Aufgrund meiner 15-jährigen Erfahrung als Softwareentwickler und Teamleiter stoße ich sehr oft auf dasselbe. Das Programmieren wird zu einer Religion - selten versucht jemand, Technologie auf der Grundlage einer vernünftigen Auswahl einzuführen, wobei Einschränkungen, Portabilität, der Grad der Bindung an den Anbieter, der tatsächliche Preis, die Aussichten auf Technologie und die Lizenzfreiheit berücksichtigt werden. Entwickler gehen zu Konferenzen oder lesen Beiträge - starten Sie einen Hype, und ihre IT-Direktoren und -Manager werden nicht nur bei Veranstaltungen, verschiedenen Visionären, Verkäufern und Beratern mit Geschichten über eine glänzende, agile Zukunft versorgt. Und es stellt sich heraus, dass die Technologien im Projekt enthalten waren, ohne die Bequemlichkeit der Entwicklung und Implementierung zu berücksichtigen, nicht funktionale Anforderungen des Projekts, sondern weil es Hype ist und Google sich selbst verwendet,amazon empfiehlt (obwohl ihre offenen Stellen besagen, dass sie es selbst nicht oft nutzen) oder die höchste Entscheidung wurde vom Management des Unternehmens getroffen, "dies" umzusetzen.
Was beeinflusst die Auswahl der Datenbank?
Aus meiner Sicht muss ich bei der Auswahl einer Datenbank mindestens die folgenden Kompromisse lösen:- Transaktionsverarbeitung in Echtzeit oder Online-Analyseverarbeitung
- vertikal oder horizontal skalierbar
- im Fall einer verteilten Basis - Datenkonsistenz / Verfügbarkeit / Trennungswiderstand (CAP-Theorem)
- ein bestimmtes Datenschema und Einschränkungen in der Datenbank oder im Speicher, für die kein Datenschema erforderlich ist
- Datenmodell - Schlüsselwert, hierarchisch, grafisch, dokumentarisch oder relational
- Verarbeitungslogik so nah wie möglich an Daten oder die gesamte Verarbeitung in der Anwendung
- arbeiten hauptsächlich im RAM oder mit einem Festplattensubsystem
- universelle Lösung oder spezialisiert
- Wir nutzen das vorhandene Fachwissen in einer Datenbank, die für die Anforderungen des Projekts nicht besonders geeignet ist, oder entwickeln eine neue in geeigneter, aber nicht vertrauter Ausbildung, „Blut und Schweiß“ (dies gilt nicht nur für die Entwicklung, sondern auch für den Betrieb).
- eingebaut oder in einem anderen Prozess / Netzwerk
- Hipster oder retrograd
Oft bekommen wir ein „Geschenk“ für die implementierte Lösung:- Abfragesprache "Alien"
- Die einzige native API für die Arbeit mit der Datenbank, die den Übergang zu anderen Datenbanken erschwert (Zeit, Teamaufwand und Projektbudget wurden aufgewendet).
