Machen wir uns mit einem der Angriffe auf das neuronale Netzwerk vertraut, der zu Klassifizierungsfehlern mit minimalen externen Einflüssen führt. Stellen Sie sich für einen Moment vor, dass Sie das neuronale Netzwerk sind. Und im Moment klassifizieren Sie beim Trinken einer Tasse aromatischen Kaffees die Bilder von Katzen mit einer Genauigkeit von mehr als 90 Prozent, ohne zu ahnen, dass der „Ein-Pixel-Angriff“ alle Ihre „Katzen“ zu Lastwagen gemacht hat.Und jetzt machen wir eine Pause, schieben den Kaffee beiseite, importieren alle benötigten Bibliotheken und sehen, wie diese Ein-Pixel-Angriffe funktionieren.Der Zweck dieses Angriffs besteht darin, dass der Algorithmus (neuronales Netzwerk) eine falsche Antwort gibt. Im Folgenden sehen wir dies anhand verschiedener Modelle von Faltungs-Neuronalen Netzen. Mit einer der Methoden der mehrdimensionalen mathematischen Optimierung - der differentiellen Evolution - finden wir ein spezielles Pixel, das das Bild so ändern kann, dass das neuronale Netzwerk dieses Bild falsch zu klassifizieren beginnt (obwohl der Algorithmus früher dasselbe Bild korrekt und mit hoher Genauigkeit „erkannt“ hat).Importieren Sie die Bibliotheken:
%matplotlib inline
import pickle
import numpy as np
import pandas as pd
import matplotlib
from keras.datasets import cifar10
from keras import backend as K
from networks.lenet import LeNet
from networks.pure_cnn import PureCnn
from networks.network_in_network import NetworkInNetwork
from networks.resnet import ResNet
from networks.densenet import DenseNet
from networks.wide_resnet import WideResNet
from networks.capsnet import CapsNet
from differential_evolution import differential_evolution
import helper
matplotlib.style.use('ggplot')
Für unser Experiment werden wir den CIFAR-10-Datensatz laden, der reale Bilder enthält, die in 10 Klassen unterteilt sind.(x_train, y_train), (x_test, y_test) = cifar10.load_data()
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
Schauen wir uns jedes Bild anhand seines Index an. Zum Beispiel hier auf diesem Pferd.image_id = 99
helper.plot_image(x_test[image_id])
 Wir müssen nach dem sehr leistungsfähigen Pixel suchen, das die Reaktion des neuronalen Netzwerks ändern kann. Dies bedeutet, dass es Zeit ist, eine Funktion zu schreiben, um ein oder mehrere Pixel des Bildes zu ändern.
Wir müssen nach dem sehr leistungsfähigen Pixel suchen, das die Reaktion des neuronalen Netzwerks ändern kann. Dies bedeutet, dass es Zeit ist, eine Funktion zu schreiben, um ein oder mehrere Pixel des Bildes zu ändern.def perturb_image(xs, img):
if xs.ndim < 2:
xs = np.array([xs])
tile = [len(xs)] + [1]*(xs.ndim+1)
imgs = np.tile(img, tile)
xs = xs.astype(int)
for x,img in zip(xs, imgs):
pixels = np.split(x, len(x) // 5)
for pixel in pixels:
x_pos, y_pos, *rgb = pixel
img[x_pos, y_pos] = rgb
return imgs
Hör zu ?! Ändern Sie ein Pixel unseres Pferdes mit den Koordinaten (16, 16) in gelb.image_id = 99
pixel = np.array([16, 16, 255, 255, 0])
image_perturbed = perturb_image(pixel, x_test[image_id])[0]
helper.plot_image(image_perturbed)
 Um den Angriff zu demonstrieren, müssen Sie vorab trainierte Modelle neuronaler Netze in unseren CIFAR-10-Datensatz herunterladen. Wir werden zwei Modelle lenet und resnet verwenden, aber Sie können andere für Ihre Experimente verwenden, indem Sie die entsprechenden Codezeilen auskommentieren.
