Das Suchen und Markieren verbundener Komponenten in Binärbildern ist einer der grundlegenden Algorithmen für die Bildanalyse und -verarbeitung. Insbesondere kann dieser Algorithmus in der Bildverarbeitung verwendet werden, um gemeinsame Strukturen im Bild mit ihrer anschließenden Analyse zu suchen und zu zählen.Im Rahmen dieses Artikels werden zwei Algorithmen zum Markieren verbundener Komponenten betrachtet, deren Implementierung in der Programmiersprache F # gezeigt wird. Und auch eine vergleichende Analyse der Algorithmen, die Suche nach Schwachstellen. Das Ausgangsmaterial für die Implementierung der Algorithmen stammt aus dem Buch „ Computer Vision“ (Autoren L. Shapiro, J. Stockman. Übersetzung aus dem Englischen von A. A. Boguslavsky, herausgegeben von S. M. Sokolov) .Einführung
Eine verbundene Komponente mit einem Wert von v ist eine Menge von C solchen Pixeln, die einen Wert von v haben, und jedes Paar dieser Pixel ist mit einem Wert von v verbunden
Es klingt abstrus, also schauen wir uns einfach das Bild an. Wir nehmen an, dass die Vordergrundpixel des Binärbildes als 1 und die Hintergrundpixel als 0 markiert sind .Nach der Verarbeitung des Bildes mit dem Markierungsalgorithmus der angeschlossenen Komponenten erhalten wir das folgende Bild. Hier werden anstelle von Pixeln verbundene Komponenten gebildet, die sich in ihrer Anzahl voneinander unterscheiden. In diesem Beispiel wurden 5 Komponenten gefunden, mit denen wie mit separaten Entitäten gearbeitet werden kann.Abbildung 1: Beschriftete verbundene Komponenten
Zwei Algorithmen, die zur Lösung eines solchen Problems verwendet werden können, werden nachstehend betrachtet.Rekursiver Markierungsalgorithmus
Wir werden zunächst den rekursionsbasierten Algorithmus als den offensichtlichsten betrachten. Das Funktionsprinzip eines solchen Algorithmus lautet wie folgt:Weisen Sie eine Bezeichnung zu, die wir als zugehörige Komponenten markieren, den Anfangswert.- Wir sortieren alle Punkte in der Tabelle, beginnend mit der Koordinate 0x0 (obere linke Ecke). Erhöhen Sie nach der Verarbeitung des nächsten Punkts das Etikett um eins
- Wenn das Pixel an der aktuellen Koordinate 1 ist , scannen wir alle vier Nachbarn dieses Punktes (oben, unten, rechts, links).
- 1, , 0
- , .
Wenn Sie also alle Punkte im Array sortieren und für jeden einen rekursiven Algorithmus aufrufen, erhalten Sie am Ende der Suche eine vollständig markierte Tabelle. Da geprüft wird, ob ein bestimmter Punkt bereits markiert wurde, wird jeder Punkt nur einmal verarbeitet. Die Rekursionstiefe hängt nur von der Anzahl der mit dem aktuellen Punkt verbundenen Nachbarn ab. Dieser Algorithmus eignet sich gut für Bilder ohne große Bildfüllung. Das heißt, Bilder, in denen dünne und kurze Linien vorhanden sind, und alles andere ist ein Hintergrundbild, das nicht verarbeitet wird. Darüber hinaus kann die Geschwindigkeit eines solchen Algorithmus höher sein als der zeilenweise Algorithmus (wir werden später in diesem Artikel darauf eingehen).Da zweidimensionale Binärbilder zweidimensionale Matrizen sind, werde ich beim Schreiben des Algorithmus mit den Konzepten von Matrizen arbeiten, über die ich einen separaten Artikel verfasst habe, der hier gelesen werden kann.Funktionale Programmierung am Beispiel der Arbeit mit Matrizen aus der Theorie der linearen Algebra.Betrachten und analysieren wir die F # -Funktion, die implementiert wird, im Detail rekursiver Beschriftungsalgorithmus für verbundene binäre Bildkomponentenlet recMarkingOfConnectedComponents matrix =
