 Der Effekt des Aufblähens von Tabellen und Indizes (Aufblähen) ist weithin bekannt und tritt nicht nur bei Postgres auf. Es gibt Möglichkeiten, wie "VACUUM FULL" oder "CLUSTER" "out of the box" damit umzugehen, aber sie sperren Tabellen während des Betriebs und können daher nicht immer verwendet werden.Der Artikel wird ein wenig Theorie darüber enthalten, wie Aufblähen auftritt, wie damit umgegangen wird, über verzögerte Einschränkungen und die Probleme, die sie bei der Verwendung der Erweiterung pg_repack mit sich bringen.Dieser Artikel basiert auf meiner Präsentation auf der PgConf.Russia 2020.
Der Effekt des Aufblähens von Tabellen und Indizes (Aufblähen) ist weithin bekannt und tritt nicht nur bei Postgres auf. Es gibt Möglichkeiten, wie "VACUUM FULL" oder "CLUSTER" "out of the box" damit umzugehen, aber sie sperren Tabellen während des Betriebs und können daher nicht immer verwendet werden.Der Artikel wird ein wenig Theorie darüber enthalten, wie Aufblähen auftritt, wie damit umgegangen wird, über verzögerte Einschränkungen und die Probleme, die sie bei der Verwendung der Erweiterung pg_repack mit sich bringen.Dieser Artikel basiert auf meiner Präsentation auf der PgConf.Russia 2020.Warum Blähungen auftreten
Postgres basiert auf dem Multi-Version-Modell ( MVCC ). Das Wesentliche ist, dass jede Zeile in der Tabelle mehrere Versionen haben kann, während Transaktionen nicht mehr als eine dieser Versionen sehen, aber nicht unbedingt dieselbe. Dadurch können mehrere Transaktionen gleichzeitig ausgeführt werden und haben praktisch keine Auswirkungen aufeinander.Natürlich müssen alle diese Versionen gespeichert werden. Postgres arbeitet Seite für Seite mit dem Speicher und die Seite ist die minimale Datenmenge, die von der Festplatte gelesen oder geschrieben werden kann. Schauen wir uns ein kleines Beispiel an, um zu verstehen, wie dies geschieht.Angenommen, wir haben eine Tabelle, in der wir mehrere Datensätze hinzugefügt haben. Auf der ersten Seite der Datei, auf der die Tabelle gespeichert ist, wurden neue Daten angezeigt. Hierbei handelt es sich um Live-Versionen von Zeichenfolgen, die nach einem Commit für andere Transaktionen verfügbar sind (der Einfachheit halber wird davon ausgegangen, dass die Isolationsstufe Read Committed verwendet wird).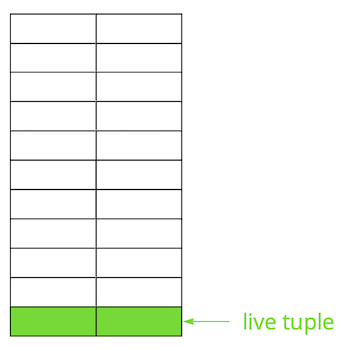 Dann haben wir einen der Einträge aktualisiert und damit die alte Version als irrelevant markiert.
Dann haben wir einen der Einträge aktualisiert und damit die alte Version als irrelevant markiert.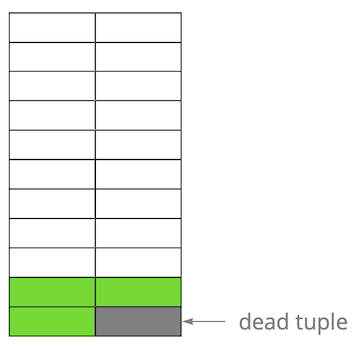 Schritt für Schritt, indem wir die Version der Zeilen aktualisieren und löschen, erhalten wir eine Seite, auf der etwa die Hälfte der Daten "Müll" ist. Diese Daten sind für keine Transaktion sichtbar.
Schritt für Schritt, indem wir die Version der Zeilen aktualisieren und löschen, erhalten wir eine Seite, auf der etwa die Hälfte der Daten "Müll" ist. Diese Daten sind für keine Transaktion sichtbar.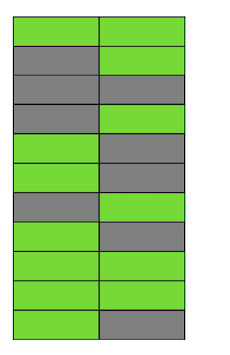 Postgres hat einen VACUUM- Mechanismus, wodurch irrelevante Versionen bereinigt und Speicherplatz für neue Daten frei wird. Wenn es jedoch nicht aggressiv genug konfiguriert ist oder in anderen Tabellen arbeitet, bleiben die „Junk-Daten“ erhalten, und wir müssen zusätzliche Seiten für neue Daten verwenden.In unserem Beispiel besteht die Tabelle zu einem bestimmten Zeitpunkt aus vier Seiten, enthält jedoch nur die Hälfte der Live-Daten. Infolgedessen lesen wir beim Zugriff auf die Tabelle viel mehr Daten als erforderlich.
