Hallo, mein Name ist Alexander Vasin, ich bin ein Backend-Entwickler in Edadil. Die Idee zu diesem Material begann mit der Tatsache, dass ich die Einführungsaufgabe ( Ya.Disk ) in die Yandex Backend Development School analysieren wollte . Ich begann alle Feinheiten der Auswahl bestimmter Technologien, der Testmethode zu beschreiben ... Es stellte sich heraus, dass es sich überhaupt nicht um eine Analyse handelte, sondern um eine sehr detaillierte Anleitung zum Schreiben von Backends in Python. Von der ersten Idee an gab es nur Anforderungen an den Service, an deren Beispiel es zweckmäßig ist, Werkzeuge und Technologien zu zerlegen. Infolgedessen bin ich mit hunderttausend Zeichen aufgewacht. Es war genau so viel erforderlich, um alles im Detail zu betrachten. Also das Programm für die nächsten 100 Kilobyte: Wie man ein Service-Backend erstellt, von der Auswahl der Tools bis zur Bereitstellung. TL; DR: Hier ist ein GitHub-Vertreter mit Anwendungund wer (echte) Longreads liebt - bitte unter Katze.Wir werden den REST-API-Service in Python entwickeln und testen, ihn in einen leichten Docker-Container packen und ihn mit Ansible bereitstellen.
TL; DR: Hier ist ein GitHub-Vertreter mit Anwendungund wer (echte) Longreads liebt - bitte unter Katze.Wir werden den REST-API-Service in Python entwickeln und testen, ihn in einen leichten Docker-Container packen und ihn mit Ansible bereitstellen.Sie können den REST-API-Service mit verschiedenen Tools auf unterschiedliche Weise implementieren. Die beschriebene Lösung ist nicht die einzig richtige. Ich habe die Implementierung und die Tools basierend auf meinen persönlichen Erfahrungen und Vorlieben ausgewählt.
Was werden wir machen?
Stellen Sie sich vor, ein Online-Geschenkeladen plant, eine Aktion in verschiedenen Regionen zu starten. Damit eine Vertriebsstrategie effektiv ist, ist eine Marktanalyse erforderlich. Das Geschäft verfügt über einen Lieferanten, der regelmäßig (z. B. per Post) Daten mit Informationen über die Bewohner entlädt.Lassen Sie uns einen Python-REST-API-Service entwickeln, der die bereitgestellten Daten analysiert und die Nachfrage nach Geschenken von Bewohnern verschiedener Altersgruppen in verschiedenen Städten nach Monat ermittelt.Wir implementieren die folgenden Handler im Service:POST /imports
Fügt einen neuen Upload mit Daten hinzu.
GET /imports/$import_id/citizens
Gibt die Bewohner der angegebenen Entlastung zurück;
PATCH /imports/$import_id/citizens/$citizen_id
Ändert Informationen über den Bewohner (und seine Verwandten) in der angegebenen Entladung;
GET /imports/$import_id/citizens/birthdays
, ( ), ;
GET /imports/$import_id/towns/stat/percentile/age
50-, 75- 99- ( ) .
?
Wir schreiben also einen Dienst in Python unter Verwendung vertrauter Frameworks, Bibliotheken und DBMS.In 4 Vorlesungen des Videokurses werden verschiedene DBMS und deren Funktionen beschrieben. Für meine Implementierung habe ich das PostgreSQL- DBMS ausgewählt , das sich als zuverlässige Lösung mit hervorragender Dokumentation auf Russisch , einer starken russischen Community (Sie können die Antwort auf eine Frage immer auf Russisch finden) und sogar kostenlosen Kursen etabliert hat . Das relationale Modell ist sehr vielseitig und wird von vielen Entwicklern gut verstanden. Obwohl das Gleiche mit jedem NoSQL-DBMS möglich ist, werden wir in diesem Artikel PostgreSQL betrachten.Das Hauptziel des Dienstes - die Datenübertragung über das Netzwerk zwischen der Datenbank und den Clients - bedeutet keine große Belastung des Prozessors, sondern die Fähigkeit, mehrere Anforderungen gleichzeitig zu verarbeiten. In 10 Vorlesungen als asynchroner Ansatz betrachtet. Sie können damit mehrere Clients innerhalb desselben Betriebssystemprozesses effizient bedienen (im Gegensatz zum Beispiel zum in Flask / Django verwendeten Pre-Fork-Modell, das mehrere Prozesse für die Verarbeitung von Benutzeranforderungen erstellt, von denen jeder Speicher verbraucht, aber die meiste Zeit im Leerlauf ist ) Daher habe ich als Bibliothek zum Schreiben des Dienstes das asynchrone aiohttp gewählt . Die 5. Vorlesung des Videokurses erzählt, dass SQLAlchemy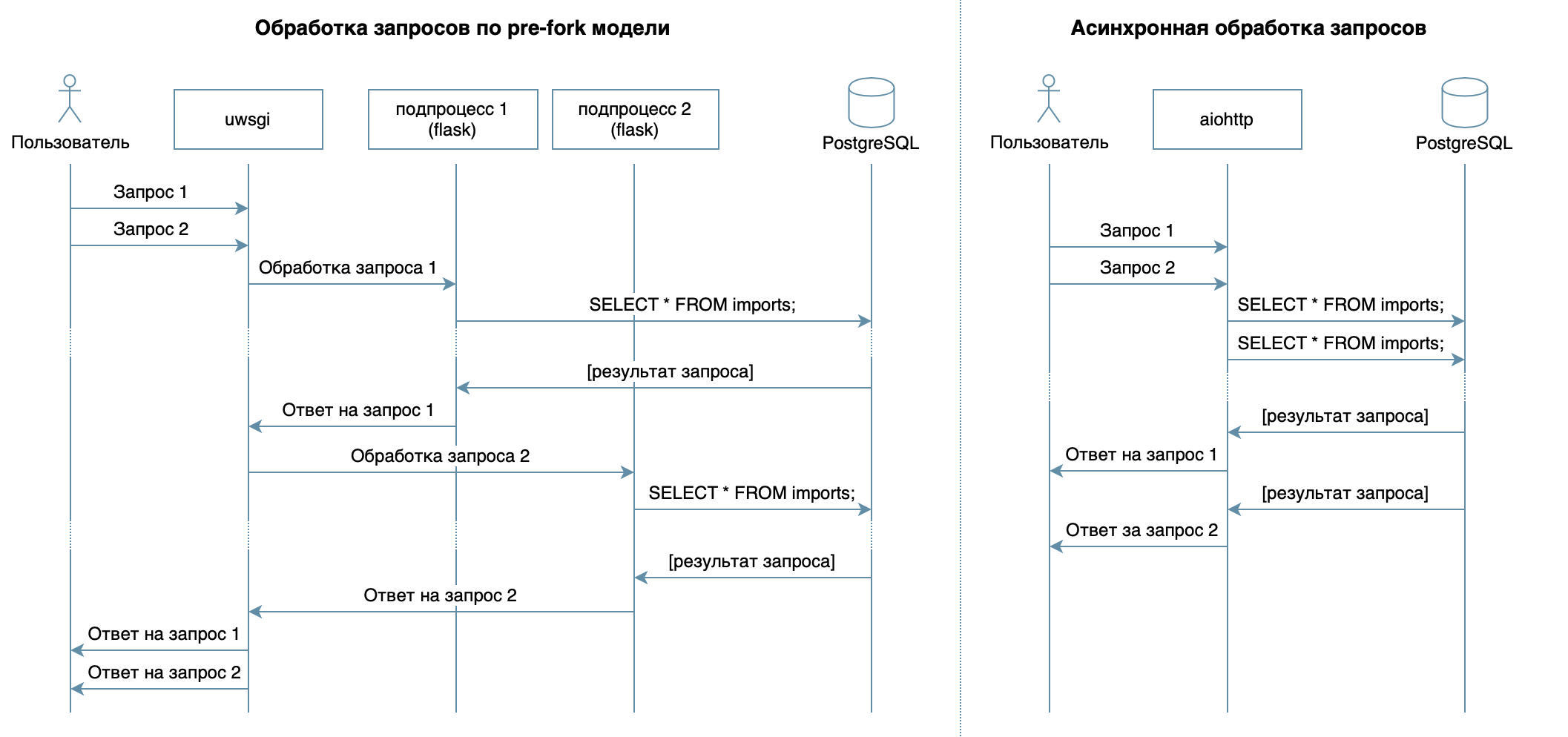 Mit dieser Option können Sie komplexe Abfragen in Teile zerlegen, wiederverwenden, Abfragen mit einem dynamischen Satz von Feldern generieren (z. B. ermöglicht der PATCH-Prozessor die teilweise Aktualisierung eines Bewohners mit beliebigen Feldern) und sich direkt auf die Geschäftslogik konzentrieren. Der asyncpg- Treiber kann diese Anforderungen verarbeiten und die Daten am schnellsten übertragen . Asyncpgsa hilft ihnen dabei, Freunde zu finden .Mein Lieblingswerkzeug zum Verwalten des Datenbankstatus und zum Arbeiten mit Migrationen ist Alembic . Übrigens habe ich kürzlich in Moscow Python darüber gesprochen .Die Logik der Validierung wurde durch Marshmallow- Schemata (einschließlich der Überprüfung auf familiäre Bindungen) kurz und bündig beschrieben . Verwenden des Moduls aiohttp-specIch habe Aiohttp-Handler und Schemata für die Datenvalidierung verknüpft. Der Bonus bestand darin, Dokumentation im Swagger- Format zu erstellen und in einer grafischen Oberfläche anzuzeigen .Für das Schreiben von Tests habe ich
Mit dieser Option können Sie komplexe Abfragen in Teile zerlegen, wiederverwenden, Abfragen mit einem dynamischen Satz von Feldern generieren (z. B. ermöglicht der PATCH-Prozessor die teilweise Aktualisierung eines Bewohners mit beliebigen Feldern) und sich direkt auf die Geschäftslogik konzentrieren. Der asyncpg- Treiber kann diese Anforderungen verarbeiten und die Daten am schnellsten übertragen . Asyncpgsa hilft ihnen dabei, Freunde zu finden .Mein Lieblingswerkzeug zum Verwalten des Datenbankstatus und zum Arbeiten mit Migrationen ist Alembic . Übrigens habe ich kürzlich in Moscow Python darüber gesprochen .Die Logik der Validierung wurde durch Marshmallow- Schemata (einschließlich der Überprüfung auf familiäre Bindungen) kurz und bündig beschrieben . Verwenden des Moduls aiohttp-specIch habe Aiohttp-Handler und Schemata für die Datenvalidierung verknüpft. Der Bonus bestand darin, Dokumentation im Swagger- Format zu erstellen und in einer grafischen Oberfläche anzuzeigen .Für das Schreiben von Tests habe ich pytestmehr darüber in 3 Vorlesungen ausgewählt .Zum Debuggen und Profilieren dieses Projekts habe ich den PyCharm-Debugger verwendet ( Vorlesung 9 ).In der Vorlesung 7 wird beschrieben, wie Docker (oder sogar auf einem anderen Betriebssystem) auf einem Computer ausgeführt werden kann, ohne dass die Anwendungsumgebung zum Starten angepasst werden muss und die Anwendung auf dem Server einfach installiert / aktualisiert / gelöscht werden kann.Für die Bereitstellung habe ich Ansible ausgewählt. Sie können den gewünschten Status des Servers und seiner Dienste deklarativ beschreiben, arbeiten über ssh und benötigen keine spezielle Software.Entwicklung
Ich habe beschlossen, dem Python-Paket einen Namen zu geben analyzerund die folgende Struktur zu verwenden: In der Datei habe
In der Datei habe analyzer/__init__.pyich allgemeine Informationen zum Paket veröffentlicht: Beschreibung ( Dokumentzeichenfolge ), Version, Lizenz, Entwicklerkontakte.Es kann mit der eingebauten Hilfe angezeigt werden$ python
>>> import analyzer
>>> help(analyzer)
Help on package analyzer:
NAME
analyzer
DESCRIPTION
REST API, .
PACKAGE CONTENTS
api (package)
db (package)
utils (package)
DATA
__all__ = ('__author__', '__email__', '__license__', '__maintainer__',...
__email__ = 'alvassin@yandex.ru'
__license__ = 'MIT'
__maintainer__ = 'Alexander Vasin'
VERSION
0.0.1
AUTHOR
Alexander Vasin
FILE
/Users/alvassin/Work/backendschool2019/analyzer/__init__.py
Das Paket verfügt über zwei Eingabepunkte - den REST-API-Dienst ( analyzer/api/__main__.py) und das Dienstprogramm zur Verwaltung des Datenbankstatus ( analyzer/db/__main__.py). Dateien werden __main__.pyaus einem bestimmten Grund aufgerufen - erstens zieht ein solcher Name die Aufmerksamkeit auf sich und macht deutlich, dass die Datei ein Einstiegspunkt ist.Zweitens dank dieser Herangehensweise an Einstiegspunkte python -m:
$ python -m analyzer.api --help
$ python -m analyzer.db --help
Warum müssen Sie mit setup.py beginnen?
