Dieser Artikel ist nützlich für diejenigen, die gerade erst begonnen haben, sich mit der Microservice-Architektur und dem Apache Kafka-Service vertraut zu machen. Das Material erhebt keinen Anspruch auf ein detailliertes Tutorial, hilft Ihnen jedoch dabei, schnell mit dieser Technologie zu beginnen. Ich werde darüber sprechen, wie Kafka unter Windows 10 installiert und konfiguriert wird. Wir werden auch ein Projekt mit Intellij IDEA und Spring Boot erstellen.Wozu?
Schwierigkeiten beim Verständnis verschiedener Tools hängen häufig damit zusammen, dass der Entwickler noch nie auf Situationen gestoßen ist, in denen diese Tools möglicherweise benötigt werden. Bei Kafka ist das genau das gleiche. Wir beschreiben die Situation, in der diese Technologie nützlich sein wird. Wenn Sie eine monolithische Anwendungsarchitektur haben, benötigen Sie natürlich kein Kafka. Mit dem Übergang zu Microservices ändert sich alles. Tatsächlich ist jeder Mikrodienst ein separates Programm, das die eine oder andere Funktion ausführt und das unabhängig von anderen Mikrodiensten gestartet werden kann. Microservices können mit Mitarbeitern im Büro verglichen werden, die an separaten Schreibtischen sitzen und ihr Problem unabhängig lösen. Die Arbeit eines solchen verteilten Teams ist ohne zentrale Koordination undenkbar.Die Mitarbeiter sollten in der Lage sein, Nachrichten und Ergebnisse ihrer Arbeit miteinander auszutauschen. Apache Kafka für Microservices wurde entwickelt, um dieses Problem zu lösen.Apache Kafka ist ein Nachrichtenbroker. Damit können Microservices miteinander interagieren und wichtige Informationen senden und empfangen. Es stellt sich die Frage, warum Sie nicht die reguläre POST-Anfrage für diese Zwecke verwenden, in deren Hauptteil Sie die erforderlichen Daten übertragen und die Antwort auf die gleiche Weise erhalten können. Dieser Ansatz weist eine Reihe offensichtlicher Nachteile auf. Beispielsweise kann ein Produzent (ein Dienst, der eine Nachricht sendet) Daten nur in Form einer Antwort als Antwort auf eine Anfrage eines Verbrauchers (eines Dienstes, der Daten empfängt) senden. Angenommen, ein Verbraucher sendet eine POST-Anfrage und der Hersteller beantwortet sie. Aus irgendeinem Grund kann der Verbraucher die Antwort derzeit nicht akzeptieren. Was wird mit den Daten passieren? Sie werden verloren gehen. Der Verbraucher muss erneut eine Anfrage senden und hofft, dass sich die Daten, die er erhalten wollte, in dieser Zeit nicht geändert haben.und der Hersteller ist immer noch bereit, die Anfrage anzunehmen.Apache Kafka löst dieses und viele andere Probleme, die beim Austausch von Nachrichten zwischen Microservices auftreten. Es wird nicht verkehrt sein, daran zu erinnern, dass ein ununterbrochener und bequemer Datenaustausch eines der Hauptprobleme ist, die gelöst werden müssen, um den stabilen Betrieb der Mikroservice-Architektur sicherzustellen.Installieren und konfigurieren Sie ZooKeeper und Apache Kafka unter Windows 10