Postgres hat einen VACUUM- Mechanismus, wodurch irrelevante Versionen bereinigt und Speicherplatz für neue Daten frei wird. Wenn es jedoch nicht aggressiv genug konfiguriert ist oder in anderen Tabellen arbeitet, bleiben die „Junk-Daten“ erhalten, und wir müssen zusätzliche Seiten für neue Daten verwenden.In unserem Beispiel besteht die Tabelle zu einem bestimmten Zeitpunkt aus vier Seiten, enthält jedoch nur die Hälfte der Live-Daten. Infolgedessen lesen wir beim Zugriff auf die Tabelle viel mehr Daten als erforderlich.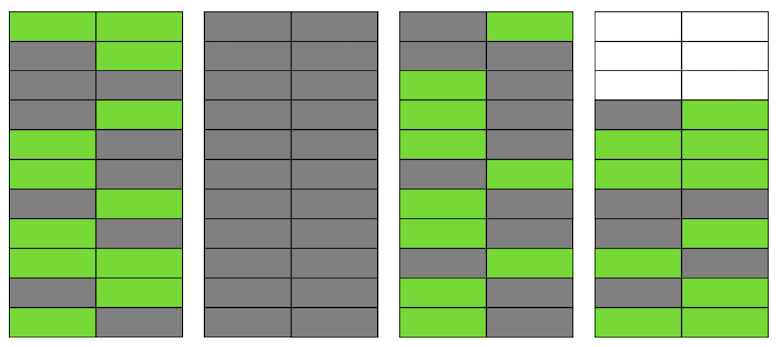 Selbst wenn VACUUM jetzt alle irrelevanten Versionen von Zeichenfolgen löscht, wird sich die Situation nicht dramatisch verbessern. Wir haben freien Speicherplatz auf den Seiten oder sogar ganze Seiten für neue Zeilen, aber wir werden weiterhin mehr Daten als nötig lesen.Wenn sich übrigens eine vollständig leere Seite (die zweite in unserem Beispiel) am Ende der Datei befindet, kann VACUUM sie zuschneiden. Aber jetzt ist sie in der Mitte, also kann nichts mit ihr gemacht werden.
Selbst wenn VACUUM jetzt alle irrelevanten Versionen von Zeichenfolgen löscht, wird sich die Situation nicht dramatisch verbessern. Wir haben freien Speicherplatz auf den Seiten oder sogar ganze Seiten für neue Zeilen, aber wir werden weiterhin mehr Daten als nötig lesen.Wenn sich übrigens eine vollständig leere Seite (die zweite in unserem Beispiel) am Ende der Datei befindet, kann VACUUM sie zuschneiden. Aber jetzt ist sie in der Mitte, also kann nichts mit ihr gemacht werden.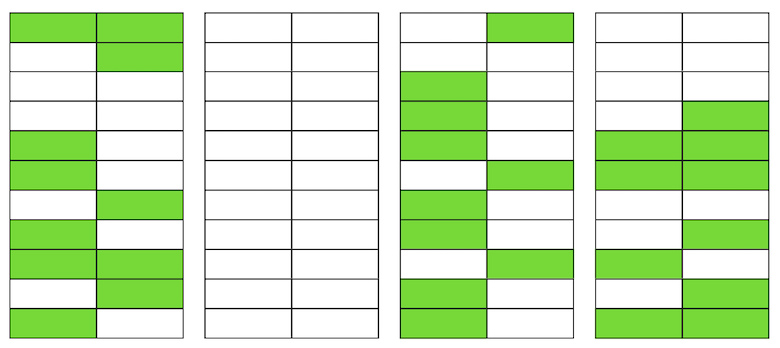 Wenn die Anzahl solcher leeren oder sehr flachen Seiten groß wird, was als Aufblähen bezeichnet wird, beginnt dies die Leistung zu beeinträchtigen.Alles, was oben beschrieben wurde, ist die Mechanik des Auftretens von Aufblähungen in Tabellen. In Indizes geschieht dies ähnlich.
Wenn die Anzahl solcher leeren oder sehr flachen Seiten groß wird, was als Aufblähen bezeichnet wird, beginnt dies die Leistung zu beeinträchtigen.Alles, was oben beschrieben wurde, ist die Mechanik des Auftretens von Aufblähungen in Tabellen. In Indizes geschieht dies ähnlich.Habe ich ein Aufblähen?
Es gibt verschiedene Möglichkeiten, um festzustellen, ob Sie eine Aufblähung haben. Die Idee der ersten besteht darin, interne Postgres-Statistiken zu verwenden, die ungefähre Informationen über die Anzahl der Zeilen in Tabellen, die Anzahl der "aktiven" Zeilen usw. enthalten. Im Internet finden Sie viele Variationen vorgefertigter Skripte. Wir haben ein Skript von PostgreSQL Experts zugrunde gelegt, das Bloat-Tabellen zusammen mit Toast- und Bloat-Btree-Indizes auswerten kann. Nach unserer Erfahrung beträgt der Fehler 10-20%.Eine andere Möglichkeit ist die Verwendung der pgstattuple- Erweiterung , mit der Sie in die Seiten schauen und sowohl geschätzte als auch genaue Aufblähungswerte erhalten können. Im zweiten Fall müssen Sie jedoch die gesamte Tabelle scannen.Einen kleinen Aufblähungswert von bis zu 20% halten wir für akzeptabel. Es kann als Analogon des Füllfaktors für Tabellen und Indizes betrachtet werden . Bei 50% und mehr können Leistungsprobleme auftreten.Möglichkeiten, mit Aufblähen umzugehen
Es gibt verschiedene Möglichkeiten, mit dem Aufblähen in Postgres umzugehen, aber sie sind bei weitem nicht immer für jeden geeignet.Stellen Sie AUTOVACUUM so ein, dass kein Aufblähen auftritt . Und genauer gesagt, um es für Sie auf einem akzeptablen Niveau zu halten. Dies scheint der Rat eines Kapitäns zu sein, aber in Wirklichkeit ist dies nicht immer leicht zu erreichen. Beispielsweise entwickeln Sie sich aktiv mit regelmäßigen Änderungen am Datenschema oder es findet eine Art Datenmigration statt. Infolgedessen kann sich Ihr Lastprofil häufig ändern und in der Regel für verschiedene Tabellen unterschiedlich sein. Dies bedeutet, dass Sie ständig ein Stück vor der Kurve arbeiten und AUTOVACUUM an das sich ändernde Profil jeder Tabelle anpassen müssen. Es ist jedoch offensichtlich, dass dies nicht einfach ist.Ein weiterer häufiger Grund dafür, dass AUTOVACUUM keine Zeit zum Verarbeiten von Tabellen hat, ist das Vorhandensein langwieriger Transaktionen, die verhindern, dass Daten gelöscht werden, da sie für diese Transaktionen verfügbar sind. Die Empfehlung hier ist auch offensichtlich - beseitigen Sie hängende Transaktionen und minimieren Sie die Zeit aktiver Transaktionen. Wenn die Last Ihrer Anwendung jedoch eine Mischung aus OLAP und OLTP ist, können Sie gleichzeitig viele häufige Aktualisierungen und kurze Anforderungen sowie langwierige Vorgänge ausführen, z. B. das Erstellen eines Berichts. In einer solchen Situation lohnt es sich, über eine Verteilung der Last auf verschiedene Basen nachzudenken, um eine feinere Abstimmung der einzelnen Basen zu ermöglichen.Ein weiteres Beispiel: Selbst wenn das Profil einheitlich ist, die Datenbank jedoch sehr stark ausgelastet ist, kann es sein, dass selbst das aggressivste AUTOVACUUM nicht zurechtkommt und ein Aufblähen auftritt. Die Skalierung (vertikal oder horizontal) ist die einzige Lösung.Aber was ist mit der Situation, als Sie AUTOVACUUM konfiguriert haben, aber das Aufblähen wächst weiter? VACUUM FULL-
