Beim Schreiben von Anwendungen in Python werden häufig objektrelationale Mapper (ORMs) verwendet, um mit Datenbanken zu arbeiten. Beispiele für ORMs sind SQLALchemy, PonyORM und der in Django enthaltene objektrelationale Mapper. Bei der Auswahl von ORM spielt die Leistung eine wichtige Rolle.
Auf Habr und im gesamten Internet kann kein einziger Leistungstest gefunden werden. Als Beispiel für einen hochwertigen Python-ORM-Benchmark können Sie den Tortoise ORM-Benchmark ( Link zum Repository ) verwenden. Dieser Benchmark analysiert die Geschwindigkeit von sechs ORMs für elf verschiedene Arten von SQL-Abfragen.
Im Allgemeinen ermöglicht der Schildkröten-Benchmark die Bewertung der Geschwindigkeit der Abfrageausführung mithilfe verschiedener ORMs, aber ich sehe ein Problem bei diesem Testansatz. ORMs werden häufig in Webanwendungen verwendet, in denen mehrere Benutzer gleichzeitig unterschiedliche Anforderungen senden können. Ich habe jedoch keinen einzigen Benchmark gefunden, der die Leistung von ORM unter solchen Bedingungen bewertet. Aus diesem Grund habe ich beschlossen, meinen Benchmark zu schreiben und PonyORM und SQLAlchemy damit zu vergleichen. Als Basis habe ich den TPC-C-Benchmark genommen.
Das Unternehmen TPC entwickelt seit 1988 Tests zur Datenverarbeitung. Sie sind seit langem ein Industriestandard und werden von fast allen Anbietern von Geräten für verschiedene Hardware- und Softwarebeispiele verwendet. Das Hauptmerkmal dieser Tests ist, dass sie darauf abzielen, unter enormen Belastungen unter Bedingungen zu testen, die den realen möglichst nahe kommen.
TPC-C simuliert ein Lagernetzwerk. Es enthält eine Kombination von fünf gleichzeitig ausgeführten Transaktionen verschiedener Arten und Komplexität. Die Datenbank besteht aus neun Tabellen mit einer großen Anzahl von Datensätzen. Die Leistung im TPC-C-Test wird in Transaktionen pro Minute gemessen.
Ich habe beschlossen, zwei Python-ORMs (SQLALchemy und PonyORM) mit der für diese Aufgabe angepassten TPC-C-Testmethode zu testen. Der Zweck des Tests besteht darin, die Geschwindigkeit der Transaktionsverarbeitung zu bewerten, wenn mehrere virtuelle Benutzer gleichzeitig auf die Datenbank zugreifen.
Testbeschreibung
In dem Test, den ich geschrieben habe, wird zuerst eine Datenbank erstellt und gefüllt, die eine Datenbank eines Netzwerks von Lagern ist. Das Datenbankschema sieht aus wie diese :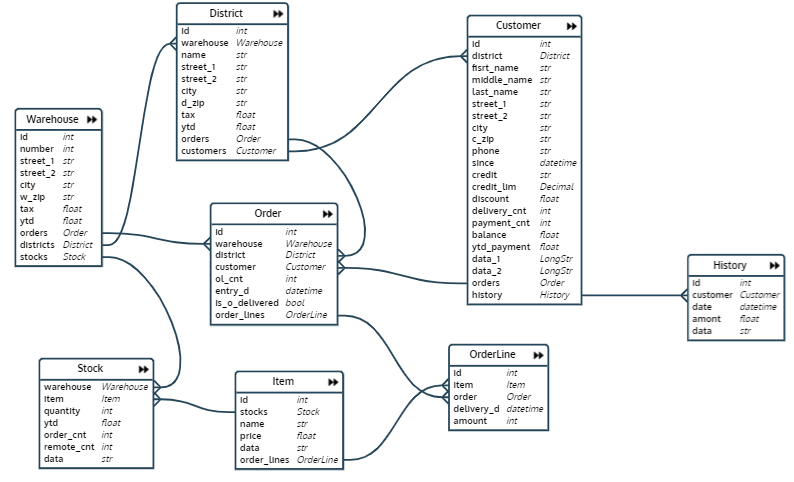
Die Datenbank besteht aus acht Beziehungen:
- Lager - Lager
- Bezirk - Lagerfläche
- Bestellung - Bestellung
- Bestellposition - Bestellposition (Bestellposition)
- Lagerbestand - Menge eines bestimmten Produkts in einem bestimmten Lager
- Gegenstand - Gegenstand
- Kunde - Kunde
- Verlauf - Zahlungsverlauf des Kunden
, e . . , :
- new_order ( ) — 45%
- payment ( ) — 43%
- order_status ( ) — 4%
- delivery ( ) — 4%
- stock_level ( ) — 4%
, TPC-C.