- Nichtverfügbarkeit von Treibern für andere Plattformen / Sprachen / Betriebssysteme
- Fehlen von Quellcodes, Beschreibungen des Datenformats auf der Festplatte (oder Verbot von Reverse Engineering-Lizenzen, insbesondere Oracle mit dem Buggy Coherence)
- Lizenzkostenwachstum von Jahr zu Jahr
- eigenes Ökosystem und Schwierigkeiten, Spezialisten zu finden
- , ,
Die horizontale Skalierung von Systemen ist recht komplex und erfordert Team-Know-how. Erfahrene Entwickler sind auf dem Markt ziemlich teuer, verteilte Anwendungen sind schwieriger zu entwickeln, zu debuggen und zu testen. Wenn es daher möglich ist, den Server auf einen leistungsstärkeren Server und die vom System zugelassene Datenmenge umzustellen, tun sie dies häufig. Jetzt können Server Terabyte RAM und Hunderte von Prozessorkernen an Bord haben. Daher wird es wie nie zuvor wichtig, alle Serverressourcen so effizient wie möglich zu nutzen. Die Kosten für Datenbanklizenzen sind ebenfalls wichtig. Wenn sie von Prozessorkernen verkauft werden, kann das Betriebsbudget selbst bei vertikaler Skalierung so viel kosten wie ein Superpower-Space-Programm. Daher ist es wichtig, dies zu berücksichtigen, um die Datenbankleistung aufgrund von Lizenzen nicht skalieren zu können.Es ist klar, dass sie mit Hilfe des Marketings versuchen werden, Sie davon zu überzeugen, dass nur die Lösung eines bestimmten Unternehmens alle Ihre Probleme lösen wird (aber sie schweigen darüber, wie viele neue auftauchen werden). Es gibt keine ideale Datenbank, die für jeden geeignet und für alles geeignet ist.Daher werden wir in absehbarer Zeit weiterhin mehrere verschiedene Datenbanken unterstützen, um dieselben Daten für verschiedene Arten von Abfragen in verschiedenen Systemen zu verarbeiten. Keine Lösung für Data Fabric ohne Daten-Caching. Data Lake kann hinsichtlich Leistung und Abfrageoptimalität noch nicht mit Datenbanken mit massenparalleler Architektur verglichen werden. Transaktionsdaten werden weiterhin in PostgreSQL, Oracle, MS SQL Server gespeichert, analytische Abfragen in Citus, Greenplum, Snowflake, Redshift, Vertica, Impala, Teradata und Rohdatensümpfe in HDFS / S3 / ADLS (Azure) werden von Dremio verwaltet , Rotverschiebungsspektrum, Apache Spark, Presto.Die oben aufgeführten Lösungen eignen sich jedoch nur schlecht zur Analyse von Zeitreihendaten mit einer geringen Antwortzeit. Aufgrund seiner Beliebtheit bei der Arbeit mit Zeitreihendaten gehört es nun zu den Favoriten von InfluxDB. In der In-Memory-Datenbanknische behalten kdb + und memSQL ihren Platz.QuestDB
Was kann all diesen Open-Source- QuestDB- Lösungen mit einer Apache-Lizenz entgegenstehen?- Ein Versuch, die Hardware für analytische Abfragen optimal zu nutzen - Vektorisierung von Aggregationsfunktionen, Arbeiten mit Daten über Speicherzuordnungsdateien
- SQL als Sprache für DML-Abfragen und DDL-Operationen zur Verwaltung der Datenbankstruktur
- Unterstützung für Join-Tabellen, die für die Zeitreihen-DB spezifisch sind
- Unterstützung für Fenster- und Aggregationsfunktionen in SQL
- die Möglichkeit, eine Datenbank in eine Anwendung in der JVM einzubetten
- JVM, ServiceLoader
- Influx DB line protocol (ILP) UDP Telegraf. «What makes QuestDB faster than InfluxDB»
- PostgreSql 11 PostgreSQL: JDBC, ODBC psql
- web - REST endpoint , SQL json
- ,
- zero-GC API, .
