Was soll ich tun, wenn ich viele „Fakten“ in die Datenbank eines viel größeren Volumens schreiben möchte, als es aushalten kann? Zunächst bringen wir die Daten natürlich in eine wirtschaftlichere Normalform und erhalten „Wörterbücher“, die wir einmal schreiben werden . Aber wie geht das am effektivsten?Dies ist genau die Frage, mit der wir bei der Entwicklung der Überwachung und Analyse von PostgreSQL-Serverprotokollen konfrontiert waren , als andere Methoden zur Optimierung des Datensatzes in der Datenbank erschöpft waren.Wir reservieren sofort, dass auf unseren Sammlern Node.js ausgeführt wird , sodass wir in keiner Weise mit Prozessorregistern und Caches interagieren. Und die Option, "hundert" oder externe Caching-Dienste / Datenbanken zu verwenden, führt zu einer zu großen Verzögerung für eingehende Streams mit mehreren hundert Mbit / s .Daher versuchen wir, alles im RAM zwischenzuspeichern , insbesondere im Speicher des JavaScript-Prozesses. Wie wir dies effizienter organisieren können, und wir werden noch weiter gehen.Verfügbarkeits-Caching
Unsere Hauptaufgabe besteht darin, sicherzustellen, dass die einzige Instanz eines Objekts in die Datenbank gelangt. Dies sind die wiederholt wiederholten Originaltexte von SQL-Abfragen, Vorlagen von Plänen für ihre Implementierung , Knoten dieser Pläne - kurz einige Textblöcke .In der UUIDVergangenheit haben wir als Bezeichner einen Wert verwendet, der als Ergebnis der direkten Berechnung des MD5-Hash aus dem Text des Objekts erhalten wurde. Danach überprüfen wir die Verfügbarkeit eines solchen Hash im lokalen "Wörterbuch" im Prozessspeicher , und wenn er nicht vorhanden ist, schreiben wir erst dann in die Datenbank in der Tabelle "Wörterbuch".Das heißt, wir müssen den ursprünglichen Textwert nicht selbst speichern (und manchmal dauert es mehrere zehn Kilobyte) - allein die Tatsache, dass der entsprechende Hash im Wörterbuch vorhanden ist, reicht aus .Schlüsselwörterbuch
Ein solches Wörterbuch kann aufbewahrt Arrayund Array.includes()zur Überprüfung der Verfügbarkeit verwendet werden, dies ist jedoch ziemlich redundant - die Suche verschlechtert sich (zumindest in früheren Versionen von V8) linear von der Größe des Arrays O (N). Und in modernen Implementierungen verliert es trotz aller Optimierungen mit einer Geschwindigkeit von 2-3%.In der Zeit vor ES6 war Speicher daher die traditionelle Lösung Objectmit gespeicherten Werten als Schlüssel. Aber jeder hat den Werten der Schlüssel das zugewiesen, was er wollte - zum Beispiel Boolean:var dict = {};
