Die Fernbedienung vor dem Hintergrund der universellen Selbstisolation kann zu sehr schlimmen Folgen führen. Und emotionales Burnout - es ist immer noch da, wo es hingeht: Immerhin ist es nicht weit vom Dach entfernt. In dieser Hinsicht versuchte er, wie viele andere auch, sich zu "beruhigen", indem er Zeit für andere Klassen zur Verfügung stellte - und begann, die interessantesten Artikel aus dem Englischen ins Russische zu übersetzen: "Sie geben den Massen maschinelles Lernen !".) Wir müssen Tribut zollen: Es ist sehr ablenkend. Wenn Sie Vorschläge für den semantischen Inhalt und die Übersetzung dieses Textes für einen russischsprachigen Leser haben, nehmen Sie an der Diskussion teil. Hier ist eine Übersetzung der Zeitreihen-Prognoseseite aus dem Abschnitt zum Tensorflow-Handbuch: Link . Meine Ergänzungen zusammen mit Abbildungen für die Übersetzung sollen helfen, die Grundideen in einem der interessantesten Bereiche der ML und der Ökonometrie im Allgemeinen zu verstehen - der Vorhersage von Zeitreihen.Eine kleine Einführung vor der Übersetzung.Das Handbuch beschreibt die Lufttemperaturvorhersage anhand eindimensionaler Zeitreihen (univariate Zeitreihen) und multivariater Zeitreihen (multivariate Zeitreihen) . Geben Sie für jedes Teil Daten einsollte entsprechend vorbereitet sein. Unter Berücksichtigung des in diesem Handbuch berücksichtigten meteorologischen Datensatzes lautet die Trennung wie folgt:
Hier ist eine Übersetzung der Zeitreihen-Prognoseseite aus dem Abschnitt zum Tensorflow-Handbuch: Link . Meine Ergänzungen zusammen mit Abbildungen für die Übersetzung sollen helfen, die Grundideen in einem der interessantesten Bereiche der ML und der Ökonometrie im Allgemeinen zu verstehen - der Vorhersage von Zeitreihen.Eine kleine Einführung vor der Übersetzung.Das Handbuch beschreibt die Lufttemperaturvorhersage anhand eindimensionaler Zeitreihen (univariate Zeitreihen) und multivariater Zeitreihen (multivariate Zeitreihen) . Geben Sie für jedes Teil Daten einsollte entsprechend vorbereitet sein. Unter Berücksichtigung des in diesem Handbuch berücksichtigten meteorologischen Datensatzes lautet die Trennung wie folgt: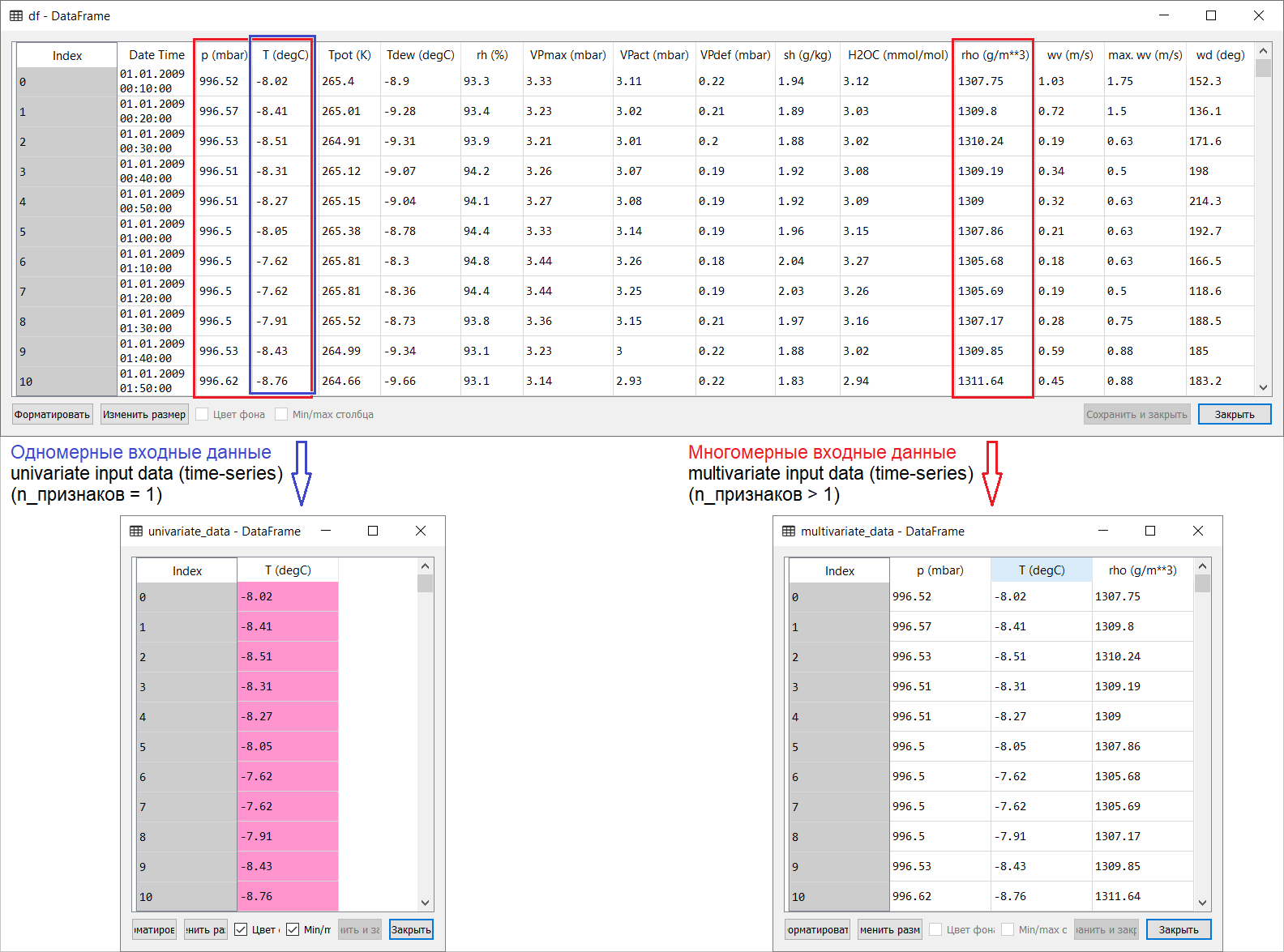 Bei Fragen, was für X und was für Y zu beachten ist, dh wie Daten für die Klasse des überwachten Trainings vorzubereiten sind, wird dies aus den folgenden Abbildungen deutlich. Ich stelle nur fest, dass die Bildung des Zielvektors (Y) für die Arbeit mit eindimensionalen und mehrdimensionalen Zeitreihen gleich ist: Der Zielvektor wird auf der Basis des Vorzeichens T (degC) zusammengestellt.(Lufttemperatur). Der Unterschied zwischen ihnen liegt in der Bildung einer Reihe von Merkmalen, die der Modelleingabe zugeführt werden: Bei einer eindimensionalen Zeitreihe zur Vorhersage der Temperatur in der Zukunft besteht der Eingabevektor (X) aus einem Merkmal: Lufttemperatur; und für mehrdimensionale - mehr als eine: Zusätzlich zur Lufttemperatur werden im Beispiel dieses Handbuchs p (mbar) (atmosphärischer Druck) und rho (g / m ** 3) (Luftfeuchtigkeit) verwendet .Zunächst sieht ein weit flaches Aussehen, ein Beispiel mit Temperaturvorhersage, unter dem Gesichtspunkt der Verwendung einer mehrdimensionalen Eingabe nicht überzeugend aus: Für die Temperaturvorhersage ist die Temperatur das relevanteste Zeichen. Dies ist jedoch absolut nicht der Fall: Um eine qualitative Vorhersage der Lufttemperatur zu erstellen, müssen viele Faktoren bis zur Luftreibung auf der Erdoberfläche usw. berücksichtigt werden. Darüber hinaus sind in der Praxis einige Dinge alles andere als offensichtlich, und der Zielvektor kann in Form dieses Durcheinander (oder Borschtsches) vorliegen. In dieser Hinsicht ist eine explorative Datenanalyse mit der Auswahl der relevantesten Merkmale für die nachfolgende Bildung einer mehrdimensionalen Eingabe die einzig richtige Entscheidung.Daher wird die Übersetzung des Handbuchs unten dargestellt. Zusätzlicher Text wird kursiv dargestellt .
