Hallo liebe Abonnenten! Sie wissen wahrscheinlich bereits, dass wir einen neuen Kurs "Computer Vision" gestartet haben , dessen Unterricht in den kommenden Tagen beginnen wird. Im Vorgriff auf den Beginn des Unterrichts haben wir eine weitere interessante Übersetzung für das Eintauchen in die Welt des Lebenslaufs vorbereitet.
Mein Hobby ist das Spielen von Brettspielen. Da ich mit Faltungs-Neuronalen Netzen ein wenig vertraut bin, habe ich beschlossen, eine Anwendung zu erstellen, die eine Person in einem Kartenspiel schlagen kann. Ich wollte ein Modell von Grund auf mit meinem eigenen Datensatz erstellen und sehen, wie gut es mit einem kleinen Datensatz funktioniert. Ich beschloss, mit dem einfachen Dobble-Spiel (auch bekannt als Spot it!) Zu beginnen.Wenn Sie nicht wissen, was Dobble ist, erinnere ich mich kurz an die Spielregeln: Dobble ist ein einfaches Mustererkennungsspiel, bei dem die Spieler versuchen, ein Bild zu finden, das gleichzeitig auf zwei Karten abgebildet ist. Jede Karte im ursprünglichen Dobble-Spiel enthält acht verschiedene Charaktere und auf verschiedenen Karten sind sie unterschiedlich groß. Zwei beliebige Karten haben nur ein gemeinsames Symbol. Wenn Sie das Symbol zuerst finden, nehmen Sie eine Karte. Wenn das Kartenspiel mit 55 Karten endet, gewinnt das mit den meisten Karten. Probieren Sie es aus: Welches Symbol haben diese beiden Karten gemeinsam?
Probieren Sie es aus: Welches Symbol haben diese beiden Karten gemeinsam?Wo soll ich anfangen?
Der erste Schritt bei der Lösung einer Datenanalyseaufgabe besteht darin, Daten zu sammeln. Ich habe sechs Fotos von jeder Karte am Telefon gemacht. Insgesamt sind 330 Fotos entstanden. Vier davon sehen Sie unten. Sie fragen sich vielleicht, ob dies ausreicht, um ein gutes neuronales Faltungsnetzwerk zu schaffen? Wir werden darauf zurückkommen!
Bildverarbeitung
OK, die Daten, die wir haben, wie geht es weiter? Der wahrscheinlich wichtigste Teil auf dem Weg zum Erfolg: die Bildverarbeitung. Wir müssen Zeichen aus jedem Bild erhalten. Hier erwarten uns einige Schwierigkeiten. Auf den Fotos oben ist zu erkennen, dass einige Zeichen schwieriger zu unterscheiden sind als andere: Der Schneemann und der Geist (auf dem dritten Foto) und die Nadel (auf dem vierten) in hellen Farben sowie die Flecken (auf dem zweiten Foto) und das Ausrufezeichen (auf dem vierten Foto) bestehen aus mehreren Teilen . Um helle Zeichen zu verarbeiten, fügen wir Kontrast hinzu. Danach ändern wir die Größe und speichern das Bild.Kontrast hinzufügen
Um den Kontrast zu erhöhen, verwenden wir den Lab- Farbraum . L ist die Helligkeit, a ist die chromatische Komponente im Bereich von grün bis magenta und b ist die chromatische Komponente im Bereich von blau bis gelb. Wir können diese Komponenten einfach mit OpenCV extrahieren :import cv2
import imutils
imgname = 'picture1'
image = cv2.imread(f’{imgname}.jpg’)
lab = cv2.cvtColor(image, cv2.COLOR_BGR2LAB)
l, a, b = cv2.split(lab)
 Von links nach rechts: das Originalbild, die Helligkeitskomponente, Komponente a und Komponente bNun fügen wir der Helligkeitskomponente einen Kontrast hinzu, kombinieren erneut alle Komponenten miteinander und konvertieren sie in ein normales Bild:
Von links nach rechts: das Originalbild, die Helligkeitskomponente, Komponente a und Komponente bNun fügen wir der Helligkeitskomponente einen Kontrast hinzu, kombinieren erneut alle Komponenten miteinander und konvertieren sie in ein normales Bild:clahe = cv2.createCLAHE(clipLimit=3.0, tileGridSize=(8,8))
cl = clahe.apply(l)
limg = cv2.merge((cl,a,b))
final = cv2.cvtColor(limg, cv2.COLOR_LAB2BGR)
