 Das Internet ist voll von Artikeln über N-Gramm-basierte Sprachmodelle. Gleichzeitig sind nur wenige Bibliotheken einsatzbereit.Es gibt KenLM , SriLM und IRSTLM . Sie sind beliebt und werden in vielen großen Projekten eingesetzt. Aber es gibt Probleme:
Das Internet ist voll von Artikeln über N-Gramm-basierte Sprachmodelle. Gleichzeitig sind nur wenige Bibliotheken einsatzbereit.Es gibt KenLM , SriLM und IRSTLM . Sie sind beliebt und werden in vielen großen Projekten eingesetzt. Aber es gibt Probleme:- Bibliotheken sind alt und entwickeln sich nicht.
- Schlechte Unterstützung für die russische Sprache.
- Arbeiten Sie nur mit sauberem, speziell vorbereitetem Text
- Schlechte Unterstützung für UTF-8. Zum Beispiel bricht SriLM mit dem Tolower- Flag die Codierung.
KenLM
hebt sich ein wenig von der Liste ab . Es wird regelmäßig unterstützt und hat keine Probleme mit UTF-8, stellt aber auch Anforderungen an die Qualität des Textes.Einmal brauchte ich eine Bibliothek, um ein Sprachmodell zu erstellen. Nach vielen Versuchen und Irrtümern kam ich zu dem Schluss, dass die Vorbereitung eines Datensatzes für das Unterrichten eines Sprachmodells zu kompliziert und ein langer Prozess ist. Besonders wenn es russisch ist ! Aber ich wollte irgendwie alles automatisieren.Bei seinen Recherchen ging er von der SriLM- Bibliothek aus . Ich werde sofort feststellen , dass dies keine Code-Ausleihe oder SriLM-Gabel ist . Der gesamte Code wird komplett von Grund auf neu geschrieben.Ein kleines Textbeispiel:
! .
Das Fehlen eines Leerzeichens zwischen Sätzen ist ein ziemlich häufiger Tippfehler. Ein solcher Fehler ist in einer großen Datenmenge schwer zu finden, während er den Tokenizer beschädigt.Nach der Verarbeitung wird im Sprachmodell das folgende N-Gramm angezeigt:
-0.3009452 !
Natürlich gibt es viele andere Probleme, Tippfehler, Sonderzeichen, Abkürzungen, verschiedene mathematische Formeln ... All dies muss korrekt behandelt werden.ANYKS LM ( ALM )
Die Bibliothek unterstützt nur Linux- , MacOS X- und FreeBSD- Betriebssysteme . Ich habe kein Windows und es ist keine Unterstützung geplant.Kurze Beschreibung der Funktionalität
- Unterstützung für UTF-8 ohne Abhängigkeiten von Drittanbietern.
- Unterstützung für Datenformate: Arpa, Vocab, Kartensequenz, N-Gramm, Binäres Alm-Wörterbuch.
- : Kneser-Nay, Modified Kneser-Nay, Witten-Bell, Additive, Good-Turing, Absolute discounting.
- , , , .
- , N-, N- , N-.
- — N-, .
- : , -.
- N- — N-, backoff .
- N- backoff-.
- , : , , , , Python3.
- « », .
- 〈unk〉 .
- N- Python3.
- , .
- . : , , .
- Im Gegensatz zu anderen Sprachmodellen sammelt ALM garantiert alle N-Gramm aus Text, unabhängig von ihrer Länge (mit Ausnahme von Modified Kneser-Nay). Es besteht auch die Möglichkeit der obligatorischen Registrierung aller seltenen N-Gramme, auch wenn sie sich nur einmal getroffen haben.
Von den Standardformaten für Sprachmodelle wird nur das ARPA- Format unterstützt . Ehrlich gesagt sehe ich keinen Grund, den gesamten Zoo in allen möglichen Formaten zu unterstützen.Das ARPA-Format unterscheidet zwischen Groß- und Kleinschreibung und dies ist auch ein eindeutiges Problem.Manchmal ist es nützlich, nur das Vorhandensein bestimmter Daten im N-Gramm zu kennen. Zum Beispiel müssen Sie das Vorhandensein von Zahlen im N-Gramm verstehen, und ihre Bedeutung ist nicht so wichtig.Beispiel:
, 2
Infolgedessen gelangt das N-Gramm in das Sprachmodell:
-0.09521468 2
Die genaue Anzahl spielt in diesem Fall keine Rolle. Der Verkauf im Laden kann 1 und 3 und so viele Tage dauern, wie Sie möchten.Um dieses Problem zu lösen, verwendet ALM die Klassentokenisierung.Unterstützte Token
Standard:<s> - Token des Anfangs des Satzes</ s> - Token des Endes des Satzes<unk> - Token eines unbekannten WortNicht-Standard:<URL> - Token der URL - Adresse<num> - Token von Zahlen (arabische oder römische)<Datum> - Datum Token (18. Juli 2004 | 18.07.2004)〈time〉 - Zeitmarke (15:44:56)〈abbr〉 - Abkürzungstoken (1. | 2. | 20.)〉 anum〉 - Pseudo- Token Zahlen (T34 | 895-M-86 | 39km)〈math〉 - Token für mathematische Operationen (+ | - | = | / | * | ^)〈range〉 - Token für den Zahlenbereich (1-2 | 100-200 | 300- 400)〈aprox〉- Ein ungefährer Zahlentoken (~ 93 | ~ 95,86 | 10 ~ 20)〉score〉 - Ein numerischer Kontotoken (4: 3 | 01:04)〈dimen〉 - Gesamttoken (200x300 | 1920x1080)〈fract〉 - Ein Bruchbruch- Token (5/20 | 192/864)〈punct〉 - Satzzeichen (. | ... |, |! |? |: |;)PecSpecl〉 - Sonderzeichen- Token (~ | @ | # | Nr. |% | & | $ | § | ±)〈isolat〉 - Isolationssymbol-Token ("| '|" | "|„ | “|` | (|) | [|] | {|})Natürlich kann die Unterstützung für jedes der Token deaktiviert werden, wenn Solche N-Gramme werden benötigt. WennSie andere Tags verarbeiten müssen (z. B. müssen Sie Ländernamen im Text finden), ALM unterstützt die Verbindung externer Skripte in Python3.Ein Beispiel für ein Token-Erkennungsskript:
def init():
"""
:
"""
def run(token, word):
"""
:
@token
@word
"""
if token and (token == "<usa>"):
if word and (word.lower() == ""): return "ok"
elif token and (token == "<russia>"):
if word and (word.lower() == ""): return "ok"
return "no"
Ein solches Skript fügt der Liste der Standard-Tags zwei weitere Tags hinzu: "usa" und "Russland" .Zusätzlich zum Skript zum Erkennen von Token wird ein Skript zum Vorverarbeiten von verarbeiteten Wörtern unterstützt. Dieses Skript kann das Wort ändern, bevor es dem Sprachmodell hinzugefügt wird.Ein Beispiel für ein Textverarbeitungsskript:
def init():
"""
:
"""
def run(word, context):
"""
:
@word
@context
"""
return word
Ein solcher Ansatz kann nützlich sein , wenn es notwendig ist , ein Sprachmodell, bestehend aus zusammen Lemmata oder stemms .Von ALM unterstützte Sprachmodell- Textformate
ARPA:
\data\
ngram 1=52
ngram 2=68
ngram 3=15
\1-grams:
-1.807052 1- -0.30103
-1.807052 2 -0.30103
-1.807052 3~4 -0.30103
-2.332414 -0.394770
-3.185530 -0.311249
-3.055896 -0.441649
-1.150508 </s>
-99 <s> -0.3309932
-2.112406 <unk>
-1.807052 T358 -0.30103
-1.807052 VII -0.30103
-1.503878 -0.39794
-1.807052 -0.30103
-1.62953 -0.30103
...
\2-grams:
-0.29431 1-
-0.29431 2
-0.29431 3~4
-0.8407791 <s>
-1.328447 -0.477121
...
\3-grams:
-0.09521468
-0.166590
...
\end\
ARPA ist das Standardtextformat für das von Sphinx / CMU und Kaldi verwendete Sprachmodell in natürlicher Sprache .NGRAMME:
\data\
ad=1
cw=23832
unq=9390
ngram 1=9905
ngram 2=21907
ngram 3=306
\1-grams:
<s> 2022 | 1
<num> 117 | 1
<unk> 19 | 1
<abbr> 16 | 1
<range> 7 | 1
</s> 2022 | 1
244 | 1
244 | 1
11 | 1
762 | 1
112 | 1
224 | 1
1 | 1
86 | 1
978 | 1
396 | 1
108 | 1
77 | 1
32 | 1
...
