Ich werde den Titel des Artikels sofort erklären. Ursprünglich war geplant, anhand eines einfachen, aber realistischen Beispiels gute und zuverlässige Ratschläge zur Beschleunigung der Reflexion zu geben. Beim Benchmarking stellte sich jedoch heraus, dass die Reflexion nicht so langsam funktioniert, wie ich dachte. LINQ arbeitet langsamer als in Albträumen geträumt. Aber am Ende stellte sich heraus, dass ich auch bei den Messungen einen Fehler gemacht habe ... Details dieser Lebensgeschichte unter dem Schnitt und in den Kommentaren. Da das Beispiel ziemlich alltäglich ist und im Prinzip implementiert wird, wie es normalerweise im Unternehmen üblich ist, erwies es sich als ziemlich interessant, wie es mir scheint, als Demonstration des Lebens: Aufgrund der externen Logik gab es keinen merklichen Einfluss auf die Geschwindigkeit des Hauptthemas des Artikels: Moq, Autofac, EF Core usw. "Umreifen".Ich habe meine Arbeit unter dem Eindruck dieses Artikels begonnen: Warum ist die Reflexion langsam?Wie Sie sehen, schlägt der Autor vor, kompilierte Delegaten zu verwenden, anstatt direkt Reflexionsmethoden aufzurufen, um die Anwendung erheblich zu beschleunigen. Es gibt natürlich IL-Emissionen, aber ich möchte sie vermeiden, da dies der arbeitsintensivste Weg ist, um die mit Fehlern behaftete Aufgabe zu erledigen.In Anbetracht der Tatsache, dass ich mich immer an eine ähnliche Meinung über die Geschwindigkeit der Reflexion hielt, wollte ich die Schlussfolgerungen des Autors nicht besonders in Frage stellen.Ich begegne oft dem naiven Gebrauch von Reflexion in einem Unternehmen. Typ wird genommen. Eigenschaftsinformationen werden übernommen. Die SetValue-Methode wird aufgerufen und alle sind glücklich. Der Wert flog ins Zielfeld, alle sind glücklich. Leute, die sehr klug sind - Siniors und Teamleiter -, schreiben ihre Erweiterungen auf Objekt, basierend auf einer solch naiven Implementierung von "universellen" Mappern eines Typs in einem anderen. Das Wesentliche dabei ist normalerweise: Wir nehmen alle Felder, wir nehmen alle Eigenschaften, iterieren über sie: Wenn die Namen der Typmitglieder übereinstimmen, führen wir SetValue aus. Wir fangen regelmäßig Ausnahmen bei Fehlern ein, bei denen einer der Typen keine Eigenschaft gefunden hat, aber es gibt auch einen Ausweg, der Leistung erzielt. Versuchen / fangen.Ich sah Leute, die Parser und Mapper neu erfanden, ohne mit Informationen darüber ausgestattet zu sein, wie die Motorräder erfunden wurden, bevor sie funktionierten. Ich sah Leute, die ihre naiven Implementierungen hinter Strategien, hinter Schnittstellen, hinter Injektionen versteckten, als würde dies die nachfolgenden Bacchanalien entschuldigen. Von solchen Implementierungen drehte ich meine Nase. Tatsächlich habe ich das tatsächliche Leistungsleck nicht gemessen, und wenn möglich, habe ich die Implementierung einfach auf eine „optimalere“ geändert, wenn meine Hände sie erreicht haben. Wegen der ersten Messungen, die unten diskutiert werden, war ich ernsthaft verlegen.Ich denke, viele von Ihnen haben beim Lesen von Richter oder anderen Ideologen die ziemlich faire Behauptung aufgestellt, dass die Reflexion im Code ein Phänomen ist, das sich sehr negativ auf die Anwendungsleistung auswirkt.Der Reflection-Aufruf zwingt die CLR, die Assembly auf