 Von links nach rechts: das Originalbild, die Helligkeitskomponente, das kontrastreiche Bild und das zurück in RGB konvertierte Bild
Von links nach rechts: das Originalbild, die Helligkeitskomponente, das kontrastreiche Bild und das zurück in RGB konvertierte BildGrößenänderung
Ändern Sie nun die Größe und speichern Sie das Bild:resized = cv2.resize(final, (800, 800))
# save the image
cv2.imwrite(f'{imgname}processed.jpg', blurred)
Erledigt!Karten- und Zeichenerkennung
Nachdem das Bild verarbeitet wurde, können wir eine Karte im Bild erkennen. Mit OpenCV suchen wir nach externen Konturen. Anschließend konvertieren wir das Bild in Halbtöne, wählen den Schwellenwert (in unserem Fall 190) aus, um ein Schwarzweißbild zu erstellen, und suchen nach einem Pfad. Der Code:image = cv2.imread(f’{imgname}processed.jpg’)
gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
thresh = cv2.threshold(gray, 190, 255, cv2.THRESH_BINARY)[1]
# find contours
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
output = image.copy()
# draw contours on image
for c in cnts:
cv2.drawContours(output, [c], -1, (255, 0, 0), 3)
 Verarbeitetes Bild, das mithilfe des Schwellenwerts und der Auswahl externer Konturen in Halbtöne umgewandelt wurdeWenn wir die externen Konturen nach Fläche sortieren, finden wir die Kontur mit der größten Fläche - dies ist unsere Karte. Um die Zeichen zu extrahieren, können wir einen weißen Hintergrund erstellen.
Verarbeitetes Bild, das mithilfe des Schwellenwerts und der Auswahl externer Konturen in Halbtöne umgewandelt wurdeWenn wir die externen Konturen nach Fläche sortieren, finden wir die Kontur mit der größten Fläche - dies ist unsere Karte. Um die Zeichen zu extrahieren, können wir einen weißen Hintergrund erstellen.# sort by area, grab the biggest one
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[0]
# create mask with the biggest contour
mask = np.zeros(gray.shape,np.uint8)
mask = cv2.drawContours(mask, [cnts], -1, 255, cv2.FILLED)
# card in foreground
fg_masked = cv2.bitwise_and(image, image, mask=mask)
# white background (use inverted mask)
mask = cv2.bitwise_not(mask)
bk = np.full(image.shape, 255, dtype=np.uint8)
bk_masked = cv2.bitwise_and(bk, bk, mask=mask)
# combine back- and foreground
final = cv2.bitwise_or(fg_masked, bk_masked)
 Maske, Hintergrund, Vordergrundbild, endgültiges BildJetzt ist es Zeit für die Zeichenerkennung! Wir können das resultierende Bild verwenden, um wieder externe Konturen darauf zu erkennen. Diese Konturen sind Symbole. Wenn wir um jedes Symbol ein Quadrat erstellen, können wir diesen Bereich extrahieren. Hier ist der Code etwas länger:
Maske, Hintergrund, Vordergrundbild, endgültiges BildJetzt ist es Zeit für die Zeichenerkennung! Wir können das resultierende Bild verwenden, um wieder externe Konturen darauf zu erkennen. Diese Konturen sind Symbole. Wenn wir um jedes Symbol ein Quadrat erstellen, können wir diesen Bereich extrahieren. Hier ist der Code etwas länger:
gray = cv2.cvtColor(final, cv2.COLOR_RGB2GRAY)
thresh = cv2.threshold(gray, 195, 255, cv2.THRESH_BINARY)[1]
thresh = cv2.bitwise_not(thresh)
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:10]
i = 0
for c in cnts:
if cv2.contourArea(c) > 1000:
mask = np.zeros(gray.shape, np.uint8)
mask = cv2.drawContours(mask, [c], -1, 255, cv2.FILLED)
fg_masked = cv2.bitwise_and(image, image, mask=mask)
mask = cv2.bitwise_not(mask)
bk = np.full(image.shape, 255, dtype=np.uint8)
bk_masked = cv2.bitwise_and(bk, bk, mask=mask)
finalcont = cv2.bitwise_or(fg_masked, bk_masked)
output = finalcont.copy()
x,y,w,h = cv2.boundingRect(c)