\2-grams:
<s> <num> 7 | 1
<s> <unk> 1 | 1
<s> 84 | 1
<s> 83 | 1
<s> 57 | 1
82 | 1
11 | 1
24 | 1
18 | 1
31 | 1
45 | 1
97 | 1
71 | 1
...
\3-grams:
<s> <num> </s> 3 | 1
<s> 6 | 1
<s> 4 | 1
<s> 2 | 1
<s> 3 | 1
2 | 1
</s> 2 | 1
2 | 1
2 | 1
2 | 1
2 | 1
2 | 1
</s> 2 | 1
</s> 3 | 1
2 | 1
...
\end\
Ngrams - nicht standardmäßiges Textformat des Sprachmodells, ist eine Modifikation des ARPA- Formats .Beschreibung:- ad - Anzahl der Dokumente im Gehäuse
- cw - Die Anzahl der Wörter in allen Dokumenten im Korpus
- unq - Anzahl der gesammelten eindeutigen Wörter
VOKABELN:
\data\
ad=1
cw=23832
unq=9390
\words:
33 244 | 1 | 0.010238 | 0.000000 | -3.581616
34 11 | 1 | 0.000462 | 0.000000 | -6.680889
35 762 | 1 | 0.031974 | 0.000000 | -2.442838
40 12 | 1 | 0.000504 | 0.000000 | -6.593878
330344 47 | 1 | 0.001972 | 0.000000 | -5.228637
335190 17 | 1 | 0.000713 | 0.000000 | -6.245571
335192 1 | 1 | 0.000042 | 0.000000 | -9.078785
335202 22 | 1 | 0.000923 | 0.000000 | -5.987742
335206 7 | 1 | 0.000294 | 0.000000 | -7.132874
335207 29 | 1 | 0.001217 | 0.000000 | -5.711489
2282019644 1 | 1 | 0.000042 | 0.000000 | -9.078785
2282345502 10 | 1 | 0.000420 | 0.000000 | -6.776199
2282416889 2 | 1 | 0.000084 | 0.000000 | -8.385637
3009239976 1 | 1 | 0.000042 | 0.000000 | -9.078785
3009763109 1 | 1 | 0.000042 | 0.000000 | -9.078785
3013240091 1 | 1 | 0.000042 | 0.000000 | -9.078785
3014009989 1 | 1 | 0.000042 | 0.000000 | -9.078785
3015727462 2 | 1 | 0.000084 | 0.000000 | -8.385637
3025113549 1 | 1 | 0.000042 | 0.000000 | -9.078785
3049820849 1 | 1 | 0.000042 | 0.000000 | -9.078785
3061388599 1 | 1 | 0.000042 | 0.000000 | -9.078785
3063804798 1 | 1 | 0.000042 | 0.000000 | -9.078785
3071212736 1 | 1 | 0.000042 | 0.000000 | -9.078785
3074971025 1 | 1 | 0.000042 | 0.000000 | -9.078785
3075044360 1 | 1 | 0.000042 | 0.000000 | -9.078785
3123271427 1 | 1 | 0.000042 | 0.000000 | -9.078785
3123322362 1 | 1 | 0.000042 | 0.000000 | -9.078785
3126399411 1 | 1 | 0.000042 | 0.000000 | -9.078785
…
Vocab ist ein nicht standardmäßiges Textwörterbuchformat im Sprachmodell.Beschreibung:- ok - Fallvorkommen
- Gleichstrom - Vorkommen in Dokumenten
- tf - (term frequency — ) — . , , : [tf = oc / cw]
- idf - (inverse document frequency — ) — , , : [idf = log(ad / dc)]
- tf-idf - : [tf-idf = tf * idf]
- wltf - , : [wltf = 1 + log(tf * dc)]
MAP:
1:{2022,1,0}|42:{57,1,0}|279603:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|320749:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|351283:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|379815:{3,1,0}
1:{2022,1,0}|42:{57,1,0}|26122748:{3,1,0}
1:{2022,1,0}|44:{6,1,0}
1:{2022,1,0}|48:{1,1,0}
1:{2022,1,0}|51:{11,1,0}|335967:{3,1,0}
1:{2022,1,0}|53:{14,1,0}|371327:{3,1,0}
1:{2022,1,0}|53:{14,1,0}|40260976:{7,1,0}
1:{2022,1,0}|65:{68,1,0}|34:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|3277:{3,1,0}
1:{2022,1,0}|65:{68,1,0}|278003:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|320749:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|11353430797:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|34270133320:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|51652356484:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|66967237546:{2,1,0}
1:{2022,1,0}|2842:{11,1,0}|42:{7,1,0}
…
Karte - der Inhalt der Datei hat eine rein technische Bedeutung. In Verbindung mit der Vokabeldatei können Sie mehrere Sprachmodelle kombinieren, ändern, speichern, verteilen und in ein beliebiges Format exportieren ( arpa , ngrams , binary alm ).Beim Zusammenstellen eines Sprachmodells treten häufig Tippfehler im Text auf, bei denen es sich um Substitutionen von Buchstaben handelt (mit visuell ähnlichen Buchstaben eines anderen Alphabets).ALM löst dieses Problem mit einer Datei mit ähnlich aussehenden Buchstaben.p
c
o
t
k
e
a
h
x
b
m
Wenn Sie beim Unterrichten eines Sprachmodells Dateien mit einer Liste von Domänen und Abkürzungen der ersten Ebene übertragen können, kann ALM bei der genaueren Erkennung der Klassen-Tags 〈url〉 und 〈abbr helfen .Abkürzungen Listendatei:
…
Domain Zone List File:
ru
su
cc
net
com
org
info
…
Um das 〈url〉 -Token genauer zu erkennen , sollten Sie Ihre Domänenzonen der ersten Ebene hinzufügen (alle Domänenzonen aus dem Beispiel sind bereits vorinstalliert) .Binärcontainer des ALM- Sprachmodells
Um einen Binärcontainer für das Sprachmodell zu erstellen, müssen Sie eine JSON-Datei mit einer Beschreibung Ihrer Parameter erstellen .JSON-Optionen:
{
"aes": 128,
"name": "Name dictionary",
"author": "Name author",
"lictype": "License type",
"lictext": "License text",
"contacts": "Contacts data",
"password": "Password if needed",
"copyright": "Copyright author"
}
Beschreibung:- aes - AES-Verschlüsselungsgröße (128, 192, 256) Bit
- name - Wörterbuchname
- author - Wörterbuchautor
- lictype - Art der Lizenz
- lictext - Lizenztext
- Kontakte - Kontaktdaten des Autors
- Passwort - Verschlüsselungskennwort (falls erforderlich), Verschlüsselung wird nur beim Festlegen eines Passworts durchgeführt
- copyright - Copyright des Wörterbuchbesitzers
Alle Parameter außer dem Namen des Containers sind optional.Beispiele für ALM- Bibliotheken
Tokenizer-Betrieb
Der Tokenizer empfängt Text an der Eingabe und generiert JSON an der Ausgabe.$ echo 'Hello World?' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
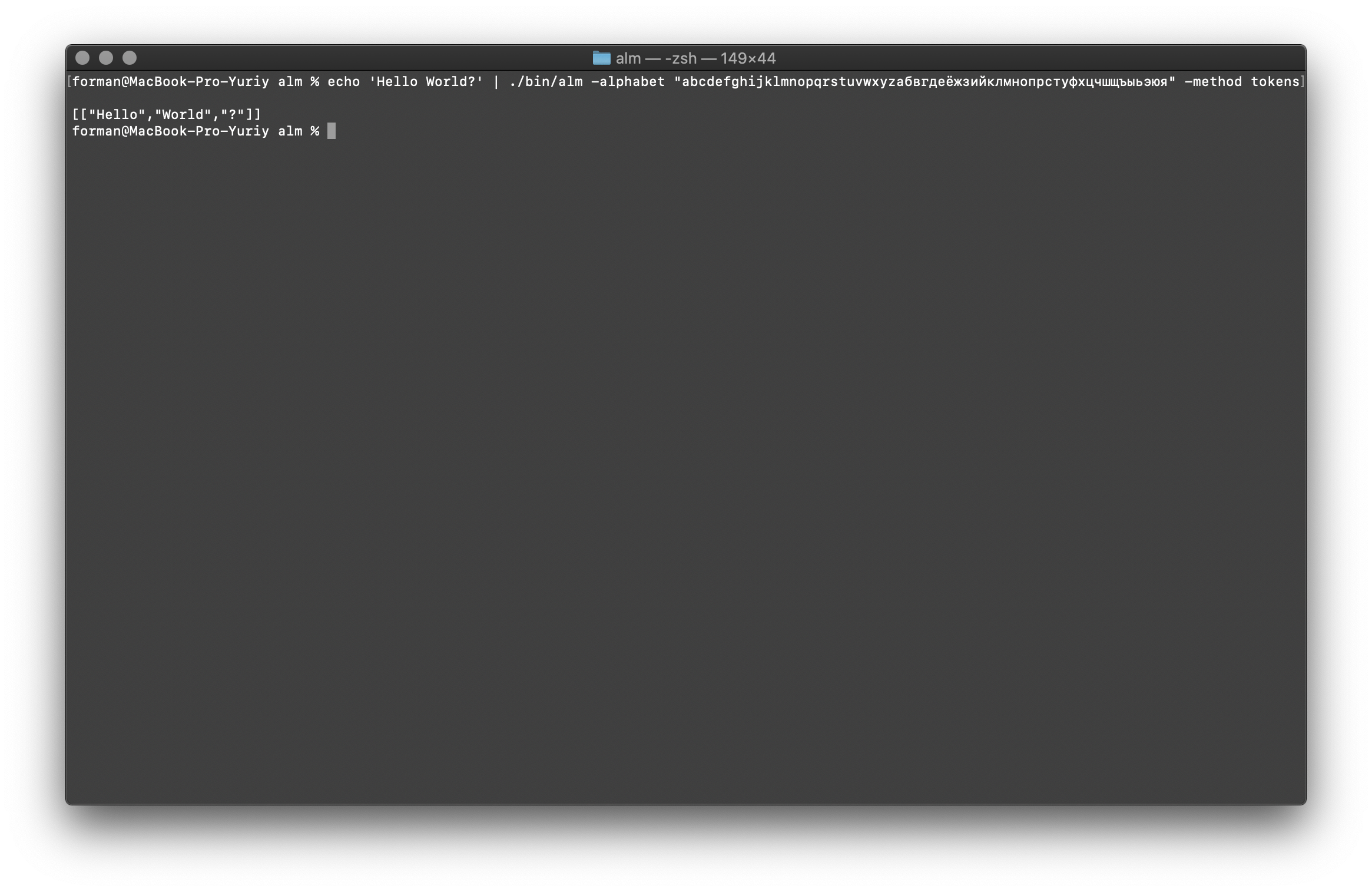 Prüfung:
Prüfung:Hello World?
