 (Bild von hier )
(Bild von hier )
Heute möchten wir Sie über die Aufgabe der Nachbearbeitung der Ergebnisse der Erkennung von Textfeldern auf der Grundlage von A-priori-Kenntnissen des Feldes informieren. Wir haben bereits zuvor über die Methode der Feldkorrektur auf der Basis von Trigrammen geschrieben , mit der Sie einige Erkennungsfehler von Wörtern korrigieren können, die in natürlichen Sprachen geschrieben wurden. Ein wesentlicher Teil wichtiger Dokumente, einschließlich Ausweisdokumente, sind jedoch Felder unterschiedlicher Art - Daten, Nummern, VIN-Codes von Autos, TIN- und SNILS-Nummern, maschinenlesbare Zonenmit ihren Prüfsummen und mehr. Obwohl sie nicht den Feldern einer natürlichen Sprache zugeordnet werden können, weisen solche Felder häufig ein manchmal implizites Sprachmodell auf, was bedeutet, dass einige Korrekturalgorithmen auch auf sie angewendet werden können. In diesem Beitrag werden zwei Mechanismen für die Nachbearbeitung von Erkennungsergebnissen erläutert, die für eine große Anzahl von Dokumenten und Feldtypen verwendet werden können.Das Sprachmodell des Feldes kann bedingt in drei Komponenten unterteilt werden:- Syntax : Regeln für die Struktur einer Textfelddarstellung. Beispiel: Das Feld "Ablaufdatum des Dokuments" in einer maschinenlesbaren Zone wird als siebenstellige "DDDDDDD" dargestellt.
- : , . : “ ” - – , 3- 4- – , 5- 6- – , 7- – .
- : , . : “ ” , , “ ”.
Mit Informationen über die semantische und syntaktische Struktur des Dokuments und das erkannte Feld können Sie einen speziellen Algorithmus für die Nachbearbeitung des Erkennungsergebnisses erstellen. Angesichts der Notwendigkeit, Erkennungssysteme zu unterstützen und zu entwickeln, und der Komplexität ihrer Entwicklung ist es jedoch interessant, „universelle“ Methoden und Werkzeuge in Betracht zu ziehen, mit denen mit minimalem Aufwand (von den Entwicklern) ein ziemlich guter Nachbearbeitungsalgorithmus erstellt werden kann, der mit einer umfangreichen Klasse funktioniert Dokumente und Felder. Die Methodik zum Einrichten und Unterstützen eines solchen Algorithmus wäre einheitlich, und nur das Sprachmodell wäre eine variable Komponente der Algorithmusstruktur.Es ist erwähnenswert, dass die Nachbearbeitung von Ergebnissen der Textfelderkennung nicht immer nützlich und manchmal sogar schädlich ist: Wenn Sie ein ziemlich gutes Zeilenerkennungsmodul haben und in kritischen Systemen mit Identifikationsdokumenten arbeiten, dann eine Art Nachbearbeitung Es ist besser, die Ergebnisse so wie sie sind zu minimieren und zu produzieren oder Änderungen klar zu überwachen und sie dem Kunden zu melden. In vielen Fällen kann jedoch die Verwendung von Nachbearbeitungsalgorithmen die endgültige Erkennungsqualität erheblich verbessern, wenn bekannt ist, dass das Dokument gültig ist und das Sprachmodell des Feldes zuverlässig ist.Der Artikel wird also zwei Nachbearbeitungsmethoden diskutieren, die behaupten, universell zu sein. Die erste basiert auf gewichteten endlichen Konvertern, erfordert eine Beschreibung des Sprachmodells in Form einer endlichen Zustandsmaschine, ist nicht sehr einfach zu bedienen, aber universeller. Die zweite ist einfacher zu verwenden, effizienter, erfordert nur das Schreiben einer Funktion zum Überprüfen der Gültigkeit des Feldwerts, weist jedoch auch eine Reihe von Nachteilen auf.Weighted End Transmitter-Methode
