Hallo alle zusammen. Vor dem Start des Python Neural Networks- Kurses haben wir für Sie eine Übersetzung eines weiteren interessanten Materials vorbereitet.
Wir freuen uns , PyCaret vorstellen zu können , eine Open-Source-Python-Bibliothek für maschinelles Lernen zum Lernen und Bereitstellen von Modellen mit und ohne Lehrer in einer Umgebung mit geringem Code. Mit PyCaret können Sie in der von Ihnen ausgewählten Notebook-Umgebung in wenigen Sekunden von der Datenaufbereitung zur Modellbereitstellung übergehen.Im Vergleich zu anderen offenen Bibliotheken für maschinelles Lernen ist PyCaret eine Low-Code-Alternative, die Hunderte von Codezeilen mit nur wenigen Wörtern ersetzen kann. Die Geschwindigkeit effizienterer Experimente wird exponentiell zunehmen. PyCaret ist im Wesentlichen eine Python-Shell über mehrere maschinelle Lernbibliotheken wie Scikit-Learn , XGBoost , Microsoft LightGBM und SpaCyund viele andere.PyCaret ist einfach und leicht zu bedienen. Alle von PyCaret ausgeführten Vorgänge werden nacheinander in einer Pipeline gespeichert, die vollständig für die Bereitstellung bereit ist. Unabhängig davon, ob fehlende Werte hinzugefügt, kategoriale Daten konvertiert, technische Funktionen erstellt oder Hyperparameter optimiert werden, kann PyCaret all dies automatisieren. In diesem kurzen Video erfahren Sie mehr über PyCaret .Erste Schritte mit PyCaret
Die erste stabile Version von PyCaret Version 1.0.0 kann mit pip installiert werden. Verwenden Sie die Befehlszeilenschnittstelle oder die Notebook-Umgebung und führen Sie den folgenden Befehl aus, um PyCaret zu installieren.pip install pycaret