der Suche nach der richtigen zu umgehen, ihre Metadaten abzurufen, sie zu analysieren usw. Darüber hinaus führt die Reflexion während des Durchlaufens der Sequenz zur Zuweisung einer großen Speichermenge. Wir verbringen Erinnerung, die CLR deckt die HZ auf und friert Rennen ein. Es sollte merklich langsam sein, glauben Sie mir. Die enormen Speichermengen moderner Produktionsserver oder Cloud-Maschinen sparen nicht vor hohen Verarbeitungsverzögerungen. Je mehr Speicher vorhanden ist, desto höher ist die Wahrscheinlichkeit, dass Sie feststellen, wie die HZ funktioniert. Reflexion ist theoretisch ein zusätzlicher roter Lappen für ihn.Trotzdem verwenden wir alle sowohl IoC-Container als auch Datumszuordnungen, deren Prinzip ebenfalls auf Reflexion beruht. Fragen zu ihrer Leistung stellen sich jedoch normalerweise nicht. Nein, nicht weil die Einführung von Abhängigkeiten und die Abstraktion von Modellen mit externem begrenztem Kontext so notwendig sind, dass wir auf jeden Fall die Leistung opfern müssen. Alles ist einfacher - es hat keinen großen Einfluss auf die Leistung.Tatsache ist, dass die gängigsten Frameworks, die auf Reflexionstechnologie basieren, alle möglichen Tricks verwenden, um optimaler damit zu arbeiten. Dies ist normalerweise ein Cache. Normalerweise sind dies Ausdrücke und Delegaten, die aus dem Ausdrucksbaum kompiliert wurden. Der gleiche Auto-Mapper enthält ein wettbewerbsfähiges Wörterbuch, das Typen mit Funktionen vergleicht, die sie ineinander konvertieren können, ohne Reflection aufzurufen.Wie wird das erreicht? Dies unterscheidet sich nicht von der Logik, die die Plattform selbst zum Generieren von JIT-Code verwendet. Wenn Sie eine Methode zum ersten Mal aufrufen, wird sie kompiliert (und dieser Prozess ist nicht schnell). Bei nachfolgenden Aufrufen wird die Steuerung auf die bereits kompilierte Methode übertragen, und es treten keine besonderen Leistungseinbußen auf.In unserem Fall können Sie auch die JIT-Kompilierung verwenden und dann das kompilierte Verhalten mit der gleichen Leistung wie die AOT-Gegenstücke verwenden. In diesem Fall helfen uns Ausdrücke.Kurz gesagt, wir können das fragliche Prinzip wie folgt formulieren: DasEndergebnis der Reflexion sollte in Form eines Delegaten zwischengespeichert werden, der eine kompilierte Funktion enthält. Es ist auch sinnvoll, alle erforderlichen Objekte mit Informationen zu Typen in Feldern Ihres Typs zwischenzuspeichern, die außerhalb von Objekten gespeichert sind - dem Worker.Darin liegt Logik. Der gesunde Menschenverstand sagt uns, dass etwas getan werden sollte, wenn etwas kompiliert und zwischengespeichert werden kann.Mit Blick auf die Zukunft sollte gesagt werden, dass der Cache beim Arbeiten mit Reflektion seine Vorteile hat, auch wenn Sie die vorgeschlagene Methode zum Kompilieren von Ausdrücken nicht verwenden. Eigentlich wiederhole ich hier einfach die Thesen des Autors des Artikels, auf den ich mich oben beziehe.Nun zum Code. Schauen wir uns ein Beispiel an, das auf meinen jüngsten Schmerzen basiert, denen ich bei der ernsthaften Produktion einer ernsthaften Kreditorganisation ausgesetzt war. Alle Entitäten sind fiktiv, so dass niemand raten würde.Es gibt eine bestimmte Entität. Lass es Kontakt sein. Es gibt Buchstaben mit einem standardisierten Körper, aus