Um den Angriff zu demonstrieren, müssen Sie vorab trainierte Modelle neuronaler Netze in unseren CIFAR-10-Datensatz herunterladen. Wir werden zwei Modelle lenet und resnet verwenden, aber Sie können andere für Ihre Experimente verwenden, indem Sie die entsprechenden Codezeilen auskommentieren.lenet = LeNet()
resnet = ResNet()
models = [lenet, resnet]
Nach dem Laden der Modelle müssen die Testbilder jedes Modells ausgewertet werden, um sicherzustellen, dass nur Bilder angegriffen werden, die korrekt klassifiziert sind. Der folgende Code zeigt die Genauigkeit und Anzahl der Parameter für jedes Modell an.network_stats, correct_imgs = helper.evaluate_models(models, x_test, y_test)
correct_imgs = pd.DataFrame(correct_imgs, columns=['name', 'img', 'label', 'confidence', 'pred'])
network_stats = pd.DataFrame(network_stats, columns=['name', 'accuracy', 'param_count'])
network_stats
Evaluating lenet
Evaluating resnet
Out[11]:
name accuracy param_count
0 lenet 0.748 62006
1 resnet 0.9231 470218
Alle diese Angriffe können in zwei Klassen unterteilt werden: WhiteBox und BlackBox. Der Unterschied zwischen ihnen besteht darin, dass wir alle im ersten Fall zuverlässig über den Algorithmus Bescheid wissen, das Modell, mit dem wir es zu tun haben. Im Fall der BlackBox benötigen wir lediglich Eingabe (Bild) und Ausgabe (Wahrscheinlichkeit, einer der Klassen zugewiesen zu werden). Ein Pixelangriff bezieht sich auf die BlackBox.In diesem Artikel werden zwei Optionen für den Angriff auf ein einzelnes Pixel betrachtet: nicht zielgerichtet und zielgerichtet. Im ersten Fall wird es absolut gleich sein, zu welcher Klasse das neuronale Netzwerk unserer Katze gehören wird, vor allem nicht zur Klasse der Katzen. Ein gezielter Angriff ist anwendbar, wenn unsere Katze ein LKW und nur ein LKW werden soll.Aber wie findet man genau die Pixel, deren Änderung zu einer Änderung der Bildklasse führt? Wie finde ich ein Pixel, indem ich ändere, welcher Angriff mit einem Pixel möglich und erfolgreich wird? Versuchen wir, dieses Problem als Optimierungsproblem zu formulieren, aber nur in sehr einfachen Worten: Bei einem nicht zielgerichteten Angriff müssen wir das Vertrauen in die gewünschte Klasse minimieren und mit gezielt das Vertrauen in die Zielklasse maximieren.Bei solchen Angriffen ist es schwierig, die Funktion mit einem Gradienten zu optimieren. Es muss ein Optimierungsalgorithmus verwendet werden, der nicht von der Glätte der Funktion abhängt.Denken Sie daran, dass wir für unser Experiment den CIFAR-10-Datensatz verwenden, der reale Bilder mit einer Größe von 32 x 32 Pixel enthält, die in 10 Klassen unterteilt sind. Dies bedeutet, dass wir ganzzahlige diskrete Werte von 0 bis 31 und Farbintensitäten von 0 bis 255 haben und die Funktion nicht glatt, sondern gezackt sein soll, wie unten gezeigt: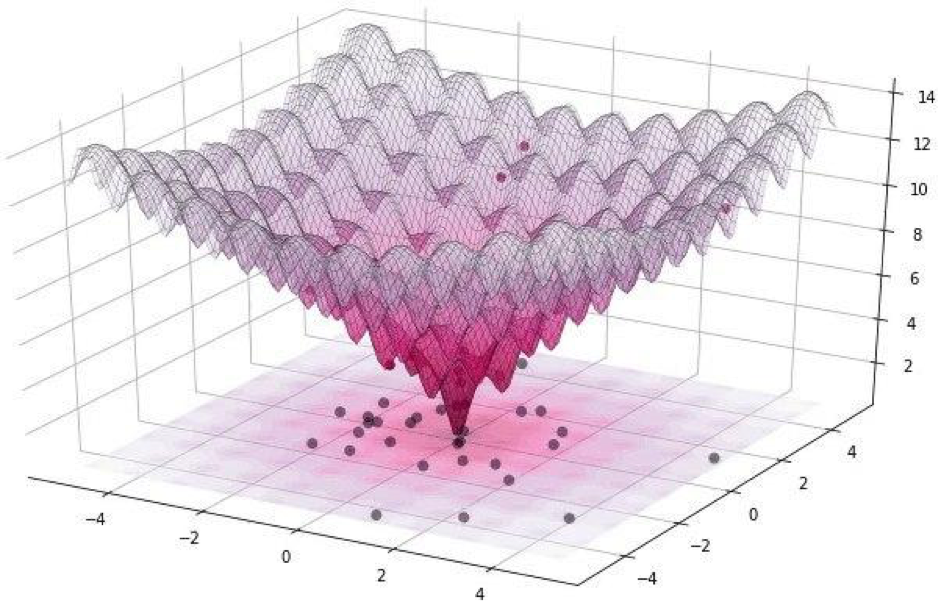 Deshalb verwenden wir den Differential-Evolutions-Algorithmus.Aber zurück zum Code und schreiben Sie eine Funktion, die die Wahrscheinlichkeit der Zuverlässigkeit des Modells zurückgibt. Wenn die Zielklasse korrekt ist, möchten wir diese Funktion minimieren, damit das Modell einer anderen Klasse sicher ist (was nicht wahr ist).