if w < h:
x += int((w-h)/2)
w = h
else:
y += int((h-w)/2)
h = w
roi = finalcont[y:y+h, x:x+w]
roi = cv2.resize(roi, (400,400))
cv2.imwrite(f"{imgname}_icon{i}.jpg", roi)
i += 1
 Schwarzweißbild (Schwellenwert), erkannte Umrisse, ein Geistersymbol und ein Herzsymbol (mit Masken extrahierte Zeichen)
Schwarzweißbild (Schwellenwert), erkannte Umrisse, ein Geistersymbol und ein Herzsymbol (mit Masken extrahierte Zeichen)Zeichensortierung
Und jetzt das langweiligste! Sie müssen die Zeichen sortieren. Sie benötigen die Zug-, Test- und Validierungsverzeichnisse mit jeweils 57 Verzeichnissen (wir haben insgesamt 57 verschiedene Zeichen). Die Ordnerstruktur ist wie folgt:symbols
├── test
│ ├── anchor
│ ├── apple
│ │ ...
│ └── zebra
├── train
│ ├── anchor
│ ├── apple
│ │ ...
│ └── zebra
└── validation
├── anchor
├── apple
│ ...
└── zebra
Es wird einige Zeit dauern, bis die extrahierten Zeichen (mehr als 2500 Teile) in den erforderlichen Verzeichnissen gespeichert sind! Ich habe Code zum Erstellen von Unterordnern, eine Testsuite und ein Validierungskit auf GitHub . Vielleicht ist es beim nächsten Mal besser, die Sortierung basierend auf dem Clustering-Algorithmus durchzuführen ...Faltungs-Training für neuronale Netze
Nach dem langweiligen Teil kommt der Spaß wieder! Es ist Zeit, ein Faltungsnetzwerk zu erstellen und zu trainieren. Informationen zu Faltungs-Neuronalen Netzen finden Sie hier .Modellarchitektur
Wir haben die Aufgabe, mehrere Klassen mit einem Etikett zu klassifizieren. Für jedes Zeichen benötigen wir ein Etikett. Aus diesem Grund benötigen wir eine Funktion zum Aktivieren der Ausgabe- Softmax- Schicht mit 57 Knoten und kategorialer Kreuzentropie als Verlustfunktion.Die Architektur des endgültigen Modells ist wie folgt:
from keras import layers
from keras import models
from keras import optimizers
from keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(400, 400, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(256, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(256, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(57, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=optimizers.RMSprop(lr=1e-4), metrics=['acc'])
Datenerweiterung
Um die Leistung zu verbessern, habe ich die Datenerweiterung verwendet. Bei der Datenerweiterung werden das Volumen und die Vielfalt der Eingabedaten erhöht. Dies kann durch Drehen, Verschieben, Skalieren, Zuschneiden und Spiegeln vorhandener Bilder erfolgen. Keras kann Daten leicht erweitern:
train_dir = 'symbols/train'
validation_dir = 'symbols/validation'
test_dir = 'symbols/test'
train_datagen = ImageDataGenerator(rescale=1./255, rotation_range=40, width_shift_range=0.1, height_shift_range=0.1, shear_range=0.1, zoom_range=0.1, horizontal_flip=True, vertical_flip=True)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(train_dir, target_size=(400,400), batch_size=20, class_mode='categorical')
validation_generator = test_datagen.flow_from_directory(validation_dir, target_size=(400,400), batch_size=20, class_mode='categorical')
Wenn Sie interessiert waren, sieht der erweiterte Geist folgendermaßen aus: Das Originalbild des Geistes links, erweiterte Geister in allen anderen Bildern
Das Originalbild des Geistes links, erweiterte Geister in allen anderen BildernModelltraining
Lassen Sie uns das Modell trainieren, speichern, um es für Vorhersagen zu verwenden, und die Ergebnisse überprüfen.history = model.fit_generator(train_generator, steps_per_epoch=100, epochs=100, validation_data=validation_generator, validation_steps=50)
model.save('models/model.h5')
 Perfekte Vorhersagen!