denen der Parser und der Hydrator dieselben Kontakte herstellen. Ein Brief ist angekommen, wir haben ihn gelesen, die Schlüssel-Wert-Paare zerlegt, einen Kontakt erstellt und in der Datenbank gespeichert.Das ist elementar. Angenommen, ein Kontakt hat den Namen, das Alter und die Kontaktnummer der Immobilie. Diese Daten werden in einem Brief übermittelt. Außerdem möchte das Unternehmen, dass die Unterstützung in der Lage ist, schnell neue Schlüssel für die Zuordnung von Entitätseigenschaften zu Paaren im Hauptteil des Briefes hinzuzufügen. Falls jemand in die Vorlage eingeprägt ist oder vor der Veröffentlichung, muss dringend mit der Zuordnung von einem neuen Partner begonnen werden, um das neue Format anzupassen. Dann können wir eine neue Mapping-Korrelation als billigen Datenfix hinzufügen. Das heißt, ein Lebensbeispiel.Wir implementieren, erstellen Tests. Funktioniert.Ich werde den Code nicht angeben: Es gab viele Quellen, die auf GitHub über den Link am Ende des Artikels verfügbar sind. Sie können sie herunterladen, bis zur Unkenntlichkeit foltern und messen, da dies Ihren Fall beeinträchtigen würde. Ich werde nur den Code von zwei Vorlagenmethoden angeben, die den Hydrator, der schnell sein sollte, vom Hydrator unterscheiden, der langsam sein sollte.Die Logik lautet wie folgt: Die Vorlagenmethode empfängt die von der Basisparserlogik gebildeten Paare. Die LINQ-Ebene ist ein Parser und die Grundlogik des Hydrators, die eine Anforderung an den Datenbankkontext stellt und Schlüssel mit Paaren aus dem Parser abgleichen (für diese Funktionen gibt es einen Code ohne LINQ zum Vergleich). Als nächstes werden die Paare auf die Haupthydratationsmethode übertragen und die Werte der Paare werden auf die entsprechenden Eigenschaften der Entität gesetzt."Schnell" (schnelles Präfix in Benchmarks): protected override Contact GetContact(PropertyToValueCorrelation[] correlations)
{
var contact = new Contact();
foreach (var setterMapItem in _proprtySettersMap)
{
var correlation = correlations.FirstOrDefault(x => x.PropertyName == setterMapItem.Key);
setterMapItem.Value(contact, correlation?.Value);
}
return contact;
}
Wie wir sehen können, wird eine statische Sammlung mit Eigenschaftssetzern verwendet - kompilierte Lambdas, die die Setter-Entität aufrufen. Generiert mit folgendem Code: static FastContactHydrator()
{
var type = typeof(Contact);
foreach (var property in type.GetProperties())
{
_proprtySettersMap[property.Name] = GetSetterAction(property);
}
}
private static Action<Contact, string> GetSetterAction(PropertyInfo property)
{
var setterInfo = property.GetSetMethod();
var paramValueOriginal = Expression.Parameter(property.PropertyType, "value");
var paramEntity = Expression.Parameter(typeof(Contact), "entity");
var setterExp = Expression.Call(paramEntity, setterInfo, paramValueOriginal).Reduce();
var lambda = (Expression<Action<Contact, string>>)Expression.Lambda(setterExp, paramEntity, paramValueOriginal);
return lambda.Compile();
}
Im Allgemeinen ist es klar. Wir gehen die Eigenschaften um, erstellen Delegaten für sie, die die Setter aufrufen, und speichern sie. Dann rufen wir bei Bedarf an."Langsam" (langsames Präfix in Benchmarks): protected override Contact GetContact(PropertyToValueCorrelation[] correlations)
{
var contact = new Contact();