Deshalb verwenden wir den Differential-Evolutions-Algorithmus.Aber zurück zum Code und schreiben Sie eine Funktion, die die Wahrscheinlichkeit der Zuverlässigkeit des Modells zurückgibt. Wenn die Zielklasse korrekt ist, möchten wir diese Funktion minimieren, damit das Modell einer anderen Klasse sicher ist (was nicht wahr ist).def predict_classes(xs, img, target_class, model, minimize=True):
imgs_perturbed = perturb_image(xs, img)
predictions = model.predict(imgs_perturbed)[:,target_class]
return predictions if minimize else 1 - predictions
image_id = 384
pixel = np.array([16, 13, 25, 48, 156])
model = resnet
true_class = y_test[image_id, 0]
prior_confidence = model.predict_one(x_test[image_id])[true_class]
confidence = predict_classes(pixel, x_test[image_id], true_class, model)[0]
print('Confidence in true class', class_names[true_class], 'is', confidence)
print('Prior confidence was', prior_confidence)
helper.plot_image(perturb_image(pixel, x_test[image_id])[0])
Confidence in true class bird is 0.00018887444
Prior confidence was 0.70661753
 Wir benötigen die nächste Funktion, um das Kriterium für den Erfolg des Angriffs zu bestätigen. Sie gibt True zurück, wenn die Änderung ausreicht, um das Modell auszutricksen.
Wir benötigen die nächste Funktion, um das Kriterium für den Erfolg des Angriffs zu bestätigen. Sie gibt True zurück, wenn die Änderung ausreicht, um das Modell auszutricksen.def attack_success(x, img, target_class, model, targeted_attack=False, verbose=False):
attack_image = perturb_image(x, img)
confidence = model.predict(attack_image)[0]
predicted_class = np.argmax(confidence)
if verbose:
print('Confidence:', confidence[target_class])
if ((targeted_attack and predicted_class == target_class) or
(not targeted_attack and predicted_class != target_class)):
return True
Schauen wir uns die Arbeit der Erfolgskriteriumfunktion an. Zur Demonstration gehen wir von einem Nicht-Ziel-Angriff aus.image_id = 541
pixel = np.array([17, 18, 185, 36, 215])
model = resnet
true_class = y_test[image_id, 0]
prior_confidence = model.predict_one(x_test[image_id])[true_class]
success = attack_success(pixel, x_test[image_id], true_class, model, verbose=True)
print('Prior confidence', prior_confidence)
print('Attack success:', success == True)
helper.plot_image(perturb_image(pixel, x_test[image_id])[0])
Confidence: 0.07460087
Prior confidence 0.50054216
Attack success: True
 Es ist Zeit, alle Rätsel in einem Bild zu sammeln. Wir werden eine kleine Modifikation der Implementierung der differentiellen Evolution in Scipy verwenden.