let copy = Matrix.clone matrix
let (|Value|Zero|Out|) (x, y) =
if x < 0 || y < 0
|| x > (copy.values.[0, *].Length - 1)
|| y > (copy.values.[*, 0].Length - 1) then
Out
else
let row = copy.values.[y, *]
match row.[x] with
| 0 -> Zero
| v -> Value(v)
let rec markBits x y value =
match (x, y) with
| Value(v) ->
if value > v then
copy.values.[y, x] <- value
markBits (x + 1) y value
markBits (x - 1) y value
markBits x (y + 1) value
markBits x (y - 1) value
| Zero | Out -> ()
let mutable value = 2
copy.values
|> Array2D.iteri (fun y x v -> if v = 1 then
markBits x y value
value <- value + 1)
copy
Wir deklarieren die
Funktion recMarkingOfConnectedComponents , die ein zweidimensionales Matrixarray verwendet , das in einen Datensatz vom Typ Matrix gepackt ist. Die Funktion ändert das ursprüngliche Array nicht. Erstellen Sie daher zuerst eine Kopie davon, die vom Algorithmus verarbeitet und zurückgegeben wird.let copy = Matrix.clone matrix
Erstellen Sie eine aktive Vorlage, die einen von drei Werten zurückgibt, um die Überprüfung der Indizes der angeforderten Punkte außerhalb des Arrays zu vereinfachen.Out - Der angeforderte Index ging über das zweidimensionale ArrayNull hinaus. - Der Punkt enthält ein Hintergrundpixel (gleich Null).Wert - Der angeforderte Index befindet sich innerhalb des Arrays.Diese Vorlage vereinfacht die Überprüfung der Koordinaten des Bildpunkts beim nächsten Rekursionsrahmen:let (|Value|Zero|Out|) (x, y) =
if x < 0 || y < 0
|| x > (copy.values.[0, *].Length - 1)
|| y > (copy.values.[*, 0].Length - 1) then
Out
else
let row = copy.values.[y, *]
match row.[x] with
| 0 -> Zero
| v -> Value(v)
Die MarkBits- Funktion wird als rekursiv deklariert und dient zur Verarbeitung des aktuellen Pixels und aller seiner Nachbarn (oben, unten, links, rechts):let rec markBits x y value =
match (x, y) with
| Value(v) ->
if value > v then
copy.values.[y, x] <- value
markBits (x + 1) y value
markBits (x - 1) y value
markBits x (y + 1) value
markBits x (y - 1) value
| Zero | Out -> ()
Die Funktion nimmt die folgenden Parameter als eine Eingabe:x - Zeilennummery - SpaltennummerWert - aktuellen Markierungswert den Pixel zu markierenVerwenden die Übereinstimmung / mit Konstrukt und der aktiven Schablone (oben), werden die Pixelkoordinaten überprüft , so dass sie nicht über die zweidimensionale gehen Array. Befindet sich der Punkt innerhalb eines zweidimensionalen Arrays, führen wir eine vorläufige Überprüfung durch, um den bereits verarbeiteten Punkt nicht zu verarbeiten.if value > v then
Andernfalls tritt eine unendliche Rekursion auf und der Algorithmus funktioniert nicht.Markieren Sie als Nächstes den Punkt mit dem aktuellen Markierungswert:copy.values.[y, x] <- value
Und wir verarbeiten alle seine Nachbarn und rufen rekursiv dieselbe Funktion auf:markBits (x + 1) y value
markBits (x - 1) y value
markBits x (y + 1) value
markBits x (y - 1) value
Nachdem wir den Algorithmus implementiert haben, muss er verwendet werden. Betrachten Sie den Code genauer.let mutable value = 2
copy.values
|> Array2D.iteri (fun y x v -> if v = 1 then
markBits x y value
