Der Zugriff auf die GPU über Java zeigt eine enorme Leistung. Es beschreibt, wie die GPU funktioniert und wie von Java aus zugegriffen wird.Die GPU-Programmierung ist für Java-Programmierer eine himmelhohe Welt. Dies ist verständlich, da normale Java-Tasks nicht für die GPU geeignet sind. GPUs weisen jedoch Teraflops der Leistung auf. Lassen Sie uns daher ihre Funktionen untersuchen.Um das Thema zugänglich zu machen, werde ich einige Zeit damit verbringen, die Architektur der GPU zusammen mit einer kleinen Geschichte zu erklären, die ein Eintauchen in die Eisenprogrammierung erleichtert.Nachdem mir die Unterschiede zwischen der GPU und dem CPU-Computing gezeigt wurden, werde ich zeigen, wie die GPU in der Java-Welt verwendet wird. Abschließend werde ich die wichtigsten Frameworks und Bibliotheken beschreiben, die zum Schreiben und Ausführen von Java-Code auf der GPU verfügbar sind, und einige Codebeispiele geben.Ein bisschen Hintergrund
Die GPU wurde erstmals 1999 von NVIDIA populär gemacht. Es handelt sich um einen speziellen Prozessor, der Grafikdaten verarbeitet, bevor sie auf das Display übertragen werden. In vielen Fällen ermöglicht dies einige Berechnungen, die CPU zu entladen, wodurch CPU-Ressourcen freigesetzt werden, die diese entladenen Berechnungen beschleunigen. Das Ergebnis ist, dass große Eingaben mit einer höheren Ausgabeauflösung verarbeitet und dargestellt werden können, wodurch die visuelle Darstellung attraktiver und die Bildrate flüssiger wird.Die Essenz der 2D / 3D-Verarbeitung liegt hauptsächlich in der Manipulation von Matrizen, dies kann unter Verwendung eines verteilten Ansatzes gesteuert werden. Was wird ein effektiver Ansatz für die Bildverarbeitung sein? Um dies zu beantworten, vergleichen wir die Standard-CPU-Architektur (siehe Abbildung 1) und die GPU.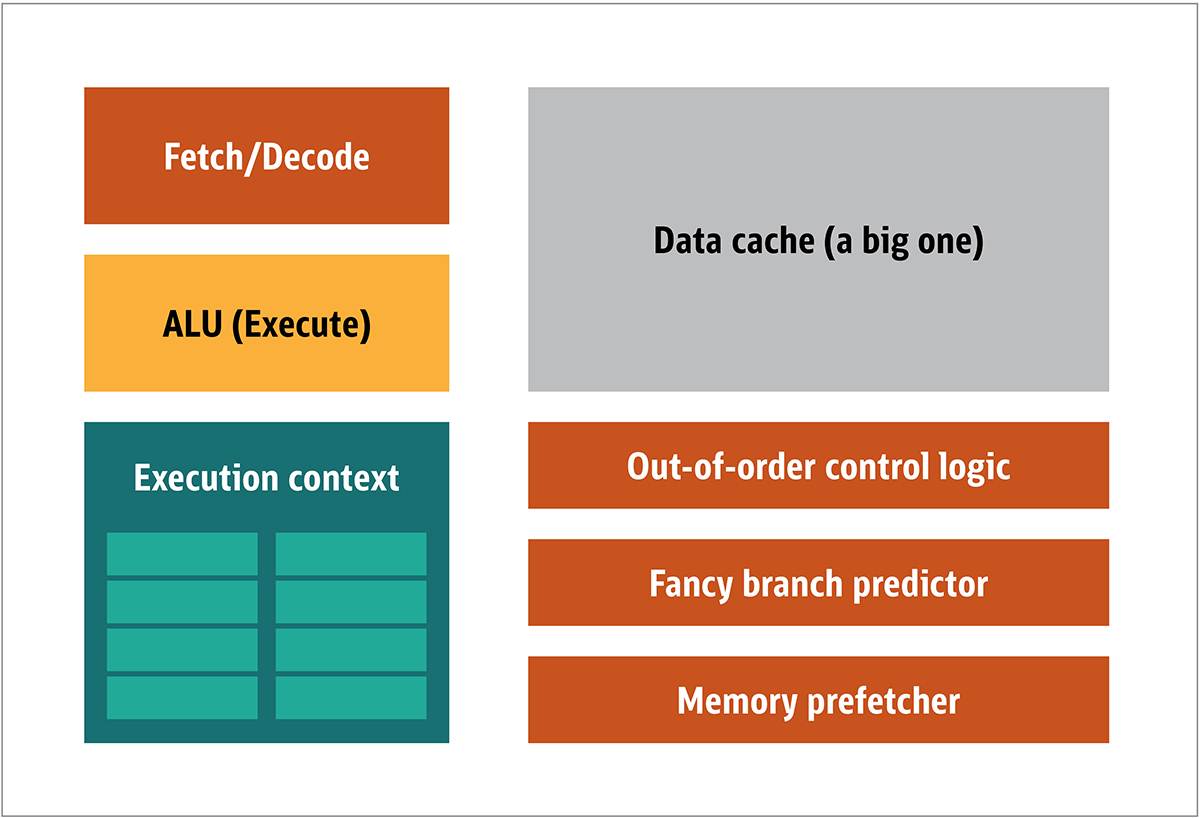 Feige. 1. CPU-ArchitekturblöckeIn der CPU sind die eigentlichen Verarbeitungselemente - Register, arithmetische Logikeinheit (ALU) und Ausführungskontexte - nur kleine Teile des gesamten Systems. Um unregelmäßige Zahlungen in unvorhersehbarer Reihenfolge zu beschleunigen, gibt es einen großen, schnellen und teuren Cache. verschiedene Arten von Sammlern; und Zweigprädiktoren.Sie benötigen dies alles nicht auf der GPU, da die Daten auf vorhersehbare Weise empfangen werden und die GPU nur sehr wenige Operationen mit den Daten ausführt. Somit ist es möglich, sie sehr klein zu machen, und ein kostengünstiger Prozessor mit einer Blockarchitektur ähnlich dieser ist in Fig. 1 gezeigt. 2.