Es ist Zeit, alle Rätsel in einem Bild zu sammeln. Wir werden eine kleine Modifikation der Implementierung der differentiellen Evolution in Scipy verwenden.def attack(img_id, model, target=None, pixel_count=1,
maxiter=75, popsize=400, verbose=False):
targeted_attack = target is not None
target_class = target if targeted_attack else y_test[img_id, 0]
bounds = [(0,32), (0,32), (0,256), (0,256), (0,256)] * pixel_count
popmul = max(1, popsize // len(bounds))
def predict_fn(xs):
return predict_classes(xs, x_test[img_id], target_class,
model, target is None)
def callback_fn(x, convergence):
return attack_success(x, x_test[img_id], target_class,
model, targeted_attack, verbose)
attack_result = differential_evolution(
predict_fn, bounds, maxiter=maxiter, popsize=popmul,
recombination=1, atol=-1, callback=callback_fn, polish=False)
attack_image = perturb_image(attack_result.x, x_test[img_id])[0]
prior_probs = model.predict_one(x_test[img_id])
predicted_probs = model.predict_one(attack_image)
predicted_class = np.argmax(predicted_probs)
actual_class = y_test[img_id, 0]
success = predicted_class != actual_class
cdiff = prior_probs[actual_class] - predicted_probs[actual_class]
helper.plot_image(attack_image, actual_class, class_names, predicted_class)
return [model.name, pixel_count, img_id, actual_class, predicted_class, success, cdiff, prior_probs, predicted_probs, attack_result.x]
Es ist Zeit, die Ergebnisse der Studie (den Angriff) zu teilen und zu sehen, wie durch Ändern eines Pixels aus einem Frosch ein Hund, aus einer Katze ein Frosch und aus einem Auto ein Flugzeug wird. Je mehr Bildpunkte sich ändern dürfen, desto höher ist die Wahrscheinlichkeit eines erfolgreichen Angriffs auf ein Bild.

 Demonstrieren Sie einen erfolgreichen Angriff auf ein Froschbild mithilfe des Resnet-Modells. Wir sollten nach mehreren Iterationen Vertrauen in den wahren Klassenrückgang sehen.
Demonstrieren Sie einen erfolgreichen Angriff auf ein Froschbild mithilfe des Resnet-Modells. Wir sollten nach mehreren Iterationen Vertrauen in den wahren Klassenrückgang sehen.image_id = 102
pixels = 1
model = resnet
_ = attack(image_id, model, pixel_count=pixels, verbose=True)
Confidence: 0.9938618
Confidence: 0.77454716
Confidence: 0.77454716
Confidence: 0.77454716
Confidence: 0.77454716
Confidence: 0.77454716
Confidence: 0.53226393
Confidence: 0.53226393
Confidence: 0.53226393
Confidence: 0.53226393
Confidence: 0.4211318
 Dies waren Beispiele für einen nicht zielgerichteten Angriff. Jetzt führen wir einen gezielten Angriff durch und wählen aus, in welche Klasse das Modell das Bild klassifizieren soll. Die Aufgabe ist viel komplizierter als die vorherige, da das neuronale Netzwerk das Bild eines Schiffes als Auto und eines Pferdes als Katze klassifizieren wird.