Das erste, was Sie wissen müssen, um loszulegen, ist, dass Apache Kafka über dem ZooKeeper-Dienst ausgeführt wird. ZooKeeper ist ein verteilter Konfigurations- und Synchronisierungsdienst, und das ist alles, was wir in diesem Zusammenhang darüber wissen müssen. Wir müssen es herunterladen, konfigurieren und ausführen, bevor wir mit Kafka beginnen können. Stellen Sie vor der Arbeit mit ZooKeeper sicher, dass JRE installiert und konfiguriert ist.Sie können die neueste Version von ZooKeeper von der offiziellen Website herunterladen .Wir extrahieren die Dateien aus dem heruntergeladenen ZooKeeper-Archiv in einen Ordner auf der Festplatte.Im zookeeper-Ordner mit der Versionsnummer finden wir den conf-Ordner und darin die Datei „zoo_sample.cfg“. Kopieren Sie es und ändern Sie den Namen der Kopie in "zoo.cfg". Öffnen Sie die Kopierdatei und suchen Sie die Zeile dataDir = / tmp / zookeeper darin. In dieser Zeile schreiben wir den vollständigen Pfad in unseren Ordner zookeeper-x.x.x. Für mich sieht es so aus: dataDir = C: \\ ZooKeeper \\ zookeeper-3.6.0
Kopieren Sie es und ändern Sie den Namen der Kopie in "zoo.cfg". Öffnen Sie die Kopierdatei und suchen Sie die Zeile dataDir = / tmp / zookeeper darin. In dieser Zeile schreiben wir den vollständigen Pfad in unseren Ordner zookeeper-x.x.x. Für mich sieht es so aus: dataDir = C: \\ ZooKeeper \\ zookeeper-3.6.0 Jetzt fügen wir die Systemumgebungsvariable hinzu: ZOOKEEPER_HOME = C: \ ZooKeeper \ zookeeper-3.4.9 und am Ende der Systemvariablen Path den Eintrag :;% ZOOKEEPER_HOME % \ Behälter;Führen Sie die Befehlszeile aus und schreiben Sie den Befehl:
Jetzt fügen wir die Systemumgebungsvariable hinzu: ZOOKEEPER_HOME = C: \ ZooKeeper \ zookeeper-3.4.9 und am Ende der Systemvariablen Path den Eintrag :;% ZOOKEEPER_HOME % \ Behälter;Führen Sie die Befehlszeile aus und schreiben Sie den Befehl:zkserver
Wenn alles richtig gemacht ist, sehen Sie ungefähr Folgendes.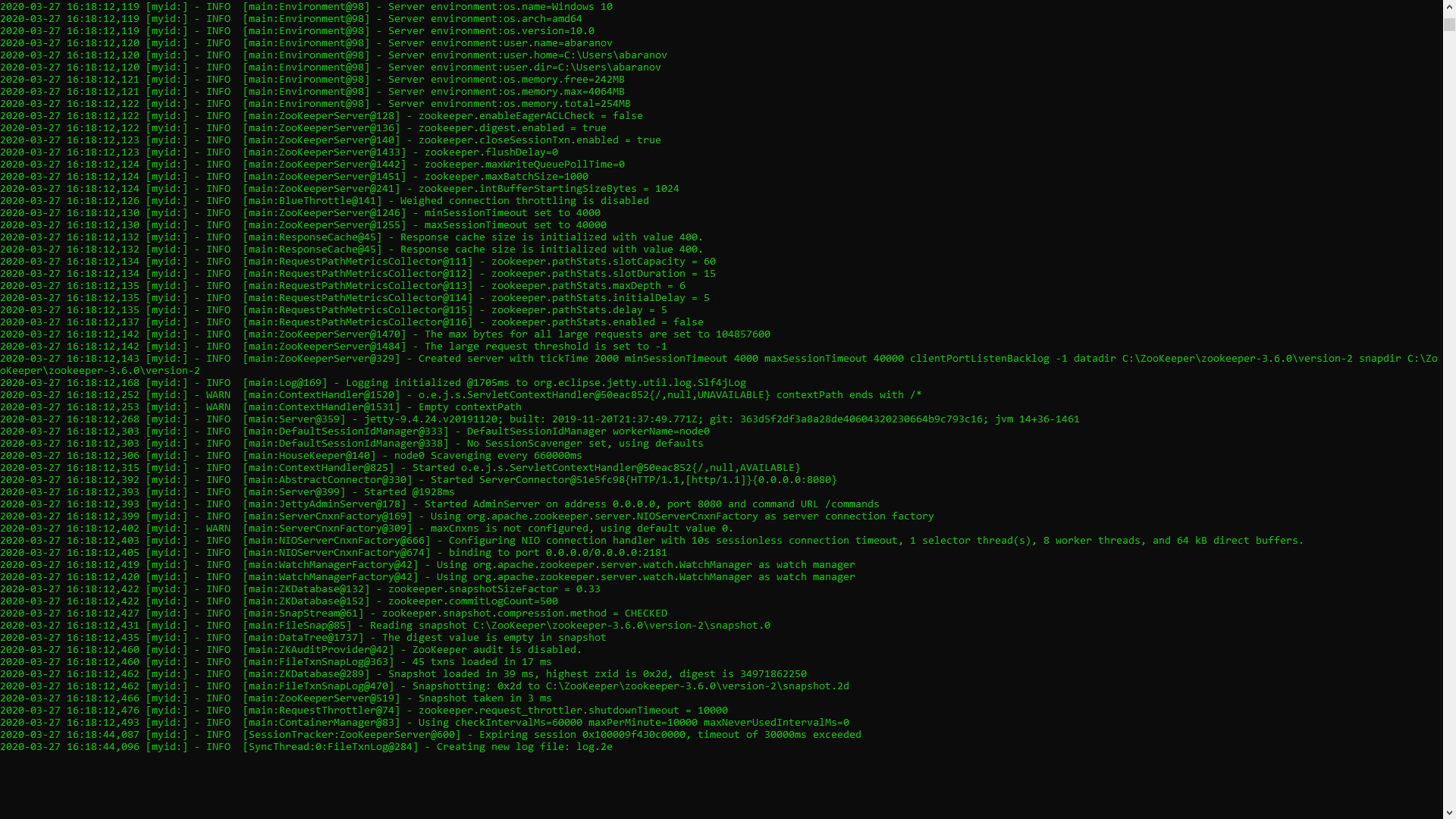 Dies bedeutet, dass ZooKeeper normal gestartet wurde. Wir fahren direkt mit der Installation und Konfiguration des Apache Kafka-Servers fort. Laden Sie die neueste Version von der offiziellen Website herunter und extrahieren Sie den Inhalt des Archivs: kafka.apache.org/downloadsIm Ordner mit Kafka finden wir den Konfigurationsordner, darin finden wir die Datei server.properties und öffnen sie.
Dies bedeutet, dass ZooKeeper normal gestartet wurde. Wir fahren direkt mit der Installation und Konfiguration des Apache Kafka-Servers fort. Laden Sie die neueste Version von der offiziellen Website herunter und extrahieren Sie den Inhalt des Archivs: kafka.apache.org/downloadsIm Ordner mit Kafka finden wir den Konfigurationsordner, darin finden wir die Datei server.properties und öffnen sie. Wir finden die Zeile log.dirs = / tmp / kafka-logs und geben darin den Pfad an, in dem Kafka die Protokolle speichert: log.dirs = c: / kafka / kafka-logs.