Bei Fragen, was für X und was für Y zu beachten ist, dh wie Daten für die Klasse des überwachten Trainings vorzubereiten sind, wird dies aus den folgenden Abbildungen deutlich. Ich stelle nur fest, dass die Bildung des Zielvektors (Y) für die Arbeit mit eindimensionalen und mehrdimensionalen Zeitreihen gleich ist: Der Zielvektor wird auf der Basis des Vorzeichens T (degC) zusammengestellt.(Lufttemperatur). Der Unterschied zwischen ihnen liegt in der Bildung einer Reihe von Merkmalen, die der Modelleingabe zugeführt werden: Bei einer eindimensionalen Zeitreihe zur Vorhersage der Temperatur in der Zukunft besteht der Eingabevektor (X) aus einem Merkmal: Lufttemperatur; und für mehrdimensionale - mehr als eine: Zusätzlich zur Lufttemperatur werden im Beispiel dieses Handbuchs p (mbar) (atmosphärischer Druck) und rho (g / m ** 3) (Luftfeuchtigkeit) verwendet .Zunächst sieht ein weit flaches Aussehen, ein Beispiel mit Temperaturvorhersage, unter dem Gesichtspunkt der Verwendung einer mehrdimensionalen Eingabe nicht überzeugend aus: Für die Temperaturvorhersage ist die Temperatur das relevanteste Zeichen. Dies ist jedoch absolut nicht der Fall: Um eine qualitative Vorhersage der Lufttemperatur zu erstellen, müssen viele Faktoren bis zur Luftreibung auf der Erdoberfläche usw. berücksichtigt werden. Darüber hinaus sind in der Praxis einige Dinge alles andere als offensichtlich, und der Zielvektor kann in Form dieses Durcheinander (oder Borschtsches) vorliegen. In dieser Hinsicht ist eine explorative Datenanalyse mit der Auswahl der relevantesten Merkmale für die nachfolgende Bildung einer mehrdimensionalen Eingabe die einzig richtige Entscheidung.Daher wird die Übersetzung des Handbuchs unten dargestellt. Zusätzlicher Text wird kursiv dargestellt .Zeitreihenprognose
Dieser Leitfaden ist eine Einführung in die Vorhersage von Zeitreihen unter Verwendung wiederkehrender neuronaler Netze (RNS, vom English Recurrent Neural Network, RNN ). Es besteht aus zwei Teilen: Der erste beschreibt die Vorhersage der Lufttemperatur anhand einer eindimensionalen Zeitreihe und der zweite Teil basiert auf einer mehrdimensionalen Zeitreihe.import tensorflow as tf
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
mpl.rcParams['figure.figsize'] = (8, 6)
mpl.rcParams['axes.grid'] = False
Eine Reihe von meteorologischen DatenAlle Beispiele für die manuelle Verwendung von Zeitsequenzen von Wetterdaten, die an einer hydrometeorologischen Station des nach ihr benannten Instituts für Biogeochemie aufgezeichnet wurden Max Planck .Dieser Datensatz enthält Messungen von 14 verschiedenen meteorologischen Indikatoren (wie Lufttemperatur, Luftdruck, Luftfeuchtigkeit), die seit 2003 alle 10 Minuten durchgeführt wurden. Um Zeit und Speicherplatz zu sparen, werden im Handbuch Daten für den Zeitraum von 2009 bis 2016 verwendet. Dieser Abschnitt des Datensatzes wurde von François Chollet für sein Buch Deep Learning with Python vorbereitet .zip_path = tf.keras.utils.get_file(
origin='https://storage.googleapis.com/tensorflow/tf-keras-datasets/jena_climate_2009_2016.csv.zip',
fname='jena_climate_2009_2016.csv.zip',
extract=True)
csv_path, _ = os.path.splitext(zip_path)
df = pd.read_csv(csv_path)
Mal sehen, was wir haben.df.head()
 Die Tatsache, dass der Beobachtungszeitraum 10 Minuten beträgt, kann anhand der obigen Tabelle überprüft werden. Somit haben Sie in einer Stunde 6 Beobachtungen. Pro Tag werden wiederum 144 (6x24) Beobachtungen gesammelt.Angenommen, Sie möchten die Temperatur vorhersagen, die in 6 Stunden in der Zukunft liegen wird. Sie erstellen diese Prognose basierend auf den Daten, die Sie für einen bestimmten Zeitraum haben: Sie entscheiden sich beispielsweise für eine Beobachtung von 5 Tagen. Um das Modell zu trainieren, müssen Sie daher ein Zeitintervall erstellen, das die letzten 720 (5x144) Beobachtungen enthält (da unterschiedliche Konfigurationen möglich sind, ist dieser Datensatz eine gute Grundlage für Experimente).Die folgende Funktion gibt die obigen Zeitintervalle für das Training des Modells zurück. Streit
Die Tatsache, dass der Beobachtungszeitraum 10 Minuten beträgt, kann anhand der obigen Tabelle überprüft werden. Somit haben Sie in einer Stunde 6 Beobachtungen. Pro Tag werden wiederum 144 (6x24) Beobachtungen gesammelt.Angenommen, Sie möchten die Temperatur vorhersagen, die in 6 Stunden in der Zukunft liegen wird. Sie erstellen diese Prognose basierend auf den Daten, die Sie für einen bestimmten Zeitraum haben: Sie entscheiden sich beispielsweise für eine Beobachtung von 5 Tagen. Um das Modell zu trainieren, müssen Sie daher ein Zeitintervall erstellen, das die letzten 720 (5x144) Beobachtungen enthält (da unterschiedliche Konfigurationen möglich sind, ist dieser Datensatz eine gute Grundlage für Experimente).Die folgende Funktion gibt die obigen Zeitintervalle für das Training des Modells zurück. Streithistory_size- Dies ist die Größe des letzten Zeitintervalls. target_size- Ein Argument, das bestimmt, wie weit das Modell in die Zukunft voraussagen sollte. Mit anderen Worten, target_sizeist der Zielvektor, der vorhergesagt werden muss.def univariate_data(dataset, start_index, end_index, history_size, target_size):