Mit Blick auf die Zukunft werden wir darüber nachdenken, wie die Anwendung verteilt werden kann: Sie kann in ein Zip-Archiv (sowie ein Rad- / Ei-Archiv), ein RPM-Paket, eine Paketdatei für MacOS gepackt und auf einem Remotecomputer, in einer virtuellen Maschine, einem MacBook oder Docker installiert werden. Container.Der Hauptzweck der Datei setup.pybesteht darin, das Paket mit der Anwendung für zu beschreiben . Die Datei muss allgemeine Informationen zum Paket enthalten (Name, Version, Autor usw.). Sie können jedoch auch die für die Arbeit erforderlichen Module, zusätzliche Abhängigkeiten (z. B. zum Testen) und Einstiegspunkte (z. B. ausführbare Befehle) angeben ) und Anforderungen an den Dolmetscher. Mit Setuptools-Plugins können Sie Artefakte aus dem beschriebenen Paket sammeln. Es gibt eingebaute Plugins: zip, Ei, U / min, macOS pkg. Die restlichen Plugins werden über PyPI verteilt: Rad ,distutils/setuptoolsxar , pex .Unter dem Strich, wenn wir eine Datei beschreiben, erhalten wir großartige Möglichkeiten. Deshalb muss die Entwicklung eines neuen Projekts beginnen setup.py.In der Funktion werden setup()abhängige Module durch eine Liste angezeigt:setup(..., install_requires=["aiohttp", "SQLAlchemy"])
Aber ich habe die Abhängigkeiten in separaten Dateien beschrieben requirements.txtund requirements.dev.txtderen Inhalt in verwendet wird setup.py. Es scheint mir flexibler zu sein, und es gibt ein Geheimnis: Später können Sie damit schneller ein Docker-Image erstellen. Abhängigkeiten werden vor der Installation der Anwendung selbst als separater Schritt festgelegt. Wenn Sie den Docker-Container neu erstellen, befindet er sich im Cache.Um setup.pydie Abhängigkeiten aus den Dateien requirements.txtund lesen zu können requirements.dev.txt, wird die Funktion geschrieben:def load_requirements(fname: str) -> list:
requirements = []
with open(fname, 'r') as fp:
for req in parse_requirements(fp.read()):
extras = '[{}]'.format(','.join(req.extras)) if req.extras else ''
requirements.append(
'{}{}{}'.format(req.name, extras, req.specifier)
)
return requirements
Es ist erwähnenswert, dass , setuptoolswenn die Standardmontage Source - Distribution enthält nur die Baugruppendateien .py, .c, .cppund .h. Um eine Abhängigkeitsdatei requirements.txtund requirements.dev.txtdie Tasche zu treffen, sollten sie in der Datei klar angegeben werden MANIFEST.in.setup.py vollständigimport os
from importlib.machinery import SourceFileLoader
from pkg_resources import parse_requirements
from setuptools import find_packages, setup
module_name = 'analyzer'
module = SourceFileLoader(
module_name, os.path.join(module_name, '__init__.py')
).load_module()
def load_requirements(fname: str) -> list:
requirements = []
with open(fname, 'r') as fp:
for req in parse_requirements(fp.read()):
extras = '[{}]'.format(','.join(req.extras)) if req.extras else ''
requirements.append(
'{}{}{}'.format(req.name, extras, req.specifier)
)
return requirements
setup(
name=module_name,
version=module.__version__,
author=module.__author__,
author_email=module.__email__,
license=module.__license__,
description=module.__doc__,
long_description=open('README.rst').read(),
url='https://github.com/alvassin/backendschool2019',
platforms='all',
classifiers=[
'Intended Audience :: Developers',
'Natural Language :: Russian',
'Operating System :: MacOS',
'Operating System :: POSIX',
'Programming Language :: Python',
'Programming Language :: Python :: 3',
'Programming Language :: Python :: 3.8',
'Programming Language :: Python :: Implementation :: CPython'
],
python_requires='>=3.8',
packages=find_packages(exclude=['tests']),
install_requires=load_requirements('requirements.txt'),
extras_require={'dev': load_requirements('requirements.dev.txt')},
entry_points={
'console_scripts': [
'{0}-api = {0}.api.__main__:main'.format(module_name),
'{0}-db = {0}.db.__main__:main'.format(module_name)
]
},
include_package_data=True
)
Sie können ein Projekt im Entwicklungsmodus mit dem folgenden Befehl installieren (im bearbeitbaren Modus installiert Python nicht das gesamte Paket in einem Ordner site-packages, sondern erstellt nur Links, sodass alle an den Paketdateien vorgenommenen Änderungen sofort sichtbar sind):
pip install -e '.[dev]'
pip install -e .
Wie werden Abhängigkeitsversionen angegeben?
Es ist großartig, wenn Entwickler aktiv an ihren Paketen arbeiten - Fehler werden aktiv in ihnen behoben, neue Funktionen werden angezeigt und Feedback kann schneller eingeholt werden. Manchmal sind Änderungen in abhängigen Bibliotheken jedoch nicht abwärtskompatibel und können zu Fehlern in Ihrer Anwendung führen, wenn Sie nicht vorher darüber nachdenken.Für jedes abhängige Paket können Sie beispielsweise eine bestimmte Version angeben aiohttp==3.6.2. Dann wird garantiert, dass die Anwendung speziell mit den Versionen der abhängigen Bibliotheken erstellt wird, mit denen sie getestet wurde. Dieser Ansatz hat jedoch einen Nachteil: Wenn Entwickler einen kritischen Fehler in einem abhängigen Paket beheben, der die Abwärtskompatibilität nicht beeinträchtigt, wird dieser Fix nicht in die Anwendung übernommen.Es gibt einen Ansatz zur Versionierung der semantischen Versionierung, was vorschlägt, die Version im Format einzureichen MAJOR.MINOR.PATCH:MAJOR - erhöht sich, wenn rückwärts inkompatible Änderungen hinzugefügt werden;MINOR - Erhöht sich beim Hinzufügen neuer Funktionen mit Unterstützung der Abwärtskompatibilität.PATCH - erhöht sich beim Hinzufügen von Fehlerkorrekturen mit Abwärtskompatibilitätsunterstützung.
Wenn ein abhängiges Paket diesen Ansatz folgt (von denen die Autoren in der Regel in der Readme und CHANGELOG Dateien berichten), ist es ausreichend , den Wert zu fixieren MAJOR, MINORund den Minimalwert für PATCH-Version zu begrenzen: >= MAJOR.MINOR.PATCH, == MAJOR.MINOR.*.Eine solche Anforderung kann mit dem Operator ~ = implementiert werden . Beispielsweise kann aiohttp~=3.6.2PIP für aiohttpVersion 3.6.3 installiert werden , nicht jedoch für Version 3.7.Wenn Sie das Intervall der Abhängigkeitsversionen angeben, bietet dies einen weiteren Vorteil: Es gibt keine Versionskonflikte zwischen abhängigen Bibliotheken.Wenn Sie eine Bibliothek entwickeln, für die ein anderes Abhängigkeitspaket erforderlich ist, lassen Sie nicht eine bestimmte Version, sondern ein Intervall zu. Dann ist es für die Benutzer Ihrer Bibliothek viel einfacher, sie zu verwenden (plötzlich erfordert ihre Anwendung dasselbe Abhängigkeitspaket, jedoch eine andere Version).Die semantische Versionierung ist nur eine Vereinbarung zwischen Autoren und Verbrauchern von Paketen. Es garantiert nicht, dass Autoren Code ohne Fehler schreiben und in der neuen Version ihres Pakets keinen Fehler machen können.Datenbank
Wir entwerfen das Schema
Die Beschreibung des POST / Imports-Handlers enthält ein Beispiel für das Entladen mit Informationen zu Anwohnern:Beispiel zum Hochladen{
"citizens": [
{
"citizen_id": 1,
"town": "",
"street": " ",
"building": "1675",
"apartment": 7,
"name": " ",
"birth_date": "26.12.1986",
"gender": "male",
"relatives": [2]
},
{
"citizen_id": 2,
"town": "",
"street": " ",
"building": "1675",
"apartment": 7,
"name": " ",
"birth_date": "01.04.1997",
"gender": "male",
"relatives": [1]
},
{
"citizen_id": 3,
"town": "",
"street": " ",
"building": "2",
"apartment": 11,
"name": " ",
"birth_date": "23.11.1986",
"gender": "female",
"relatives": []
},
...
]
}
Der erste Gedanke war, alle Informationen über den Bewohner in einer Tabelle zu speichern citizens, in der die Beziehung durch ein Feld relativesin Form einer Liste von ganzen Zahlen dargestellt wird .Diese Methode hat jedoch mehrere NachteileGET /imports/$import_id/citizens/birthdays , , citizens . relatives UNNEST.
, 10- :
SELECT
relations.citizen_id,
relations.relative_id,
date_part('month', relatives.birth_date) as relative_birth_month
FROM (
SELECT
citizens.import_id,
citizens.citizen_id,
UNNEST(citizens.relatives) as relative_id
FROM citizens
WHERE import_id = 1
) as relations
INNER JOIN citizens as relatives ON
relations.import_id = relatives.import_id AND
relations.relative_id = relatives.citizen_id
relatives PostgreSQL, : relatives , . ( ) .
Außerdem habe ich beschlossen, alle für die Arbeit erforderlichen Daten auf eine dritte Normalform zu bringen , und die folgende Struktur wurde erhalten:
- Die Importtabelle besteht aus einer automatisch inkrementierenden Spalte
import_id. Es ist erforderlich, eine Fremdschlüsselprüfung in der Tabelle zu erstellen citizens.
- In der Bürger- Tabelle werden skalare Daten zum Bewohner gespeichert (alle Felder außer Informationen zu familiären Beziehungen).
Ein Paar ( import_id, citizen_id) wird als Primärschlüssel verwendet , um die Eindeutigkeit der Bewohner citizen_idinnerhalb des Rahmens zu gewährleisten import_id.
Ein Fremdschlüssel citizens.import_id -> imports.import_idstellt sicher, dass das Feld citizens.import_idnur vorhandene Entladungen enthält.
- relations .
( ): citizens relations .
(import_id, citizen_id, relative_id) , import_id citizen_id c relative_id.
: (relations.import_id, relations.citizen_id) -> (citizens.import_id, citizens.citizen_id) (relations.import_id, relations.relative_id) -> (citizens.import_id, citizens.citizen_id), , citizen_id relative_id .
Diese Struktur stellt die Integrität der Daten mithilfe von PostgreSQL-Tools sicher. Sie ermöglicht es Ihnen , Bewohner mit Verwandten effizient aus der Datenbank zu holen. Sie unterliegt jedoch einer Race-Bedingung, wenn Informationen über Bewohner mit Wettbewerbsanfragen aktualisiert werden (wir werden uns die Implementierung des PATCH-Handlers genauer ansehen).Beschreiben Sie das Schema in SQLAlchemy
In Kapitel 5 habe ich darüber gesprochen, wie Abfragen mit SQLAlchemy erstellt werden. Sie müssen das Datenbankschema mit speziellen Objekten beschreiben: Tabellen werden mit beschrieben sqlalchemy.Tableund an eine Registrierung gebunden sqlalchemy.MetaData, in der alle Metainformationen über die Datenbank gespeichert sind. Übrigens kann die Registrierung MetaDatanicht nur die in Python beschriebenen Metainformationen speichern, sondern auch den tatsächlichen Status der Datenbank in Form von SQLAlchemy-Objekten darstellen.Mit dieser Funktion kann Alembic auch Bedingungen vergleichen und automatisch einen Migrationscode generieren.Übrigens hat jede Datenbank ihr eigenes Benennungsschema für Standardeinschränkungen. Damit Sie keine Zeit damit verschwenden, neue Einschränkungen zu benennen oder zu suchen / abzurufen, welche Einschränkung Sie entfernen möchten, empfiehlt SQLAlchemy die Verwendung von Namenskonventionen für Namensmuster . Sie können in der Registrierung definiert werden MetaData.Erstellen Sie eine MetaData-Registrierung und übergeben Sie ihr Namensmuster
from sqlalchemy import MetaData
convention = {
'all_column_names': lambda constraint, table: '_'.join([
column.name for column in constraint.columns.values()
]),
'ix': 'ix__%(table_name)s__%(all_column_names)s',
'uq': 'uq__%(table_name)s__%(all_column_names)s',
'ck': 'ck__%(table_name)s__%(constraint_name)s',
'fk': 'fk__%(table_name)s__%(all_column_names)s__%(referred_table_name)s',
'pk': 'pk__%(table_name)s'
}
metadata = MetaData(naming_convention=convention)
Wenn Sie Namensmuster angeben, verwendet Alembic diese während der automatischen Generierung von Migrationen und benennt alle Einschränkungen entsprechend. In Zukunft muss die erstellte Registrierung MetaDatadie Tabellen beschreiben:Wir beschreiben das Datenbankschema mit SQLAlchemy-Objekten
from enum import Enum, unique
from sqlalchemy import (
Column, Date, Enum as PgEnum, ForeignKey, ForeignKeyConstraint, Integer,
String, Table
)
@unique
class Gender(Enum):
female = 'female'
male = 'male'
imports_table = Table(
'imports',
metadata,
Column('import_id', Integer, primary_key=True)
)
citizens_table = Table(
'citizens',
metadata,
Column('import_id', Integer, ForeignKey('imports.import_id'),
primary_key=True),
Column('citizen_id', Integer, primary_key=True),
Column('town', String, nullable=False, index=True),
Column('street', String, nullable=False),
Column('building', String, nullable=False),
Column('apartment', Integer, nullable=False),
Column('name', String, nullable=False),
Column('birth_date', Date, nullable=False),
Column('gender', PgEnum(Gender, name='gender'), nullable=False),
)
relations_table = Table(
'relations',
metadata,
Column('import_id', Integer, primary_key=True),
Column('citizen_id', Integer, primary_key=True),
Column('relative_id', Integer, primary_key=True),
ForeignKeyConstraint(
('import_id', 'citizen_id'),
('citizens.import_id', 'citizens.citizen_id')
),
ForeignKeyConstraint(
('import_id', 'relative_id'),
('citizens.import_id', 'citizens.citizen_id')
),
)
Passen Sie Alembic an
Wenn das Datenbankschema beschrieben wird, müssen Migrationen generiert werden. Dazu müssen Sie jedoch zuerst Alembic konfigurieren, was auch in Kapitel 5 erläutert wird .Um den Befehl zu verwenden alembic, müssen Sie die folgenden Schritte ausführen:- Installationspaket:
pip install alembic - Alembic initialisieren :
cd analyzer && alembic init db/alembic.