function has(key) {
return dict[key] !== undefined;
}
function add(key) {
dict[key] = true;
}
Es ist jedoch ziemlich offensichtlich, dass wir hier eindeutig den Überschuss speichern - den Wert des Schlüssels, den niemand benötigt. Aber was ist, wenn es überhaupt nicht gespeichert ist? Also erschien das Set-Objekt .Ist Tests zeigen , dass mit Hilfe der Suche Set.has()etwa 20-25% schneller als Schlüsselüberprüfung c Object. Dies ist jedoch nicht sein einziger Vorteil. Da wir weniger speichern, sollten wir weniger Speicher benötigen - und dies wirkt sich direkt auf die Leistung aus, wenn es um Hunderttausende solcher Schlüssel geht.Also, Objectin der es 100 UUID Schlüssel in einer Textdarstellung, nimmt es 6216 Bytes im Speicher :
Setmit dem gleichen Inhalt - 2632 Bytes :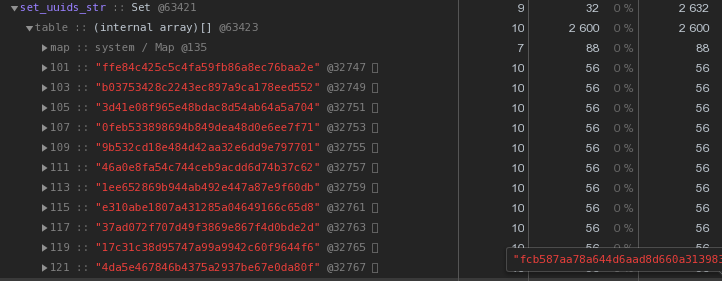 Das heißt, es
Das heißt, es Setarbeitet schneller und zugleich nimmt2,5-mal weniger Speicher - der Gewinner liegt auf der Hand.Wir optimieren die Speicherung von UUID-Schlüsseln
In der Regel in der Art von verteilten Systemen, UUID Schlüssel sind durchaus üblich - in unserem VLSI sie sind, auf ein Minimum, verwendet , um Dokumente und Vorschriften zu identifizieren , die elektronische Dokumentenverwaltung , die Menschen in Messaging , ...Nun lasst uns schauen Sie genau auf das Bild oben - jeder UUID- Der in der Hex-Darstellung gespeicherte Schlüssel „kostet“ uns 56 Byte Speicher . Aber wir haben Hunderttausende von ihnen, daher ist es vernünftig zu fragen: "Ist es möglich, weniger zu haben?"Denken Sie zunächst daran, dass die UUID eine 16-Byte-Kennung ist. Im Wesentlichen ein Stück Binärdaten. Und für die Übertragung per E-Mail werden beispielsweise Binärdaten in base64 codiert - versuchen Sie, sie anzuwenden:let str = Buffer.from(uuidstr, 'hex').toString('base64');
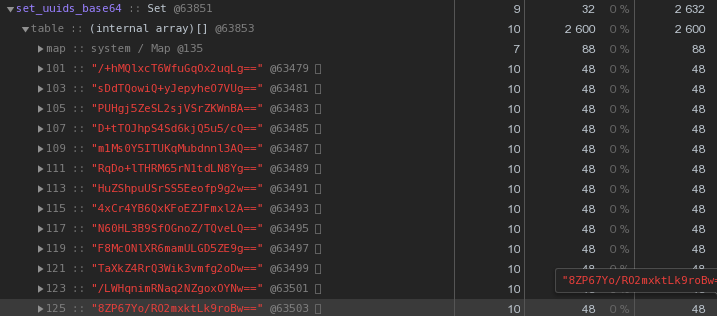 Bereits 48 Bytes sind besser, aber unvollkommen. Versuchen wir, die hexadezimale Darstellung direkt in eine Zeichenfolge zu übersetzen:
Bereits 48 Bytes sind besser, aber unvollkommen. Versuchen wir, die hexadezimale Darstellung direkt in eine Zeichenfolge zu übersetzen:let str = Buffer.from(uuidstr, 'hex').toString('binary');
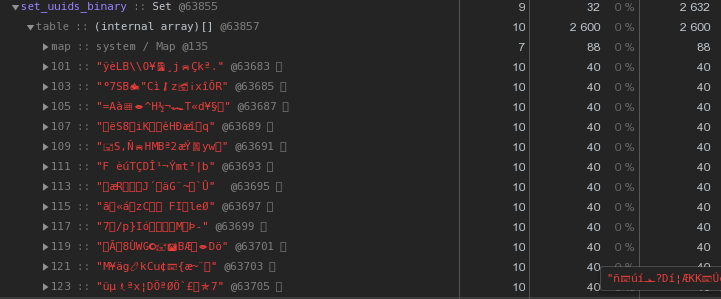 Anstelle von 56 Bytes pro Schlüssel - 40 Bytes, was fast 30% spart !