Feige. 1. CPU-ArchitekturblöckeIn der CPU sind die eigentlichen Verarbeitungselemente - Register, arithmetische Logikeinheit (ALU) und Ausführungskontexte - nur kleine Teile des gesamten Systems. Um unregelmäßige Zahlungen in unvorhersehbarer Reihenfolge zu beschleunigen, gibt es einen großen, schnellen und teuren Cache. verschiedene Arten von Sammlern; und Zweigprädiktoren.Sie benötigen dies alles nicht auf der GPU, da die Daten auf vorhersehbare Weise empfangen werden und die GPU nur sehr wenige Operationen mit den Daten ausführt. Somit ist es möglich, sie sehr klein zu machen, und ein kostengünstiger Prozessor mit einer Blockarchitektur ähnlich dieser ist in Fig. 1 gezeigt. 2.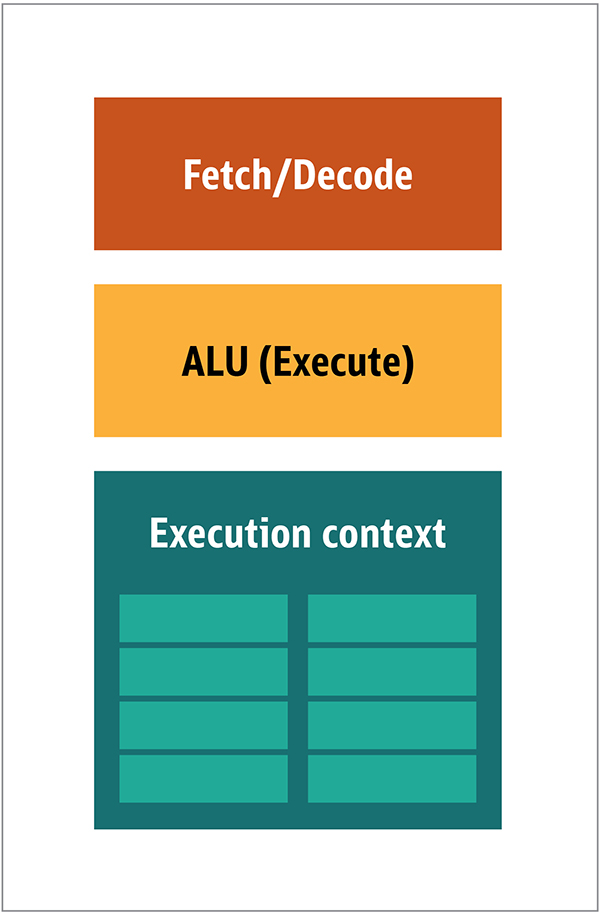 Abb. 2. Blockarchitektur für einen einfachen GPU-KernDa solche Prozessoren billiger sind und die darin verarbeiteten Daten in parallelen Blöcken verarbeitet werden, ist es einfach, viele von ihnen parallel arbeiten zu lassen. Es wurde unter Bezugnahme auf mehrere Anweisungen, mehrere Daten oder MIMD (ausgesprochen "mim-dee") entwickelt.Der zweite Ansatz basiert auf der Tatsache, dass häufig eine einzelne Anweisung auf mehrere Daten angewendet wird. Dies ist als einzelne Anweisung, mehrere Daten oder SIMD (ausgesprochen „sim-dee“) bekannt. In diesem Entwurf enthält eine einzelne GPU mehrere ALUs und Ausführungskontexte, kleine Bereiche, die in gemeinsam genutzte Kontextdaten übertragen werden (siehe Abbildung) 3.