Dieser Befehl erstellt eine Konfigurationsdatei analyzer/alembic.iniund einen Ordner analyzer/db/alembicmit den folgenden Inhalten:
env.py- Wird jedes Mal angerufen, wenn Sie Alembic starten. Stellt eine Verbindung zur Alembic-Registrierung sqlalchemy.MetaDatamit einer Beschreibung des gewünschten Status der Datenbank her und enthält Anweisungen zum Starten von Migrationen.
script.py.mako - die Vorlage, auf deren Grundlage Migrationen generiert werden.versions - Der Ordner, in dem Alembic Migrationen durchsucht (und generiert).
- Geben Sie die Datenbankadresse in der Datei alembic.ini an:
; analyzer/alembic.ini
[alembic]
sqlalchemy.url = postgresql://user:hackme@localhost/analyzer
- Geben Sie eine Beschreibung des gewünschten Status der Datenbank (Registrierung
sqlalchemy.MetaData) an, damit Alembic automatisch Migrationen generieren kann:
from analyzer.db import schema
target_metadata = schema.metadata
Alembic ist konfiguriert und kann bereits verwendet werden. In unserem Fall weist diese Konfiguration jedoch mehrere Nachteile auf:- Das Dienstprogramm
alembicsucht alembic.iniim aktuellen Arbeitsverzeichnis. Sie alembic.inikönnen den Pfad zum Befehlszeilenargument angeben, dies ist jedoch unpraktisch: Ich möchte den Befehl von jedem Ordner aus ohne zusätzliche Parameter aufrufen können. - Um Alembic für die Arbeit mit einer bestimmten Datenbank zu konfigurieren, müssen Sie die Datei ändern
alembic.ini. Es wäre viel bequemer, beispielsweise die Datenbankeinstellungen für die Umgebungsvariable und / oder ein Befehlszeilenargument anzugeben --pg-url. - Der Name des Dienstprogramms
alembickorreliert nicht sehr gut mit dem Namen unseres Dienstes (und der Benutzer hat möglicherweise überhaupt kein Python und weiß nichts über Alembic). Für den Endbenutzer wäre es viel bequemer, wenn beispielsweise alle ausführbaren Befehle des Dienstes ein gemeinsames Präfix hätten analyzer-*.
Diese Probleme werden mit einem kleinen Wrapper gelöst. analyzer/db/__main__.py:- Alembic verwendet ein Standardmodul zur Verarbeitung von Befehlszeilenargumenten
argparse. Sie können ein optionales Argument --pg-urlmit einem Standardwert aus einer Umgebungsvariablen hinzufügen ANALYZER_PG_URL.
Der Codeimport os
from alembic.config import CommandLine, Config
from analyzer.utils.pg import DEFAULT_PG_URL
def main():
alembic = CommandLine()
alembic.parser.add_argument(
'--pg-url', default=os.getenv('ANALYZER_PG_URL', DEFAULT_PG_URL),
help='Database URL [env var: ANALYZER_PG_URL]'
)
options = alembic.parser.parse_args()
config = Config(file_=options.config, ini_section=options.name,
cmd_opts=options)
config.set_main_option('sqlalchemy.url', options.pg_url)
exit(alembic.run_cmd(config, options))
if __name__ == '__main__':
main()
- Der Pfad zur Datei
alembic.inikann relativ zum Speicherort der ausführbaren Datei und nicht zum aktuellen Arbeitsverzeichnis des Benutzers berechnet werden.
Der Codeimport os
from alembic.config import CommandLine, Config
from pathlib import Path
PROJECT_PATH = Path(__file__).parent.parent.resolve()
def main():
alembic = CommandLine()
options = alembic.parser.parse_args()
if not os.path.isabs(options.config):
options.config = os.path.join(PROJECT_PATH, options.config)
config = Config(file_=options.config, ini_section=options.name,
cmd_opts=options)
alembic_location = config.get_main_option('script_location')
if not os.path.isabs(alembic_location):
config.set_main_option('script_location',
os.path.join(PROJECT_PATH, alembic_location))
exit(alembic.run_cmd(config, options))
if __name__ == '__main__':
main()
Wenn das Dienstprogramm zum Verwalten des Status der Datenbank bereit ist, kann es setup.pyals ausführbarer Befehl mit einem Namen registriert werden , der für den Endbenutzer verständlich ist, z. B analyzer-db.:Registrieren Sie einen ausführbaren Befehl in setup.pyfrom setuptools import setup
setup(..., entry_points={
'console_scripts': [
'analyzer-db = analyzer.db.__main__:main'
]
})
Nach der Neuinstallation des Moduls wird eine Datei generiert env/bin/analyzer-dbund der Befehl analyzer-dbwird verfügbar:$ pip install -e '.[dev]'
Wir generieren Migrationen
Um Migrationen zu generieren, sind zwei Zustände erforderlich: der gewünschte Zustand (den wir mit SQLAlchemy-Objekten beschrieben haben) und der reale Zustand (die Datenbank ist in unserem Fall leer).Ich entschied, dass der einfachste Weg, Postgres zu erhöhen, Docker war, und fügte der Einfachheit halber einen Befehl hinzu make postgres, der einen Container im Hintergrund mit PostgreSQL auf Port 5432 ausführt:Erhöhen Sie PostgreSQL und generieren Sie eine Migration$ make postgres
...
$ analyzer-db revision --message="Initial" --autogenerate
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [alembic.autogenerate.compare] Detected added table 'imports'
INFO [alembic.autogenerate.compare] Detected added table 'citizens'
INFO [alembic.autogenerate.compare] Detected added index 'ix__citizens__town' on '['town']'
INFO [alembic.autogenerate.compare] Detected added table 'relations'
Generating /Users/alvassin/Work/backendschool2019/analyzer/db/alembic/versions/d5f704ed4610_initial.py ... done
Alembic leistet im Allgemeinen gute Arbeit bei der Routinearbeit zur Generierung von Migrationen, aber ich möchte auf Folgendes aufmerksam machen:- Die in den erstellten Tabellen angegebenen Benutzerdatentypen werden automatisch erstellt (in unserem Fall -
gender), aber der Code zum Löschen wird downgradenicht generiert. Wenn Sie die Migration anwenden, zurücksetzen und dann erneut anwenden, führt dies zu einem Fehler, da der angegebene Datentyp bereits vorhanden ist.
Löschen Sie den Geschlechtsdatentyp in der Downgrade-Methodefrom alembic import op
from sqlalchemy import Column, Enum
GenderType = Enum('female', 'male', name='gender')
def upgrade():
...
op.create_table('citizens', ...,
Column('gender', GenderType, nullable=False))
...
def downgrade():
op.drop_table('citizens')
GenderType.drop(op.get_bind())
- In der Methode können
downgradeeinige Aktionen manchmal entfernt werden (wenn wir die gesamte Tabelle löschen, können Sie ihre Indizes nicht separat löschen):
zum Beispieldef downgrade():
op.drop_table('relations')
op.drop_index(op.f('ix__citizens__town'), table_name='citizens')
op.drop_table('citizens')
op.drop_table('imports')
Wenn die Migration behoben und bereit ist, wenden wir sie an:$ analyzer-db upgrade head
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [alembic.runtime.migration] Running upgrade -> d5f704ed4610, Initial
Anwendung
Bevor Sie mit der Erstellung von Handlern beginnen, müssen Sie die aiohttp-Anwendung konfigurieren.Wenn Sie sich aiohttp quickstart ansehen, können Sie so etwas schreibenimport logging
from aiohttp import web
def main():
logging.basicConfig(level=logging.DEBUG)
app = web.Application()
app.router.add_route(...)
web.run_app(app)
Dieser Code wirft eine Reihe von Fragen auf und hat eine Reihe von Nachteilen:- Wie konfiguriere ich die Anwendung? Sie müssen mindestens den Host und den Port für die Verbindung mit Clients sowie Informationen für die Verbindung mit der Datenbank angeben.
Ich möchte dieses Problem wirklich gerne mit Hilfe des Moduls lösen ConfigArgParse: Es erweitert das Standardmodul argparseund ermöglicht die Verwendung von Befehlszeilenargumenten, Umgebungsvariablen (unverzichtbar für die Konfiguration von Docker-Containern) und sogar Konfigurationsdateien (sowie die Kombination dieser Methoden) für die Konfiguration. Mit ConfigArgParsedieser Funktion können Sie auch die Werte der Anwendungskonfigurationsparameter überprüfen.
Ein Beispiel für die Verarbeitung von Parametern mit ConfigArgParsefrom aiohttp import web
from configargparse import ArgumentParser, ArgumentDefaultsHelpFormatter
from analyzer.utils.argparse import positive_int
parser = ArgumentParser(
auto_env_var_prefix='ANALYZER_',
formatter_class=ArgumentDefaultsHelpFormatter
)
parser.add_argument('--api-address', default='0.0.0.0',
help='IPv4/IPv6 address API server would listen on')
parser.add_argument('--api-port', type=positive_int, default=8081,
help='TCP port API server would listen on')
def main():
args = parser.parse_args()
app = web.Application()
web.run_app(app, host=args.api_address, port=args.api_port)
if __name__ == '__main__':
main()
, ConfigArgParse, argparse, ( -h --help). :
$ python __main__.py --help
usage: __main__.py [-h] [--api-address API_ADDRESS] [--api-port API_PORT]
If an arg is specified in more than one place, then commandline values override environment variables which override defaults.
optional arguments:
-h, --help show this help message and exit
--api-address API_ADDRESS
IPv4/IPv6 address API server would listen on [env var: ANALYZER_API_ADDRESS] (default: 0.0.0.0)
--api-port API_PORT TCP port API server would listen on [env var: ANALYZER_API_PORT] (default: 8081)
- — , «» . , .
os.environ.clear(), Python (, asyncio?), , ConfigArgParser.
import os
from typing import Callable
from configargparse import ArgumentParser
from yarl import URL
from analyzer.api.app import create_app
from analyzer.utils.pg import DEFAULT_PG_URL
ENV_VAR_PREFIX = 'ANALYZER_'
parser = ArgumentParser(auto_env_var_prefix=ENV_VAR_PREFIX)
parser.add_argument('--pg-url', type=URL, default=URL(DEFAULT_PG_URL),
help='URL to use to connect to the database')
def clear_environ(rule: Callable):
"""
,
rule
"""
for name in filter(rule, tuple(os.environ)):
os.environ.pop(name)
def main():
args = parser.parse_args()
clear_environ(lambda i: i.startswith(ENV_VAR_PREFIX))
app = create_app(args)
...
if __name__ == '__main__':
main()
- stderr/ .
9 , logging.basicConfig() stderr.
, . aiomisc.
aiomiscimport logging
from aiomisc.log import basic_config
basic_config(logging.DEBUG, buffered=True)
- , ? ,
fork , (, Windows ).
import os
from sys import argv
import forklib
from aiohttp.web import Application, run_app
from aiomisc import bind_socket
from setproctitle import setproctitle
def main():
sock = bind_socket(address='0.0.0.0', port=8081, proto_name='http')
setproctitle(f'[Master] {os.path.basename(argv[0])}')
def worker():
setproctitle(f'[Worker] {os.path.basename(argv[0])}')
app = Application()
run_app(app, sock=sock)
forklib.fork(os.cpu_count(), worker, auto_restart=True)
if __name__ == '__main__':
main()
- - ? , ( — ) ,
nobody. — .
import os
import pwd
from aiohttp.web import run_app
from aiomisc import bind_socket
from analyzer.api.app import create_app
def main():
sock = bind_socket(address='0.0.0.0', port=8085, proto_name='http')
user = pwd.getpwnam('nobody')
os.setgid(user.pw_gid)
os.setuid(user.pw_uid)
app = create_app(...)
run_app(app, sock=sock)
if __name__ == '__main__':
main()
create_app, .
