Hintergrund
Vor kurzem musste ich im Rahmen von Bildungsaktivitäten den guten alten genetischen Algorithmus verwenden, um die minimalen und maximalen Funktionen zweier Variablen zu finden. Zu meiner Überraschung gab es jedoch keine ähnliche Implementierung für Python im Internet, und dieser Abschnitt wurde im Artikel über den genetischen Algorithmus auf Wikipedia nicht behandelt. Deshalb habe ich beschlossen, mein kleines Paket in Python mit einer Visualisierung des Algorithmus zu schreiben, nach der es bequem sein wird, diesen Algorithmus zu konfigurieren und nach den Feinheiten des ausgewählten Modells zu suchen.In diesem kurzen Artikel möchte ich den Prozess, die Beobachtungen und die Ergebnisse mitteilen.
Deshalb habe ich beschlossen, mein kleines Paket in Python mit einer Visualisierung des Algorithmus zu schreiben, nach der es bequem sein wird, diesen Algorithmus zu konfigurieren und nach den Feinheiten des ausgewählten Modells zu suchen.In diesem kurzen Artikel möchte ich den Prozess, die Beobachtungen und die Ergebnisse mitteilen.Das Prinzip des Algorithmus
Ich werde nicht über das globale Prinzip der Arbeit genetischer Algorithmen sprechen, aber wenn Sie noch nichts davon gehört haben, können Sie sich auf Wikipedia damit vertraut machen .Derzeit implementiert das Paket nur eine GA, die durch die Eingabedaten über eine einfache Guiche parametrisiert wird. Ich werde Ihnen kurz die ausgewählten genetischen Funktionen und grundlegenden algorithmischen Lösungen erläutern.Das monochromosomale Individuum trägt in jeder seiner Geninformationen Informationen über die entsprechende x- oder y-Koordinate. Eine Population wird von vielen Personen bestimmt, aber die Population ist in 4 Personen unterteilt. Diese Lösung beruht natürlich auf dem Versuch, eine Konvergenz zu einem lokalen Optimum zu vermeiden, da die Aufgabe darin besteht, ein globales Extremum zu finden. Eine solche Aufteilung erlaubt, wie