Anstelle von 56 Bytes pro Schlüssel - 40 Bytes, was fast 30% spart !Meister, Arbeiter - wo Wörterbücher aufbewahren?
In Anbetracht der Tatsache, dass sich die Vokabeldaten der Mitarbeiter sehr stark überschneiden, haben wir die Wörterbücher gespeichert und im Master-Prozess in die Datenbank geschrieben sowie die Daten der Mitarbeiter über den IPC-Nachrichtenmechanismus übertragen .Ein erheblicher Teil der Zeit des Masters wurde jedoch für die channel.onreadVerarbeitung des Empfangs von Paketen mit "Wörterbuch" -Informationen von untergeordneten Prozessen aufgewendet :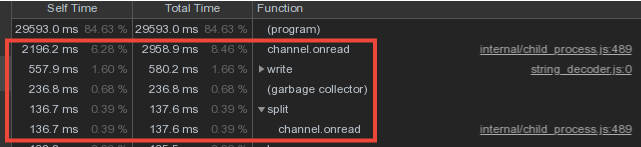
Dual Set Write Barrier
Denken wir jetzt eine Sekunde darüber nach - die Mitarbeiter senden und senden dem Master dieselben Vokabeldaten (im Grunde sind dies die Planvorlagen und die sich wiederholenden Anforderungskörper), er analysiert sie mit seinem Schweiß und ... tut nichts, weil sie bereits zuvor an die Datenbank gesendet wurden !Wenn wir also Setdie Datenbank mit einem Wörterbuch vor einer erneuten Aufzeichnung vom Master „geschützt“ haben, warum nicht den gleichen Ansatz verwenden, um den Master vor der Übertragung durch den Worker zu „schützen“?Tatsächlich wurde dies getan und die direkten Kosten für die dreimalige Wartung des Austauschkanals gesenkt :
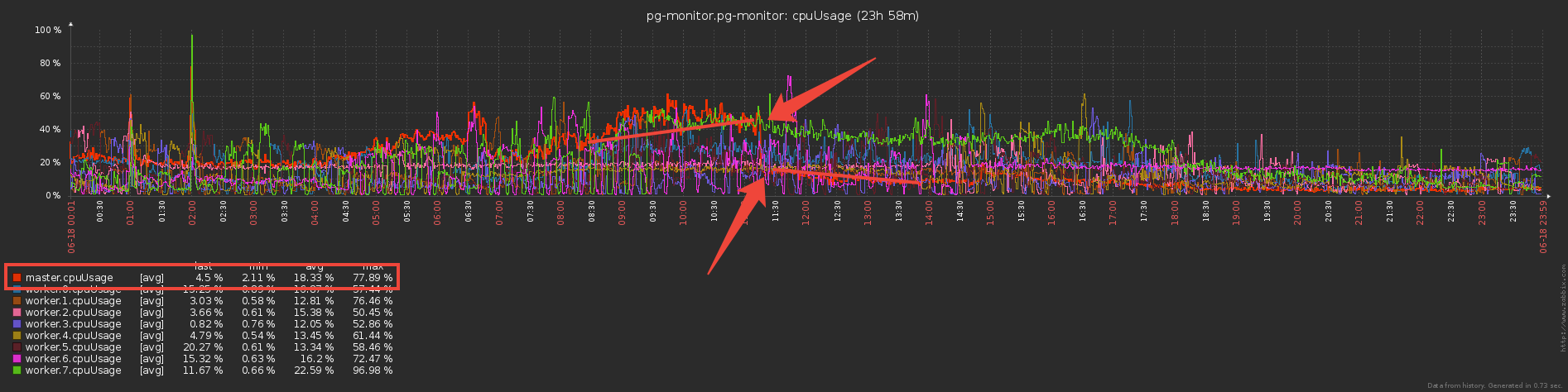 Aber jetzt scheinen die Arbeiter mehr zu arbeiten - Wörterbücher speichern und nach ihnen filtern? Oder nicht? .. Tatsächlich begannen sie deutlich weniger zu arbeiten, da die Übertragung großer Mengen (auch über IPC!) Nicht billig ist.