Alle erfolgreichen Handlerantworten werden im JSON-Format zurückgegeben. Für Clients wäre es auch praktisch, Informationen über Fehler in serialisierter Form zu erhalten (z. B. um festzustellen, welche Felder die Validierung nicht bestanden haben).Die Dokumentation aiohttpbietet eine Methode json_response, mit der ein Objekt übernommen, in JSON serialisiert und ein neues Objekt aiohttp.web.Responsemit einem Header Content-Type: application/jsonund serialisierten Daten zurückgegeben wird.So serialisieren Sie Daten mit json_responsefrom aiohttp.web import Application, View, run_app
from aiohttp.web_response import json_response
class SomeView(View):
async def get(self):
return json_response({'hello': 'world'})
app = Application()
app.router.add_route('*', '/hello', SomeView)
run_app(app)
Es gibt aber noch einen anderen Weg: Mit aiohttp können Sie einen beliebigen Serializer für einen bestimmten Typ von Antwortdaten in der Registrierung registrieren aiohttp.PAYLOAD_REGISTRY. Beispielsweise können Sie einen Serializer aiohttp.JsonPayloadfür Objekte vom Typ Mapping angeben .In diesem Fall reicht es aus, wenn der Handler ein Objekt Responsemit den Antwortdaten im Parameter zurückgibt body. aiohttp findet einen Serializer, der dem Datentyp entspricht, und serialisiert die Antwort.Neben der Tatsache, dass die Serialisierung von Objekten an einer Stelle beschrieben wird, ist dieser Ansatz auch flexibler - Sie können sehr interessante Lösungen implementieren (wir werden einen der Anwendungsfälle im Handler betrachten GET /imports/$import_id/citizens).So serialisieren Sie Daten mit aiohttp.PAYLOAD_REGISTRYfrom types import MappingProxyType
from typing import Mapping
from aiohttp import PAYLOAD_REGISTRY, JsonPayload
from aiohttp.web import run_app, Application, Response, View
PAYLOAD_REGISTRY.register(JsonPayload, (Mapping, MappingProxyType))
class SomeView(View):
async def get(self):
return Response(body={'hello': 'world'})
app = Application()
app.router.add_route('*', '/hello', SomeView)
run_app(app)
Es ist wichtig zu verstehen , dass json_response, wie aiohttp.JsonPayloadsie einen Standard verwenden Methode json.dumps, die sich nicht serialize komplexe Datentypen, zum Beispiel, datetime.dateoder asyncpg.Record( asyncpgkehrt Datensätze aus der Datenbank als Instanzen dieser Klasse). Darüber hinaus können einige komplexe Objekte andere enthalten: In einem Datensatz aus der Datenbank kann sich ein Typfeld befinden datetime.date.Python-Entwickler haben dieses Problem behoben: Mit dieser Methode json.dumpskönnen Sie mithilfe des Arguments defaulteine Funktion angeben, die aufgerufen wird, wenn ein unbekanntes Objekt serialisiert werden muss. Es wird erwartet, dass die Funktion ein unbekanntes Objekt in einen Typ umwandelt, der das JSON-Modul serialisieren kann.So erweitern Sie JsonPayload, um beliebige Objekte zu serialisierenimport json
from datetime import date
from functools import partial, singledispatch
from typing import Any
from aiohttp.payload import JsonPayload as BaseJsonPayload
from aiohttp.typedefs import JSONEncoder
@singledispatch
def convert(value):
raise NotImplementedError(f'Unserializable value: {value!r}')
@convert.register(Record)
def convert_asyncpg_record(value: Record):
"""
,
asyncpg
"""
return dict(value)
@convert.register(date)
def convert_date(value: date):
"""
date —
.
..
"""
return value.strftime('%d.%m.%Y')
dumps = partial(json.dumps, default=convert)
class JsonPayload(BaseJsonPayload):
def __init__(self,
value: Any,
encoding: str = 'utf-8',
content_type: str = 'application/json',
dumps: JSONEncoder = dumps,
*args: Any,
**kwargs: Any) -> None:
super().__init__(value, encoding, content_type, dumps, *args, **kwargs)
Handler
Mit aiohttp können Sie Handler mit asynchronen Funktionen und Klassen implementieren. Klassen sind erweiterbarer: Erstens kann der Code, der zu einem Handler gehört, an einer Stelle platziert werden, und zweitens können Sie mithilfe von Klassen die Vererbung verwenden, um die Codeduplizierung zu beseitigen (z. B. benötigt jeder Handler eine Datenbankverbindung).Handler-Basisklassefrom aiohttp.web_urldispatcher import View
from asyncpgsa import PG
class BaseView(View):
URL_PATH: str
@property
def pg(self) -> PG:
return self.request.app['pg']
Da es schwierig ist, eine große Datei zu lesen, habe ich beschlossen, die Handler in Dateien aufzuteilen. Kleine Dateien fördern eine schwache Konnektivität, und wenn beispielsweise Ringimporte in Handlern vorhanden sind, bedeutet dies, dass möglicherweise etwas mit der Zusammensetzung von Entitäten nicht stimmt.POST / Importe
Der Eingabehandler empfängt json mit Daten über Bewohner. Die maximal zulässige Anforderungsgröße in aiohttp wird von der Option gesteuert client_max_sizeund beträgt standardmäßig 2 MB . Wenn das Limit überschritten wird, gibt aiohttp eine HTTP-Antwort mit dem Status 413: Request Entity Too Large Error zurück.Gleichzeitig wiegt der richtige JSON mit den längsten Zeilen und Zahlen ~ 63 Megabyte, sodass die Einschränkungen für die Größe der Anforderung erweitert werden müssen.Als nächstes müssen Sie die Daten überprüfen und deserialisieren . Wenn sie falsch sind, müssen Sie eine HTTP-Antwort zurückgeben 400: Bad Request.Ich brauchte zwei Pläne Marhsmallow. Der erste CitizenSchemaüberprüft die Daten jedes einzelnen Bewohners und deserialisiert auch die Happy Birthday-Zeichenfolge in das Objekt datetime.date:- Datentyp, Format und Verfügbarkeit aller erforderlichen Felder;
- Mangel an unbekannten Feldern;
- Das Geburtsdatum muss im Format angegeben werden
DD.MM.YYYYund kann für die Zukunft keine Bedeutung haben. - Die Liste der Verwandten jedes Bewohners muss eindeutige Kennungen der in diesem Upload vorhandenen Bewohner enthalten.
Das zweite Schema ImportSchemaüberprüft das gesamte Entladen:citizen_id Jeder Bewohner des Entladens sollte eindeutig sein.- Familienbande sollten wechselseitig sein (wenn Bewohner Nr. 1 einen Bewohner Nr. 2 in der Liste der Verwandten hat, muss Bewohner Nr. 2 auch einen Verwandten Nr. 1 haben).
Wenn die Daten korrekt sind, müssen sie der Datenbank mit einer neuen eindeutigen hinzugefügt werdenimport_id .Um Daten hinzuzufügen, müssen Sie mehrere Abfragen in verschiedenen Tabellen ausführen. Um zu vermeiden, dass im Falle eines Fehlers oder einer Ausnahme teilweise teilweise hinzugefügte Daten in die Datenbank aufgenommen werden (z. B. wenn Sie einen Client trennen, der keine vollständige Antwort erhalten hat, löst aiohttp eine CancelledError-Ausnahme aus ), müssen Sie eine Transaktion verwenden .Es ist erforderlich, Daten in Teilen zu Tabellen hinzuzufügen , da in einer Abfrage an PostgreSQL nicht mehr als 32.767 Argumente vorhanden sein dürfen. Die Tabelle enthält citizens9 Felder. Dementsprechend können für 1 Abfrage nur 32.767 / 9 = 3.640 Zeilen in diese Tabelle eingefügt werden, und in einem Upload können bis zu 10.000 Einwohner vorhanden sein.GET / imports / $ import_id / Bürger
Der Handler gibt alle Bewohner zum Entladen mit der angegebenen zurück import_id. Wenn der angegebene Upload nicht vorhanden ist , müssen Sie die HTTP-Antwort 404: Not Found zurückgeben. Dieses Verhalten scheint bei Handlern üblich zu sein, die eine vorhandene Entladung benötigen. Daher habe ich den Bestätigungscode in eine separate Klasse gezogen.Basisklasse für Handler mit Entladungenfrom aiohttp.web_exceptions import HTTPNotFound
from sqlalchemy import select, exists
from analyzer.db.schema import imports_table
class BaseImportView(BaseView):
@property
def import_id(self):
return int(self.request.match_info.get('import_id'))
async def check_import_exists(self):
query = select([
exists().where(imports_table.c.import_id == self.import_id)
])
if not await self.pg.fetchval(query):
raise HTTPNotFound()
Um eine Liste der Verwandten für jeden Bewohner zu erhalten, müssen Sie LEFT JOINvon Tabelle citizenszu Tabelle arbeiten relationsund das relations.relative_idnach import_idund gruppierte Feld aggregieren citizen_id.Wenn der Bewohner keine Verwandten hat, gibt er LEFT JOINden relations.relative_idWert für ihn vor Ort zurück, NULLund als Ergebnis der Aggregation sieht die Liste der Verwandten so aus [NULL].Um diesen falschen Wert zu beheben, habe ich die Funktion array_remove verwendet .Die Datenbank speichert das Datum in einem Format YYYY-MM-DD, aber wir benötigen ein Format DD.MM.YYYY.Technisch gesehen können Sie das Datum entweder mit einer SQL-Abfrage oder auf der Python-Seite zum Zeitpunkt der Serialisierung der Antwort mit json.dumpsformatieren (asyncpg gibt den Feldwert birth_dateals Instanz der Klasse zurückdatetime.date)Ich habe mich für die Serialisierung auf der Python-Seite entschieden, da dies birth_datedas einzige Objekt datetime.dateim Projekt mit einem einzigen Format ist (siehe Abschnitt „Serialisierung von Daten“ ).Trotz der Tatsache, dass der Prozessor zwei Anforderungen ausführt (Überprüfung auf das Vorhandensein eines Entladens und eine Anforderung für eine Liste von Bewohnern), ist es nicht erforderlich, eine Transaktion zu verwenden . Standardmäßig verwendet PostgreSQL die Isolationsstufe, READ COMMITTEDund selbst innerhalb einer Transaktion werden alle Änderungen an anderen, erfolgreich abgeschlossenen Transaktionen sichtbar (Hinzufügen neuer Zeilen, Ändern vorhandener).Der größte Upload in einer Textansicht kann ~ 63 Megabyte dauern - dies ist ziemlich viel, insbesondere wenn man bedenkt, dass mehrere Anforderungen zum Empfangen von Daten gleichzeitig eingehen können. Es gibt eine interessante Möglichkeit , Daten mit dem Cursor aus der Datenbank abzurufen und in Teilen an den Client zu senden .Dazu müssen wir zwei Objekte implementieren:- Ein
SelectQueryTyp - Objekt , AsyncIterabledas Datensätze aus der Datenbank zurückgibt. Beim ersten Aufruf wird eine Verbindung zur Datenbank hergestellt, eine Transaktion geöffnet und ein Cursor erstellt. Während der weiteren Iteration werden Datensätze aus der Datenbank zurückgegeben. Es wird vom Handler zurückgegeben.
SelectQuery Codefrom collections import AsyncIterable
from asyncpgsa.transactionmanager import ConnectionTransactionContextManager
from sqlalchemy.sql import Select
class SelectQuery(AsyncIterable):
"""
, PostgreSQL
, ,
"""
PREFETCH = 500
__slots__ = (
'query', 'transaction_ctx', 'prefetch', 'timeout'
)
def __init__(self, query: Select,
transaction_ctx: ConnectionTransactionContextManager,
prefetch: int = None,
timeout: float = None):
self.query = query
self.transaction_ctx = transaction_ctx
self.prefetch = prefetch or self.PREFETCH
self.timeout = timeout
async def __aiter__(self):
async with self.transaction_ctx as conn:
cursor = conn.cursor(self.query, prefetch=self.prefetch,
timeout=self.timeout)
async for row in cursor:
yield row
- Ein Serializer
AsyncGenJSONListPayload, der über asynchrone Generatoren iterieren, Daten von einem asynchronen Generator an JSON serialisieren und Daten in Teilen an Clients senden kann. Es ist aiohttp.PAYLOAD_REGISTRYals Serializer von Objekten registriert AsyncIterable.
AsyncGenJSONListPayload-Codeimport json
from functools import partial
from aiohttp import Payload
dumps = partial(json.dumps, default=convert, ensure_ascii=False)
class AsyncGenJSONListPayload(Payload):
"""
AsyncIterable,
JSON
"""
def __init__(self, value, encoding: str = 'utf-8',
content_type: str = 'application/json',
root_object: str = 'data',
*args, **kwargs):
self.root_object = root_object
super().__init__(value, content_type=content_type, encoding=encoding,
*args, **kwargs)
async def write(self, writer):
await writer.write(
('{"%s":[' % self.root_object).encode(self._encoding)
)
first = True
async for row in self._value:
if not first:
await writer.write(b',')
else:
first = False
await writer.write(dumps(row).encode(self._encoding))
await writer.write(b']}')
Darüber hinaus ist es im Handler möglich, ein Objekt zu erstellen SelectQuery, eine SQL-Abfrage und eine Funktion zu übergeben, um die Transaktion zu öffnen und an Folgendes zurückzugeben Response body:Handler-Code
from aiohttp.web_response import Response
from aiohttp_apispec import docs, response_schema
from analyzer.api.schema import CitizensResponseSchema
from analyzer.db.schema import citizens_table as citizens_t
from analyzer.utils.pg import SelectQuery
from .query import CITIZENS_QUERY
from .base import BaseImportView
class CitizensView(BaseImportView):
URL_PATH = r'/imports/{import_id:\d+}/citizens'
@docs(summary=' ')
@response_schema(CitizensResponseSchema())
async def get(self):
await self.check_import_exists()
query = CITIZENS_QUERY.where(
citizens_t.c.import_id == self.import_id
)
body = SelectQuery(query, self.pg.transaction())
return Response(body=body)
aiohttpEs erkennt einen registrierten aiohttp.PAYLOAD_REGISTRYSerializer AsyncGenJSONListPayloadfür Objekte vom Typ in der Registrierung AsyncIterable. Dann iteriert der Serializer über das Objekt SelectQueryund sendet Daten an den Client. Beim ersten Aufruf SelectQueryempfängt das Objekt eine Verbindung zur Datenbank, öffnet eine Transaktion und erstellt einen Cursor. Während der weiteren Iteration empfängt es mit dem Cursor Daten aus der Datenbank und gibt sie zeilenweise zurück.Dieser Ansatz ermöglicht es, nicht bei jeder Anforderung Speicher für die gesamte Datenmenge zuzuweisen, hat jedoch eine Besonderheit: Die Anwendung kann den entsprechenden HTTP-Status nicht an den Client zurückgeben, wenn ein Fehler auftritt (schließlich wurden der HTTP-Status, Header bereits an den Client gesendet und Daten werden geschrieben).Wenn eine Ausnahme auftritt, bleibt nichts anderes übrig, als die Verbindung zu trennen. Eine Ausnahme kann natürlich gesichert werden, aber der Client kann nicht genau verstehen, welcher Fehler aufgetreten ist.Andererseits kann eine ähnliche Situation auftreten, selbst wenn der Prozessor alle Daten aus der Datenbank empfängt, das Netzwerk jedoch blinkt, während Daten an den Client übertragen werden - niemand ist davor sicher.PATCH / imports / $ import_id / bürger / $ bürger_id
Der Handler erhält die Kennung des Entladens import_id, des Bewohners citizen_idsowie von json mit den neuen Daten über den Bewohner. Im Falle eines nicht vorhandenen Entladens oder eines residenten Ereignisses muss eine HTTP-Antwort zurückgegeben werden 404: Not Found.Die vom Kunden übermittelten Daten müssen überprüft und deserialisiert werden . Wenn sie falsch sind, müssen Sie eine HTTP-Antwort zurückgeben 400: Bad Request. Ich habe ein Marshmallow-Schema implementiert, das Folgendes PatchCitizenSchemaüberprüft:- Art und Format der Daten für die angegebenen Felder.
