In modernen x86 Intel-Prozessoren kann die Pipeline in zwei Teile unterteilt werden: Front-End und Back-End.Das Front-End ist dafür verantwortlich, Code aus dem Speicher zu laden und in Mikrooperationen zu dekodieren.Das Back-End ist für die Durchführung von Mikrooperationen vom Front-End aus verantwortlich. Da diese Mikrooperationen vom Kernel außerhalb der Reihenfolge ausgeführt werden können, stellt das Back-End auch sicher, dass das Ergebnis dieser Mikrooperationen genau der Reihenfolge entspricht, in der sie im Code enthalten sind.In den meisten Fällen wirkt sich eine ineffiziente Verwendung von Front End'a nicht spürbar auf die Leistung aus. Die maximale Bandbreite auf den meisten Intel-Prozessoren beträgt 4 Mikrooperationen pro Zyklus. Daher kann die CPU beispielsweise einen speicher- / L3-gebundenen Code nicht vollständig nutzen.Pro relativ neuer Ice Lake, Ice Lake 4 5 . , , .
In einigen Fällen kann der Leistungsunterschied jedoch erheblich sein. Unter dem Schnitt befindet sich eine Analyse der Auswirkungen des Mikrooperations-Cache auf die Leistung.Der Inhalt des Artikels
- Umgebung
- Übersicht über Front End'a Intel-Prozessoren
- Spitzenbandbreitenanalyse µop-Cache -> IDQ
- Beispiel
Umgebung
Für alle Messungen in diesem Artikel wird i7-8550U Kaby LakeHT aktiviert / verwendet Ubuntu 18.04/Linux Kernel 5.3.0-45-generic. In diesem Fall kann eine solche Umgebung von Bedeutung sein, weil Jedes CPU-Modell hat ein eigenes Leistungsereignis. Insbesondere für Mikroarchitekturen, die älter als Sandy Bridge sind, sind einige der in Zukunft verwendeten Ereignisse einfach nicht sinnvoll.Übersicht über Front End'a Intel-Prozessoren
Die übergeordnete Fließbandorganisation ist öffentlich verfügbar und wird in der offiziellen Dokumentation von Intel zur Softwareoptimierung veröffentlicht . Eine detailliertere Beschreibung einiger Funktionen, die in der offiziellen Dokumentation nicht aufgeführt sind, finden Sie in anderen seriösen Quellen wie Agner Fog oder Travis Downs . So sieht beispielsweise das Assembly-Pipeline-Schema für Skylake in der Intel-Dokumentation folgendermaßen aus: Schauen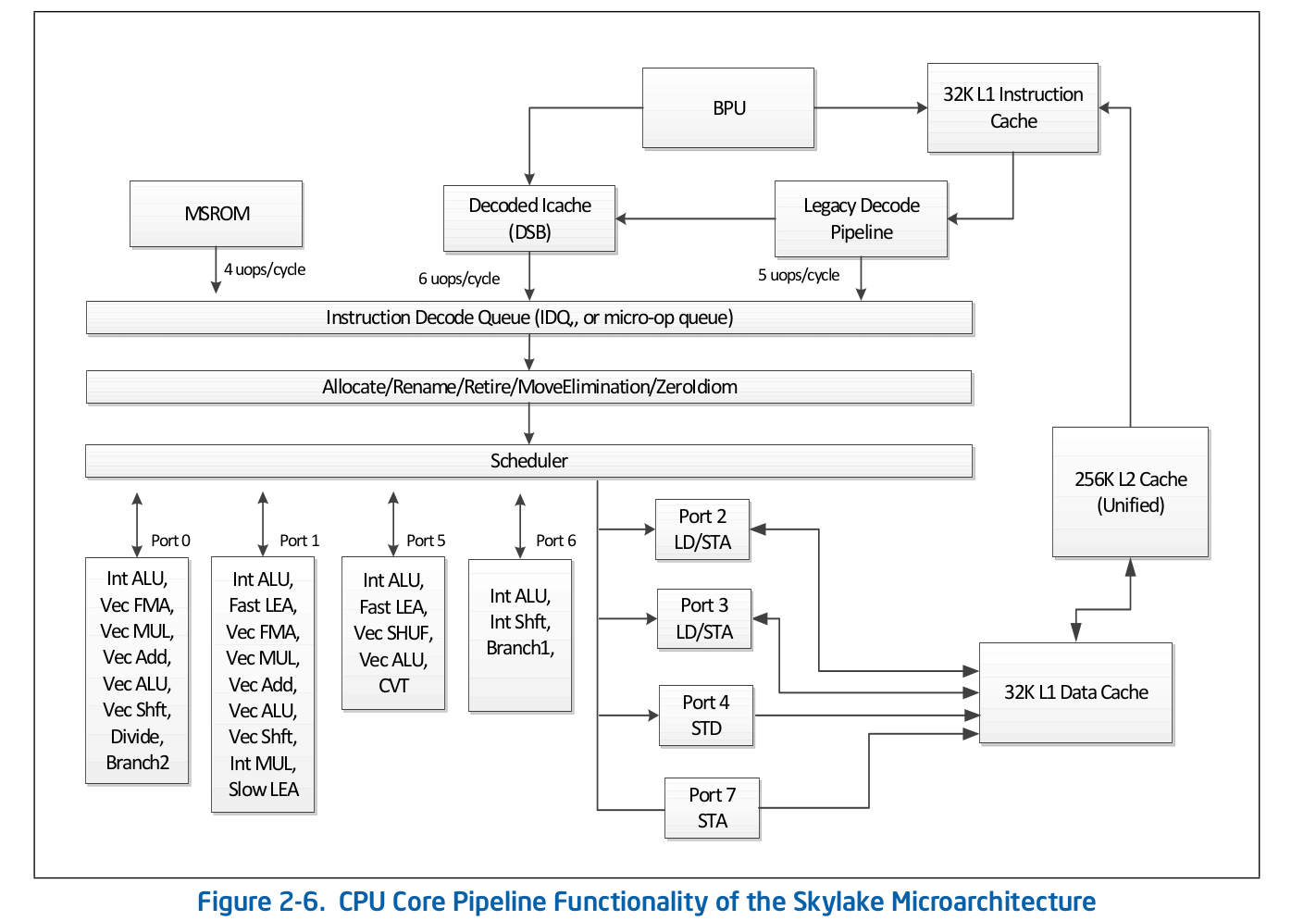 wir uns den Anfang dieses Schemas genauer an - das Front-End.
wir uns den Anfang dieses Schemas genauer an - das Front-End. Die Legacy Decode Pipeline ist für die Dekodierung des Codes in Mikrooperationen verantwortlich. Es besteht aus folgenden Komponenten:
Die Legacy Decode Pipeline ist für die Dekodierung des Codes in Mikrooperationen verantwortlich. Es besteht aus folgenden Komponenten:- Instruction Fetch Unit - IFU
- First Level Instructions Cache - L1i
- Adresscache für die Übersetzung von Anweisungsprotokollen - ITLB
- Instructor Prefector
- Pre-Decoder-Anweisungen
- Warteschlange vordecodierter Anweisungen
- Vordecodierte Befehlsdecoder für die Mikrooperation