Wenn Sie Azure Notebooks oder Google Colab verwenden , führen Sie den folgenden Befehl aus:!pip install pycaret
Wenn Sie PyCaret installieren, werden alle Abhängigkeiten automatisch installiert. Sie können die Liste der Abhängigkeiten sehen hier .Einfacher geht es nicht
Exemplarische Vorgehensweise
1. DatenerfassungIn dieser exemplarischen Vorgehensweise verwenden wir einen Datensatz für Diabetiker. Unser Ziel ist es, das Ergebnis des Patienten (in binären 0 oder 1) anhand verschiedener Faktoren wie Druck, Blutinsulinspiegel, Alter usw. vorherzusagen. . Dieser Datensatz ist im PyCaret GitHub-Repository verfügbar . Der einfachste Weg, das Dataset direkt aus dem Repository zu importieren, besteht darin, die Funktion get_dataaus den Modulen zu verwenden pycaret.datasets.from pycaret.datasets import get_data
diabetes = get_data('diabetes')
 PyCaret kann direkt mit Pandas2 -Datenrahmen arbeiten . Einrichten der UmgebungJedes Experiment mit maschinellem Lernen in PyCaret beginnt mit dem Einrichten der Umgebung durch Importieren des erforderlichen Moduls und Initialisieren
PyCaret kann direkt mit Pandas2 -Datenrahmen arbeiten . Einrichten der UmgebungJedes Experiment mit maschinellem Lernen in PyCaret beginnt mit dem Einrichten der Umgebung durch Importieren des erforderlichen Moduls und Initialisieren setup(). Das Modul, das in diesem Beispiel verwendet wird, ist pycaret.classification .Nach dem Import des Moduls wird es setup()initialisiert, indem ein Datenrahmen ( 'Diabetes' ) und eine Zielvariable ( 'Klassenvariable' ) definiert werden.from pycaret.classification import *
exp1 = setup(diabetes, target = 'Class variable')
 Die gesamte Vorverarbeitung erfolgt in