Wir finden die Zeile log.dirs = / tmp / kafka-logs und geben darin den Pfad an, in dem Kafka die Protokolle speichert: log.dirs = c: / kafka / kafka-logs.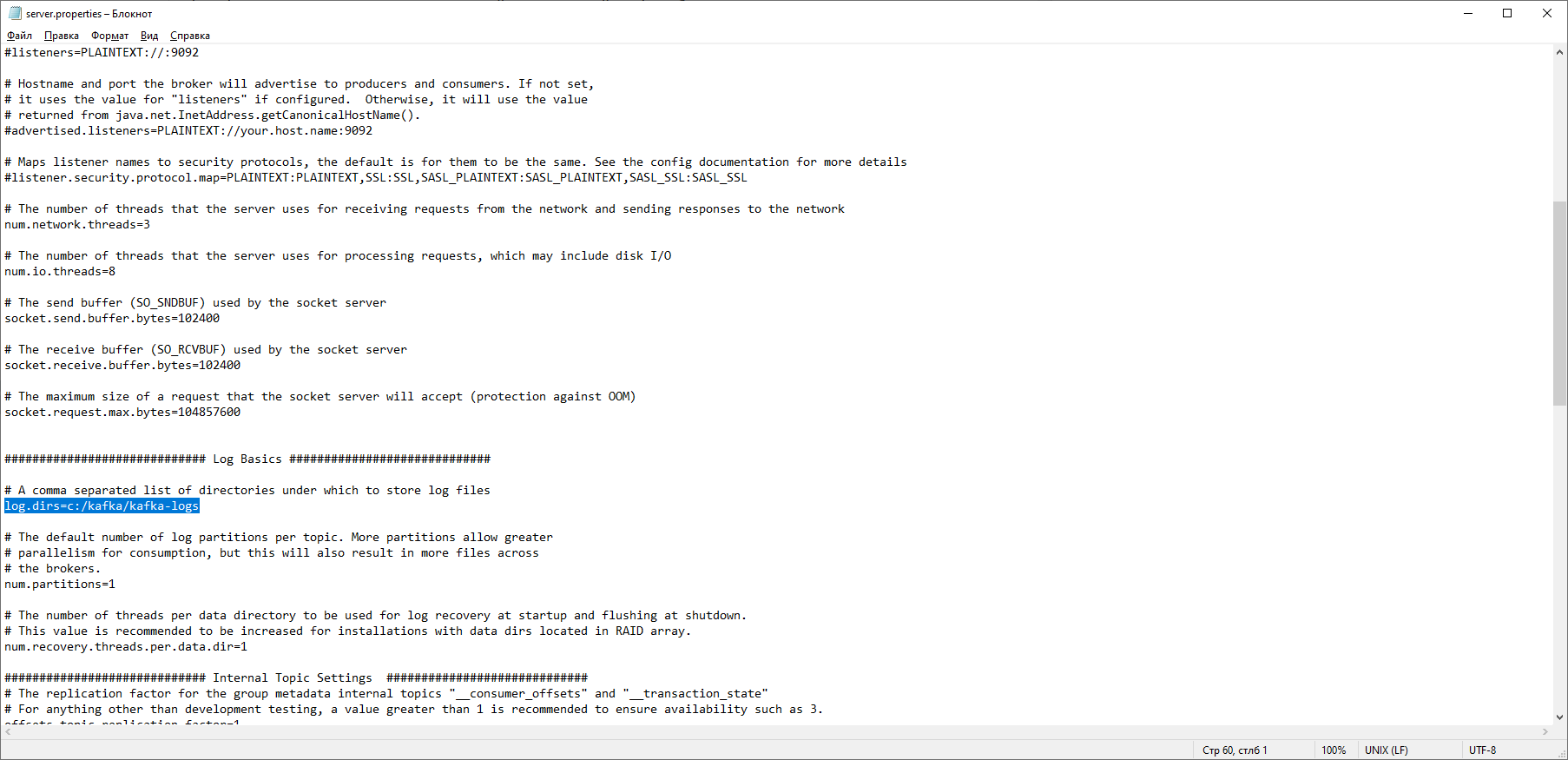 Bearbeiten Sie im selben Ordner die Datei zookeeper.properties. Wir ändern die Zeile dataDir = / tmp / zookeeper in dataDir = c: / kafka / zookeeper-data, ohne zu vergessen, den Pfad zu Ihrem Kafka-Ordner nach dem Datenträgernamen anzugeben. Wenn Sie alles richtig gemacht haben, können Sie ZooKeeper und Kafka ausführen.
Bearbeiten Sie im selben Ordner die Datei zookeeper.properties. Wir ändern die Zeile dataDir = / tmp / zookeeper in dataDir = c: / kafka / zookeeper-data, ohne zu vergessen, den Pfad zu Ihrem Kafka-Ordner nach dem Datenträgernamen anzugeben. Wenn Sie alles richtig gemacht haben, können Sie ZooKeeper und Kafka ausführen. Für einige mag es eine unangenehme Überraschung sein, dass es keine grafische Benutzeroberfläche gibt, mit der Kafka gesteuert werden kann. Vielleicht liegt dies daran, dass der Dienst für harte Nerds konzipiert ist, die ausschließlich mit der Konsole arbeiten. Auf die eine oder andere Weise benötigen wir eine Befehlszeile, um Kafka auszuführen.Zuerst müssen Sie ZooKeeper starten. In dem Ordner mit der kafka finden wir den Ordner bin / windows, darin finden wir die Datei zum Starten des Dienstes zookeeper-server-start.bat, klicken Sie darauf. Es passiert nichts? Es sollte so sein. Öffnen Sie die Konsole in diesem Ordner und schreiben Sie:
Für einige mag es eine unangenehme Überraschung sein, dass es keine grafische Benutzeroberfläche gibt, mit der Kafka gesteuert werden kann. Vielleicht liegt dies daran, dass der Dienst für harte Nerds konzipiert ist, die ausschließlich mit der Konsole arbeiten. Auf die eine oder andere Weise benötigen wir eine Befehlszeile, um Kafka auszuführen.Zuerst müssen Sie ZooKeeper starten. In dem Ordner mit der kafka finden wir den Ordner bin / windows, darin finden wir die Datei zum Starten des Dienstes zookeeper-server-start.bat, klicken Sie darauf. Es passiert nichts? Es sollte so sein. Öffnen Sie die Konsole in diesem Ordner und schreiben Sie: start zookeeper-server-start.bat
