Schauen Sie sich diese beiden Punkte an und denken Sie: Welcher scheint Ihnen „zufälliger“ zu sein? Die Verteilung in der linken Abbildung ist deutlich ungleichmäßig. Es gibt Orte, an denen Punkte verdichtet werden, und es gibt auch Orte, an denen es fast keine Punkte gibt. Aus diesem Grund scheint das linke Diagramm sogar dunkler zu sein. In der rechten Abbildung sind auch lokale Kondensationen und Verdünnungen vorhanden, die jedoch weniger auffällig sind.
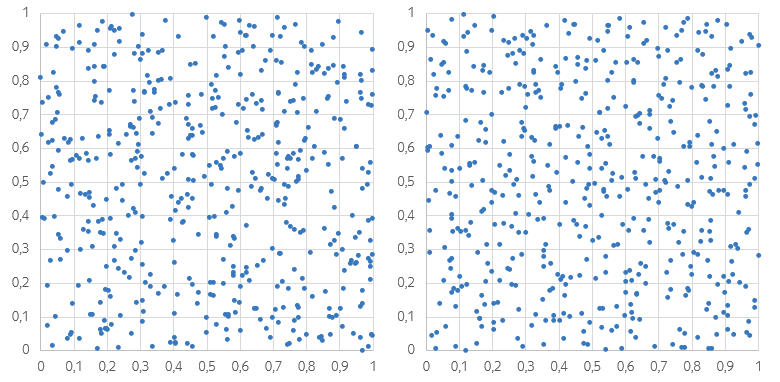
In der Zwischenzeit wurde der linke Graph unter Verwendung eines "ehrlichen" Zufallszahlengenerators erhalten. Das rechte Diagramm enthält auch völlig zufällige Punkte. Diese Punkte werden jedoch so generiert, dass alle kleinen Quadrate die gleiche Anzahl von Punkten enthalten.
Die Schichtung ist eine Methode zur Auswahl einer Teilmenge von Objekten aus der allgemeinen Grundgesamtheit, die in Teilmengen (Schichten) unterteilt ist. Während der Schichtung werden Objekte so ausgewählt, dass die endgültige Stichprobe das Verhältnis der Größe der Schichten beibehält (oderdiese Verhältnisse kontrolliert verletzt , siehe Absatz 3). Angenommen, im betrachteten Beispiel ist die allgemeine Bevölkerung Punkte innerhalb eines Einheitsquadrats. Schichten sind Punktmengen innerhalb kleinerer Quadrate.
. , . , - .
1. :

, , — , 0.4. . -.

() :
import random
random.seed(100)
for i in range(500):
x, y = random.random(), random.random()
print x, y
, : , ; . , , , .
import random
random.seed(100)
cellsCount = 10
cellId = 0
for i in range(500):
cellVerticalIdx = (cellId / cellsCount) % cellsCount
cellHorizontalIdx = cellId % cellsCount
cellId += 1
left = float(cellVerticalIdx + 0) / cellsCount
right = float(cellVerticalIdx + 1) / cellsCount
top = float(cellHorizontalIdx + 1) / cellsCount
bottom = float(cellHorizontalIdx + 0) / cellsCount
x, y = random.random(), random.random()
x = left + x * (right - left)
y = bottom + y * (top - bottom)
print x, y
— . , — .

, , , .
, . ! , , , .
2. -
.
: , . , , . , .
: , .. . , , . , . , , — .
. :
. , . , «» , , . , , !
, , -, .. , . ( ), :

, , , . , , , , .
3.
-, -: , , , . A/B- , , , 0.5% , .
( , , ..), , .
Online Stratified Sampling: Evaluating Classifiers at Web-Scale Microsoft Research, .
, , .
— . - .
:
, !
, - :
, . , .
, : . , - , , .

, , . - SimilarWeb Alexa - , . , . , , .
: ? ? ?
Wenn es keine Antworten gibt oder diese unbefriedigend sind, kann es durchaus sein, dass die Daten Sie täuschen.