data = []
labels = []
start_index = start_index + history_size
if end_index is None:
end_index = len(dataset) - target_size
for i in range(start_index, end_index):
indices = range(i-history_size, i)
data.append(np.reshape(dataset[indices], (history_size, 1)))
labels.append(dataset[i+target_size])
return np.array(data), np.array(labels)
In beiden Teilen des Handbuchs werden die ersten 300.000 Datenzeilen zum Trainieren des Modells verwendet, die restlichen zur Validierung (Validierung). In diesem Fall beträgt die Menge der Trainingsdaten ungefähr 2100 Tage.TRAIN_SPLIT = 300000
Um reproduzierbare Ergebnisse zu gewährleisten, wird die Seed-Funktion eingestellt.tf.random.set_seed(13)
Teil 1. Prognose basierend auf einer eindimensionalen Zeitreihe
Im ersten Teil trainieren Sie das Modell mit nur einem Attribut - Temperatur; Das trainierte Modell wird verwendet, um zukünftige Temperaturen vorherzusagen.Zunächst extrahieren wir nur die Temperatur aus dem Datensatz.uni_data = df['T (degC)']
uni_data.index = df['Date Time']
uni_data.head()
Date Time
01.01.2009 00:10:00 -8.02
01.01.2009 00:20:00 -8.41
01.01.2009 00:30:00 -8.51
01.01.2009 00:40:00 -8.31
01.01.2009 00:50:00 -8.27
Name: T (degC), dtype: float64
Und mal sehen, wie sich diese Daten im Laufe der Zeit ändern.uni_data.plot(subplots=True)

uni_data = uni_data.values
Vor dem Training eines künstlichen neuronalen Netzwerks (im Folgenden - ANN) ist die Datenskalierung ein wichtiger Schritt. Eine der gebräuchlichen Methoden zur Durchführung der Skalierung ist die Standardisierung ( Standardisierung ), bei der der Mittelwert subtrahiert und für jedes Merkmal durch die Standardabweichung dividiert wird. Sie können auch eine Methode verwenden tf.keras.utils.normalize, die Werte auf den Bereich [0,1] skaliert.Hinweis : Die Standardisierung sollte nur anhand von Trainingsdaten durchgeführt werden.uni_train_mean = uni_data[:TRAIN_SPLIT].mean()
uni_train_std = uni_data[:TRAIN_SPLIT].std()
Wir führen eine Datenstandardisierung durch.uni_data = (uni_data-uni_train_mean)/uni_train_std
Als nächstes bereiten wir die Daten für das Modell mit einer eindimensionalen Eingabe vor. Die letzten 20 aufgezeichneten Beobachtungen der Temperatur werden dem Eingang des Modells zugeführt, und das Modell muss trainiert werden, um die Temperatur im nächsten Zeitschritt vorherzusagen.univariate_past_history = 20
univariate_future_target = 0
x_train_uni, y_train_uni = univariate_data(uni_data, 0, TRAIN_SPLIT,
univariate_past_history,
univariate_future_target)
x_val_uni, y_val_uni = univariate_data(uni_data, TRAIN_SPLIT, None,
univariate_past_history,
univariate_future_target)
Die Ergebnisse der Anwendung der Funktion univariate_data.print ('Single window of past history')
print (x_train_uni[0])
print ('\n Target temperature to predict')
print (y_train_uni[0])
Single window of past history
[[-1.99766294]
[-2.04281897]
[-2.05439744]
[-2.0312405 ]
[-2.02660912]
[-2.00113649]
[-1.95134907]
[-1.95134907]
[-1.98492663]
[-2.04513467]
[-2.08334362]
[-2.09723778]
[-2.09376424]
[-2.09144854]
[-2.07176515]
[-2.07176515]
[-2.07639653]
[-2.08913285]
[-2.09260639]
[-2.10418486]]
Target temperature to predict
-2.1041848598100876
Ergänzung: Die Vorbereitung von Daten für ein Modell mit einer eindimensionalen Eingabe ist in der folgenden Abbildung schematisch dargestellt (der Einfachheit halber werden die Daten in dieser und den folgenden Abbildungen vor der Standardisierung in einer „Rohform“ und auch ohne das Attribut 'Datum / Uhrzeit' als Index dargestellt): Jetzt, da die Daten Betrachten Sie ein konkretes Beispiel, wenn Sie entsprechend vorbereitet sind. Die an das ANN übertragenen Informationen sind blau hervorgehoben. Ein rotes Kreuz zeigt den zukünftigen Wert an, den das ANN vorhersagen sollte.
Jetzt, da die Daten Betrachten Sie ein konkretes Beispiel, wenn Sie entsprechend vorbereitet sind. Die an das ANN übertragenen Informationen sind blau hervorgehoben. Ein rotes Kreuz zeigt den zukünftigen Wert an, den das ANN vorhersagen sollte.def create_time_steps(length):
return list(range(-length, 0))
def show_plot(plot_data, delta, title):
labels = ['History', 'True Future', 'Model Prediction']
marker = ['.-', 'rx', 'go']
time_steps = create_time_steps(plot_data[0].shape[0])
if delta:
future = delta
else:
future = 0
plt.title(title)
for i, x in enumerate(plot_data):
if i:
plt.plot(future, plot_data[i], marker[i], markersize=10,
label=labels[i])
else:
plt.plot(time_steps, plot_data[i].flatten(), marker[i], label=labels[i])
plt.legend()
plt.xlim([time_steps[0], (future+5)*2])
plt.xlabel('Time-Step')
return plt
show_plot([x_train_uni[0], y_train_uni[0]], 0, 'Sample Example')
 Basislösung (ohne maschinelles Lernen)Vor Beginn des Modelltrainings installieren wir eine einfache Basislösung ( Baseline ). Es besteht aus Folgendem: Für einen bestimmten Eingabevektor „scannt“ die grundlegende Lösungsmethode den gesamten Verlauf und sagt den nächsten Wert als Durchschnitt der letzten 20 Beobachtungen voraus.