Die gesamte Vorverarbeitung erfolgt in setup(). PyCaret verwendet mehr als 20 Funktionen, um Daten vor dem maschinellen Lernen vorzubereiten, und erstellt eine Pipeline von Transformationen basierend auf den in der Funktion definierten Parametern setup(). Es werden automatisch alle Abhängigkeiten in der Pipeline erstellt, sodass Sie die sequentielle Ausführung von Transformationen für einen Test oder ein neues (unsichtbares) Dataset nicht manuell steuern müssen.Die PyCaret-Pipeline kann problemlos von einer Umgebung in eine andere übertragen oder für die Produktion bereitgestellt werden. Im Folgenden können Sie sich mit den Vorverarbeitungsfunktionen vertraut machen, die seit der ersten Veröffentlichung in PyCaret verfügbar sind.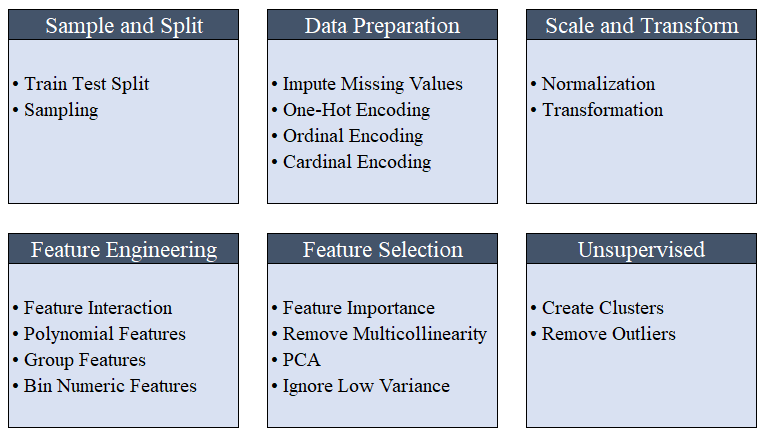 Datenvorverarbeitungsschritte sind für das maschinelle Lernen obligatorisch, z. B. das Hinzufügen fehlender Werte, das Codieren von Qualitätsvariablen, das Codieren von Etiketten (Ja oder Nein zu 1 oder 0) und das Aufteilen von Zugtests werden während der Initialisierung automatisch ausgeführt
Datenvorverarbeitungsschritte sind für das maschinelle Lernen obligatorisch, z. B. das Hinzufügen fehlender Werte, das Codieren von Qualitätsvariablen, das Codieren von Etiketten (Ja oder Nein zu 1 oder 0) und das Aufteilen von Zugtests werden während der Initialisierung automatisch ausgeführt setup(). Weitere Informationen zu Vorverarbeitungsfunktionen in PyCaret finden Sie hier .3. ModellvergleichDies ist der erste Schritt, der bei der Arbeit mit der Lehrerausbildung ( Klassifizierung oder Regression ) empfohlen wird . Diese Funktion trainiert alle Modelle in der Modellbibliothek und vergleicht den geschätzten Indikator unter Verwendung der Kreuzvalidierung für K-Blöcke (standardmäßig 10 Blöcke) miteinander. Geschätzte Indikatoren werden wie folgt verwendet:- Zur Klassifizierung: Genauigkeit, AUC, Rückruf, Präzision, F1, Kappa