Betrachten Sie jeden Teil der Legacy Decode-Pipeline einzeln.Instruction Fetch Unit.Er ist verantwortlich für das Laden des Codes, das Vorcodieren (Bestimmen der Länge des Befehls und der Eigenschaften, z. B. "ob der Befehl ein Zweig ist") und das Bereitstellen vordecodierter Befehle an die Warteschlange.First Level Instructions Cache - L1iZum Herunterladen des Codes verwendet die IFU L1i, den Anweisungscache der ersten Ebene, und L2 / LLC, den Cache der zweiten Ebene und den Offcore-Cache der obersten Ebene, die Code und Daten gemeinsam haben. Der Download erfolgt in Teilen von 16 Bytes, die ebenfalls auf 16 Bytes ausgerichtet sind. Wenn der nächste 16-Byte-Code der Reihe nach geladen wird, wird L1i aufgerufen, und wenn die entsprechende Zeile nicht gefunden wird, wird eine Suche in L2 und im Fehlerfall in LLC und Speicher durchgeführt. Vor Skylake LLC war der Cache inklusive - jede Zeile in L1 (i / d) und L2 sollte in der LLC enthalten sein. Somit "wusste" LLC über alle Leitungen in allen Kernen Bescheid und im Fall von LLC-Fehlern war bekannt, ob die Caches in anderen Kernen die erforderliche Zeile im modifizierten Zustand enthielten, was bedeutet, dass diese Leitung von einem anderen Kern geladen werden konnte. Skylake LLC wurde zu einem nicht inklusive L2-Opfer-Cache, aber die L2-Größe wurde viermal erhöht. Ich weiß es nichtob L2 in Bezug auf L1i inklusive ist. L2nicht inklusive in Bezug auf L1d.Übersetzung logischer Adressadressen - ITLBBevor Sie Daten aus dem Cache herunterladen, müssen Sie nach der entsprechenden Zeile suchen. Bei nassoziativen Zwischencaches kann sich jede Zeile an nverschiedenen Stellen im Cache selbst befinden. Um die möglichen Positionen im Cache zu bestimmen, wird ein Index verwendet (normalerweise einige niedrigere Bits der Adresse). Um festzustellen, ob die Zeile mit der von uns benötigten Adresse übereinstimmt, wird ein Tag verwendet (der Rest der Adresse). Welche Adressen verwendet werden sollen: physisch oder logisch - hängt von der Cache-Implementierung ab. Die Verwendung physischer Adressen erfordert eine Adressübersetzung. Für die Adressumsetzung wird ein TLB-Puffer verwendet, der die Ergebnisse von Seitenläufen zwischenspeichert, wodurch die Verzögerung beim Empfang einer physischen Adresse von einer logischen Adresse bei nachfolgenden Aufrufen verringert wird. Für Anweisungen gibt es einen eigenen Anweisungs-TLB-Puffer, der sich getrennt vom Daten-TLB befindet. Der CPU-Kern verfügt außerdem über einen TLB der zweiten Ebene, der Code und Daten gemeinsam ist - STLB. Ob STLB inklusive ist, ist mir unbekannt (es wird gemunkelt, dass es sich nicht um einen inklusive Opfer-Cache im Vergleich zu D / I TLB handelt). Verwenden von Software-Prefetch-Anweisungenprefetcht1Sie können die Zeile mit dem Code in L2 aufrufen, der entsprechende TLB-Datensatz wird jedoch nur in DTLB aufgerufen. Wenn STLB nicht inklusive ist, erhalten Sie bei der Suche nach dieser Zeile mit dem Code in den Caches ITLB-Fehler -> STLB-Fehler -> Seitenlauf (tatsächlich ist dies nicht so einfach, da der Kernel einen spekulativen Seitenlauf initiieren kann , bevor dies geschieht TLB Miss). Die Intel-Dokumentation rät auch von der Verwendung von SW-Prefetches für Code ab. Intel Software Optimization Manual / 2.5.5.4:Der softwaregesteuerte Prefetch dient zum Prefetching von Daten, nicht jedoch zum Prefetching von Code.
