Die Übersetzung des Artikels wurde speziell für Studierende des Kurses „Datenbanken“ erstellt .
Was Sie möglicherweise nicht über die Generierung von Sysbench-Zufallszahlengewusst haben Sysbench ist ein beliebtes Tool zum Testen der Leistung. Es wurde ursprünglich von Peter Zaitsev in den frühen 2000er Jahren geschrieben und wurde zum De-facto-Standard für Tests und Benchmarking. Es wird derzeit von Alexei Kopytov unterstützt und ist auf Github unter veröffentlicht .Ich bemerkte jedoch, dass es trotz seiner breiten Verbreitung Momente gibt, die vielen in sysbench unbekannt sind. Zum Beispiel die Möglichkeit, MySQL-Tests einfach mit Lua zu ändern oder die Parameter des eingebauten Zufallszahlengenerators zu konfigurieren.Wovon handelt der Artikel?
Ich habe diesen Artikel geschrieben, um zu zeigen, wie einfach es ist, sysbench an Ihre Anforderungen anzupassen. Es gibt viele Möglichkeiten, die Funktionalität von sysbench zu erweitern. Eine davon besteht darin, die Generierung von Zufallskennungen (IDs) zu konfigurieren.Standardmäßig bietet sysbench fünf verschiedene Optionen zum Generieren von Zufallszahlen. Aber sehr oft (in der Tat fast nie) wird keiner von ihnen explizit angegeben, und noch seltener können Sie die Generierungsparameter sehen (für Optionen, bei denen sie verfügbar sind).Wenn Sie eine Frage haben: „Und warum sollte mich das interessieren? Schließlich sind die Standardwerte durchaus geeignet. “Dieser Beitrag soll Ihnen helfen, zu verstehen, warum dies nicht immer der Fall ist.Lasst uns beginnen
Wie können Zufallszahlen in sysbench generiert werden? Folgendes ist derzeit implementiert (Sie können sie leicht über die Option --help anzeigen):- Spezial (Sonderverteilung)
- Gaußsche (Gaußsche Verteilung)
- Pareto (Pareto-Verteilung)
- Zipfian (Zipf-Verteilung)
- Gleichförmig (gleichmäßige Verteilung)
Standardmäßig wird Special mit den folgenden Parametern verwendet:rand-spec-iter = 12 - Anzahl der Iterationen für eine spezielle Verteilungrand-spec-pct = 1 - Prozentsatz des gesamten Bereichs, in den „spezielle“ Werte mit einer speziellen Verteilung fallenrand-spec-res = 75 - Prozentsatz der „speziellen“ Werte zur Verwendung in einer speziellen Verteilung
Da ich einfache und leicht zu reproduzierende Tests und Skripte mag, werden alle nachfolgenden Daten mit den folgenden sysbench-Befehlen gesammelt:- sysbench ./src/lua/oltp_read.lua -mysql_storage_engine = innodb –db-driver = mysql –tables = 10 –table_size = 100 vorbereiten
- sysbench ./src/lua/oltp_read_write.lua –db-driver=mysql –tables=10 –table_size=100 –skip_trx=off –report-interval=1 –mysql-ignore-errors=all –mysql_storage_engine=innodb –auto_inc=on –histogram –stats_format=csv –db-ps-mode=disable –threads=10 –time=60 –rand-type=XXX run
Fühlen Sie sich frei, selbst zu experimentieren. Die Skriptbeschreibung und Daten finden Sie hier .Warum verwendet sysbench einen Zufallszahlengenerator? Einer der Zwecke besteht darin, IDs zu generieren, die in Abfragen verwendet werden. In unserem Beispiel werden also Zahlen zwischen 1 und 100 generiert, wobei die Erstellung von 10 Tabellen mit jeweils 100 Zeilen berücksichtigt wird.Was ist, wenn Sie sysbench wie oben beschrieben ausführen und nur -rand-type ändern?Ich habe dieses Skript ausgeführt und das allgemeine Protokoll verwendet, um die Häufigkeit der generierten ID-Werte zu erfassen und zu analysieren. Hier ist das Ergebnis:Spezielle Uniform
Uniform Zipfian
Zipfian Pareto
Pareto Gaussian
Gaussian Es ist zu sehen, dass dieser Parameter wichtig ist, oder? Schließlich macht sysbench genau das, was wir von ihm erwartet haben.Schauen wir uns die einzelnen Distributionen genauer an.