- Geburtsdatum. Es muss in einem Format angegeben werden
DD.MM.YYYYund kann für die Zukunft nicht von Bedeutung sein. - Eine Liste der Verwandten jedes Bewohners. Es muss eindeutige Kennungen für die Bewohner haben.
Die Existenz der im Feld angegebenen Verwandten relativeskann nicht separat überprüft werden: Wenn der Tabelle ein relationsnicht vorhandener Bewohner hinzugefügt wird, gibt PostgreSQL einen Fehler zurück ForeignKeyViolationError, der verarbeitet werden kann, und der HTTP-Status kann zurückgegeben werden 400: Bad Request.Welcher Status sollte zurückgegeben werden, wenn der Client falsche Daten für einen nicht vorhandenen Bewohner gesendet oder entladen hat ? Es ist semantisch korrekter, zuerst das Vorhandensein eines Entladens und eines Bewohners zu überprüfen (wenn es keine gibt, Rückgabe 404: Not Found) und erst dann, ob der Client die richtigen Daten gesendet hat (wenn nicht, Rückgabe 400: Bad Request). In der Praxis ist es oft günstiger, die Daten zuerst zu überprüfen und nur dann auf die Datenbank zuzugreifen, wenn sie korrekt sind.Beide Optionen sind akzeptabel, aber ich habe mich für eine günstigere zweite Option entschieden, da das Ergebnis der Operation in jedem Fall ein Fehler ist, der nichts beeinflusst (der Client korrigiert die Daten und stellt dann auch fest, dass der Bewohner nicht existiert).Wenn die Daten korrekt sind, müssen die Informationen über den Bewohner in der Datenbank aktualisiert werden . Im Handler müssen Sie mehrere Abfragen an verschiedene Tabellen durchführen. Wenn ein Fehler oder eine Ausnahme auftritt, müssen die Änderungen an der Datenbank rückgängig gemacht werden, sodass Abfragen in einer Transaktion ausgeführt werden müssen .Mit dieser Methode PATCH können Sie nur einige Felder für einen Bewohner übertragen.Der Handler muss so geschrieben sein, dass er beim Zugriff auf Daten, die der Client nicht angegeben hat, nicht abstürzt und keine Abfragen für Tabellen ausführt, in denen sich die Daten nicht geändert haben.Wenn der Kunde das Feld angegeben hat relatives, muss eine Liste der vorhandenen Verwandten abgerufen werden. Wenn es sich geändert hat, bestimmen Sie, welche Datensätze aus der Tabelle relativesgelöscht und welche hinzugefügt werden müssen, um die Datenbank mit der Anforderung des Clients in Einklang zu bringen. Standardmäßig verwendet PostgreSQL die Transaktionsisolation READ COMMITTED. Dies bedeutet, dass im Rahmen der aktuellen Transaktion Änderungen für vorhandene (sowie neue) Datensätze anderer abgeschlossener Transaktionen sichtbar sind. Dies kann zu einer Rennbedingung zwischen Wettbewerbsanforderungen führen .Angenommen, es wird mit den Bewohnern entladen#1. #2, #3ohne Verwandtschaft. Der Dienst erhält zwei gleichzeitige Anforderungen zum Ändern des Bewohners Nr. 1: {"relatives": [2]}und {"relatives": [3]}. aiohttp erstellt zwei Handler, die gleichzeitig den aktuellen Status des Bewohners von PostgreSQL empfangen.Jeder Handler erkennt keine einzelne verwandte Beziehung und beschließt, eine neue Beziehung mit dem angegebenen Verwandten hinzuzufügen. Infolgedessen hat Einwohner Nr. 1 das gleiche Feld wie Verwandte [2,3]. Dieses Verhalten kann nicht als offensichtlich bezeichnet werden. Es werden zwei Optionen erwartet, um über das Ergebnis des Rennens zu entscheiden: Nur die erste Anforderung abzuschließen und für die zweite eine HTTP-Antwort zurückzugeben
Dieses Verhalten kann nicht als offensichtlich bezeichnet werden. Es werden zwei Optionen erwartet, um über das Ergebnis des Rennens zu entscheiden: Nur die erste Anforderung abzuschließen und für die zweite eine HTTP-Antwort zurückzugeben409: Conflict(damit der Client die Anforderung wiederholt) oder Anforderungen nacheinander auszuführen (die zweite Anforderung wird erst verarbeitet, nachdem die erste abgeschlossen ist).Die erste Option kann durch Aktivieren des Isolationsmodus implementiert werdenSERIALIZABLE. Wenn es während der Verarbeitung der Anforderung bereits jemandem gelungen ist, die Daten zu ändern und festzuschreiben, wird eine Ausnahme ausgelöst, die verarbeitet und der entsprechende HTTP-Status zurückgegeben werden kann.Der Nachteil dieser Lösung - eine große Anzahl von Sperren in PostgreSQL - SERIALIZABLElöst eine Ausnahme aus, selbst wenn Wettbewerbsabfragen die Aufzeichnungen von Bewohnern aus verschiedenen Entladungen ändern.Sie können auch den Empfehlungssperrmechanismus verwenden . Wenn Sie eine solche Sperre erhalten import_id, können wettbewerbsfähige Anforderungen für verschiedene Entladungen parallel ausgeführt werden.Um wettbewerbsfähige Anforderungen in einem Upload zu verarbeiten, können Sie das Verhalten einer der folgenden Optionen implementieren: Die Funktion pg_try_advisory_xact_lockversucht, eine Sperre und zu erhaltenEs gibt das boolesche Ergebnis sofort zurück (wenn es nicht möglich war, die Sperre zu erhalten, kann eine Ausnahme ausgelöst werden) und pg_advisory_xact_lockwartet, bis dieRessource zum Blockieren verfügbar ist (in diesem Fall werden die Anforderungen nacheinander ausgeführt, ich habe mich für diese Option entschieden).Infolgedessen muss der Handler die aktuellen Informationen über den aktualisierten Bewohner zurückgeben . Es war möglich, uns darauf zu beschränken, Daten von seiner Anfrage an den Kunden zurückzugeben (da wir eine Antwort an den Kunden zurücksenden, bedeutet dies, dass es keine Ausnahmen gab und alle Anfragen erfolgreich abgeschlossen wurden). Oder - verwenden Sie das Schlüsselwort RETURNING in Abfragen, die die Datenbank ändern und aus den Ergebnissen eine Antwort generieren. Beide Ansätze würden es uns jedoch nicht erlauben, den Fall mit der Rasse der Staaten zu sehen und zu testen.Es gab keine hohen Lastanforderungen für den Dienst, daher habe ich beschlossen, alle Daten über den Bewohner erneut anzufordern und dem Kunden ein ehrliches Ergebnis aus der Datenbank zurückzugeben.GET / imports / $ import_id / Bürger / Geburtstage
Der Handler berechnet die Anzahl der Geschenke, die jeder Bewohner des Entladens an seine Verwandten erhält (erste Bestellung). Die Nummer wird nach Monat zum Hochladen mit der angegebenen Nummer gruppiert import_id. Bei einem nicht vorhandenen Upload muss eine HTTP-Antwort zurückgegeben werden 404: Not Found.Es gibt zwei Implementierungsoptionen:- Rufen Sie Daten für Einwohner mit Verwandten aus der Datenbank ab und aggregieren Sie auf Python-Seite Daten nach Monat und generieren Sie Listen für die Monate, für die keine Daten in der Datenbank vorhanden sind.
- Kompilieren Sie eine JSON-Anfrage in der Datenbank und fügen Sie Stubs für die fehlenden Monate hinzu.
Ich habe mich für die erste Option entschieden - visuell sieht sie verständlicher und unterstützter aus. Die Anzahl der Geburtstage in einem bestimmten Monat kann ermittelt werden, indem JOINaus der Tabelle mit familiären Bindungen ( relations.citizen_id- dem Bewohner, für den wir die Geburtstage von Verwandten betrachten) die Tabelle citizens(mit dem Geburtsdatum, von dem Sie den Monat erhalten möchten) hervorgeht.Monatswerte dürfen keine führenden Nullen enthalten. Der birth_datemit der Funktion aus dem Feld erhaltene Monat date_partkann eine führende Null enthalten. Um sie zu entfernen, führte ich castzu integerin der SQL - Abfrage.Trotz der Tatsache, dass der Handler zwei Anforderungen erfüllen muss (überprüfen Sie das Vorhandensein des Entladens und erhalten Sie Informationen zu Geburtstagen und Geschenken), ist eine Transaktion nicht erforderlich .Standardmäßig verwendet PostgreSQL den READ COMMITTED-Modus, in dem alle neuen (durch andere Transaktionen hinzugefügten) und vorhandenen (durch andere Transaktionen geänderten) Datensätze in der aktuellen Transaktion sichtbar sind, nachdem sie erfolgreich abgeschlossen wurden.Wenn beispielsweise zum Zeitpunkt des Empfangs der Daten ein neuer Upload hinzugefügt wird, hat dies keine Auswirkungen auf die vorhandenen. Wenn zum Zeitpunkt des Empfangs der Daten eine Anforderung zum Ändern des Bewohners erfüllt ist, sind entweder die Daten noch nicht sichtbar (wenn die Transaktion zum Ändern der Daten noch nicht abgeschlossen wurde) oder die Transaktion wird vollständig abgeschlossen und alle Änderungen werden sofort sichtbar. Die aus der Datenbank erhaltene Integrität wird nicht verletzt.GET / imports / $ import_id / Towns / Stat / Perzentil / Alter
Der Handler berechnet das 50., 75. und 99. Perzentil des Alters (volle Jahre) der Einwohner nach Stadt in der Stichprobe mit der angegebenen import_id. Bei einem nicht vorhandenen Upload muss eine HTTP-Antwort zurückgegeben werden 404: Not Found.Trotz der Tatsache, dass der Prozessor zwei Anforderungen ausführt (Überprüfung auf das Vorhandensein des Entladens und Abrufen einer Liste von Bewohnern), ist es nicht erforderlich, eine Transaktion zu verwenden .Es gibt zwei Implementierungsoptionen:- Holen Sie sich das Alter der Einwohner aus der Datenbank, gruppiert nach Stadt, und berechnen Sie dann auf der Python-Seite die Perzentile mit numpy (das in der Aufgabe als Referenz angegeben wird) und runden Sie auf zwei Dezimalstellen auf.
- PostgreSQL: percentile_cont , SQL-, numpy .