Abb. 2. Blockarchitektur für einen einfachen GPU-KernDa solche Prozessoren billiger sind und die darin verarbeiteten Daten in parallelen Blöcken verarbeitet werden, ist es einfach, viele von ihnen parallel arbeiten zu lassen. Es wurde unter Bezugnahme auf mehrere Anweisungen, mehrere Daten oder MIMD (ausgesprochen "mim-dee") entwickelt.Der zweite Ansatz basiert auf der Tatsache, dass häufig eine einzelne Anweisung auf mehrere Daten angewendet wird. Dies ist als einzelne Anweisung, mehrere Daten oder SIMD (ausgesprochen „sim-dee“) bekannt. In diesem Entwurf enthält eine einzelne GPU mehrere ALUs und Ausführungskontexte, kleine Bereiche, die in gemeinsam genutzte Kontextdaten übertragen werden (siehe Abbildung) 3.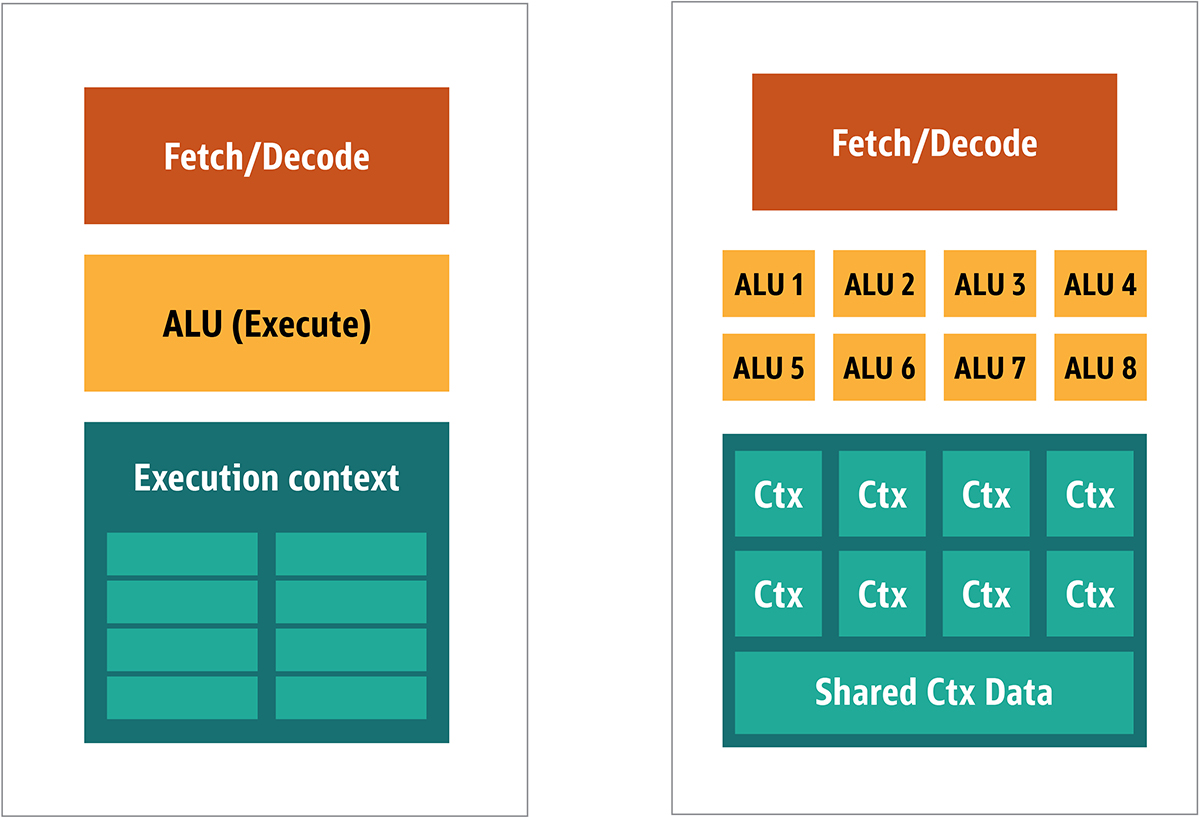 Abb. 3. Vergleich der MIMD-Architektur der GPU-Blöcke (von links) mit dem SIMD-Design (von rechts)Das Mischen von SIMD- und MIMD-Verarbeitung bietet die maximale Bandbreite, die ich umgehen werde. In diesem Design laufen mehrere SIMD-Prozessoren parallel (siehe Abbildung) 4.