Es ist zu sehen, dass dieser Parameter wichtig ist, oder? Schließlich macht sysbench genau das, was wir von ihm erwartet haben.Schauen wir uns die einzelnen Distributionen genauer an.Besondere
Special wird standardmäßig verwendet. Wenn Sie also NICHT den Rand-Typ angeben, verwendet sysbench special. Special verwendet eine sehr begrenzte Anzahl von ID-Werten. In unserem Beispiel können wir sehen, dass die Werte 50-51 hauptsächlich verwendet werden, die verbleibenden Werte zwischen 44-56 sind äußerst selten, während andere praktisch nicht verwendet werden. Bitte beachten Sie, dass die ausgewählten Werte in der Mitte des verfügbaren Bereichs von 1 bis 100 liegen.In diesem Fall beträgt der Peak ungefähr zwei IDs, die 2% der Probe darstellen. Wenn ich die Anzahl der Datensätze auf eine Million erhöhe, bleibt der Peak bestehen, liegt jedoch bei 7493, was 0,74% der Stichprobe entspricht. Da dies restriktiver sein wird, ist es wahrscheinlich, dass die Anzahl der Seiten mehr als eins beträgt.Gleichförmig (gleichmäßige Verteilung)
Wie der Name schon sagt, wenn wir Uniform verwenden, werden alle Werte für die ID verwendet und die Verteilung wird ... einheitlich sein.Zipfian (Zipf-Verteilung)
Die Zipf-Verteilung, manchmal auch als Zeta-Verteilung bezeichnet, ist eine diskrete Verteilung, die üblicherweise in der Linguistik, Versicherung und Modellierung seltener Ereignisse verwendet wird. In diesem Fall verwendet sysbench Zahlen, die mit der kleinsten (1) beginnen, und reduziert sehr schnell die Verwendungshäufigkeit, wobei größere Zahlen verwendet werden.Pareto (Pareto)
Pareto wendet die Regel „80-20“ an . In diesem Fall werden die generierten IDs noch weniger verschmiert und konzentrieren sich mehr auf ein kleines Segment. In unserem Beispiel hatten 52% aller IDs den Wert 1 und 73% der Werte befanden sich in den ersten 10 Zahlen.Gaußsche (Gaußsche Verteilung)
Die Gaußsche Verteilung (Normalverteilung) ist bekannt und bekannt . Es wird hauptsächlich in der Statistik und Prognose um einen zentralen Faktor verwendet. In diesem Fall werden die verwendeten IDs entlang der glockenförmigen Kurve verteilt, beginnend mit dem Durchschnittswert und langsam bis zu den Kanten abnehmend.Was ist der Sinn davon?
Jede der oben genannten Optionen hat ihre eigene Verwendung und kann nach Zweck gruppiert werden. Pareto und Special konzentrieren sich auf Hot Spots. In diesem Fall verwendet die Anwendung immer wieder dieselbe Seite / dieselben Daten. Das mögen wir brauchen, aber wir müssen verstehen, was wir tun und dürfen hier keine Fehler machen.Wenn wir beispielsweise die Leistung der InnoDB-Seitenkomprimierung beim Lesen testen, sollten Sie vermeiden, den Standardwert Special oder Pareto zu verwenden. Wenn wir einen 1-TB-Datensatz und einen 30-GB-Pufferpool haben und dieselbe Seite mehrmals anfordern, wird diese Seite bereits von der Festplatte gelesen und ist unkomprimiert im Speicher verfügbar.Kurz gesagt, ein solcher Test ist eine Verschwendung von Zeit und Mühe.Das Gleiche gilt, wenn wir die Leistung der Aufnahme überprüfen müssen. Immer wieder dieselbe Seite zu schreiben, ist nicht die beste Option.Wie wäre es mit Leistungstests?Auch hier möchten wir die Leistung testen, aber für welchen Fall? Es ist wichtig zu verstehen, dass die Methode zur Erzeugung von Zufallszahlen die Testergebnisse stark beeinflusst. Und Ihre „guten Standardeinstellungen“ können zu falschen Schlussfolgerungen führen.Die folgenden Grafiken zeigen je nach Rand-Typ unterschiedliche Latenzen (Testtyp, Zeit, zusätzliche Parameter und Anzahl der Threads sind überall gleich).Von Typ zu Typ sind die Verzögerungen erheblich unterschiedlich: Hier habe ich gelesen und geschrieben, und die Daten wurden aus dem Leistungsschema (
Hier habe ich gelesen und geschrieben, und die Daten wurden aus dem Leistungsschema (sys.schema_table_statistics) Wie erwartet dauern Pareto und Special viel länger als andere, was dazu führt, dass das System (MySQL-InnoDB) an einem „Hot Spot“ künstlich unter der Konkurrenz leidet.Das Ändern des Rand-Typs wirkt sich nicht nur auf die Verzögerung aus, sondern auch auf die Anzahl der verarbeiteten Zeilen, wie im Leistungsschema angegeben.