Funktioniert nicht wieder Das ist die Norm. Dies liegt daran, dass zookeeper-server-start.bat die in der Datei zookeeper.properties angegebenen Parameter benötigt, die sich, wie wir uns erinnern, für ihre Arbeit im Konfigurationsordner befindet. Wir schreiben an die Konsole:start zookeeper-server-start.bat c:\kafka\config\zookeeper.properties
Jetzt sollte alles normal beginnen. Öffnen Sie erneut die Konsole in diesem Ordner (schließen Sie ZooKeeper nicht!) Und führen Sie kafka aus:
Öffnen Sie erneut die Konsole in diesem Ordner (schließen Sie ZooKeeper nicht!) Und führen Sie kafka aus:start kafka-server-start.bat c:\kafka\config\server.properties
Um nicht jedes Mal Befehle in die Befehlszeile zu schreiben, können Sie die alte bewährte Methode verwenden und eine Batchdatei mit den folgenden Inhalten erstellen:start C:\kafka\bin\windows\zookeeper-server-start.bat C:\kafka\config\zookeeper.properties
timeout 10
start C:\kafka\bin\windows\kafka-server-start.bat C:\kafka\config\server.properties
Die Timeout 10-Zeile wird benötigt, um eine Pause zwischen dem Starten von zookeeper und kafka festzulegen. Wenn Sie alles richtig gemacht haben, sollten beim Klicken auf die Batch-Datei zwei Konsolen mit zookeeper und kafka geöffnet werden. Jetzt können wir einen Nachrichtenproduzenten und einen Konsumenten mit den erforderlichen Parametern direkt über die Befehlszeile erstellen. In der Praxis kann dies jedoch erforderlich sein, es sei denn, Sie testen den Dienst. Wir werden uns viel mehr dafür interessieren, wie man mit Kafka von IDEA arbeitet.Arbeite mit Kafka von IDEA
Wir werden die einfachste mögliche Anwendung schreiben, die gleichzeitig Produzent und Konsument der Nachricht ist, und dann nützliche Funktionen hinzufügen. Erstellen Sie ein neues Frühlingsprojekt. Dies geschieht am bequemsten mit einem Federinitialisierer. Fügen Sie die Abhängigkeiten org.springframework.kafka und spring-boot-startup-web hinzu.
 Daher sollte die Datei pom.xml folgendermaßen aussehen:
Daher sollte die Datei pom.xml folgendermaßen aussehen: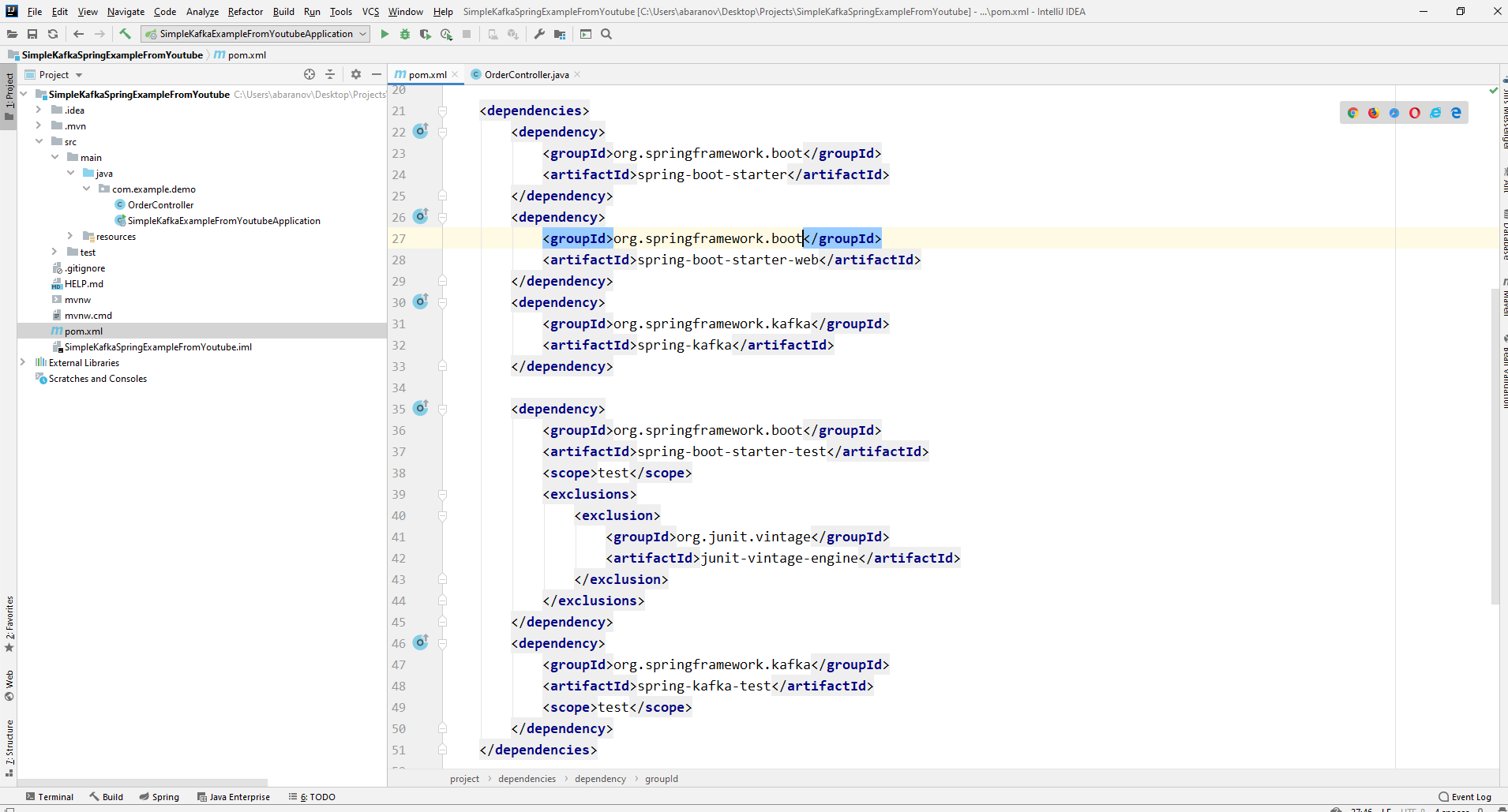 Zum Senden von Nachrichten benötigen wir das Objekt KafkaTemplate <K, V>. Wie wir sehen, ist das Objekt getippt. Der erste Parameter ist der Schlüsseltyp, der zweite ist die Nachricht selbst. Im Moment werden wir beide Parameter als String angeben. Wir werden das Objekt im Klassencontroller erstellen. Deklarieren Sie KafkaTemplate und bitten Sie Spring, es durch Annotieren zu initialisierenAutowired.
