
Die Fortschritte beim maschinellen Lernen für die Verarbeitung natürlicher Sprachen haben sich in den letzten Jahren erheblich beschleunigt. Models verließen die Forschungslabors und wurden zur Grundlage führender digitaler Produkte. Ein gutes Beispiel dafür ist die kürzlich erfolgte Ankündigung, dass das BERT-Modell zur Hauptkomponente der Google-Suche geworden ist . Google ist der Ansicht, dass dieser Schritt (dh die Einführung eines fortschrittlichen Modells zum Verständnis der natürlichen Sprache in der Suchmaschine) "den größten Durchbruch in den letzten fünf Jahren und einen der bedeutendsten in der Geschichte der Suchmaschinen" darstellt.
– BERT' . , , , , .
, Colab.
: SST2
SST2, , ( 1), ( 0):

:
– , ( , ) 1 ( ), 0 ( ). :

:
, , 768. , .
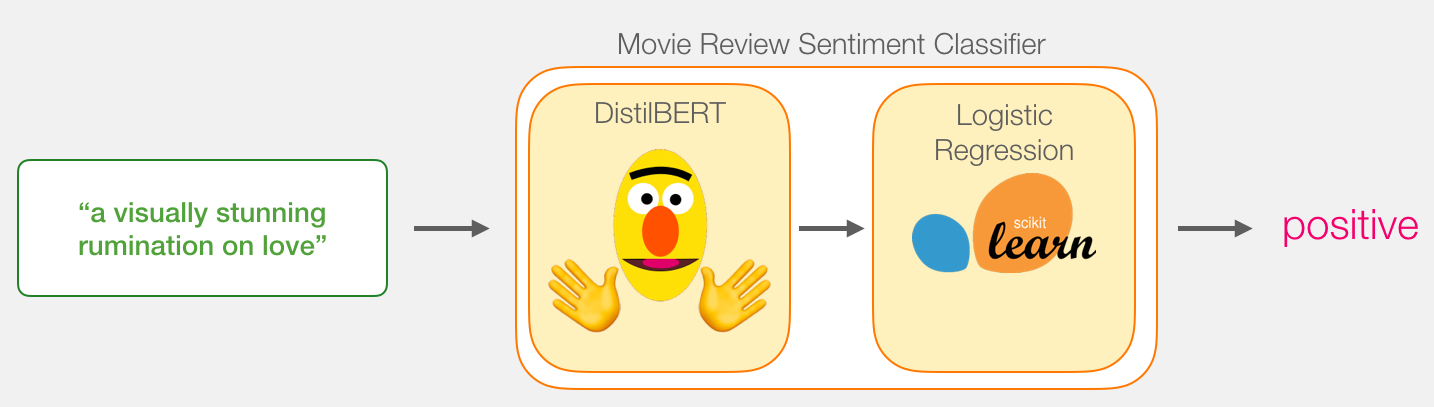
, BERT, ELMO ( NLP ): ( [CLS]).
, , . DistilBERT', . , , «» BERT', . , , BERT , [CLS] . , , . , , BERT .
transformers DistilBERT', .
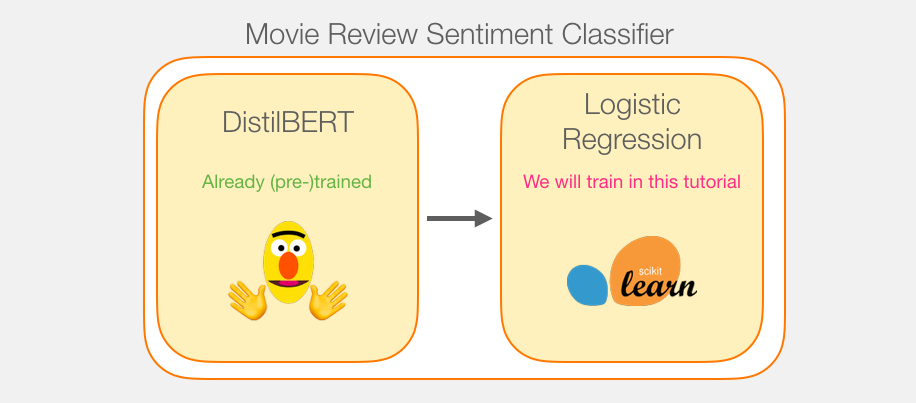
, . DistilBERT' 2 .