Die zweite Option erfordert weniger Datenübertragung zwischen der Anwendung und PostgreSQL, weist jedoch keine offensichtliche Gefahr auf: In PostgreSQL ist die Rundung mathematisch ( SELECT ROUND(2.5)Rückgabe 3) und in Python - Accounting auf die nächste Ganzzahl ( round(2.5)Rückgabe 2).Um den Handler zu testen, muss die Implementierung in PostgreSQL und Python identisch sein (die Implementierung einer Funktion mit mathematischer Rundung in Python sieht einfacher aus). Es ist anzumerken, dass bei der Berechnung von Perzentilen numpy und PostgreSQL leicht unterschiedliche Zahlen zurückgeben können. Angesichts der Rundung ist dieser Unterschied jedoch nicht erkennbar.Testen
Was muss in dieser Anwendung überprüft werden? Erstens, dass die Handler die Anforderungen erfüllen und die erforderlichen Arbeiten in einer Umgebung ausführen, die so nah wie möglich an der Kampfumgebung liegt. Zweitens funktionieren Migrationen, die den Status der Datenbank ändern, fehlerfrei. Drittens gibt es eine Reihe von Hilfsfunktionen, die auch durch Tests korrekt abgedeckt werden könnten.Ich habe mich wegen seiner Flexibilität und Benutzerfreundlichkeit für das Pytest-Framework entschieden . Es bietet einen leistungsstarken Mechanismus zur Vorbereitung der Umgebung für Tests - Vorrichtungen , dh Funktionen mit einem Dekorateurpytest.mark.fixturederen Namen können durch den Parameter im Test angegeben werden. Wenn pytest einen Parameter mit einem Fixture-Namen in der Testanmerkung erkennt, führt es dieses Fixture aus und übergibt das Ergebnis an den Wert dieses Parameters. Wenn das Gerät ein Generator ist, nimmt der Testparameter den zurückgegebenen Wert an yield, und nach Abschluss des Tests wird der zweite Teil des Geräts ausgeführt, wodurch Ressourcen gelöscht oder Verbindungen geschlossen werden können.Für die meisten Tests benötigen wir eine PostgreSQL-Datenbank. Um Tests voneinander zu isolieren, können Sie vor jedem Test eine separate Datenbank erstellen und nach der Ausführung löschen.Erstellen Sie für jeden Test eine Fixture-Datenbankimport os
import uuid
import pytest
from sqlalchemy import create_engine
from sqlalchemy_utils import create_database, drop_database
from yarl import URL
from analyzer.utils.pg import DEFAULT_PG_URL
PG_URL = os.getenv('CI_ANALYZER_PG_URL', DEFAULT_PG_URL)
@pytest.fixture
def postgres():
tmp_name = '.'.join([uuid.uuid4().hex, 'pytest'])
tmp_url = str(URL(PG_URL).with_path(tmp_name))
create_database(tmp_url)
try:
yield tmp_url
finally:
drop_database(tmp_url)
def test_db(postgres):
"""
, PostgreSQL
"""
engine = create_engine(postgres)
assert engine.execute('SELECT 1').scalar() == 1
engine.dispose()
Das Modul sqlalchemy_utils hat diese Aufgabe unter Berücksichtigung der Funktionen verschiedener Datenbanken und Treiber hervorragend erledigt . Beispielsweise erlaubt PostgreSQL keine Ausführung CREATE DATABASEin einem Transaktionsblock. Beim Erstellen einer Datenbank wird diese in den Autocommit-Modus sqlalchemy_utilsübersetzt psycopg2(der normalerweise alle Anforderungen in einer Transaktion ausführt).Ein weiteres wichtiges Merkmal: Wenn mindestens ein Client mit PostgreSQL verbunden ist, kann die Datenbank nicht gelöscht werden, sqlalchemy_utilstrennt jedoch alle Clients, bevor die Datenbank gelöscht wird . Die Datenbank wird erfolgreich gelöscht, auch wenn ein Test mit aktiven Verbindungen zu ihr hängt.Wir benötigen PostgreSQL in verschiedenen Zuständen: Zum Testen von Migrationen benötigen wir eine saubere Datenbank, während Handler die Anwendung aller Migrationen erfordern. Sie können den Status einer Datenbank mithilfe von Alembic-Befehlen programmgesteuert ändern. Dazu muss das Alembic-Konfigurationsobjekt aufgerufen werden.Erstellen Sie ein Fixture Alembic-Konfigurationsobjektfrom types import SimpleNamespace
import pytest
from analyzer.utils.pg import make_alembic_config
@pytest.fixture()
def alembic_config(postgres):
cmd_options = SimpleNamespace(config='alembic.ini', name='alembic',
pg_url=postgres, raiseerr=False, x=None)
return make_alembic_config(cmd_options)
Bitte beachten Sie, dass Geräte alembic_configeinen Parameter haben postgres- pytestmit dem nicht nur die Abhängigkeit des Tests von Geräten angezeigt werden kann, sondern auch die Abhängigkeiten zwischen Geräten.Mit diesem Mechanismus können Sie die Logik flexibel trennen und sehr präzisen und wiederverwendbaren Code schreiben.Handler
Zum Testen von Handlern ist eine Datenbank mit erstellten Tabellen und Datentypen erforderlich. Um Migrationen anzuwenden, müssen Sie programmgesteuert den Befehl upgrade Alembic aufrufen. Um es aufzurufen, benötigen Sie ein Objekt mit der Alembic-Konfiguration, die wir bereits mit Fixtures definiert haben alembic_config. Die Datenbank mit Migrationen sieht aus wie eine völlig unabhängige Entität und kann als Fixture dargestellt werden:from alembic.command import upgrade
@pytest.fixture
async def migrated_postgres(alembic_config, postgres):
upgrade(alembic_config, 'head')
return postgres
Wenn das Projekt viele Migrationen enthält, kann die Anwendung für jeden Test zu lange dauern. Um den Prozess zu beschleunigen, können Sie eine Datenbank mit einmaligen Migrationen erstellen und diese dann als Vorlage verwenden .Zusätzlich zur Datenbank zum Testen von Handlern benötigen Sie eine laufende Anwendung sowie einen Client, der für die Arbeit mit dieser Anwendung konfiguriert ist. Um das Testen der Anwendung zu vereinfachen, habe ich ihre Erstellung in eine Funktion create_appeingefügt, für deren Ausführung Parameter erforderlich sind : eine Datenbank, ein Port für die REST-API und andere.Argumente zum Starten der Anwendung können auch als separates Gerät dargestellt werden. Um sie zu erstellen, müssen Sie den freien Port zum Ausführen der Testanwendung und die Adresse für die migrierte temporäre Datenbank ermitteln.Um den freien Port zu bestimmen, habe ich das Gerät aiomisc_unused_portaus dem Aiomisc-Paket verwendet.Ein Standard-Fixture aiohttp_unused_portwäre ebenfalls in Ordnung, gibt jedoch eine Funktion zum Ermitteln freier Ports zurück, während aiomisc_unused_portdie Portnummer sofort zurückgegeben wird. Für unsere Anwendung müssen wir nur einen freien Port bestimmen, daher habe ich beschlossen, bei einem Aufruf keine zusätzliche Codezeile zu schreiben aiohttp_unused_port.@pytest.fixture
def arguments(aiomisc_unused_port, migrated_postgres):
return parser.parse_args(
[
'--log-level=debug',
'--api-address=127.0.0.1',
f'--api-port={aiomisc_unused_port}',
f'--pg-url={migrated_postgres}'
]
)
Alle Tests mit Handlern implizieren Anforderungen an die REST-API. Eine direkte Arbeit mit der Anwendung ist aiohttpnicht erforderlich. Aus diesem Grund habe ich ein Gerät erstellt, das die Anwendung startet und mithilfe der Factory aiohttp_clienteinen Standardtest-Client erstellt und zurückgibt, der mit der Anwendung verbunden ist aiohttp.test_utils.TestClient.from analyzer.api.app import create_app
@pytest.fixture
async def api_client(aiohttp_client, arguments):
app = create_app(arguments)
client = await aiohttp_client(app, server_kwargs={
'port': arguments.api_port
})
try:
yield client
finally:
await client.close()
Wenn Sie nun in den Testparametern eine Vorrichtung angeben api_client, geschieht Folgendes:postgres ( migrated_postgres).alembic_config Alembic, ( migrated_postgres).migrated_postgres ( arguments).aiomisc_unused_port ( arguments).arguments ( api_client).api_client .- .
api_client .postgres .
Mit Fixtures können Sie Doppelcode vermeiden, aber zusätzlich zur Vorbereitung der Umgebung in den Tests gibt es einen weiteren potenziellen Ort, an dem viele der gleichen Code-Anwendungsanforderungen auftreten.Wenn wir eine Anfrage stellen, erwarten wir zunächst einen bestimmten HTTP-Status. Zweitens, wenn der Status mit dem erwarteten übereinstimmt, müssen Sie vor dem Arbeiten mit den Daten sicherstellen, dass sie das richtige Format haben. Es ist leicht, hier einen Fehler zu machen und einen Handler zu schreiben, der die richtigen Berechnungen durchführt und das richtige Ergebnis zurückgibt, aber aufgrund des falschen Antwortformats keine automatische Validierung besteht (vergessen Sie beispielsweise, die Antwort mit einem Schlüssel in ein Wörterbuch zu packen data). Alle diese Überprüfungen könnten an einem Ort durchgeführt werden.Im Modulanalyzer.testing Ich habe für jeden Handler eine Hilfsfunktion vorbereitet, die den Status von HTTP sowie das Antwortformat mit Marshmallow überprüft.GET / imports / $ import_id / Bürger
Ich habe beschlossen, mit einem Handler zu beginnen, der Bewohner zurückgibt, da dies sehr nützlich ist, um die Ergebnisse anderer Handler zu überprüfen, die den Status der Datenbank ändern.Ich habe absichtlich keinen Code verwendet, der der Datenbank Daten vom Handler hinzufügt POST /imports, obwohl es nicht schwierig ist, daraus eine separate Funktion zu machen. Der Code der Handler kann geändert werden. Wenn der Code, der der Datenbank hinzugefügt wird, einen Fehler enthält, funktioniert der Test möglicherweise nicht mehr wie beabsichtigt und implizit für Entwickler werden keine Fehler mehr angezeigt.Für diesen Test habe ich folgende Testdatensätze definiert:- Entladen mit mehreren Verwandten. Überprüft, ob für jeden Einwohner eine Liste mit Kennungen von Verwandten korrekt erstellt wird.
- Entladen mit einem Bewohner ohne Verwandte. Überprüft, ob das Feld
relativeseine leere Liste ist (aufgrund LEFT JOINder SQL-Abfrage kann die Liste der Verwandten gleich sein [None]). - Entladen mit einem Bewohner, der ein Verwandter von sich selbst ist.
- Leeres Entladen. Überprüft, ob der Handler das Hinzufügen eines leeren Entladens zulässt und nicht mit einem Fehler abstürzt.
Um den gleichen Test bei jedem Upload separat durchzuführen, habe ich einen anderen sehr leistungsfähigen Pytest-Mechanismus verwendet - die Parametrisierung . Mit diesem Mechanismus können Sie die Testfunktion in den Dekorator einbinden pytest.mark.parametrizeund darin beschreiben, welche Parameter die Testfunktion für jeden einzelnen Testfall annehmen soll.So parametrisieren Sie einen Testimport pytest
from analyzer.utils.testing import generate_citizen
datasets = [
[
generate_citizen(citizen_id=1, relatives=[2, 3]),
generate_citizen(citizen_id=2, relatives=[1]),
generate_citizen(citizen_id=3, relatives=[1])
],
[
generate_citizen(relatives=[])
],
[
generate_citizen(citizen_id=1, name='', gender='male',
birth_date='17.02.2020', relatives=[1])
],
[],
]
@pytest.mark.parametrize('dataset', datasets)
async def test_get_citizens(api_client, dataset):
"""
4 ,
"""
Der Test fügt also den Upload zur Datenbank hinzu. Anschließend erhält er mithilfe einer Anfrage an den Handler Informationen zu den Bewohnern und vergleicht den Referenz-Upload mit dem empfangenen. Aber wie vergleicht man die Bewohner?Jeder Bewohner besteht aus Skalarfeldern und einem Feld relatives- einer Liste von Kennungen von Verwandten. Eine Liste in Python ist ein geordneter Typ, und beim Vergleichen der Reihenfolge der Elemente jeder Liste spielt dies eine Rolle. Beim Vergleichen von Listen mit Geschwistern sollte die Reihenfolge jedoch keine Rolle spielen.Wenn Sie relativesvor dem Vergleich zum Set bringen , funktioniert es beim Vergleich nicht, eine Situation zu finden, in der einer der Bewohner des Feldes relativesDuplikate hat. Wenn Sie die Liste mit den Kennungen von Verwandten sortieren, wird das Problem der unterschiedlichen Reihenfolge der Kennungen von Verwandten umgangen, gleichzeitig werden jedoch Duplikate erkannt.Beim Vergleich zweier Listen mit Bewohnern kann es zu einem ähnlichen Problem kommen: Technisch gesehen ist die Reihenfolge der Bewohner beim Entladen nicht wichtig, es ist jedoch wichtig zu erkennen, ob sich bei einem Entladen zwei Bewohner mit denselben Kennungen befinden und bei dem anderen nicht. Zusätzlich zum Sortieren der Liste mit Verwandten müssen Verwandte für jeden Bewohner die Bewohner bei jedem Entladen arrangieren.Da sich die Aufgabe des Vergleichs von Bewohnern mehr als einmal stellen wird, habe ich zwei Funktionen implementiert: eine zum Vergleichen von zwei Bewohnern und die zweite zum Vergleichen von zwei Listen mit Bewohnern:Bewohner vergleichenfrom typing import Iterable, Mapping
def normalize_citizen(citizen):
"""
"""
return {**citizen, 'relatives': sorted(citizen['relatives'])}
def compare_citizens(left: Mapping, right: Mapping) -> bool:
"""
"""
return normalize_citizen(left) == normalize_citizen(right)
def compare_citizen_groups(left: Iterable, right: Iterable) -> bool:
"""
,
"""
left = [normalize_citizen(citizen) for citizen in left]
left.sort(key=lambda citizen: citizen['citizen_id'])
right = [normalize_citizen(citizen) for citizen in right]
right.sort(key=lambda citizen: citizen['citizen_id'])
return left == right
Um sicherzustellen, dass dieser Handler keine Bewohner anderer Entladungen zurückgibt, habe ich beschlossen, vor jedem Test eine zusätzliche Entladung mit einem Einwohner hinzuzufügen.POST / Importe
Ich habe die folgenden Datensätze zum Testen des Handlers definiert:- Richtige Daten, die voraussichtlich erfolgreich zur Datenbank hinzugefügt werden.