Zum Senden von Nachrichten benötigen wir das Objekt KafkaTemplate <K, V>. Wie wir sehen, ist das Objekt getippt. Der erste Parameter ist der Schlüsseltyp, der zweite ist die Nachricht selbst. Im Moment werden wir beide Parameter als String angeben. Wir werden das Objekt im Klassencontroller erstellen. Deklarieren Sie KafkaTemplate und bitten Sie Spring, es durch Annotieren zu initialisierenAutowired.@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
Grundsätzlich ist unser Produzent bereit. Sie müssen nur noch die send () -Methode aufrufen. Es gibt mehrere überladene Versionen dieser Methode. Wir verwenden in unserem Projekt eine Option mit 3 Parametern - send (String-Thema, K-Taste, V-Daten). Da KafkaTemplate von String eingegeben wird, sind der Schlüssel und die Daten in der send-Methode eine Zeichenfolge. Der erste Parameter gibt das Thema an, dh das Thema, an das Nachrichten gesendet werden und das Verbraucher abonnieren können, um sie zu empfangen. Wenn das in der Sendemethode angegebene Thema nicht vorhanden ist, wird es automatisch erstellt. Der vollständige Klassentext sieht so aus.@RestController
@RequestMapping("msg")
public class MsgController {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@PostMapping
public void sendOrder(String msgId, String msg){
kafkaTemplate.send("msg", msgId, msg);
}
}
Der Controller ordnet localhost zu : 8080 / msg, der Schlüssel und die Nachricht selbst werden im Anforderungshauptteil übertragen.Der Absender der Nachricht ist bereit. Erstellen Sie jetzt einen Listener. Mit Spring können Sie dies auch ohne großen Aufwand tun. Es reicht aus, eine Methode zu erstellen und sie mit der Annotation @KafkaListener zu markieren, in deren Parametern Sie nur das Thema angeben können, das angehört werden soll. In unserem Fall sieht es so aus.@KafkaListener(topics="msg")
Die mit Anmerkungen gekennzeichnete Methode selbst kann einen akzeptierten Parameter angeben, der den vom Produzenten übertragenen Nachrichtentyp enthält.Die Klasse, in der der Consumer erstellt wird, muss mit der Annotation @EnableKafka gekennzeichnet sein.@EnableKafka
@SpringBootApplication
public class SimpleKafkaExampleApplication {
@KafkaListener(topics="msg")
public void msgListener(String msg){
System.out.println(msg);
}
public static void main(String[] args) {
SpringApplication.run(SimpleKafkaExampleApplication.class, args);
}
}
Außerdem müssen Sie in der Einstellungsdatei application.property den Concierge-Parameter groupe-id angeben. Andernfalls wird die Anwendung nicht gestartet. Der Parameter ist vom Typ String und kann beliebig sein.spring.kafka.consumer.group-id=app.1
Unser einfachstes Kafka-Projekt ist fertig. Wir haben einen Absender und einen Empfänger von Nachrichten. Es bleibt nur zu laufen. Starten Sie zuerst ZooKeeper und Kafka mit der zuvor geschriebenen Batch-Datei und starten Sie dann unsere Anwendung. Am bequemsten ist es, eine Anfrage mit Postman zu senden. Vergessen Sie nicht, im Hauptteil der Anforderung die Parameter msgId und msg anzugeben. Wenn wir ein solches Bild in IDEA sehen, funktioniert alles: Der Produzent hat eine Nachricht gesendet, der Verbraucher hat sie empfangen und auf der Konsole angezeigt.