Basislösung (ohne maschinelles Lernen)Vor Beginn des Modelltrainings installieren wir eine einfache Basislösung ( Baseline ). Es besteht aus Folgendem: Für einen bestimmten Eingabevektor „scannt“ die grundlegende Lösungsmethode den gesamten Verlauf und sagt den nächsten Wert als Durchschnitt der letzten 20 Beobachtungen voraus.def baseline(history):
return np.mean(history)
show_plot([x_train_uni[0], y_train_uni[0], baseline(x_train_uni[0])], 0,
'Baseline Prediction Example')
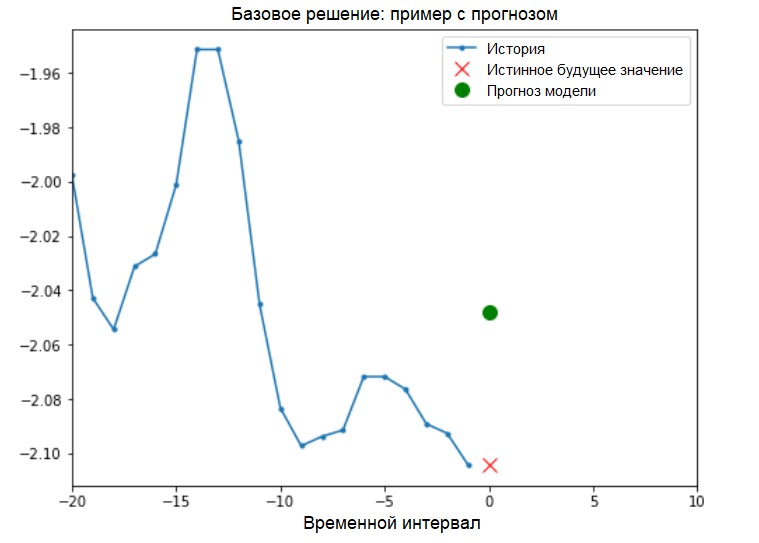 Mal sehen, ob wir das Ergebnis der „Mittelwertbildung“ mithilfe eines wiederkehrenden neuronalen Netzwerks übertreffen können.Wiederkehrendes neuronales Netzwerk Einwiederkehrendes neuronales Netzwerk (RNS) ist eine Art von ANN, die sich gut zur Lösung von Zeitreihenproblemen eignet. RNS verarbeitet Schritt für Schritt die zeitliche Abfolge von Daten, sortiert ihre Elemente und behält den internen Zustand bei, der durch die Verarbeitung der vorherigen Elemente erhalten wird. Weitere Informationen zu RNS finden Sie in der folgenden Anleitung . In diesem Handbuch wird eine spezielle RNC-Schicht namens Long Short-Term Memory ( LSTM ) verwendet.Weitere Verwendung
Mal sehen, ob wir das Ergebnis der „Mittelwertbildung“ mithilfe eines wiederkehrenden neuronalen Netzwerks übertreffen können.Wiederkehrendes neuronales Netzwerk Einwiederkehrendes neuronales Netzwerk (RNS) ist eine Art von ANN, die sich gut zur Lösung von Zeitreihenproblemen eignet. RNS verarbeitet Schritt für Schritt die zeitliche Abfolge von Daten, sortiert ihre Elemente und behält den internen Zustand bei, der durch die Verarbeitung der vorherigen Elemente erhalten wird. Weitere Informationen zu RNS finden Sie in der folgenden Anleitung . In diesem Handbuch wird eine spezielle RNC-Schicht namens Long Short-Term Memory ( LSTM ) verwendet.Weitere Verwendungtf.dataMische den Datensatz, staple ihn und speichere ihn zwischen.Ergänzung:
Weitere Informationen zu den Shuffle- , Batch- und Cache-Methoden finden Sie auf der Tensorflow- Seite :BATCH_SIZE = 256
BUFFER_SIZE = 10000
train_univariate = tf.data.Dataset.from_tensor_slices((x_train_uni, y_train_uni))
train_univariate = train_univariate.cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat()
val_univariate = tf.data.Dataset.from_tensor_slices((x_val_uni, y_val_uni))
val_univariate = val_univariate.batch(BATCH_SIZE).repeat()
Die folgende Visualisierung soll Ihnen helfen, zu verstehen, wie die Daten nach der Stapelverarbeitung aussehen. Es ist ersichtlich, dass LSTM eine bestimmte Form der Dateneingabe erfordert, die ihm bereitgestellt wird.
Es ist ersichtlich, dass LSTM eine bestimmte Form der Dateneingabe erfordert, die ihm bereitgestellt wird.simple_lstm_model = tf.keras.models.Sequential([
tf.keras.layers.LSTM(8, input_shape=x_train_uni.shape[-2:]),
tf.keras.layers.Dense(1)
])
simple_lstm_model.compile(optimizer='adam', loss='mae')
Überprüfen Sie die Modellausgabe.for x, y in val_univariate.take(1):
print(simple_lstm_model.predict(x).shape)
(256, 1)
Ergänzung:
Im Allgemeinen arbeiten RNSs mit Sequenzen. Dies bedeutet, dass die an die Eingabe des Modells gelieferten Daten die folgende Form haben sollten:
[, , - ]
Die Form der Trainingsdaten für das Modell mit einer eindimensionalen Eingabe hat die folgende Form:print(x_train_uni.shape)
(299980, 20, 1)Als nächstes werden wir das Modell untersuchen. Aufgrund der Größe des Datensatzes und um Zeit zu sparen, durchläuft jede Epoche nur 200 Schritte ( step_per_epoch = 200 ) anstelle der vollständigen Trainingsdaten, wie dies normalerweise der Fall ist.EVALUATION_INTERVAL = 200
EPOCHS = 10
simple_lstm_model.fit(train_univariate, epochs=EPOCHS,
steps_per_epoch=EVALUATION_INTERVAL,
validation_data=val_univariate, validation_steps=50)
Train for 200 steps, validate for 50 steps
Epoch 1/10
200/200 [==============================] - 2s 11ms/step - loss: 0.4075 - val_loss: 0.1351
Epoch 2/10
200/200 [==============================] - 1s 4ms/step - loss: 0.1118 - val_loss: 0.0360
Epoch 3/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0490 - val_loss: 0.0289
Epoch 4/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0444 - val_loss: 0.0257
Epoch 5/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0299 - val_loss: 0.0235
Epoch 6/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0317 - val_loss: 0.0224
Epoch 7/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0287 - val_loss: 0.0206
Epoch 8/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0263 - val_loss: 0.0200
Epoch 9/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0254 - val_loss: 0.0182
Epoch 10/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0228 - val_loss: 0.0174
Vorhersage mit einem einfachen LSTM-ModellNach Abschluss der Erstellung eines einfachen LSTM-Modells werden wir mehrere Vorhersagen treffen.for x, y in val_univariate.take(3):
plot = show_plot([x[0].numpy(), y[0].numpy(),
simple_lstm_model.predict(x)[0]], 0, 'Simple LSTM model')
plot.show()
 Es sieht besser aus als das Basislevel.Nachdem Sie sich mit den Grundlagen vertraut gemacht haben, fahren wir mit dem zweiten Teil fort, in dem die Arbeit mit einer mehrdimensionalen Zeitreihe beschrieben wird.