Abb. 3. Vergleich der MIMD-Architektur der GPU-Blöcke (von links) mit dem SIMD-Design (von rechts)Das Mischen von SIMD- und MIMD-Verarbeitung bietet die maximale Bandbreite, die ich umgehen werde. In diesem Design laufen mehrere SIMD-Prozessoren parallel (siehe Abbildung) 4. Abb. 4. Mehrere SIMD-Prozessoren gleichzeitig arbeiten; Es gibt 16 Kerne mit 128 ALUs.Da Sie eine Reihe kleiner, einfacher Prozessoren haben, können Sie diese so programmieren, dass sie einen besonderen Effekt in der Ausgabe erzielen.
Abb. 4. Mehrere SIMD-Prozessoren gleichzeitig arbeiten; Es gibt 16 Kerne mit 128 ALUs.Da Sie eine Reihe kleiner, einfacher Prozessoren haben, können Sie diese so programmieren, dass sie einen besonderen Effekt in der Ausgabe erzielen.Ausführen von Programmen auf der GPU
Die meisten frühen Grafikeffekte in Spielen waren wirklich hartcodierte kleine Programme, die auf der GPU ausgeführt und auf Datenströme von der CPU angewendet wurden.Dies war offensichtlich, selbst wenn hartcodierte Algorithmen unzureichend waren, insbesondere im Spieldesign, wo visuelle Effekte eine der wichtigsten magischen Richtungen sind. Als Reaktion darauf eröffneten große Verkäufer den Zugriff auf die GPU, und dann konnten Entwickler von Drittanbietern sie programmieren.Ein typischer Ansatz bestand darin, ein kleines Programm namens Shader in einer speziellen Sprache (normalerweise eine Unterart von C) zu schreiben und diese mit speziellen Compilern für die gewünschte Architektur zu kompilieren. Der Begriff Shader wurde gewählt, weil Shader häufig zur Steuerung von Licht- und Schatteneffekten verwendet werden. Dies bedeutet jedoch nicht, dass sie andere Spezialeffekte steuern können.Jeder GPU-Anbieter verfügte über eine eigene Programmiersprache und Infrastruktur, um Shader für seine Architektur zu erstellen. Auf diesem Ansatz wurden viele Plattformen erstellt.Die wichtigsten sind:- DirectCompute: Die private Shader-Sprache / API von Microsoft, die Teil von Direct3D ist, beginnend mit DirectX 10.
- AMD FireStream: Private ATI / Radeon-Technologien, die von AMD veraltet sind.
- OpenACC: Multi-Vendor Consortium, Parallel Computing-Lösung
- ++ AMP: Microsoft C++
- CUDA: Nvidia,
- OpenL: , Apple, Khronos Group
Die Arbeit mit der GPU ist meistens eine einfache Programmierung. Um dies für Entwickler ein wenig verständlicher zu machen, wurden für die Codierung mehrere Abstraktionen bereitgestellt. Am bekanntesten ist DirectX von Microsoft und OpenGL von der Khronos Group. Dies sind APIs zum Schreiben von Code auf hoher Ebene, die dann für die GPU semantischer für den Programmierer vereinfacht werden können.Soweit ich weiß, gibt es keine Java-Infrastruktur für DirectX, aber es gibt eine gute Lösung für OpenGL. JSR 231 wurde 2002 gestartet und richtet sich an GPU-Programmierer. Es wurde jedoch 2008 aufgegeben und unterstützt nur OpenGL 2.0.Die OpenGL-Unterstützung wird im unabhängigen JOCL-Projekt (das auch OpenCL unterstützt) fortgesetzt und steht dem Publikum zur Verfügung. So wurde das berühmte Minecraft-Spiel mit JOCL geschrieben.GPGPU kommt
Bisher hatten Java und die GPU keine Gemeinsamkeiten, obwohl dies der Fall sein sollte. Java wird häufig in Unternehmen, in der Datenwissenschaft und im Finanzsektor verwendet, wo viel Computer vorhanden ist und viel Rechenleistung benötigt wird. So ist die Idee der Allzweck-GPU (GPGPU). Die Idee, die GPU auf diesem Weg zu verwenden, begann, als die Hersteller von Videoadaptern Zugriff auf den Programmrahmenpuffer gewährten, sodass Entwickler den Inhalt lesen konnten. Einige Hacker haben festgestellt, dass sie die volle Leistung der GPU für Universal Computing nutzen können.Das Rezept war wie folgt:- Codieren Sie Daten als Rasterarray.
- Schreiben Sie Shader, um damit umzugehen.
- Senden Sie beide an die Grafikkarte.
- Ergebnis aus Bildpuffer abrufen
- Dekodieren Sie Daten aus einem Rasterarray.