Wenn wir ein solches Bild in IDEA sehen, funktioniert alles: Der Produzent hat eine Nachricht gesendet, der Verbraucher hat sie empfangen und auf der Konsole angezeigt.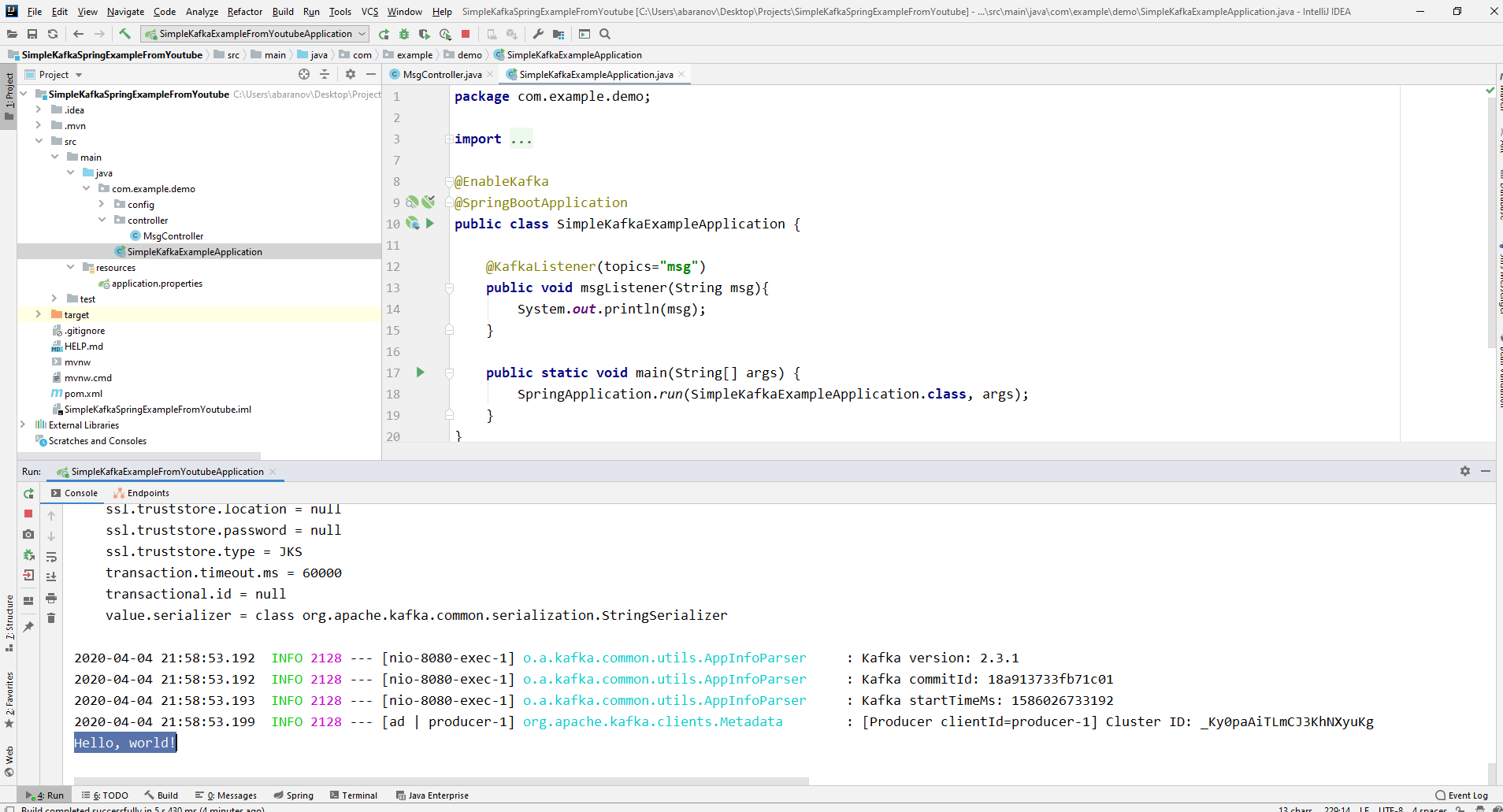
Wir erschweren das Projekt
Echte Projekte mit Kafka sind sicherlich komplizierter als die, die wir erstellt haben. Nachdem wir die Grundfunktionen des Dienstes herausgefunden haben, überlegen Sie, welche zusätzlichen Funktionen er bietet. Zunächst werden wir den Produzenten verbessern.Wenn Sie die send () -Methode geöffnet haben, stellen Sie möglicherweise fest, dass alle Varianten den Rückgabewert ListenableFuture <SendResult <K, V >> haben. Jetzt werden wir die Funktionen dieser Schnittstelle nicht im Detail betrachten. Hier genügt es zu sagen, dass es erforderlich ist, das Ergebnis des Sendens einer Nachricht anzuzeigen.@PostMapping
public void sendMsg(String msgId, String msg){
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send("msg", msgId, msg);
future.addCallback(System.out::println, System.err::println);
kafkaTemplate.flush();
}
Die addCallback () -Methode akzeptiert zwei Parameter - SuccessCallback und FailureCallback. Beide sind funktionale Schnittstellen. Anhand des Namens können Sie erkennen, dass die Methode der ersten als Ergebnis eines erfolgreichen Sendens der Nachricht aufgerufen wird, die zweite als Ergebnis eines Fehlers. Wenn wir nun das Projekt ausführen, wird auf der Konsole Folgendes angezeigt:SendResult [producerRecord=ProducerRecord(topic=msg, partition=null, headers=RecordHeaders(headers = [], isReadOnly = true), key=1, value=Hello, world!, timestamp=null), recordMetadata=msg-0@6]
Schauen wir uns unseren Produzenten noch einmal genau an. Interessanterweise, was passiert, wenn der Schlüssel nicht String ist, sondern beispielsweise Long, aber als übertragene Nachricht noch schlimmer - eine Art kompliziertes DTO? Versuchen wir zunächst, den Schlüssel in einen numerischen Wert zu ändern ... Wenn wir Long als Schlüssel im Produzenten angeben, wird die Anwendung normal gestartet. Wenn Sie jedoch versuchen, eine Nachricht zu senden, wird eine ClassCastException ausgelöst und es wird gemeldet, dass die Long-Klasse nicht in die String-Klasse umgewandelt werden kann.
wir zunächst, den Schlüssel in einen numerischen Wert zu ändern ... Wenn wir Long als Schlüssel im Produzenten angeben, wird die Anwendung normal gestartet. Wenn Sie jedoch versuchen, eine Nachricht zu senden, wird eine ClassCastException ausgelöst und es wird gemeldet, dass die Long-Klasse nicht in die String-Klasse umgewandelt werden kann. Wenn wir versuchen, das KafkaTemplate-Objekt manuell zu erstellen, wird das Schnittstellenobjekt ProducerFactory <K, V>, z. B. DefaultKafkaProducerFactory <>, als Parameter an den Konstruktor übergeben. Um eine DefaultKafkaProducerFactory zu erstellen, müssen wir eine Map mit ihren Produzenteneinstellungen an ihren Konstruktor übergeben. Der gesamte Code für die Konfiguration und Erstellung des Produzenten wird in eine separate Klasse eingeordnet. Erstellen Sie dazu das Konfigurationspaket und darin die KafkaProducerConfig-Klasse.