 In Anbetracht all dieser Punkte ist es wichtig zu verstehen, was wir zu bewerten und zu testen versuchen.Wenn mein Ziel darin besteht, die Systemleistung auf allen Ebenen zu testen, bevorzuge ich möglicherweise die Verwendung von Uniform, das den Datensatz / Datenbankserver / das System gleichermaßen lädt und das Lesen / Laden / Schreiben mit größerer Wahrscheinlichkeit gleichmäßig verteilt.Wenn es meine Aufgabe ist, mit Hot Spots zu arbeiten, sind Pareto und Special wahrscheinlich die richtige Wahl.Verwenden Sie die Standardwerte jedoch nicht blind. Sie mögen zu Ihnen passen, sind aber oft für extreme Fälle gedacht. Nach meiner Erfahrung können Sie die Einstellungen häufig anpassen, um das gewünschte Ergebnis zu erzielen.Sie möchten beispielsweise die Werte in der Mitte verwenden, indem Sie das Intervall so erweitern, dass keine scharfe Spitze (standardmäßig Spezial) oder Glocke (Gauß) angezeigt wird.Sie können Special so konfigurieren, dass etwa Folgendes angezeigt wird:
In Anbetracht all dieser Punkte ist es wichtig zu verstehen, was wir zu bewerten und zu testen versuchen.Wenn mein Ziel darin besteht, die Systemleistung auf allen Ebenen zu testen, bevorzuge ich möglicherweise die Verwendung von Uniform, das den Datensatz / Datenbankserver / das System gleichermaßen lädt und das Lesen / Laden / Schreiben mit größerer Wahrscheinlichkeit gleichmäßig verteilt.Wenn es meine Aufgabe ist, mit Hot Spots zu arbeiten, sind Pareto und Special wahrscheinlich die richtige Wahl.Verwenden Sie die Standardwerte jedoch nicht blind. Sie mögen zu Ihnen passen, sind aber oft für extreme Fälle gedacht. Nach meiner Erfahrung können Sie die Einstellungen häufig anpassen, um das gewünschte Ergebnis zu erzielen.Sie möchten beispielsweise die Werte in der Mitte verwenden, indem Sie das Intervall so erweitern, dass keine scharfe Spitze (standardmäßig Spezial) oder Glocke (Gauß) angezeigt wird.Sie können Special so konfigurieren, dass etwa Folgendes angezeigt wird: In diesem Fall befinden sich die IDs noch in der Nähe, und es besteht Konkurrenz. Der Einfluss eines „Hot Spots“ ist jedoch geringer. Daher können jetzt Konflikte mit mehreren IDs auftreten, die sich je nach Anzahl der Datensätze auf einer Seite auf mehreren Seiten befinden können.Ein weiteres Beispiel ist die Partitionierung. Wie können Sie beispielsweise überprüfen, wie Ihr System mit Partitionen arbeitet, sich auf die neuesten Daten konzentrieren und die alten archivieren?Einfach! Erinnern Sie sich an das Pareto-Verteilungsdiagramm? Sie können es nach Ihren Wünschen ändern.