Perfekte Vorhersagen!Ergebnisse
Das Grundmodell, das ich ohne Datenerweiterung, Aussetzer und mit weniger Ebenen trainiert habe. Dieses Modell ergab die folgenden Ergebnisse: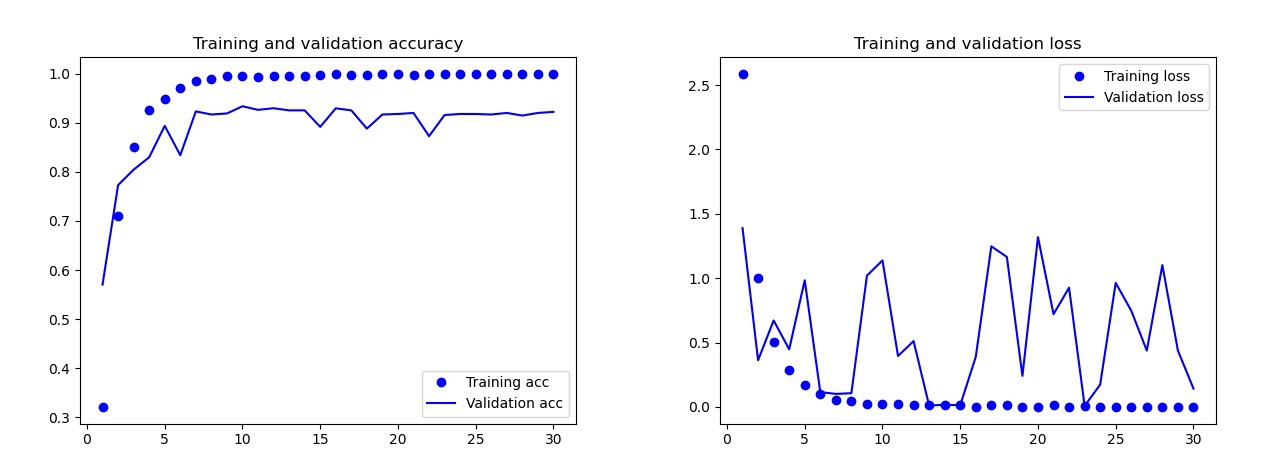 Die Ergebnisse des GrundmodellsMit bloßem Auge ist klar, dass dieses Modell umgeschult wird. Die Ergebnisse der endgültigen Version des Modells (der Code wird in den vorherigen Abschnitten vorgestellt) sind viel besser. In der folgenden Grafik sehen Sie die Genauigkeit und Verluste während des Trainings und im Validierungssatz.