foreach (var property in _properties)
{
var correlation = correlations.FirstOrDefault(x => x.PropertyName == property.Name);
if (correlation?.Value == null)
continue;
property.SetValue(contact, correlation.Value);
}
return contact;
}
Hier gehen wir sofort um die Eigenschaften herum und rufen SetValue direkt auf.Aus Gründen der Klarheit und als Referenz habe ich eine naive Methode implementiert, die die Werte ihrer Korrelationspaare direkt in die Entitätsfelder schreibt. Das Präfix ist Manuell.Jetzt nehmen wir BenchmarkDotNet und untersuchen die Produktivität. Und plötzlich ... (Spoiler ist nicht das richtige Ergebnis, Details sind unten)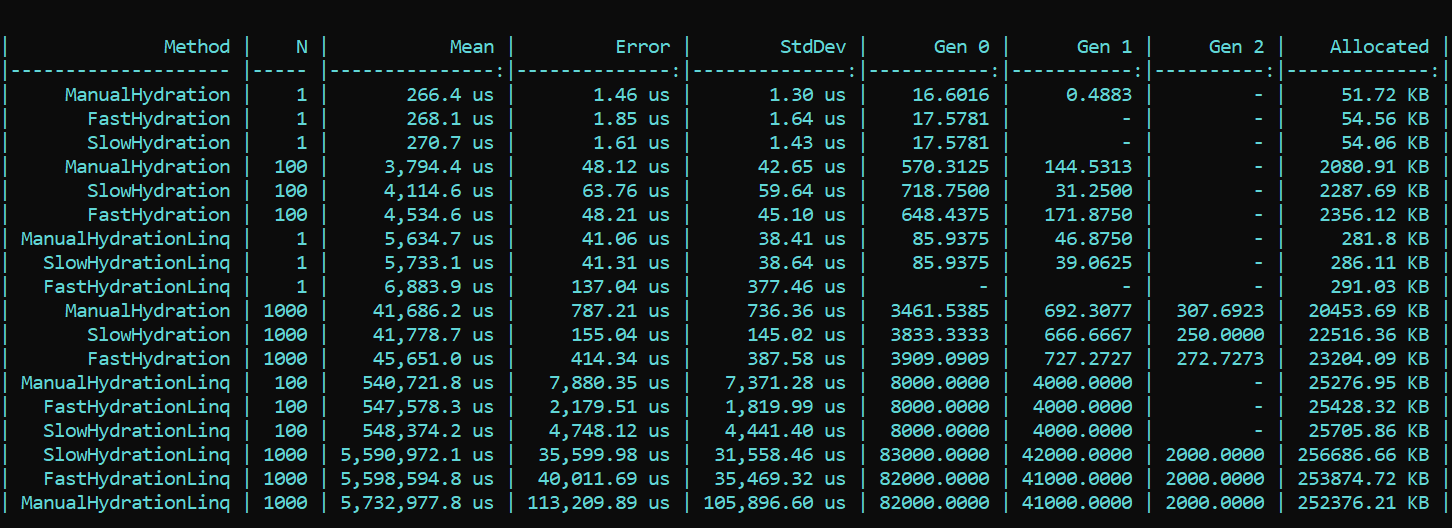 Was sehen wir hier? Methoden, die triumphierend das Fast-Präfix tragen, sind in fast allen Durchgängen langsamer als Methoden mit dem Slow-Präfix. Dies gilt für die Zuordnung und für die Geschwindigkeit. Andererseits verschlechtert die schöne und elegante Implementierung des Mappings mit LINQ-Methoden, die für diesen Zweck entwickelt wurden, die Leistung erheblich. Der Unterschied in den Bestellungen. Der Trend ändert sich nicht mit einer anderen Anzahl von Durchgängen. Der Unterschied liegt nur in der Größenordnung. Wenn LINQ 4 bis 200 Mal langsamer ist, gibt es mehr Schmutz in ungefähr demselben Maßstab.AKTUALISIERTIch konnte meinen Augen nicht trauen, aber was noch wichtiger ist, weder meine Augen noch mein Code wurden von unserem Kollegen - Dmitry Tikhonov 0x1000000 - geglaubt. Nachdem er meine Lösung erneut überprüft hatte, entdeckte er brillant einen Fehler und wies ihn darauf hin, den ich aufgrund einer Reihe von Änderungen in der Implementierung übersehen hatte. Nachdem der gefundene Fehler im Moq-Setup behoben wurde, fielen alle Ergebnisse zusammen. Nach den Ergebnissen des erneuten Tests ändert sich der Haupttrend nicht - LINQ beeinflusst die Leistung ist immer noch stärker als die Reflexion. Es ist jedoch schön, dass die Arbeit mit dem Kompilieren von Ausdrücken nicht umsonst ist und das Ergebnis sowohl in der Zuweisung als auch in der Laufzeit sichtbar ist. Der erste Lauf, wenn statische Felder initialisiert werden, ist bei der "schnellen" Methode natürlich langsamer, aber die Situation ändert sich weiter.Hier ist das Ergebnis des erneuten Tests:
Was sehen wir hier? Methoden, die triumphierend das Fast-Präfix tragen, sind in fast allen Durchgängen langsamer als Methoden mit dem Slow-Präfix. Dies gilt für die Zuordnung und für die Geschwindigkeit. Andererseits verschlechtert die schöne und elegante Implementierung des Mappings mit LINQ-Methoden, die für diesen Zweck entwickelt wurden, die Leistung erheblich. Der Unterschied in den Bestellungen. Der Trend ändert sich nicht mit einer anderen Anzahl von Durchgängen. Der Unterschied liegt nur in der Größenordnung. Wenn LINQ 4 bis 200 Mal langsamer ist, gibt es mehr Schmutz in ungefähr demselben Maßstab.AKTUALISIERTIch konnte meinen Augen nicht trauen, aber was noch wichtiger ist, weder meine Augen noch mein Code wurden von unserem Kollegen - Dmitry Tikhonov 0x1000000 - geglaubt. Nachdem er meine Lösung erneut überprüft hatte, entdeckte er brillant einen Fehler und wies ihn darauf hin, den ich aufgrund einer Reihe von Änderungen in der Implementierung übersehen hatte. Nachdem der gefundene Fehler im Moq-Setup