- ( )
- 64 Windows, Linux, OSX, ARM Linux FreeBSD
- , open source,
Wann diese Datenbank für Sie nützlich sein kann - wenn Sie Finanzsysteme auf der JVM mit geringer Latenz entwickeln und eine Lösung für die Datenanalyse im RAM benötigen. Als Ersatz für kdb + aufgrund der Lizenzkosten. Wenn Sie Metriken gemäß dem Influx / Telegraf-Protokoll erfassen, die Leistung und Benutzerfreundlichkeit der Arbeit mit InfluxDB jedoch nicht zufriedenstellend ist. Wenn Ihr Projekt auf der JVM ausgeführt wird und Sie eine integrierte Datenbank zum Speichern von Metriken oder Anwendungsdaten benötigen, die nur hinzugefügt und nicht aktualisiert werden.Die neue Version 4.2.0 mit Unterstützung für SIMD-Anweisungen löste eine Welle von Kommentaren zu Reddit aus . Damit Fans am Wettbewerb um das Wissen über moderne Hardware und deren effektive Programmierung teilnehmen können, empfehle ich, in den Kommentaren mit dem Autor der Datenbank (bluestreak01) zu sprechen!SIMD-Operationen
Das Projektteam führte einen Test mit synthetischen Daten durch und verglich QuestDB 4.2.0 mit kdb 4.0, um eine Milliarde Werte zu aggregieren, wobei die SIMD-Anweisungen der Prozessoren genutzt wurden.Auf der Intel 8850H-Plattform: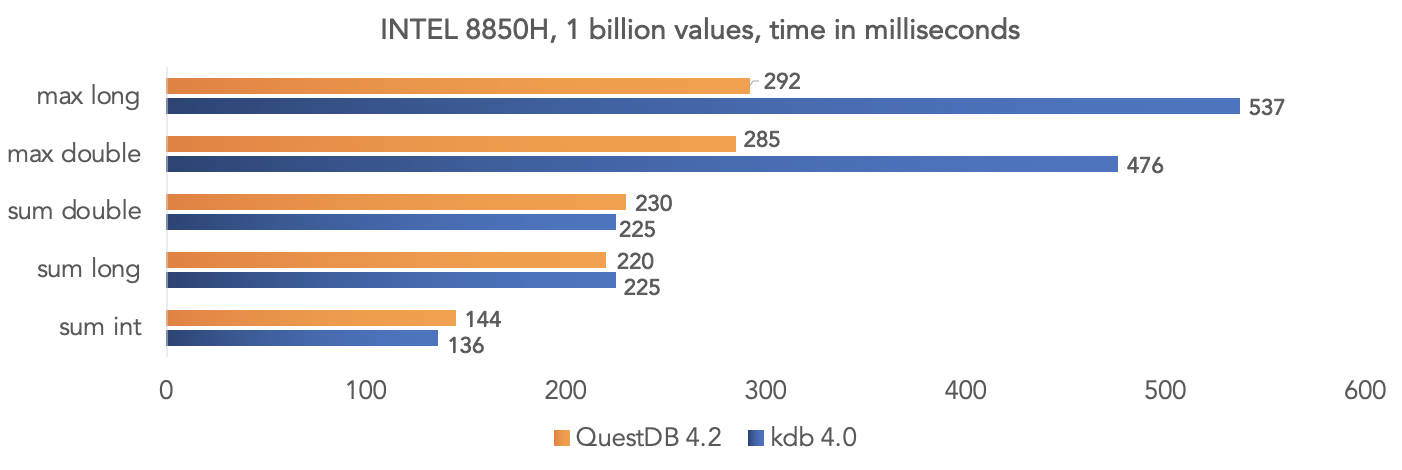 Auf der AMD Ryzen 3900X-Plattform:
Auf der AMD Ryzen 3900X-Plattform: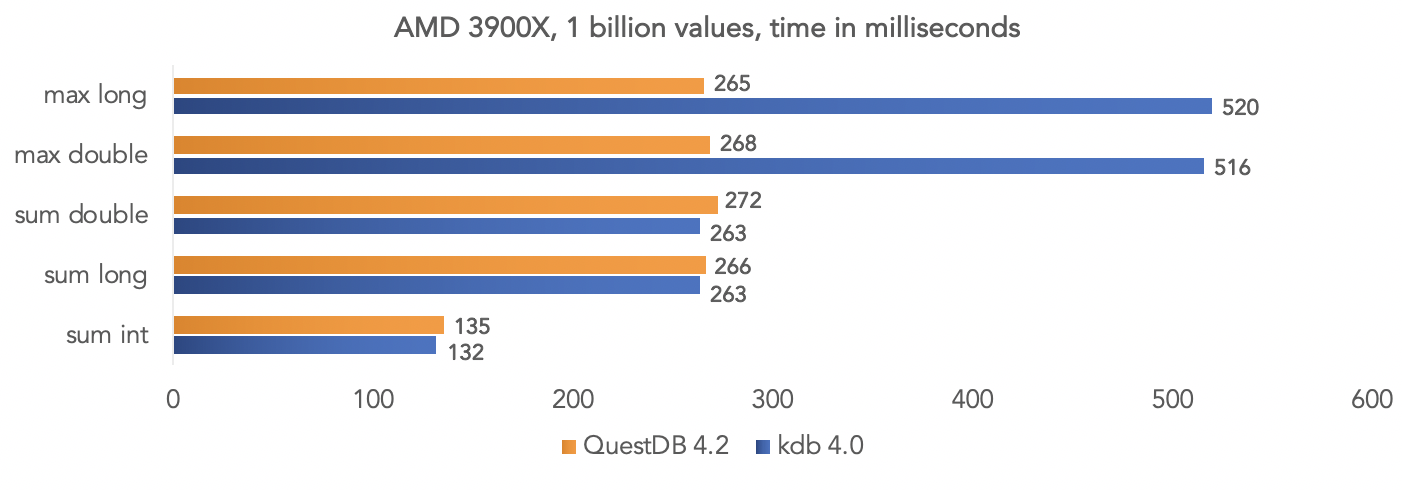 Es ist klar, dass dies alles Tests in einem „Vakuum“ sind, aber Sie können Ihre Daten vergleichen, wenn Ihr Projekt kdb verwendet, und die Ergebnisse mit der Community teilen.
Es ist klar, dass dies alles Tests in einem „Vakuum“ sind, aber Sie können Ihre Daten vergleichen, wenn Ihr Projekt kdb verwendet, und die Ergebnisse mit der Community teilen.Docker-Datenbank-Image ausführen
Die Datenbank wird mit jeder Version auf Dockerhub veröffentlicht. Weitere Details sind in der Projektdokumentation beschrieben .Holen Sie sich das QuestDB-Bild:docker pull questdb/questdb
Wir starten:docker run --rm -it -p 9000:9000 -p 8812:8812 questdb/questdb
Danach können Sie über das PostgreSQL-Protokoll eine Verbindung zu Port 8812 herstellen. Die Webkonsole ist über Port 9000 verfügbar.JDBC-Zugriff
