Kürzlich habe ich darüber gesprochen, wie die Standardrezepte verwendet werden können, um die Leistung von SQL-Abfragen aus einer PostgreSQL-Datenbank zu verbessern . Heute werden wir darüber sprechen, wie Sie das Schreiben in die Datenbank effizienter gestalten können, ohne „Wendungen“ in der Konfiguration zu verwenden - einfach indem Sie die Datenflüsse korrekt organisieren.# 1. Partitionierung
Ein Artikel darüber, wie und warum es sich lohnt, angewandte Partitionierung „theoretisch“ zu organisieren, wurde bereits veröffentlicht. Hier konzentrieren wir uns auf die Praxis, einige Ansätze im Rahmen unseres Überwachungsdienstes für Hunderte von PostgreSQL-Servern zu verwenden ."Fälle vergangener Tage ..."
Wie jedes MVP begann unser Projekt zunächst unter relativ geringer Last - die Überwachung wurde nur für die zehn kritischsten Server durchgeführt, alle Tabellen waren relativ kompakt ... Aber die Zeit verging, es gab immer mehr überwachte Hosts und versuchte erneut, etwas damit zu tun Bei einem der Tische mit einer Größe von 1,5 TB haben wir festgestellt, dass es zwar möglich ist, so weiterzuleben , aber sehr unpraktisch ist.Die Zeiten waren fast episch, verschiedene PostgreSQL 9.x-Varianten waren relevant, daher mussten alle Partitionen „manuell“ durchgeführt werden - durch Tabellenvererbung und dynamische Routing- TriggerEXECUTE .Die resultierende Lösung erwies sich als universell genug, um sie in alle Tabellen übersetzen zu können:PG10:
Die Partitionierung durch Vererbung war jedoch in der Vergangenheit nicht gut geeignet, um mit einem aktiven Schreibstrom oder einer großen Anzahl von Nachkommenabschnitten zu arbeiten. Sie können sich beispielsweise daran erinnern, dass der Algorithmus zur Auswahl des gewünschten Abschnitts eine quadratische Komplexitätaufwies und mit mehr als 100 Abschnitten funktioniert. Sie verstehen, wie ... In PG10 wurde diese Situation durch die Implementierung der Unterstützung für die native Partitionierung erheblich optimiert . Daher haben wir sofort versucht, es unmittelbar nach der Migration des Speichers anzuwenden, aber ...Wie sich nach dem Ausgraben des Handbuchs herausstellte, war die nativ partitionierte Tabelle in dieser Version:- unterstützt keine Beschreibung von Indizes
- unterstützt keine Trigger darauf
- kann selbst kein "Nachkomme" sein
- nicht unterstützen
INSERT ... ON CONFLICT - Abschnitt kann nicht automatisch erzeugt werden
Als wir schmerzhaft einen Rechen auf die Stirn bekamen, stellten wir fest, dass wir nicht auf eine Änderung der Anwendung verzichten konnten, und schoben die weitere Forschung um sechs Monate auf.PG10: Zweite Chance
Also begannen wir, die Probleme der Reihe nach zu lösen:- Da sich die Trigger
ON CONFLICTan einigen Stellen als notwendig herausstellten, haben wir eine Zwischen- Proxy-Tabelle erstellt , um sie zu ermitteln . - Wir haben das "Routing" in Triggern beseitigt - das heißt von
EXECUTE. - Sie nahmen eine separate Vorlagentabelle mit allen Indizes heraus, so dass sie nicht einmal in der Proxy-Tabelle vorhanden waren.