Befehlerstellt den Inhalt von Tabellen und Indizes neu und belässt nur relevante Daten darin. Um das Aufblähen zu vermeiden, funktioniert es einwandfrei. Während der Ausführung wird jedoch eine exklusive Sperre für die Tabelle (AccessExclusiveLock) erfasst, die keine Abfragen für diese Tabelle zulässt, selbst wenn diese ausgewählt werden. Wenn Sie es sich leisten können, Ihren Dienst oder einen Teil davon für eine Weile einzustellen (von zehn Minuten bis zu mehreren Stunden, abhängig von der Größe der Datenbank und Ihrer Hardware), ist diese Option die beste. Leider haben wir während der geplanten Wartung keine Zeit, VACUUM FULL auszuführen, sodass diese Methode nicht zu uns passt. CLUSTER-BefehlAußerdem wird der Inhalt von Tabellen neu erstellt, ebenso wie VACUUM FULL. Gleichzeitig können Sie den Index angeben, nach dem die Daten physisch auf der Festplatte sortiert werden (in Zukunft ist die Reihenfolge jedoch nicht garantiert). In bestimmten Situationen ist dies eine gute Optimierung für eine Reihe von Abfragen - mit dem Lesen mehrerer Datensätze nach Index. Der Nachteil des Befehls ist der gleiche wie der von VACUUM FULL - er sperrt die Tabelle während des Betriebs.Der Befehl REINDEX ähnelt den beiden vorherigen, erstellt jedoch einen bestimmten Index oder alle Indizes in der Tabelle neu. Sperren sind etwas schwächer: ShareLock für die Tabelle (verhindert Änderungen, aber Sie können auswählen) und AccessExclusiveLock für den wiederherstellbaren Index (blockiert Anforderungen, die diesen Index verwenden). In Version 12 von Postgres jedoch der Parameter CONCURRENTLYHiermit können Sie den Index neu erstellen, ohne das parallele Hinzufügen, Ändern oder Löschen von Datensätzen zu blockieren.In früheren Versionen von Postgres können Sie mit CREATE INDEX CONCURRENTLY ein ähnliches Ergebnis wie REINDEX CONCURRENTLY erzielen . Sie können einen Index ohne strikte Blockierung erstellen (ShareUpdateExclusiveLock, der parallele Abfragen nicht beeinträchtigt), dann den alten Index durch einen neuen ersetzen und den alten Index löschen. Dadurch werden aufgeblähte Indizes eliminiert, ohne Ihre Anwendung zu beeinträchtigen. Es ist wichtig zu berücksichtigen, dass beim Neuerstellen von Indizes das Festplattensubsystem zusätzlich belastet wird.Wenn es also Möglichkeiten für Indizes gibt, das Aufblähen „heiß“ zu beseitigen, gibt es für Tabellen keine. Hier kommen verschiedene externe Erweiterungen ins Spiel : pg_repack(früher pg_reorg), pgcompact , pgcompacttable und andere. Im Rahmen dieses Artikels werde ich sie nicht vergleichen und nur über pg_repack sprechen, das wir nach einiger Verfeinerung zu Hause verwenden.Wie pg_repack funktioniert
Angenommen, wir haben eine ganz normale Tabelle für uns - mit Indizes, Einschränkungen und leider mit Aufblähen. Der erste Schritt ist, dass pg_repack eine Protokolltabelle erstellt, in der Daten zu allen Änderungen während des Betriebs gespeichert werden. Der Trigger repliziert diese Änderungen bei jedem Einfügen, Aktualisieren und Löschen. Anschließend wird eine Tabelle erstellt, die in ihrer Struktur dem Original ähnelt, jedoch keine Indizes und Einschränkungen aufweist, um das Einfügen von Daten nicht zu verlangsamen.Als Nächstes überträgt pg_repack Daten von der alten in die neue Tabelle, filtert automatisch alle irrelevanten Zeilen und erstellt dann Indizes für die neue Tabelle. Während der Ausführung all dieser Vorgänge werden Änderungen in der Protokolltabelle gesammelt.Der nächste Schritt besteht darin, die Änderungen in die neue Tabelle zu übertragen. Die Migration wird in mehreren Iterationen durchgeführt. Wenn weniger als 20 Einträge in der Protokolltabelle verbleiben, erfasst pg_repack eine strikte Sperre, überträgt die neuesten Daten und ersetzt die alte Tabelle durch die neue in den Postgres-Systemtabellen. Dies ist der einzige und sehr kurze Zeitpunkt, an dem Sie nicht mit der Tabelle arbeiten können. Danach werden die alte Tabelle und die Tabelle mit den Protokollen gelöscht und Speicherplatz im Dateisystem freigegeben. Der Vorgang ist abgeschlossen.Theoretisch sieht alles gut aus, was in der Praxis? Wir haben pg_repack ohne Last getestet und unter Last die Funktion im Falle eines vorzeitigen Stopps überprüft (mit anderen Worten, Strg + C). Alle Tests waren positiv.Wir gingen zum Produkt - und dann lief alles schief, wie wir es erwartet hatten.Der erste Pfannkuchen auf Prod
Beim ersten Cluster wurde ein Fehler bezüglich der Verletzung einer eindeutigen Einschränkung angezeigt:$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.