- Für die Regression: MAE, MSE, RMSE, R2, RMSLE, MAPE
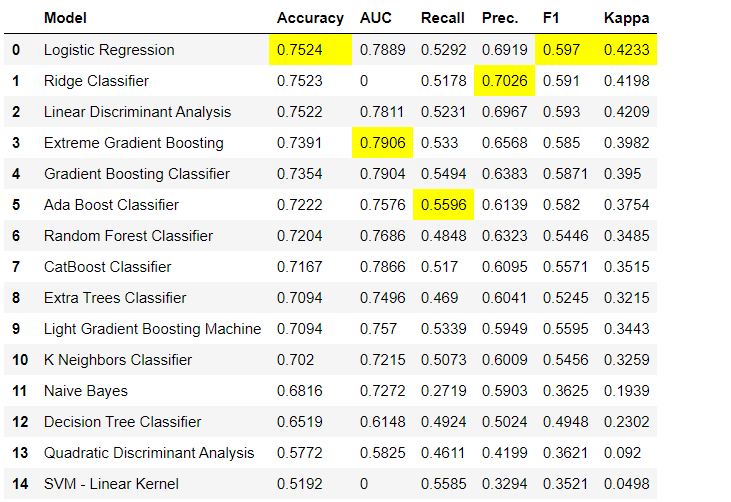 Standardmäßig werden Metriken mithilfe einer Kreuzvalidierung über 10 Blöcke ausgewertet. Die Anzahl der Blöcke kann durch Ändern des Parameters geändert werden
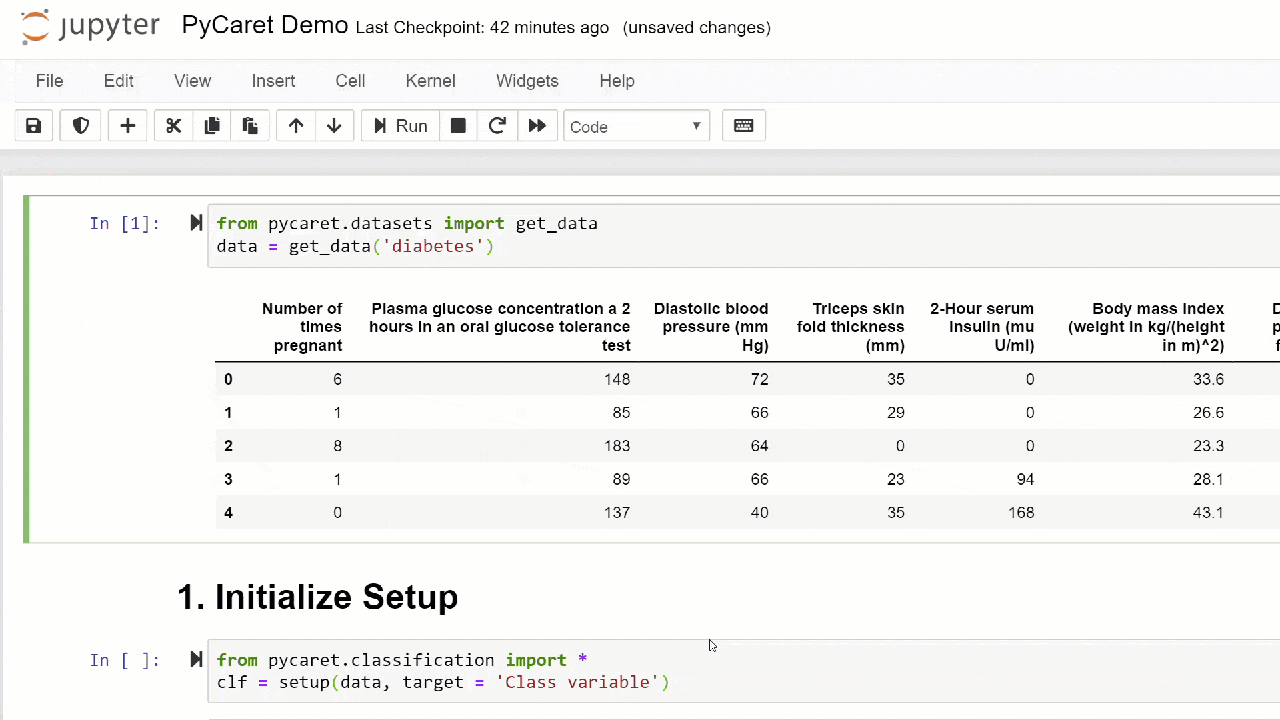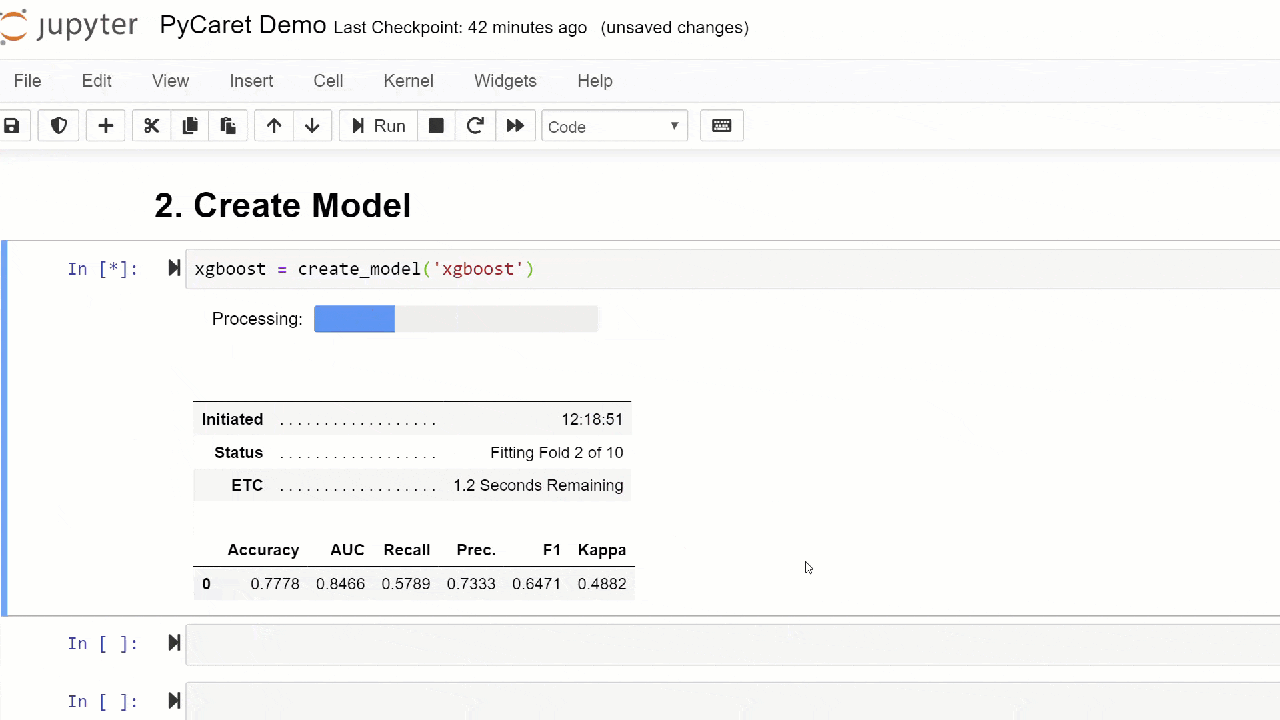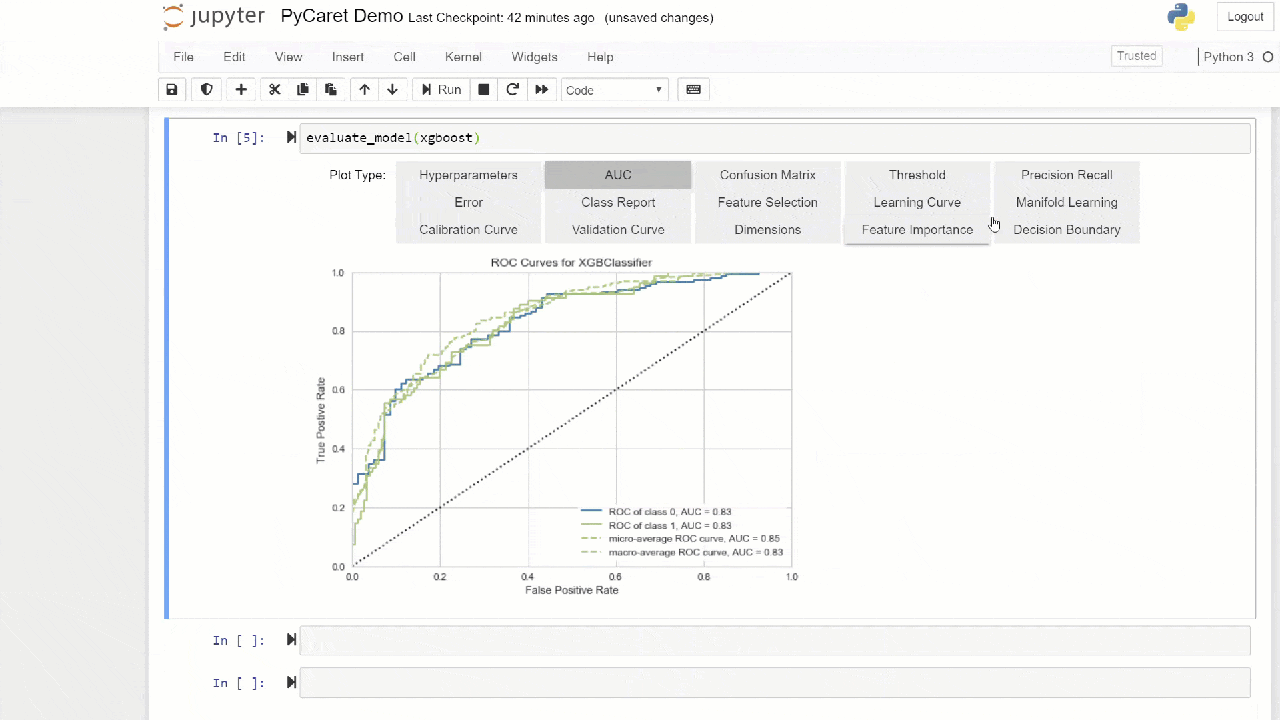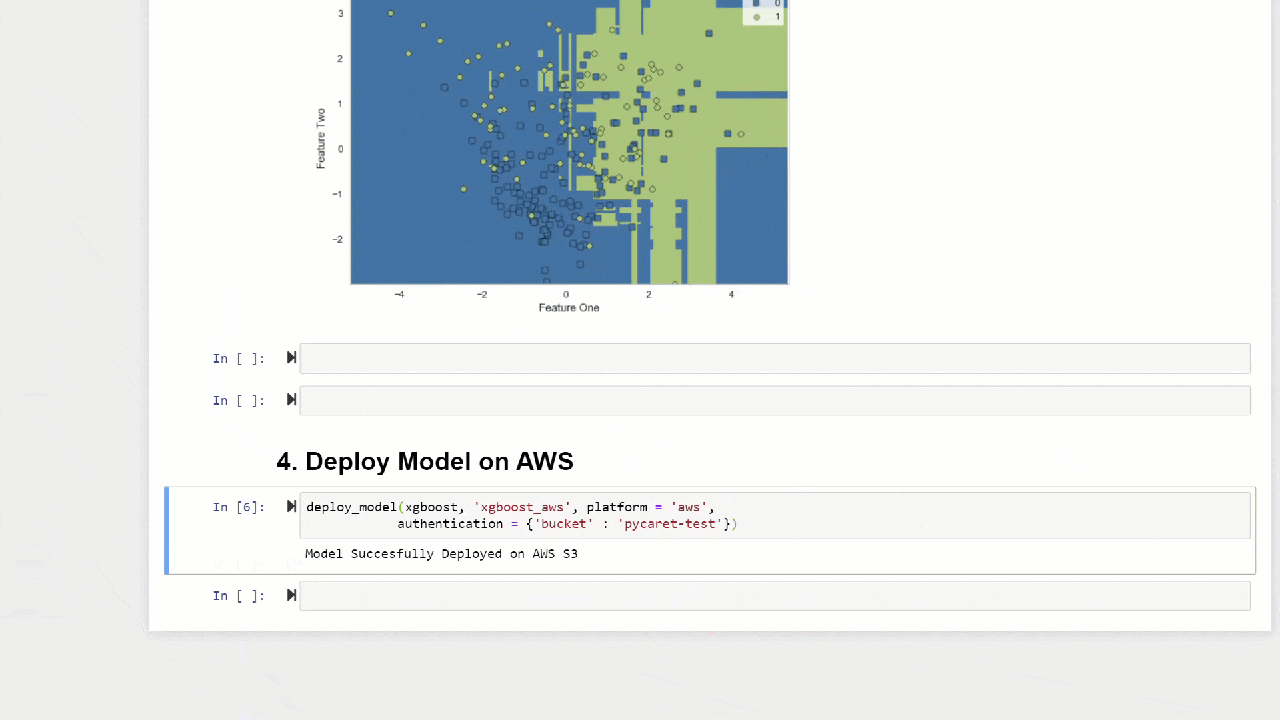
Standardmäßig werden Metriken mithilfe einer Kreuzvalidierung über 10 Blöcke ausgewertet. Die Anzahl der Blöcke kann durch Ändern des Parameters geändert werden fold.Die Standardtabelle ist nach „Genauigkeit“ vom höchsten zum niedrigsten Wert sortiert. Die Sortierreihenfolge kann auch über die Option geändert werden sort.4. Erstellen eines ModellsDas Erstellen eines Modells in einem PyCaret-Modul ist so einfach, dass Sie es nur schreiben müssen create_model. Die Funktion nimmt einen Parameter am Eingang an, d.h. Modellname als Zeichenfolge übergeben. Diese Funktion gibt eine Tabelle mit kreuzvalidierten Bewertungen und ein trainiertes Modellobjekt zurück.adaboost = create_model('ada')
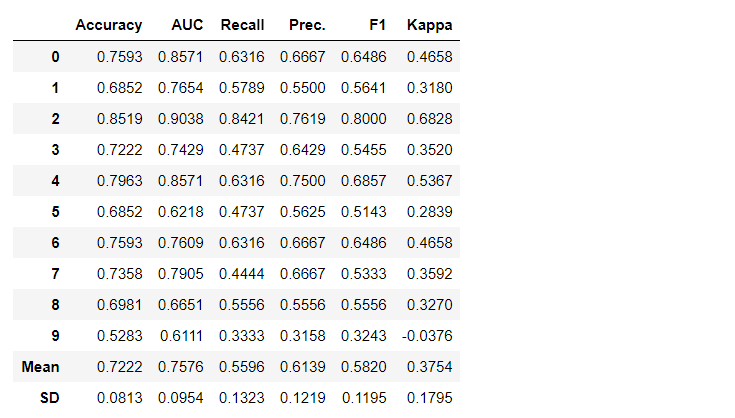 Die Variable "adaboost" speichert das Objekt des trainierten Modells, das eine Funktion zurückgibt