die Praxis gezeigt hat, in vielen Fällen nicht, dass ein Genotyp in der gesamten Population dominiert, sondern verleiht der „Evolution“ im Gegenteil eine größere Dynamik. Für jeden solchen Teil der Bevölkerung wird der folgende Algorithmus angewendet:- Die Auswahl erfolgt ähnlich wie bei der Rangfolge. 3 Personen werden mit den besten Fitnessfunktionsindikatoren ausgewählt (d. H. Personen werden in aufsteigender / absteigender Reihenfolge der vom Benutzer festgelegten Funktion sortiert, die als Anpassungsfunktion fungiert).
- Als nächstes wird die Kreuzungsfunktion so angewendet, dass eine neue Generation (oder vielmehr ein neues Segment einer Population von 4 Individuen) 2 Paare nicht gedämpfter Gene von einem Individuum mit einem besseren Hinweis auf die Fitnessfunktion und ein Paar mutierter Gene von zwei anderen Individuen erhält. Weitere Informationen zur Zusammenstellung der Mutationsfunktion finden Sie im nächsten Abschnitt.
Das Funktionsprinzip von Selektion, Kreuzung und Mutation sieht eindeutig so aus (in Generation N sind die Chromosomen von Individuen bereits in der richtigen Reihenfolge sortiert, und ein kleines schwarzes Quadrat bedeutet Mutation):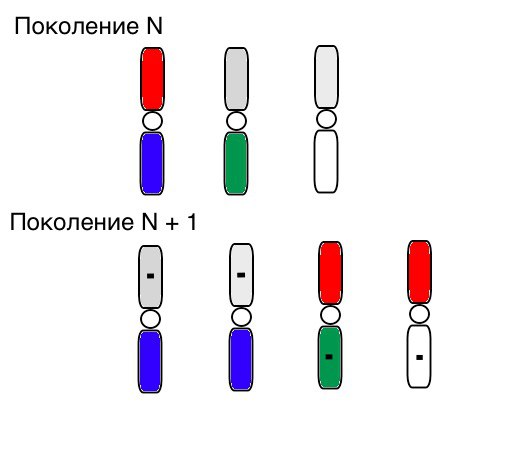
Primärtests und Beobachtungen
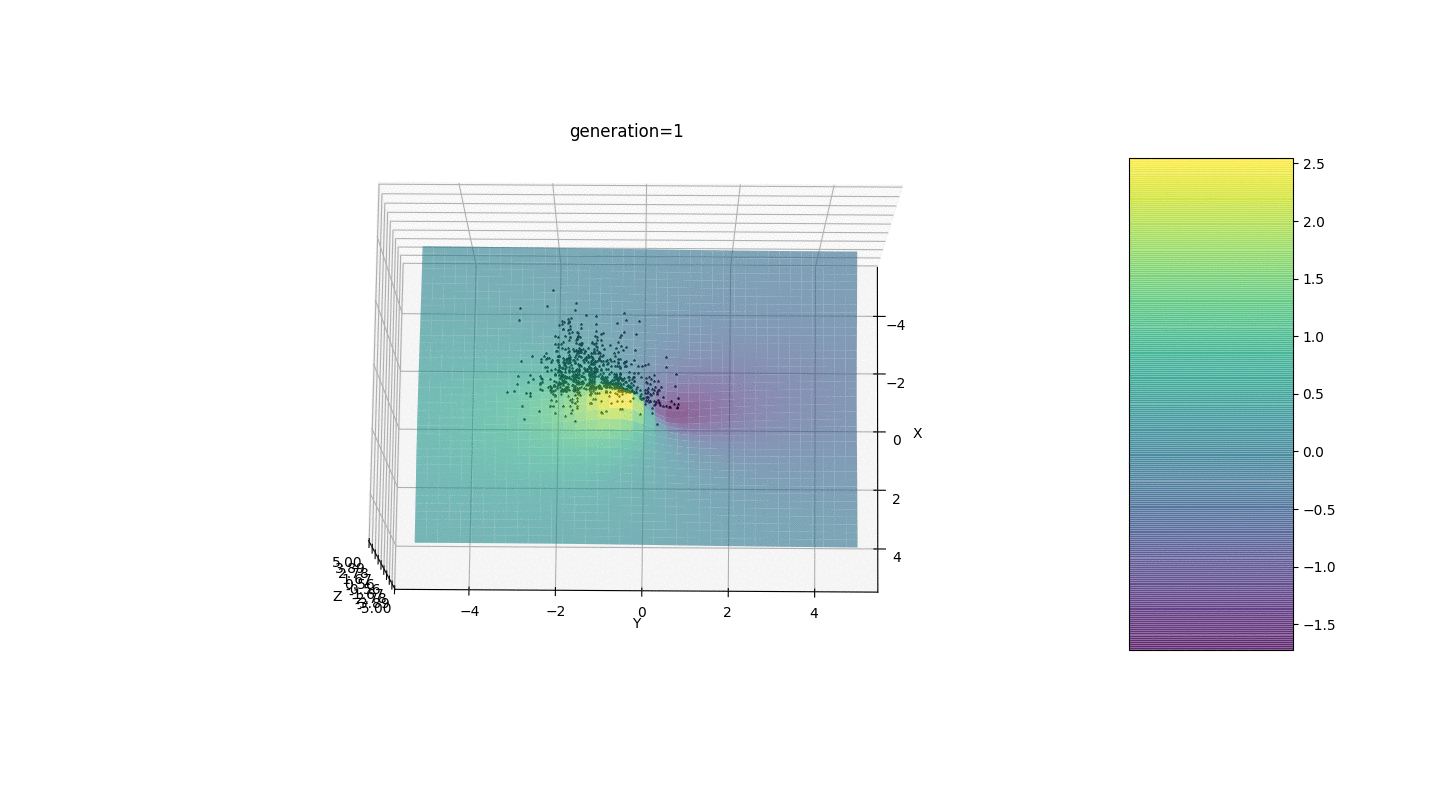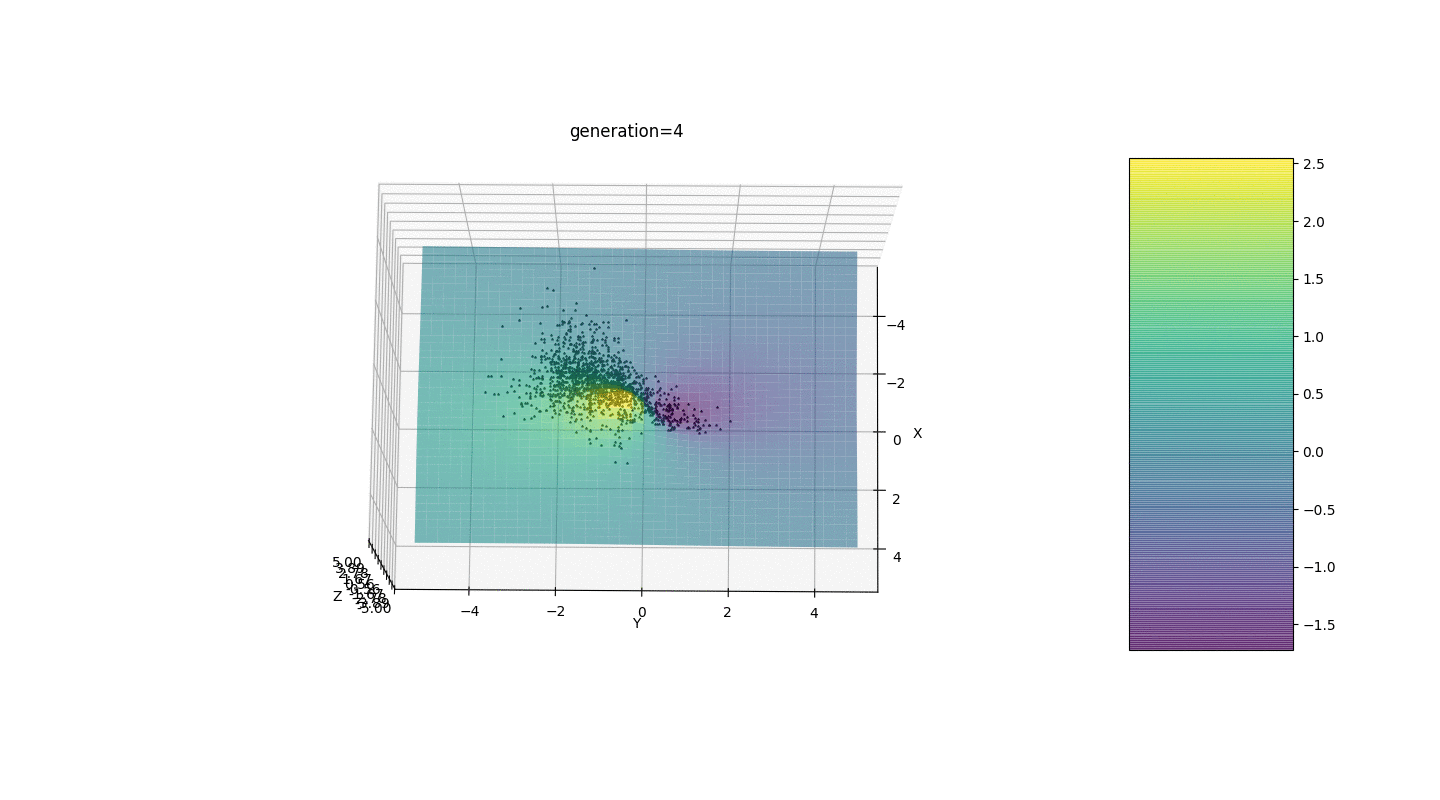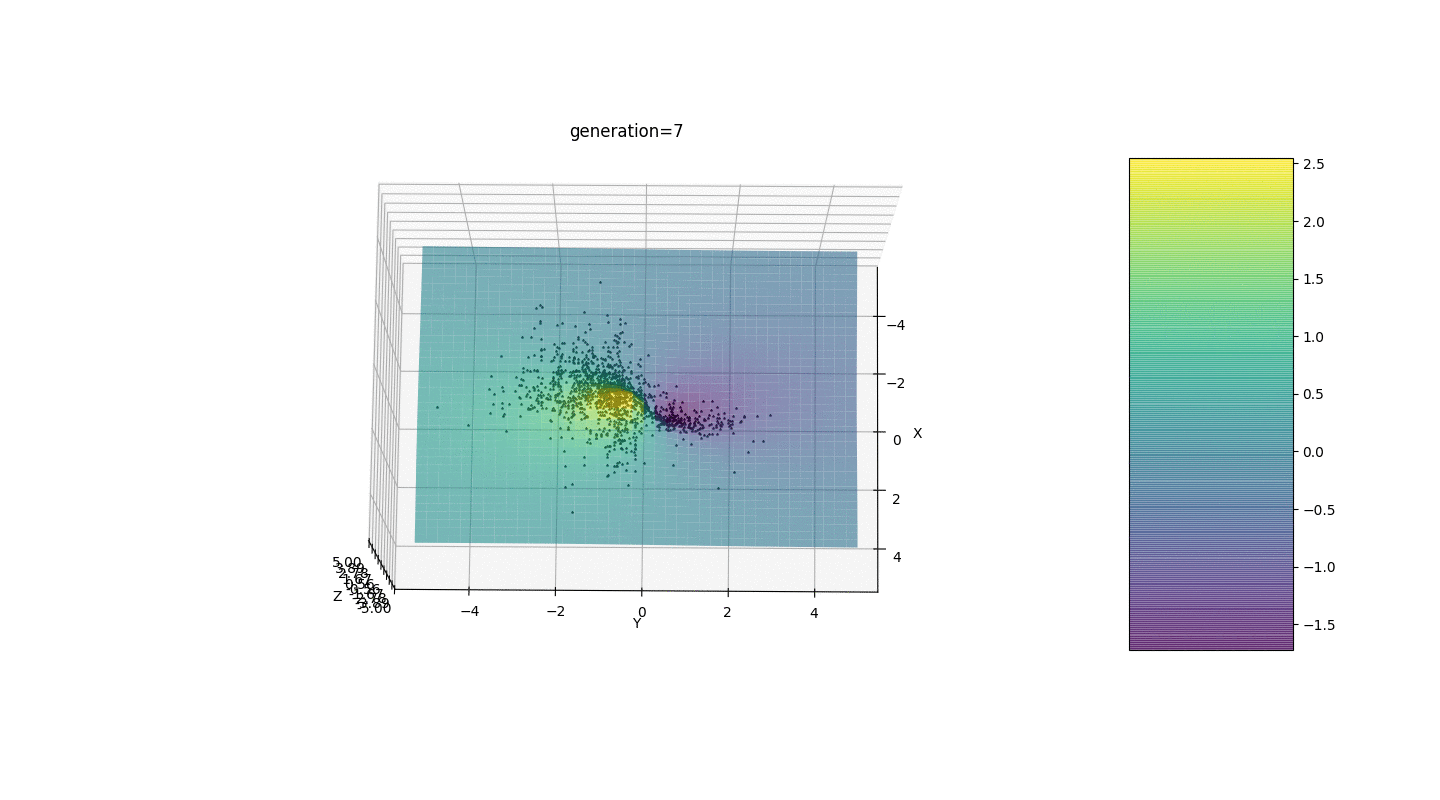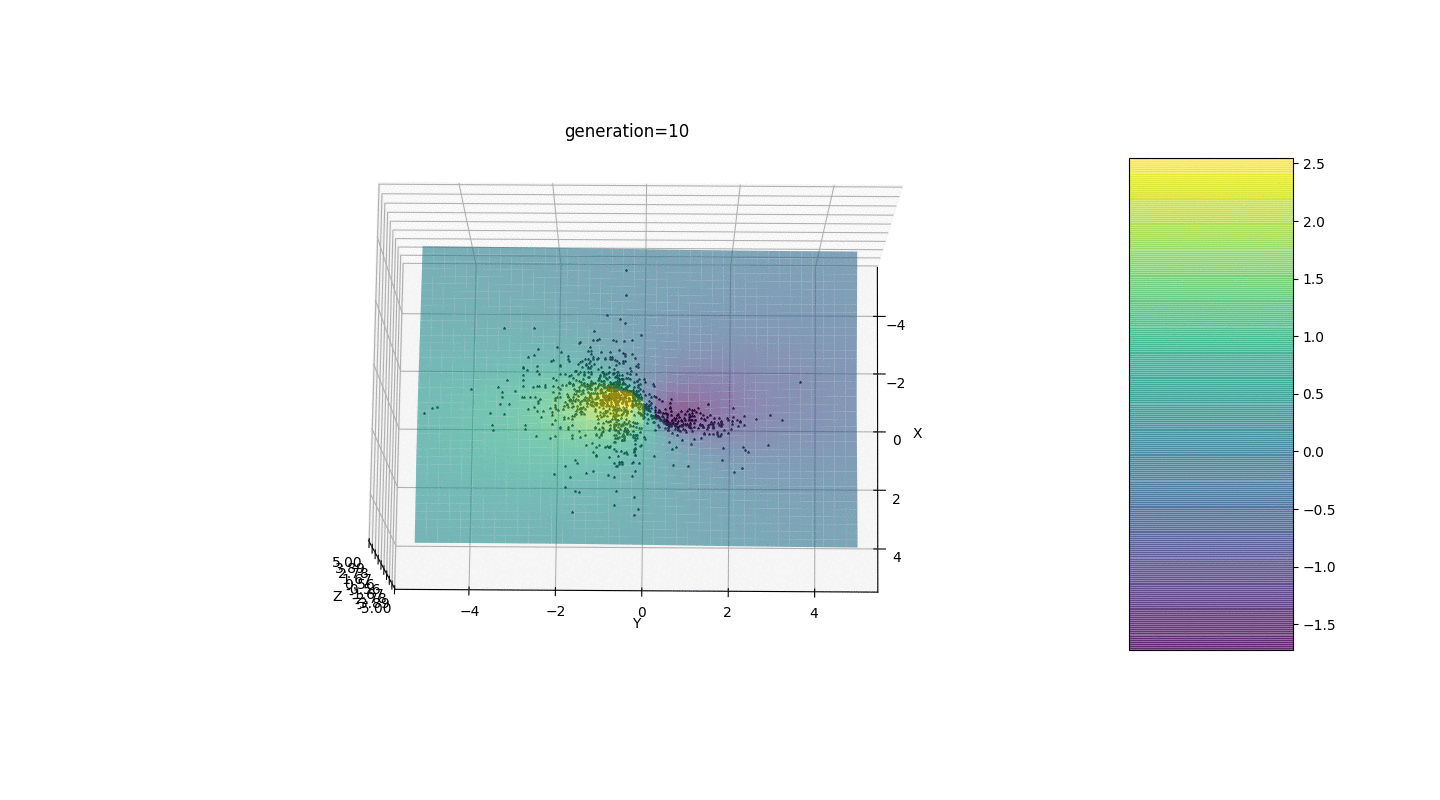
Wir testen diesen Algorithmus also an zwei einfachen Beispielen:Test 1
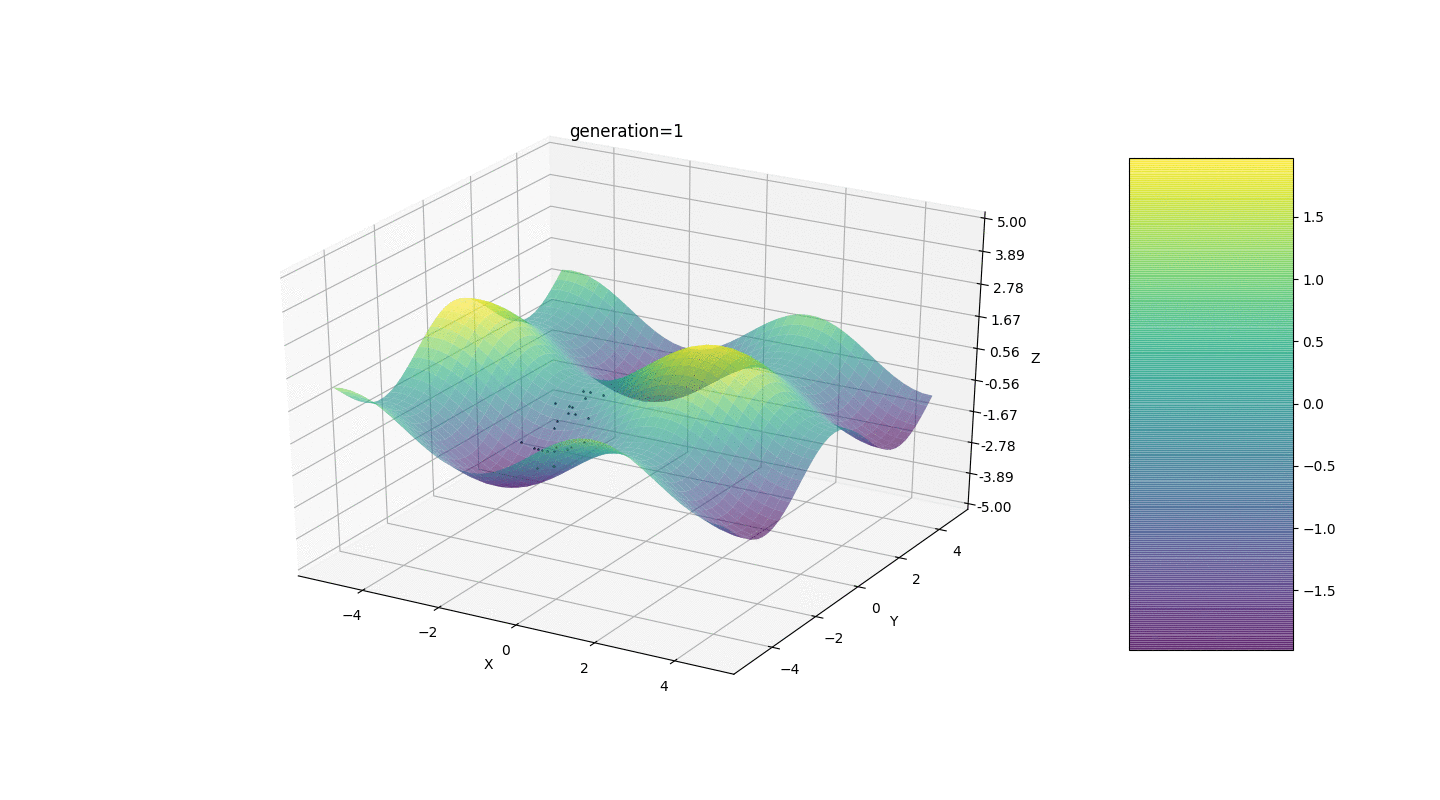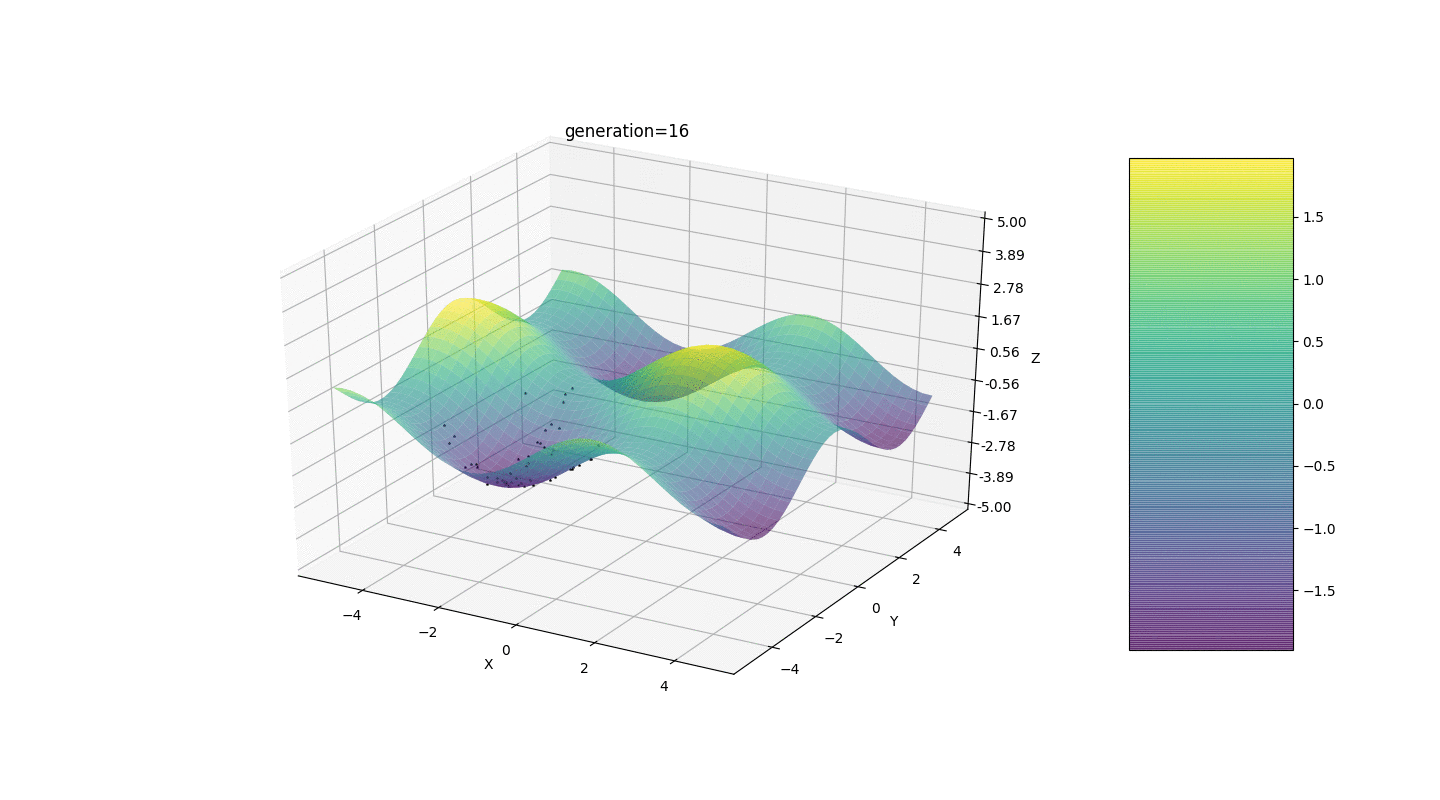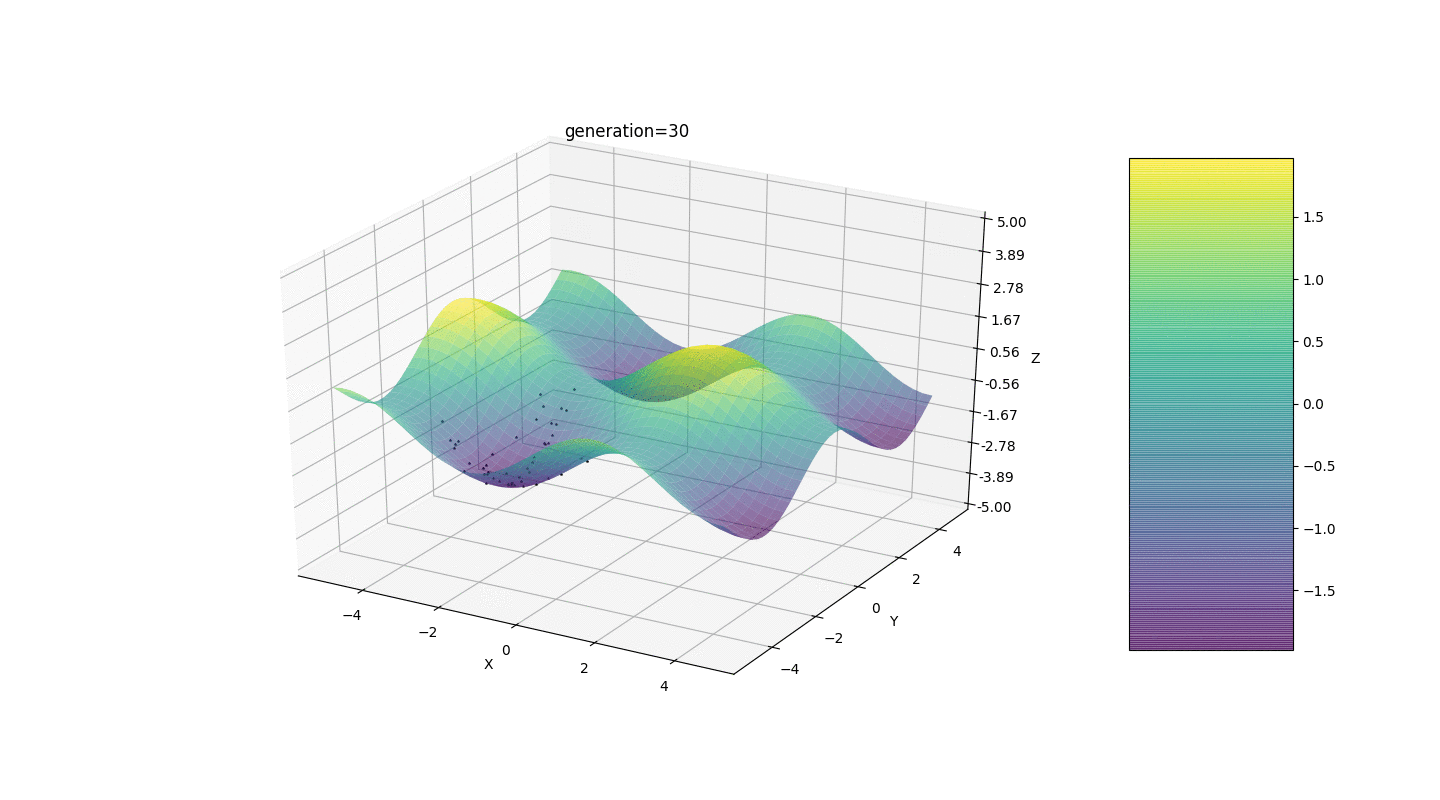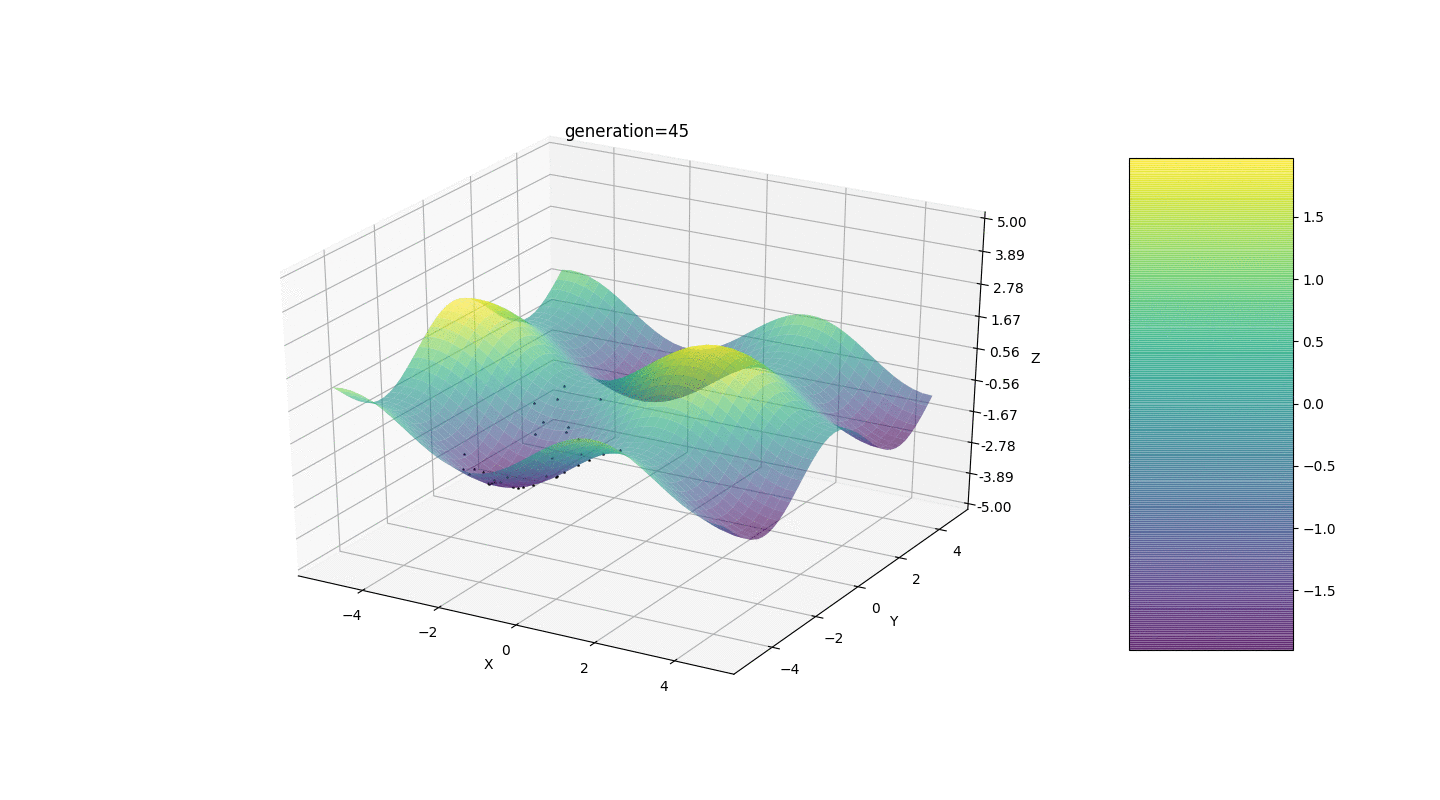
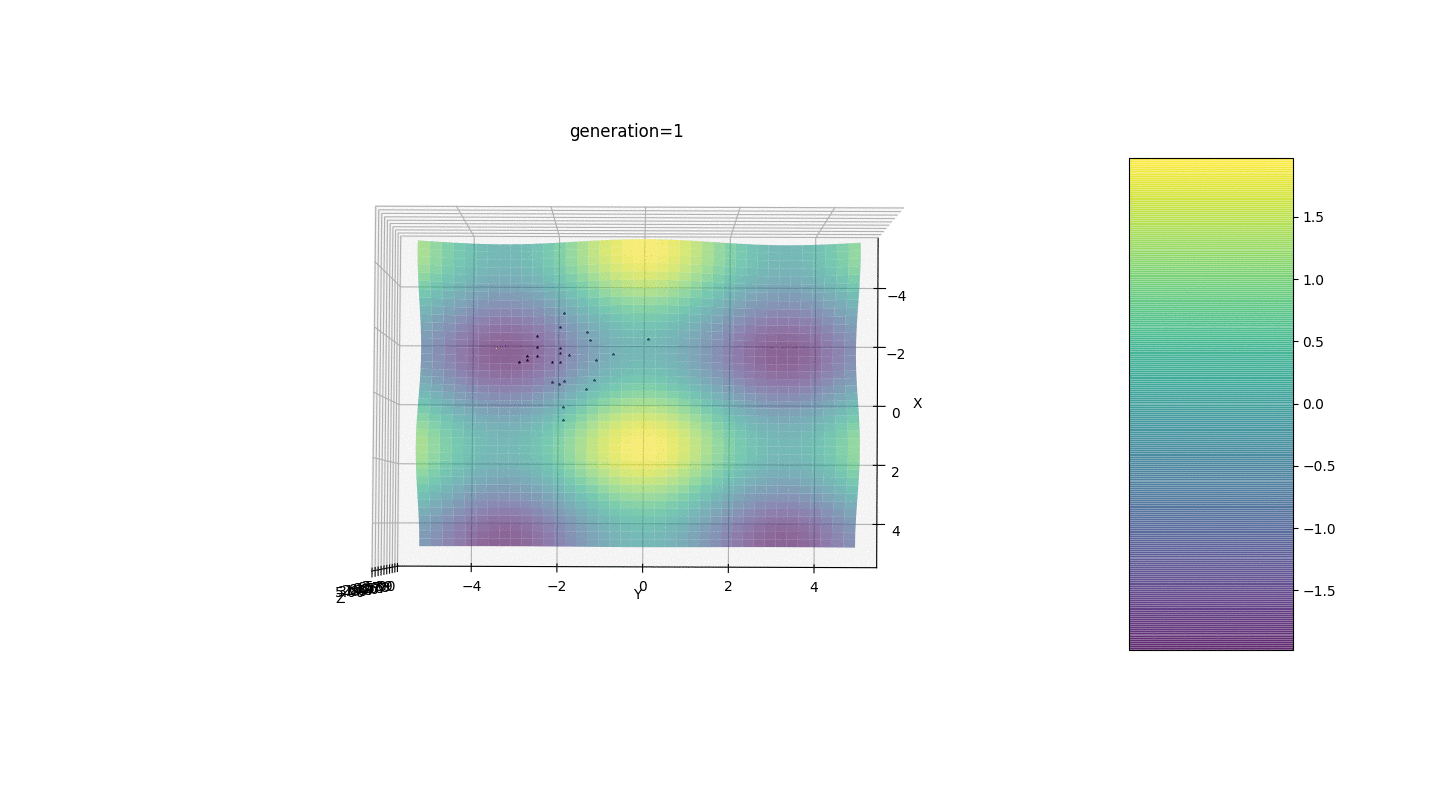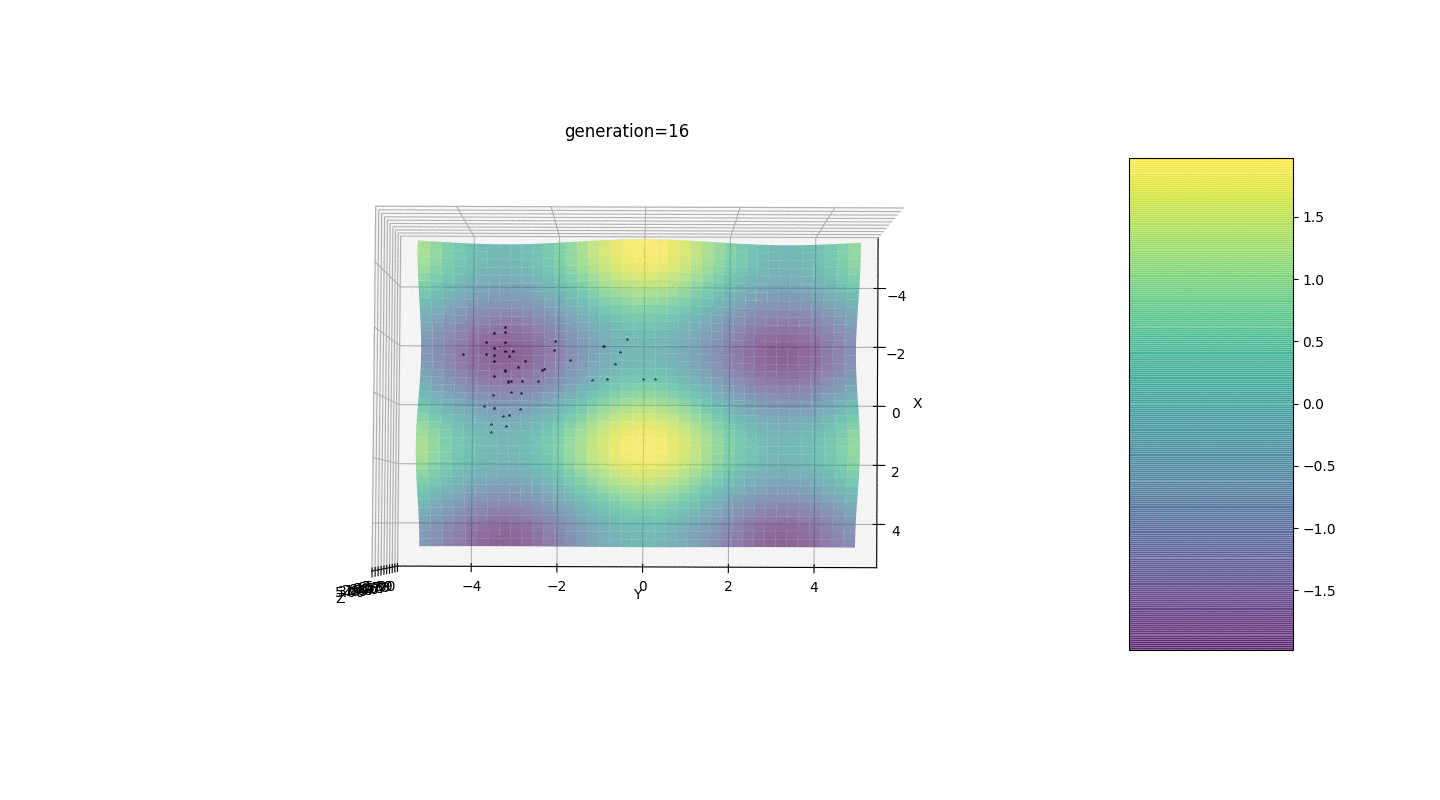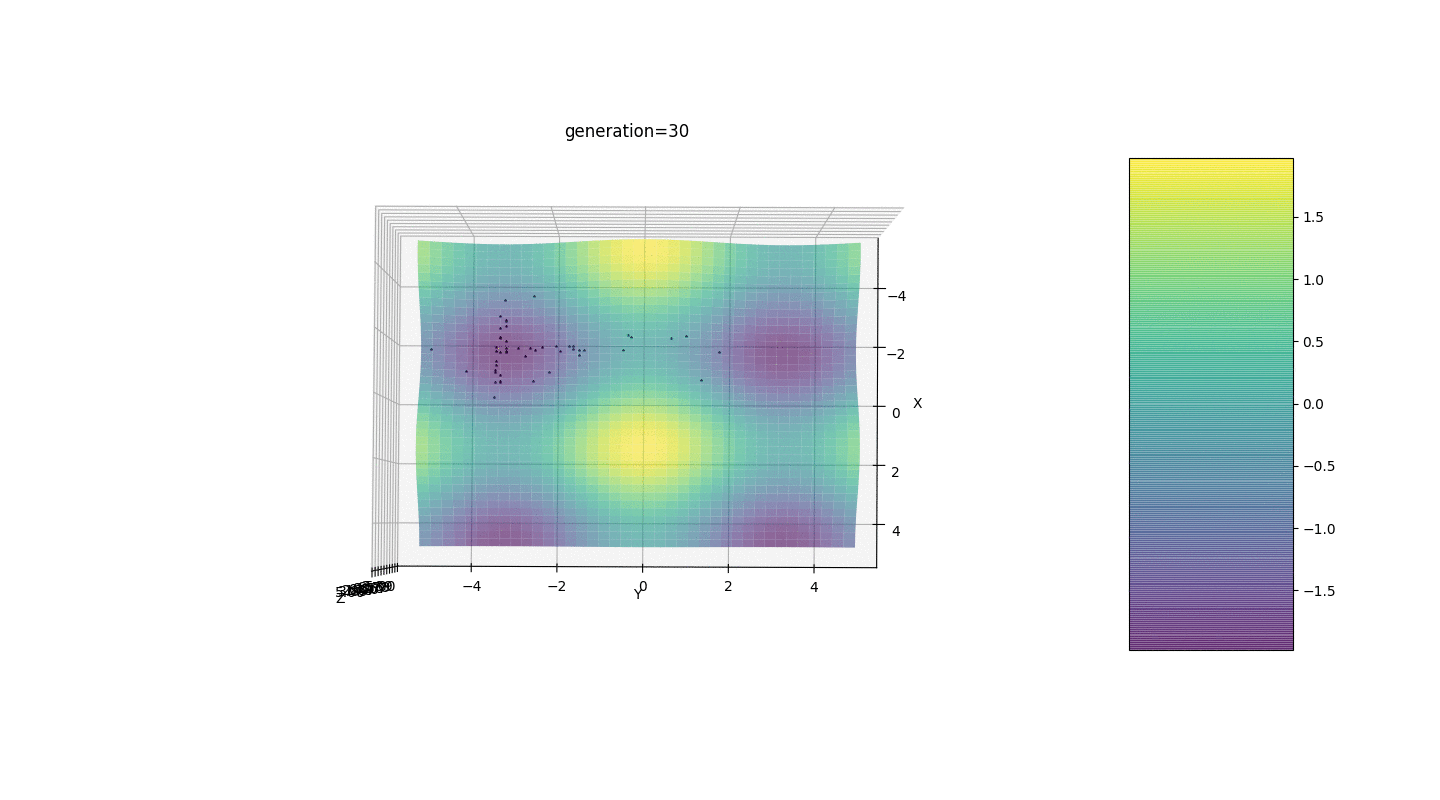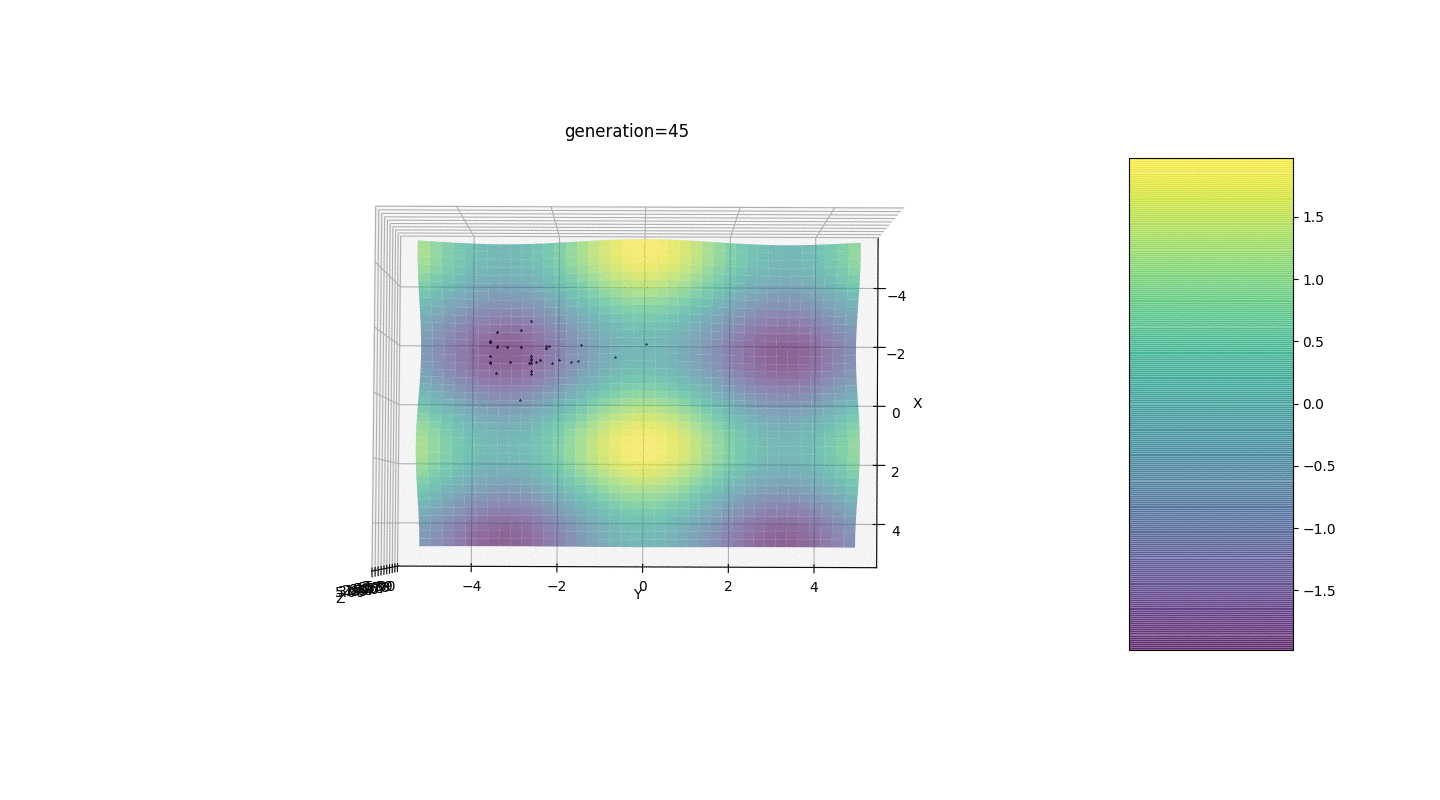
 Test 2
Test 2

 Nach dem Testen und Studieren der Funktionsweise des Algorithmus mit der Methode des Blicks und des zufälligen Stocherns wurden mehrere Hypothesenmuster aufgedeckt:
Nach dem Testen und Studieren der Funktionsweise des Algorithmus mit der Methode des Blicks und des zufälligen Stocherns wurden mehrere Hypothesenmuster aufgedeckt:- Der Fehler des Algorithmus ist direkt proportional zur Anzahl der Personen, aber im Durchschnitt wird der Fehler mit Hundertstel berechnet, obwohl der Fehler bei erfolglosen Parametern Zehntel erreichen kann
- Im Moment tritt eine Mutation auf, indem dem Gen eine Zufallszahl aus dem Halbintervall hinzugefügt wirdaufgrund dessen Individuen nicht in der Nähe des Extremums bleiben können und eine relativ starke Schwankung in der Entfernung zwischen Individuen verschiedener Generationen auftritt. In einigen Fällen können solche Schwingungen nützlich sein, um ein lokales Extremum, beispielsweise eine periodische Funktion, zu verlassen, aber die Extrema können einen großen Abstand voneinander haben (Abstand im euklidischen Sinne).
