu bearbeiten und schnell ein neues Ergebnis zu erhalten, anstatt def zu duplizieren oder einzuwickeln. Natürlich sollte eine solche Versuchung vermieden werden. Es ist notwendig, nach einem guten Code zu streben, auch „für sich selbst“, zumindest weil der Start selbst für eine Analysearbeit viele Male durchgeführt wird und sich die Investition von Zeit am Anfang sicherlich in Zukunft auszahlen wird. Und Sie können Tests auch auf Laptops in Form von Überprüfungen kritischer Parameter und Auslösen von Ausnahmen hinzufügen - dies ist sehr nützlich.Achte: Sparen Sie öfter. Bei jedem Schritt habe ich eine neue Version der Datei gespeichert. Insgesamt stellte sich heraus, dass sie ungefähr 10 waren. Dies ist praktisch, da es bei der Erkennung eines Fehlers hilfreich ist, schnell festzustellen, in welchem Stadium er aufgetreten ist. Außerdem habe ich die Quelldaten in den als roh gekennzeichneten Spalten gespeichert. Auf diese Weise können Sie das Ergebnis schnell überprüfen und die Diskrepanz feststellen.Neunte:Es ist notwendig, den Zeitaufwand und das Ergebnis zu messen. An einigen Stellen habe ich sehr lange gebraucht, um Daten wiederherzustellen, die einen Bruchteil eines Prozentsatzes der Gesamtmenge ausmachen. Tatsächlich machte das keinen Sinn, man musste sie einfach wegwerfen, und das ist alles. Und ich würde es tun, wenn es ein kommerzielles Projekt wäre, kein Autotraining. Dies würde es Ihnen ermöglichen, das Ergebnis viel schneller zu erhalten. Hier funktioniert das Pareto-Prinzip - 80% des Ergebnisses werden in 20% der Fälle erzielt.Und der Letzte:Die Arbeit an solchen Projekten erweitert den Horizont erheblich. Bereitwillig lernen Sie etwas Neues - zum Beispiel die Namen fremder Länder - wie die Pitcairn-Inseln, dass der ISO-Code für die Schweiz CHE ist, aus dem lateinischen „Confoederatio Helvetica“, was der spanische Name eigentlich über den Triathlon selbst ist - Aufzeichnungen, ihre Besitzer, Orte von Rassen, Geschichte von Ereignissen und so weiter.Vielleicht genug. Das ist alles. Vielen Dank an alle, die bis zum Ende gelesen haben!