In dieser Arbeit wird ein schönes und ziemlich allgemeines Modell beschrieben, mit dem Sie einen universellen Algorithmus für die Nachbearbeitung von Erkennungsergebnissen erstellen können . Das Modell basiert auf der Datenstruktur von gewichteten Finite-State-Wandlern (WFST).WFSTs sind eine Verallgemeinerung von gewichteten endlichen Zustandsmaschinen - wenn eine gewichtete endliche Zustandsmaschine eine gewichtete Sprache  (d. H. Einen gewichteten Satz von Zeilen über einem bestimmten Alphabet
(d. H. Einen gewichteten Satz von Zeilen über einem bestimmten Alphabet  ) codiert, codiert WFST eine gewichtete Karte einer Sprache
) codiert, codiert WFST eine gewichtete Karte einer Sprache  über dem Alphabet
über dem Alphabet  in eine Sprache
in eine Sprache  über dem Alphabet
über dem Alphabet  . Eine gewichtete endliche Zustandsmaschine, die eine Zeichenfolge
. Eine gewichtete endliche Zustandsmaschine, die eine Zeichenfolge  über das Alphabet nimmt , weist ihr eine gewisse Gewichtung zu
über das Alphabet nimmt , weist ihr eine gewisse Gewichtung zu  , während WFST eine Zeichenfolge nimmt
, während WFST eine Zeichenfolge nimmt ordnet über dem Alphabet eine Reihe von (möglicherweise unendlichen) Paaren zu
ordnet über dem Alphabet eine Reihe von (möglicherweise unendlichen) Paaren zu  , wobei
, wobei  die Linie über dem Alphabet, in die die Linie umgewandelt wird , und
die Linie über dem Alphabet, in die die Linie umgewandelt wird , und  das Gewicht einer solchen Umwandlung ist. Jeder Übergang des Konverters ist durch zwei Zustände (zwischen denen der Übergang erfolgt) gekennzeichnet, die Eingabezeichen (aus dem Alphabet ), die Ausgabezeichen (aus dem Alphabet ) und das Gewicht des Übergangs. Ein leeres Zeichen (leere Zeichenfolge) wird als Element beider Alphabete betrachtet. Das Gewicht der Konvertierung von Zeichenfolge
das Gewicht einer solchen Umwandlung ist. Jeder Übergang des Konverters ist durch zwei Zustände (zwischen denen der Übergang erfolgt) gekennzeichnet, die Eingabezeichen (aus dem Alphabet ), die Ausgabezeichen (aus dem Alphabet ) und das Gewicht des Übergangs. Ein leeres Zeichen (leere Zeichenfolge) wird als Element beider Alphabete betrachtet. Das Gewicht der Konvertierung von Zeichenfolge  zu Zeichenfolge
zu Zeichenfolge  ist die Summe der Produkte der Übergangsgewichte entlang aller Pfade, auf denen die Verkettung der Eingabezeichen die Zeichenfolge bildet , und die Verkettung der Ausgabezeichen die Zeichenfolgeund die den Wandler vom Ausgangszustand in einen der Endzustände übertragen.Die Zusammensetzungsoperation wird über WFST bestimmt, auf dem die Nachbearbeitungsmethode basiert. Lassen Sie zwei Transformatoren gegeben werden ,
ist die Summe der Produkte der Übergangsgewichte entlang aller Pfade, auf denen die Verkettung der Eingabezeichen die Zeichenfolge bildet , und die Verkettung der Ausgabezeichen die Zeichenfolgeund die den Wandler vom Ausgangszustand in einen der Endzustände übertragen.Die Zusammensetzungsoperation wird über WFST bestimmt, auf dem die Nachbearbeitungsmethode basiert. Lassen Sie zwei Transformatoren gegeben werden ,  und
und  , und wandeln die Linie oben
, und wandeln die Linie oben  auf die Linie oben
auf die Linie oben  mit dem Gewicht
mit dem Gewicht  , und konvertiert über die Linie
, und konvertiert über die Linie  oben
