Nach all den in dieser und dieser Veröffentlichung vorgestellten Berechnungen können wir uns mit der statistischen Analyse befassen und die Methode der kleinsten Quadrate betrachten. Zu diesem Zweck wird die Statistikmodellbibliothek verwendet, mit der Benutzer Daten untersuchen, statistische Modelle auswerten und statistische Tests durchführen können. Dieser Artikel und dieser Artikel wurden als Grundlage genommen . Die Beschreibung der in Englisch verwendeten Funktion finden Sie unter folgendem Link .Zunächst eine kleine Theorie:Über lineare Regression
Die lineare Regression wird als Vorhersagemodell verwendet, wenn eine lineare Beziehung zwischen der abhängigen Variablen (der Variablen, die wir vorhersagen möchten) und der unabhängigen Variablen (der Variablen und / oder den Variablen, die für die Vorhersage verwendet werden) angenommen wird.Im einfachsten Fall wird bei der Betrachtung eine Variable verwendet, auf deren Grundlage wir versuchen, eine andere vorherzusagen. Die Formel in diesem Fall lautet wie folgt:Y = C + M * X.- Y = abhängige Variable (Ergebnis / Prognose / Schätzung)
- C = Konstante (Y-Achsenabschnitt)
- M = Steigung der Regressionslinie (Steigung oder Gradient der geschätzten Linie; dies ist der Betrag, um den Y im Durchschnitt zunimmt, wenn wir X um eine Einheit erhöhen).
- X = unabhängige Variable (Prädiktor in Prognose Y verwendet)
Tatsächlich kann es auch eine Beziehung zwischen der abhängigen Variablen und mehreren unabhängigen Variablen geben. Für diese Modelltypen (unter der Annahme einer Linearität) können wir mehrere lineare Regressionen der folgenden Form verwenden:Y = C + M1X1 + M2X2 + ...Beta-Verhältnis
Über diesen Koeffizienten wurde bereits viel geschrieben, zum Beispiel auf dieser Seite. Wenn Sie nicht auf Details eingehen, können Sie ihn wie folgt charakterisieren:Aktien mit einem Beta-Koeffizienten:- Null bedeutet, dass keine Korrelation zwischen Aktie und Index besteht
- Die Einheit gibt an, dass die Aktie die gleiche Volatilität wie der Index aufweist
- mehr als eins - zeigt eine höhere Rentabilität (und damit höhere Risiken) der Aktie als der Index an
- weniger als eine - weniger volatile Aktie als der Index
Mit anderen Worten, wenn die Aktie um 14% wächst, während der Markt nur um 10% wächst, beträgt der Beta-Koeffizient der Aktie 1,4. In der Regel bieten Märkte mit einem höheren Beta bessere Bedingungen für die Belohnung (und damit für das Risiko).
Trainieren
Der folgende Python-Code enthält ein Beispiel für eine lineare Regression, bei der die Eingabevariable die Rendite des Moskauer Börsenindex und die geschätzte Variable die Rendite von Aeroflot-Aktien ist.Um zu vermeiden, dass Sie sich daran erinnern müssen, wie Daten heruntergeladen und in die für die Berechnung erforderliche Form gebracht werden, wird der Code ab dem Zeitpunkt des Herunterladens der Daten und bis zum Erhalt der Ergebnisse angegeben. Hier ist die vollständige Syntax für die lineare Regression in Python mithilfe von Statistikmodellen:
import pandas as pd
import yfinance as yf
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
ticker = ['AFLT.ME','IMOEX.ME']
stock = yf.download(ticker)
all_adj_close = stock[['Adj Close']]
all_returns = np.log(all_adj_close / all_adj_close.shift(1))
aflt_returns = all_returns['Adj Close'][['AFLT.ME']].fillna(0)
moex_returns = all_returns['Adj Close'][['IMOEX.ME']].fillna(0)
return_data = pd.concat([aflt_returns, moex_returns], axis=1)[1:]
return_data.columns = ['AFLT.ME', 'IMOEX.ME']
X = sm.add_constant(return_data['IMOEX.ME'])
y = return_data['AFLT.ME']
model_moex = sm.OLS(y,X).fit()
print(model_moex.summary())
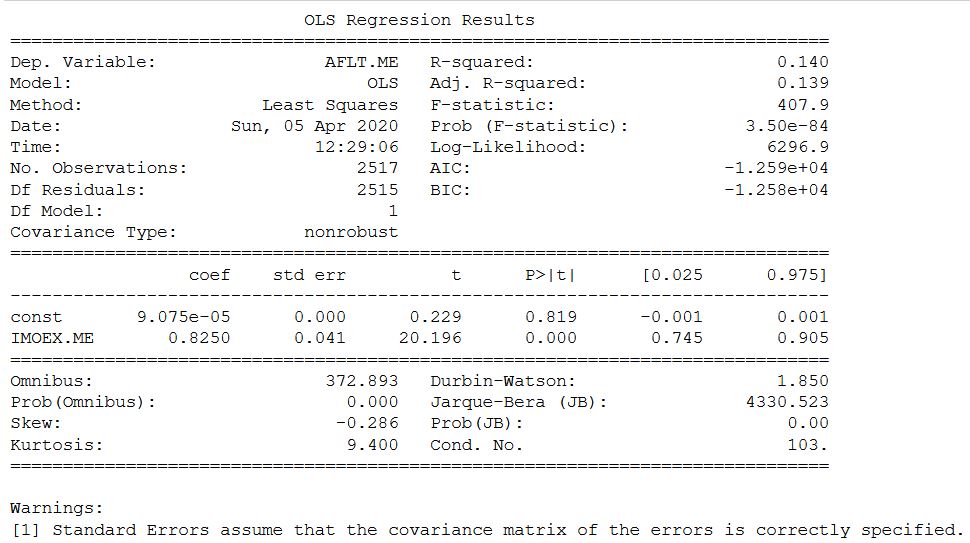 Auf der Yahoo-Website und Mosbirzhi Beta-Koeffizient unterscheidet sich leicht nach oben. Aber ich muss ehrlich zugeben, dass die Berechnung für einige andere Aktien der russischen Börse größere Unterschiede ergab, jedoch innerhalb des Intervalls.