Travis D. erwähnte jedoch, dass ein solcher Prefetch sehr effektiv sein kann (und höchstwahrscheinlich auch), aber dies ist mir bisher nicht klar, und um davon überzeugt zu sein, muss ich dieses Problem separat untersuchen.Instructor PrefectorDas Laden von Daten in den Cache (L1d / i, L2 usw.) erfolgt beim Zugriff auf einen nicht zwischengespeicherten Speicherort. Wenn dies jedoch nur unter solchen Bedingungen geschehen würde, würden wir als Ergebnis eine ineffiziente Nutzung der Cache-Bandbreite erhalten. Zum Beispiel auf Sandy Bridge für L1d - 2 Leseoperationen, 1 Schreibvorgang 16 Bytes pro Zyklus; Für den L1i-1-Lesevorgang mit 16 Bytes ist der Schreibdurchsatz in der Dokumentation nicht angegeben. Agner Fog wurde ebenfalls nicht gefunden. Um dieses Problem zu lösen, gibt es Hardware-Prefetchers, die das Muster des Zugriffs auf den Speicher bestimmen und die erforderlichen Zeilen in den Cache ziehen können, bevor der Code sie tatsächlich adressiert. Die Intel-Dokumentation definiert 4 Prefetchers: 2 für L1d, 2 für L2:- L1 DCU - Serielle Cache-Zeilen mit Präfix. Schreibgeschützt weiterleiten
- L1 IP — (. 0x5555555545a0, 0x5555555545b0, 0x5555555545c0, ...), , ,
- L2 Spatial — L2 -, 128-. LLC
- L2 Streamer — . L1 DCU «». LLC
Die Intel-Dokumentation beschreibt nicht das Prinzip des L1i-Präfektors. Es ist lediglich bekannt, dass die Branch Prediction Unit (BPU) an diesem Prozess beteiligt ist. Intel Software Optimization Manual / 2.6.2: Agner Fog sieht ebenfalls keine Details.Das Code-Prefetching in L2 / LLC ist explizit nur für Streamer definiert. Optimierungshandbuch / 2.5.5.4 Datenpräfektion:
Agner Fog sieht ebenfalls keine Details.Das Code-Prefetching in L2 / LLC ist explizit nur für Streamer definiert. Optimierungshandbuch / 2.5.5.4 Datenpräfektion:Streamer : Dieser Prefetcher überwacht Leseanforderungen aus dem L1-Cache auf aufsteigende und absteigende Folgen von Adressen. Zu den überwachten Leseanforderungen gehören L1-DCache-Anforderungen, die durch Lade- und Speicheroperationen sowie durch die Hardware-Prefetchers initiiert wurden, sowie L1-ICache-Anforderungen für das Abrufen von Code.
Für den Spatial Prefetcher ist dies eindeutig nicht klargestellt:Spatial Prefetcher: Dieser Prefetcher versucht, jede in den L2-Cache abgerufene Cache-Zeile mit der Paarzeile zu vervollständigen, die ihn zu einem 128-Byte-ausgerichteten Block vervollständigt.
Dies kann jedoch überprüft werden. Jeder dieser Prefetchers kann mithilfe von deaktiviert werden MSR 0x1A4, wie im Handbuch Modellspezifische Register beschrieben.Über MSR 0x1A4MSR L2 Spatial L1i. . , LLC. L2 Streamer 2.5 .