Diese Einschränkung hatte den automatisch generierten Namen index_16508 - er wurde von pg_repack erstellt. Durch die in seiner Zusammensetzung enthaltenen Attribute haben wir „unsere“ Einschränkung bestimmt, die dieser entspricht. Es stellte sich heraus, dass dies keine gewöhnliche Einschränkung ist, sondern eine verzögerte Einschränkung , d.h. Die Überprüfung erfolgt später als der Befehl sql, was zu unerwarteten Konsequenzen führt.Aufgeschobene Einschränkungen: Warum werden sie benötigt und wie funktionieren sie?
Ein bisschen Theorie über verzögerte Einschränkungen.Stellen Sie sich ein einfaches Beispiel vor: Wir haben eine Fahrzeugreferenztabelle mit zwei Attributen - dem Namen und der Reihenfolge des Fahrzeugs im Verzeichnis.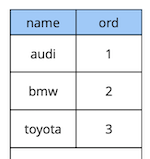
create table cars
(
name text constraint pk_cars primary key,
ord integer not null constraint uk_cars unique
);
Nehmen wir an, wir mussten das erste und das zweite Auto tauschen. Die Lösung "in der Stirn" besteht darin, den ersten Wert auf den zweiten und den zweiten auf den ersten zu aktualisieren:begin;
update cars set ord = 2 where name = 'audi';
update cars set ord = 1 where name = 'bmw';
commit;
Bei der Ausführung dieses Codes wird jedoch eine Verletzung der Einschränkung erwartet, da die Reihenfolge der Werte in der Tabelle eindeutig ist:[23305] ERROR: duplicate key value violates unique constraint “uk_cars”
Detail: Key (ord)=(2) already exists.
Wie mache ich das anders? Option 1: Fügen Sie einen zusätzlichen Ersatz des Werts durch eine Bestellung hinzu, die garantiert nicht in der Tabelle vorhanden ist, z. B. "-1". In der Programmierung wird dies als "Austausch der Werte zweier Variablen durch die dritte" bezeichnet. Der einzige Nachteil dieser Methode ist das zusätzliche Update.Option 2: Entwerfen Sie die Tabelle neu, um anstelle von Ganzzahlen einen Gleitkomma-Datentyp für den Auftragswert zu verwenden. Wenn Sie dann den Wert von beispielsweise 1 auf 2,5 aktualisieren, wird der erste Datensatz automatisch zwischen dem zweiten und dem dritten Datensatz "aufstehen". Diese Lösung funktioniert, es gibt jedoch zwei Einschränkungen. Erstens funktioniert es für Sie nicht, wenn der Wert irgendwo in der Schnittstelle verwendet wird. Zweitens haben Sie abhängig von der Genauigkeit des Datentyps eine begrenzte Anzahl möglicher Einfügungen, bevor Sie die Werte aller Datensätze neu berechnen.Option 3: Verschieben Sie die Einschränkung so, dass sie nur zum Zeitpunkt des Festschreibens überprüft wird:create table cars
(
name text constraint pk_cars primary key,
ord integer not null constraint uk_cars unique deferrable initially deferred
);
Da die Logik unserer ersten Anforderung sicherstellt, dass alle Werte zum Zeitpunkt des Festschreibens eindeutig sind, ist dies erfolgreich.Das obige Beispiel ist natürlich sehr synthetisch, aber es zeigt die Idee. In unserer Anwendung verwenden wir verzögerte Einschränkungen, um Logik zu implementieren, die für die Lösung von Konflikten verantwortlich ist, während gleichzeitig mit allgemeinen Widget-Objekten auf der Karte gearbeitet wird. Durch die Verwendung solcher Einschränkungen können wir den Anwendungscode etwas vereinfachen.Abhängig von der Art der Einschränkung in Postgres gibt es im Allgemeinen drei Granularitätsebenen, um sie zu überprüfen: Zeilenebene, Transaktion und Ausdruck.