Ergebnis:[
["Hello","World","?"]
]
Versuchen wir etwas härteres ...$ echo ' ??? ....' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
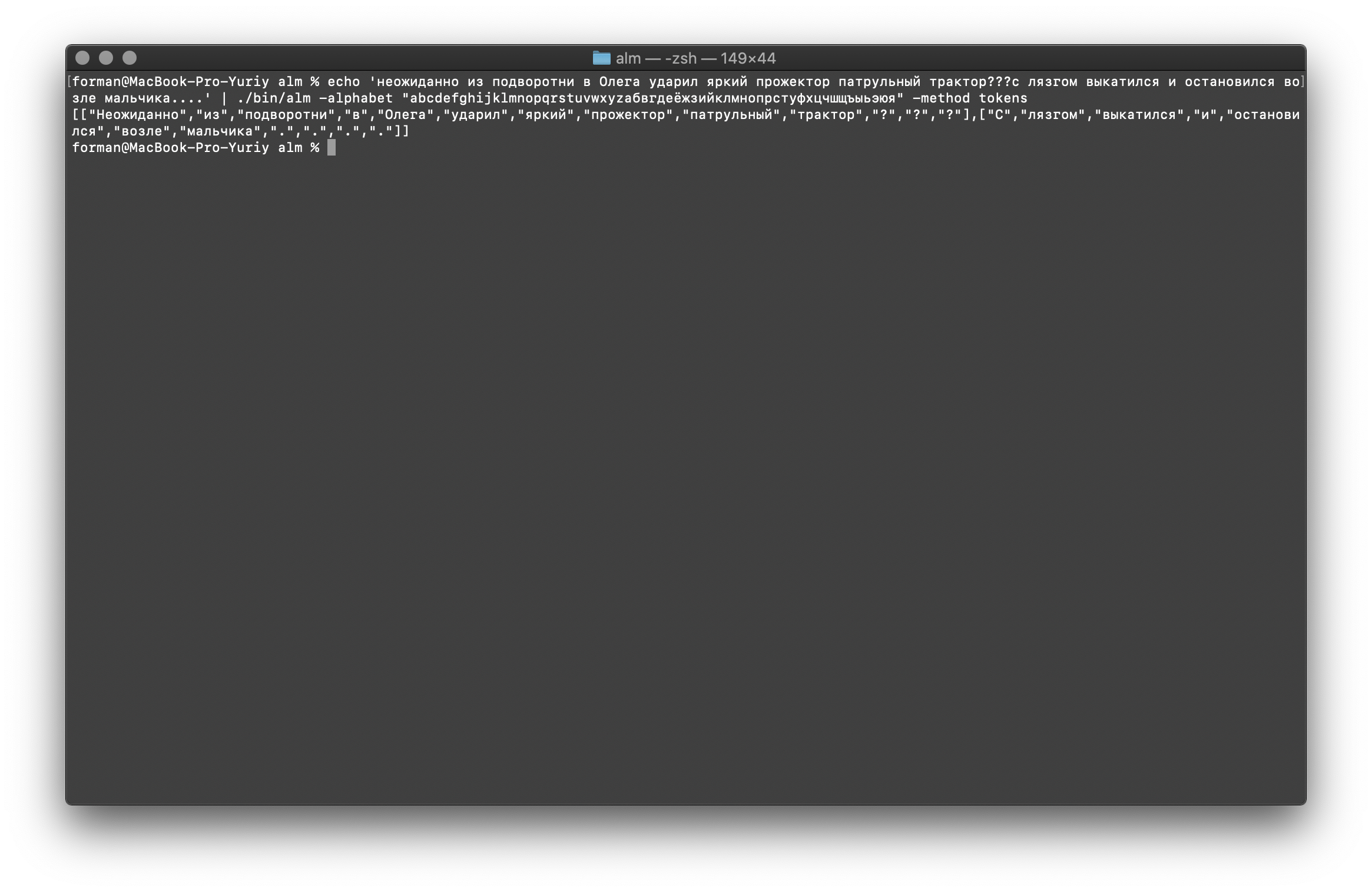 Prüfung:
Prüfung: ??? ....
Ergebnis:[
[
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"?",
"?",
"?"
],[
"",
"",
"",
"",
"",
"",
"",
".",
".",
".",
"."
]
]
Wie Sie sehen können, hat der Tokenizer ordnungsgemäß funktioniert und die grundlegenden Fehler behoben.Ändern Sie den Text ein wenig und sehen Sie das Ergebnis.$ echo ' ... .' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
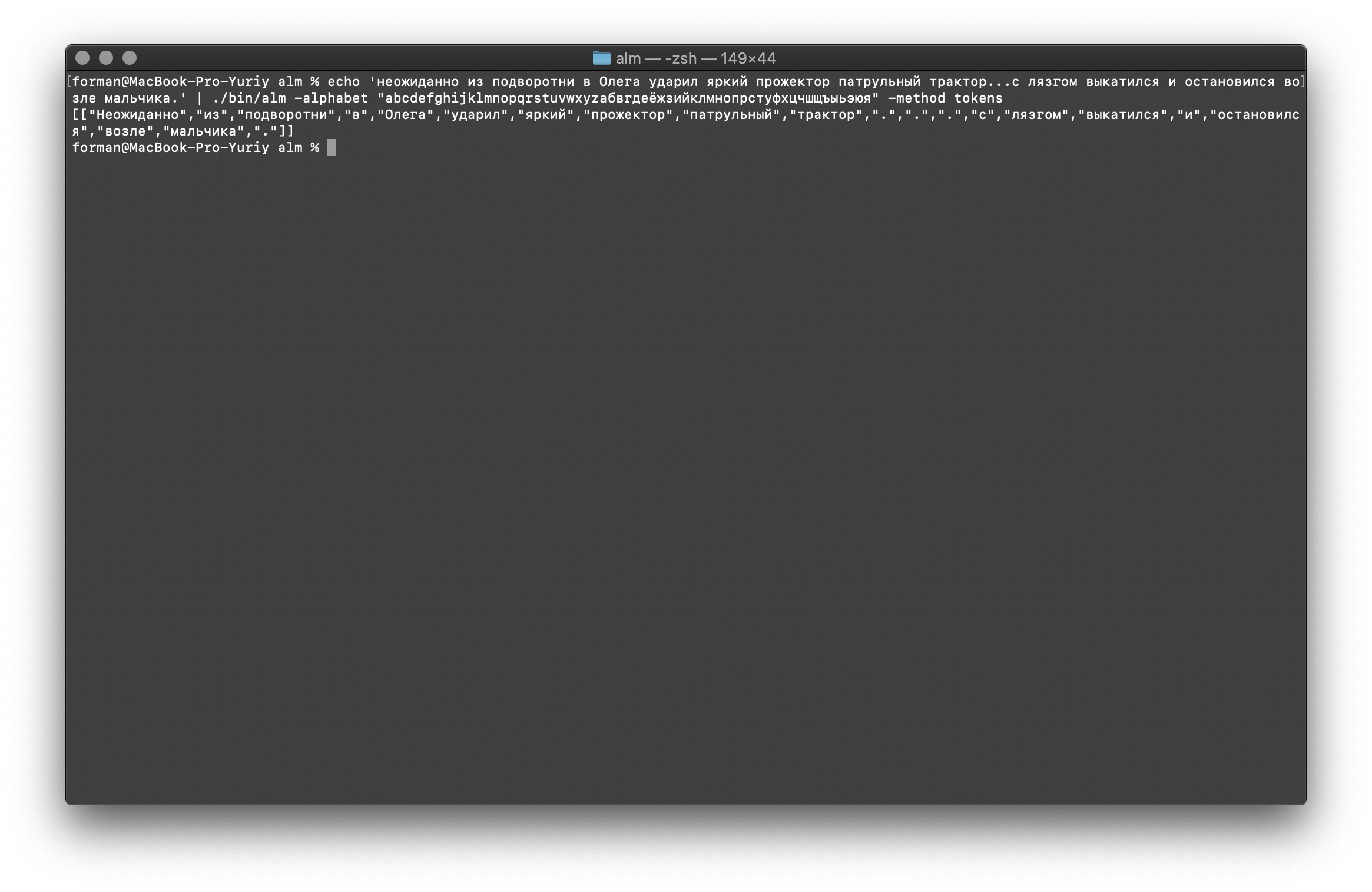 Prüfung:
Prüfung: ... .