Aber jetzt scheinen die Arbeiter mehr zu arbeiten - Wörterbücher speichern und nach ihnen filtern? Oder nicht? .. Tatsächlich begannen sie deutlich weniger zu arbeiten, da die Übertragung großer Mengen (auch über IPC!) Nicht billig ist.Schöner Bonus
Als der Assistent nun eine viel geringere Menge an Informationen erhielt, wurde diesen Containern viel weniger Speicher zugewiesen. Dies bedeutet, dass die für die Arbeit des Garbage Collector aufgewendete Zeit erheblich abnahm, was sich positiv auf die Latenz des gesamten Systems auswirkte.Ein solches Schema bietet Schutz vor wiederholten Einträgen auf Kollektorebene. Was ist jedoch, wenn wir mehrere Kollektoren haben? Hier hilft nur der Auslöser mit INSERT ... ON CONFLICT DO NOTHING.Beschleunigen Sie die Hash-Berechnung
In unserer Architektur wird der gesamte Protokolldatenstrom von einem PostgreSQL-Server von einem Worker verarbeitet.Das heißt, ein Server ist eine Aufgabe für den Mitarbeiter. Gleichzeitig wird die Belastung der Worker durch den Zweck der Server-Tasks ausgeglichen, so dass der CPU-Verbrauch der Worker aller Kollektoren ungefähr gleich ist. Dies ist ein separater Service-Dispatcher.„Im Durchschnitt“ erledigt jeder Mitarbeiter Dutzende von Aufgaben, die ungefähr die gleiche Gesamtlast erzeugen. Es gibt jedoch Server, die den Rest der Anzahl der Protokolleinträge deutlich übertreffen. Und selbst wenn der Dispatcher diese Aufgabe als einzige auf dem Worker belässt, ist der Download viel höher als bei den anderen:Wir haben das CPU-Profil dieses Workers entfernt: In den obersten Zeilen die Berechnung von MD5-Hashes. Und sie sind wirklich eine riesige Menge - für den gesamten Strom eingehender Objekte.
In den obersten Zeilen die Berechnung von MD5-Hashes. Und sie sind wirklich eine riesige Menge - für den gesamten Strom eingehender Objekte.xxHash
Wie kann man diesen Teil optimieren, außer diesen Hashes, die wir nicht können?Wir haben uns entschlossen, eine andere Hash-Funktion auszuprobieren - xxHash , die einen extrem schnellen nicht-kryptografischen Hash-Algorithmus implementiert . Das Modul für Node.js ist xxhash-addon , das die neueste Version der Bibliothek xxHash 0.7.3 mit dem neuen XXH3-Algorithmus verwendet.Überprüfen Sie dies, indem Sie jede Option für eine Reihe von Zeilen unterschiedlicher Länge ausführen:const crypto = require('crypto');
const { XXHash3, XXHash64 } = require('xxhash-addon');
const hasher3 = new XXHash3(0xDEADBEAF);
const hasher64 = new XXHash64(0xDEADBEAF);
const buf = Buffer.allocUnsafe(16);
const getBinFromHash = (hash) => buf.fill(hash, 'hex').toString('binary');
const funcs = {
xxhash64 : (str) => hasher64.hash(Buffer.from(str)).toString('binary')
, xxhash3 : (str) => hasher3.hash(Buffer.from(str)).toString('binary')
, md5 : (str) => getBinFromHash(crypto.createHash('md5').update(str).digest('hex'))
};
const check = (hash) => {
let log = [];
let cnt = 10000;
while (cnt--) log.push(crypto.randomBytes(cnt).toString('hex'));
console.time(hash);
log.forEach(funcs[hash]);
console.timeEnd(hash);
};
Object.keys(funcs).forEach(check);
Ergebnisse:xxhash64 : 148.268ms
xxhash3 : 108.337ms
md5 : 317.584ms