Die Variable "adaboost" speichert das Objekt des trainierten Modells, das eine Funktion zurückgibt create_model, die unter der Haube ein Scikit-Learn-Evaluator ist. Der Zugriff auf die Quellattribute des trainierten Objekts kann über die Funktion period ( . )nach der Variablen erfolgen. Ein Anwendungsbeispiel finden Sie unten. PyCaret verfügt über mehr als 60 gebrauchsfertige Open Source-Algorithmen. Eine vollständige Liste der in PyCaret verfügbaren Evaluatoren / Modelle finden Sie hier .5. ModelleinrichtungMit dieser Funktion werden
PyCaret verfügt über mehr als 60 gebrauchsfertige Open Source-Algorithmen. Eine vollständige Liste der in PyCaret verfügbaren Evaluatoren / Modelle finden Sie hier .5. ModelleinrichtungMit dieser Funktion werden tune_modeldie Hyperparameter des Modells für maschinelles Lernen automatisch konfiguriert. PyCaret verwendetrandom grid searchin einem bestimmten Suchraum. Die Funktion gibt eine Tabelle mit kreuzvalidierten Schätzungen und einem Objekt eines trainierten Modells zurück.tuned_adaboost = tune_model('ada')
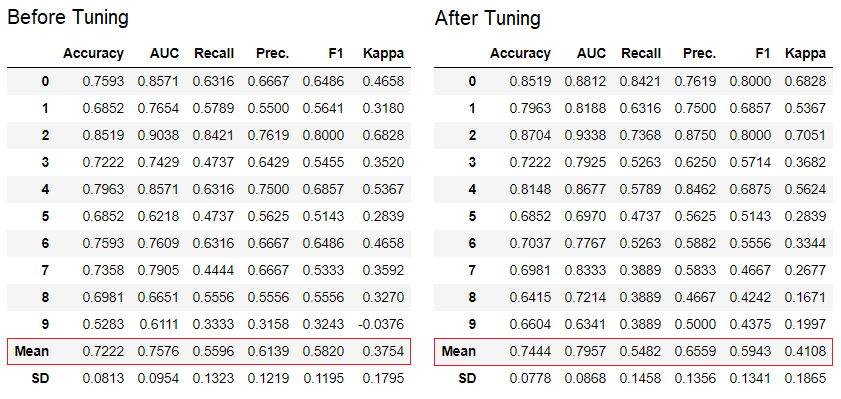 Die Funktion
Die Funktion tune_modelin Lernmodulen für Nichtlehrer wie pycaret.nlp , pycaret.clustering und pycaret.anomaly kann in Verbindung mit Lernmodulen für Lehrer verwendet werden. Beispielsweise kann das NLP-Modul in PyCaret verwendet werden, um einen Parameter anzupassen, number of topicsindem eine Zielfunktion oder eine Verlustfunktion aus einem Modell mit einem Lehrer wie „Genauigkeit“ oder „R2“ ausgewertet wird.6. Ensemble von ModellenMit dieser Funktion wird ensemble_modelein Ensemble von trainierten Modellen erstellt. Am Eingang wird ein Parameter verwendet - das Objekt des trainierten Modells. Die Funktion gibt eine Tabelle mit kreuzvalidierten Schätzungen und einem Objekt eines trainierten Modells zurück.