Schließlich wurde die Haupttabelle bereits nativ partitioniert. Das Erstellen eines neuen Abschnitts bleibt im Gewissen der Anwendung.Wörterbücher „sägen“
Wie in jedem Analysesystem hatten wir auch „Fakten“ und „Schnitte“ (Wörterbücher). In unserem Fall handelte es sich in dieser Eigenschaft beispielsweise um den Hauptteil der „Vorlage“ des gleichen Typs langsamer Abfragen oder um den Text der Abfrage selbst.Unsere "Fakten" waren lange Zeit nach Tagen unterteilt, so dass wir die veralteten Abschnitte ruhig löschten und sie uns nicht störten (Protokolle!). Aber mit den Wörterbüchern stellte sich das Problemheraus ... Um nicht zu sagen, dass es viele davon gab, aber ungefähr 100 TB „Fakten“ erwiesen sich als Wörterbuch für 2,5 TB . Sie können bequemerweise nichts aus einer solchen Tabelle löschen, Sie werden es nicht rechtzeitig drücken, und das Schreiben darauf wurde allmählich langsamer.Es scheint wie ein Wörterbuch ... darin sollte jeder Eintrag genau einmal präsentiert werden ... und das ist richtig, aber! .. Niemand stört uns, für jeden Tag ein eigenes Wörterbuch zu haben ! Ja, dies bringt eine gewisse Redundanz mit sich, ermöglicht Ihnen jedoch Folgendes:- Schreiben / Lesen schneller aufgrund kleinerer Abschnittsgröße
- Verbrauchen Sie weniger Speicher, indem Sie mit kompakteren Indizes arbeiten
- Speichern Sie weniger Daten, da veraltete Daten schnell entfernt werden können
Infolge des gesamten Maßnahmenkomplexes verringerte sich die CPU-Auslastung um ~ 30% und die Festplatte um ~ 50% :Gleichzeitig haben wir weiterhin genau dasselbe in die Datenbank geschrieben, nur mit weniger Last.# 2 Datenbankentwicklung und Refactoring
Wir haben uns also darauf geeinigt