- In vielen Fällen wird der Extrempunkt von Individuen in 5-15 Generationen erreicht, und die verbleibenden Generationen "springen" nutzlos in die Nähe dieses Extremums
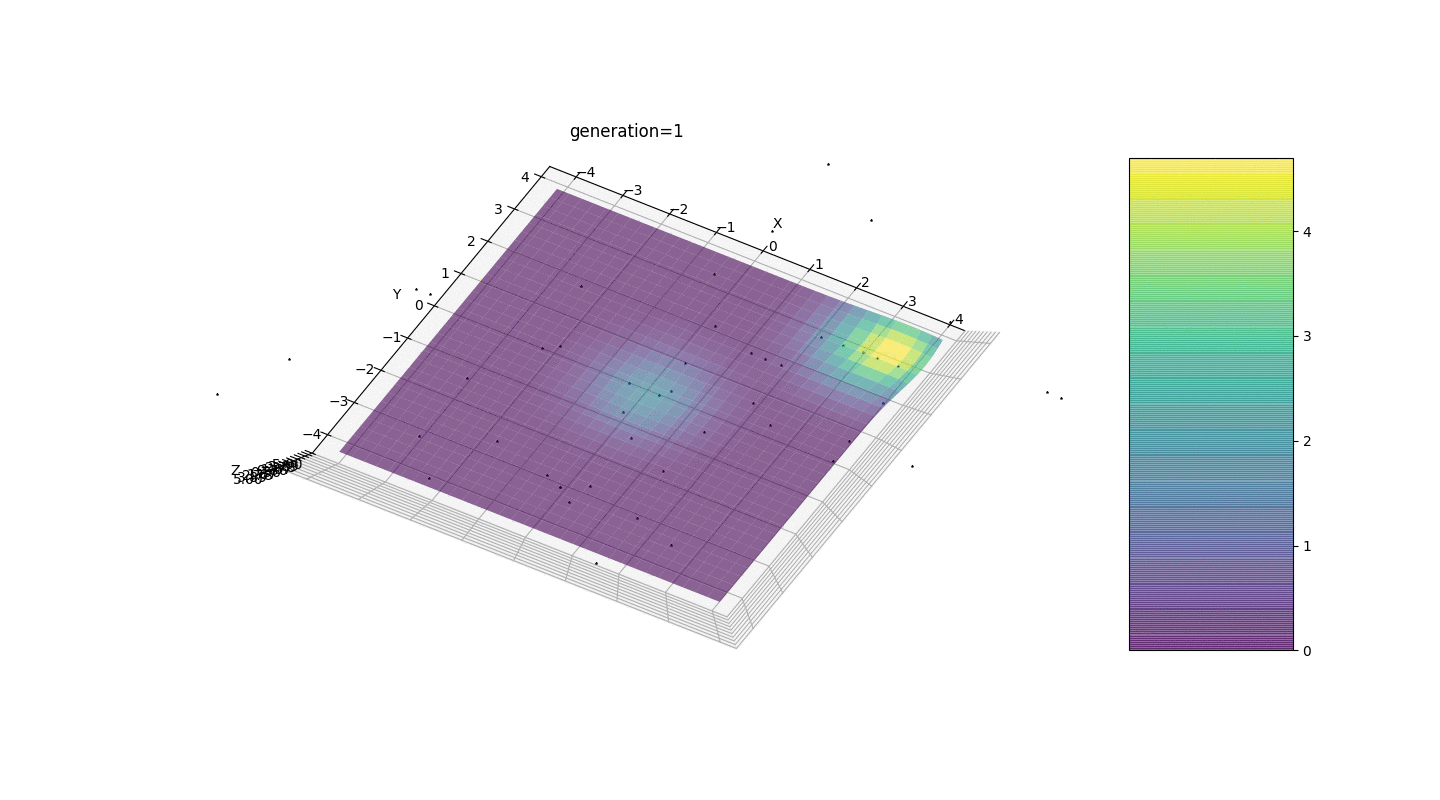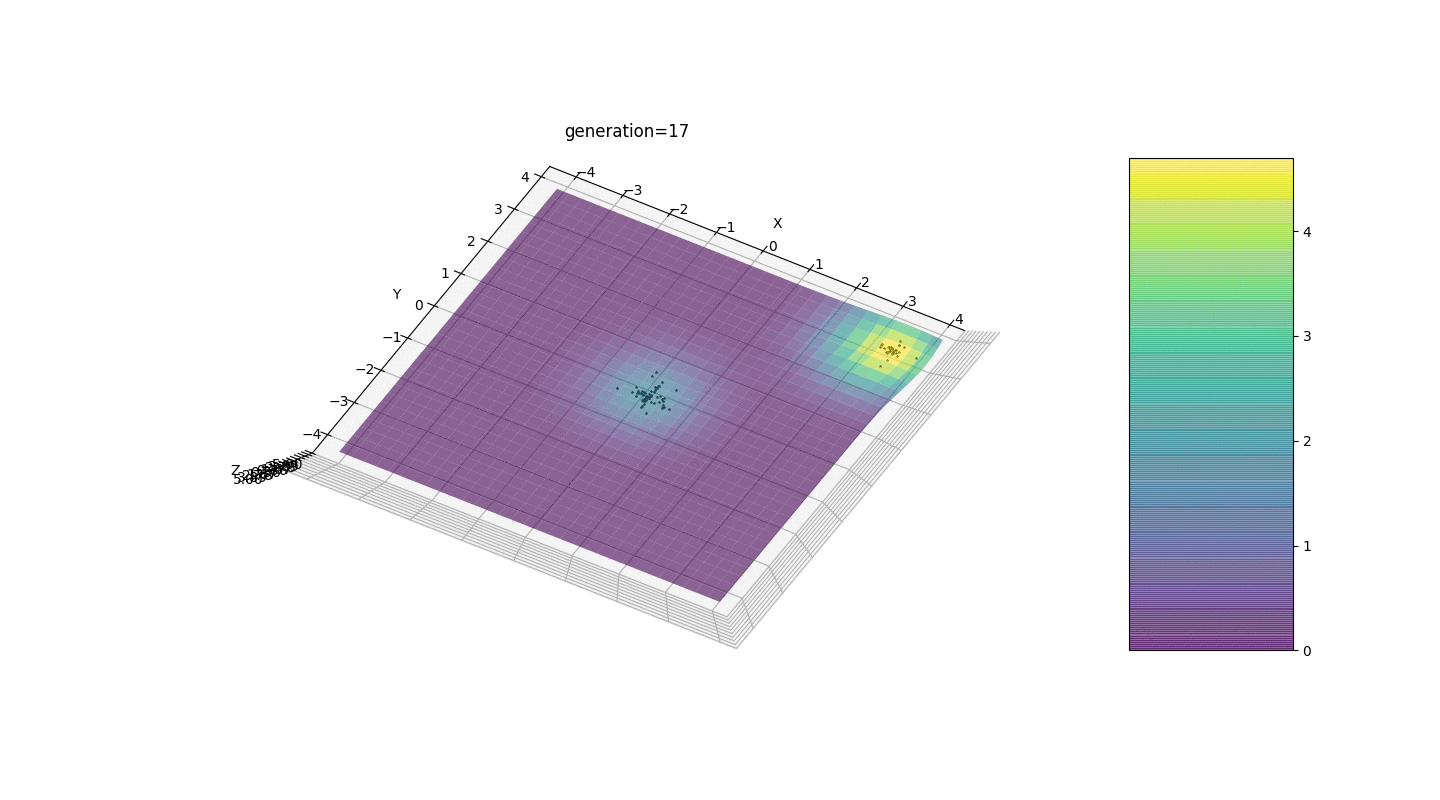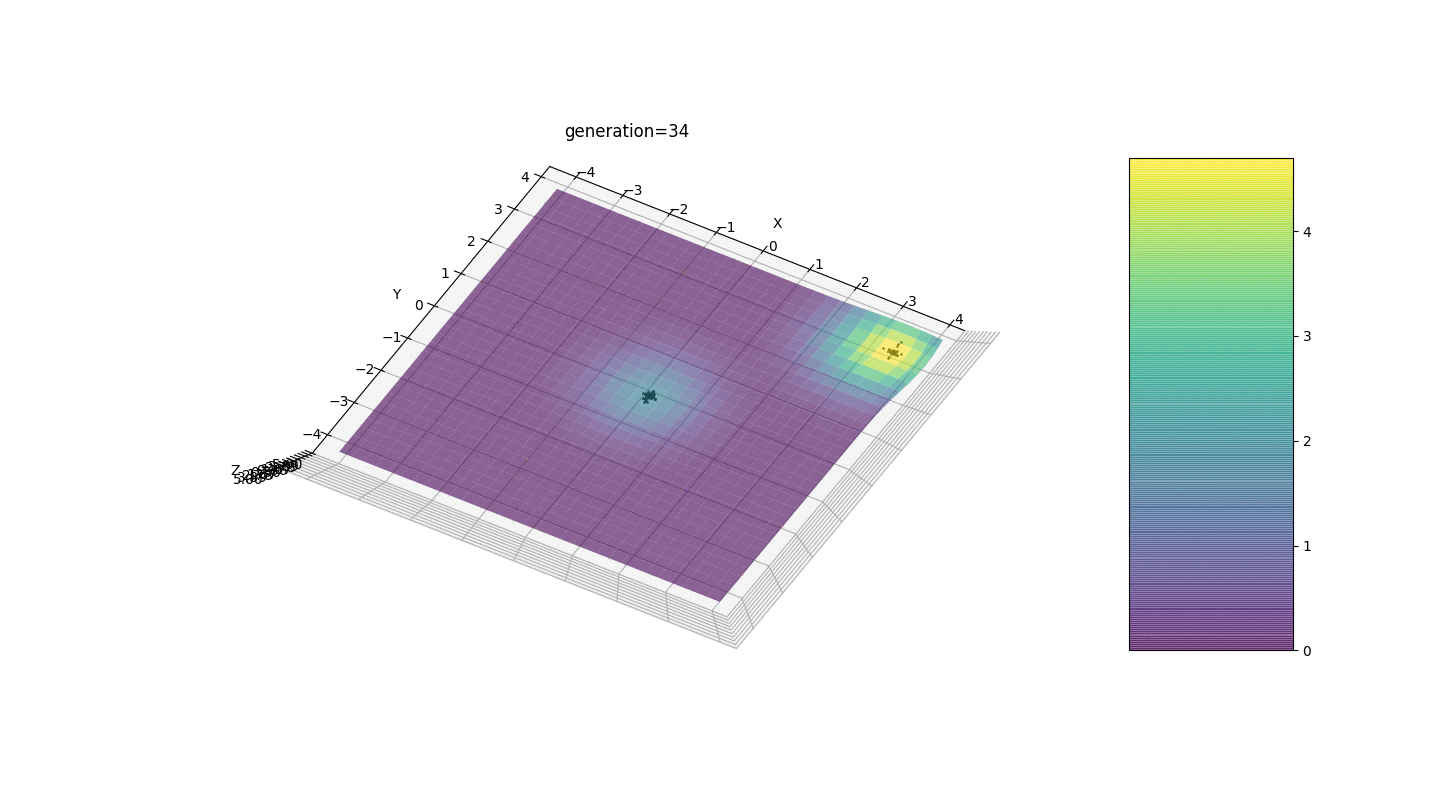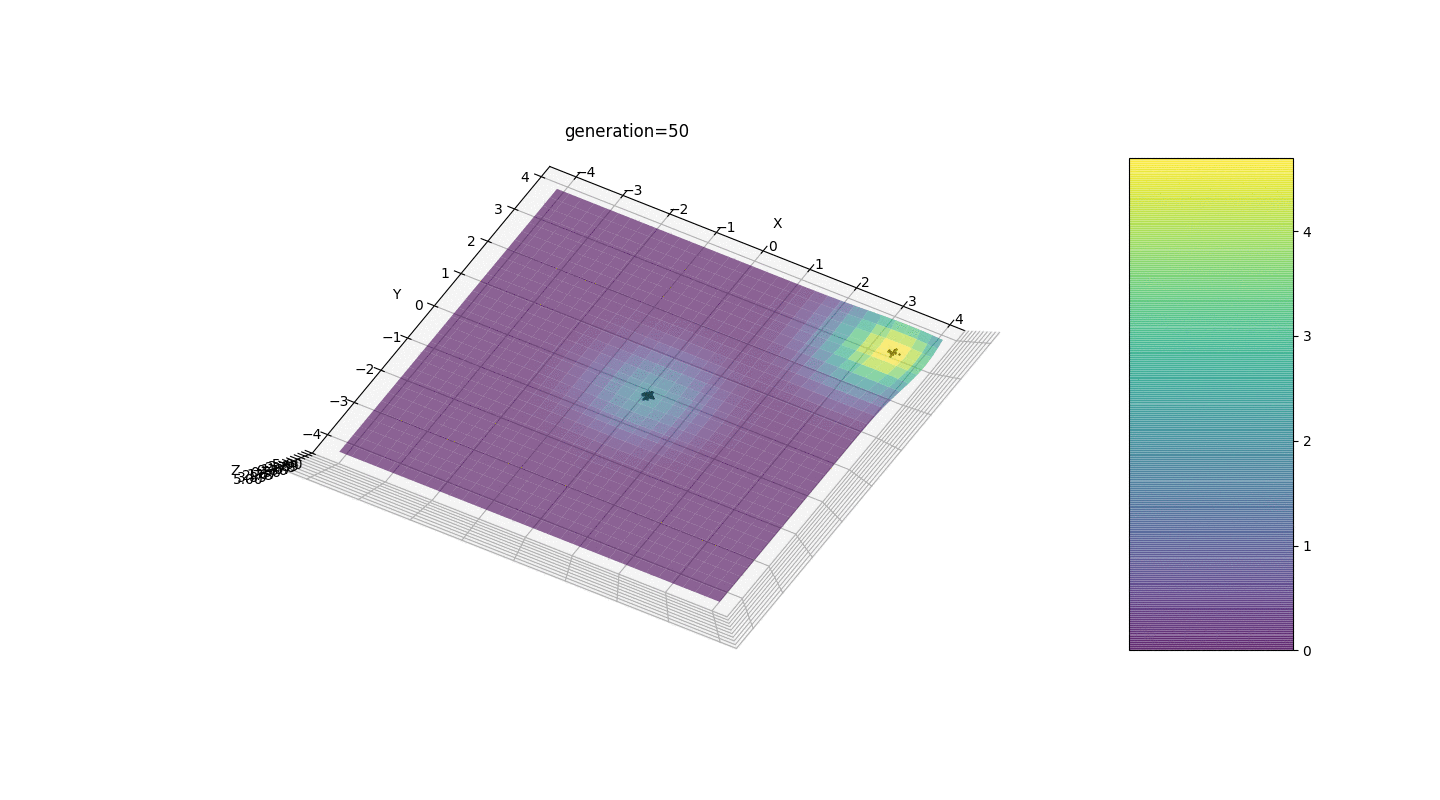
- Die Nullgenerierung wird nur in einem Quadrat mit Zufallszahlen gefüllt
und es kann Fälle geben, in denen dieses Quadrat ein lokales Extremum bedeckt, was nicht zu uns passt
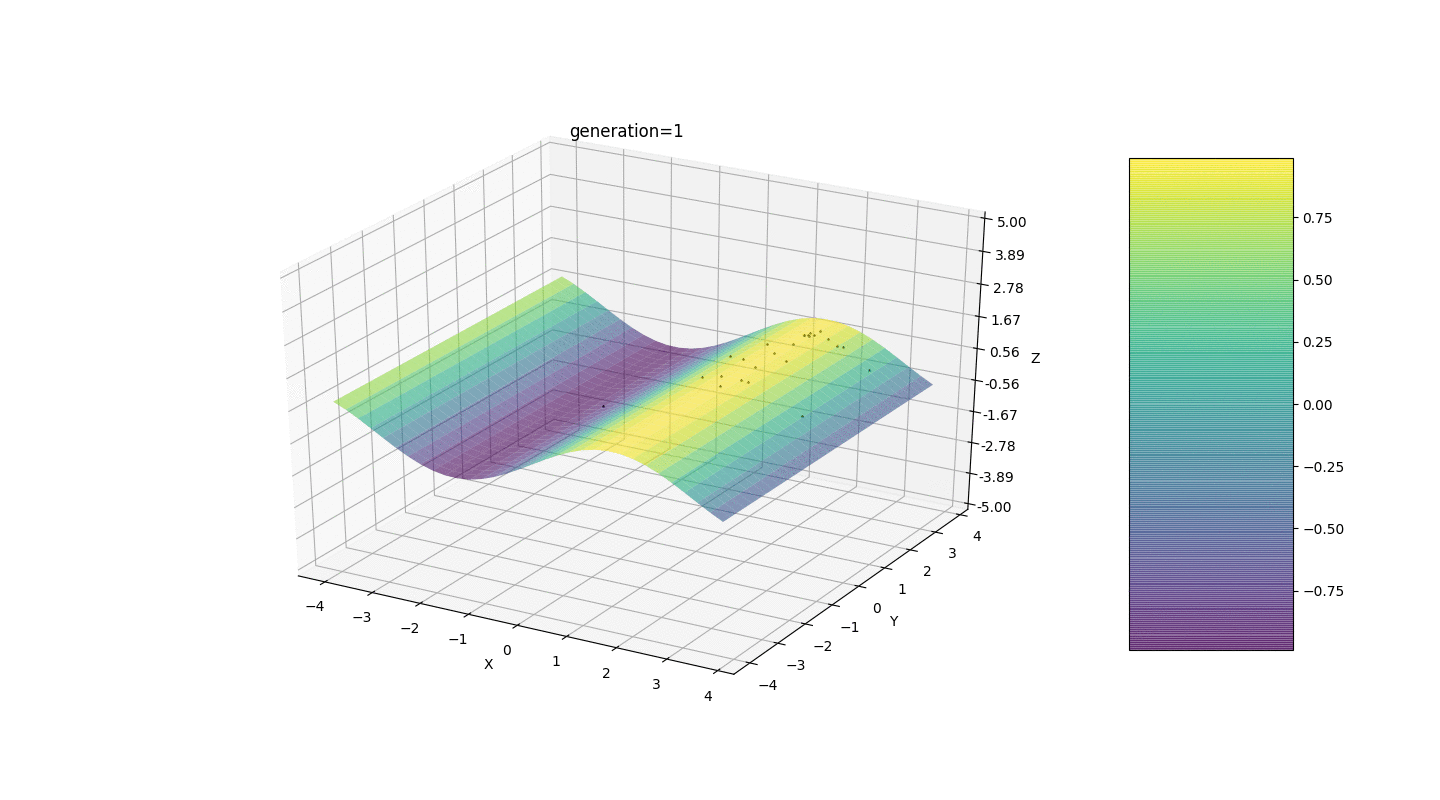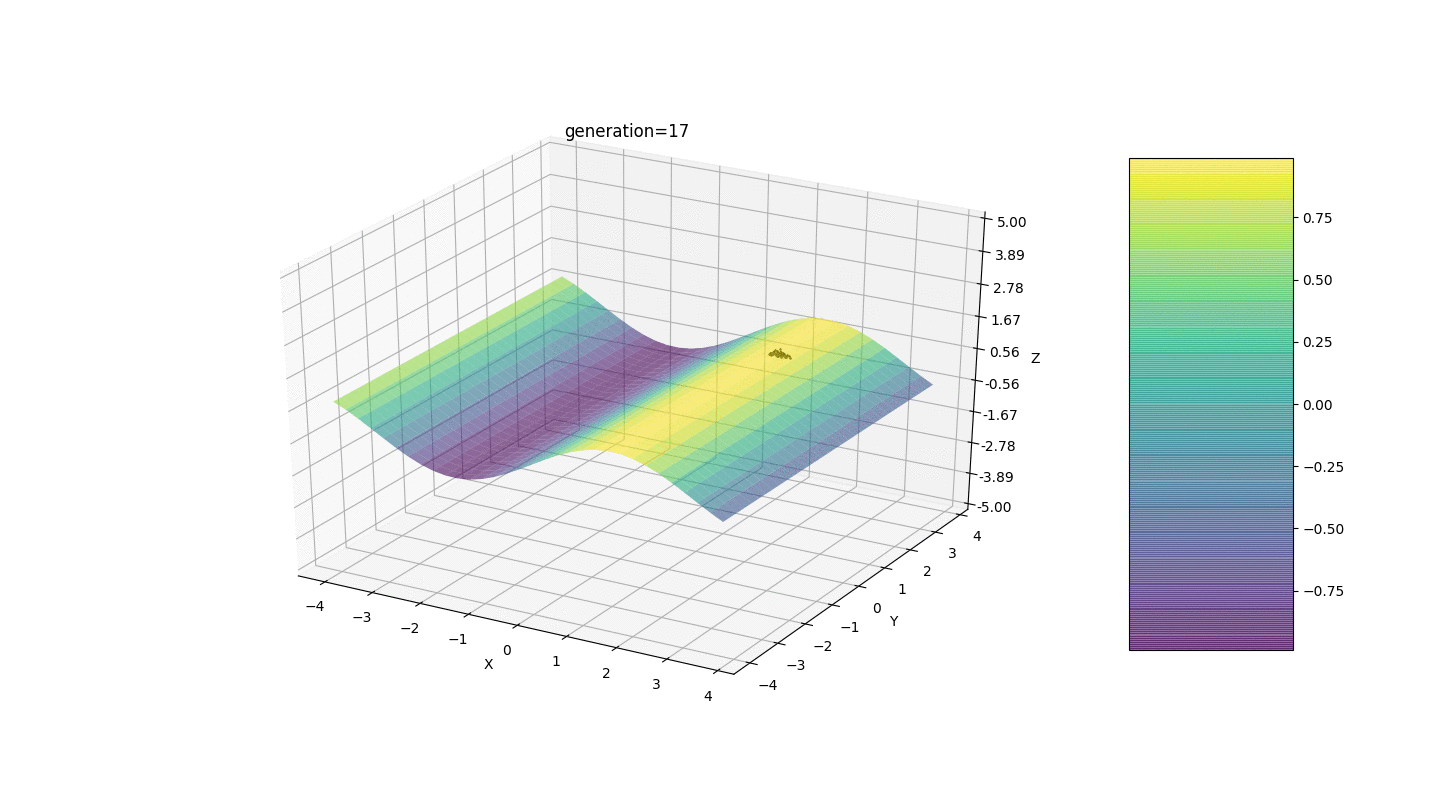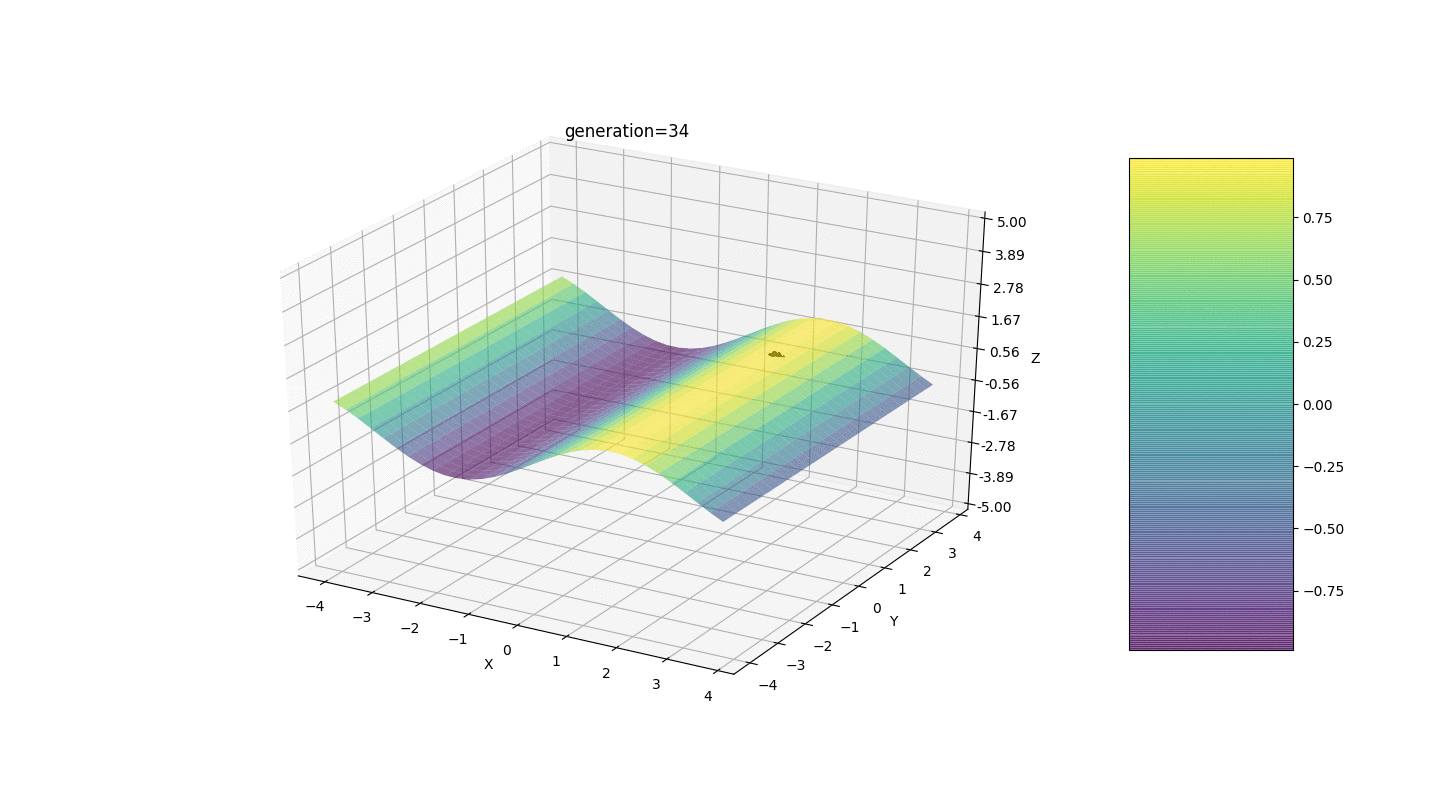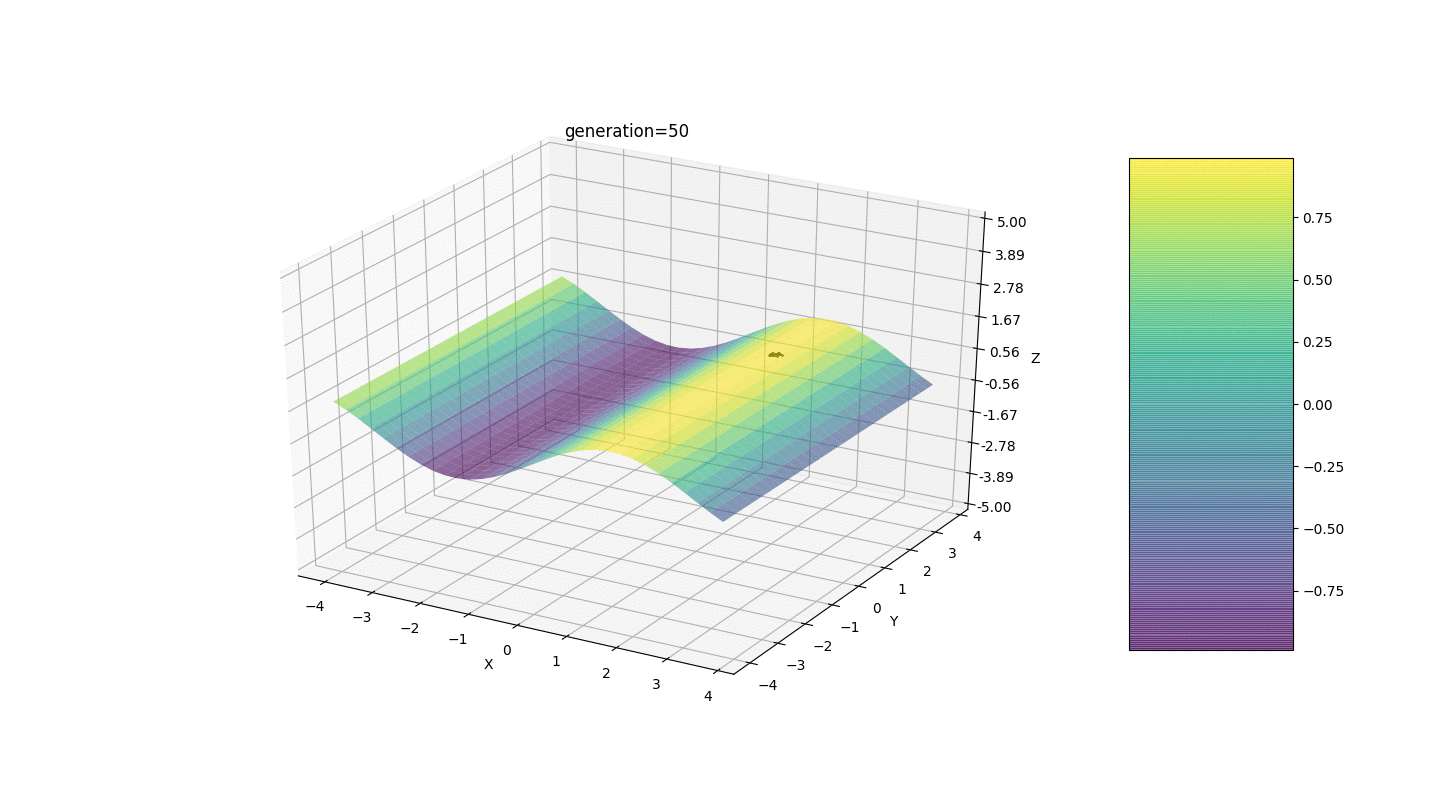
Betrachten Sie eine Oberfläche mit vielen Extrema der Form:Die Extrema der Funktion g befinden sich an Punkten.Test 3 Dieses Beispiel bestätigt und veranschaulicht alle obigen Beobachtungen.
Dieses Beispiel bestätigt und veranschaulicht alle obigen Beobachtungen.Upgrade des genetischen Algorithmus