Wenn wir versuchen, das KafkaTemplate-Objekt manuell zu erstellen, wird das Schnittstellenobjekt ProducerFactory <K, V>, z. B. DefaultKafkaProducerFactory <>, als Parameter an den Konstruktor übergeben. Um eine DefaultKafkaProducerFactory zu erstellen, müssen wir eine Map mit ihren Produzenteneinstellungen an ihren Konstruktor übergeben. Der gesamte Code für die Konfiguration und Erstellung des Produzenten wird in eine separate Klasse eingeordnet. Erstellen Sie dazu das Konfigurationspaket und darin die KafkaProducerConfig-Klasse.@Configuration
public class KafkaProducerConfig {
private String kafkaServer="localhost:9092";
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
kafkaServer);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
LongSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class);
return props;
}
@Bean
public ProducerFactory<Long, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<Long, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
Erstellen Sie in der ProducerConfigs () -Methode eine Map mit den Konfigurationen und geben Sie LongSerializer.class als Serializer für den Schlüssel an. Wir starten, senden eine Anfrage von Postman und sehen, dass jetzt alles so funktioniert, wie es sollte: Der Produzent sendet eine Nachricht und der Verbraucher empfängt sie.Ändern wir nun den Typ des übertragenen Werts. Was ist, wenn wir keine Standardklasse aus der Java-Bibliothek haben, sondern eine Art benutzerdefiniertes DTO? Sagen wir das.@Data
public class UserDto {
private Long age;
private String name;
private Address address;
}
@Data
@AllArgsConstructor
public class Address {
private String country;
private String city;
private String street;
private Long homeNumber;
private Long flatNumber;
}
Um DTO als Nachricht zu senden, müssen Sie einige Änderungen an der Herstellerkonfiguration vornehmen. Geben Sie JsonSerializer.class als Serializer des Nachrichtenwerts an und vergessen Sie nicht, den String-Typ überall in UserDto zu ändern.@Configuration
public class KafkaProducerConfig {
private String kafkaServer="localhost:9092";
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
kafkaServer);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
LongSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
JsonSerializer.class);
return props;
}
@Bean
public ProducerFactory<Long, UserDto> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<Long, UserDto> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
Eine Nachricht schicken. Die folgende Zeile wird in der Konsole angezeigt: Jetzt werden wir den Verbraucher komplizieren. Zuvor hat unsere Methode public void msgListener (String msg), die mit der Anmerkung @KafkaListener (topic = "msg") gekennzeichnet ist, String als Parameter verwendet und auf der Konsole angezeigt. Was ist, wenn wir andere Parameter der übertragenen Nachricht erhalten möchten, beispielsweise einen Schlüssel oder eine Partition? In diesem Fall muss der Typ des übertragenen Wertes geändert werden.
Jetzt werden wir den Verbraucher komplizieren. Zuvor hat unsere Methode public void msgListener (String msg), die mit der Anmerkung @KafkaListener (topic = "msg") gekennzeichnet ist, String als Parameter verwendet und auf der Konsole angezeigt. Was ist, wenn wir andere Parameter der übertragenen Nachricht erhalten möchten, beispielsweise einen Schlüssel oder eine Partition? In diesem Fall muss der Typ des übertragenen Wertes geändert werden.@KafkaListener(topics="msg")