Es sieht besser aus als das Basislevel.Nachdem Sie sich mit den Grundlagen vertraut gemacht haben, fahren wir mit dem zweiten Teil fort, in dem die Arbeit mit einer mehrdimensionalen Zeitreihe beschrieben wird.Teil 2: Mehrdimensionale Zeitreihenprognose
Wie bereits erwähnt, enthält der Originaldatensatz 14 verschiedene meteorologische Indikatoren. Der Einfachheit und Bequemlichkeit halber werden im zweiten Teil nur drei davon betrachtet - Lufttemperatur, atmosphärischer Druck und Luftdichte.Um weitere Funktionen verwenden zu können, müssen deren Namen zur Liste feature_considered hinzugefügt werden .features_considered = ['p (mbar)', 'T (degC)', 'rho (g/m**3)']
features = df[features_considered]
features.index = df['Date Time']
features.head()
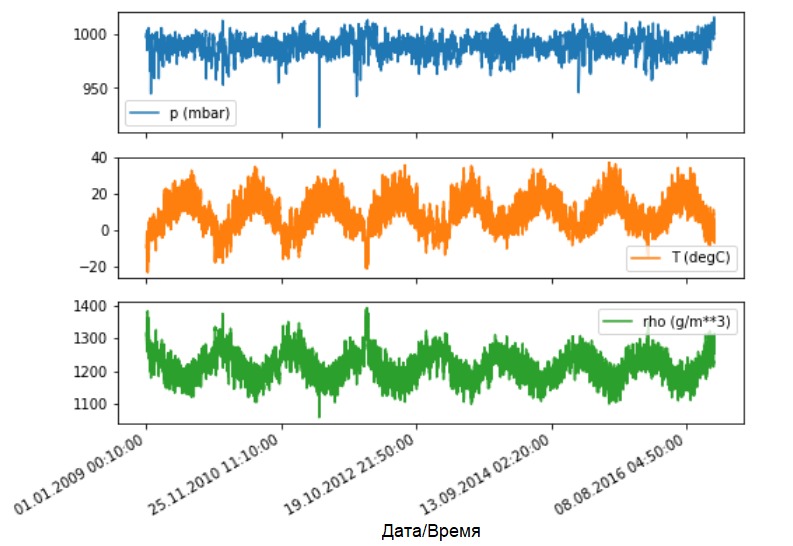
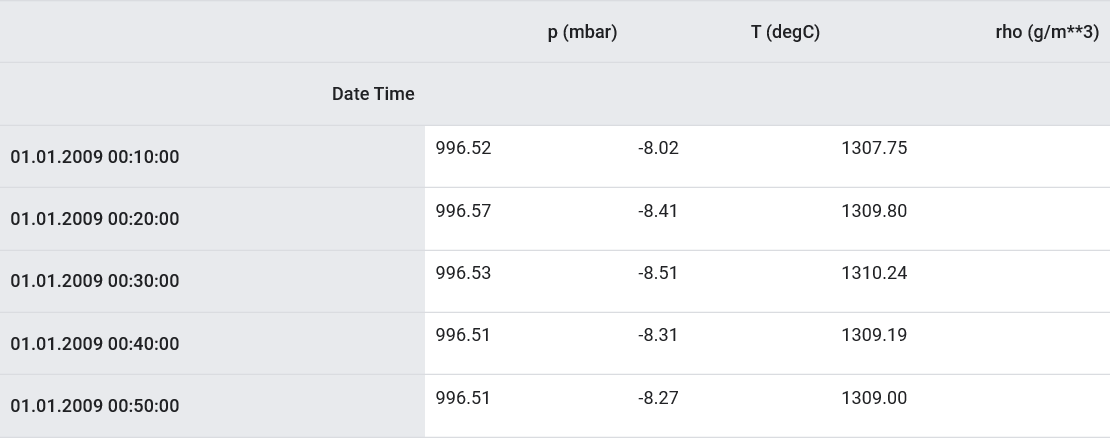 Mal sehen, wie sich diese Indikatoren im Laufe der Zeit ändern.
Mal sehen, wie sich diese Indikatoren im Laufe der Zeit ändern.features.plot(subplots=True)
 Nach wie vor besteht der erste Schritt darin, den Datensatz mit der Berechnung des Durchschnittswerts und der Standardabweichung der Trainingsdaten zu standardisieren.
Nach wie vor besteht der erste Schritt darin, den Datensatz mit der Berechnung des Durchschnittswerts und der Standardabweichung der Trainingsdaten zu standardisieren.dataset = features.values
data_mean = dataset[:TRAIN_SPLIT].mean(axis=0)
data_std = dataset[:TRAIN_SPLIT].std(axis=0)
dataset = (dataset-data_mean)/data_std
Ergänzung:
Weiter im Handbuch werden wir über Punkt- und Intervallprognosen sprechen.
Das Endergebnis ist wie folgt. Wenn Sie das Modell benötigen, um einen Wert in der Zukunft vorherzusagen (z. B. den Temperaturwert nach 12 Stunden) (Ein-Schritt- / Einzelschritt-Modell), müssen Sie das Modell so trainieren, dass es in Zukunft nur einen Wert vorhersagt. Wenn die Aufgabe darin besteht, den Wertebereich in der Zukunft vorherzusagen (z. B. stündliche Temperaturwerte in den nächsten 12 Stunden) (mehrstufiges Modell), sollte das Modell auch darauf trainiert werden, den Wertebereich in der Zukunft vorherzusagen. PunktvorhersageIn diesem Fall wird das Modell darauf trainiert, einen Wert in der Zukunft basierend auf einer verfügbaren Historie vorherzusagen.Die folgende Funktion führt dieselbe Aufgabe zum Organisieren von Zeitintervallen nur mit dem Unterschied aus, dass hier die neuesten Beobachtungen basierend auf einer bestimmten Schrittgröße ausgewählt werden.
PunktvorhersageIn diesem Fall wird das Modell darauf trainiert, einen Wert in der Zukunft basierend auf einer verfügbaren Historie vorherzusagen.Die folgende Funktion führt dieselbe Aufgabe zum Organisieren von Zeitintervallen nur mit dem Unterschied aus, dass hier die neuesten Beobachtungen basierend auf einer bestimmten Schrittgröße ausgewählt werden.def multivariate_data(dataset, target, start_index, end_index, history_size,
target_size, step, single_step=False):
data = []
labels = []
start_index = start_index + history_size
if end_index is None:
end_index = len(dataset) - target_size
for i in range(start_index, end_index):
indices = range(i-history_size, i, step)
data.append(dataset[indices])
if single_step:
labels.append(target[i+target_size])
else:
labels.append(target[i:i+target_size])
return np.array(data), np.array(labels)