Wie erwartet war xxhash3 viel schneller als MD5 !Es bleibt die Beständigkeit gegen Kollisionen zu prüfen. Jeden Tag werden Abschnitte mit Wörterbuchtabellen für uns erstellt, sodass wir außerhalb der Tagesgrenzen die Schnittmenge von Hashes sicher zulassen können.Aber nur für den Fall, wir haben im Abstand von drei Tagen mit einem Spielraum nachgesehen - kein einziger Konflikt , der uns mehr als genug zusagt.Hash-Ersatz
Wir können jedoch einfach keine alten UUID-Felder in den Wörterbuchtabellen gegen einen neuen Hash austauschen, da sowohl die Datenbank als auch das vorhandene Frontend darauf warten, dass Objekte weiterhin von der UUID identifiziert werden.Daher werden wir dem Kollektor einen weiteren Cache hinzufügen - für bereits berechnetes MD5. Jetzt wird es eine Karte sein , in der die Schlüssel xxhash3 sind, die Werte sind MD5. Bei identischen Zeilen wird der „teure“ MD5 nicht erneut nachgezählt, sondern aus dem Cache entnommen:const getHashFromBin = (bin) => Buffer.from(bin, 'binary').toString('hex');
const dictmd5 = new Map();
const getmd5 = (data) => {
const hash = xxhash(data);
let md5hash = dictmd5.get(hash);
if (!md5hash) {
md5hash = md5(data);
dictmd5.set(hash, getBinFromHash(md5hash));
return md5hash;
}
return getHashFromBin(md5hash);
};
Wir entfernen das Profil - der Bruchteil der Zeit für die Berechnung von Hashes hat sich deutlich verringert, Prost! Jetzt zählen wir xxhash3, überprüfen dann den MD5-Cache und erhalten den gewünschten MD5 und überprüfen dann den Wörterbuch-Cache. Wenn dieser md5 nicht vorhanden ist, senden Sie ihn zum Schreiben an die Datenbank.Etwas zu viele Überprüfungen ... Warum den Wörterbuch-Cache überprüfen, wenn Sie den MD5-Cache bereits überprüft haben? Es stellt sich heraus, dass nicht mehr alle Wörterbuch-Caches benötigt werden und es ausreicht, nur einen Cache zu haben - für MD5, mit dem alle grundlegenden Operationen ausgeführt werden:
Jetzt zählen wir xxhash3, überprüfen dann den MD5-Cache und erhalten den gewünschten MD5 und überprüfen dann den Wörterbuch-Cache. Wenn dieser md5 nicht vorhanden ist, senden Sie ihn zum Schreiben an die Datenbank.Etwas zu viele Überprüfungen ... Warum den Wörterbuch-Cache überprüfen, wenn Sie den MD5-Cache bereits überprüft haben? Es stellt sich heraus, dass nicht mehr alle Wörterbuch-Caches benötigt werden und es ausreicht, nur einen Cache zu haben - für MD5, mit dem alle grundlegenden Operationen ausgeführt werden: Infolgedessen haben wir die Prüfung in mehreren "Objekt" -Wörterbüchern durch einen MD5-Cache ersetzt, und die ressourcenintensive Berechnung von MD5 ist erforderlich Hash wird nur für neue Einträge ausgeführt, wobei der wesentlich effizientere xxhash für den eingehenden Stream verwendet wird.DankeKilor für Hilfe bei der Vorbereitung des Artikels.
Infolgedessen haben wir die Prüfung in mehreren "Objekt" -Wörterbüchern durch einen MD5-Cache ersetzt, und die ressourcenintensive Berechnung von MD5 ist erforderlich Hash wird nur für neue Einträge ausgeführt, wobei der wesentlich effizientere xxhash für den eingehenden Stream verwendet wird.DankeKilor für Hilfe bei der Vorbereitung des Artikels.