Vielleicht haben Sie sich der Aufgabe gestellt, parallel auf Pandas-Datenrahmen zu rechnen. Dieses Problem kann sowohl mit nativem Python als auch mit Hilfe einer wunderbaren Bibliothek - pandarallel - gelöst werden. In diesem Artikel werde ich zeigen, wie Sie mit dieser Bibliothek Ihre Daten mit allen verfügbaren Kapazitäten verarbeiten können.
Die Bibliothek ermöglicht es Ihnen, nicht über die Anzahl der Threads nachzudenken, Prozesse zu erstellen, und bietet eine interaktive Schnittstelle zur Überwachung des Fortschritts.
Installation
pip install pandas jupyter pandarallel requests tqdm
Wie Sie sehen können, installiere ich auch tqdm. Damit werde ich den Unterschied in der Geschwindigkeit der Codeausführung in einem sequentiellen und parallelen Ansatz deutlich machen.
Anpassung
import pandas as pd
import requests
from tqdm import tqdm
tqdm.pandas()
from pandarallel import pandarallel
pandarallel.initialize(progress_bar=True)
Die vollständige Liste der Einstellungen finden Sie in der pandarallelen Dokumentation.
Erstellen Sie einen Datenrahmen
Erstellen Sie für Experimente einen einfachen Datenrahmen - 100 Zeilen, 1 Spalte.
df = pd.DataFrame(
[i for i in range(100)],
columns=["sample_column"]
)

Beispiel einer für die Parallelisierung geeigneten Aufgabe
Wie wir wissen, kann die Lösung nicht aller Probleme parallelisiert werden. Ein einfaches Beispiel für eine geeignete Aufgabe ist das Aufrufen einer externen Quelle, z. B. einer API oder einer Datenbank. In der folgenden Funktion rufe ich eine API auf, die mir ein zufälliges Wort zurückgibt. Mein Ziel ist es, dem Datenrahmen eine Spalte mit Wörtern hinzuzufügen, die von dieser API abgeleitet sind.
def function_to_apply(i):
r = requests.get(f'https://random-word-api.herokuapp.com/word').json()
return r[0]
df["sample-word"] = df.sample_column.progress_apply(function_to_apply)
, tqdm, — progress_apply apply. , , progress bar.

"" 35 .
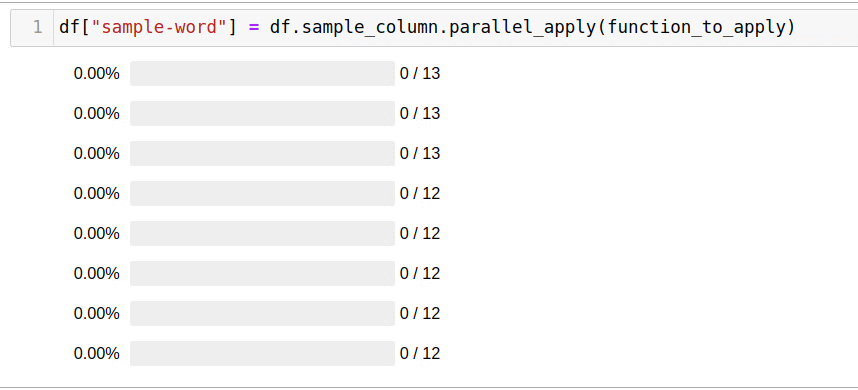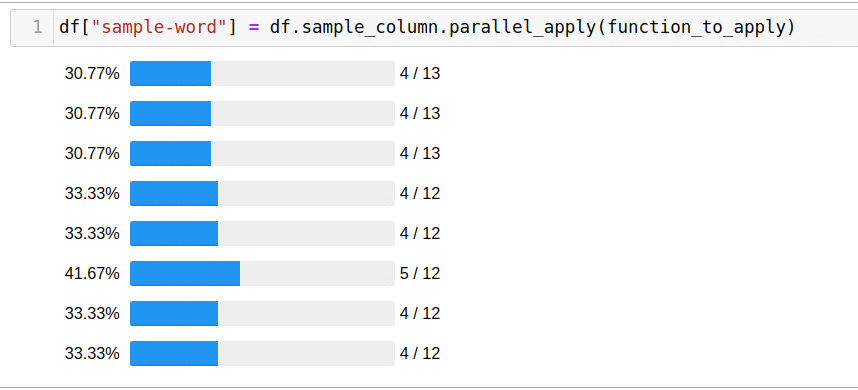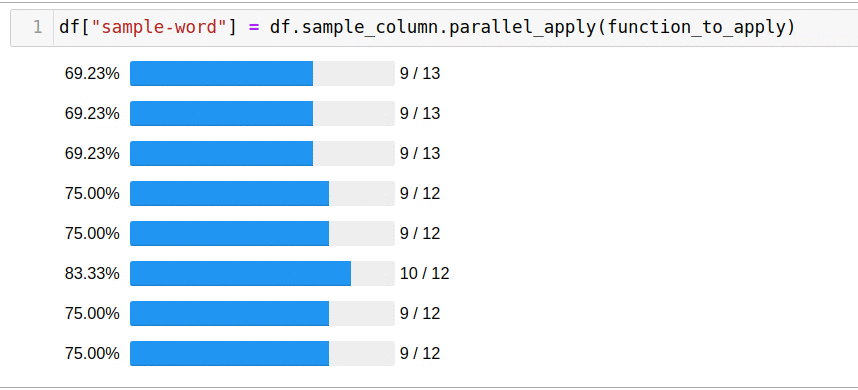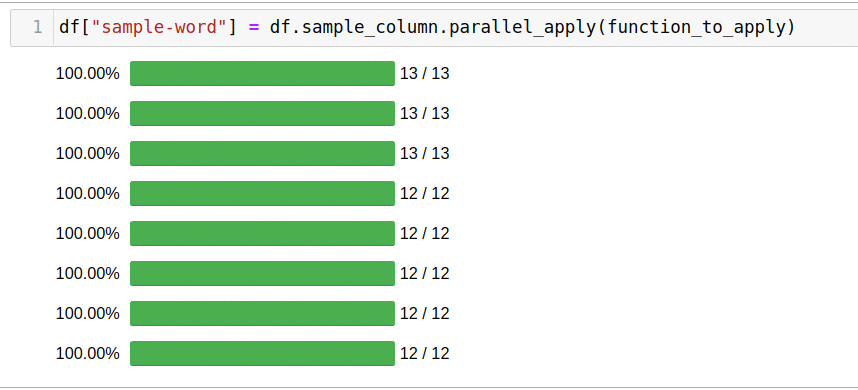
, parallel_apply:
df["sample-word"] = df.sample_column.parallel_apply(function_to_apply)
5 .
pandas , pandarallel, Github .

! — .