, dass wir für jeden Tag einen eigenen Abschnitt mit Daten haben. Tatsächlich ist dies CHECK (dt = '2018-10-12'::date)der Partitionierungsschlüssel und die Bedingung, dass der Datensatz in einen bestimmten Abschnitt fällt.Da alle Berichte in unserem Service nach einem bestimmten Datum erstellt wurden, waren die Indizes aus den "nicht partitionierten Zeiten" alle Arten von ihnen (Server, Datum , Planvorlage) , (Server, Datum , Plan-Knoten) , ( Datum , Fehlerklasse, Server) , ...Aber jetzt hat jeder Abschnitt seine eigenen Instanzen für jeden solchen Index ... Und innerhalb jedes Abschnitts ist das Datum konstant ... Es stellt sich heraus, dass wir uns jetzt in jedem solchen Index befindenWir geben trivial eine Konstante als eines der Felder ein, wodurch sowohl das Volumen als auch die Suchzeit erhöht werden, aber kein Ergebnis erzielt wird. Sie haben einen Rechen hinterlassen, oops ...Die Richtung der Optimierung liegt auf der Hand - entfernen Sie einfach das Datumsfeld aus allen Indizes für partitionierte Tabellen. Bei unseren Volumina beträgt der Gewinn ungefähr 1 TB / Woche !Und jetzt bemerken wir, dass dieses Terabyte noch irgendwie aufgeschrieben werden musste. Das heißt, wir müssen jetzt auch weniger Festplatte laden ! In diesem Bild ist der Effekt der Reinigung, der wir eine Woche gewidmet haben, deutlich sichtbar: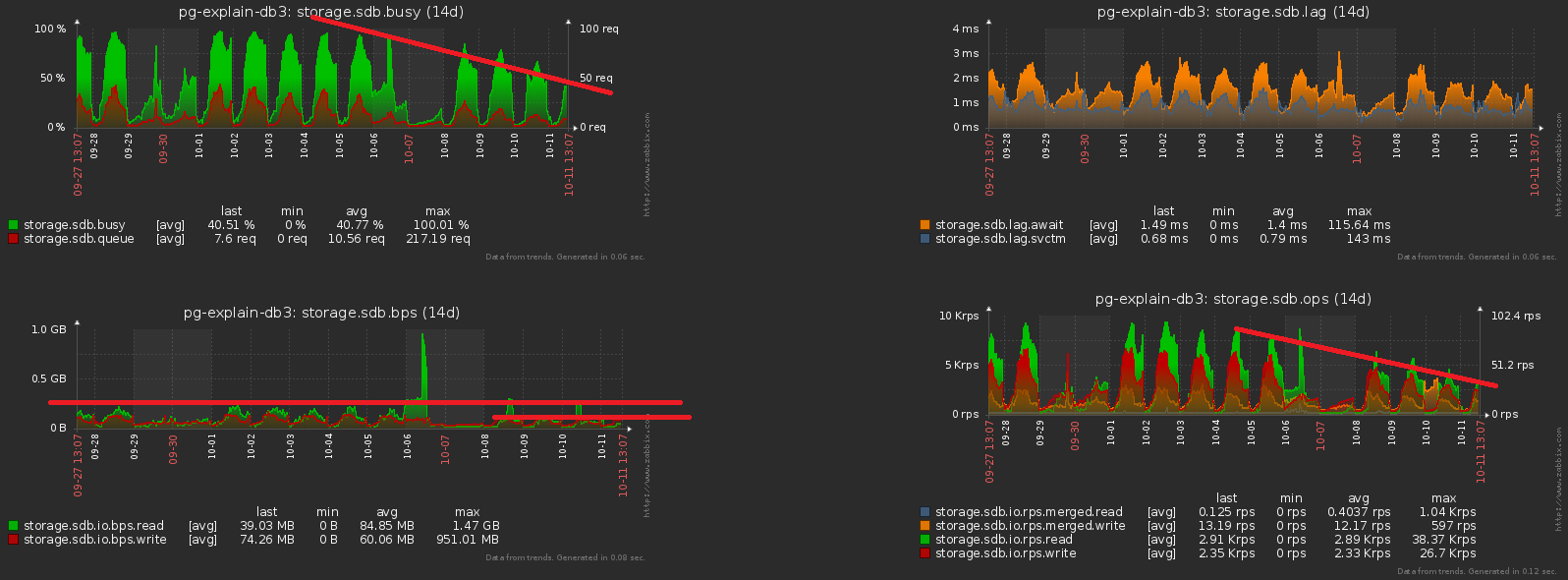
# 3 Die Spitzenlast „verschmieren“
Eines der großen Probleme geladener Systeme ist die übermäßige Synchronisation einiger Vorgänge, für die dies nicht erforderlich ist. Manchmal "weil sie es nicht bemerkt haben", manchmal "es war einfacher", aber früher oder später muss man es loswerden.Wir bringen das vorherige Bild näher - und wir sehen, dass die Scheibe mit einer Last mit doppelter Amplitude zwischen benachbarten Proben "wackelt" , was bei so vielen Operationen offensichtlich nicht "statistisch" sein sollte: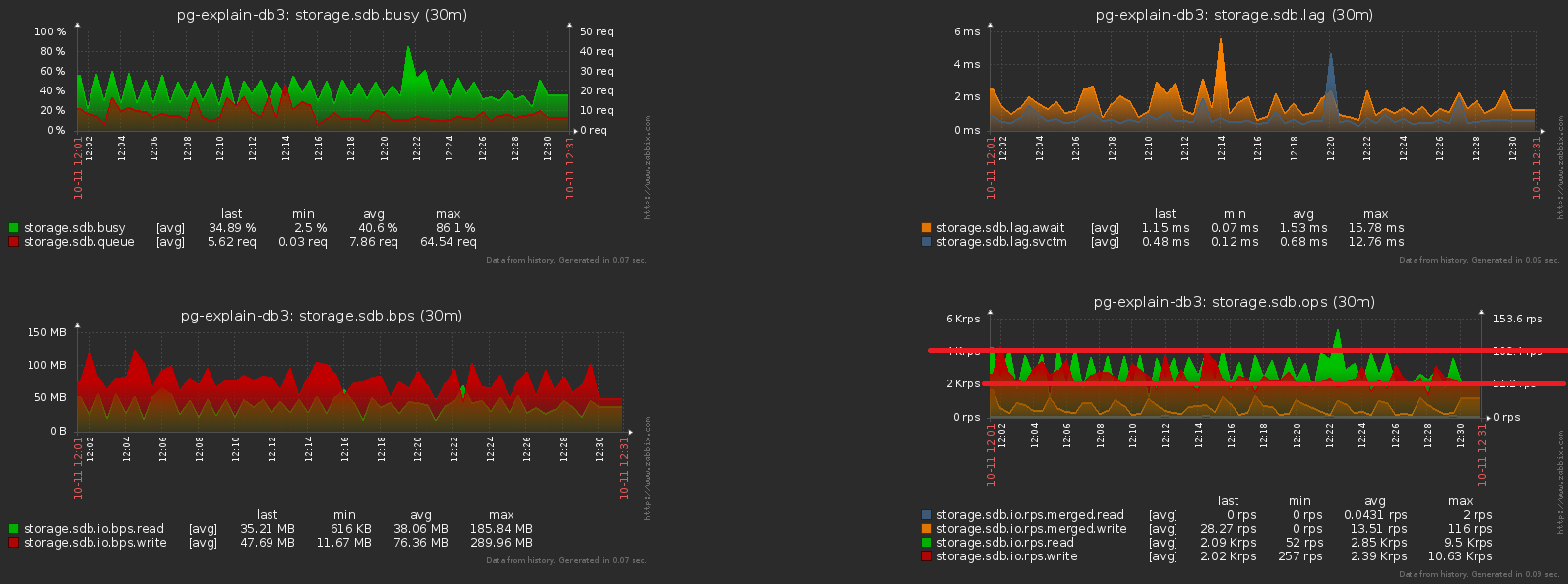 Dies zu erreichen ist recht einfach. Fast 1000 Server wurden bereits für die Überwachung eingerichtet , jeder wird von einem separaten logischen Stream verarbeitet, und jeder Stream speichert die gesammelten Informationen zum Senden an die Datenbank mit einer bestimmten Häufigkeit, etwa wie folgt:
Dies zu erreichen ist recht einfach. Fast 1000 Server wurden bereits für die Überwachung eingerichtet , jeder wird von einem separaten logischen Stream verarbeitet, und jeder Stream speichert die gesammelten Informationen zum Senden an die Datenbank mit einer bestimmten Häufigkeit, etwa wie folgt:setInterval(sendToDB, interval)
Das Problem liegt hier genau darin, dass alle Threads ungefähr zur gleichen Zeit beginnen , so dass die Sendezeiten für sie fast immer „auf den Punkt“ fallen. Ups Nr. 2 ...Glücklicherweise kann dies leicht durch Hinzufügen einer "zufälligen" Zeitspanne korrigiert werden :setInterval(sendToDB, interval * (1 + 0.1 * (Math.random() - 0.5)))
# 4. Caching, das muss sein
Das dritte traditionelle Hochlastproblem ist das Fehlen eines Caches, wo es sein könnte .Zum Beispiel haben wir es möglich gemacht, die Aufteilung der Knoten des Plans (alle diese Seq Scan on users) zu analysieren , aber sofort vergessen, dass sie im Wesentlichen gleich sind und vergessen haben.Nein, natürlich wird nichts wiederholt in die Datenbank geschrieben, dies unterbricht den Trigger mit INSERT ... ON CONFLICT DO NOTHING. Die Daten erreichen die Basis jedoch ohnehin nicht und Sie müssen zusätzliche Lesevorgänge durchführen, um den Konflikt zu überprüfen . Hoppla Nr. 3 ...Der Unterschied in der Anzahl der Datensätze, die vor / nach dem Aktivieren des Caching an die Datenbank gesendet wurden, ist offensichtlich: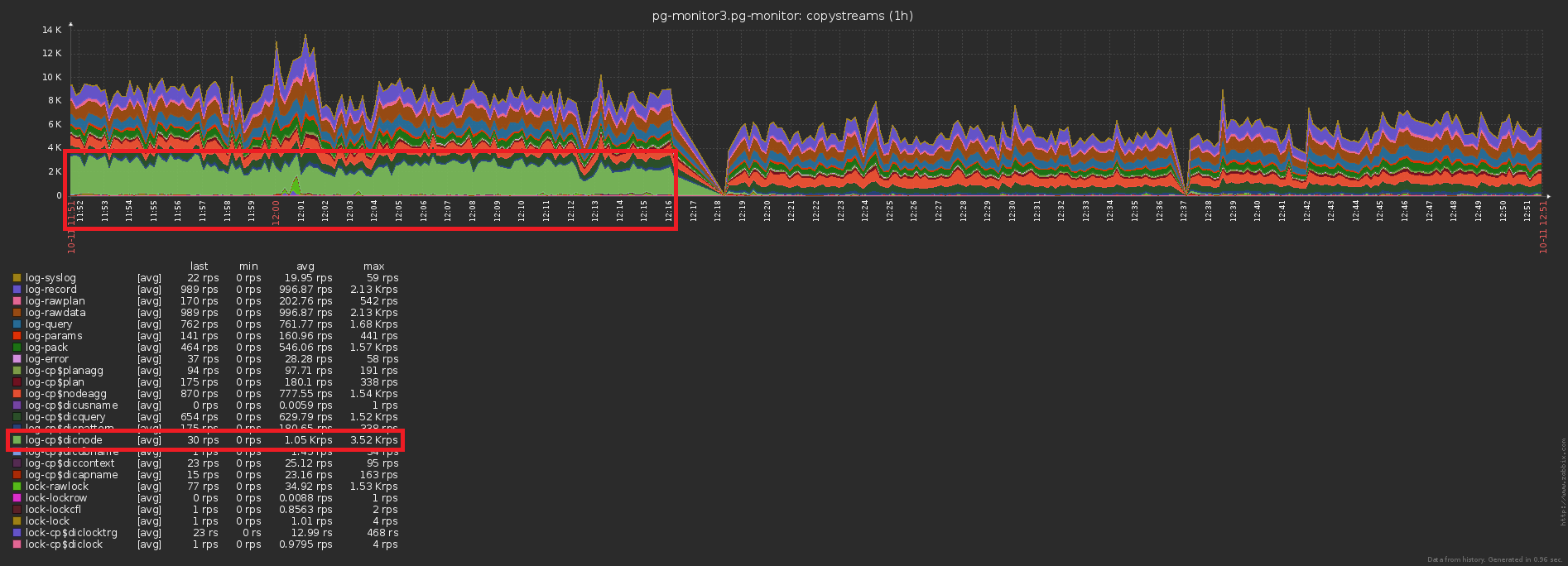 Und dies ist ein gleichzeitiger Rückgang der Speicherlast:
Und dies ist ein gleichzeitiger Rückgang der Speicherlast:
Gesamt
Terabyte pro Tag klingt nur beängstigend. Wenn Sie alles richtig machen, sind dies nur 2 ^ 40 Bytes / 86400 Sekunden = ~ 12,5 MB / s , die sogar Desktop-IDE-Schrauben halten. :)Aber im Ernst, selbst mit einem zehnfachen „Versatz“ der Last während des Tages können Sie die Möglichkeiten moderner SSDs leicht erfüllen.