DistilBERT'. Scikit Learn. , , :
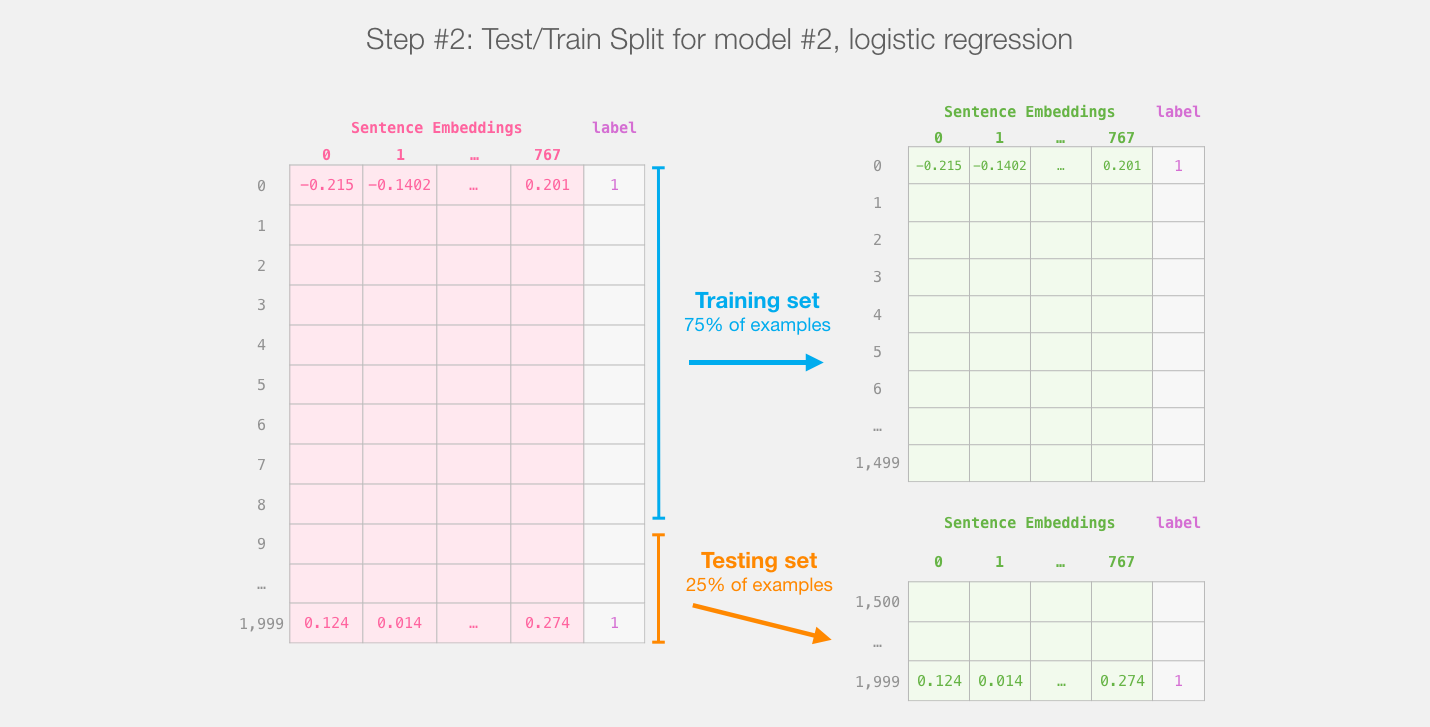
distilBERT' ( #1) , ( #2). , sklearn , , 75% ,
:

, , , .
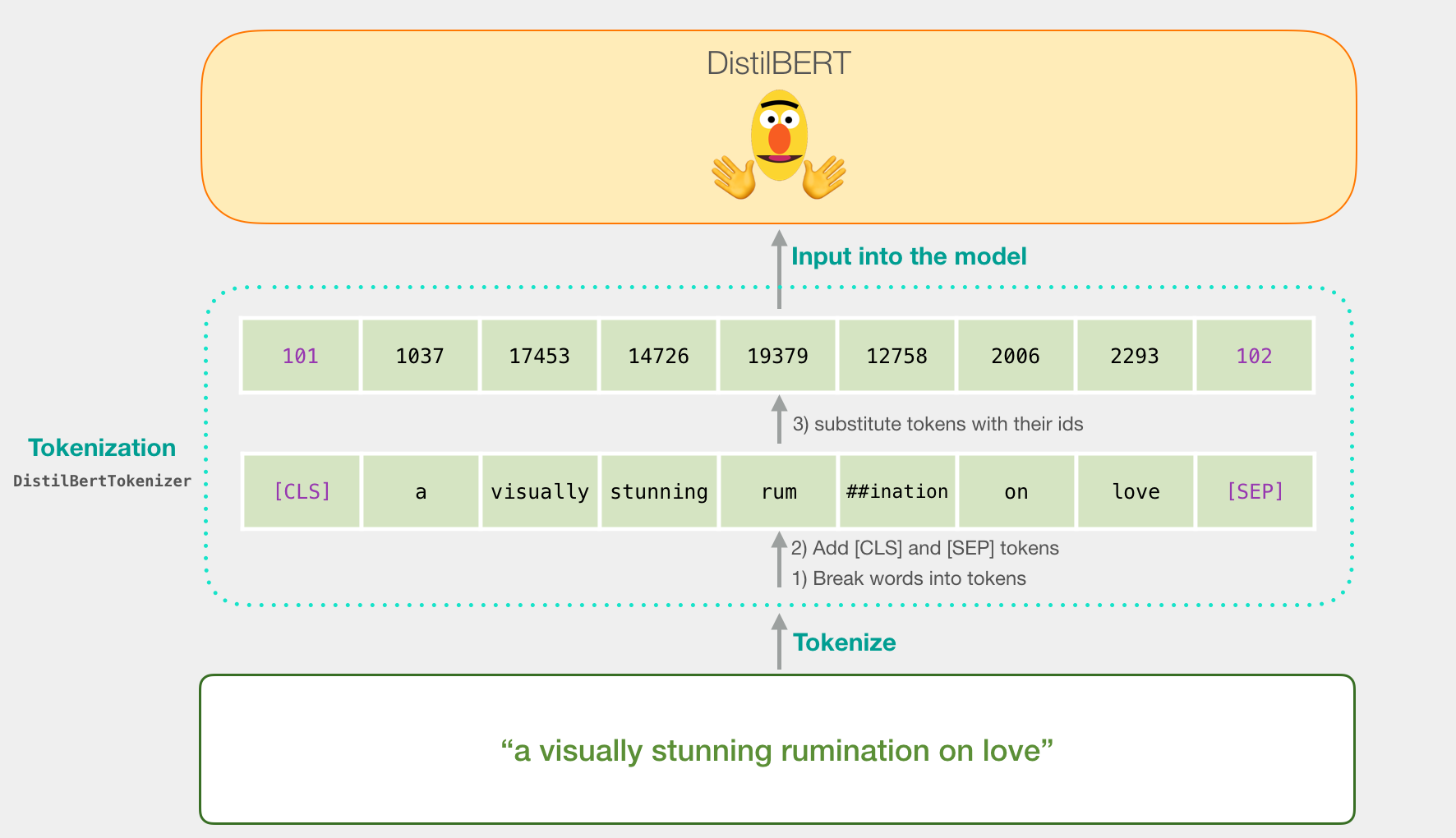
«a visually stunning rumination on love». BERT' , . , ( [CLS] [SEP] ).

, . Word2vec .