oben  mit dem Gewicht
mit dem Gewicht  . Dann konvertiert der Konverter
. Dann konvertiert der Konverter  , der als Zusammensetzung der Konverter bezeichnet wird, die Zeichenfolge in eine Zeichenfolge mit einer Gewichtung
, der als Zusammensetzung der Konverter bezeichnet wird, die Zeichenfolge in eine Zeichenfolge mit einer Gewichtung . Die Zusammensetzung der Wandler ist eine rechenintensive Operation, kann jedoch träge berechnet werden - die Zustände und Übergänge des resultierenden Wandlers können zu dem Zeitpunkt konstruiert werden, zu dem auf sie zugegriffen werden muss.Der Algorithmus zur Nachbearbeitung des Erkennungsergebnisses basierend auf WFST basiert auf drei Hauptinformationsquellen - dem Hypothesenmodell
. Die Zusammensetzung der Wandler ist eine rechenintensive Operation, kann jedoch träge berechnet werden - die Zustände und Übergänge des resultierenden Wandlers können zu dem Zeitpunkt konstruiert werden, zu dem auf sie zugegriffen werden muss.Der Algorithmus zur Nachbearbeitung des Erkennungsergebnisses basierend auf WFST basiert auf drei Hauptinformationsquellen - dem Hypothesenmodell  , dem Fehlermodell
, dem Fehlermodell  und dem Sprachmodell
und dem Sprachmodell  . Alle drei Modelle werden in Form von gewichteten Endwandlern dargestellt:
. Alle drei Modelle werden in Form von gewichteten Endwandlern dargestellt:- ( WFST – , ), , . ,
 , ():
, ():  ,
,  –
–  - ,
- ,  – () .
– () .  - , :
- , :  - ,
- ,  - – ,
- – ,  -
-  -
-  . - , . , .
. - , . , .
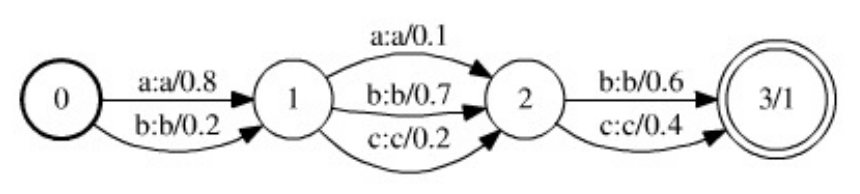
. 1. , WFST ( ). .
- , , . WFST ( ). . , .
- . .. , ( ).
Nach der Definition eines Modells von Hypothesen, Fehlern und eines Sprachmodells kann die Aufgabe der Nachbearbeitung von Erkennungsergebnissen nun wie folgt gestellt werden: Betrachten Sie die Zusammensetzung aller drei Modelle  (in Bezug auf die WFST-Zusammensetzung). Der Konverter
(in Bezug auf die WFST-Zusammensetzung). Der Konverter  codiert alle möglichen Konvertierungen von Zeichenfolgen aus dem Hypothesenmodell in Zeichenfolgen aus dem Sprachmodell und wendet im Fehlermodell codierte Transformationen auf Zeichenfolgen an . Darüber hinaus umfasst das Gewicht einer solchen Transformation das Gewicht der ursprünglichen Hypothese, das Gewicht der Transformation und das Gewicht der resultierenden Zeichenfolge (im Fall eines gewichteten Sprachmodells). Dementsprechend entspricht in einem solchen Modell die optimale Nachbearbeitung des Erkennungsergebnisses dem optimalen (in Bezug auf das Gewicht) Pfad im WandlerÜbersetzen vom Anfangszustand in einen der Endzustände. Die Eingabezeile entlang dieses Pfades entspricht der ausgewählten Anfangshypothese und die Ausgabezeile dem korrigierten Erkennungsergebnis. Der optimale Pfad kann unter Verwendung von Algorithmen zum Finden der kürzesten Pfade in gerichteten Graphen gesucht werden.Die Vorteile dieses Ansatzes sind seine Allgemeingültigkeit und Flexibilität. Das Fehlermodell kann beispielsweise leicht so erweitert werden, dass das Löschen und Hinzufügen von Zeichen berücksichtigt wird (dazu lohnt es sich nur, dem Fehlermodell Übergänge mit einem leeren Ausgabe- bzw. Eingabesymbol hinzuzufügen). Dieses Modell weist jedoch erhebliche Nachteile auf. Zunächst sollte das Sprachmodell hier als endlich gewichteter endlicher Transformator dargestellt werden. Für komplexe Sprachen kann sich