dt = create_model('dt')
dt_bagged = ensemble_model(dt)
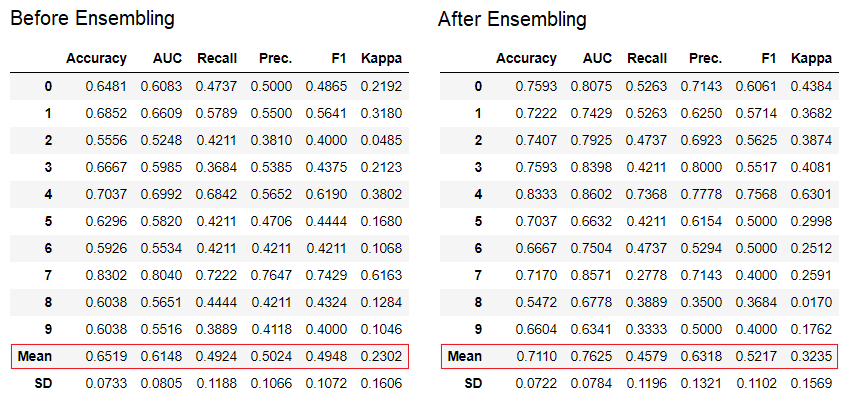 Die "Bagging" -Methode wird standardmäßig beim Erstellen des Ensembles verwendet. Sie kann mithilfe des Parameters
Die "Bagging" -Methode wird standardmäßig beim Erstellen des Ensembles verwendet. Sie kann mithilfe des Parameters methodin der Funktion in "Boosten" geändert werden ensemble_model.PyCaret bietet auch Funktionen blend_modelsund Stack_Models zum Kombinieren mehrerer trainierter Modelle.7. Modellvisualisierung:Mit der Funktion können Sie die Leistung bewerten und ein geschultes Modell für maschinelles Lernen diagnostizieren plot_model. Es nimmt das Objekt des trainierten Modells und den Diagrammtyp in Form einer Zeichenfolge auf.
adaboost = create_model('ada')
plot_model(adaboost, plot = 'auc')
plot_model(adaboost, plot = 'boundary')
plot_model(adaboost, plot = 'pr')
plot_model(adaboost, plot = 'vc')
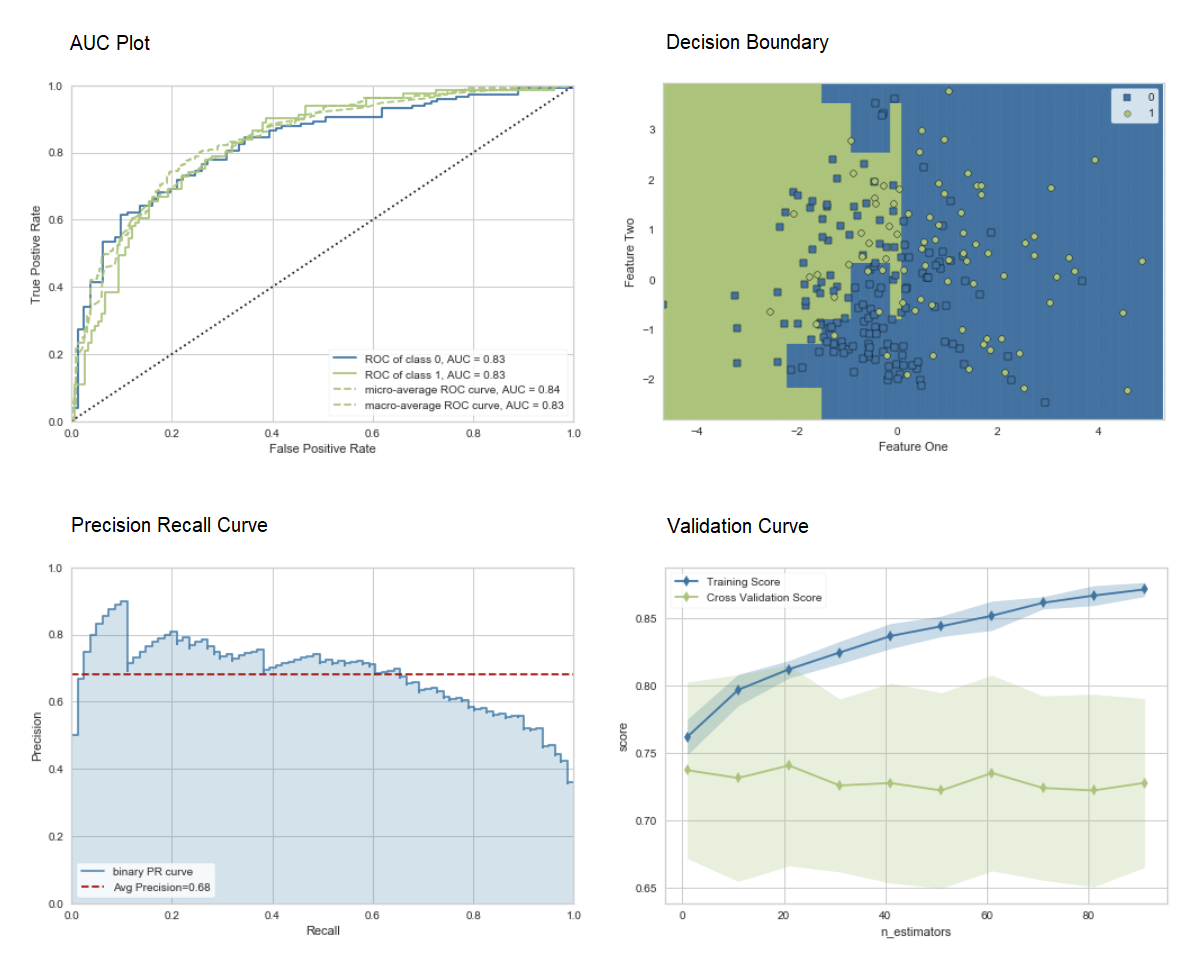 Hier erfahren Sie mehr über die Visualisierung in PyCaret.Sie können die Funktion auch verwenden