:
tokenizer.encode("a visually stunning rumination on love", add_special_tokens=True)
DistilBERT'.
BERT, ELMO ( NLP ), :
DistilBERT
DistilBERT' , BERT'. , 768 .
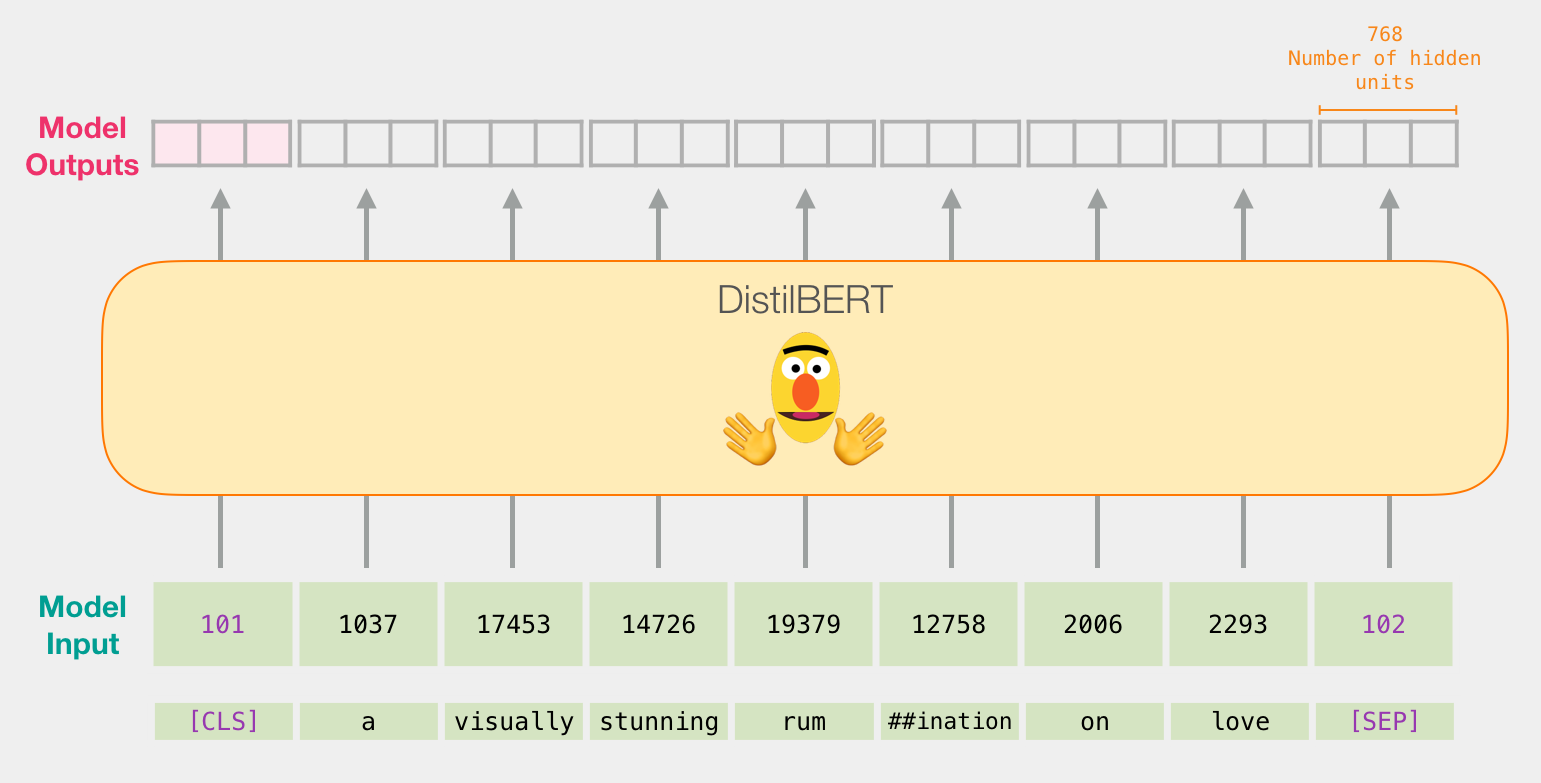
, , ( [CLS] ). .
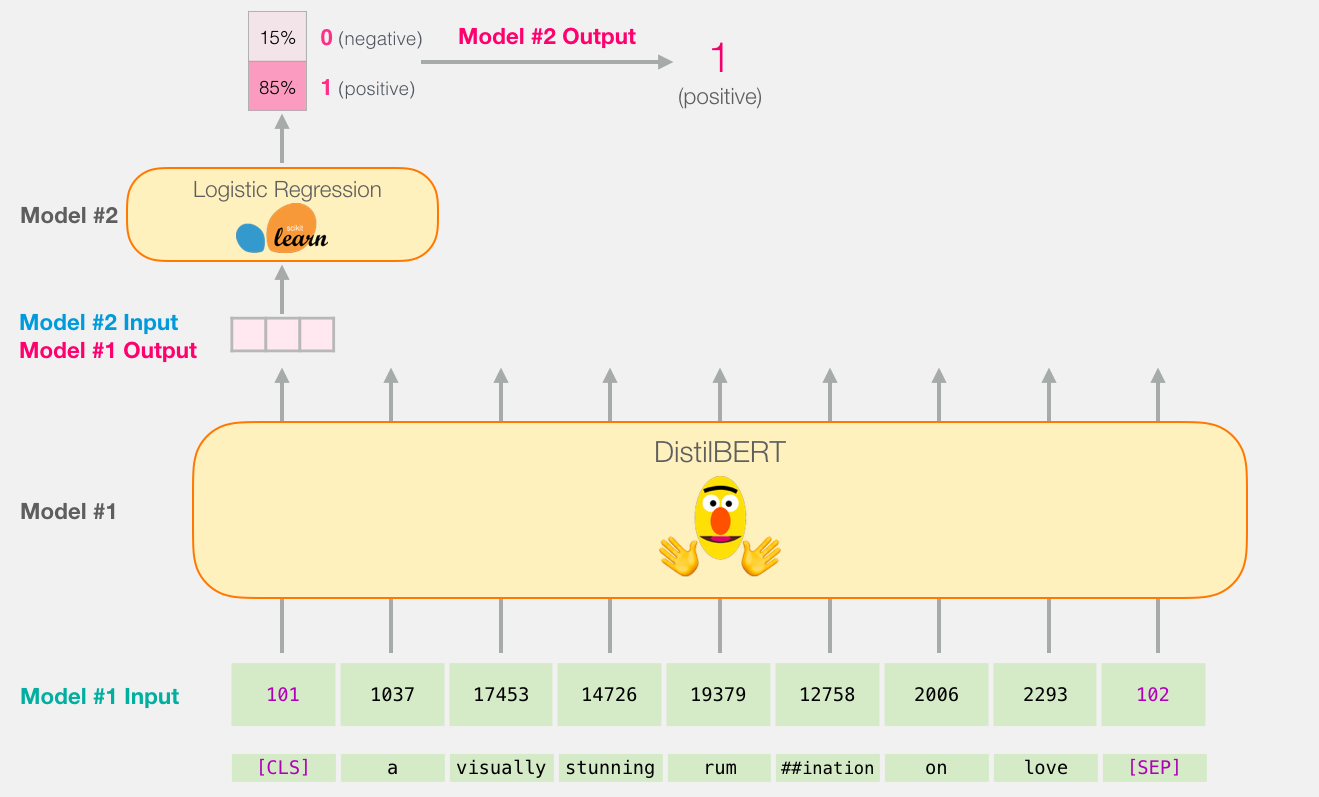
, , . :
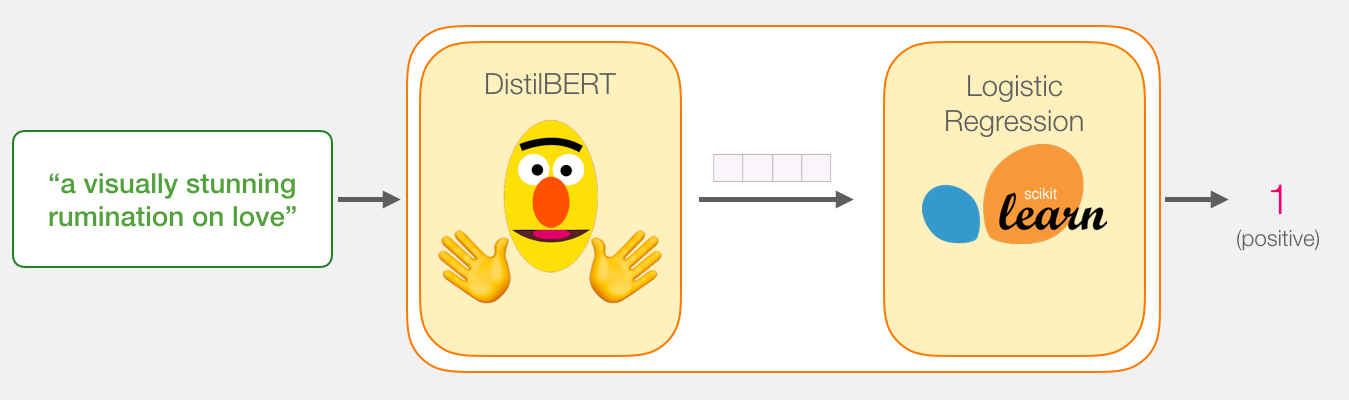
, .
. Colab github.
:
import numpy as np
import pandas as pd
import torch
import transformers as ppb
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
github, pandas:
df = pd.read_csv('https://github.com/clairett/pytorch-sentiment-classification/raw/master/data/SST2/train.tsv', delimiter='\t', header=None)
df.head() , 5 , :
df.head()