ein solcher Automat als ziemlich umständlich herausstellen, und im Falle einer Änderung oder Verfeinerung des Sprachmodells muss es neu erstellt werden. Es sollte auch beachtet werden, dass die Zusammensetzung der drei Wandler infolgedessen in der Regel einen noch sperrigeren Wandler aufweist,Diese Zusammensetzung wird jedes Mal berechnet, wenn Sie mit der Nachbearbeitung eines Erkennungsergebnisses beginnen. Aufgrund der Sperrigkeit der Komposition muss die Suche nach dem optimalen Pfad in der Praxis mit heuristischen Methoden wie der A * -Suche durchgeführt werden.Unter Verwendung des Modells zur Überprüfung von Grammatiken ist es möglich, ein einfacheres Modell der Aufgabe der Nachbearbeitung von Erkennungsergebnissen zu erstellen, das nicht so allgemein wie das auf WFST basierende Modell ist, aber leicht erweiterbar und leicht zu implementieren ist.Eine prüfende Grammatik ist ein Paar
codiert alle möglichen Konvertierungen von Zeichenfolgen aus dem Hypothesenmodell in Zeichenfolgen aus dem Sprachmodell und wendet im Fehlermodell codierte Transformationen auf Zeichenfolgen an . Darüber hinaus umfasst das Gewicht einer solchen Transformation das Gewicht der ursprünglichen Hypothese, das Gewicht der Transformation und das Gewicht der resultierenden Zeichenfolge (im Fall eines gewichteten Sprachmodells). Dementsprechend entspricht in einem solchen Modell die optimale Nachbearbeitung des Erkennungsergebnisses dem optimalen (in Bezug auf das Gewicht) Pfad im WandlerÜbersetzen vom Anfangszustand in einen der Endzustände. Die Eingabezeile entlang dieses Pfades entspricht der ausgewählten Anfangshypothese und die Ausgabezeile dem korrigierten Erkennungsergebnis. Der optimale Pfad kann unter Verwendung von Algorithmen zum Finden der kürzesten Pfade in gerichteten Graphen gesucht werden.Die Vorteile dieses Ansatzes sind seine Allgemeingültigkeit und Flexibilität. Das Fehlermodell kann beispielsweise leicht so erweitert werden, dass das Löschen und Hinzufügen von Zeichen berücksichtigt wird (dazu lohnt es sich nur, dem Fehlermodell Übergänge mit einem leeren Ausgabe- bzw. Eingabesymbol hinzuzufügen). Dieses Modell weist jedoch erhebliche Nachteile auf. Zunächst sollte das Sprachmodell hier als endlich gewichteter endlicher Transformator dargestellt werden. Für komplexe Sprachen kann sich ein solcher Automat als ziemlich umständlich herausstellen, und im Falle einer Änderung oder Verfeinerung des Sprachmodells muss es neu erstellt werden. Es sollte auch beachtet werden, dass die Zusammensetzung der drei Wandler infolgedessen in der Regel einen noch sperrigeren Wandler aufweist,Diese Zusammensetzung wird jedes Mal berechnet, wenn Sie mit der Nachbearbeitung eines Erkennungsergebnisses beginnen. Aufgrund der Sperrigkeit der Komposition muss die Suche nach dem optimalen Pfad in der Praxis mit heuristischen Methoden wie der A * -Suche durchgeführt werden.Unter Verwendung des Modells zur Überprüfung von Grammatiken ist es möglich, ein einfacheres Modell der Aufgabe der Nachbearbeitung von Erkennungsergebnissen zu erstellen, das nicht so allgemein wie das auf WFST basierende Modell ist, aber leicht erweiterbar und leicht zu implementieren ist.Eine prüfende Grammatik ist ein Paar  , wobei das Alphabet
, wobei das Alphabet  das Prädikat für die Zulässigkeit einer Zeichenfolge über dem Alphabet ist , d. H.