Abhängig von unserem Projekt fügen wir den PostrgreSQL-JDBC-Treiber org.postgresql: postgresql: 42.2.12 hinzu . Für diesen Test verwende ich mein QuestDB-Modul für Testcontainer . Der Test ist auf github zusammen mit dem Build-Skript verfügbar :import org.junit.jupiter.api.Test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import static org.assertj.core.api.Assertions.*;
public class QuestDbDriverTest {
@Test
void containerIsUpTestByJdbcInvocation() throws Exception {
try (Connection connection = DriverManager.getConnection("jdbc:tc:questdb:///?user=admin&password=quest")){
try (Statement statement = connection.createStatement()){
try (ResultSet resultSet = statement.executeQuery("select 42 from long_sequence(1)")){
resultSet.next();
assertThat(resultSet.getInt(1)).isEqualTo(42);
}
}
}
}
}
Das Ausführen von Docker führt zu zusätzlichem Overhead. Dies kann vermieden werden, indem einfach org.questdb: core: jar: 4.2.0 als Abhängigkeit vom Projekt implementiert und io.questdb.ServerMain ausgeführt wird:import io.questdb.ServerMain;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.io.TempDir;
import java.nio.file.Path;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.Statement;
public class QuestDbJdbcTest {
@Test
void embeddedServerStartTest(@TempDir Path tempDir) throws Exception{
ServerMain.main(new String[]{"-d", tempDir.toString()});
try (DriverManager.getConnection("jdbc:postgresql://localhost:8812/", "admin", "quest")){
try (Statement statement = connection.createStatement()){
try (ResultSet resultSet = statement.executeQuery("select 42 from long_sequence(1)")){
resultSet.next();
assertThat(resultSet.getInt(1)).isEqualTo(42);
}
}
}
}
}
Einbetten in Java-Anwendung
Dies ist jedoch der schnellste Weg, um mit der Datenbank mithilfe der Inprocess-Java-API zu arbeiten:import io.questdb.cairo.CairoEngine;
import io.questdb.cairo.DefaultCairoConfiguration;
import io.questdb.griffin.CompiledQuery;
import io.questdb.griffin.SqlCompiler;
import io.questdb.griffin.SqlExecutionContextImpl;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.io.TempDir;
import java.nio.file.Path;
public class TruncateExecuteTest {
@Test
void truncate(@TempDir Path tempDir) throws Exception{
SqlExecutionContextImpl executionContext = new SqlExecutionContextImpl();