Dies waren Beispiele für einen nicht zielgerichteten Angriff. Jetzt führen wir einen gezielten Angriff durch und wählen aus, in welche Klasse das Modell das Bild klassifizieren soll. Die Aufgabe ist viel komplizierter als die vorherige, da das neuronale Netzwerk das Bild eines Schiffes als Auto und eines Pferdes als Katze klassifizieren wird.
 Im Folgenden werden wir versuchen, Lenet dazu zu bringen, das Bild des Schiffes als Auto zu klassifizieren.
Im Folgenden werden wir versuchen, Lenet dazu zu bringen, das Bild des Schiffes als Auto zu klassifizieren.image_id = 108
target_class = 1
pixels = 3
model = lenet
print('Attacking with target', class_names[target_class])
_ = attack(image_id, model, target_class, pixel_count=pixels, verbose=True)
Attacking with target automobile
Confidence: 0.044409167
Confidence: 0.044409167
Confidence: 0.044409167
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.081972085
Confidence: 0.081972085
Confidence: 0.081972085
Confidence: 0.081972085
Confidence: 0.1537778
Confidence: 0.1537778
Confidence: 0.1537778
Confidence: 0.22246778
Confidence: 0.23916133
Confidence: 0.25238588
Confidence: 0.25238588
Confidence: 0.25238588
Confidence: 0.44560355
Confidence: 0.44560355
Confidence: 0.44560355
Confidence: 0.5711696
 Nachdem wir uns mit einzelnen Fällen von Angriffen befasst haben, werden wir Statistiken unter Verwendung der Architektur der Faltungs-Neuronalen Netze ResNet sammeln, die jedes Modell durchlaufen und 1, 3 oder 5 Pixel jedes Bildes ändern. In diesem Artikel zeigen wir die endgültigen Schlussfolgerungen, ohne den Leser zu stören, sich mit jeder Iteration vertraut zu machen, da dies viel Zeit und Rechenaufwand erfordert.
Nachdem wir uns mit einzelnen Fällen von Angriffen befasst haben, werden wir Statistiken unter Verwendung der Architektur der Faltungs-Neuronalen Netze ResNet sammeln, die jedes Modell durchlaufen und 1, 3 oder 5 Pixel jedes Bildes ändern. In diesem Artikel zeigen wir die endgültigen Schlussfolgerungen, ohne den Leser zu stören, sich mit jeder Iteration vertraut zu machen, da dies viel Zeit und Rechenaufwand erfordert.def attack_all(models, samples=500, pixels=(1,3,5), targeted=False,
maxiter=75, popsize=400, verbose=False):
results = []
for model in models:
model_results = []
valid_imgs = correct_imgs[correct_imgs.name == model.name].img
img_samples = np.random.choice(valid_imgs, samples, replace=False)
for pixel_count in pixels:
for i, img_id in enumerate(img_samples):
print('\n', model.name, '- image', img_id, '-', i+1, '/', len(img_samples))
targets = [None] if not targeted else range(10)
for target in targets:
if targeted:
print('Attacking with target', class_names[target])
if target == y_test[img, 0]:
continue
result = attack(img_id, model, target, pixel_count,
maxiter=maxiter, popsize=popsize,
verbose=verbose)
model_results.append(result)
results += model_results
helper.checkpoint(results, targeted)
return results
untargeted = attack_all(models, samples=100, targeted=False)
targeted = attack_all(models, samples=10, targeted=False)
Um die Möglichkeit einer Netzwerkdiskreditierung zu testen, wurde ein Algorithmus entwickelt und dessen Auswirkung auf die Prognosequalität der Mustererkennungslösung gemessen.Lassen Sie uns die Endergebnisse sehen.untargeted, targeted = helper.load_results()
columns = ['model', 'pixels', 'image', 'true', 'predicted', 'success', 'cdiff', 'prior_probs', 'predicted_probs', 'perturbation']