Dies ist eine sehr einfache Erklärung. Ich bin nicht sicher, ob dies in der Produktion funktionieren wird, aber es funktioniert wirklich.Dann begannen zahlreiche Studien des Stanford Institute, die Verwendung von GPUs zu vereinfachen. 2005 haben sie BrookGPU entwickelt, ein kleines Ökosystem, das eine Programmiersprache, einen Compiler und eine Laufzeit enthält.BrookGPU kompilierte Programme, die in der Programmiersprache Brook-Thread geschrieben wurden, die eine ANSI C-Variante war. Sie kann OpenGL v1.3 +, DirectX v9 + oder AMD Close to Metal für den Server-Computing-Teil verwenden und läuft unter Microsoft Windows und Linux. Zum Debuggen kann BrookGPU auch eine virtuelle Grafikkarte auf der CPU simulieren.Dies nahm jedoch aufgrund der zu diesem Zeitpunkt verfügbaren Ausrüstung nicht zu. In der GPGPU-Welt müssen Sie Daten auf das Gerät kopieren (in diesem Zusammenhang bezieht sich das Gerät auf die GPU und das Gerät, auf dem es sich befindet), warten, bis die GPU die Daten berechnet hat, und dann die Daten zurück in das Steuerprogramm kopieren. Dies führt zu vielen Verzögerungen. Mitte der 2000er Jahre, als sich das Projekt in der aktiven Entwicklung befand, schlossen diese Verzögerungen auch die intensive Nutzung der GPU für das Basic Computing aus.Viele Unternehmen haben jedoch die Zukunft in dieser Technologie gesehen. Mehrere Entwickler von Videoadaptern begannen, GPGPUs mit ihren proprietären Technologien auszustatten, und andere gebildete Allianzen lieferten weniger grundlegende, vielseitige Programmiermodelle, die auf einer großen Menge an Hardware arbeiteten.Nachdem ich Ihnen alles erzählt habe, schauen wir uns die beiden erfolgreichsten GPU-Computertechnologien an - OpenCL und CUDA - und sehen Sie auch, wie Java mit ihnen funktioniert.OpenCL und Java
Wie andere Infrastrukturpakete bietet OpenCL eine grundlegende Implementierung in C. Diese ist technisch über das Java Native Interface (JNI) oder Java Native Access (JNA) verfügbar, aber dieser Ansatz wird für die meisten Entwickler zu schwierig sein.Glücklicherweise wurde diese Arbeit bereits von mehreren Bibliotheken durchgeführt: JOCL, JogAmp und JavaCL. Leider ist JavaCL ein totes Projekt geworden. Aber das JOCL-Projekt ist lebendig und sehr angepasst. Ich werde es für die folgenden Beispiele verwenden.Aber zuerst muss ich erklären, was OpenCL ist. Ich habe bereits erwähnt, dass OpenCL ein sehr einfaches Modell bietet, mit dem alle Arten von Geräten programmiert werden können - nicht nur GPUs und CPUs, sondern auch DSP-Prozessoren und FPGAs.Schauen wir uns das einfachste Beispiel an: Faltvektoren sind wahrscheinlich das hellste und einfachste Beispiel. Sie haben zwei Zahlenfelder zum Hinzufügen und eines für das Ergebnis. Sie nehmen ein Element aus dem ersten Array und ein Element aus dem zweiten Array und fügen dann die Summe in das Ergebnisarray ein, wie in Abb. 5.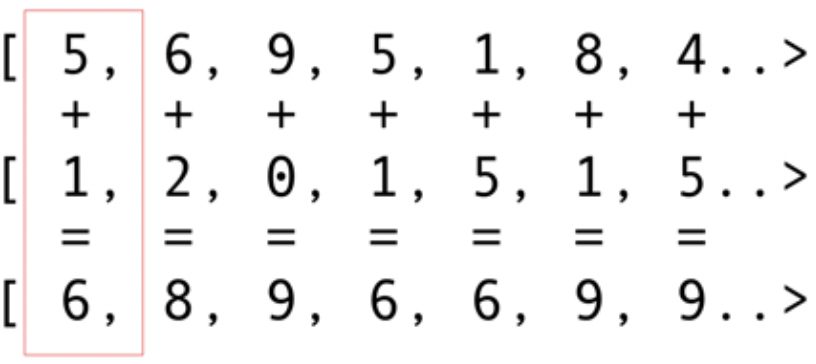 Abb. 5. Hinzufügen der Elemente von zwei Arrays und Speichern der Summe im resultierenden ArrayWie Sie sehen können, ist die Operation sehr konsistent und dennoch verteilt. Sie können jede Additionsoperation in verschiedene Kern-GPUs verschieben. Dies bedeutet, dass Sie bei 2048 Kernen wie beim Nvidia 1080 gleichzeitig 2048 Additionsvorgänge ausführen können. Dies bedeutet, dass hier die potenziellen Teraflops der Computerleistung auf Sie warten. Dieser Code für ein Array von 10 Millionen Nummern stammt von der JOCL-Website:
Abb. 5. Hinzufügen der Elemente von zwei Arrays und Speichern der Summe im resultierenden ArrayWie Sie sehen können, ist die Operation sehr konsistent und dennoch verteilt. Sie können jede Additionsoperation in verschiedene Kern-GPUs verschieben. Dies bedeutet, dass Sie bei 2048 Kernen wie beim Nvidia 1080 gleichzeitig 2048 Additionsvorgänge ausführen können. Dies bedeutet, dass hier die potenziellen Teraflops der Computerleistung auf Sie warten. Dieser Code für ein Array von 10 Millionen Nummern stammt von der JOCL-Website:public class ArrayGPU {