Linux msr , msr . $ sudo wrmsr -p 1 0x1a4 1 L2 Streamer 1.
Pre-Decoder-AnweisungenNachdem der nächste 16-Byte-Code geladen wurde, fallen sie in die Pre-Decoder-Anweisungen. Seine Aufgabe ist es, die Länge der Anweisung zu bestimmen, die Präfixe zu dekodieren und zu markieren, ob die entsprechende Anweisung eine Verzweigung ist (höchstwahrscheinlich gibt es noch viele verschiedene Eigenschaften, aber die Dokumentation darüber enthält keine Informationen). Intel Software Optimization Manual / 2.6.2.2:The predecode unit accepts the sixteen bytes from the instruction cache or prefetch buffers and carries out the following tasks:
- Determine the length of the instructions
- Decode all prefixes associated with instructions
- Mark various properties of instructions for the decoders (for example, “is branch.”)
Eine Reihe vordecodierter Anweisungen.Von der IFU werden Anweisungen zur vorcodierten Anweisungswarteschlange hinzugefügt. Diese Warteschlange ist seit Nehalem aufgetaucht. Gemäß der Intel-Dokumentation hat sie eine Größe von 18 Anweisungen. Agner Fog erwähnt auch, dass diese Warteschlange nicht mehr als 64 Bytes enthält.Auch in Core2 wurde diese Warteschlange als Schleifencache verwendet. Wenn sich alle Mikrooperationen aus dem Zyklus in der Warteschlange befinden, können in einigen Fällen die Kosten für das Laden und die Vorcodierung vermieden werden. Der Loop Stream Detector (LSD) kann Anweisungen liefern, die sich bereits in der Warteschlange befinden, bis die BPU signalisiert, dass der Zyklus beendet wurde. Agner Fog hat eine Reihe interessanter Hinweise zu LSD auf Core2:- Besteht aus 4 Zeilen mit 16 Bytes
- Spitzendurchsatz bis zu 32 Byte Code pro Zyklus
Beginnend mit Sandy Bridge wurde dieser Schleifencache von der vordecodierten Anweisungswarteschlange zurück zu IDQ verschoben.Decoder von vordecodierten Anweisungen in der MikrooperationAus der Warteschlange von vordecodierten Anweisungen wird der Code zur Decodierung in der Mikrooperation gesendet. Decoder sind für die Decodierung verantwortlich - insgesamt gibt es 4. Laut Intel-Dokumentation kann einer der Decoder Anweisungen dekodieren, die aus 4 Mikrooperationen oder weniger bestehen. Der Rest decodiert Anweisungen, die aus einer Mikrooperation (Mikro- / Makro-Fusion) bestehen, Intel Software Optimization Manual / 2.5.2.1:There are four decoding units that decode instruction into micro-ops. The first can decode all IA-32 and Intel 64 instructions up to four micro-ops in size. The remaining three decoding units handle single-micro-op instructions. All four decoding units support the common cases of single micro-op flows including micro-fusion and macro-fusion.
Anweisungen, die in einer großen Anzahl von Mikrooperationen decodiert wurden (z. B. rep movsb, die bei der Implementierung von memcpy in libc auf bestimmten Größen des kopierten Speichers verwendet werden), stammen vom Microcode Sequencer (MS ROM). Die Spitzenbandbreite des Sequenzers beträgt 4 Mikrooperationen pro Zyklus.Wie Sie im Fließbanddiagramm sehen können, kann die Legacy Decode Pipeline auf Skylake bis zu 5 Mikrooperationen pro Zyklus decodieren. Bei Broadwell und älteren Versionen betrug der Spitzendurchsatz der Legacy Decode Pipeline 4 Mikrooperationen pro Zyklus.Mikrooperations-CacheNachdem die Anweisungen in Mikrooperationen decodiert wurden, fallen sie aus der Legacy Decode Pipeline in die spezielle Mikrooperationswarteschlange - Instruction Decode Queue (IDQ) - sowie in den sogenannten Mikrooperationscache (Decoded ICache, µop Cache). Der Mikrooperations-Cache wurde ursprünglich in Sandy Bridge eingeführt und wird verwendet, um das Abrufen und Dekodieren von Anweisungen bei Mikrooperationen zu vermeiden, wodurch der Durchsatz für die Bereitstellung von Mikrooperationen in IDQ erhöht wird - bis zu 6 pro Zyklus. Nach dem Einstieg in IDQ werden Mikrooperationen zur Ausführung mit einem Spitzendurchsatz von 4 Mikrooperationen pro Zyklus an das Back-End gesendet.Laut Intel-Dokumentation besteht der Mikrooperations-Cache aus 32 Sätzen, jeder Satz enthält 8 Zeilen, jede Zeile kann bis zu 6 Mikrooperationen (Mikro- / Makro-Fusion) zwischenspeichern, was einen Gesamt-Cache von bis zu 32 * 8 * 6 = 1536 Mikrooperationen ermöglicht . Das Zwischenspeichern von Mikrooperationen erfolgt mit einer Granularität von 32 Bytes, d.h. Mikrooperationen, die Anweisungen aus verschiedenen 32-Byte-Regionen folgen, können nicht in eine Zeile fallen. Bis zu 3 verschiedene Cache-Zeilen können jedoch einer 32-Byte-Region entsprechen. Somit können bis zu 18 Mikrooperationen im µop-Cache jeder 32-Byte-Region entsprechen.Intel Software Optimization Manual / 2.5.5.2The Decoded ICache consists of 32 sets. Each set contains eight Ways. Each Way can hold up to six micro-ops. The Decoded ICache can ideally hold up to 1536 micro-ops. The following are some of the rules how the Decoded ICache is filled with micro-ops:
- ll micro-ops in a Way represent instructions which are statically contiguous in the code and have their EIPs within the same aligned 32-byte region.