Ergebnis:[
[
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
".",
".",
".",
"",
"",
"",
"",
"",
"",
"",
"."
]
]
Wie Sie sehen, hat sich das Ergebnis geändert. Versuchen Sie jetzt etwas anderes.$ echo ' 5–7 . : 1 . ( +37–38°), 5–10 . – ( +12–15°) ..»| |()' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
 Prüfung:
Prüfung: 5–7 . : 1 . ( +37–38°), 5–10 . – ( +12–15°) ..»| |()
Ergebnis:[
[
"",
"",
"",
"",
"5–7",
".",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
":",
"1",
".",
"",
"",
"(",
"+37–38°",
")",
",",
"",
"5–10",
".",
"–",
"",
"",
"(",
"+12–15°",
")",
"",
"..",
"»",
"|",
"|",
"(",
")"
]
]
Kombiniere alles wieder zu Text
Stellen Sie zunächst den ersten Test wieder her.$ echo '[["Hello","World","?"]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
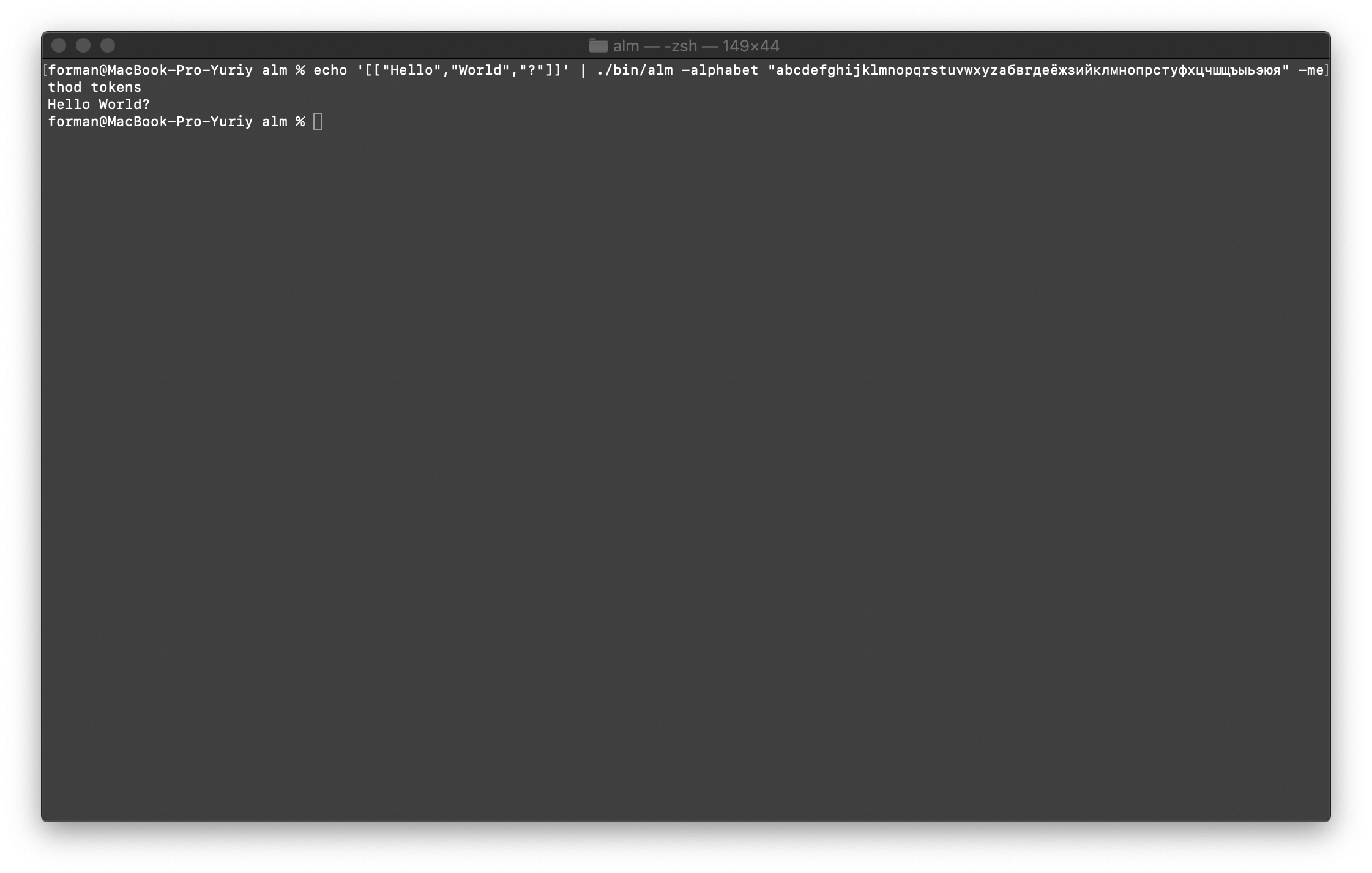 Prüfung:
Prüfung:[["Hello","World","?"]]
Ergebnis:Hello World?