In diesem Handbuch verarbeitet das ANN Daten für die letzten fünf (5) Tage, d. H. 720 Beobachtungen (6 x 24 x 5). Angenommen, die Auswahl der Daten erfolgt nicht alle 10 Minuten, sondern jede Stunde: Innerhalb von 60 Minuten sind keine starken Änderungen zu erwarten. Daher besteht die Geschichte der letzten fünf Tage aus 120 Beobachtungen (720/6). Für ein Modell, das eine Punktvorhersage durchführt, ist das Ziel der Temperaturwert nach 12 Stunden in der Zukunft. In diesem Fall ist der Zielvektor die Temperatur nach 72 (12x6) Beobachtungen ( siehe folgenden Zusatz. - Ungefährer Übersetzer ).past_history = 720
future_target = 72
STEP = 6
x_train_single, y_train_single = multivariate_data(dataset, dataset[:, 1], 0,
TRAIN_SPLIT, past_history,
future_target, STEP,
single_step=True)
x_val_single, y_val_single = multivariate_data(dataset, dataset[:, 1],
TRAIN_SPLIT, None, past_history,
future_target, STEP,
single_step=True)
Überprüfen Sie das Zeitintervall.print ('Single window of past history : {}'.format(x_train_single[0].shape))
Single window of past history : (120, 3)
train_data_single = tf.data.Dataset.from_tensor_slices((x_train_single, y_train_single))
train_data_single = train_data_single.cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat()
val_data_single = tf.data.Dataset.from_tensor_slices((x_val_single, y_val_single))
val_data_single = val_data_single.batch(BATCH_SIZE).repeat()
single_step_model = tf.keras.models.Sequential()
single_step_model.add(tf.keras.layers.LSTM(32,
input_shape=x_train_single.shape[-2:]))
single_step_model.add(tf.keras.layers.Dense(1))
single_step_model.compile(optimizer=tf.keras.optimizers.RMSprop(), loss='mae')
Wir werden unsere Stichprobe überprüfen und Verlustkurven in den Phasen des Trainings und der Überprüfung ableiten.for x, y in val_data_single.take(1):
print(single_step_model.predict(x).shape)
(256, 1)
single_step_history = single_step_model.fit(train_data_single, epochs=EPOCHS,
steps_per_epoch=EVALUATION_INTERVAL,
validation_data=val_data_single,
validation_steps=50)
Train for 200 steps, validate for 50 steps
Epoch 1/10
200/200 [==============================] - 4s 18ms/step - loss: 0.3090 - val_loss: 0.2646
Epoch 2/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2624 - val_loss: 0.2435
Epoch 3/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2616 - val_loss: 0.2472
Epoch 4/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2567 - val_loss: 0.2442
Epoch 5/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2263 - val_loss: 0.2346
Epoch 6/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2416 - val_loss: 0.2643
Epoch 7/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2411 - val_loss: 0.2577
Epoch 8/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2410 - val_loss: 0.2388
Epoch 9/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2447 - val_loss: 0.2485
Epoch 10/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2388 - val_loss: 0.2422
def plot_train_history(history, title):
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(loss))
plt.figure()
plt.plot(epochs, loss, 'b', label='Training loss')
plt.plot(epochs, val_loss, 'r', label='Validation loss')
plt.title(title)
plt.legend()
plt.show()
plot_train_history(single_step_history,
'Single Step Training and validation loss')
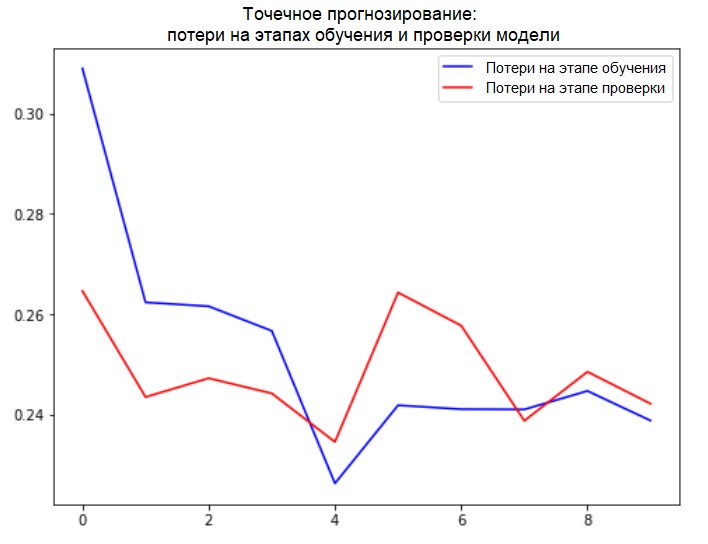 Ergänzung:
Ergänzung:
Die Datenvorbereitung für ein Modell mit einer mehrdimensionalen Eingabe zur Punktvorhersage ist in der folgenden Abbildung schematisch dargestellt. Zur Vereinfachung und eine visuelle Darstellung der Datenaufbereitung, das Argument STEPist 1. Man beachte , daß in den gegebenen Generatorfunktionen, die sich Argument STEP nur für die Bildung der Geschichte bestimmt , und nicht für den Zielvektor.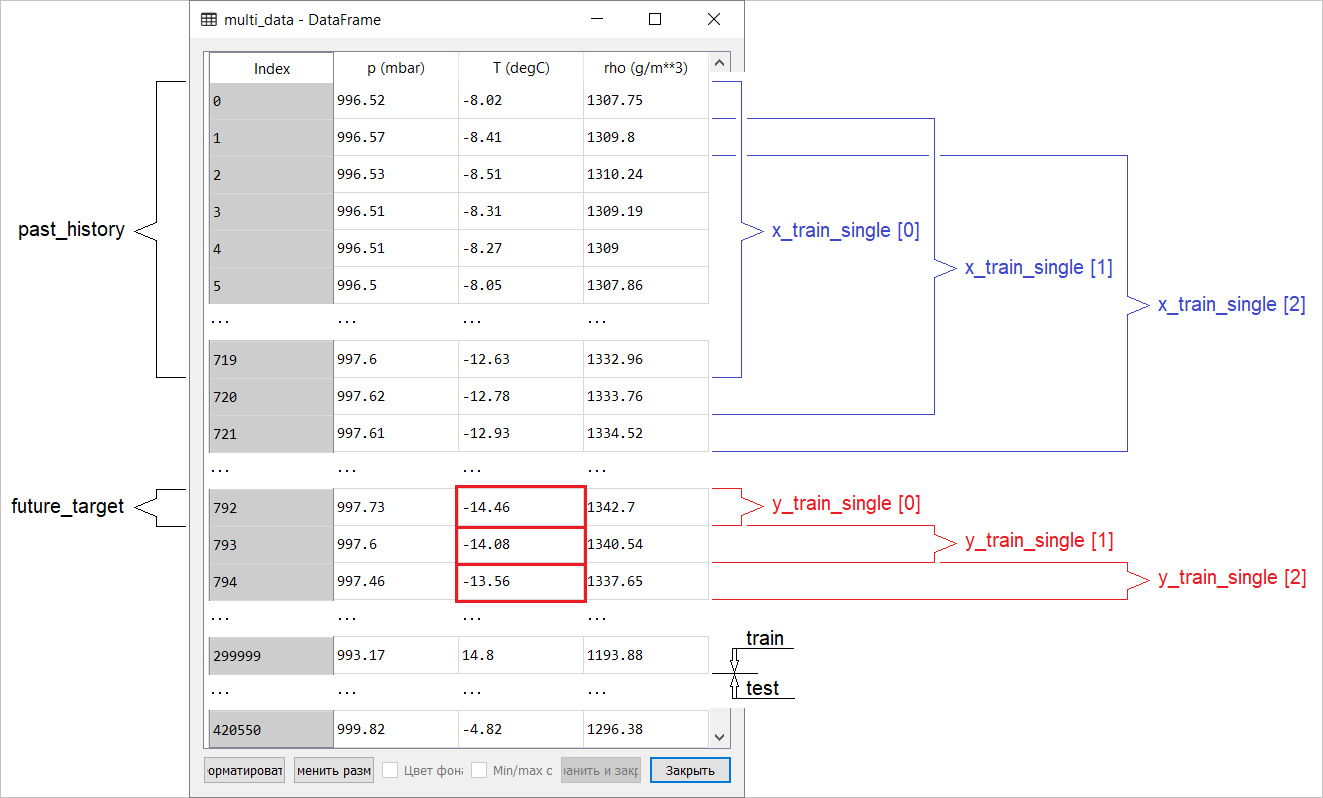 In diesem Fall hat es
In diesem Fall hat es x_train_singledie Form (299280, 720, 3).