das Prädikat für die Zulässigkeit einer Zeichenfolge über dem Alphabet ist , d. H.  . Eine prüfende Grammatik codiert eine bestimmte Sprache über dem Alphabet wie folgt: Eine Zeile
. Eine prüfende Grammatik codiert eine bestimmte Sprache über dem Alphabet wie folgt: Eine Zeile  gehört zur Sprache, wenn das Prädikat in dieser Zeile einen wahren Wert annimmt. Es ist erwähnenswert, dass das Überprüfen der Grammatik eine allgemeinere Art der Darstellung eines Sprachmodells ist als eine Zustandsmaschine. In der Tat jede Sprache, die als endliche Zustandsmaschine dargestellt wirdkann in Form einer Überprüfungsgrammatik dargestellt werden (mit einem Prädikat
gehört zur Sprache, wenn das Prädikat in dieser Zeile einen wahren Wert annimmt. Es ist erwähnenswert, dass das Überprüfen der Grammatik eine allgemeinere Art der Darstellung eines Sprachmodells ist als eine Zustandsmaschine. In der Tat jede Sprache, die als endliche Zustandsmaschine dargestellt wirdkann in Form einer Überprüfungsgrammatik dargestellt werden (mit einem Prädikat  , wobei
, wobei  der Satz von Zeilen vom Automaten akzeptiert wird . Im allgemeinen Fall können jedoch nicht alle Sprachen, die als Überprüfungsgrammatik dargestellt werden können, als endlicher Automat dargestellt werden (z. B. eine Sprache von Wörtern mit unbegrenzter Länge) Alphabet
der Satz von Zeilen vom Automaten akzeptiert wird . Im allgemeinen Fall können jedoch nicht alle Sprachen, die als Überprüfungsgrammatik dargestellt werden können, als endlicher Automat dargestellt werden (z. B. eine Sprache von Wörtern mit unbegrenzter Länge) Alphabet  , in dem die Anzahl der Zeichen
, in dem die Anzahl der Zeichen  größer als die Anzahl der Zeichen ist
größer als die Anzahl der Zeichen ist  .)Das Erkennungsergebnis (Hypothesenmodell) sei als Folge von Zellen angegeben(wie im vorherigen Abschnitt). Der Einfachheit halber nehmen wir an, dass jede Zelle K Alternativen enthält und alle alternativen Schätzungen einen positiven Wert annehmen. Die Bewertung (Gewichtung) der Zeichenfolge wird als Produkt der Bewertungen der einzelnen Zeichen dieser Zeichenfolge betrachtet. Wenn das Sprachmodell in Form einer Überprüfungsgrammatik angegeben ist , kann das Nachbearbeitungsproblem als diskretes Optimierungsproblem (Maximierungsproblem) für den Satz von Steuerelementen
.)Das Erkennungsergebnis (Hypothesenmodell) sei als Folge von Zellen angegeben(wie im vorherigen Abschnitt). Der Einfachheit halber nehmen wir an, dass jede Zelle K Alternativen enthält und alle alternativen Schätzungen einen positiven Wert annehmen. Die Bewertung (Gewichtung) der Zeichenfolge wird als Produkt der Bewertungen der einzelnen Zeichen dieser Zeichenfolge betrachtet. Wenn das Sprachmodell in Form einer Überprüfungsgrammatik angegeben ist , kann das Nachbearbeitungsproblem als diskretes Optimierungsproblem (Maximierungsproblem) für den Satz von Steuerelementen  (den Satz aller Längenzeilen über dem Alphabet ) mit dem Zulässigkeitsprädikat und der Funktion formuliert werden
(den Satz aller Längenzeilen über dem Alphabet ) mit dem Zulässigkeitsprädikat und der Funktion formuliert werden  , wobei
, wobei  sich die Symbolschätzung