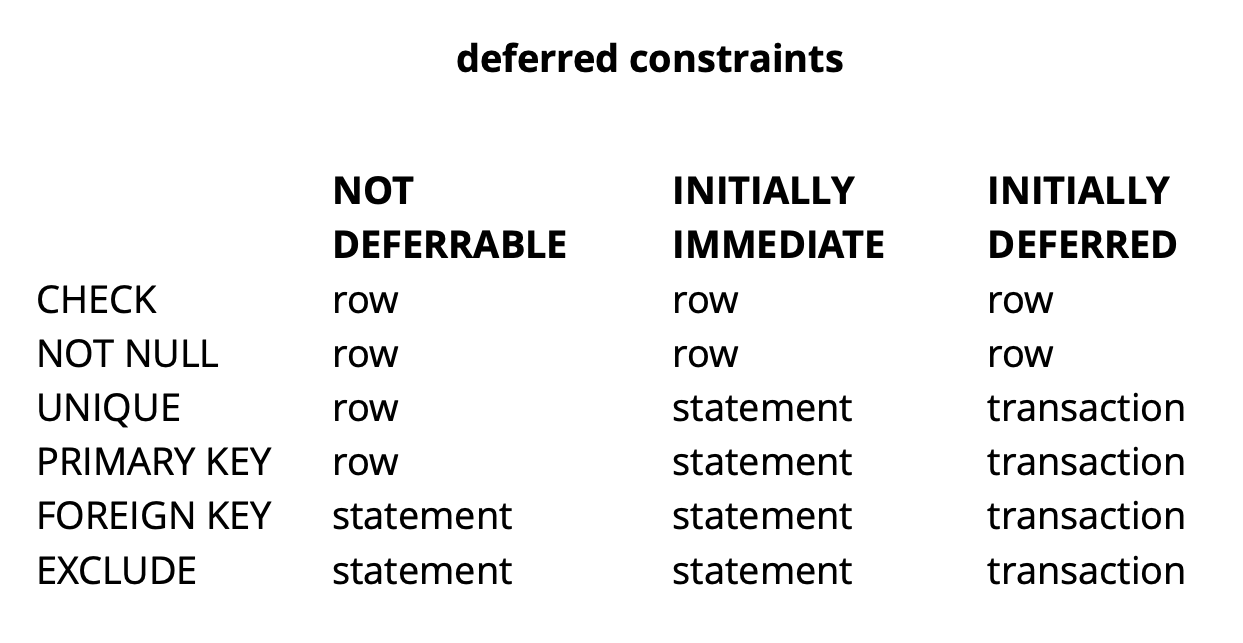 Quelle: begriffsCHECK und NOT NULL werden immer auf Zeilenebene überprüft. Für andere Einschränkungen gibt es, wie aus der Tabelle hervorgeht, verschiedene Optionen. Lesen Sie hier mehr .Kurz zusammengefasst ergeben ausstehende Einschränkungen in einigen Situationen mehr lesbaren Code und weniger Befehle. Sie müssen dies jedoch bezahlen, indem Sie den Debug-Prozess komplizieren, da der Moment, in dem der Fehler aufgetreten ist und der Moment, in dem Sie davon erfahren, zeitlich getrennt sind. Ein weiteres mögliches Problem besteht darin, dass der Scheduler nicht immer den optimalen Plan erstellen kann, wenn die Anforderung eine verzögerte Einschränkung enthält.
Quelle: begriffsCHECK und NOT NULL werden immer auf Zeilenebene überprüft. Für andere Einschränkungen gibt es, wie aus der Tabelle hervorgeht, verschiedene Optionen. Lesen Sie hier mehr .Kurz zusammengefasst ergeben ausstehende Einschränkungen in einigen Situationen mehr lesbaren Code und weniger Befehle. Sie müssen dies jedoch bezahlen, indem Sie den Debug-Prozess komplizieren, da der Moment, in dem der Fehler aufgetreten ist und der Moment, in dem Sie davon erfahren, zeitlich getrennt sind. Ein weiteres mögliches Problem besteht darin, dass der Scheduler nicht immer den optimalen Plan erstellen kann, wenn die Anforderung eine verzögerte Einschränkung enthält.Verfeinerung pg_repack
Wir haben herausgefunden, welche Einschränkungen noch ausstehen, aber wie hängen sie mit unserem Problem zusammen? Erinnern Sie sich an den Fehler, den wir zuvor erhalten haben:$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.
Es tritt zum Zeitpunkt des Kopierens von Daten aus der Protokolltabelle in die neue Tabelle auf. Es sieht komisch aus, weil Die Daten in der Protokolltabelle werden zusammen mit den Daten in der Originaltabelle festgeschrieben. Wenn sie die Einschränkungen der ursprünglichen Tabelle erfüllen, wie können sie dann dieselben Einschränkungen in der neuen Tabelle verletzen?Wie sich herausstellte, liegt die Wurzel des Problems im vorherigen Schritt von pg_repack, für den nur Indizes erstellt werden, jedoch keine Einschränkungen: Die alte Tabelle hatte eine eindeutige Einschränkung, und die neue Tabelle erstellte stattdessen einen eindeutigen Index. Hierbei ist zu beachten, dass, wenn die Einschränkung normal und nicht zurückgestellt ist, der stattdessen erstellte eindeutige Index dieser Einschränkung entspricht, da Postgres-eindeutige Einschränkungen werden durch Erstellen eines eindeutigen Index implementiert. Im Fall einer verzögerten Einschränkung ist das Verhalten jedoch nicht dasselbe, da der Index nicht verzögert werden kann und immer zum Zeitpunkt der Ausführung des Befehls sql überprüft wird.Das Wesentliche des Problems liegt also in der „Verschiebung“ der Prüfung: In der ursprünglichen Tabelle tritt sie zum Zeitpunkt des Festschreibens und in der neuen Tabelle zum Zeitpunkt der Ausführung des Befehls sql auf. Wir müssen also sicherstellen, dass die Überprüfungen in beiden Fällen auf die gleiche Weise durchgeführt werden: entweder immer zurückgestellt oder immer sofort.Welche Ideen hatten wir?