Wann STEP=6hat das Formular die folgende Form: (299280, 120, 3)und die Geschwindigkeit der Funktion wird erheblich erhöht. Im Allgemeinen müssen Sie dem Programmierer Anerkennung zollen: Die im Handbuch vorgestellten Generatoren sind hinsichtlich des Speicherverbrauchs sehr unersättlich.Durchführen einer PunktvorhersageNachdem das Modell trainiert wurde, werden wir mehrere Testvorhersagen durchführen. Die stündlich ausgewählte Beobachtungshistorie von 3 Zeichen für die letzten fünf Tage (Zeitintervall = 120) wird der Modelleingabe zugeführt. Da unser Ziel darin besteht, nur die Temperatur vorherzusagen, werden die vergangenen Temperaturwerte ( Verlauf ) in der Grafik blau angezeigt . Die Prognose wurde einen halben Tag in die Zukunft erstellt (daher die Lücke zwischen der Geschichte und dem vorhergesagten Wert).for x, y in val_data_single.take(3):
plot = show_plot([x[0][:, 1].numpy(), y[0].numpy(),
single_step_model.predict(x)[0]], 12,
'Single Step Prediction')
plot.show()
 IntervallprognoseIn diesem Fall wird das Modell auf der Grundlage einer verfügbaren Historie trainiert, um das Intervall zukünftiger Werte vorherzusagen. Im Gegensatz zu einem Modell, das in Zukunft nur einen Wert vorhersagt, sagt dieses Modell daher eine Folge von Werten in der Zukunft voraus.Angenommen, wie im Fall des Modells, das eine Punktvorhersage durchführt, sind die Trainingsdaten für das Modell, das eine Intervallvorhersage durchführt, die stündlichen Messungen der letzten fünf Tage (720/6). In diesem Fall muss das Modell jedoch darauf trainiert werden, die Temperatur für die nächsten 12 Stunden vorherzusagen. Da Beobachtungen alle 10 Minuten aufgezeichnet werden, sollte die Ausgabe des Modells aus 72 Vorhersagen bestehen. Um diese Aufgabe abzuschließen, muss der Datensatz erneut vorbereitet werden, jedoch mit einem anderen Zielintervall.
IntervallprognoseIn diesem Fall wird das Modell auf der Grundlage einer verfügbaren Historie trainiert, um das Intervall zukünftiger Werte vorherzusagen. Im Gegensatz zu einem Modell, das in Zukunft nur einen Wert vorhersagt, sagt dieses Modell daher eine Folge von Werten in der Zukunft voraus.Angenommen, wie im Fall des Modells, das eine Punktvorhersage durchführt, sind die Trainingsdaten für das Modell, das eine Intervallvorhersage durchführt, die stündlichen Messungen der letzten fünf Tage (720/6). In diesem Fall muss das Modell jedoch darauf trainiert werden, die Temperatur für die nächsten 12 Stunden vorherzusagen. Da Beobachtungen alle 10 Minuten aufgezeichnet werden, sollte die Ausgabe des Modells aus 72 Vorhersagen bestehen. Um diese Aufgabe abzuschließen, muss der Datensatz erneut vorbereitet werden, jedoch mit einem anderen Zielintervall.future_target = 72
x_train_multi, y_train_multi = multivariate_data(dataset, dataset[:, 1], 0,
TRAIN_SPLIT, past_history,
future_target, STEP)
x_val_multi, y_val_multi = multivariate_data(dataset, dataset[:, 1],
TRAIN_SPLIT, None, past_history,
future_target, STEP)
Überprüfen Sie die Auswahl.print ('Single window of past history : {}'.format(x_train_multi[0].shape))
print ('\n Target temperature to predict : {}'.format(y_train_multi[0].shape))
Single window of past history : (120, 3)
Target temperature to predict : (72,)
train_data_multi = tf.data.Dataset.from_tensor_slices((x_train_multi, y_train_multi))
train_data_multi = train_data_multi.cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat()
val_data_multi = tf.data.Dataset.from_tensor_slices((x_val_multi, y_val_multi))
val_data_multi = val_data_multi.batch(BATCH_SIZE).repeat()
Addition: Der Unterschied in der Bildung des Zielvektors für das „Intervallmodell“ gegenüber dem „Punktmodell“ ist in der folgenden Abbildung dargestellt. Wir werden die Visualisierung vorbereiten.
Wir werden die Visualisierung vorbereiten.def multi_step_plot(history, true_future, prediction):
plt.figure(figsize=(12, 6))
num_in = create_time_steps(len(history))
num_out = len(true_future)
plt.plot(num_in, np.array(history[:, 1]), label='History')
plt.plot(np.arange(num_out)/STEP, np.array(true_future), 'bo',
label='True Future')
if prediction.any():
plt.plot(np.arange(num_out)/STEP, np.array(prediction), 'ro',
label='Predicted Future')
plt.legend(loc='upper left')
plt.show()
In diesem und den folgenden ähnlichen Diagrammen sind der Verlauf und zukünftige Daten stündlich.for x, y in train_data_multi.take(1):
multi_step_plot(x[0], y[0], np.array([0]))
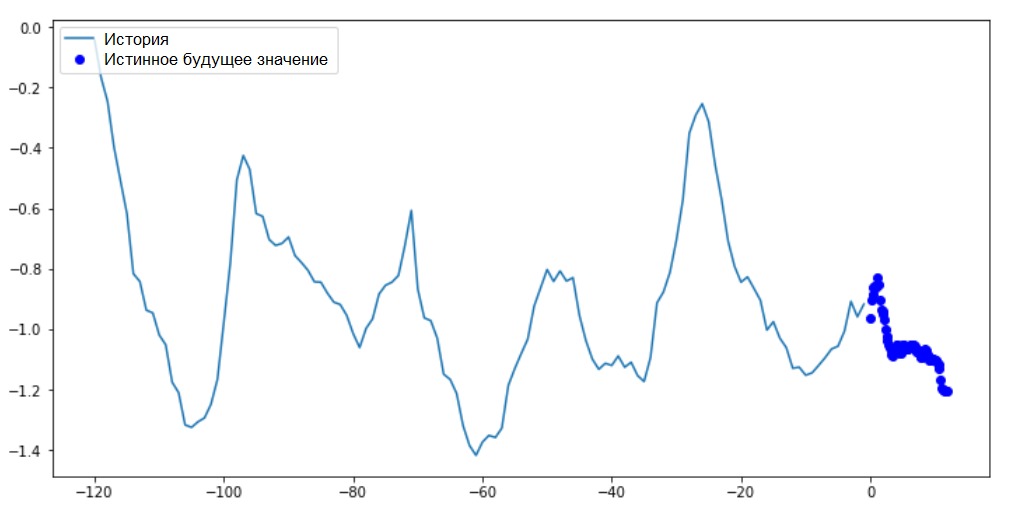 Da diese Aufgabe etwas komplizierter ist als die vorherige, besteht das Modell aus zwei LSTM-Schichten. Schließlich hat die Ausgangsschicht 72 Neuronen, da 72 Vorhersagen durchgeführt werden.