value <- value + 1)
Legen Sie vor der Verarbeitung des Bildes den Anfangswert des Etiketts fest, der die verbundenen Pixelgruppen markiert.let mutable value = 2
Tatsache ist, dass die vorderen Pixel im Binärbild bereits auf 1 gesetzt sind. Wenn also der Anfangswert des Etiketts ebenfalls 1 ist , funktioniert der Algorithmus nicht. Daher muss der Anfangswert des Etiketts größer als 1 sein . Es gibt einen anderen Weg, um das Problem zu lösen. Markieren Sie vor dem Starten des Algorithmus alle auf 1 gesetzten Pixel mit einem Anfangswert von -1 . Dann können wir den Wert auf 1 setzen . Sie können es selbst tun, wenn Sie möchten. Beider nächsten Konstruktion mit der Funktion Array2D.iteri werden alle Punkte im Array durchlaufen , und wenn Sie während der Suche auf einen Punkt stoßen, der auf 1 gesetzt istDies bedeutet dann, dass es nicht verarbeitet wird und Sie dafür die rekursive Funktion markBits mit dem aktuellen Beschriftungswert aufrufen müssen . Alle auf 0 gesetzten Pixel werden vom Algorithmus ignoriert.Nach der rekursiven Verarbeitung des Punkts können wir davon ausgehen, dass die gesamte verbundene Gruppe, zu der dieser Punkt gehört, garantiert markiert ist, und Sie können den Beschriftungswert um 1 erhöhen , um ihn auf den nächsten verbundenen Punkt anzuwenden.Betrachten Sie ein Beispiel für die Anwendung eines solchen Algorithmus.let a = array2D [[1;1;0;1;1;1;0;1]
[1;1;0;1;0;1;0;1]
[1;1;1;1;0;0;0;1]
[0;0;0;0;0;0;0;1]
[1;1;1;1;0;1;0;1]
[0;0;0;1;0;1;0;1]
[1;1;0;1;0;0;0;1]
[1;1;0;1;0;1;1;1]]
let A = Matrix.ofArray2D a
let t = System.Diagnostics.Stopwatch.StartNew()
let R = Algorithms.recMarkingOfConnectedComponents A
t.Stop()
printfn "origin =\n %A" A.values
printfn "rec markers =\n %A" R.values
printfn "elapsed recurcive = %O" t.Elapsed
origin =
[[1; 1; 0; 1; 1; 1; 0; 1]
[1; 1; 0; 1; 0; 1; 0; 1]
[1; 1; 1; 1; 0; 0; 0; 1]
[0; 0; 0; 0; 0; 0; 0; 1]
[1; 1; 1; 1; 0; 1; 0; 1]
[0; 0; 0; 1; 0; 1; 0; 1]
[1; 1; 0; 1; 0; 0; 0; 1]
[1; 1; 0; 1; 0; 1; 1; 1]]
rec markers =
[[2; 2; 0; 2; 2; 2; 0; 3]
[2; 2; 0; 2; 0; 2; 0; 3]
[2; 2; 2; 2; 0; 0; 0; 3]
[0; 0; 0; 0; 0; 0; 0; 3]
[4; 4; 4; 4; 0; 5; 0; 3]
[0; 0; 0; 4; 0; 5; 0; 3]
[6; 6; 0; 4; 0; 0; 0; 3]
[6; 6; 0; 4; 0; 3; 3; 3]]
elapsed recurcive = 00:00:00.0037342
Zu den Vorteilen eines rekursiven Algorithmus gehört seine Einfachheit beim Schreiben und Verstehen. Es eignet sich hervorragend für Binärbilder mit großem Hintergrund und kleinen Pixelgruppen (z. B. Linien, kleine Flecken usw.). In diesem Fall kann die Bildverarbeitungsgeschwindigkeit hoch sein, da der Algorithmus das gesamte Bild in einem Durchgang verarbeitet.Die Nachteile liegen ebenfalls auf der Hand - dies ist eine Rekursion. Wenn das Bild aus großen Flecken besteht oder vollständig überflutet ist, sinkt die Verarbeitungsgeschwindigkeit stark (um Größenordnungen) und es besteht die Gefahr, dass das Programm aufgrund des Mangels an freiem Speicherplatz auf dem Stapel überhaupt abstürzt.Leider kann das Prinzip der Schwanzrekursion in diesem Algorithmus nicht angewendet werden, da die Schwanzrekursion zwei Anforderungen hat:- Jeder Rekursionsrahmen muss Berechnungen durchführen und das Ergebnis zum Akkumulator hinzufügen, der über den Stapel übertragen wird.
- Es sollte nicht mehr als einen rekursiven Funktionsaufruf in einem Rekursionsrahmen geben.
