Intro
Wenn Sie in den letzten Jahren nicht verschlafen haben, haben Sie natürlich von Transformatoren gehört - Architektur aus der kanonischen Aufmerksamkeit ist alles, was Sie brauchen . Warum sind Transformatoren so gut? Zum Beispiel vermeiden sie Wiederholungen, wodurch sie effizient eine solche Darstellung von Daten erstellen können, in die viele Kontextinformationen übertragen werden können, was sich positiv auf die Fähigkeit zum Generieren von Texten und die unübertroffene Fähigkeit zum Lerntransfer auswirkt.
Transformers startete eine Lawine von Arbeiten zur Sprachmodellierung - eine Aufgabe, bei der das Modell das nächste Wort auswählt und dabei die Wahrscheinlichkeiten der vorherigen Wörter berücksichtigt, dh lernt, p(x)wo sich das xaktuelle Token befindet. Wie Sie vielleicht erraten haben, erfordert diese Aufgabe überhaupt kein Markup, und daher können Sie große, nicht kommentierte Textfelder darin verwenden. Ein bereits trainiertes Sprachmodell kann Text erzeugen, so dass sich Autoren manchmal weigern, trainierte Modelle zu erstellen .
Aber was ist, wenn wir der Texterzeugung einige „Stifte“ hinzufügen möchten? Führen Sie beispielsweise eine bedingte Generierung durch, indem Sie ein Thema festlegen oder andere Attribute steuern. Eine solche Form erfordert bereits eine bedingte Wahrscheinlichkeit p(x|a), wobei adas gewünschte Attribut ist. Interessant? Lass uns unter den Schnitt gehen!
Die Autoren des Artikels bieten einen einfachen (und daher Plug-and-Play) und eleganten Ansatz für die bedingte Generierung unter Verwendung eines umfangreichen vorab trainierten Sprachmodells (im Folgenden: LM) und mehrerer einfacher Klassifizierer, wodurch Stichproben aus einer Ansichtsverteilung erstellt werden p(x|a) ∝ p(a|x)p(x). Es ist zu beachten, dass der ursprüngliche LM in keiner Weise modifiziert wird. Die Autoren schlagen zwei Arten von Klassifizierern vor, die im Artikel Attributmodelle genannt werden: BoW für die Themensteuerung und einen linearen Klassifizierer für die Tonalitätssteuerung. Die Autoren analysieren ihre wichtigsten Beiträge ziemlich detailliert und vergleichen die Ideen und Ansätze ihrer Methode mit anderen Artikeln. Einer der wichtigsten Punkte ist die einfache Herangehensweise, und hier sehen
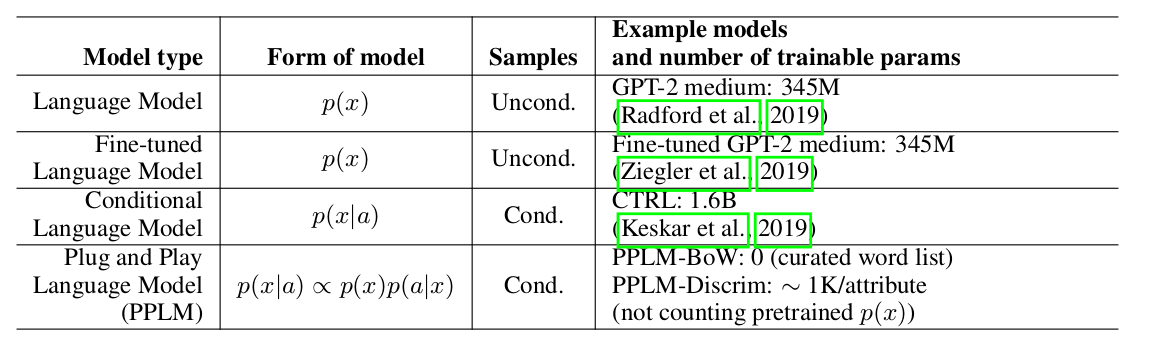
Sie sich vielleicht nur diese Platte an: Es ist ersichtlich, dass PPLM alle Wettbewerber in Bezug auf die Anzahl der Parameter übertrifft.
Gewichtete Dekodierung 2.0
Uber weighted decoding: , . , , . , . , , , .
Uber : , LM, . , , , ( , ) . ( perturb_past — , .
? log-likelihood: p(x) a attribute model p(a|x). , backward pass .