sich die Symbolschätzung  in der i-ten Zelle befindet .Jedes diskrete Optimierungsproblem (d. H. Mit einem endlichen Satz von Steuerelementen) kann unter Verwendung einer vollständigen Aufzählung von Steuerelementen gelöst werden. Der beschriebene Algorithmus durchläuft die Steuerelemente (Zeilen) effizient in absteigender Reihenfolge des Funktionswerts, bis das Gültigkeitsprädikat den wahren Wert akzeptiert. Wir setzen die
in der i-ten Zelle befindet .Jedes diskrete Optimierungsproblem (d. H. Mit einem endlichen Satz von Steuerelementen) kann unter Verwendung einer vollständigen Aufzählung von Steuerelementen gelöst werden. Der beschriebene Algorithmus durchläuft die Steuerelemente (Zeilen) effizient in absteigender Reihenfolge des Funktionswerts, bis das Gültigkeitsprädikat den wahren Wert akzeptiert. Wir setzen die  maximale Anzahl von Iterationen des Algorithmus, d.h. Die maximale Anzahl von Zeilen mit der maximalen Schätzung, für die das Prädikat berechnet wird.Zuerst sortieren wir die Alternativen in absteigender Reihenfolge der Schätzungen und nehmen weiter an, dass für jede Zelle die Ungleichung
maximale Anzahl von Iterationen des Algorithmus, d.h. Die maximale Anzahl von Zeilen mit der maximalen Schätzung, für die das Prädikat berechnet wird.Zuerst sortieren wir die Alternativen in absteigender Reihenfolge der Schätzungen und nehmen weiter an, dass für jede Zelle die Ungleichung  für wahr ist
für wahr ist  . Die Position ist die Folge von Indizes
. Die Position ist die Folge von Indizes  , die der Zeile entsprechen
, die der Zeile entsprechen . Positionsbewertung, d.h. Funktionswert in dieser Position, berücksichtigen Sie die Bewertungen der Produktalternativen, die den in Position enthaltenen Indizes entsprechen :
. Positionsbewertung, d.h. Funktionswert in dieser Position, berücksichtigen Sie die Bewertungen der Produktalternativen, die den in Position enthaltenen Indizes entsprechen :  . Zum Speichern von Positionen benötigen Sie die PositionBase- Datenstruktur , mit der Sie neue Positionen hinzufügen (mit deren Adressen), die Position an der Adresse abrufen und prüfen können, ob die angegebene Position zur Datenbank hinzugefügt wurde.Bei der Auflistung von Positionen wählen wir eine nicht angezeigte Position mit einer maximalen Bewertung aus und fügen dann der Position zur Prüfung PositionQueue alle Positionen hinzu, die aus der aktuellen Position erhalten werden können, indem eine zu einem der in der Position enthaltenen Indizes hinzugefügt wird. Die zu berücksichtigende Warteschlange PositionQueue enthält Tripel
. Zum Speichern von Positionen benötigen Sie die PositionBase- Datenstruktur , mit der Sie neue Positionen hinzufügen (mit deren Adressen), die Position an der Adresse abrufen und prüfen können, ob die angegebene Position zur Datenbank hinzugefügt wurde.Bei der Auflistung von Positionen wählen wir eine nicht angezeigte Position mit einer maximalen Bewertung aus und fügen dann der Position zur Prüfung PositionQueue alle Positionen hinzu, die aus der aktuellen Position erhalten werden können, indem eine zu einem der in der Position enthaltenen Indizes hinzugefügt wird. Die zu berücksichtigende Warteschlange PositionQueue enthält Tripel  , wobei
, wobei - Bewertung der nicht
- Bewertung der nicht  überprüften Position, - Adresse der Position, die in PositionBase angezeigt wurde, von der diese Position erhalten wurde,