In unserem Fall führt die Rekursion keine endgültigen Berechnungen durch, die an den nächsten Rekursionsrahmen übergeben werden können, sondern modifiziert einfach ein zweidimensionales Array. Im Prinzip könnte dies umgangen werden, indem einfach eine einzelne Zahl zurückgegeben wird, was an sich nichts bedeutet. Wir machen auch 4 Anrufe rekursiv, da wir alle vier Nachbarn des Punktes verarbeiten müssen.Klassischer Algorithmus zum Markieren verbundener Komponenten basierend auf der Datenstruktur, um Suchvorgänge zu kombinieren
Der Algorithmus hat auch einen anderen Namen, "Algorithmus der progressiven Markierung", und hier werden wir versuchen, ihn zu analysieren.Der Algorithmus verarbeitet das Bild in zwei Durchgängen. Beim ersten Durchgang werden Äquivalenzklassen bestimmt und temporäre Bezeichnungen zugewiesen. Beim zweiten Durchgang wird jede temporäre Marke durch die Marke der entsprechenden Äquivalenzklasse ersetzt. Zwischen dem ersten und dem zweiten Durchgang wird der aufgezeichnete Satz von Äquivalenzbeziehungen, die in Form einer Binärtabelle gespeichert sind, verarbeitet, um Äquivalenzklassen zu bestimmen.
Die obige Definition ist noch verwirrender, daher werden wir versuchen, das Prinzip des Algorithmus auf andere Weise zu behandeln und von weitem zu beginnen.Zunächst werden wir uns mit der Definition einer vier- und achtverbundenen Nachbarschaft des aktuellen Punktes befassen . Schauen Sie sich die Bilder unten an, um zu verstehen, was es ist und was der Unterschied ist.Abbildung 2: Vierfach verbundene Komponente
Abbildung 2: Acht verbundene Komponente
Das erste Bild zeigt die vier verbundene Komponente eines Punkts, dh, der Algorithmus verarbeitet 4 Nachbarn des aktuellen Punkts (links, rechts, oben und unten). Dementsprechend bedeutet die achtverbundene Komponente eines Punktes, dass er 8 Nachbarn hat. In diesem Artikel werden wir mit vier verbundenen Komponenten arbeiten.Nun müssen Sie herausfinden, was eine Datenstruktur zum Kombinieren der Suche ist , die auf einigen Mengen basiert .Angenommen, wir haben zwei Sätze
Diese Mengen sind in Form der folgenden Bäume organisiert: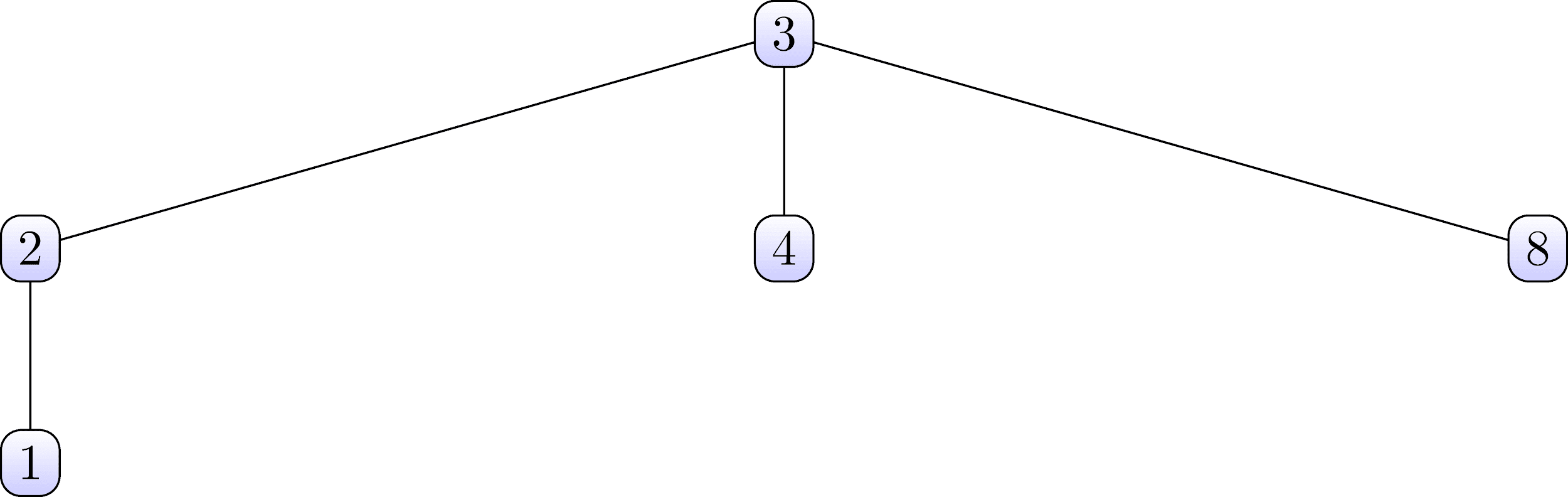
 Beachten Sie, dass in der ersten Menge die Knoten 3 root und in der zweiten die Knoten 6 sind.Nun betrachten wir die Datenstruktur für eine Suchvereinigung, die beide Mengen enthält, und organisieren auch ihre Baumstruktur .Abbildung 4: Datenstruktur für die Suchvereinigung
Beachten Sie, dass in der ersten Menge die Knoten 3 root und in der zweiten die Knoten 6 sind.Nun betrachten wir die Datenstruktur für eine Suchvereinigung, die beide Mengen enthält, und organisieren auch ihre Baumstruktur .Abbildung 4: Datenstruktur für die Suchvereinigung
Sehen Sie sich die obige Tabelle genau an und versuchen Sie, eine Beziehung zu den oben gezeigten festgelegten Bäumen zu finden. Die Tabelle sollte in vertikalen Spalten angezeigt werden. Es ist zu sehen, dass die Nummer 3Die erste Zeile entspricht der Nummer 0 in der zweiten Zeile. Und im ersten Baum ist die Zahl 3 die Wurzel des ersten Satzes. Analog können Sie feststellen, dass die Nummer 7 aus der ersten Zeile der Nummer 0 aus der zweiten Zeile entspricht. Die Zahl 7 ist auch