DistilBERT
model_class, tokenizer_class, pretrained_weights = (ppb.DistilBertModel, ppb.DistilBertTokenizer, 'distilbert-base-uncased')
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
model = model_class.from_pretrained(pretrained_weights)
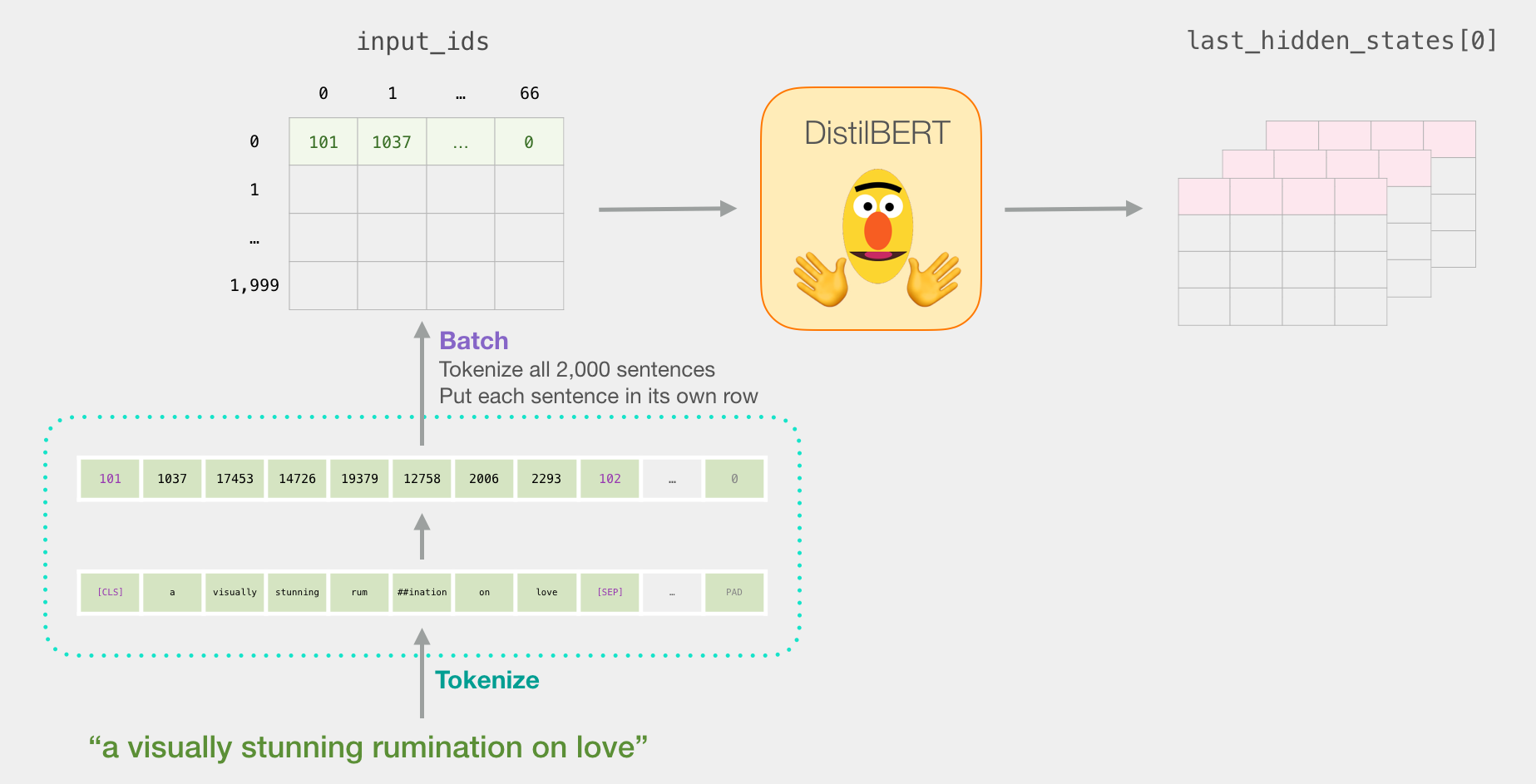
. , , . . ( , 2000).
tokenized = df[0].apply((lambda x: tokenizer.encode(x, add_special_tokens=True)))
.