Hierbei ist zu beachten, dass, wenn die Einschränkung normal und nicht zurückgestellt ist, der stattdessen erstellte eindeutige Index dieser Einschränkung entspricht, da Postgres-eindeutige Einschränkungen werden durch Erstellen eines eindeutigen Index implementiert. Im Fall einer verzögerten Einschränkung ist das Verhalten jedoch nicht dasselbe, da der Index nicht verzögert werden kann und immer zum Zeitpunkt der Ausführung des Befehls sql überprüft wird.Das Wesentliche des Problems liegt also in der „Verschiebung“ der Prüfung: In der ursprünglichen Tabelle tritt sie zum Zeitpunkt des Festschreibens und in der neuen Tabelle zum Zeitpunkt der Ausführung des Befehls sql auf. Wir müssen also sicherstellen, dass die Überprüfungen in beiden Fällen auf die gleiche Weise durchgeführt werden: entweder immer zurückgestellt oder immer sofort.Welche Ideen hatten wir?Erstellen Sie einen Index ähnlich dem verzögerten
Die erste Idee besteht darin, beide Überprüfungen im Sofortmodus durchzuführen. Dies kann zu mehreren falsch positiven Auslösern der Einschränkung führen. Wenn jedoch nur wenige davon vorhanden sind, sollte dies die Arbeit der Benutzer nicht beeinträchtigen, da solche Konflikte für sie eine normale Situation sind. Sie treten beispielsweise auf, wenn zwei Benutzer gleichzeitig dasselbe Widget bearbeiten und der Client des zweiten Benutzers keine Zeit hat, Informationen abzurufen, dass das Widget bereits für die Bearbeitung durch den ersten Benutzer gesperrt ist. In dieser Situation lehnt der Server den zweiten Benutzer ab, und sein Client setzt die Änderungen zurück und blockiert das Widget. Wenig später, wenn der erste Benutzer die Bearbeitung beendet hat, erhält der zweite Benutzer die Information, dass das Widget nicht mehr gesperrt ist, und kann seine Aktion wiederholen.
CREATE UNIQUE INDEX CONCURRENTLY uk_tablename__immediate ON tablename (id, index);
DROP INDEX CONCURRENTLY uk_tablename__immediate;
In der Testumgebung haben wir nur wenige erwartete Fehler erhalten. Erfolg! Wir haben pg_repack erneut auf dem Produkt gestartet und 5 Fehler im ersten Cluster innerhalb einer Arbeitsstunde erhalten. Dies ist ein akzeptables Ergebnis. Bereits im zweiten Cluster hat sich die Anzahl der Fehler jedoch um ein Vielfaches erhöht, und wir mussten pg_repack stoppen.Warum ist das geschehen? Die Wahrscheinlichkeit eines Fehlers hängt davon ab, wie viele Benutzer gleichzeitig mit denselben Widgets arbeiten. Anscheinend gab es zu diesem Zeitpunkt mit den im ersten Cluster gespeicherten Daten viel weniger Wettbewerbsänderungen als im Rest, d. H. Wir hatten einfach "Glück".Die Idee hat nicht funktioniert. In diesem Moment sahen wir zwei weitere Lösungsoptionen: Schreiben Sie unseren Anwendungscode neu, um ausstehende Einschränkungen aufzuheben, oder „lehren“ Sie pg_repack, mit ihnen zu arbeiten. Wir haben die zweite gewählt.Ersetzen Sie Indizes in einer neuen Tabelle durch verzögerte Einschränkungen aus der Quelltabelle
Der Zweck der Überarbeitung lag auf der Hand: Wenn die ursprüngliche Tabelle eine verzögerte Einschränkung aufweist, müssen Sie für die neue Tabelle eine solche Einschränkung erstellen, keinen Index.Um unsere Änderungen zu testen, haben wir einen einfachen Test geschrieben:- Tabelle mit aufgeschobener Einschränkung und einem Datensatz;
- Fügen Sie Daten in die Schleife ein, die mit dem vorhandenen Datensatz in Konflikt stehen.
- Update durchführen - die Daten stehen nicht mehr in Konflikt;
- Veränderung begehen.
create table test_table
(
id serial,
val int,
constraint uk_test_table__val unique (val) deferrable initially deferred
);
INSERT INTO test_table (val) VALUES (0);
FOR i IN 1..10000 LOOP
BEGIN
INSERT INTO test_table VALUES (0) RETURNING id INTO v_id;
UPDATE test_table set val = i where id = v_id;
COMMIT;
END;
END LOOP;
Die Originalversion von pg_repack stürzte beim ersten Einfügen immer ab, die überarbeitete Version funktionierte fehlerfrei. Fein.Wir gehen zum Produkt und erhalten erneut einen Fehler in derselben Phase des Kopierens von Daten aus der Protokolltabelle in die neue:$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.