Wir werden jetzt den komplexeren Test wiederherstellen.$ echo '[["","","","","","","","","","","?","?","?"],["","","","","","","",".",".",".","."]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
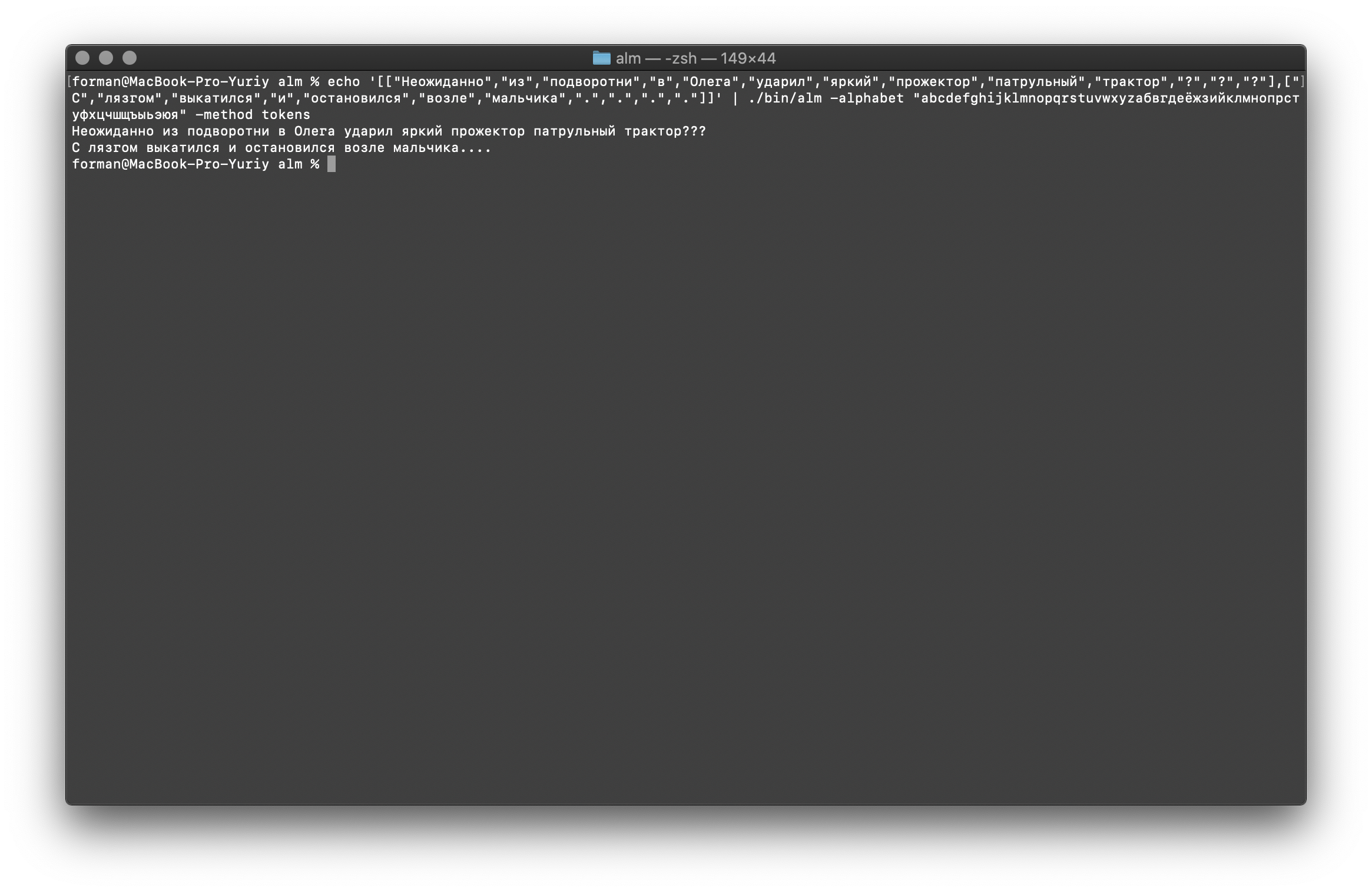 Prüfung:
Prüfung:[["","","","","","","","","","","?","?","?"],["","","","","","","",".",".",".","."]]
Ergebnis: ???
….
Wie Sie sehen können, konnte der Tokenizer den ursprünglich fehlerhaften Text wiederherstellen.Weitermachen mit.$ echo '[["","","","","","","","","","",".",".",".","","","","","","","","."]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
 Prüfung:
Prüfung:[["","","","","","","","","","",".",".",".","","","","","","","","."]]
Ergebnis: ... .
Und schließlich überprüfen Sie die schwierigste Option.$ echo '[["","","","","5–7",".","","","","","","","","","","","","","",":","1",".","","","(","+37–38°",")",",","","5–10",".","–","","","(","+12–15°",")","","..","»","|","|","(",")"]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
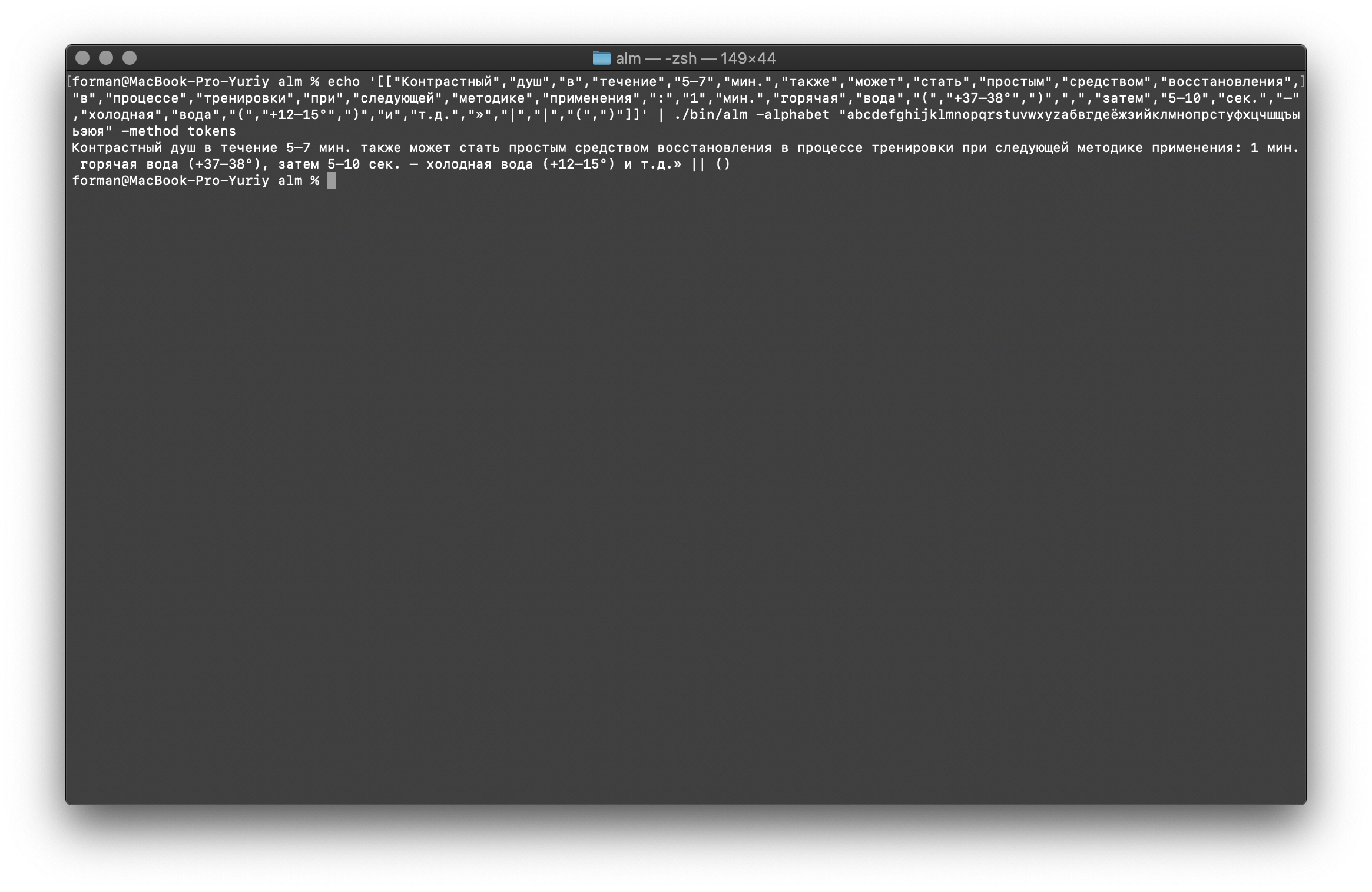 Prüfung:
Prüfung:[["","","","","5–7",".","","","","","","","","","","","","","",":","1",".","","","(","+37–38°",")",",","","5–10",".","–","","","(","+12–15°",")","","..","»","|","|","(",")"]]
Ergebnis: 5–7 . : 1 . (+37–38°), 5–10 . – (+12–15°) ..» || ()
Wie aus den Ergebnissen hervorgeht, kann der Tokenizer die meisten Fehler im Textdesign beheben.Sprachmodelltraining
$ ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -size 3 -smoothing wittenbell -method train -debug 1 -w-arpa ./lm.arpa -w-map ./lm.map -w-vocab ./lm.vocab -w-ngram ./lm.ngrams -allow-unk -interpolate -corpus ./text.txt -threads 0 -train-segments
Ich werde die Baugruppenparameter genauer beschreiben.- Größe - Die Größe der Länge von N-Gramm (die Größe ist auf 3 Gramm eingestellt )
- Glättung - Glättungsalgorithmus (von Witten-Bell ausgewählter Algorithmus )
- Methode - Arbeitsmethode (Methode spezifiziertes Training )
- Debug - Debug-Modus (Lernstatusanzeige ist gesetzt)
- w-arpa — ARPA
- w-map — MAP
- w-vocab — VOCAB
- w-ngram — NGRAM
- allow-unk — 〈unk〉
- interpolate —
- corpus — . ,
- Threads - Verwenden Sie Multithreading für das Training (0 - für das Training werden alle verfügbaren Prozessorkerne angegeben,> 0 die Anzahl der am Training teilnehmenden Kerne)
- Zugsegmente - Das Schulungsgebäude wird gleichmäßig über alle Kerne verteilt
Weitere Informationen erhalten Sie mit dem Flag [-help] .
Ratlosigkeit
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method ppl -debug 2 -r-arpa ./lm.arpa -confidence -threads 0
 Prüfung:
Prüfung: ??? ….