überprüften Position, - Adresse der Position, die in PositionBase angezeigt wurde, von der diese Position erhalten wurde,  - Index des Positionselements mit der Adresse , die um eins erhöht wurde, um diese Position zu erhalten. Für die Positionierung einer PositionQueue- Warteschlange ist eine Datenstruktur erforderlich, mit der Sie ein weiteres Tripel hinzufügen und ein Tripel mit maximaler Bewertung abrufen können .Bei der ersten Iteration des Algorithmus muss die Position
- Index des Positionselements mit der Adresse , die um eins erhöht wurde, um diese Position zu erhalten. Für die Positionierung einer PositionQueue- Warteschlange ist eine Datenstruktur erforderlich, mit der Sie ein weiteres Tripel hinzufügen und ein Tripel mit maximaler Bewertung abrufen können .Bei der ersten Iteration des Algorithmus muss die Position  mit der maximalen Schätzung berücksichtigt werden. Wenn das Prädikat den wahren Wert in der dieser Position entsprechenden Zeile annimmt, endet der Algorithmus. Andernfalls wird die Position zu PositionBase und in hinzugefügtPositionQueue fügt alle Tripel der Ansicht
mit der maximalen Schätzung berücksichtigt werden. Wenn das Prädikat den wahren Wert in der dieser Position entsprechenden Zeile annimmt, endet der Algorithmus. Andernfalls wird die Position zu PositionBase und in hinzugefügtPositionQueue fügt alle Tripel der Ansicht  für alle hinzu
für alle hinzu  , wobei
, wobei  die Adresse der Startposition in PositionBase angegeben ist . Bei jeder nachfolgenden Iteration des Algorithmus wird das Tripel mit dem Maximalwert der Schätzung aus der PositionQueue extrahiert , und die betreffende Position wird an der Adresse der Anfangsposition und des Index wiederhergestellt . Wenn die Position bereits zur Datenbank der berücksichtigten PositionBase- Positionen hinzugefügt wurde , wird sie übersprungen und die nächsten drei mit dem Maximalwert der Schätzung werden aus der PositionQueue extrahiert . Andernfalls wird der Prädikatwert in der der Position entsprechenden Zeile überprüft . Wenn das PrädikatNimmt der wahre Wert in dieser Zeile, dann endet der Algorithmus. Wenn das Prädikat den wahren Wert in dieser Zeile nicht akzeptiert, wird die Zeile zur PositionBase hinzugefügt (mit der zugewiesenen Adresse
die Adresse der Startposition in PositionBase angegeben ist . Bei jeder nachfolgenden Iteration des Algorithmus wird das Tripel mit dem Maximalwert der Schätzung aus der PositionQueue extrahiert , und die betreffende Position wird an der Adresse der Anfangsposition und des Index wiederhergestellt . Wenn die Position bereits zur Datenbank der berücksichtigten PositionBase- Positionen hinzugefügt wurde , wird sie übersprungen und die nächsten drei mit dem Maximalwert der Schätzung werden aus der PositionQueue extrahiert . Andernfalls wird der Prädikatwert in der der Position entsprechenden Zeile überprüft . Wenn das PrädikatNimmt der wahre Wert in dieser Zeile, dann endet der Algorithmus. Wenn das Prädikat den wahren Wert in dieser Zeile nicht akzeptiert, wird die Zeile zur PositionBase hinzugefügt (mit der zugewiesenen Adresse  ), alle abgeleiteten Positionen werden zur PositionQueue- Warteschlange hinzugefügt und die nächste Iteration wird fortgesetzt.