- Up to three Ways may be dedicated to the same 32-byte aligned chunk, allowing a total of 18 micro-ops to be cached per 32-byte region of the original IA program.
- A multi micro-op instruction cannot be split across Ways.
- Up to two branches are allowed per Way.
- An instruction which turns on the MSROM consumes an entire Way.
- A non-conditional branch is the last micro-op in a Way.
- Micro-fused micro-ops (load+op and stores) are kept as one micro-op.
- A pair of macro-fused instructions is kept as one micro-op.
- Instructions with 64-bit immediate require two slots to hold the immediate.
Agner Fog erwähnt auch, dass nur einzeilige Mikrooperationen pro Zyklus heruntergeladen werden können (in der Intel-Dokumentation nicht explizit angegeben, obwohl dies leicht manuell überprüft werden kann).µop cache --> IDQ
In einigen Fällen ist es sehr praktisch, nopLängen von 1 Byte zu verwenden, um das Verhalten des Frontends zu untersuchen . Gleichzeitig können wir sicher sein, dass wir aus irgendeinem Grund das Front-End und nicht den Resource Stall am Back-End untersuchen. Tatsache ist, dass sie nopneben anderen Anweisungen in der Legacy Decode Pipeline decodiert, im µop-Cache gemischt und an IDQ gesendet werden. Weiter nop, sowie andere Anweisungen, nimmt Back-End. Der wesentliche Unterschied besteht darin, dass bei den Ressourcen im Back-End nopnur der Nachbestellungspuffer verwendet wird und kein Steckplatz in der Reservierungsstation (auch als Scheduler bezeichnet) erforderlich ist. Somit ist es unmittelbar nach Eingabe nopdes Bestellpuffers für den Ruhestand bereit, der gemäß der Reihenfolge im Programmcode ausgeführt wird.Deklarieren Sie eine Funktion, um den Durchsatz zu testenvoid test_decoded_icache(size_t iteration_count);
mit Umsetzung am nasm:align 32
test_decoded_icache:
;nop', 0 23
dec rdi
ja test_decoded_icache
ret
jaEs wurde nicht zufällig ausgewählt. jaund decverwenden Sie verschiedene Flags - jaliest von CFund ZFnimmt decnicht in der CF auf, sodass Macro Fusion nicht angewendet wird. Dies geschieht lediglich, um Mikrooperationen in einem Zyklus bequem zählen zu können - jeder Befehl entspricht einer Mikrooperation.Für Messungen benötigen wir die folgenden Perf-Ereignisse:1. uops_issued.any- Wird verwendet, um die Mikrooperationen zu zählen, die Renamer von IDQ übernimmt.Das Intel System Programming Guide dokumentiert dieses Ereignis als die Anzahl der Mikrooperationen, die Renamer in die Reservierungsstation einfügt:Zählt die Anzahl der Uops, die die Resource Allocation Table (RAT) an die Reservation Station (RS) ausgibt.
Diese Beschreibung korreliert nicht vollständig mit den Werten, die aus Experimenten erhalten werden können. Insbesondere nopfallen sie in diesen Schalter, obwohl es nur eine Tatsache ist, dass sie an der Reservierungsstation überhaupt nicht benötigt werden.2. uops_retired.retire_slots- die Gesamtzahl der Mikrooperationen im Ruhestand unter Berücksichtigung der Mikro- / Makrofusion3. uops_retired.stall_cycles- die Anzahl der Zecken, für die es keine einzige Mikrooperation im Ruhestand gab4. resource_stalls.any- die Anzahl der Zecken im Leerlaufförderer aufgrund der Unzugänglichkeit einer der Ressourcen Back-Endim Intel Software Optimization Manual / B. .4.1 Es gibt ein Inhaltsdiagramm, das die oben beschriebenen Ereignisse charakterisiert: 5.