die Wurzel des Baums des zweiten Satzes.Wir schließen daraus, dass die Zahlen aus der oberen Reihe die Tochterknoten der Mengen sind und die entsprechenden Zahlen aus der unteren Reihe ihre Elternknoten sind. Anhand dieser Regel können Sie beide Bäume aus der obigen Tabelle problemlos wiederherstellen.Wir analysieren solche Details, damit wir später leichter verstehen können, wie der progressive Markierungsalgorithmus funktioniert.. Lassen Sie uns zunächst auf die Tatsache eingehen, dass eine Reihe von Zahlen aus der ersten Zeile immer Zahlen von 1 bis zu einer bestimmten maximalen Zahl sind. Tatsächlich ist die maximale Anzahl der ersten Zeile der Maximalwert der Beschriftungen, mit denen die gefundenen verbundenen Komponenten markiert werden . Und einzelne Mengen sind Übergänge zwischen Beschriftungen, die als Ergebnis des ersten Durchgangs gebildet werden (wir werden später genauer darauf eingehen).Bevor Sie fortfahren, betrachten Sie den Pseudocode einiger Funktionen, die vom Algorithmus verwendet werden.Wir bezeichnen die Tabelle, die die Datenstruktur für die Join-Suche darstellt, als PARENT . Die nächste Funktion heißt find und verwendet die aktuelle Bezeichnung X als Parameterund eine Reihe von Eltern . Diese Prozedur verfolgt übergeordnete Zeiger bis zur Wurzel des Baums und findet die Bezeichnung des Wurzelknotens des Baums, zu dem X gehört . ̆ ̆ .
X —
PARENT — , ̆ -
procedure find(X, PARENT);
{
j := X;
while PARENT[j] <> 0
j := PARENT[j]; return(j);
}
Überlegen Sie, wie eine solche Funktion auf F # implementiert werden kannlet rec find x =
let index = Array.tryFindIndex ((=)x) parents.[0, *]
match index with
| Some(i) ->
match parents.[1, i] with
| p when p <> 0 -> find p
| _ -> x
| None -> x
Hier deklarieren wir eine rekursive Funktion des Funds , die die aktuelle Bezeichnung X annimmt . Das PARRENT- Array wird hier nicht übergeben, da es bereits im globalen Namespace vorhanden ist und die Funktion es bereits sieht und damit arbeiten kann.Zunächst versucht die Funktion, den Index des Etiketts in der obersten Zeile zu finden (da Sie das übergeordnete Element finden müssen, das sich in der untersten Zeile befindet.let index = Array.tryFindIndex ((=)x) parents.[0, *]
Wenn die Suche erfolgreich ist, erhalten wir das übergeordnete Element und vergleichen es mit 0 . Wenn das übergeordnete Element nicht gleich 0 ist , hat dieser Knoten auch ein übergeordnetes Element, und die Funktion ruft sich rekursiv auf, bis das übergeordnete Element gleich 0 ist . Dies bedeutet, dass wir den Wurzelknoten der Menge gefunden haben.match index with
| Some(i) ->
match parents.[1, i] with
| p when p <> 0 -> find p
| _ -> x
| None -> x
Die nächste Funktion, die wir brauchen, heißt Vereinigung . Es werden zwei Bezeichnungen X und Y sowie ein Array von PARENT benötigt . Diese Struktur modifiziert (falls erforderlich) die PARENT-Fusionsuntermenge, die eine Markierung X enthält , wobei die Menge die Markierung Y umfasst . Die Prozedur sucht nach den Stammknoten beider Beschriftungen. Wenn diese nicht übereinstimmen, wird der Knoten einer der Beschriftungen als übergeordneter Knoten der zweiten Beschriftung festgelegt. Es gibt also eine Vereinigung von zwei Sätzen. .