Da diese Aufgabe etwas komplizierter ist als die vorherige, besteht das Modell aus zwei LSTM-Schichten. Schließlich hat die Ausgangsschicht 72 Neuronen, da 72 Vorhersagen durchgeführt werden.multi_step_model = tf.keras.models.Sequential()
multi_step_model.add(tf.keras.layers.LSTM(32,
return_sequences=True,
input_shape=x_train_multi.shape[-2:]))
multi_step_model.add(tf.keras.layers.LSTM(16, activation='relu'))
multi_step_model.add(tf.keras.layers.Dense(72))
multi_step_model.compile(optimizer=tf.keras.optimizers.RMSprop(clipvalue=1.0), loss='mae')
Wir werden unsere Stichprobe überprüfen und Verlustkurven in den Phasen des Trainings und der Überprüfung ableiten.for x, y in val_data_multi.take(1):
print (multi_step_model.predict(x).shape)
(256, 72)
multi_step_history = multi_step_model.fit(train_data_multi, epochs=EPOCHS,
steps_per_epoch=EVALUATION_INTERVAL,
validation_data=val_data_multi,
validation_steps=50)
Train for 200 steps, validate for 50 steps
Epoch 1/10
200/200 [==============================] - 21s 103ms/step - loss: 0.4952 - val_loss: 0.3008
Epoch 2/10
200/200 [==============================] - 18s 89ms/step - loss: 0.3474 - val_loss: 0.2898
Epoch 3/10
200/200 [==============================] - 18s 89ms/step - loss: 0.3325 - val_loss: 0.2541
Epoch 4/10
200/200 [==============================] - 18s 89ms/step - loss: 0.2425 - val_loss: 0.2066
Epoch 5/10
200/200 [==============================] - 18s 89ms/step - loss: 0.1963 - val_loss: 0.1995
Epoch 6/10
200/200 [==============================] - 18s 90ms/step - loss: 0.2056 - val_loss: 0.2119
Epoch 7/10
200/200 [==============================] - 18s 91ms/step - loss: 0.1978 - val_loss: 0.2079
Epoch 8/10
200/200 [==============================] - 18s 89ms/step - loss: 0.1957 - val_loss: 0.2033
Epoch 9/10
200/200 [==============================] - 18s 90ms/step - loss: 0.1977 - val_loss: 0.1860
Epoch 10/10
200/200 [==============================] - 18s 88ms/step - loss: 0.1904 - val_loss: 0.1863
plot_train_history(multi_step_history, 'Multi-Step Training and validation loss')
 Durchführen einer IntervallvorhersageLassen Sie uns herausfinden, wie erfolgreich ein trainierter ANN mit Vorhersagen zukünftiger Temperaturwerte umgeht.
Durchführen einer IntervallvorhersageLassen Sie uns herausfinden, wie erfolgreich ein trainierter ANN mit Vorhersagen zukünftiger Temperaturwerte umgeht.for x, y in val_data_multi.take(3):
multi_step_plot(x[0], y[0], multi_step_model.predict(x)[0])
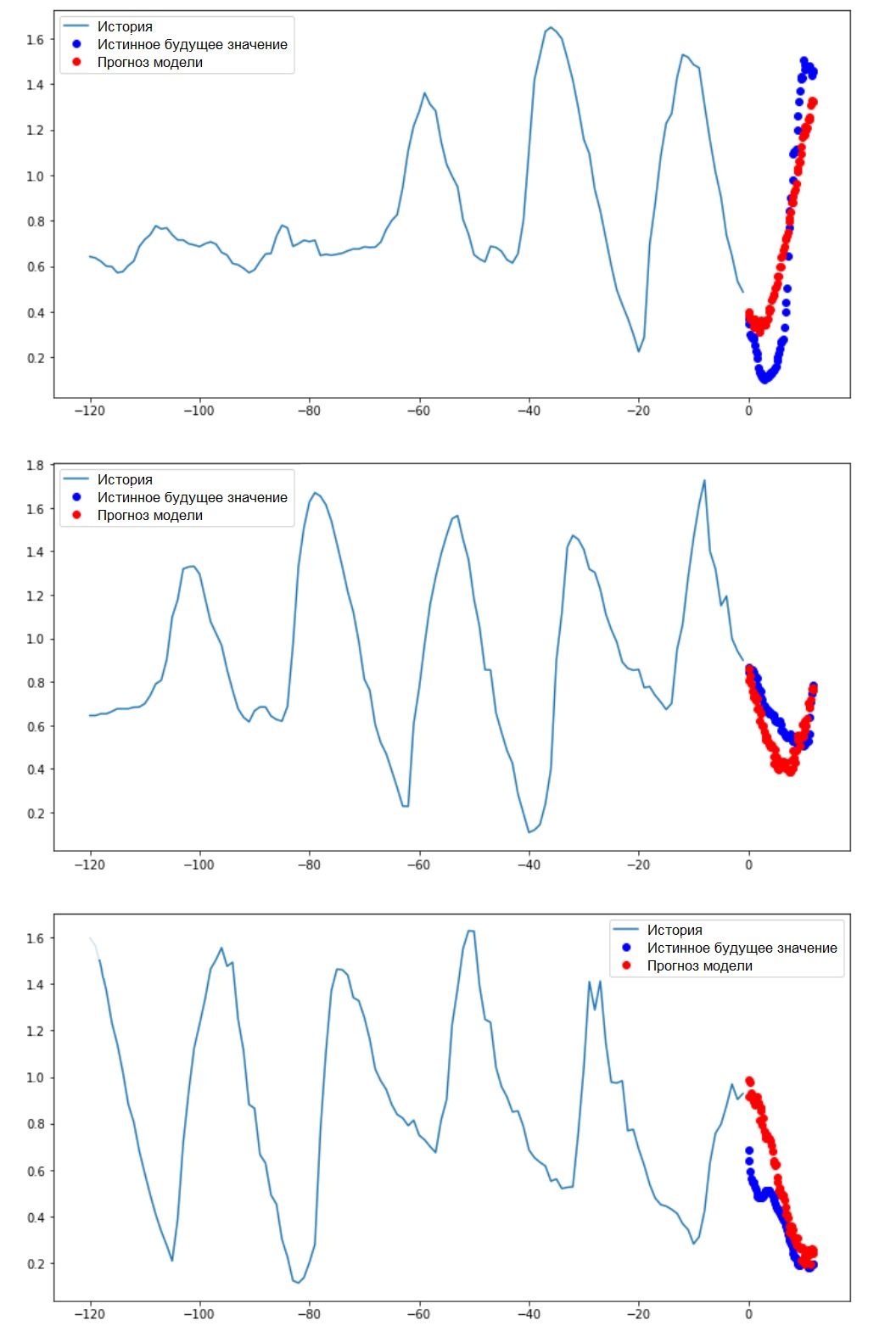
Nächste Schritte
Dieser Leitfaden ist eine kurze Einführung in die Vorhersage von Zeitreihen mit RNS. Jetzt können Sie versuchen, den Aktienmarkt vorherzusagen und Milliardär zu werden (im Original einfach so :). - Hinweis Übersetzer) .Darüber hinaus können Sie anstelle der Funktion uni / multivariate_data einen eigenen Generator zum Vorbereiten von Daten schreiben , um den Speicher effizienter zu nutzen. Sie können sich auch mit der Arbeit des „ Zeitreihenfensters “ vertraut machen und seine Ideen in diesen Leitfaden einbringen.Zum besseren Verständnis wird empfohlen, Kapitel 15 des Buches „Angewandtes maschinelles Lernen mit Scikit-Learn, Keras und TensorFlow“ (Aurelien Geron, 2. Auflage) und Kapitel 6 des Buches zu lesen"Deep Learning in Python" (Francois Scholl).Letzte Ergänzung
Achten Sie während Ihres Aufenthalts zu Hause nicht nur auf Ihre Gesundheit, sondern auch auf den Computer, indem Sie Beispiele des Handbuchs für einen abgeschnittenen Datensatz ausführen. Wenn Sie beispielsweise den Anteil von 70 x 30 (Schulung / Test) berücksichtigen, können Sie ihn wie folgt einschränken:dataset = features[300000:].values
TRAIN_SPLIT = 85000