Hier erfahren Sie mehr über die Visualisierung in PyCaret.Sie können die Funktion auch verwenden evaluate_model, um Diagramme über die Notebook-Benutzeroberfläche anzuzeigen. Die Funktion
Die Funktion plot_modelim Modul pycaret.nlpkann verwendet werden, um den Textkörper und semantische thematische Modelle zu visualisieren. Hier können Sie mehr über sie erfahren.8. Interpretation des ModellsWenn die Daten nicht linear sind, was im wirklichen Leben häufig vorkommt, sehen wir immer, dass baumartige Modelle viel besser funktionieren als einfache Gaußsche Modelle. Dies ist jedoch auf einen Verlust der Interpretierbarkeit zurückzuführen, da Baummodelle keine einfachen Koeffizienten wie lineare Modelle liefern. PyCaret implementiert SHAP (SHapley Additive Erklärungen ) unter Verwendung einer Funktion interpret_model.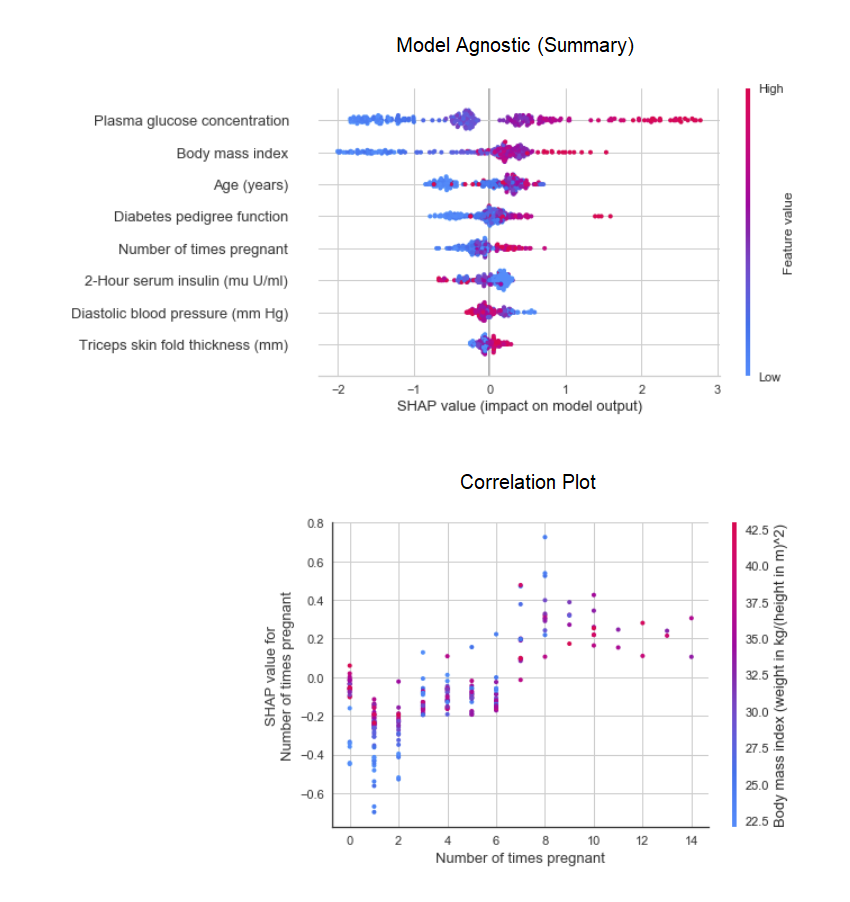 Die Interpretation eines bestimmten Datenpunkts in einem Testdatensatz kann mithilfe des Diagramms „Grund“ geschätzt werden. Im folgenden Beispiel testen wir die erste Instanz im Testdatensatz.