log-likelihood? , :
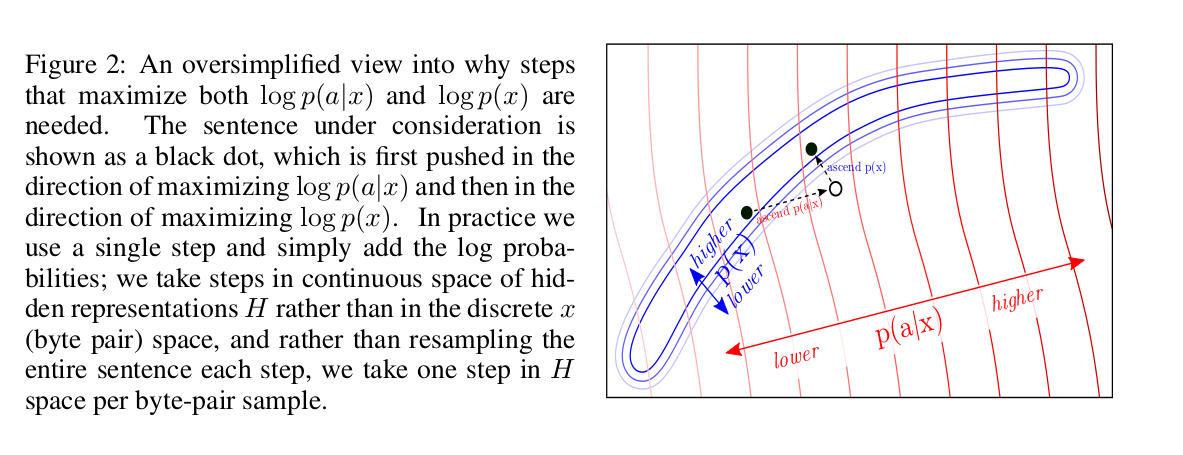
, , LM. , fluency LM.
, :

forward pass LM, p(a|x) — attribute model. backward pass, , attribute model, , . , .
, : “” k k forward backward pass’, n. LM forward pass. , : ( num of iterations=3 gen length=5, ).
, ( colab , ) , , , “the kitten” “military” :
- The kitten is a creature with no real personality, it is just a pet. You can use it as a combat item.
- The kitten that is now being called the "suspected killer" of a woman in a San Diego apartment complex was shot by another person who then shot him, according to authorities.
combat, shot, killer — , military. LM :
- The kitten that escaped a cage has been rescued from a cat sanctuary in Texas.
- The cat, named "Lucky," was found wandering in the back yard of the Humane Society at the time of the incident on Friday.
attribute models
, BoW discriminator. :
p_t+1 — LM, w_i — i- .
Discriminator model , BoW, , , , . , .
, LM, LM weighted decoding CTRL (conditional LM). fluency , , perplexity . PPLM :
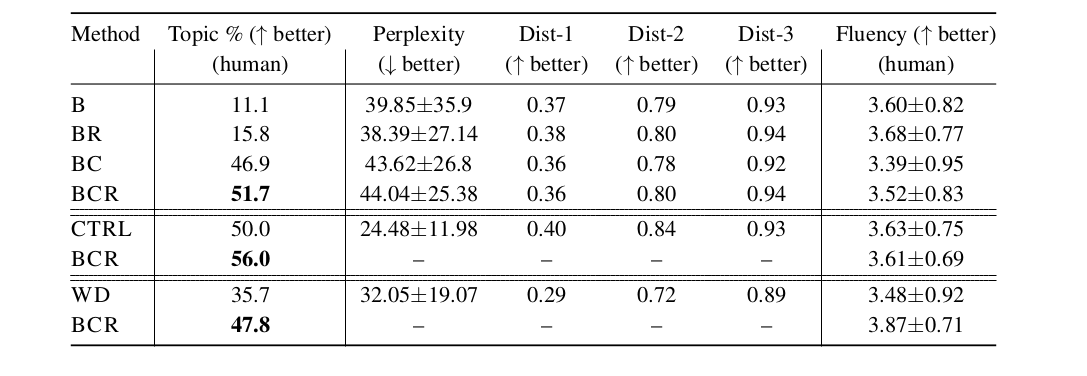
:
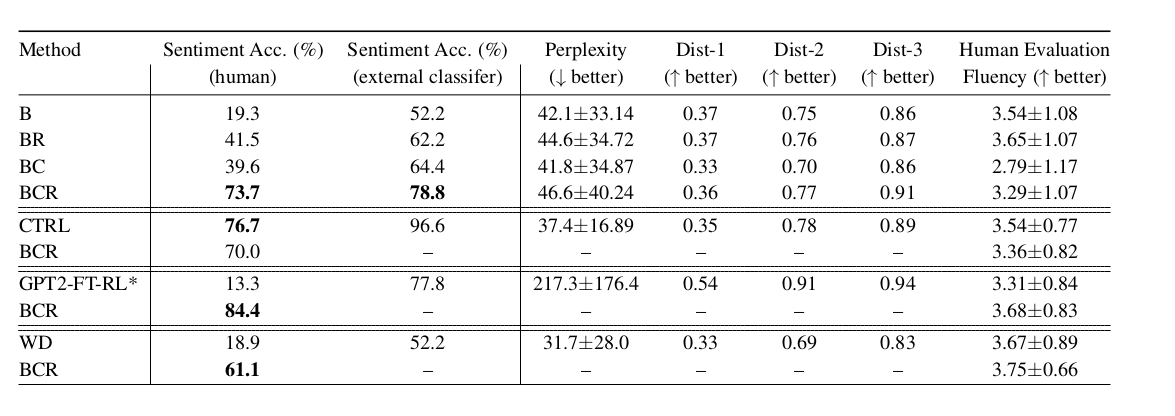
- B — baseline, GPT-2 LM;
- BR — , B,
r , log-likelihood ; - BC — , ;
- BCR — , BC,
r , log-likelihood ; - CTRL — Keskar et al, 2019;
- GPT2-FT-RL — GPT2, fine-tuned RL ;
- WD — weighted decoding,
p(a|x);
— , LM, . , , - :)