TPC-C , , ORM, . 64+ , .
:
- ,
- . : Stock 100 000 * W, W — , : 100 * W
- 5 . Payment ID, . ID,
- NewOrder. , , Order, NewOrder. , NewOrder. , , , , , . Order bool “is_o_delivered”, False, ,
, .
New Order
- : id id
- id
- ()
- . Item.
- , .
Payment
- : id id
- id
- .
- 1
- , ,
- .
Bestellstatus
- Transaktionen, die von der Kunden-ID bedient werden
- Der Kunde und seine letzte Bestellung werden aus der Datenbank übernommen
- Der Status wird aus der Bestellung (geliefert oder nicht) und den Bestellpositionen übernommen
Lieferung
- Transaktionen, die von der Lager-ID bedient werden
- Das Lager wird von der Datenbank nach ID und allen seinen Abschnitten angefordert
- Für jeden Standort wird die älteste der nicht zugestellten Bestellungen entgegengenommen. In jedem von ihnen ändert sich der Lieferstatus in True
- Aus der Datenbank werden Benutzer entnommen, deren Bestellungen während dieser Transaktion geliefert wurden, und jeder von ihnen erhöht den Lieferzähler
Lagerbestand
- Transaktionen, die von der Lager-ID bedient werden
- Das Lager wird von der Datenbank nach ID angefordert
- Die letzten 20 Bestellungen dieses Lagers werden aus der Datenbank angefordert
- Für jeden Artikel dieser Bestellungen aus der Datenbank wird die Menge der verbleibenden Waren im Lager angefordert
Testergebnisse
An Tests sind zwei ORMs beteiligt:- SQLAlchemy Die Grafiken sind durch eine blaue Linie dargestellt.
- PonyORM. Die Grafiken sind durch die gelbe Linie dargestellt.
10 2 , . multiprocessing.
—
—
PostgreSQL
, TPC-C. Pony .

:
Pony — 2543 /
SQLAlchemy — 1353.4 /
ORM . .
“New Order”

Durchschnittsgeschwindigkeit:
Pony - 3349,2 trans / min
SQLAlchemy - 1415,3 trans / min
Transaktion "Zahlung"
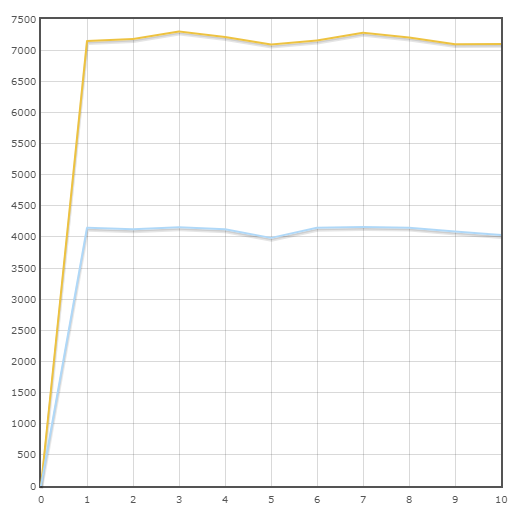
Durchschnittsgeschwindigkeit:
Pony - 7175,3 trans / min
SQLAlchemy - 4110,6 trans / min
Transaktion "Auftragsstatus"
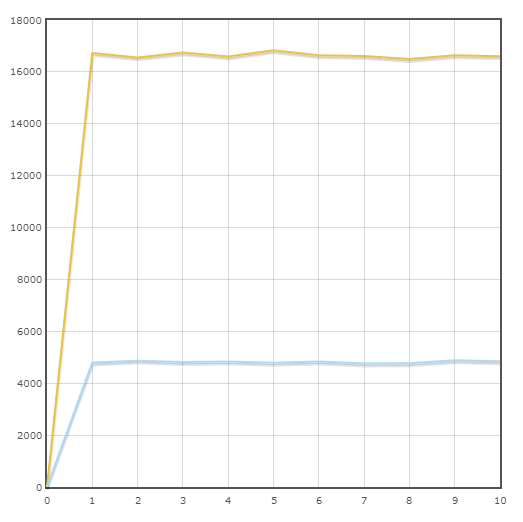
Durchschnittsgeschwindigkeit:
Pony - 16645.6 trans / min
SQLAlchemy - 4820.8 trans / min
Transaktion "Lieferung"
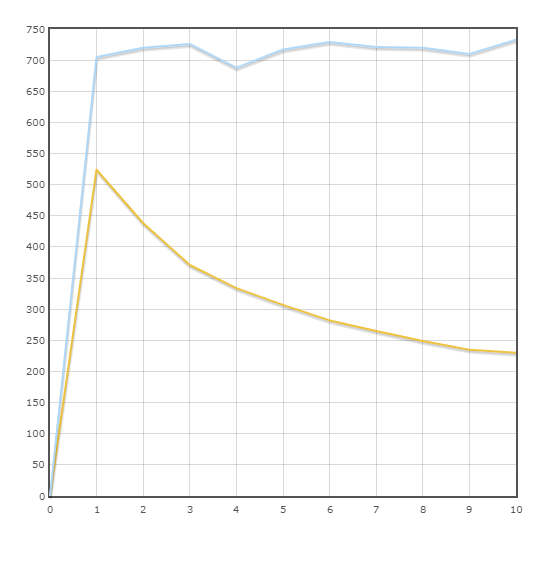