Ergebnis:info: <s> <punct> <punct> <punct> </s>
info: p( | <s> ) = [2gram] 0.00209192 [ -2.67945500 ] / 0.99999999
info: p( | ...) = [3gram] 0.91439744 [ -0.03886500 ] / 1.00000035
info: p( | ...) = [3gram] 0.86302624 [ -0.06397600 ] / 0.99999998
info: p( | ...) = [3gram] 0.98003368 [ -0.00875900 ] / 1.00000088
info: p( | ...) = [3gram] 0.85783547 [ -0.06659600 ] / 0.99999955
info: p( | ...) = [3gram] 0.95238819 [ -0.02118600 ] / 0.99999897
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( <punct> | ...) = [3gram] 0.78127873 [ -0.10719400 ] / 1.00000031
info: p( <punct> | <punct> ...) = [2gram] 0.29417110 [ -0.53140000 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( </s> | <punct> ...) = [3gram] 0.45569787 [ -0.34132300 ] / 0.99999998
info: 1 sentences, 13 words, 0 OOVs
info: 0 zeroprobs, logprob= -4.18477000 ppl= 1.99027067 ppl1= 2.09848266
info: <s> <punct> <punct> <punct> <punct> </s>
info: p( | <s> ) = [2gram] 0.00809597 [ -2.09173100 ] / 0.99999999
info: p( | ...) = [3gram] 0.19675329 [ -0.70607800 ] / 0.99999972
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.98007204 [ -0.00874200 ] / 0.99999931
info: p( | ...) = [3gram] 0.85785325 [ -0.06658700 ] / 1.00000018
info: p( | ...) = [3gram] 0.81482810 [ -0.08893400 ] / 1.00000027
info: p( | ...) = [3gram] 0.93507404 [ -0.02915400 ] / 1.00000058
info: p( <punct> | ...) = [3gram] 0.76391493 [ -0.11695500 ] / 0.99999971
info: p( <punct> | <punct> ...) = [2gram] 0.29417110 [ -0.53140000 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( </s> | <punct> ...) = [3gram] 0.45569787 [ -0.34132300 ] / 0.99999998
info: 1 sentences, 11 words, 0 OOVs
info: 0 zeroprobs, logprob= -4.57026500 ppl= 2.40356248 ppl1= 2.60302678
info: 2 sentences, 24 words, 0 OOVs
info: 0 zeroprobs, logprob= -8.75503500 ppl= 2.23975957 ppl1= 2.31629103
info: work time shifting: 0 seconds
Ich denke, es gibt nichts Besonderes zu kommentieren, also werden wir weiter machen.Kontextexistenzprüfung
$ echo "<s> </s>" | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method checktext -debug 1 -r-arpa ./lm.arpa -confidence
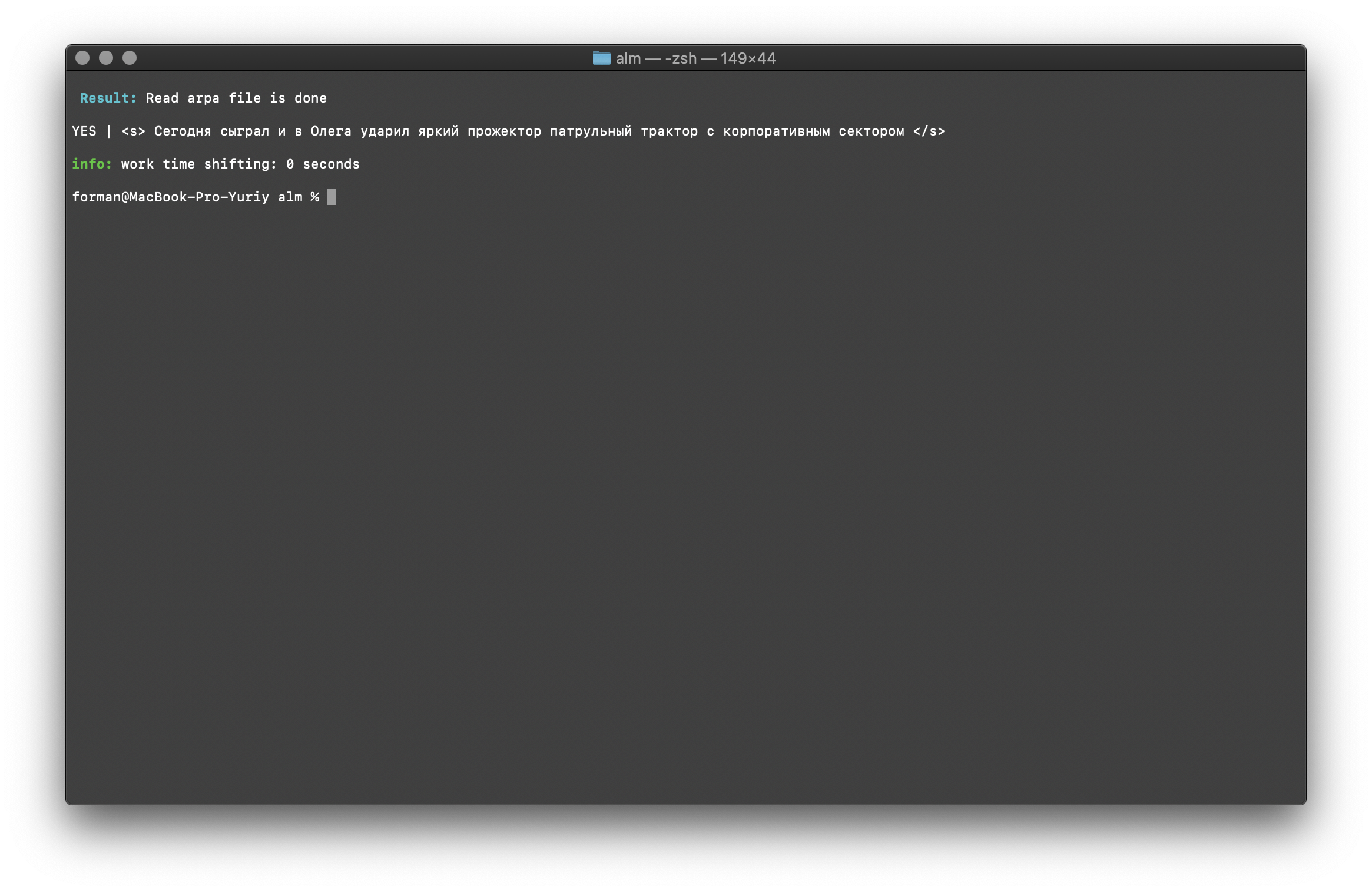 Prüfung:
Prüfung:<s> </s>
Ergebnis:YES | <s> </s>
Das Ergebnis zeigt, dass der zu prüfende Text hinsichtlich des zusammengestellten Sprachmodells den richtigen Kontext aufweist.Flag [ -confidence ] - bedeutet, dass das Sprachmodell so geladen wird, wie es erstellt wurde, ohne zu übertönen.Korrektur der Groß- und Kleinschreibung
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method fixcase -debug 1 -r-arpa ./lm.arpa -confidence
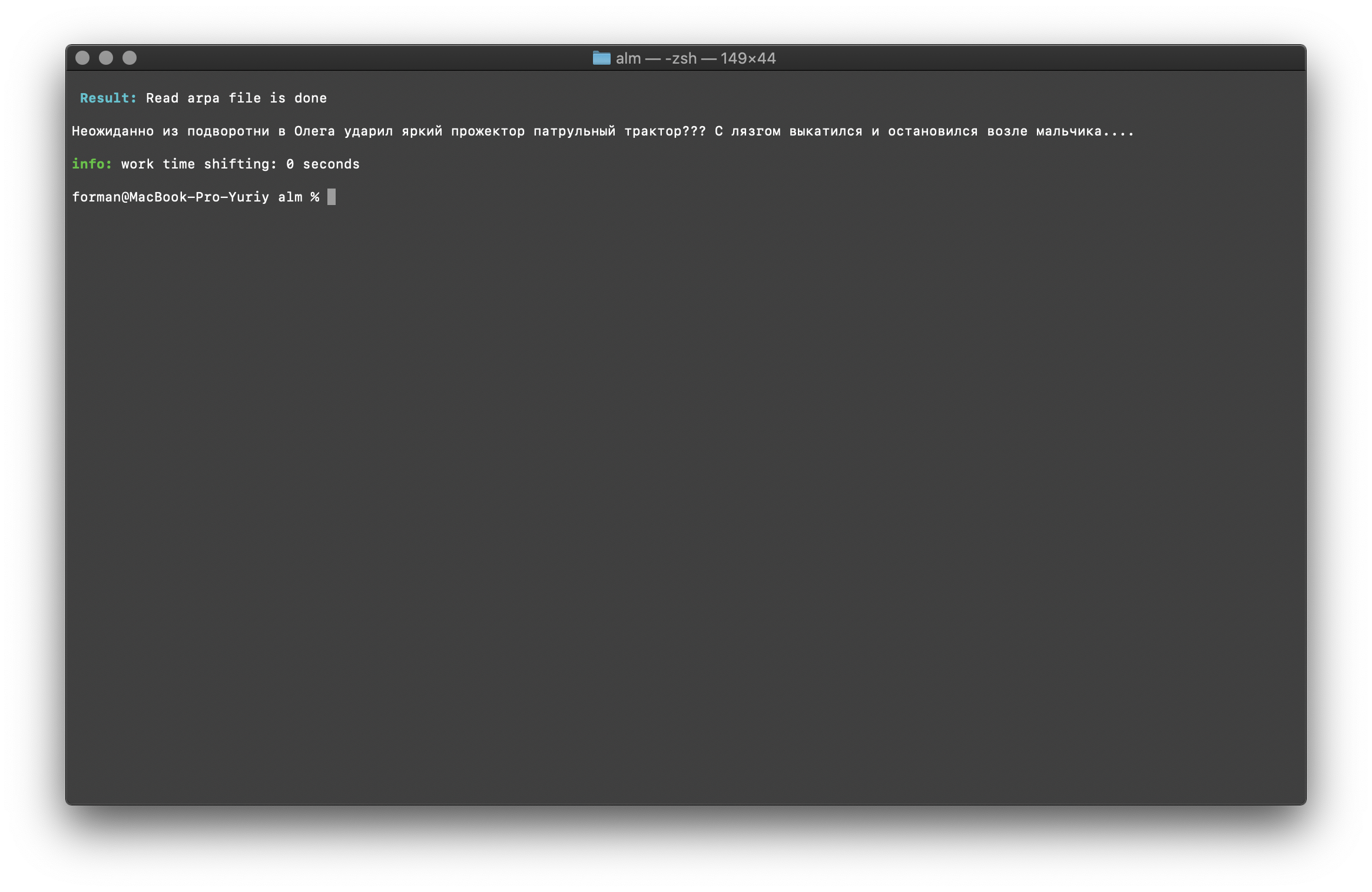 Prüfung:
Prüfung: ??? ....