X — , .
Y — , .
PARENT — , ̆ -.
procedure union(X, Y, PARENT);
{
j := X;
k := Y;
while PARENT[j] <> 0
j := PARENT[j];
while PARENT[k]] <> 0
k := PARENT[k];
if j <> k then PARENT[k] := j;
}
Die F # -Implementierung sieht so auslet union x y =
let j = find x
let k = find y
if j <> k then parents.[1, k-1] <- j
Beachten Sie, dass die find Funktion wir bereits umgesetzt haben bereits hier verwendet wird .Der Algorithmus erfordert außerdem zwei zusätzliche Funktionen, die als Nachbarn und Beschriftungen bezeichnet werden . Die Nachbarfunktion gibt die Menge der benachbarten Punkte links und oben (da in unserem Fall der Algorithmus mit einer Komponente mit vier Verbindungen arbeitet) vom angegebenen Pixel zurück, und die Beschriftungsfunktion gibt die Menge der Beschriftungen zurück, die bereits der gegebenen Menge von Pixeln zugewiesen wurden, die die Nachbarfunktion zurückgegeben hat . In unserem Fall werden wir diese beiden Funktionen nicht implementieren, sondern nur eine erstellen, die beide Funktionen kombiniert und die gefundenen Beschriftungen zurückgibt.let neighbors_labels x y =
match (x, y) with
| (0, 0) -> []
| (0, _) -> [step1.[0, y-1]]
| (_, 0) -> [step1.[x-1, 0]]
| _ -> [step1.[x, y-1]; step1.[x-1, y]]
|> List.filter ((<>)0)
Mit Blick auf die Zukunft werde ich sofort sagen, dass das Array step1 , das die Funktion verwendet, bereits im globalen Raum vorhanden ist und das Ergebnis der Verarbeitung des Algorithmus beim ersten Durchgang enthält. Ich möchte dem zusätzlichen Filter besondere Aufmerksamkeit schenken.|> List.filter ((<>)0)
Es werden alle Ergebnisse abgeschnitten, die 0 sind . Das heißt, wenn das Etikett 0 enthält , handelt es sich um einen Punkt im Hintergrundbild, der nicht verarbeitet werden muss. Dies ist eine sehr wichtige Nuance, die in dem Buch, aus dem wir Beispiele nehmen, nicht erwähnt wird. Dennoch wird der Algorithmus ohne eine solche Überprüfung nicht funktionieren.Schritt für Schritt nähern wir uns dem Wesen des Algorithmus. Schauen wir uns noch einmal das Bild an, das wir verarbeiten müssen.Abbildung 5: Original-Binärbild
Erstellen Sie vor der Verarbeitung ein leeres Array step1 , in dem das Ergebnis des ersten Durchlaufs gespeichert wird.Abbildung 6: Array-Schritt 1 zum Speichern der primären Verarbeitungsergebnisse
Betrachten Sie die ersten Schritte der primären Datenverarbeitung (nur die ersten drei Zeilen des ursprünglichen Binärbilds).Bevor wir uns Schritt für Schritt mit dem Algorithmus befassen, schauen wir uns den Pseudocode an, der das allgemeine Funktionsprinzip erklärt. .
B — .