- ( ).
. , , insert , . - ( , ).
, .
- .
, . :)
, aiohttp PostgreSQL 32 767 ( ).
- Leeres Entladen
Der Handler sollte einen solchen Fall berücksichtigen und nicht fallen und versuchen, mit den Bewohnern eine leere Einfügung in den Tisch durchzuführen.
- Bei fehlerhaften Daten wird eine HTTP-Antwort von 400: Bad Request erwartet.
- Geburtsdatum ist falsch (Zukunftsform).
- bürger_id ist innerhalb des Uploads nicht eindeutig.
- Eine Verwandtschaft wird falsch angegeben (es gibt nur von einem Bewohner zum anderen, aber es gibt keine Rückmeldung).
- Der Bewohner hat einen nicht existierenden Verwandten beim Entladen.
- Familienbande sind nicht einzigartig.
Wenn der Prozessor erfolgreich funktioniert hat und die Daten hinzugefügt wurden, müssen Sie die Bewohner zur Datenbank hinzufügen und sie mit dem Standardentladen vergleichen. Um die Bewohner zu erreichen, habe ich den bereits getesteten Handler GET /imports/$import_id/citizensund zum Vergleich eine Funktion verwendet compare_citizen_groups.PATCH / imports / $ import_id / bürger / $ bürger_id
Die Validierung von Daten ähnelt in vielerlei Hinsicht der im Handler beschriebenen, POST /importsmit wenigen Ausnahmen: Es gibt nur einen Bewohner, und der Client kann nur die gewünschten Felder übergeben .Ich habe beschlossen, die folgenden Sätze mit falschen Daten zu verwenden, um zu überprüfen, ob der Handler eine HTTP-Antwort zurückgibt 400: Bad request:- Das Feld ist angegeben, hat jedoch einen falschen Datentyp und / oder ein falsches Format
- Das Geburtsdatum ist falsch (zukünftige Zeit).
- Das Feld
relativesenthält einen Verwandten, der beim Entladen nicht vorhanden ist.
Es muss auch überprüft werden, ob der Handler die Informationen über den Bewohner und seine Verwandten korrekt aktualisiert.Erstellen Sie dazu einen Upload mit drei Einwohnern, von denen zwei Verwandte sind, und senden Sie eine Anfrage mit neuen Werten für alle Skalarfelder und einer neuen relativen Kennung im Feld relatives.Um sicherzustellen, dass der Handler vor dem Test zwischen Bewohnern unterschiedlicher Entladungen unterscheidet (und beispielsweise Bewohner mit denselben Kennungen nicht von anderen Entladungen ändert), habe ich eine zusätzliche Entladung mit drei Bewohnern mit denselben Kennungen erstellt.Der Handler muss die neuen Werte der Skalarfelder speichern, einen neuen angegebenen Verwandten hinzufügen und die Beziehung zu einem alten, nicht angegebenen Verwandten entfernen. Alle Verwandtschaftsänderungen sollten bilateral sein. Bei anderen Entladungen sollten sich keine Änderungen ergeben.Da ein solcher Handler möglicherweise einer Rennbedingung unterliegt (dies wurde im Abschnitt "Entwicklung" erläutert), habe ich zwei zusätzliche Tests hinzugefügt . Einer reproduziert das Problem mit dem Race-Status (erweitert die Handler-Klasse und entfernt die Sperre), der zweite beweist, dass das Problem mit dem Race-Status nicht reproduziert wird.GET / imports / $ import_id / Bürger / Geburtstage
Um diesen Handler zu testen, habe ich die folgenden Datensätze ausgewählt:- Eine Entladung, bei der ein Bewohner in einem Monat einen Verwandten und in einem anderen zwei Verwandte hat.
- Entladen mit einem Bewohner ohne Verwandte. Überprüft, ob der Handler dies bei den Berechnungen nicht berücksichtigt.
- Leeres Entladen. Überprüft, ob der Handler nicht fehlschlägt und das richtige Wörterbuch mit einer Antwort von 12 Monaten zurückgibt.
- Entladen mit einem Bewohner, der ein Verwandter von sich selbst ist. Überprüft, ob ein Bewohner ein Geschenk für den Monat seiner Geburt kauft.
Der Handler muss alle Monate in der Antwort zurückgeben, auch wenn in diesen Monaten keine Geburtstage vorliegen. Um Doppelarbeit zu vermeiden, habe ich eine Funktion erstellt, an die Sie das Wörterbuch übergeben können, damit es mit Werten für fehlende Monate ergänzt wird.Um sicherzustellen, dass der Handler zwischen Bewohnern unterschiedlicher Entladungen unterscheidet, habe ich eine zusätzliche Entladung mit zwei Verwandten hinzugefügt. Wenn der Handler sie fälschlicherweise in den Berechnungen verwendet, sind die Ergebnisse falsch und der Handler fällt mit einem Fehler aus.GET / imports / $ import_id / Towns / Stat / Perzentil / Alter
Die Besonderheit dieses Tests ist, dass die Ergebnisse seiner Arbeit von der aktuellen Zeit abhängen: Das Alter der Einwohner wird anhand des aktuellen Datums berechnet. Um sicherzustellen, dass sich die Testergebnisse im Laufe der Zeit nicht ändern, müssen das aktuelle Datum, das Geburtsdatum der Bewohner und die erwarteten Ergebnisse aufgezeichnet werden. Dies macht es einfach, auch Randfälle zu reproduzieren.Was ist das beste Fixdatum? Im Handler wird zur Berechnung des Alters der Bewohner eine PostgreSQL-Funktion verwendet AGE, die den ersten Parameter als Datum verwendet, für das das Alter berechnet werden muss, und den zweiten als Basisdatum (definiert durch eine Konstante TownAgeStatView.CURRENT_DATE).Wir ersetzen das Basisdatum im Handler durch die Testzeitfrom unittest.mock import patch
import pytz
CURRENT_DATE = datetime(2020, 2, 17, tzinfo=pytz.utc)
@patch('analyzer.api.handlers.TownAgeStatView.CURRENT_DATE', new=CURRENT_DATE)
async def test_get_ages(...):
...
Zum Testen des Handlers habe ich die folgenden Datensätze ausgewählt (für alle Einwohner habe ich eine Stadt angegeben, da der Handler die Ergebnisse nach Stadt aggregiert):- Entladen mit mehreren Bewohnern, deren Geburtstag morgen ist (Alter - mehrere Jahre und 364 Tage). Überprüft, ob der Prozessor nur die Anzahl der vollen Jahre für die Berechnungen verwendet.
- Entladen mit einem Bewohner, dessen Geburtstag heute ist (Alter - genau einige Jahre). Es prüft den regionalen Fall - das Alter eines Bewohners, dessen Geburtstag heute ist, sollte nicht als um 1 Jahr verkürzt berechnet werden.
- Leeres Entladen. Der Handler sollte nicht darauf fallen.
Der numpyBenchmark für die Berechnung von Perzentilen - mit linearer Interpolation - und die Benchmark-Ergebnisse für Tests, die ich für sie berechnet habe.Sie müssen auch die gebrochenen Perzentilwerte auf zwei Dezimalstellen runden. Wenn Sie PostgreSQL zum Runden im Handler und Python zum Berechnen der Referenzdaten verwendet haben, stellen Sie möglicherweise fest, dass das Runden in Python 3 und PostgreSQL zu unterschiedlichen Ergebnissen führen kann .zum Beispiel# Python 3
round(2.5)
> 2
-- PostgreSQL
SELECT ROUND(2.5)
> 3
Tatsache ist, dass Python die Bankrundung auf die nächste Gerade verwendet und PostgreSQL die mathematische (Halbierung) verwendet. Wenn Berechnungen und Rundungen in PostgreSQL durchgeführt werden, ist es richtig, die mathematische Rundung auch in Tests zu verwenden.Zuerst habe ich Datensätze mit Geburtsdaten in einem Textformat beschrieben, aber es war unpraktisch, einen Test in diesem Format zu lesen: Jedes Mal musste ich das Alter jedes Bewohners in meinem Kopf berechnen, um mich daran zu erinnern, was ein bestimmter Datensatz überprüfte. Natürlich könnten Sie mit den Kommentaren im Code auskommen, aber ich habe mich entschlossen, etwas weiter zu gehen und eine Funktion geschrieben age2date, mit der Sie das Geburtsdatum in Form des Alters beschreiben können: die Anzahl der Jahre und Tage.Zum Beispiel soimport pytz
from analyzer.utils.testing import generate_citizen
CURRENT_DATE = datetime(2020, 2, 17, tzinfo=pytz.utc)
def age2date(years: int, days: int = 0, base_date=CURRENT_DATE) -> str:
birth_date = copy(base_date).replace(year=base_date.year - years)
birth_date -= timedelta(days=days)
return birth_date.strftime(BIRTH_DATE_FORMAT)
generate_citizen(birth_date='17.02.2009')
generate_citizen(birth_date=age2date(years=11))
Um sicherzustellen, dass der Handler zwischen Bewohnern unterschiedlicher Entladungen unterscheidet, habe ich eine zusätzliche Entladung mit einem Bewohner einer anderen Stadt hinzugefügt: Wenn der Handler sie versehentlich verwendet, wird in den Ergebnissen eine zusätzliche Stadt angezeigt und der Test wird abgebrochen.Eine interessante Tatsache: Als ich diesen Test am 29. Februar 2020 schrieb, hörte ich aufgrund eines Fehlers in Faker plötzlich auf, Entladungen mit Anwohnern zu generieren (2020 ist ein Schaltjahr, und andere Jahre, die Faker gewählt hatte, waren nicht immer auch Schaltjahre in ihnen war nicht der 29. Februar). Denken Sie daran, Daten aufzuzeichnen und Randfälle zu testen!
Migrationen
Der Migrationscode scheint auf den ersten Blick offensichtlich und am wenigsten fehleranfällig. Warum sollten Sie ihn testen? Dies ist ein sehr gefährlicher Fehler: Die heimtückischsten Fehler von Migrationen können sich im ungünstigsten Moment manifestieren. Selbst wenn sie die Daten nicht verderben, können sie unnötige Ausfallzeiten verursachen.Die im Projekt vorhandene anfängliche Migration ändert die Struktur der Datenbank, jedoch nicht die Daten. Welche häufigen Fehler können vor solchen Migrationen geschützt werden?downgrade ( , , ).
, (--): , — .
- C .
- ( ).
Die meisten dieser Fehler werden beim Treppentest erkannt . Seine Idee - eine einzige Migration zu verwenden, konsequent die Methoden der Durchführung upgrade, downgrade, upgradefür jede Migration. Ein solcher Test reicht aus, um dem Projekt einmal hinzugefügt zu werden. Er erfordert keine Unterstützung und dient treu.Wenn die Migration jedoch zusätzlich zur Struktur die Daten ändern würde, müsste mindestens ein separater Test geschrieben werden, um zu überprüfen, ob sich die Daten in der Methode korrekt ändern upgradeund in den Ausgangszustand zurückkehren downgrade. Nur für den Fall: Ein Projekt mit Beispielen zum Testen verschiedener Migrationen , das ich für einen Bericht über Alembic in Moscow Python vorbereitet habe .Versammlung
Das letzte Artefakt, das wir bereitstellen werden und das wir als Ergebnis der Assembly erhalten möchten, ist ein Docker-Image. Zum Erstellen müssen Sie das Basis-Image mit Python auswählen . Das offizielle Image python:latestwiegt ~ 1 GB und wenn es als Basis-Image verwendet wird, ist das Image mit der Anwendung riesig. Es gibt Bilder, die auf dem alpinen Betriebssystem basieren und deren Größe viel kleiner ist. Mit der wachsenden Anzahl installierter Pakete wächst jedoch die Größe des endgültigen Bildes, und infolgedessen wird auch das auf der Grundlage von Alpine gesammelte Bild nicht so klein sein. Ich habe Snakepacker / Python als Basis-Image gewählt - es wiegt etwas mehr als Alpine-Images, basiert jedoch auf Ubuntu, das eine riesige Auswahl an Paketen und Bibliotheken bietet.Ein anderer WegReduzieren Sie die Größe des Images mit der Anwendung. Fügen Sie im endgültigen Image nicht den Compiler, die Bibliotheken und Dateien mit Headern für die Assembly ein, die für die Funktion der Anwendung nicht erforderlich sind.Dazu können Sie die mehrstufige Baugruppe von Docker verwenden:snakepacker/python:allErstellen Sie mit einem „schweren“ Image (~ 1 GB, ~ 500 MB komprimiert) eine virtuelle Umgebung, installieren Sie alle Abhängigkeiten und das Anwendungspaket darin. Dieses Image wird ausschließlich für die Assembly benötigt. Es kann einen Compiler, alle erforderlichen Bibliotheken und Dateien mit Headern enthalten.
FROM snakepacker/python:all as builder
RUN python3.8 -m venv /usr/share/python3/app
COPY dist/ /mnt/dist/
RUN /usr/share/python3/app/bin/pip install /mnt/dist/*
- Wir kopieren die fertige virtuelle Umgebung in ein "leichtes" Image
snakepacker/python:3.8(~ 100 MB, komprimiert ~ 50 MB), das nur den Interpreter der erforderlichen Version von Python enthält.
Wichtig: In einer virtuellen Umgebung werden absolute Pfade verwendet, daher muss sie an dieselbe Adresse kopiert werden, an der sie im Kollektorcontainer zusammengestellt wurde.