Ergebnis: ??? ....
Register im Text werden unter Berücksichtigung des Kontexts des Sprachmodells wiederhergestellt.Bei den oben beschriebenen Bibliotheken für die Arbeit mit statistischen Sprachmodellen wird zwischen Groß- und Kleinschreibung unterschieden. Zum Beispiel ist das N-Gramm „ morgen wird es in Moskau regnen “ nicht dasselbe wie das N-Gramm „ morgen wird es in Moskau regnen “, das sind völlig andere N-Gramm. Was aber, wenn der Fall zwischen Groß- und Kleinschreibung unterscheiden muss und gleichzeitig das Duplizieren derselben N-Gramm irrational ist? ALM repräsentiert alle N-Gramm in Kleinbuchstaben. Dies eliminiert die Möglichkeit der Verdoppelung von N-Gramm. ALM behält auch seine Rangfolge der Wortregister in jedem N-Gramm bei. Beim Exportieren in das Textformat eines Sprachmodells werden die Register abhängig von ihrer Bewertung wiederhergestellt.Überprüfen der Anzahl der N-Gramm
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method counts -debug 1 -r-arpa ./lm.arpa -confidence
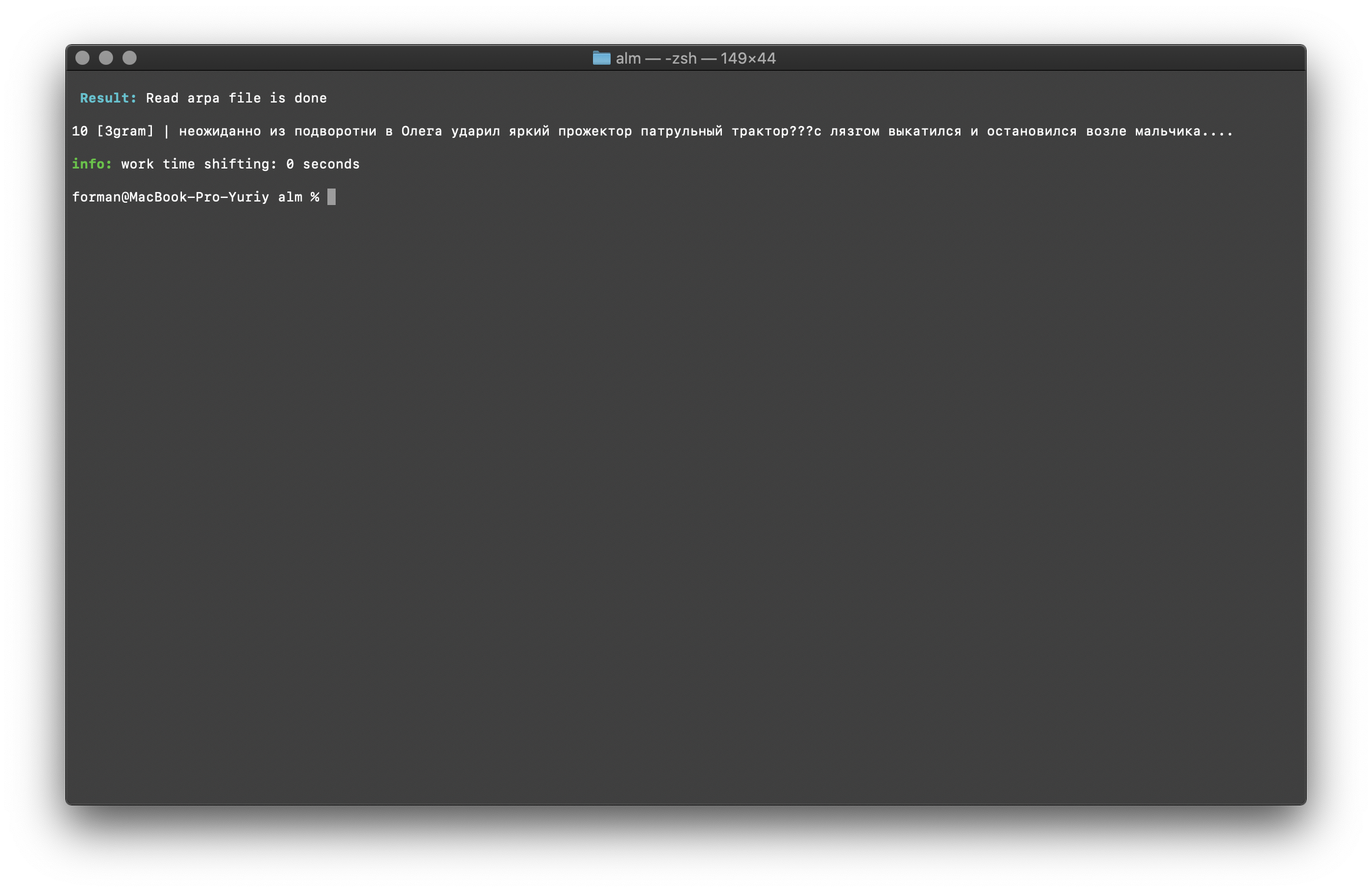 Prüfung:
Prüfung: ??? ....
Ergebnis:10 [3gram] |
N- , .