Die Ergebnisse des GrundmodellsMit bloßem Auge ist klar, dass dieses Modell umgeschult wird. Die Ergebnisse der endgültigen Version des Modells (der Code wird in den vorherigen Abschnitten vorgestellt) sind viel besser. In der folgenden Grafik sehen Sie die Genauigkeit und Verluste während des Trainings und im Validierungssatz. Ergebnisse des endgültigen Modells.Auf dem Testset machte dieses Modell nur einen Fehler, es erkannte die Bombe als Tropfen. Ich entschied mich für dieses Modell, die Genauigkeit des Testsatzes betrug 0,995.
Ergebnisse des endgültigen Modells.Auf dem Testset machte dieses Modell nur einen Fehler, es erkannte die Bombe als Tropfen. Ich entschied mich für dieses Modell, die Genauigkeit des Testsatzes betrug 0,995.Erkennung eines gemeinsamen Symbols auf zwei Karten
Jetzt können Sie auf zwei Karten nach gemeinsamen Symbolen suchen. Wir verwenden zwei Fotos, machen Vorhersagen für jedes Bild separat und verwenden den Schnittpunkt von Mengen, um herauszufinden, welches Symbol sich auf beiden Karten befindet. Wir haben 3 Arbeitsmöglichkeiten:- Während der Vorhersage ist etwas schiefgegangen: Es wurden keine gemeinsamen Zeichen gefunden.
- An der Kreuzung befindet sich ein Symbol (Vorhersage kann wahr oder falsch sein).
- Es gibt mehr als ein Zeichen an der Kreuzung. In diesem Fall wähle ich das Symbol mit der höchsten Wahrscheinlichkeit (den Durchschnitt beider Vorhersagen).
Der Code für die ganze Kombination auf den beiden Bildern in den Katalog liegt bei der Vorhersage GitHub ist main.py.Und hier sind die Ergebnisse:
Fazit
Ist das nicht das perfekte Modell? Leider gibt es keine. Als ich neue Fotos von den Karten machte und ihnen die Modelle zur Vorhersage gab, gab es einige Probleme mit dem Schneemann. Manchmal erkannte er das Auge oder Zebra als Schneemann! Infolgedessen waren die Ergebnisse manchmal seltsam: Nun, wo ist der Schneemann hier?Ist dieses Modell besser als der Mensch? Je nachdem, was wir brauchen: Die Leute erkennen perfekt, aber das Modell macht es schneller! Ich bemerkte die Zeit, für die der Computer zurechtkommt: Ich gab ein Kartenspiel mit 55 Karten und musste für jede Kombination von zwei Karten ein gemeinsames Symbol erhalten. Insgesamt sind dies 1485 Kombinationen. Der Computer hat es in weniger als 140 Sekunden geschafft. Er hat ein paar Fehler gemacht, aber er wird definitiv jeden schlagen, wenn es um Geschwindigkeit geht!
Nun, wo ist der Schneemann hier?Ist dieses Modell besser als der Mensch? Je nachdem, was wir brauchen: Die Leute erkennen perfekt, aber das Modell macht es schneller! Ich bemerkte die Zeit, für die der Computer zurechtkommt: Ich gab ein Kartenspiel mit 55 Karten und musste für jede Kombination von zwei Karten ein gemeinsames Symbol erhalten. Insgesamt sind dies 1485 Kombinationen. Der Computer hat es in weniger als 140 Sekunden geschafft. Er hat ein paar Fehler gemacht, aber er wird definitiv jeden schlagen, wenn es um Geschwindigkeit geht! Ich denke nicht, dass es schwierig ist, ein funktionierendes 100% -Modell zu erstellen. Dies kann durch Transfer-Training erreicht werden. Um zu verstehen, was das Modell tut, könnten wir Ebenen für das Testbild visualisieren. Du kannst es das nächste Mal tun!
Ich denke nicht, dass es schwierig ist, ein funktionierendes 100% -Modell zu erstellen. Dies kann durch Transfer-Training erreicht werden. Um zu verstehen, was das Modell tut, könnten wir Ebenen für das Testbild visualisieren. Du kannst es das nächste Mal tun!
Erfahren Sie mehr über den Kurs und bestehen Sie den Eingangstest