private static String programSource =
"__kernel void "+
"sampleKernel(__global const float *a,"+
" __global const float *b,"+
" __global float *c)"+
"{"+
" int gid = get_global_id(0);"+
" c[gid] = a[gid] + b[gid];"+
"}";
public static void main(String args[])
{
int n = 10_000_000;
float srcArrayA[] = new float[n];
float srcArrayB[] = new float[n];
float dstArray[] = new float[n];
for (int i=0; i<n; i++)
{
srcArrayA[i] = i;
srcArrayB[i] = i;
}
Pointer srcA = Pointer.to(srcArrayA);
Pointer srcB = Pointer.to(srcArrayB);
Pointer dst = Pointer.to(dstArray);
final int platformIndex = 0;
final long deviceType = CL.CL_DEVICE_TYPE_ALL;
final int deviceIndex = 0;
CL.setExceptionsEnabled(true);
int numPlatformsArray[] = new int[1];
CL.clGetPlatformIDs(0, null, numPlatformsArray);
int numPlatforms = numPlatformsArray[0];
cl_platform_id platforms[] = new cl_platform_id[numPlatforms];
CL.clGetPlatformIDs(platforms.length, platforms, null);
cl_platform_id platform = platforms[platformIndex];
cl_context_properties contextProperties = new cl_context_properties();
contextProperties.addProperty(CL.CL_CONTEXT_PLATFORM, platform);
int numDevicesArray[] = new int[1];
CL.clGetDeviceIDs(platform, deviceType, 0, null, numDevicesArray);
int numDevices = numDevicesArray[0];
cl_device_id devices[] = new cl_device_id[numDevices];
CL.clGetDeviceIDs(platform, deviceType, numDevices, devices, null);
cl_device_id device = devices[deviceIndex];
cl_context context = CL.clCreateContext(
contextProperties, 1, new cl_device_id[]{device},
null, null, null);
cl_command_queue commandQueue =
CL.clCreateCommandQueue(context, device, 0, null);
cl_mem memObjects[] = new cl_mem[3];
memObjects[0] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_ONLY | CL.CL_MEM_COPY_HOST_PTR,
Sizeof.cl_float * n, srcA, null);
memObjects[1] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_ONLY | CL.CL_MEM_COPY_HOST_PTR,
Sizeof.cl_float * n, srcB, null);
memObjects[2] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_WRITE,
Sizeof.cl_float * n, null, null);
cl_program program = CL.clCreateProgramWithSource(context,
1, new String[]{ programSource }, null, null);
CL.clBuildProgram(program, 0, null, null, null, null);
cl_kernel kernel = CL.clCreateKernel(program, "sampleKernel", null);
CL.clSetKernelArg(kernel, 0,
Sizeof.cl_mem, Pointer.to(memObjects[0]));
CL.clSetKernelArg(kernel, 1,
Sizeof.cl_mem, Pointer.to(memObjects[1]));
CL.clSetKernelArg(kernel, 2,
Sizeof.cl_mem, Pointer.to(memObjects[2]));
long global_work_size[] = new long[]{n};
long local_work_size[] = new long[]{1};
CL.clEnqueueNDRangeKernel(commandQueue, kernel, 1, null,
global_work_size, local_work_size, 0, null, null);
CL.clEnqueueReadBuffer(commandQueue, memObjects[2], CL.CL_TRUE, 0,
n * Sizeof.cl_float, dst, 0, null, null);
CL.clReleaseMemObject(memObjects[0]);
CL.clReleaseMemObject(memObjects[1]);
CL.clReleaseMemObject(memObjects[2]);
CL.clReleaseKernel(kernel);
CL.clReleaseProgram(program);
CL.clReleaseCommandQueue(commandQueue);
CL.clReleaseContext(context);
}
private static String getString(cl_device_id device, int paramName) {
long size[] = new long[1];
CL.clGetDeviceInfo(device, paramName, 0, null, size);
byte buffer[] = new byte[(int)size[0]];
CL.clGetDeviceInfo(device, paramName, buffer.length, Pointer.to(buffer), null);
return new String(buffer, 0, buffer.length-1);
}
}