), alle abgeleiteten Positionen werden zur PositionQueue- Warteschlange hinzugefügt und die nächste Iteration wird fortgesetzt.FindSuitableString(M, N, K, P, C[1], ..., C[N]):
i : 1 ... N:
C[i]
( )
PositionBase PositionQueue
S_1 = {1, 1, 1, ..., 1}
P(S_1):
: S_1,
( )
S_1 PositionBase R(S_1)
i : 1 ... N:
K > 1, :
<Q * q[i][2] / q[i][1], R(S_1), i> PositionQueue
( )
( )
PositionBase M:
PositionQueue:
PositionQueue <Q, R, I> Q
S_from = PositionBase R
S_curr = {S_from[1], S_from[2], ..., S_from[I] + 1, ..., S_from[N]}
S_curr PositionBase:
:
S_curr PositionBase R(S_curr)
( )
P(S_curr):
: S_curr,
( )
i : 1 ... N:
K > S_curr[i]:
<Q * q[i][S_curr[i] + 1] / q[i][S_curr[i]],
R(S_curr),
i> PositionQueue
( )
( )
( )
( )
M
Beachten Sie, dass während der Iterationen das Prädikat nicht mehr als einmal überprüft wird , die PositionBase nicht mehr ergänzt wird und die PositionQueue hinzugefügt wird , dass die Extraktion aus der PositionQueue sowie eine Suche in der PositionBase nicht mehr als  einmal durchgeführt werden. Wenn die Implementierung PositionQueue "Bündel" von Datenstrukturen verwendet und für die Organisation PositionBase die Datenstruktur "Bor" verwendet, ist die Komplexität des Algorithmus
einmal durchgeführt werden. Wenn die Implementierung PositionQueue "Bündel" von Datenstrukturen verwendet und für die Organisation PositionBase die Datenstruktur "Bor" verwendet, ist die Komplexität des Algorithmus  , wobei
, wobei  - trudoemost Test Prädikat auf der Länge der Linie .Der vielleicht wichtigste Nachteil des Algorithmus, der auf der Überprüfung von Grammatiken basiert, besteht darin, dass er keine Hypothesen unterschiedlicher Länge verarbeiten kann (die aufgrund von Segmentierungsfehlern entstehen können : Verlust oder Auftreten zusätzlicher Zeichen, Kleben und Schneiden von Zeichen usw.) Änderungen in Hypothesen wie "Löschen eines Zeichens", "Hinzufügen eines Zeichens" oder sogar "Ersetzen eines Zeichens durch ein Paar" können im Fehlermodell des WFST-basierten Algorithmus codiert werden.Die Geschwindigkeit und Benutzerfreundlichkeit (wenn Sie mit einem neuen Feldtyp arbeiten, müssen Sie dem Algorithmus lediglich Zugriff auf die Wertvalidierungsfunktion gewähren) machen die auf Grammatikprüfungen basierende Methode jedoch zu einem sehr leistungsfähigen Werkzeug im Arsenal des Entwicklers von Dokumentenerkennungssystemen. Wir verwenden diesen Ansatz für eine große Anzahl verschiedener Felder, z. B. verschiedene Daten, Bankkartennummer (Prädikat - Überprüfung des Mondcodes ), Felder maschinenlesbarer Dokumentbereiche mit Prüfsummen und viele andere.
- trudoemost Test Prädikat auf der Länge der Linie .Der vielleicht wichtigste Nachteil des Algorithmus, der auf der Überprüfung von Grammatiken basiert, besteht darin, dass er keine Hypothesen unterschiedlicher Länge verarbeiten kann (die aufgrund von Segmentierungsfehlern entstehen können : Verlust oder Auftreten zusätzlicher Zeichen, Kleben und Schneiden von Zeichen usw.) Änderungen in Hypothesen wie "Löschen eines Zeichens", "Hinzufügen eines Zeichens" oder sogar "Ersetzen eines Zeichens durch ein Paar" können im Fehlermodell des WFST-basierten Algorithmus codiert werden.Die Geschwindigkeit und Benutzerfreundlichkeit (wenn Sie mit einem neuen Feldtyp arbeiten, müssen Sie dem Algorithmus lediglich Zugriff auf die Wertvalidierungsfunktion gewähren) machen die auf Grammatikprüfungen basierende Methode jedoch zu einem sehr leistungsfähigen Werkzeug im Arsenal des Entwicklers von Dokumentenerkennungssystemen. Wir verwenden diesen Ansatz für eine große Anzahl verschiedener Felder, z. B. verschiedene Daten, Bankkartennummer (Prädikat - Überprüfung des Mondcodes ), Felder maschinenlesbarer Dokumentbereiche mit Prüfsummen und viele andere.
Die Veröffentlichung wurde auf der Grundlage des Artikels erstellt : Ein universeller Algorithmus zur Nachbearbeitung von Erkennungsergebnissen basierend auf der Validierung von Grammatiken. K.B. Bulatov, D.P. Nikolaev, V.V. Postnikov. Proceedings of ISA RAS, Band 65, Nr. 4, 2015, S. 68-73.