Klassische Situation: Alles funktioniert in Testumgebungen, aber nicht auf Produkten ?!APPLY_COUNT und die Verbindung zweier Chargen
Wir begannen, den Code buchstäblich Zeile für Zeile zu analysieren und fanden einen wichtigen Punkt: Daten werden mit Stapeln von der Protokolltabelle in die neue übertragen. Die Konstante APPLY_COUNT gab die Größe des Stapels an:for (;;)
{
num = apply_log(connection, table, APPLY_COUNT);
if (num > MIN_TUPLES_BEFORE_SWITCH)
continue;
...
}
Das Problem besteht darin, dass die Daten der ursprünglichen Transaktion, bei denen mehrere Vorgänge möglicherweise gegen die Beschränkung verstoßen können, während der Übertragung auf zwei Chargen übertragen werden können - die Hälfte der Teams wird im ersten Spiel und die andere Hälfte im zweiten Spiel festgeschrieben. Und so viel Glück: Wenn die Teams in der ersten Partie nichts verletzen, ist alles in Ordnung, aber wenn sie verletzen, tritt ein Fehler auf.APPLY_COUNT entspricht 1000 Einträgen, was erklärt, warum unsere Tests erfolgreich waren - sie deckten nicht den Fall der „Verbindung von Chargen“ ab. Wir haben zwei Befehle verwendet - Einfügen und Aktualisieren, sodass immer genau 500 Transaktionen von zwei Teams im Stapel platziert wurden und wir keine Probleme hatten. Nach dem Hinzufügen des zweiten Updates funktionierte unsere Bearbeitung nicht mehr:FOR i IN 1..10000 LOOP
BEGIN
INSERT INTO test_table VALUES (1) RETURNING id INTO v_id;
UPDATE test_table set val = i where id = v_id;
UPDATE test_table set val = i where id = v_id;
COMMIT;
END;
END LOOP;
Die nächste Aufgabe besteht also darin, sicherzustellen, dass die Daten aus der Quelltabelle, die sich in einer Transaktion geändert haben, auch innerhalb derselben Transaktion in die neue Tabelle fallen.Ablehnung des Schlachtens
Und wieder hatten wir zwei Lösungen. Erstens: Lassen Sie uns die Stapelverarbeitung vollständig aufgeben und die Datenübertragung in einer Transaktion durchführen. Für diese Lösung war ihre Einfachheit von Vorteil - die erforderlichen Codeänderungen waren minimal (in älteren Versionen funktionierte pg_reorg übrigens genau so). Aber es gibt ein Problem - wir schaffen eine lange Transaktion, und dies ist, wie bereits gesagt, eine Bedrohung für die Entstehung eines neuen Aufblähens.Die zweite Lösung ist komplizierter, aber wahrscheinlich korrekter: Erstellen Sie eine Spalte in der Protokolltabelle mit der Kennung der Transaktion, die die Daten zur Tabelle hinzugefügt hat. Wenn wir dann Daten kopieren, können wir sie nach diesem Attribut gruppieren und sicherstellen, dass die zugehörigen Änderungen zusammen übertragen werden. Ein Stapel wird aus mehreren Transaktionen (oder einer großen) gebildet und seine Größe hängt davon ab, wie viele Daten sich in diesen Transaktionen geändert haben. Es ist wichtig zu beachten, dass, da die Daten verschiedener Transaktionen in zufälliger Reihenfolge in die Protokolltabelle fallen, es nicht möglich ist, sie wie zuvor nacheinander zu lesen. seqscan für jede von tx_id gefilterte Anfrage ist zu teuer. Sie benötigen einen Index, verlangsamen jedoch die Methode aufgrund des Aktualisierungsaufwands. Im Allgemeinen müssen Sie wie immer etwas opfern.Deshalb haben wir uns entschlossen, mit der ersten Option zu beginnen, als einer einfacheren. Zunächst musste verstanden werden, ob eine lange Transaktion ein echtes Problem darstellt. Da die Hauptdatenübertragung von der alten zur neuen Tabelle auch in