In diesem Fall befinden sich die IDs noch in der Nähe, und es besteht Konkurrenz. Der Einfluss eines „Hot Spots“ ist jedoch geringer. Daher können jetzt Konflikte mit mehreren IDs auftreten, die sich je nach Anzahl der Datensätze auf einer Seite auf mehreren Seiten befinden können.Ein weiteres Beispiel ist die Partitionierung. Wie können Sie beispielsweise überprüfen, wie Ihr System mit Partitionen arbeitet, sich auf die neuesten Daten konzentrieren und die alten archivieren?Einfach! Erinnern Sie sich an das Pareto-Verteilungsdiagramm? Sie können es nach Ihren Wünschen ändern. Durch Angabe des -rand-pareto-Werts können Sie genau das erreichen, was Sie möchten, indem Sie sysbench zwingen, sich auf große ID-Werte zu konzentrieren.Zipfian kann auch eingerichtet werden, und obwohl Sie keine Inversion erhalten können, wie dies bei Pareto der Fall ist, können Sie leicht von einem Peak auf einem Wert zu einer gleichmäßigeren Verteilung wechseln. Ein gutes Beispiel ist das Folgende:
Durch Angabe des -rand-pareto-Werts können Sie genau das erreichen, was Sie möchten, indem Sie sysbench zwingen, sich auf große ID-Werte zu konzentrieren.Zipfian kann auch eingerichtet werden, und obwohl Sie keine Inversion erhalten können, wie dies bei Pareto der Fall ist, können Sie leicht von einem Peak auf einem Wert zu einer gleichmäßigeren Verteilung wechseln. Ein gutes Beispiel ist das Folgende: Das Letzte, was Sie beachten sollten, und es scheint mir, dass dies offensichtliche Dinge sind, aber es ist besser zu sagen, als nicht zu sagen, dass sich die Leistung ändert, wenn Sie die Parameter für die Zufallszahlengenerierung ändern.Latenz vergleichen:
Das Letzte, was Sie beachten sollten, und es scheint mir, dass dies offensichtliche Dinge sind, aber es ist besser zu sagen, als nicht zu sagen, dass sich die Leistung ändert, wenn Sie die Parameter für die Zufallszahlengenerierung ändern.Latenz vergleichen: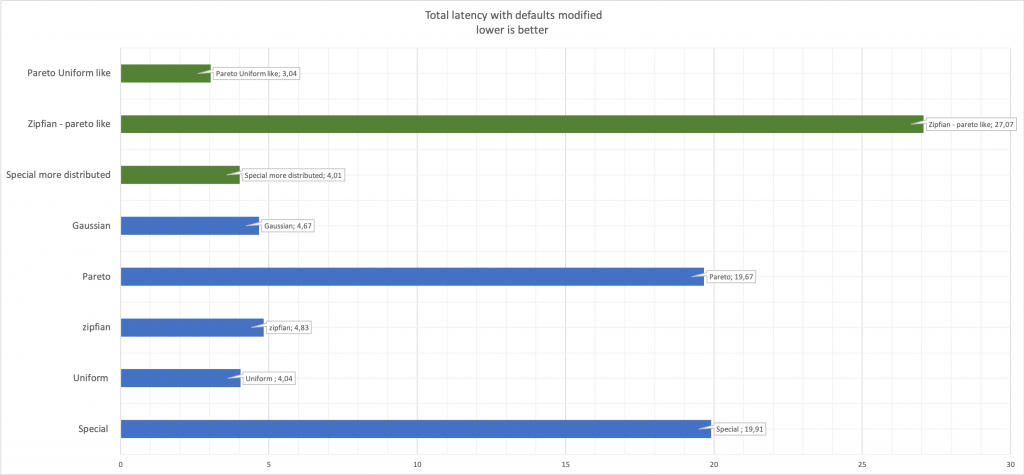 Hier zeigt Grün die geänderten Werte im Vergleich zum ursprünglichen Blau.
Hier zeigt Grün die geänderten Werte im Vergleich zum ursprünglichen Blau.
Ergebnisse
Zu diesem Zeitpunkt sollten Sie bereits verstehen, wie einfach es ist, die Zufallszahlengenerierung in sysbench einzurichten, und wie nützlich dies für Sie sein kann. Beachten Sie, dass das oben Gesagte für alle Anrufe gilt, z. B sysbench.rand.default.:local function get_id()
return sysbench.rand.default(1, sysbench.opt.table_size)
End
Kopieren Sie vor diesem Hintergrund nicht sinnlos den Code aus den Artikeln anderer Personen, sondern überlegen Sie, was Sie benötigen und wie Sie dies erreichen können.Überprüfen Sie vor dem Ausführen der Tests die Optionen zur Generierung von Zufallszahlen, um sicherzustellen, dass sie Ihren Anforderungen entsprechen. Um mein Leben zu vereinfachen, benutze ich diesen einfachen Test . Dieser Test zeigt ziemlich klare Informationen zur ID-Verteilung an.Mein Rat ist, dass Sie Ihre Bedürfnisse verstehen und Tests / Benchmarking korrekt durchführen sollten.Verweise
Zuallererst ist dies sysbench selbst .Artikel über Zipfian:Pareto:Perconas Artikel zum Schreiben Ihrer Skripte in sysbenchAlle für diesen Artikel verwendeten Materialien befinden sich auf GitHub .
→ Erfahren Sie mehr über den Kurs