Im Moment ist die Mutationsfunktion also sehr primitiv zusammengesetzt: Sie addiert zufällige Werte aus dem Halbintervallzum mutierten Gen. Eine solche Mutationsinvarianz stört manchmal die korrekte Funktionsweise des Algorithmus, aber es gibt einen wirksamen Weg, um diesen Defekt zu korrigieren.Wir führen einen neuen Parameter ein, den wir als "Mutationsbereich" bezeichnen und der zeigt, in welchem Halbintervall das Gen mutiert. Lassen Sie uns diesen Mutationskoeffizienten umgekehrt proportional zur Generationszahl machen. Jene. Je höher die Generationszahl, desto schwächer mutieren die Gene. Mit dieser Lösung können Sie den Startbereich anpassen und bei Bedarf die Genauigkeit der Berechnungen verbessern.Test 1
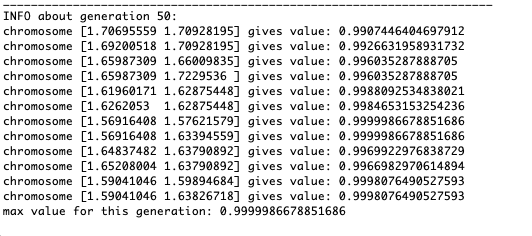 Wie das Beispiel zeigt, konvergiert die Bevölkerung mit jeder Generation mehr und mehr bis zum äußersten Punkt und berechnet aufgrund schwacher Schwankungen die genauesten Werte.Aber was ist mit dem Problem der lokalen Extreme? Betrachten Sie ein bekanntes Beispiel.Test 2
Wie das Beispiel zeigt, konvergiert die Bevölkerung mit jeder Generation mehr und mehr bis zum äußersten Punkt und berechnet aufgrund schwacher Schwankungen die genauesten Werte.Aber was ist mit dem Problem der lokalen Extreme? Betrachten Sie ein bekanntes Beispiel.Test 2