Dieser Code ist nicht wie Java-Code, aber er ist es. Ich werde den Code weiter erklären; Verbringen Sie jetzt nicht viel Zeit damit, da ich kurz auf komplexe Lösungen eingehen werde.Der Code wird dokumentiert, aber lassen Sie uns einen kleinen Durchgang machen. Wie Sie sehen können, ist der Code dem Code in C sehr ähnlich. Dies ist normal, da JOCL nur OpenCL ist. Am Anfang steht hier ein Code in der Zeile, und dieser Code ist der wichtigste Teil: Er wird mit OpenCL kompiliert und dann an die Grafikkarte gesendet, wo er ausgeführt wird. Dieser Code heißt Kernel. Verwechseln Sie diesen Begriff nicht mit OC Kernel. Dies ist der Gerätecode. Dieser Code wird in eine Teilmenge von C geschrieben.Nachdem der Kernel Java-Code zum Installieren und Konfigurieren des Geräts enthält, teilen Sie die Daten auf und erstellen Sie die entsprechenden Speicherpuffer für die resultierenden Daten.Zusammenfassend: Hier ist der „Host-Code“, bei dem es sich normalerweise um eine Sprachbindung handelt (in unserem Fall in Java), und der „Gerätecode“. Sie markieren immer, was auf dem Host funktioniert und was auf dem Gerät funktionieren soll, da der Host das Gerät steuert.Der vorhergehende Code sollte die GPU anzeigen, die "Hello World!" Wie Sie sehen können, ist das meiste davon riesig.Vergessen wir nicht die SIMD-Funktionen. Wenn Ihr Gerät die SIMD-Erweiterung unterstützt, können Sie arithmetischen Code schneller erstellen. Schauen wir uns als Beispiel den Kernel-Matrix-Multiplikationscode an. Dieser Code befindet sich in einer einfachen Java-Zeile in der Anwendung.__kernel void MatrixMul_kernel_basic(int dim,
__global float *A,
__global float *B,
__global float *C){
int iCol = get_global_id(0);
int iRow = get_global_id(1);
float result = 0.0;
for(int i=0; i< dim; ++i)
{
result +=
A[iRow*dim + i]*B[i*dim + iCol];
}
C[iRow*dim + iCol] = result;
}
Technisch gesehen funktioniert dieser Code mit Daten, die vom OpenCL-Framework für Sie installiert wurden, mit den Anweisungen, die Sie im vorbereitenden Teil aufgerufen haben.Wenn Ihre Grafikkarte SIMD-Anweisungen unterstützt und einen Vektor mit vier Gleitkommazahlen verarbeiten kann, können kleine Optimierungen den vorherigen Code wie folgt umwandeln:#define VECTOR_SIZE 4
__kernel void MatrixMul_kernel_basic_vector4(
size_t dim,
const float4 *A,
const float4 *B,
float4 *C)
{
size_t globalIdx = get_global_id(0);
size_t globalIdy = get_global_id(1);
float4 resultVec = (float4){ 0, 0, 0, 0 };
size_t dimVec = dim / 4;
for(size_t i = 0; i < dimVec; ++i) {
float4 Avector = A[dimVec * globalIdy + i];
float4 Bvector[4];
Bvector[0] = B[dimVec * (i * 4 + 0) + globalIdx];
Bvector[1] = B[dimVec * (i * 4 + 1) + globalIdx];
Bvector[2] = B[dimVec * (i * 4 + 2) + globalIdx];
Bvector[3] = B[dimVec * (i * 4 + 3) + globalIdx];
resultVec += Avector[0] * Bvector[0];
resultVec += Avector[1] * Bvector[1];
resultVec += Avector[2] * Bvector[2];
resultVec += Avector[3] * Bvector[3];
}
C[dimVec * globalIdy + globalIdx] = resultVec;
}
Mit diesem Code können Sie die Leistung verdoppeln.Cool. Sie haben gerade die GPU für die Java-Welt geöffnet! Aber möchten Sie als Java-Entwickler wirklich all diese Drecksarbeit mit C-Code machen und mit so einfachen Details arbeiten? Ich will nicht. Nachdem Sie nun einige Kenntnisse über die Verwendung der GPU haben, schauen wir uns eine andere Lösung an, die sich von dem gerade vorgestellten JOCL-Code unterscheidet.CUDA und Java
CUDA ist Nvidias Lösung für dieses Programmierproblem. CUDA bietet viel mehr gebrauchsfertige Bibliotheken für Standard-GPU-Operationen wie Matrizen, Histogramme und sogar tiefe neuronale Netze. Eine Liste von Bibliotheken mit einer Reihe vorgefertigter Lösungen ist bereits erschienen. Dies ist alles aus dem JCuda-Projekt:- JCublas: alles für Matrizen
- JCufft: Schnelle Fourier-Transformation
- JCurand: Alles für Zufallszahlen
- JCusparse: seltene Matrizen
- JCusolver: Faktorisierung von Zahlen
- JNvgraph: alles für Grafiken
- JCudpp: CUDA-Bibliothek mit primitiven parallelen Daten und einigen Sortieralgorithmen
- JNpp: GPU-Bildverarbeitung
- JCudnn: tiefe neuronale Netzwerkbibliothek
Ich denke darüber nach, JCurand zu verwenden, das Zufallszahlen generiert. Sie können dies aus Java-Code ohne eine andere spezielle Kernel-Sprache verwenden. Beispielsweise:...