Durchschnittsgeschwindigkeit:
SQLAlchemy - 716,9 trans / min
Pony - 323,5 trans / min
Transaktion "Lagerbestand"
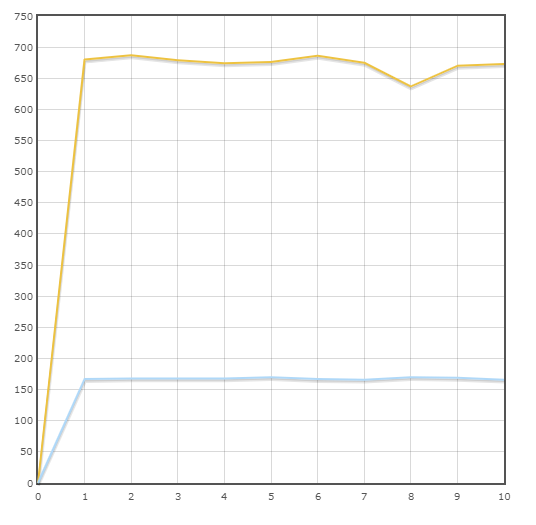
Durchschnittsgeschwindigkeit:
Pony - 677,3 trans / min
SQLAlchemy - 167,9 trans / min
Analyse der Testergebnisse
Nachdem ich die Ergebnisse erhalten hatte, analysierte ich, warum in verschiedenen Situationen ein ORM schneller ist als ein anderer und kam zu folgenden Schlussfolgerungen:4 5 PonyORM , , SQL PonyORM Python SQL, , SQLALchemy SQL . PonyORM:
stocks = select(stock for stock in Stock
if stock.warehouse == whouse
and stock.item in items).order_by(Stock.id).for_update()
SQLAlchemy:
stocks = session.query(Stock).filter(
Stock.warehouse == whouse, Stock.item.in_(items)).order_by(text("id")).with_for_update()
SQLAlchemy Delivery , UPDATE, , .
, SQLAlchemy:
INFO:sqlalchemy.engine.base.Engine:UPDATE order_line SET delivery_d=%(delivery_d)s WHERE order_line.id = %(order_line_id)s
INFO:sqlalchemy.engine.base.Engine:(
{'delivery_d': datetime.datetime(2020, 4, 6, 14, 33, 6, 922281), 'order_line_id': 316},
{'delivery_d': datetime.datetime(2020, 4, 6, 14, 33, 6, 922272), 'order_line_id': 317},
{'delivery_d': datetime.datetime(2020, 4, 6, 14, 33, 6, 922261))
Pony Update:
SELECT "id", "delivery_d", "item", "amount", "order"
FROM "orderline"
WHERE "order" = %(p1)s
{'p1':911}
UPDATE "orderline"
SET "delivery_d" = %(p1)s
WHERE "id" = %(p2)s
AND "order" = %(p3)s
{'p1':datetime.datetime(2020, 4, 7, 17, 48, 58, 585932), 'p2':5047, 'p3':911}
UPDATE "orderline"
SET "delivery_d" = %(p1)s
WHERE "id" = %(p2)s
AND "order" = %(p3)s
{'p1':datetime.datetime(2020, 4, 7, 17, 48, 58, 585990), 'p2':5048, 'p3':911}
Basierend auf den Ergebnissen dieser Tests kann ich sagen, dass Pony beim Abrufen aus einer Datenbank viel schneller arbeitet und SQLAlchemy in einigen Fällen erheblich schnellere Update-Abfragen erzeugen kann.In Zukunft plane ich, andere ORMs (Peewee, Django) auf diese Weise zu testen.
Verweise
Testcode: SQLAlchemy- Repository-Link
: Dokumentation , Community
Pony: Dokumentation , Community