einer langen Transaktion erfolgt, hat sich die Frage in "Wie viel werden wir diese Transaktion erhöhen?" Die Dauer der ersten Transaktion hängt hauptsächlich von der Größe der Tabelle ab. Die Dauer der neuen hängt davon ab, wie viele Änderungen sich während der Datenübertragung in der Tabelle ansammeln, d. H. von der Intensität der Last. Der Lauf pg_repack trat während der minimalen Auslastung des Dienstes auf, und der Änderungsbetrag war im Vergleich zur ursprünglichen Tabellengröße unvergleichlich gering. Wir haben beschlossen, die Zeit der neuen Transaktion zu vernachlässigen (zum Vergleich sind dies durchschnittlich 1 Stunde und 2-3 Minuten).Die Experimente waren positiv. Laufen auch auf Prod. Aus Gründen der Übersichtlichkeit ein Bild mit der Größe einer der Basen nach dem Lauf: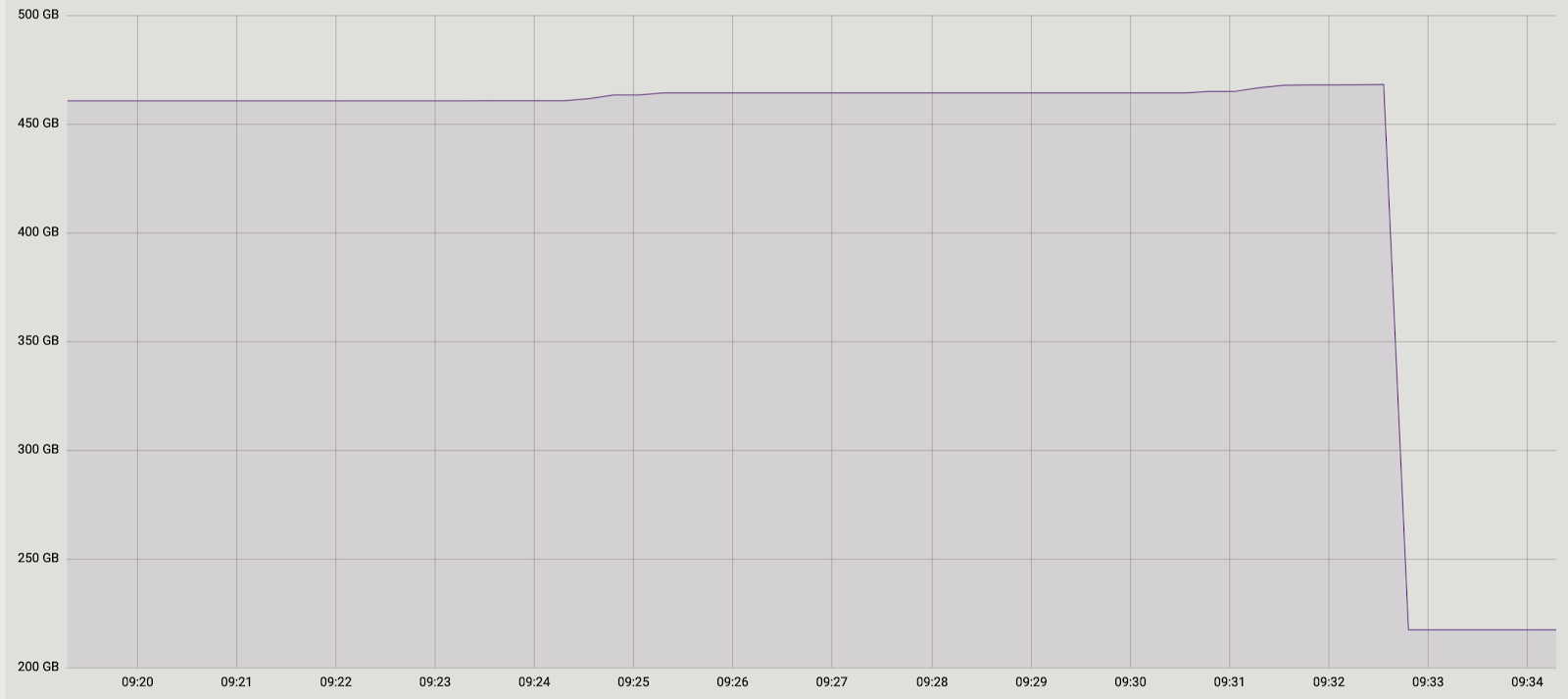 Da diese Lösung vollständig zu uns passte, haben wir nicht versucht, die zweite zu implementieren, sondern erwägen, sie mit den Entwicklern der Erweiterung zu diskutieren. Leider ist unsere aktuelle Version noch nicht zur Veröffentlichung bereit, da wir das Problem nur mit eindeutigen ausstehenden Einschränkungen gelöst haben und für einen vollwertigen Patch andere Typen unterstützt werden müssen. Wir hoffen, dies in Zukunft tun zu können.Vielleicht haben Sie eine Frage, warum wir uns mit der Fertigstellung von pg_repack auf diese Geschichte eingelassen haben und zum Beispiel ihre Analoga nicht verwendet haben? Irgendwann haben wir auch darüber nachgedacht, aber die positive Erfahrung, es früher auf Tabellen ohne ausstehende Einschränkungen zu verwenden, hat uns motiviert, zu versuchen, das Wesentliche des Problems zu verstehen und es zu beheben. Um andere Lösungen zu verwenden, dauert es auch einige Zeit, um Tests durchzuführen. Daher haben wir beschlossen, zunächst zu versuchen, das Problem darin zu beheben. Wenn wir feststellen, dass wir dies nicht in angemessener Zeit tun können, werden wir Analoga in Betracht ziehen.
Da diese Lösung vollständig zu uns passte, haben wir nicht versucht, die zweite zu implementieren, sondern erwägen, sie mit den Entwicklern der Erweiterung zu diskutieren. Leider ist unsere aktuelle Version noch nicht zur Veröffentlichung bereit, da wir das Problem nur mit eindeutigen ausstehenden Einschränkungen gelöst haben und für einen vollwertigen Patch andere Typen unterstützt werden müssen. Wir hoffen, dies in Zukunft tun zu können.Vielleicht haben Sie eine Frage, warum wir uns mit der Fertigstellung von pg_repack auf diese Geschichte eingelassen haben und zum Beispiel ihre Analoga nicht verwendet haben? Irgendwann haben wir auch darüber nachgedacht, aber die positive Erfahrung, es früher auf Tabellen ohne ausstehende Einschränkungen zu verwenden, hat uns motiviert, zu versuchen, das Wesentliche des Problems zu verstehen und es zu beheben. Um andere Lösungen zu verwenden, dauert es auch einige Zeit, um Tests durchzuführen. Daher haben wir beschlossen, zunächst zu versuchen, das Problem darin zu beheben. Wenn wir feststellen, dass wir dies nicht in angemessener Zeit tun können, werden wir Analoga in Betracht ziehen.Ergebnisse
Was wir aufgrund unserer eigenen Erfahrung empfehlen können:- Überwachen Sie Ihr Aufblähen. Anhand der Überwachungsdaten können Sie nachvollziehen, wie gut das Autovakuum konfiguriert ist.
- Stellen Sie AUTOVACUUM so ein, dass das Aufblähen auf einem vernünftigen Niveau bleibt.
- bloat “ ”, . – .
- – , .