5. idq.all_dsb_cycles_4_uops- Die Anzahl der Taktzyklen, für die 4 (oder mehr) Anweisungen aus dem µop-Cache geliefert wurden.Die Tatsache, dass diese Metrik die Bereitstellung von mehr als 4 Mikrooperationen pro Zyklus berücksichtigt, wird in der Intel-Dokumentation nicht beschrieben, stimmt jedoch sehr gut mit den Experimenten überein.6. idq.all_dsb_cycles_any_uops- die Anzahl der Maßnahmen, für die mindestens eine Mikrooperation durchgeführt wurde.7. idq.dsb_cycles- Die Gesamtzahl der Ticks, bei denen die Lieferung aus dem µop-Cache erfolgte.8. idq_uops_not_delivered.cycles_le_N_uop_deliv.core- Die Anzahl der Ticks, für die Renamer eine Noder weniger Mikrooperationen durchgeführt hat und auf der Back-End-Seite keine Ausfallzeiten aufgetreten sind. N- 1, 2, 3.Wir nehmen Nachforschungen an iteration_count = 1 << 31. Wir beginnen die Analyse dessen, was in der CPU geschieht, indem wir die Anzahl der Mikrooperationen untersuchen und zunächst die durchschnittliche Ausfallbandbreite messen, d. H. uops_retired.retire_slots/uops_retired.total_cycle:: Was sofort auffällt, ist das Absinken des Ruhestandsdurchsatzes bei einer Zyklusgröße von 7 Mikrooperationen. Um zu verstehen, worum es geht, schauen wir uns an, wie sich die durchschnittliche Übermittlungsgeschwindigkeit aus dem µop-Cache ändert
Was sofort auffällt, ist das Absinken des Ruhestandsdurchsatzes bei einer Zyklusgröße von 7 Mikrooperationen. Um zu verstehen, worum es geht, schauen wir uns an, wie sich die durchschnittliche Übermittlungsgeschwindigkeit aus dem µop-Cache ändert idq.all_dsb_cycles_any_uops / idq.dsb_cycles- und wie die Gesamtzahl der Kennzahlen und Kennzahlen, für die der µop-Cache an IDQ geliefert wird, zusammenhängt:
und wie die Gesamtzahl der Kennzahlen und Kennzahlen, für die der µop-Cache an IDQ geliefert wird, zusammenhängt: So können wir sehen, dass wir mit einem Zyklus von 6 Mikrooperationen eine effektive erzielen µop-Cache-Bandbreitennutzung - 6 Mikrooperationen pro Zyklus. Aufgrund der Tatsache, dass Renamer nicht so viel aufnehmen kann, wie der µop-Cache liefert, liefert ein Teil der µop-Cache-Zyklen nichts, was im vorherigen Diagramm deutlich sichtbar ist.Bei einem Zyklus von 7 Mikrooperationen sinkt der Durchsatz des µop-Cache stark - 3,5 Mikrooperationen pro Zyklus. Gleichzeitig ist der µop-Cache, wie aus dem vorherigen Diagramm ersichtlich, ständig in Betrieb. Mit einem Zyklus von 7 Mikrooperationen erhalten wir somit eine ineffiziente Auslastung des Bandbreiten-µop-Cache. Tatsache ist, dass, wie bereits erwähnt, der µop-Cache pro Zyklus Mikrooperationen von nur einer Zeile liefern kann. Bei Mikrooperationen 7 fallen die ersten 6 in eine Zeile und die restlichen 7 in eine andere. Auf diese Weise erhalten wir 7 Mikrooperationen pro 2 Zyklen oder 3,5 Mikrooperationen pro Zyklus.Schauen wir uns nun an, wie Renamer Mikrooperationen von IDQ übernimmt. Dafür brauchen wir
So können wir sehen, dass wir mit einem Zyklus von 6 Mikrooperationen eine effektive erzielen µop-Cache-Bandbreitennutzung - 6 Mikrooperationen pro Zyklus. Aufgrund der Tatsache, dass Renamer nicht so viel aufnehmen kann, wie der µop-Cache liefert, liefert ein Teil der µop-Cache-Zyklen nichts, was im vorherigen Diagramm deutlich sichtbar ist.Bei einem Zyklus von 7 Mikrooperationen sinkt der Durchsatz des µop-Cache stark - 3,5 Mikrooperationen pro Zyklus. Gleichzeitig ist der µop-Cache, wie aus dem vorherigen Diagramm ersichtlich, ständig in Betrieb. Mit einem Zyklus von 7 Mikrooperationen erhalten wir somit eine ineffiziente Auslastung des Bandbreiten-µop-Cache. Tatsache ist, dass, wie bereits erwähnt, der µop-Cache pro Zyklus Mikrooperationen von nur einer Zeile liefern kann. Bei Mikrooperationen 7 fallen die ersten 6 in eine Zeile und die restlichen 7 in eine andere. Auf diese Weise erhalten wir 