Auf der Yahoo-Website und Mosbirzhi Beta-Koeffizient unterscheidet sich leicht nach oben. Aber ich muss ehrlich zugeben, dass die Berechnung für einige andere Aktien der russischen Börse größere Unterschiede ergab, jedoch innerhalb des Intervalls.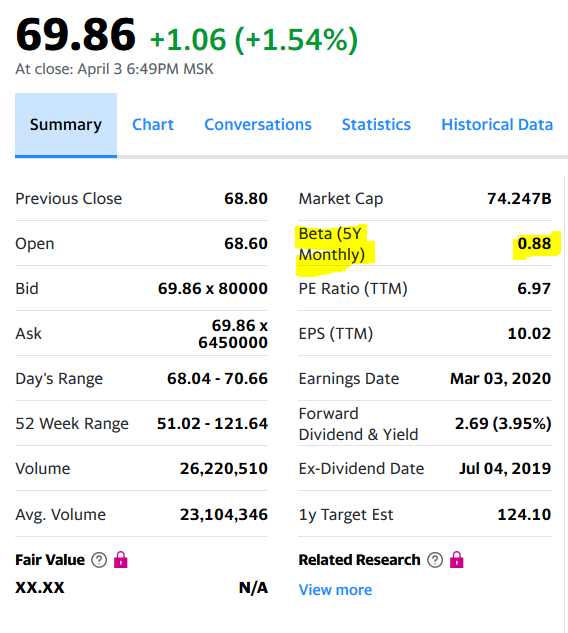 Die gleiche Analyse für die FB-Aktie und den SP500-Index. Hier erfolgt die Berechnung wie im Original über die monatliche Rendite.
Die gleiche Analyse für die FB-Aktie und den SP500-Index. Hier erfolgt die Berechnung wie im Original über die monatliche Rendite.sp_500 = yf.download('^GSPC')
fb = yf.download('FB')
fb = fb.resample('BM').apply(lambda x: x[-1])
sp_500 = sp_500.resample('BM').apply(lambda x: x[-1])
monthly_prices = pd.concat([fb['Close'], sp_500['Close']], axis=1)
monthly_prices.columns = ['FB', '^GSPC']
monthly_returns = monthly_prices.pct_change(1)
clean_monthly_returns = monthly_returns.dropna(axis=0)
X = clean_monthly_returns['^GSPC']
y = clean_monthly_returns['FB']
X1 = sm.add_constant(X)
model_fb_sp_500 = sm.OLS(y, X1)
results_fb_sp_500 = model_fb_sp_500.fit()
print(results_fb_sp_500.summary())
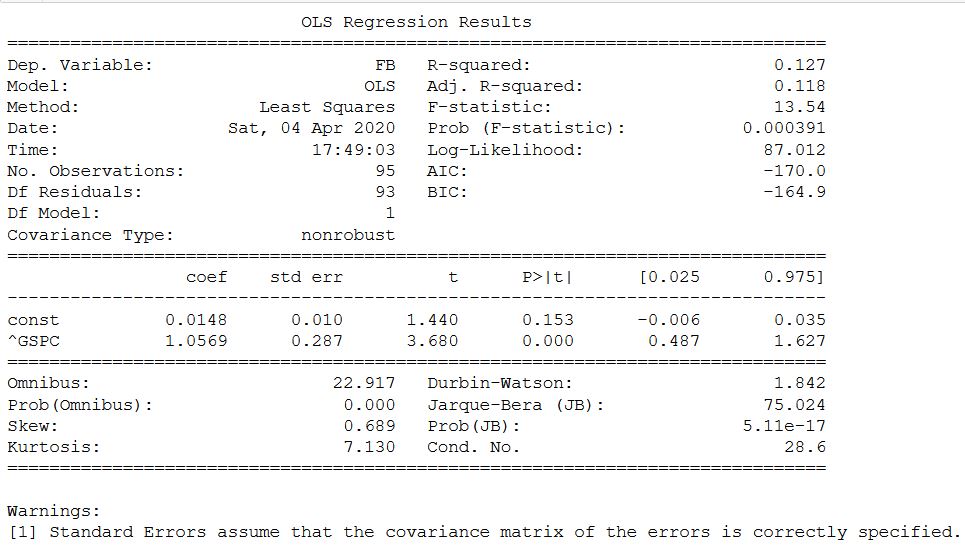
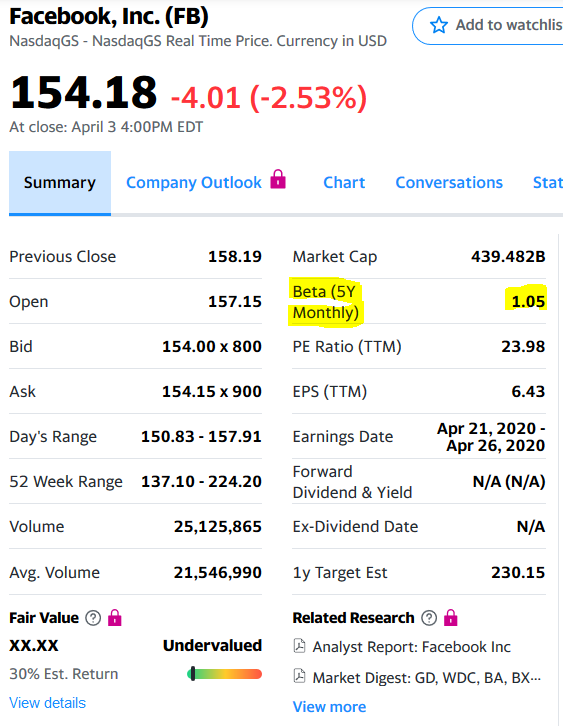 In diesem Fall stimmte alles überein und bestätigte die Möglichkeit, Statistikmodelle zur Bestimmung des Beta-Koeffizienten zu verwenden.Nun, und als Bonus - wenn Sie nur Beta erhalten möchten - möchten Sie den Koeffizienten und den Rest der Statistik beiseite lassen, wird ein anderer Code zur Berechnung vorgeschlagen:
In diesem Fall stimmte alles überein und bestätigte die Möglichkeit, Statistikmodelle zur Bestimmung des Beta-Koeffizienten zu verwenden.Nun, und als Bonus - wenn Sie nur Beta erhalten möchten - möchten Sie den Koeffizienten und den Rest der Statistik beiseite lassen, wird ein anderer Code zur Berechnung vorgeschlagen:from scipy import stats
slope, intercept, r_value, p_value, std_err = stats.linregress(X, y)
print(slope)
1.0568997978702754
Dies bedeutet zwar nicht, dass alle anderen erhaltenen Werte ignoriert werden sollten, aber Kenntnisse über Statistiken sind erforderlich, um sie zu verstehen. Ich werde einen kleinen Auszug aus den erhaltenen Werten geben:- R-Quadrat, das der Bestimmungskoeffizient ist und Werte von 0 bis 1 annimmt. Je näher der Wert des Koeffizienten an 1 liegt, desto stärker ist die Abhängigkeit;
- Adj. R-Quadrat - angepasstes R-Quadrat basierend auf der Anzahl der Beobachtungen und der Anzahl der Freiheitsgrade;
- Standardfehler - Standardfehler der Koeffizientenschätzung;
- P> | t | - p-Wert Ein Wert von weniger als 0,05 wird als statistisch signifikant angesehen.
- 0,025 und 0,975 sind die unteren und oberen Werte des Konfidenzintervalls.
- usw.
Das ist alles für jetzt. Natürlich ist es von Interesse, nach einer Beziehung zwischen verschiedenen Werten zu suchen, um den anderen durch einen vorherzusagen und einen Gewinn zu erzielen. In einer der ausländischen Quellen wurde der Index anhand des Zinssatzes und der Arbeitslosenquote vorhergesagt. Aber wenn die Änderung des Zinssatzes in Russland von der Website der Zentralbank übernommen werden kann, suche ich weiterhin nach anderen. Leider konnte die Rosstat-Website die relevanten nicht finden. Dies ist die endgültige Veröffentlichung in den Artikeln der allgemeinen Finanzanalyse.