behoben wurde, fielen alle Ergebnisse zusammen. Nach den Ergebnissen des erneuten Tests ändert sich der Haupttrend nicht - LINQ beeinflusst die Leistung ist immer noch stärker als die Reflexion. Es ist jedoch schön, dass die Arbeit mit dem Kompilieren von Ausdrücken nicht umsonst ist und das Ergebnis sowohl in der Zuweisung als auch in der Laufzeit sichtbar ist. Der erste Lauf, wenn statische Felder initialisiert werden, ist bei der "schnellen" Methode natürlich langsamer, aber die Situation ändert sich weiter.Hier ist das Ergebnis des erneuten Tests: Fazit: Wenn Sie Reflection in einem Unternehmen verwenden, ist es nicht besonders erforderlich, auf Tricks zurückzugreifen. LINQ verschlingt die Leistung stärker. Trotzdem kann man bei hoch geladenen Methoden, die eine Optimierung erfordern, die Reflexion in Form von Initialisierern und delegierten Compilern bewahren, die dann eine „schnelle“ Logik liefern. So können Sie die Flexibilität der Reflexion und die Geschwindigkeit der Anwendung beibehalten.Ein Code mit einem Benchmark ist hier verfügbar. Jeder kann meine Worte nocheinmal überprüfen: HabraReflectionTestsPS: Der Code verwendet IoC in den Tests und das explizite Design in den Benchmarks. Tatsache ist, dass ich in der endgültigen Implementierung alle Faktoren zusammenfasse, die die Leistung beeinflussen und Geräusche verursachen können.PPS: Danke an Dmitry Tikhonov @ 0x1000000zum Erkennen meines Fehlers im Moq-Setup, der die ersten Messungen betraf. Wenn einer der Leser genug Karma hat, bitte. Der Mann blieb stehen, der Mann las, der Mann überprüfte noch einmal und zeigte einen Fehler an. Ich denke, das verdient Respekt und Sympathie.PPPS: Dank dieses akribischen Lesers, der Stil und Design auf den Grund gegangen ist. Ich bin für Einheitlichkeit und Bequemlichkeit. Die Diplomatie der Präsentation lässt zu wünschen übrig, aber ich habe die Kritik berücksichtigt. Ich frage nach der Muschel.
Fazit: Wenn Sie Reflection in einem Unternehmen verwenden, ist es nicht besonders erforderlich, auf Tricks zurückzugreifen. LINQ verschlingt die Leistung stärker. Trotzdem kann man bei hoch geladenen Methoden, die eine Optimierung erfordern, die Reflexion in Form von Initialisierern und delegierten Compilern bewahren, die dann eine „schnelle“ Logik liefern. So können Sie die Flexibilität der Reflexion und die Geschwindigkeit der Anwendung beibehalten.Ein Code mit einem Benchmark ist hier verfügbar. Jeder kann meine Worte nocheinmal überprüfen: HabraReflectionTestsPS: Der Code verwendet IoC in den Tests und das explizite Design in den Benchmarks. Tatsache ist, dass ich in der endgültigen Implementierung alle Faktoren zusammenfasse, die die Leistung beeinflussen und Geräusche verursachen können.PPS: Danke an Dmitry Tikhonov @ 0x1000000zum Erkennen meines Fehlers im Moq-Setup, der die ersten Messungen betraf. Wenn einer der Leser genug Karma hat, bitte. Der Mann blieb stehen, der Mann las, der Mann überprüfte noch einmal und zeigte einen Fehler an. Ich denke, das verdient Respekt und Sympathie.PPPS: Dank dieses akribischen Lesers, der Stil und Design auf den Grund gegangen ist. Ich bin für Einheitlichkeit und Bequemlichkeit. Die Diplomatie der Präsentation lässt zu wünschen übrig, aber ich habe die Kritik berücksichtigt. Ich frage nach der Muschel.