LB — .
procedure classical_with_union-find(B, LB);
{
“ .” initialize();
“ 1 ̆ L .”
for L := 0 to MaxRow
{
“ L ”
for P := 0 to MaxCol
LB[L,P] := 0;
“ L.”
for P := 0 to MaxCol
if B[L,P] == 1 then
{
A := prior_neighbors(L,P);
if isempty(A)
then {M := label; label := label + 1;};
else M := min(labels(A));
LB[L,P] := M;
for X in labels(A) and X <> M
union(M, X, PARENT);
}
}
“ 2 , 1, .”
for L := 0 to MaxRow
for P := 0 to MaxCol
if B[L, P] == 1
then LB[L,P] := find(LB[L,P], PARENT);
};
LB ( step1) ( ).
Abbildung 7: Schritt 1. Punkt (0,0), Beschriftung = 1
Abbildung 8: Schritt 2. Punkt (1,0), Beschriftung = 1
Abbildung 9: Schritt 2. Punkt (2.0), Bezeichnung = 1
Abbildung 10: Schritt 4. Punkt (3.0), Beschriftung = 2
Abbildung 11: Letzter Schritt, Endergebnis des ersten Durchgangs
Bitte beachten Sie, dass wir durch die anfängliche Verarbeitung des Originalbildes zwei Sätze erhalten haben
Visuell kann dies als Kontakt der Markierungen 1 und 2 (Koordinaten der Punkte (1,3) und (2,3) ) und der Markierungen 3 und 7 (Koordinaten der Punkte (7,7) und (7,6) ) angesehen werden. Aus Sicht der Datenstruktur für die Suchvereinigung wird dieses Ergebnis erhalten.Abbildung 12: Berechnete Datenstruktur für die Suchaggregation
Nach der endgültigen Verarbeitung des Bildes unter Verwendung der erhaltenen Datenstruktur erhalten wir das folgende Ergebnis.Abbildung 13: Endergebnis
Jetzt haben alle verbundenen Komponenten eindeutige Beschriftungen und können in nachfolgenden Algorithmen zur Verarbeitung verwendet werden.Die F # -Code-Implementierung ist wie folgtlet markingOfConnectedComponents matrix =
// up to 10 markers
let parents = Array2D.init 2 10 (fun x y -> if x = 0 then y+1 else 0)
// create a zero initialized copy
let step1 = (Matrix.cloneO matrix).values
let rec find x =
let index = Array.tryFindIndex ((=)x) parents.[0, *]
match index with
| Some(i) ->
match parents.[1, i] with
| p when p <> 0 -> find p
| _ -> x
| None -> x
let union x y =
let j = find x
let k = find y
if j <> k then parents.[1, k-1] <- j
// returns up and left neighbors of pixel
let neighbors_labels x y =
match (x, y) with
| (0, 0) -> []
| (0, _) -> [step1.[0, y-1]]
| (_, 0) -> [step1.[x-1, 0]]
| _ -> [step1.[x, y-1]; step1.[x-1, y]]
|> List.filter ((<>)0)
let mutable label = 0
matrix.values
|> Array2D.iteri (fun x y v ->
if v = 1 then
let n = neighbors_labels x y
let m = if n.IsEmpty then
label <- label + 1
label
else
n |> List.min
n |> List.iter (fun v -> if v <> m then union m v)
step1.[x, y] <- m)
let step2 = matrix.values
|> Array2D.mapi (fun x y v ->
if v = 1 then step1.[x, y] <- find step1.[x, y]
step1.[x, y])
{ values = step2 }
Eine zeilenweise Erklärung des Codes macht keinen Sinn mehr, da alles oben beschrieben wurde. Hier können Sie einfach den F # -Code dem Pseudocode zuordnen, um zu verdeutlichen, wie er funktioniert.Benchmarking-Algorithmen
Vergleichen wir die Datenverarbeitungsgeschwindigkeit mit beiden Algorithmen (rekursiv und zeilenweise).let a = array2D [[1;1;0;1;1;1;0;1]
[1;1;0;1;0;1;0;1]
[1;1;1;1;0;0;0;1]