int n = 100;
curandGenerator generator = new curandGenerator();
float hostData[] = new float[n];
Pointer deviceData = new Pointer();
cudaMalloc(deviceData, n * Sizeof.FLOAT);
curandCreateGenerator(generator, CURAND_RNG_PSEUDO_DEFAULT);
curandSetPseudoRandomGeneratorSeed(generator, 1234);
curandGenerateUniform(generator, deviceData, n);
cudaMemcpy(Pointer.to(hostData), deviceData,
n * Sizeof.FLOAT, cudaMemcpyDeviceToHost);
System.out.println(Arrays.toString(hostData));
curandDestroyGenerator(generator);
cudaFree(deviceData);
...
Es verwendet eine GPU, um eine große Anzahl von Zufallszahlen von sehr hoher Qualität zu erstellen, basierend auf sehr starker Mathematik.In JCuda können Sie auch generischen CUDA-Code schreiben und von Java aus aufrufen, indem Sie eine JAR-Datei in Ihrem Klassenpfad aufrufen. In der JCuda-Dokumentation finden Sie gute Beispiele.Bleiben Sie über dem Low-Level-Code
Es sieht alles gut aus, aber es gibt zu viel Code, zu viel Installation, zu viele verschiedene Sprachen, um alles auszuführen. Gibt es eine Möglichkeit, die GPU zumindest teilweise zu nutzen?Was ist, wenn Sie nicht über all diese OpenCL, CUDA und andere unnötige Dinge nachdenken möchten? Was ist, wenn Sie nur in Java programmieren und nicht an alles denken möchten, was nicht offensichtlich ist? Aparapi-Projekt kann helfen. Aparapi basiert auf einer "parallelen API". Ich betrachte es als Teil von Hibernate für die GPU-Programmierung, die OpenCL unter der Haube verwendet. Schauen wir uns ein Beispiel für die Vektoraddition an.public static void main(String[] _args) {
final int size = 512;
final float[] a = new float[size];
final float[] b = new float[size];
for (int i = 0; i < size; i++){
a[i] = (float) (Math.random() * 100);
b[i] = (float) (Math.random() * 100);
}
final float[] sum = new float[size];
Kernel kernel = new Kernel(){
@Override public void run() {
I int gid = getGlobalId();
sum[gid] = a[gid] + b[gid];
}
};
kernel.execute(Range.create(size));
for(int i = 0; i < size; i++) {
System.out.printf("%6.2f + %6.2f = %8.2f\n", a[i], b[i], sum[i])
}
kernel.dispose();
}
Hier ist reiner Java-Code (aus der Aparapi-Dokumentation entnommen), auch hier und da sehen Sie einen bestimmten Begriff Kernel und getGlobalId. Sie müssen noch verstehen, wie die GPU programmiert wird, aber Sie können den GPGPU-Ansatz auf eine Java-ähnliche Weise verwenden. Darüber hinaus bietet Aparapi eine einfache Möglichkeit, den OpenGL-Kontext für die OpenCL-Schicht zu verwenden, sodass die Daten vollständig auf der Grafikkarte verbleiben, und Probleme mit der Speicherlatenz zu vermeiden.Wenn Sie viele unabhängige Berechnungen durchführen müssen, schauen Sie sich Aparapi an. Es gibt viele Beispiele für die Verwendung von Parallel Computing.Darüber hinaus gibt es ein Projekt namens TornadoVM, das die entsprechenden Berechnungen automatisch von der CPU auf die GPU überträgt und so eine sofortige Massenoptimierung ermöglicht.Ergebnisse
Es gibt viele Anwendungen, bei denen GPUs einige Vorteile bringen können, aber man könnte sagen, dass es immer noch einige Hindernisse gibt. Java und die GPU können jedoch gemeinsam großartige Dinge tun. In diesem Artikel habe ich nur dieses umfangreiche Thema angesprochen. Ich wollte verschiedene High- und Low-Level-Optionen für den Zugriff auf die GPU von Java aus zeigen. Die Erkundung dieses Bereichs bietet enorme Leistungsvorteile, insbesondere bei komplexen Aufgaben, für die mehrere Berechnungen erforderlich sind, die parallel ausgeführt werden können.Quelllink