untargeted_results = pd.DataFrame(untargeted, columns=columns)
targeted_results = pd.DataFrame(targeted, columns=columns)
Die folgende Tabelle zeigt, dass bei Verwendung des neuronalen ResNet-Netzwerks mit einer Genauigkeit von 0,9231, bei der mehrere Pixel des Bildes geändert wurden, ein sehr guter Prozentsatz erfolgreich angegriffener Bilder (attack_success_rate) erzielt wurde.helper.attack_stats(targeted_results, models, network_stats)
Out[26]:
model accuracy pixels attack_success_rate
0 resnet 0.9231 1 0.144444
1 resnet 0.9231 3 0.211111
2 resnet 0.9231 5 0.222222
helper.attack_stats(untargeted_results, models, network_stats)
Out[27]:
model accuracy pixels attack_success_rate
0 resnet 0.9231 1 0.34
1 resnet 0.9231 3 0.79
2 resnet 0.9231 5 0.79
In Ihren Experimenten können Sie andere Architekturen künstlicher neuronaler Netze verwenden, da es derzeit sehr viele davon gibt. Neuronale Netze haben die moderne Welt mit unsichtbaren Fäden umhüllt. Seit langem werden Dienste erfunden, bei denen Benutzer mithilfe von KI (künstliche Intelligenz) verarbeitete Fotos erhalten, die stilistisch der Arbeit großer Künstler ähneln. Heute können die Algorithmen selbst Bilder zeichnen, musikalische Meisterwerke erstellen, Bücher und sogar Drehbücher für Filme schreiben.Bereiche wie Computer Vision, Gesichtserkennung, unbemannte Fahrzeuge, Diagnose von Krankheiten - treffen Sie wichtige Entscheidungen und haben Sie nicht das Recht, Fehler zu machen. Eine Störung der Funktionsweise der Algorithmen führt zu katastrophalen Folgen.Ein Pixel-Angriff ist eine Möglichkeit, Angriffe zu fälschen. Um die Möglichkeit einer Netzwerkdiskreditierung zu testen, wurde ein Algorithmus entwickelt und dessen Auswirkung auf die Prognosequalität der Mustererkennungslösung gemessen. Das Ergebnis zeigte, dass die verwendeten Faltungsarchitekturen für neuronale Netze für den speziell trainierten Ein-Pixel-Angriffsalgorithmus anfällig sind, der ein Pixel ersetzt, um den Erkennungsalgorithmus zu diskreditieren.Der Artikel wurde von Alexander Andronic und Adrey Cherny-Tkach im Rahmen eines Praktikums bei Data4 erstellt .
Neuronale Netze haben die moderne Welt mit unsichtbaren Fäden umhüllt. Seit langem werden Dienste erfunden, bei denen Benutzer mithilfe von KI (künstliche Intelligenz) verarbeitete Fotos erhalten, die stilistisch der Arbeit großer Künstler ähneln. Heute können die Algorithmen selbst Bilder zeichnen, musikalische Meisterwerke erstellen, Bücher und sogar Drehbücher für Filme schreiben.Bereiche wie Computer Vision, Gesichtserkennung, unbemannte Fahrzeuge, Diagnose von Krankheiten - treffen Sie wichtige Entscheidungen und haben Sie nicht das Recht, Fehler zu machen. Eine Störung der Funktionsweise der Algorithmen führt zu katastrophalen Folgen.Ein Pixel-Angriff ist eine Möglichkeit, Angriffe zu fälschen. Um die Möglichkeit einer Netzwerkdiskreditierung zu testen, wurde ein Algorithmus entwickelt und dessen Auswirkung auf die Prognosequalität der Mustererkennungslösung gemessen. Das Ergebnis zeigte, dass die verwendeten Faltungsarchitekturen für neuronale Netze für den speziell trainierten Ein-Pixel-Angriffsalgorithmus anfällig sind, der ein Pixel ersetzt, um den Erkennungsalgorithmus zu diskreditieren.Der Artikel wurde von Alexander Andronic und Adrey Cherny-Tkach im Rahmen eines Praktikums bei Data4 erstellt .