Die Interpretation eines bestimmten Datenpunkts in einem Testdatensatz kann mithilfe des Diagramms „Grund“ geschätzt werden. Im folgenden Beispiel testen wir die erste Instanz im Testdatensatz. 9. VorhersagemodellBis zu diesem Zeitpunkt basierten die Ergebnisse auf der Kreuzvalidierung von K-Blöcken in einem Trainingsdatensatz (standardmäßig 70%). Um die Prognosen und die Modellleistung im Test- / Hold-Out-Datensatz anzuzeigen, wird eine Funktion verwendet
9. VorhersagemodellBis zu diesem Zeitpunkt basierten die Ergebnisse auf der Kreuzvalidierung von K-Blöcken in einem Trainingsdatensatz (standardmäßig 70%). Um die Prognosen und die Modellleistung im Test- / Hold-Out-Datensatz anzuzeigen, wird eine Funktion verwendet predict_model.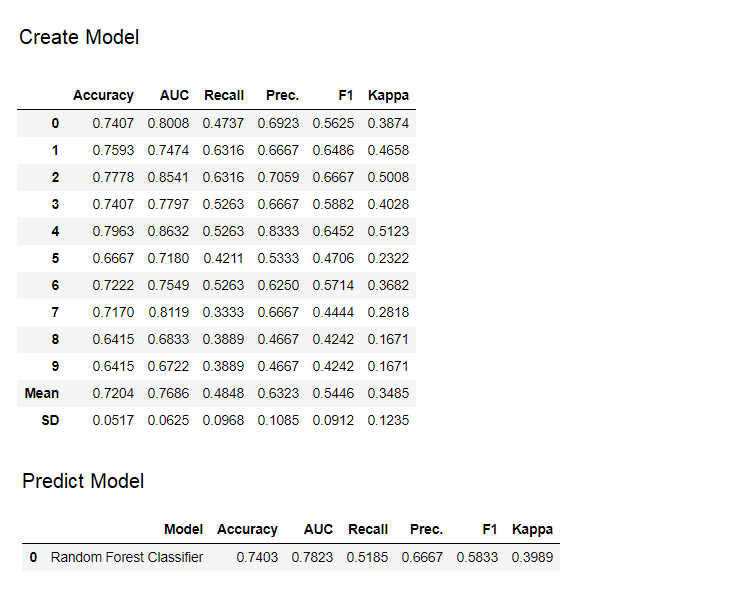 Die Funktion wird
Die Funktion wird predict_modelverwendet, um einen unsichtbaren Datensatz vorherzusagen. Jetzt verwenden wir denselben Datensatz, den wir für das Training verwendet haben, als Proxy für den neuen unsichtbaren Datensatz. In der Praxis ist die Funktionpredict_modelwird jedes Mal iterativ für einen neuen unsichtbaren Datensatz verwendet. Die Funktion
Die Funktion predict_modelkann auch Vorhersagen für eine sequentielle Kette von Modellen treffen, die mit den Funktionen stack_models und create_stacknet erstellt werden können .Die Funktion predict_modelkann mithilfe der Funktion deploy_model auch direkt Vorhersagen für auf AWS S3 gehostete Modelle treffen .10. Bereitstellen eines ModellsEine der Möglichkeiten, trainierte Modelle zum Erstellen von Prognosen für ein neues Dataset zu verwenden, besteht in der Verwendung der Funktionpredict_modelim selben Notebook / IDE, in dem das Modell trainiert wurde. Das Generieren einer Prognose für ein neues (unsichtbares) Dataset ist jedoch ein iterativer Prozess. Je nach Anwendungsfall kann die Häufigkeit der Prognosen von Echtzeitprognosen bis zu Stapelvorhersagen variieren. Mit der Funktion deploy_modelin PyCaret können Sie die gesamte Pipeline einschließlich des trainierten Modells in der Cloud aus der Notebook-Umgebung bereitstellen.deploy_model(model = rf, model_name = 'rf_aws', platform = 'aws',
authentication = {'bucket' : 'pycaret-test'})
11. Modell speichern / Experiment speichern
Nach dem Training kann die gesamte Pipeline mit allen Vorverarbeitungstransformationen und dem Objekt des trainierten Modells in einer binären Pickle-Datei gespeichert werden.
adaboost = create_model('ada')
save_model(adaboost, model_name = 'ada_for_deployment')
 Sie können auch das gesamte Experiment, das alle Zwischenausgaben enthält, als einzelne Binärdatei speichern.save_experiment (EXPERIMENT_NAME = ‚my_first_experiment‘)
Sie können auch das gesamte Experiment, das alle Zwischenausgaben enthält, als einzelne Binärdatei speichern.save_experiment (EXPERIMENT_NAME = ‚my_first_experiment‘) mit den Funktionen Sie können gespeicherte Modelle und Experimente laden
mit den Funktionen Sie können gespeicherte Modelle und Experimente laden load_modelund die load_experimentvon allen PyCaret Modulen.12. Nächstes HandbuchIm nächsten Handbuch wird gezeigt, wie das trainierte Modell für maschinelles Lernen in Power BI verwendet wird, um Stapelvorhersagen in einer realen Produktionsumgebung zu generieren.In den folgenden Modulen können Sie auch Notizblöcke für Anfänger lesen:Was ist eine Entwicklungspipeline?
Wir arbeiten aktiv an der Verbesserung von PyCaret. Unsere bevorstehende Entwicklungspipeline umfasst ein neues Zeitreihen-Prognosemodul, die TensorFlow-Integration und wichtige Verbesserungen der PyCaret-Skalierbarkeit. Wenn Sie Ihr Feedback teilen und uns bei der Verbesserung helfen möchten, können Sie ein Formular auf der Website ausfüllen oder einen Kommentar auf unserer Seite auf GitHub oder LinkedIn hinterlassen .Möchten Sie mehr über ein bestimmtes Modul erfahren?
Ab der ersten Version stehen in PyCaret 1.0.0 die folgenden Module zur Verfügung. Folgen Sie den nachstehenden Links, um sich mit der Dokumentation und den Arbeitsbeispielen vertraut zu machen.KlassifizierungRegressionClusteringAnomaly SucheNatürliche Text Processing (NLP)Assoziative Regeln AusbildungWichtige Links
Wenn Ihnen PyCaret gefallen hat, setzen Sie uns ️ auf GitHub.Um mehr über PyCaret zu erfahren, können Sie uns auf LinkedIn und Youtube folgen .
Erfahren Sie mehr über den Kurs.