public void orderListener(ConsumerRecord<Long, UserDto> record){
System.out.println(record.partition());
System.out.println(record.key());
System.out.println(record.value());
}
Über das ConsumerRecord-Objekt können wir alle Parameter abrufen, die uns interessieren.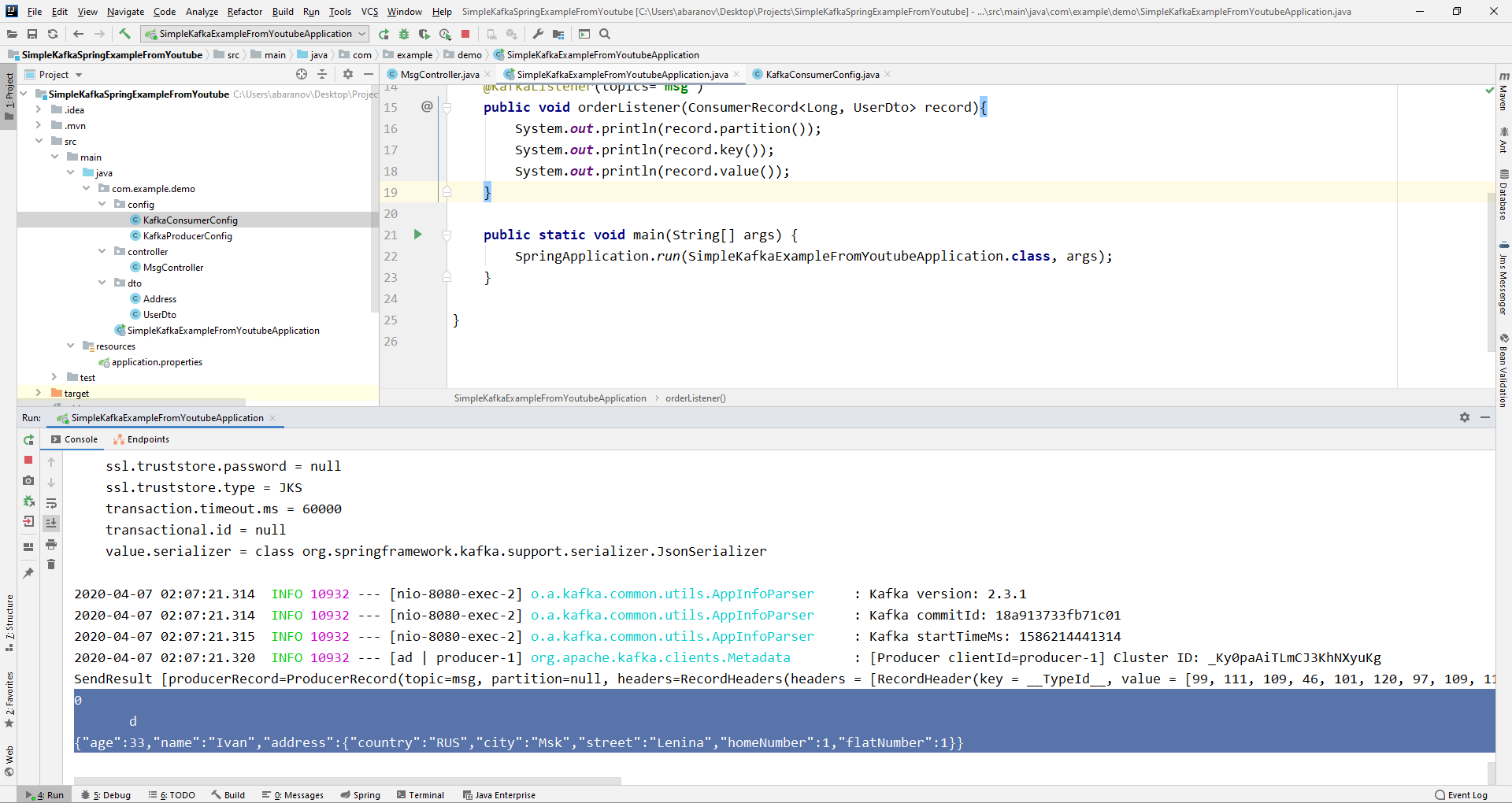 Wir sehen, dass anstelle des Schlüssels auf der Konsole eine Art Krakozyabry angezeigt wird. Dies liegt daran, dass der StringDeserializer standardmäßig zum Deserialisieren des Schlüssels verwendet wird. Wenn der Schlüssel im Ganzzahlformat korrekt angezeigt werden soll, müssen wir ihn in LongDeserializer ändern. Erstellen Sie die KafkaConsumerConfig-Klasse, um den Consumer im Konfigurationspaket zu konfigurieren.
Wir sehen, dass anstelle des Schlüssels auf der Konsole eine Art Krakozyabry angezeigt wird. Dies liegt daran, dass der StringDeserializer standardmäßig zum Deserialisieren des Schlüssels verwendet wird. Wenn der Schlüssel im Ganzzahlformat korrekt angezeigt werden soll, müssen wir ihn in LongDeserializer ändern. Erstellen Sie die KafkaConsumerConfig-Klasse, um den Consumer im Konfigurationspaket zu konfigurieren.@Configuration
public class KafkaConsumerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String kafkaServer;
@Value("${spring.kafka.consumer.group-id}")
private String kafkaGroupId;
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.GROUP_ID_CONFIG, kafkaGroupId);
return props;
}
@Bean
public KafkaListenerContainerFactory<?> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<Long, UserDto> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
@Bean
public ConsumerFactory<Long, UserDto> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
}
Die KafkaConsumerConfig-Klasse ist der zuvor erstellten KafkaProducerConfig sehr ähnlich. Es gibt auch eine Map, die die erforderlichen Konfigurationen enthält, z. B. einen Deserializer für den Schlüssel und den Wert. Die erstellte Map wird zum Erstellen der ConsumerFactory <> verwendet, die wiederum zum Erstellen der KafkaListenerContainerFactory <?> Erforderlich ist. Ein wichtiges Detail: Die Methode, die KafkaListenerContainerFactory <?> Zurückgibt, sollte kafkaListenerContainerFactory () heißen, da Spring sonst die gewünschte Bean nicht finden kann und das Projekt nicht kompiliert wird. Wir starten. Wir sehen, dass jetzt der Schlüssel so angezeigt wird, wie er sollte, was bedeutet, dass alles funktioniert. Natürlich gehen die Funktionen von Apache Kafka weit über die in diesem Artikel beschriebenen hinaus. Ich hoffe jedoch, dass Sie nach dem Lesen eine Vorstellung von diesem Service bekommen und vor allem damit beginnen können, damit zu arbeiten.Waschen Sie Ihre Hände häufiger, tragen Sie Masken, gehen Sie nicht ohne Notwendigkeit nach draußen und seien Sie gesund.
Wir sehen, dass jetzt der Schlüssel so angezeigt wird, wie er sollte, was bedeutet, dass alles funktioniert. Natürlich gehen die Funktionen von Apache Kafka weit über die in diesem Artikel beschriebenen hinaus. Ich hoffe jedoch, dass Sie nach dem Lesen eine Vorstellung von diesem Service bekommen und vor allem damit beginnen können, damit zu arbeiten.Waschen Sie Ihre Hände häufiger, tragen Sie Masken, gehen Sie nicht ohne Notwendigkeit nach draußen und seien Sie gesund.