Die Überprüfung der Anzahl der N-Gramm erfolgt anhand der Größe des N-Gramms im Sprachmodell. Es besteht auch die Möglichkeit, nach Bigrams und Trigrammen zu suchen .Bigram Check
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method counts -ngrams bigram -debug 1 -r-arpa ./lm.arpa -confidence
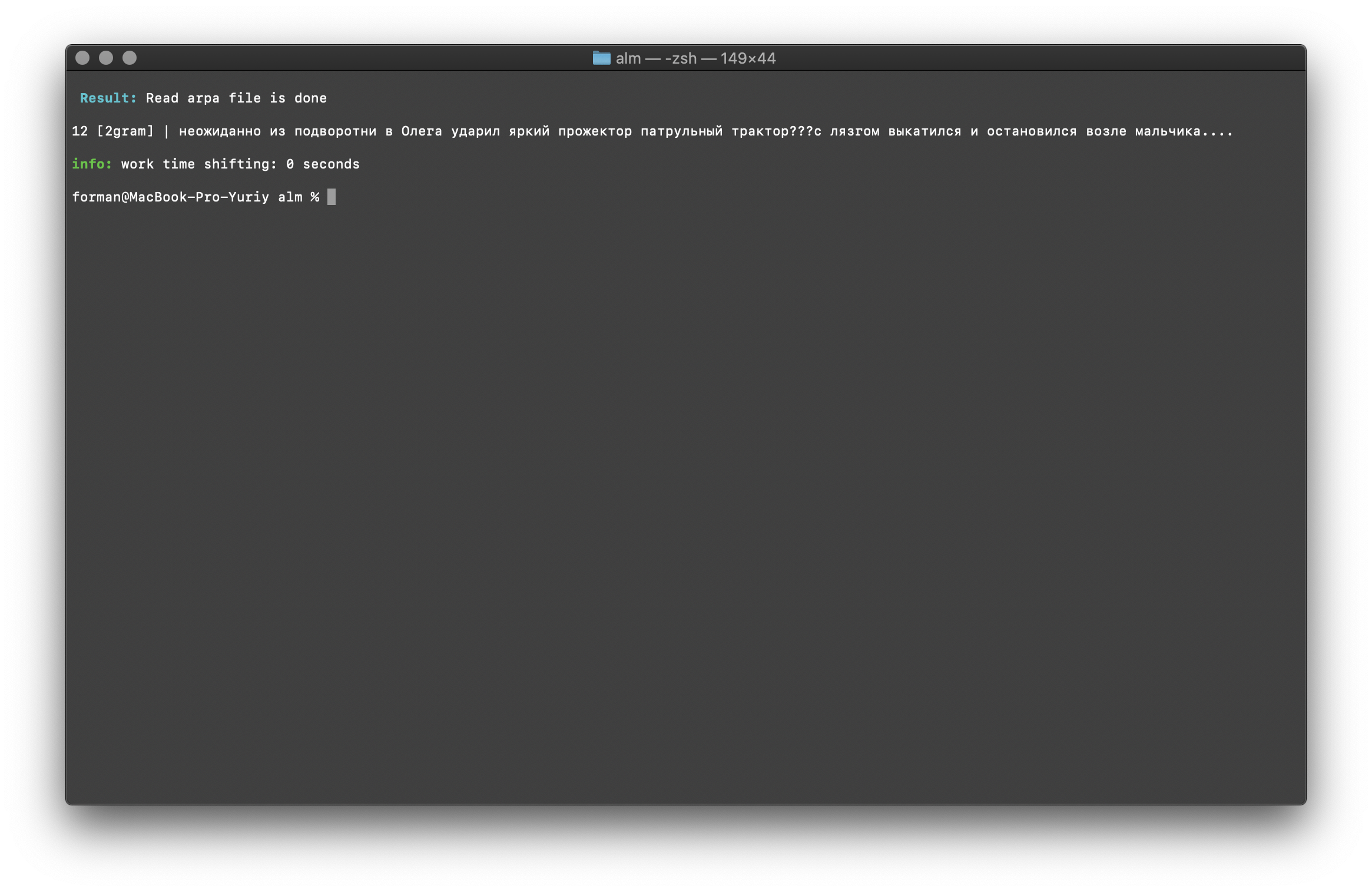 Prüfung:
Prüfung: ??? ....
Ergebnis:12 [2gram] | ??? ….
Trigrammprüfung
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method counts -ngrams trigram -debug 1 -r-arpa ./lm.arpa -confidence
Prüfung: ??? ....
Ergebnis:10 [3gram] | ??? ….
Suchen Sie im Text nach N-Gramm
$ echo " " | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method find -debug 1 -r-arpa ./lm.arpa -confidence
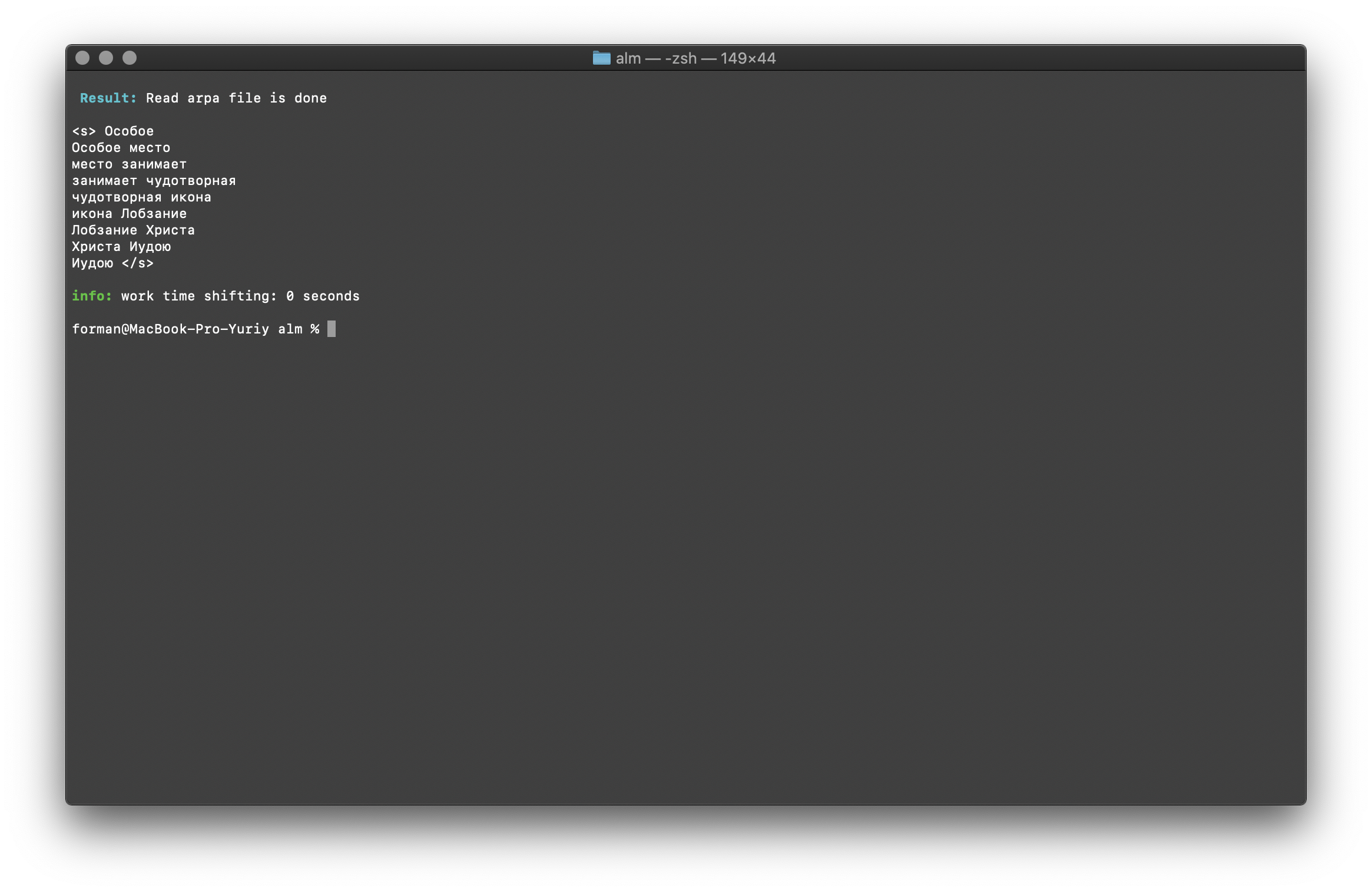 Prüfung:
Prüfung:
Ergebnis:<s>
</s>
Eine Liste der N-Gramm, die im Text enthalten sind. Hier gibt es nichts Besonderes zu erklären.Umgebungsvariablen
Alle Parameter können über Umgebungsvariablen übergeben werden. Variablen beginnen mit dem Präfix ALM_ und müssen in Großbuchstaben geschrieben werden. Ansonsten entsprechen die Variablennamen den Anwendungsparametern.Wenn sowohl Anwendungsparameter als auch Umgebungsvariablen angegeben werden, erhalten Anwendungsparameter Vorrang.$ export $ALM_SMOOTHING=wittenbell
$ export $ALM_W-ARPA=./lm.arpa
Somit kann der Montageprozess automatisiert werden. Zum Beispiel über BASH-Skripte.Fazit
Ich verstehe, dass es vielversprechendere Technologien wie RnnLM oder Bert gibt . Ich bin mir aber sicher, dass statistische N-Gramm-Modelle noch lange relevant sein werden.Diese Arbeit hat viel Zeit und Mühe gekostet. In seiner Freizeit war er nachts und am Wochenende in der Bibliothek beschäftigt. Der Code deckte die Tests nicht ab, Fehler und Bugs sind möglich. Ich werde für das Testen dankbar sein. Ich bin auch offen für Verbesserungsvorschläge und neue Bibliotheksfunktionen. ALM wird unter der MIT-Lizenz vertrieben , sodass Sie es nahezu ohne Einschränkungen verwenden können.Ich hoffe auf Kommentare, Kritik, Vorschläge.Projektstandort Projekt-Repository