 Wir sehen, dass jetzt die Idee, die Bevölkerung in Teile zu teilen, wie beabsichtigt funktioniert. Ohne diese Segmentierung könnten Individuen früher Generationen einen falsch dominanten Genotyp an einem lokalen Extremum aufdecken, was zu einer falschen Antwort in der Aufgabe führen würde. Auffällig ist auch eine qualitative Verbesserung der Genauigkeit der Antwort aufgrund der eingeführten Abhängigkeit der Mutation von der Generationszahl.
Wir sehen, dass jetzt die Idee, die Bevölkerung in Teile zu teilen, wie beabsichtigt funktioniert. Ohne diese Segmentierung könnten Individuen früher Generationen einen falsch dominanten Genotyp an einem lokalen Extremum aufdecken, was zu einer falschen Antwort in der Aufgabe führen würde. Auffällig ist auch eine qualitative Verbesserung der Genauigkeit der Antwort aufgrund der eingeführten Abhängigkeit der Mutation von der Generationszahl.Zusammenfassung
Ich fasse das Ergebnis zusammen:...
- , . , , aka
- Zeitlicher und effizienter Vergleich ähnlicher Algorithmen mit Standardoptimierungsmethoden, z. B. Gradientenabstieg
- Neue Paketfunktionen (wahrscheinlich)