7 Mikrooperationen pro 2 Zyklen oder 3,5 Mikrooperationen pro Zyklus.Schauen wir uns nun an, wie Renamer Mikrooperationen von IDQ übernimmt. Dafür brauchen wir idq_uops_not_delivered.coreund idq_uops_not_delivered.cycles_le_N_uop_deliv.core: Möglicherweise stellen Sie fest, dass bei 7 Mikrooperationen jeweils nur 3 Mikrooperationen die Hälfte der Renamer-Zyklen benötigen. Von hier aus erhalten wir einen Ruhestandsdurchsatz von durchschnittlich 3,5 Mikrooperationen pro Zyklus.Ein weiterer interessanter Punkt in Bezug auf dieses Beispiel ist zu sehen, wenn wir den effektiven Durchsatz der Pensionierung berücksichtigen . Jene. ohne Berücksichtigung
Möglicherweise stellen Sie fest, dass bei 7 Mikrooperationen jeweils nur 3 Mikrooperationen die Hälfte der Renamer-Zyklen benötigen. Von hier aus erhalten wir einen Ruhestandsdurchsatz von durchschnittlich 3,5 Mikrooperationen pro Zyklus.Ein weiterer interessanter Punkt in Bezug auf dieses Beispiel ist zu sehen, wenn wir den effektiven Durchsatz der Pensionierung berücksichtigen . Jene. ohne Berücksichtigung uops_retired.stall_cycles: Es kann angemerkt werden, dass bei 7 Mikrooperationen alle 7 Maßnahmen die Stilllegung von 4 Mikrooperationen durchgeführt wird und jede 8. Maßnahme ohne Mikrooperationen im Ruhestand im Leerlauf ist (Stillstandsstand). Nach einer Reihe von Experimenten konnte festgestellt werden, dass ein solches Verhalten immer während 7 Mikrooperationen beobachtet wurde, unabhängig von deren Anordnung 1-6, 6-1, 2-5, 5-2, 3-4, 4-3. Ich weiß nicht, warum dies genau der Fall ist, und nicht zum Beispiel wird die Stilllegung von 3 Mikrooperationen in einem Taktzyklus und von 4 im nächsten durchgeführt. Agner Fog erwähnte, dass Zweigübergänge nur einen Teil der Slots der Ruhestandsstation nutzen können. Vielleicht ist diese Einschränkung der Grund für dieses Ruhestandsverhalten.
Es kann angemerkt werden, dass bei 7 Mikrooperationen alle 7 Maßnahmen die Stilllegung von 4 Mikrooperationen durchgeführt wird und jede 8. Maßnahme ohne Mikrooperationen im Ruhestand im Leerlauf ist (Stillstandsstand). Nach einer Reihe von Experimenten konnte festgestellt werden, dass ein solches Verhalten immer während 7 Mikrooperationen beobachtet wurde, unabhängig von deren Anordnung 1-6, 6-1, 2-5, 5-2, 3-4, 4-3. Ich weiß nicht, warum dies genau der Fall ist, und nicht zum Beispiel wird die Stilllegung von 3 Mikrooperationen in einem Taktzyklus und von 4 im nächsten durchgeführt. Agner Fog erwähnte, dass Zweigübergänge nur einen Teil der Slots der Ruhestandsstation nutzen können. Vielleicht ist diese Einschränkung der Grund für dieses Ruhestandsverhalten.Beispiel
Um zu verstehen, ob dies alles in der Praxis Auswirkungen hat, betrachten Sie das folgende etwas praktischere Beispiel als bei nops:Es werden zwei Arrays angegeben unsigned. Es ist notwendig, die Summe der arithmetischen Mittelwerte für jeden Index zu akkumulieren und in das dritte Array zu schreiben.Eine Beispielimplementierung könnte folgendermaßen aussehen:
static unsigned arr1[] = { ... };
static unsigned arr2[] = { ... };
static void arithmetic_mean(unsigned *arr1, unsigned *arr2, unsigned *out, size_t sz){
unsigned sum = 0;
size_t idx = 0;
while(idx < sz){
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
}
__asm__ __volatile__("" ::: "memory");
}
int main(void){
unsigned out[sizeof arr1 / sizeof(unsigned)];
for(size_t i = 0; i < 4096 * 4096; i++){
arithmetic_mean(arr1, arr2, out, sizeof arr1 / sizeof(unsigned));
}
}
Kompilieren Sie mit gcc-Flags-Werror
-Wextra
-Wall
-pedantic
-Wno-stack-protector
-g3
-O3
-Wno-unused-result
-Wno-unused-parameter
Es ist ziemlich offensichtlich, dass die Funktion arithmetic_meannicht im Code vorhanden ist und direkt in Folgendes eingefügt wird main:(gdb) disas main
Dump of assembler code for function main:
#...