FROM snakepacker/python:3.8 as api
COPY --from=builder /usr/share/python3/app /usr/share/python3/app
RUN ln -snf /usr/share/python3/app/bin/analyzer-* /usr/local/bin/
CMD ["analyzer-api"]
Um die Zeit zum Erstellen des Images zu verkürzen , können die anwendungsabhängigen Module installiert werden, bevor sie in der virtuellen Umgebung installiert werden. Dann werden sie von Docker zwischengespeichert und nicht neu installiert, wenn sie nicht geändert wurden.Dockerfile vollständig
FROM snakepacker/python:all as builder
RUN python3.8 -m venv /usr/share/python3/app
RUN /usr/share/python3/app/bin/pip install -U pip
COPY requirements.txt /mnt/
RUN /usr/share/python3/app/bin/pip install -Ur /mnt/requirements.txt
COPY dist/ /mnt/dist/
RUN /usr/share/python3/app/bin/pip install /mnt/dist/* \
&& /usr/share/python3/app/bin/pip check
FROM snakepacker/python:3.8 as api
COPY --from=builder /usr/share/python3/app /usr/share/python3/app
RUN ln -snf /usr/share/python3/app/bin/analyzer-* /usr/local/bin/
CMD ["analyzer-api"]
Zur Vereinfachung der Montage habe ich einen Befehl hinzugefügt make upload, der das Docker-Image sammelt und auf hub.docker.com hochlädt.Ci
Nachdem der Code mit Tests abgedeckt ist und wir ein Docker-Image erstellen können, ist es Zeit, diese Prozesse zu automatisieren. Das erste, was Ihnen in den Sinn kommt: Führen Sie Tests zum Erstellen von Poolanforderungen durch, und sammeln Sie beim Hinzufügen von Änderungen zum Hauptzweig ein neues Docker-Image und laden Sie es auf den Docker Hub (oder GitHub-Pakete , wenn Sie das Image nicht öffentlich verteilen möchten) hoch .Ich habe dieses Problem mit GitHub Actions gelöst . Dazu musste eine YAML-Datei in einem Ordner erstellt .github/workflowsund darin ein Workflow (mit zwei Aufgaben: testund publish) beschrieben werden, den ich benannt habe CI.Die Aufgabe testwird bei jedem Start des Workflows CImithilfe von Diensten ausgeführtnimmt einen Container mit PostgreSQL auf, wartet darauf, dass er verfügbar ist, und startet pytestim Container snakepacker/python:all.Die Aufgabe publishwird nur ausgeführt, wenn die Änderungen dem Zweig hinzugefügt wurden masterund die Aufgabe testerfolgreich war. Es sammelt die Quellverteilung durch den Container snakepacker/python:all, sammelt und lädt dann das Docker-Image mit docker/build-push-action@v1.Vollständige Beschreibung des Workflowsname: CI
# Workflow
# - master
on:
push:
branches: [ master ]
pull_request:
branches: [ master ]
jobs:
# workflow
test:
runs-on: ubuntu-latest
services:
postgres:
image: docker://postgres
ports:
- 5432:5432
env:
POSTGRES_USER: user
POSTGRES_PASSWORD: hackme
POSTGRES_DB: analyzer
steps:
- uses: actions/checkout@v2
- name: test
uses: docker://snakepacker/python:all
env:
CI_ANALYZER_PG_URL: postgresql://user:hackme@postgres/analyzer
with:
args: /bin/bash -c "pip install -U '.[dev]' && pylama && wait-for-port postgres:5432 && pytest -vv --cov=analyzer --cov-report=term-missing tests"
# Docker-
publish:
# master
if: github.event_name == 'push' && github.ref == 'refs/heads/master'
# , test
needs: test
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: sdist
uses: docker://snakepacker/python:all
with:
args: make sdist
- name: build-push
uses: docker/build-push-action@v1
with:
username: ${{ secrets.REGISTRY_LOGIN }}
password: ${{ secrets.REGISTRY_TOKEN }}
repository: alvassin/backendschool2019
target: api
tags: 0.0.1, latest
Wenn Sie nun auf der Registerkarte Aktionen auf GitHub Änderungen am Master hinzufügen, können Sie den Start von Tests, das Zusammenstellen und Laden des Docker-Images sehen: Wenn Sie eine Poolanforderung im Master-Zweig erstellen, werden auch die Ergebnisse der Aufgabe darin angezeigt
Wenn Sie eine Poolanforderung im Master-Zweig erstellen, werden auch die Ergebnisse der Aufgabe darin angezeigt test:
Bereitstellen
Um die Anwendung auf dem bereitgestellten Server bereitzustellen, müssen Sie Docker, Docker Compose installieren, die Container mit der Anwendung und PostgreSQL starten und die Migrationen anwenden.Diese Schritte können mithilfe des Konfigurationsmanagementsystems von Ansible automatisiert werden. Es ist in Python geschrieben, benötigt keine speziellen Agenten (stellt eine direkte Verbindung über ssh her), verwendet Jinja-Vorlagen und ermöglicht die deklarative Beschreibung des gewünschten Status in YAML-Dateien. Der deklarative Ansatz ermöglicht es Ihnen, nicht über den aktuellen Status des Systems und die erforderlichen Aktionen nachzudenken, um das System in den gewünschten Status zu bringen. All diese Arbeit ruht auf den Schultern der Ansible-Module.Mit Ansible können Sie logisch verwandte Aufgaben in Rollen gruppieren und dann wiederverwenden. Wir brauchen zwei Rollen:docker(installiert und konfiguriert Docker) und analyzer(installiert und konfiguriert die Anwendung).Die Rolledocker fügt dem System ein Repository mit Docker hinzu, installiert und konfiguriert Pakete docker-ceund docker-compose.Optional können Sie festlegen, dass die REST-API nach einem Neustart des Servers automatisch fortgesetzt wird. Mit Ubuntu können Sie dieses Problem mithilfe eines Initialisierungssystems lösen systemd. Es steuert Einheiten, die verschiedene Ressourcen darstellen (Dämonen, Sockets, Mount-Punkte und andere). Um systemd eine neue Einheit hinzuzufügen, müssen Sie deren Konfiguration in einer separaten .service-Datei beschreiben und diese Datei in einem der speziellen Ordner ablegen, z /etc/systemd/system. Dann kann das Gerät gestartet und das automatische Laden aktiviert werden.Paketdocker-ceWährend der Installation wird automatisch eine Datei mit der Gerätekonfiguration erstellt. Sie müssen nur sicherstellen, dass sie ausgeführt wird und sich beim Systemstart einschaltet. Für Docker wird Compose docker-compose@.servicevon Ansible erstellt. Das Symbol @im Namen zeigt systemd an, dass das Gerät eine Vorlage ist. Auf diese Weise können Sie den Dienst docker-composemit einem Parameter starten, z. B. mit dem Namen unseres Dienstes, der anstelle der %iGerätekonfigurationsdatei ersetzt wird:[Unit]
Description=%i service with docker compose
Requires=docker.service
After=docker.service
[Service]
Type=oneshot
RemainAfterExit=true
WorkingDirectory=/etc/docker/compose/%i
ExecStart=/usr/local/bin/docker-compose up -d --remove-orphans
ExecStop=/usr/local/bin/docker-compose down
[Install]
WantedBy=multi-user.target
Die Rolleanalyzer generiert eine Datei aus der Vorlage docker-compose.ymlan der Adresse /etc/docker/compose/analyzer, registriert die Anwendung als automatisch gestarteten Dienst in systemdund wendet die Migration an. Wenn die Rollen fertig sind, müssen Sie das Playbook beschreiben.---
- name: Gathering facts
hosts: all
become: yes
gather_facts: yes
- name: Install docker
hosts: docker
become: yes
gather_facts: no
roles:
- docker
- name: Install analyzer
hosts: api
become: yes
gather_facts: no
roles:
- analyzer
Die Liste der Hosts sowie die in den Rollen verwendeten Variablen können in der Inventardatei angegeben werden hosts.ini.[api]
130.193.51.154
[docker:children]
api
[api:vars]
analyzer_image = alvassin/backendschool2019
analyzer_pg_user = user
analyzer_pg_password = hackme
analyzer_pg_dbname = analyzer
Nachdem alle Ansible-Dateien fertig sind, führen Sie sie aus:$ ansible-playbook -i hosts.ini deploy.yml
Über Stresstests, , . , -
. : , — , 10 . , (, , CI-): .
, , , 10 . ? , , . , , .
RPS, : . , ,
import_id,
POST /imports . .
, Python 3,
Locust.
,
locustfile.py locust. - .
Locust . , .
self.round .
locustfile.py
import logging
from http import HTTPStatus
from locust import HttpLocust, constant, task, TaskSet
from locust.exception import RescheduleTask
from analyzer.api.handlers import (
CitizenBirthdaysView, CitizensView, CitizenView, TownAgeStatView
)
from analyzer.utils.testing import generate_citizen, generate_citizens, url_for
class AnalyzerTaskSet(TaskSet):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.round = 0
def make_dataset(self):
citizens = [
generate_citizen(citizen_id=1, relatives=[2]),
generate_citizen(citizen_id=2, relatives=[1]),
*generate_citizens(citizens_num=9998, relations_num=1000,
start_citizen_id=3)
]
return {citizen['citizen_id']: citizen for citizen in citizens}
def request(self, method, path, expected_status, **kwargs):
with self.client.request(
method, path, catch_response=True, **kwargs
) as resp:
if resp.status_code != expected_status:
resp.failure(f'expected status {expected_status}, '
f'got {resp.status_code}')
logging.info(
'round %r: %s %s, http status %d (expected %d), took %rs',
self.round, method, path, resp.status_code, expected_status,
resp.elapsed.total_seconds()
)
return resp
def create_import(self, dataset):
resp = self.request('POST', '/imports', HTTPStatus.CREATED,
json={'citizens': list(dataset.values())})
if resp.status_code != HTTPStatus.CREATED:
raise RescheduleTask
return resp.json()['data']['import_id']
def get_citizens(self, import_id):
url = url_for(CitizensView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens')
def update_citizen(self, import_id):
url = url_for(CitizenView.URL_PATH, import_id=import_id, citizen_id=1)
self.request('PATCH', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens/{citizen_id}',
json={'relatives': [i for i in range(3, 10)]})
def get_birthdays(self, import_id):
url = url_for(CitizenBirthdaysView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens/birthdays')
def get_town_stats(self, import_id):
url = url_for(TownAgeStatView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/towns/stat/percentile/age')
@task
def workflow(self):
self.round += 1
dataset = self.make_dataset()
import_id = self.create_import(dataset)
self.get_citizens(import_id)
self.update_citizen(import_id)
self.get_birthdays(import_id)
self.get_town_stats(import_id)
class WebsiteUser(HttpLocust):
task_set = AnalyzerTaskSet
wait_time = constant(1)
100 c , , :

, ( — 95 , — ). .

— Ansible ~20.15 ~20.30 Locust.

Was kann man noch tun?
Die Profilerstellung der Anwendung ergab, dass etwa ein Viertel der gesamten Ausführungszeit für Abfragen für die JSON-Serialisierung und -Deserialisierung aufgewendet wird: Es werden viele Daten vom Dienst gesendet und empfangen. Diese Prozesse können mithilfe der Orjson- Bibliothek erheblich beschleunigt werden , der Service muss jedoch ein wenig vorbereitet werden - orjsones handelt sich nicht um einen Ersatz für das Standardmodul. jsonNormalerweise erfordert die Produktion mehrere Kopien des Service, um Fehlertoleranz zu gewährleisten und die Last zu bewältigen. Um eine Gruppe von Diensten zu verwalten, benötigen Sie ein Tool, das anzeigt, ob eine Kopie des Dienstes "lebendig" ist. Dieses Problem kann durch einen Handler gelöst werden /health, der alle für die Arbeit erforderlichen Ressourcen abfragt, in unserem Fall eine Datenbank. WennSELECT 1In weniger als einer Sekunde ausgeführt, ist der Dienst aktiv. Wenn nicht, müssen Sie darauf achten.Wenn eine Anwendung sehr intensiv mit einem Netzwerk arbeitet, kann uvloop die Leistung kühl steigern.Ein wichtiger Faktor ist die Lesbarkeit des Codes. Einer meiner Kollegen, Yuri Shikanov, hat ein graues Modul geschrieben, das mehrere Tools zur automatischen Überprüfung und Ausführung von Code kombiniert , das einfach zu einem pre-commitGit-Hook hinzugefügt werden kann , der mit einer einzigen Konfigurationsdatei oder Umgebungsvariablen eingerichtet wurde. Mit Grau können Sie Importe sortieren ( isort ), Python-Ausdrücke nach neuen Versionen der Sprache optimieren ( pyupgrade ), am Ende von Funktionsaufrufen, Importen, Listen usw. Kommas hinzufügen (add-trailing-comma ) und Anführungszeichen für ein einzelnes Formular ( Unify ).* * *
Das ist alles für mich: Wir haben den Service entwickelt, mit Tests abgedeckt, zusammengestellt und bereitgestellt sowie Lasttests durchgeführt.Danksagung
Ich möchte den Jungs, die sich die Zeit genommen haben, diesen Artikel zu schreiben, den Code zu überprüfen, meine Ideen und Kommentare vorzustellen, meinen tiefen Dank aussprechen: Maria Zelenova Zelma, Vladimir Solomatin leenr, Anastasia Semenova morkov, Yuri Shikanov DizballanzeMikhail Shushpanov Missgeschick, Pavel Mosein pavkazzz und besonders an Dmitry Orlov orlovdl.