( Series/DataFrame pandas) . DistilBERT , 0 (padding). , ( , Python).
, /, BERT':

DistilBERT'
DistilBERT.
input_ids = torch.tensor(np.array(padded))
with torch.no_grad():
last_hidden_states = model(input_ids)
last_hidden_states DistilBERT', ( , , DistilBERT). , 2000 (.. 2000 ), 66 ( 2000 ), 278 ( DistilBERT).

BERT'
3-d . :
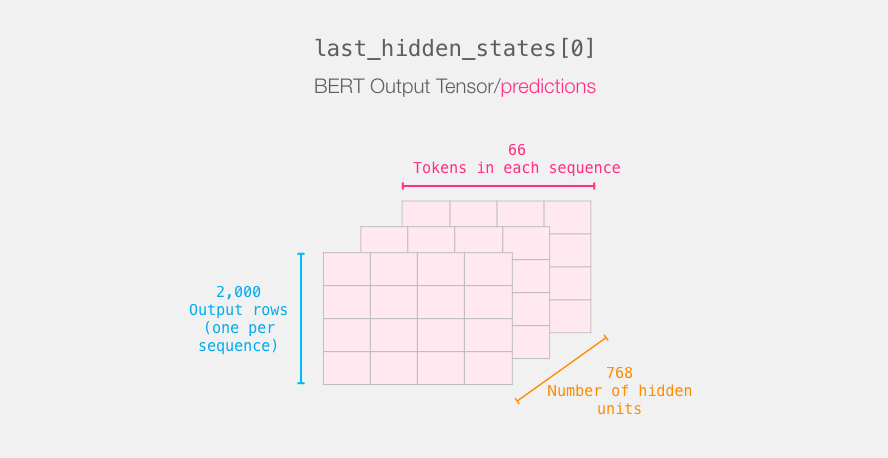
. :
BERT' [CLS]. .

, 3d , 2d :
features = last_hidden_states[0][:,0,:].numpy()
features 2d numpy, .

, BERT'
, BERT', , . 768 , .

, . BERT' [CLS] ( #0), (. ). , – , BERT/DistilBERT
, , .
labels = df[1]
train_features, test_features, train_labels, test_labels = train_test_split(features, labels)
:
.
lr_clf = LogisticRegression()
lr_clf.fit(train_features, train_labels)
, .
lr_clf.score(test_features, test_labels)
, (accuracy) – 81%.
: – 96.8. DistilBERT , – , . BERT , ( downstream task). DistilBERT' 90.7. BERT' 94.9.
Colab.
Das ist alles! Eine gute erste Bekanntschaft ist passiert. Der nächste Schritt besteht darin, sich der Dokumentation zuzuwenden und zu versuchen, Ihre eigenen Hände zu optimieren. Sie können auch ein bisschen zurückgehen und von distilBERT zu BERT gehen und sehen, wie es funktioniert.
Vielen Dank an Clément Delangue , Victor Sanh und das Huggingface-Team, das Feedback zu früheren Versionen dieses Handbuchs gegeben hat.
Autoren