[0;0;0;0;0;0;0;1]
[1;1;1;1;0;1;0;1]
[0;0;0;1;0;1;0;1]
[1;1;0;1;0;0;0;1]
[1;1;0;1;0;1;1;1]]
let A = Matrix.ofArray2D a
let t1 = System.Diagnostics.Stopwatch.StartNew()
let R1 = Algorithms.markingOfConnectedComponents A
t1.Stop()
let t2 = System.Diagnostics.Stopwatch.StartNew()
let R2 = Algorithms.recMarkingOfConnectedComponents A
t2.Stop()
printfn "origin =\n %A" A.values
printfn "markers =\n %A" R1.values
printfn "rec markers =\n %A" R2.values
printfn "elapsed lines = %O" t1.Elapsed
printfn "elapsed recurcive = %O" t2.Elapsed
origin =
[[1; 1; 0; 1; 1; 1; 0; 1]
[1; 1; 0; 1; 0; 1; 0; 1]
[1; 1; 1; 1; 0; 0; 0; 1]
[0; 0; 0; 0; 0; 0; 0; 1]
[1; 1; 1; 1; 0; 1; 0; 1]
[0; 0; 0; 1; 0; 1; 0; 1]
[1; 1; 0; 1; 0; 0; 0; 1]
[1; 1; 0; 1; 0; 1; 1; 1]]
markers =
[[1; 1; 0; 1; 1; 1; 0; 3]
[1; 1; 0; 1; 0; 1; 0; 3]
[1; 1; 1; 1; 0; 0; 0; 3]
[0; 0; 0; 0; 0; 0; 0; 3]
[4; 4; 4; 4; 0; 5; 0; 3]
[0; 0; 0; 4; 0; 5; 0; 3]
[6; 6; 0; 4; 0; 0; 0; 3]
[6; 6; 0; 4; 0; 3; 3; 3]]
rec markers =
[[2; 2; 0; 2; 2; 2; 0; 3]
[2; 2; 0; 2; 0; 2; 0; 3]
[2; 2; 2; 2; 0; 0; 0; 3]
[0; 0; 0; 0; 0; 0; 0; 3]
[4; 4; 4; 4; 0; 5; 0; 3]
[0; 0; 0; 4; 0; 5; 0; 3]
[6; 6; 0; 4; 0; 0; 0; 3]
[6; 6; 0; 4; 0; 3; 3; 3]]
elapsed lines = 00:00:00.0081837
elapsed recurcive = 00:00:00.0038338
Wie Sie in diesem Beispiel sehen können, übersteigt die Geschwindigkeit des rekursiven Algorithmus die Geschwindigkeit des zeilenweisen Algorithmus erheblich. Aber alles ändert sich, sobald wir beginnen, ein mit Volltonfarben gefülltes Bild zu verarbeiten. Aus Gründen der Klarheit werden wir auch die Größe auf 100 x 100 Pixel erhöhen.let a = Array2D.create 100 100 1
let A = Matrix.ofArray2D a
let t1 = System.Diagnostics.Stopwatch.StartNew()
let R1 = Algorithms.markingOfConnectedComponents A
t1.Stop()
printfn "elapsed lines = %O" t1.Elapsed
let t2 = System.Diagnostics.Stopwatch.StartNew()
let R2 = Algorithms.recMarkingOfConnectedComponents A
t2.Stop()
printfn "elapsed recurcive = %O" t2.Elapsed
elapsed lines = 00:00:00.0131790
elapsed recurcive = 00:00:00.2632489
Wie Sie sehen können, ist der rekursive Algorithmus bereits 25-mal langsamer als der lineare. Erhöhen wir die Größe des Bildes auf 200x200 Pixel.elapsed lines = 00:00:00.0269896
elapsed recurcive = 00:00:06.1033132
Der Unterschied ist schon viele hundert Mal. Ich stelle fest, dass der rekursive Algorithmus bereits bei einer Größe von 300 x 300 Pixel einen Stapelüberlauf verursacht und das Programm abstürzt.Zusammenfassung
Im Rahmen dieses Artikels wurde einer der grundlegenden Algorithmen zum Markieren verbundener Komponenten zur Verarbeitung von Binärbildern am Beispiel der Funktionssprache F # untersucht. Hier wurden Beispiele für die Implementierung rekursiver und klassischer Algorithmen gegeben, deren Funktionsprinzip erklärt, eine vergleichende Analyse anhand spezifischer Beispiele durchgeführt.Der hier diskutierte Quellcode kann auch auf dem MatrixAlgorithms-Githubangezeigt werden.Ich hoffe, der Artikel war für diejenigen interessant, die sich insbesondere für F # - und Bildverarbeitungsalgorithmen interessieren.