0x00000000000005dc <+60>: nop DWORD PTR [rax+0x0]
0x00000000000005e0 <+64>: mov edx,DWORD PTR [rdi+rax*4]
0x00000000000005e3 <+67>: add edx,DWORD PTR [r8+rax*4]
0x00000000000005e7 <+71>: shr edx,1
0x00000000000005e9 <+73>: add ecx,edx
0x00000000000005eb <+75>: mov DWORD PTR [rsi+rax*4],ecx
0x00000000000005ee <+78>: add rax,0x1
0x00000000000005f2 <+82>: cmp rax,0x80
0x00000000000005f8 <+88>: jne 0x5e0 <main+64>
0x00000000000005fa <+90>: sub r9,0x1
0x00000000000005fe <+94>: jne 0x5d8 <main+56>
#...
Beachten Sie, dass der Compiler den Schleifencode auf 32 Bytes ( nop DWORD PTR [rax+0x0]) ausgerichtet hat, was genau das ist, was wir brauchen. Nachdem sichergestellt wurde, dass kein resource_stalls.anyBack-End vorhanden ist (alle Messungen werden unter Berücksichtigung des beheizten L1d-Cache durchgeführt), können wir beginnen, die mit der Lieferung an IDQ verbundenen Zähler zu berücksichtigen: Performance counter stats for './test_decoded_icache':
2 273 343 251 idq.all_dsb_cycles_4_uops (15,94%)
4 458 322 025 idq.all_dsb_cycles_any_uops (16,26%)
15 473 065 238 idq.dsb_uops (16,59%)
4 358 690 532 idq.dsb_cycles (16,91%)
2 528 373 243 idq_uops_not_delivered.core (16,93%)
73 728 040 idq_uops_not_delivered.cycles_0_uops_deliv.core (16,93%)
107 262 304 idq_uops_not_delivered.cycles_le_1_uop_deliv.core (16,93%)
108 454 043 idq_uops_not_delivered.cycles_le_2_uop_deliv.core (16,65%)
2 248 557 762 idq_uops_not_delivered.cycles_le_3_uop_deliv.core (16,32%)
2 385 493 805 idq_uops_not_delivered.cycles_fe_was_ok (16,00%)
15 147 004 678 uops_retired.retire_slots
4 724 790 623 uops_retired.total_cycles
1,228684264 seconds time elapsed
Beachten Sie, dass in diesem Fall die Ausfallbreite für den Ruhestand = 15147004678/4724790623 = 3.20585733562 ist und dass nur 3 Mikrooperationen die Hälfte der Uhren von Renamer benötigen.Fügen Sie nun die Implementierung der manuellen Schleife zur Implementierung hinzu:static void arithmetic_mean(unsigned *arr1, unsigned *arr2, unsigned *out, size_t sz){
unsigned sum = 0;
size_t idx = 0;
if(sz & 2){
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
}
while(idx < sz){
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
}
__asm__ __volatile__("" ::: "memory");
}
Die resultierenden Leistungsindikatoren sehen aus wie:Performance counter stats for './test_decoded_icache':
2 152 818 549 idq.all_dsb_cycles_4_uops (14,79%)
3 207 203 856 idq.all_dsb_cycles_any_uops (15,25%)
12 855 932 240 idq.dsb_uops (15,70%)
3 184 814 613 idq.dsb_cycles (16,15%)
24 946 367 idq_uops_not_delivered.core (16,24%)
3 011 119 idq_uops_not_delivered.cycles_0_uops_deliv.core (16,24%)
5 239 222 idq_uops_not_delivered.cycles_le_1_uop_deliv.core (16,24%)
7 373 563 idq_uops_not_delivered.cycles_le_2_uop_deliv.core (16,24%)
7 837 764 idq_uops_not_delivered.cycles_le_3_uop_deliv.core (16,24%)
3 418 529 799 idq_uops_not_delivered.cycles_fe_was_ok (16,24%)
3 444 833 440 uops_retired.total_cycles (18,18%)
13 037 919 196 uops_retired.retire_slots (18,17%)
0,871040207 seconds time elapsed
In diesem Fall haben wir eine Ruhestandsbandbreite = 13037919196/3444833440 = 3.78477491672 sowie eine effiziente Nutzung der Renamer-Bandbreite.Auf diese Weise haben wir nicht nur eine Verzweigungs- und eine Inkrementierungsoperation in einem Zyklus beseitigt, sondern auch die Ausfallbandbreite erhöht, indem der Durchsatz des Mikrooperationscaches effizient genutzt wurde, was zu einer Leistungssteigerung von insgesamt 28% führte.Beachten Sie, dass nur eine Reduzierung einer Verzweigungs- und Inkrementierungsoperation eine durchschnittliche Leistungssteigerung von 9% ergibt.Kleine Bemerkung
Auf der CPU, die zur Durchführung dieser Experimente verwendet wurde, ist LSD ausgeschaltet. Es scheint, dass LSD mit einer solchen Situation umgehen könnte. Bei CPUs mit aktiviertem LSD müssen solche Fälle separat untersucht werden.