DefaultCairoConfiguration configuration = new DefaultCairoConfiguration(tempDir.toAbsolutePath().toString());
try (CairoEngine engine = new CairoEngine(configuration)) {
try (SqlCompiler compiler = new SqlCompiler(engine)) {
CompiledQuery createTable = compiler.compile("create table tr_table(id long,name string)", executionContext);
compiler.compile("truncate table tr_table", executionContext);
}
}
}
}
Webkonsole
Das Projekt umfasst eine Web - Konsole für QuestDB Abfragen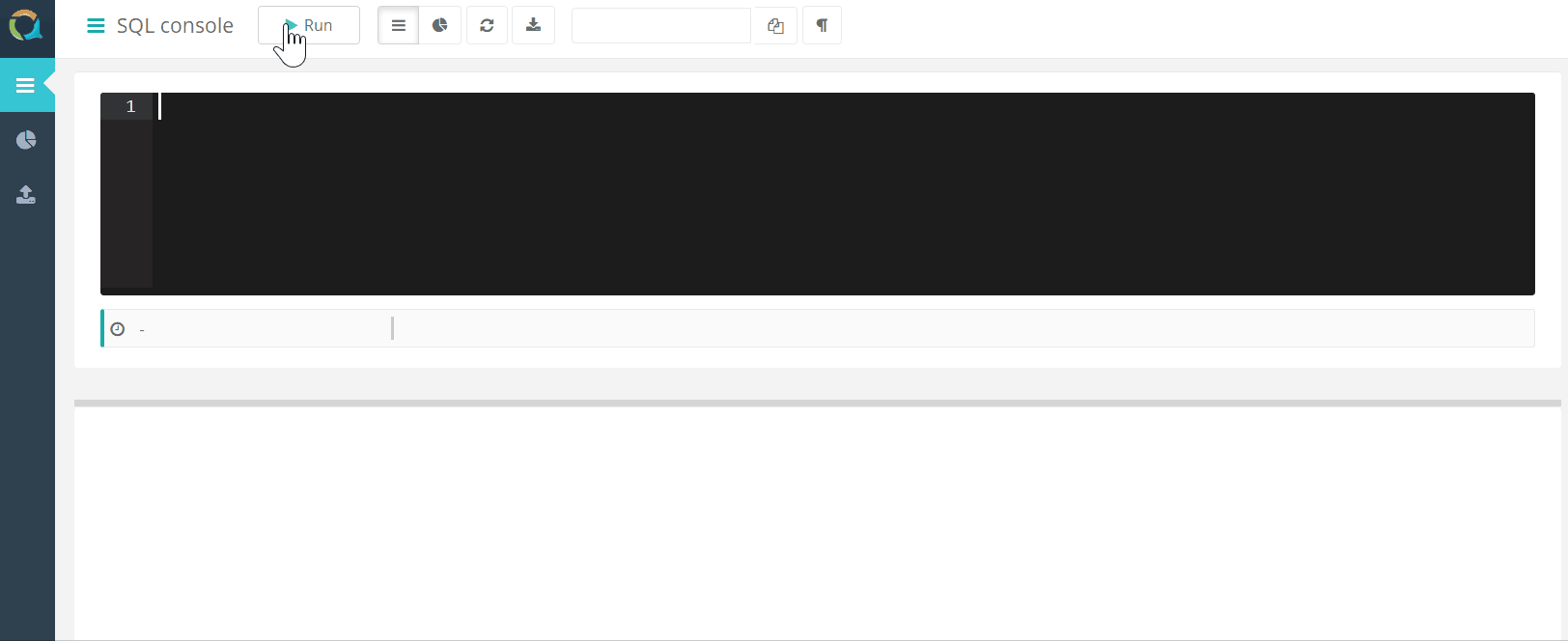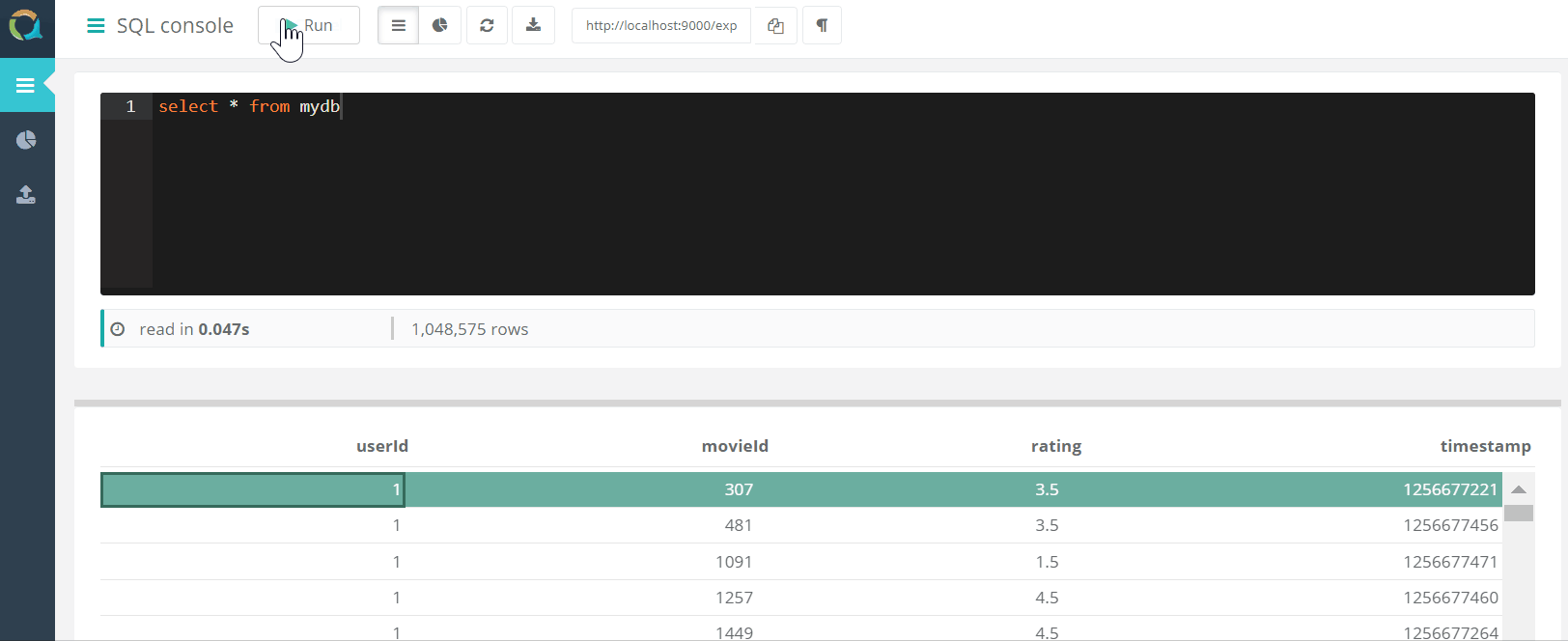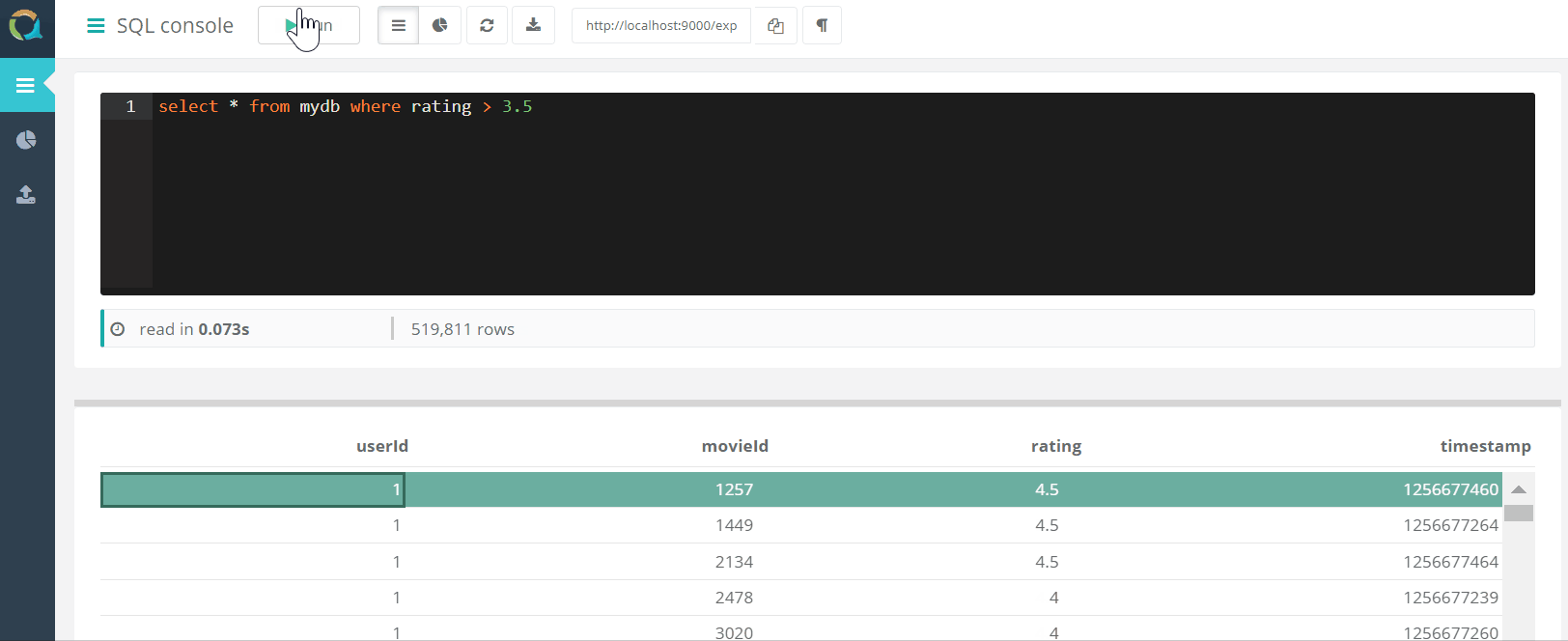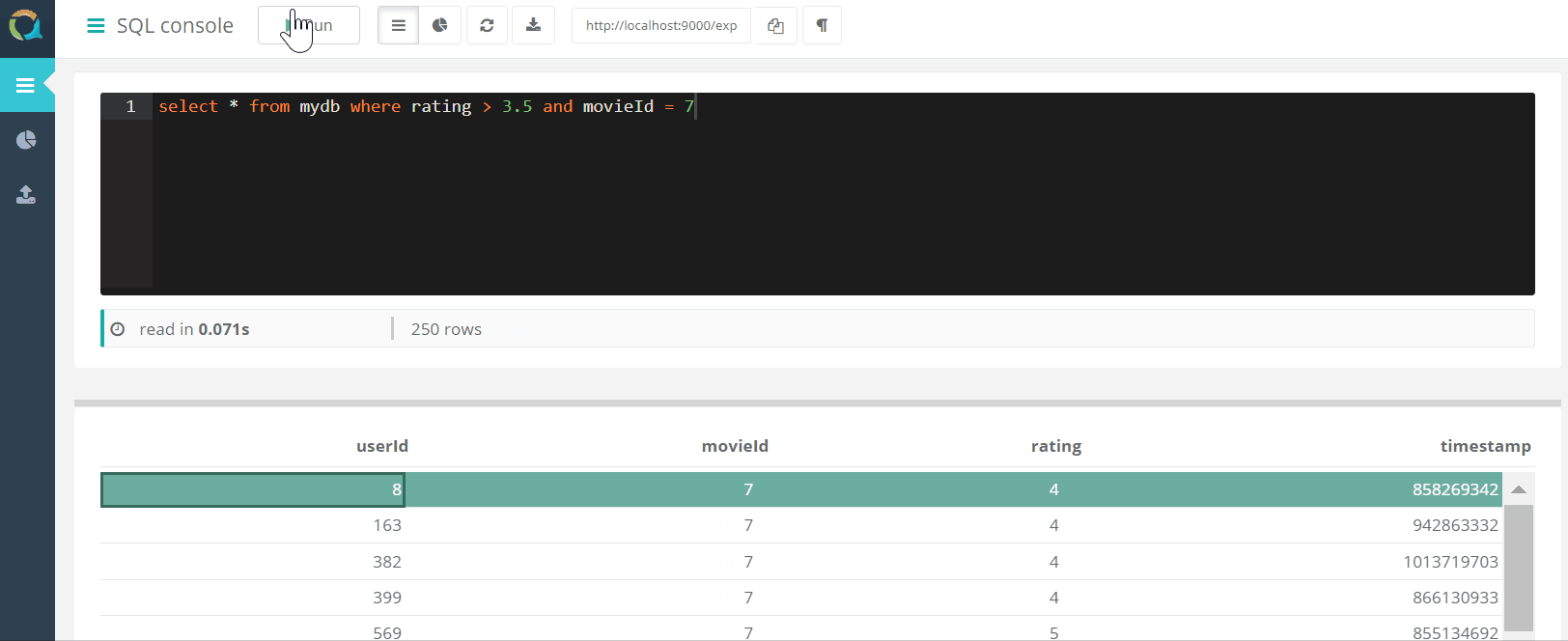 und Daten in eine Datenbank im CSV - Format über einen Browser herunterladen.
und Daten in eine Datenbank im CSV - Format über einen Browser herunterladen.
Benötigen Sie eine andere Datenbank?
Dieses Projekt ist jung und weist noch einige Unternehmensfunktionen auf, entwickelt sich jedoch recht schnell und mehrere Mitwirkende arbeiten aktiv an dem Projekt. Ich verfolge QuestDB seit letztem August und habe einige Erweiterungen für dieses Projekt entwickelt ( jdbc-Funktion und osquery ) und dieses Projekt auch in Testcontainer integriert. Jetzt versuche ich, meine aktuellen Probleme in Dremio durch inkrementelles Hochladen von Daten, Partitionieren von Daten und langwierige Transaktionen zu Datenquellen in der Produktion mit QuestDB zu lösen und durch Datenexportfunktionen zu ergänzen. Ich plane, meine Erfahrungen in den folgenden Veröffentlichungen zu teilen. Es besticht mich besonders, dass ich meine Funktionen und meine Datenbank auf der mir vertrauten Plattform debuggen und Unit-Tests schreiben kann, die mit Lichtgeschwindigkeit ausgeführt werden.Sie entscheiden sich als erfahrener Entwickler. Auch hier ist QuestDB kein Ersatz für OLTP-Datenbanken - PostgreSQL, Oracle, MS SQL Server, DB2 oder sogar ein H2- Ersatz für Testsin der JVM. Dies ist eine leistungsstarke spezialisierte Open-Source-Datenbank mit Unterstützung für PostgreSQL-, Influx / Telegraf-Netzwerkprotokolle. Wenn Ihr Nutzungsszenario zu den darin implementierten Funktionen und dem Hauptszenario für die Verwendung einer Spaltendatenbank passt, ist die Auswahl gerechtfertigt!