Sobald es interessant wurde, welche Themen die LDA (latente Platzierung von Dirichlet) auf den Materialien des "Live Journal" hervorheben würde. Wie sie sagen, gibt es Interesse - kein Problem.Für den Anfang, ein wenig über die LDA an den Fingern, werden wir nicht auf mathematische Details eingehen (jeder Interessierte - liest). LDA - ist einer der häufigsten Algorithmen zur Modellierung von Themen. Jedes Dokument (sei es ein Artikel, ein Buch oder eine andere Quelle für Textdaten) ist eine Mischung aus Themen, und jedes Thema ist eine Mischung aus Wörtern.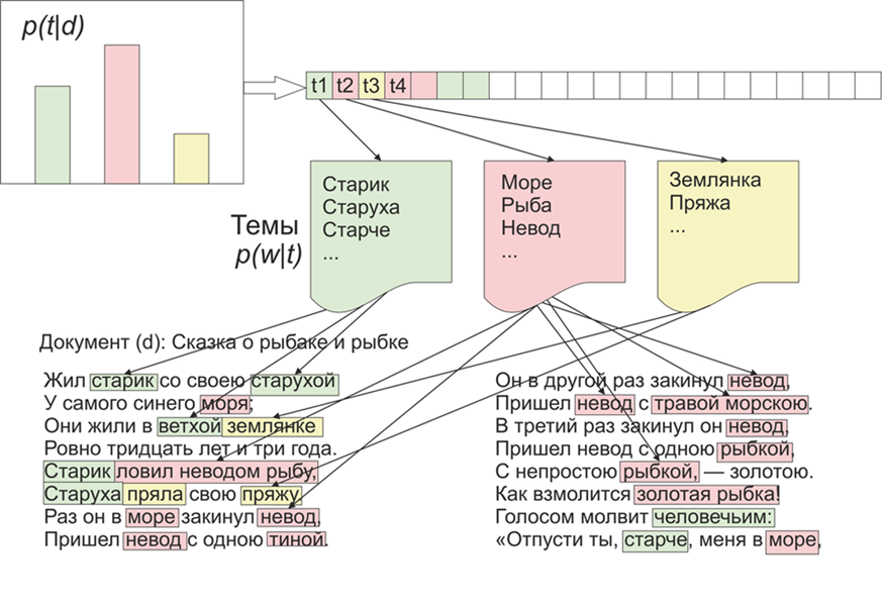 Bild aus Wikipedia genommenDie Aufgabe der LDA besteht daher darin, Wortgruppen zu finden, die Themen aus einer Sammlung von Dokumenten bilden. Anhand der Themen können Sie dann Texte gruppieren oder einfach Schlüsselwörter hervorheben.Ungefähr 1800 Artikel gingen von der LifeJournal-Website ein, alle wurden in das JSONL-Format konvertiert. Ich werde die ungereinigten Artikel auf der Yandex-Festplatte belassen . Wir werden die Daten bereinigen und normalisieren: Kommentare wegwerfen, Stoppwörter löschen (die Liste zusammen mit dem Quellcode ist auf github verfügbar), wir werden alle Wörter in Kleinbuchstaben schreiben, wir werden Interpunktion und Wörter entfernen, die 3 Buchstaben oder weniger enthalten. Eine der wichtigsten Vorverarbeitungsvorgänge: Das Löschen häufig vorkommender Wörter kann im Prinzip auf das Löschen nur von Stoppwörtern beschränkt werden. Häufig verwendete Wörter werden jedoch mit hoher Wahrscheinlichkeit in fast allen Themen enthalten sein. In diesem Fall können solche Wörter nachbearbeitet und gelöscht werden. Es ist deine Entscheidung.
Bild aus Wikipedia genommenDie Aufgabe der LDA besteht daher darin, Wortgruppen zu finden, die Themen aus einer Sammlung von Dokumenten bilden. Anhand der Themen können Sie dann Texte gruppieren oder einfach Schlüsselwörter hervorheben.Ungefähr 1800 Artikel gingen von der LifeJournal-Website ein, alle wurden in das JSONL-Format konvertiert. Ich werde die ungereinigten Artikel auf der Yandex-Festplatte belassen . Wir werden die Daten bereinigen und normalisieren: Kommentare wegwerfen, Stoppwörter löschen (die Liste zusammen mit dem Quellcode ist auf github verfügbar), wir werden alle Wörter in Kleinbuchstaben schreiben, wir werden Interpunktion und Wörter entfernen, die 3 Buchstaben oder weniger enthalten. Eine der wichtigsten Vorverarbeitungsvorgänge: Das Löschen häufig vorkommender Wörter kann im Prinzip auf das Löschen nur von Stoppwörtern beschränkt werden. Häufig verwendete Wörter werden jedoch mit hoher Wahrscheinlichkeit in fast allen Themen enthalten sein. In diesem Fall können solche Wörter nachbearbeitet und gelöscht werden. Es ist deine Entscheidung.stop=open('stop.txt')
stop_words=[]
for line in stop:
stop_words.append(line)
for i in range(0,len(stop_words)):
stop_words[i]=stop_words[i][:-1]
texts=[re.split( r' [\w\.\&\?!,_\-#)(:;*%$№"\@]* ' ,texts[i])[0].replace("\n","") for i in range(0,len(texts))]
texts=[test_re(line) for line in texts]
texts=[t.lower() for t in texts]
texts = [[word for word in document.split() if word not in stop_words] for document in texts]
texts=[[word for word in document if len(word)>=3]for document in texts]
Als nächstes bringen wir alle Wörter in die normale Form: Dazu verwenden wir die pymorphy2-Bibliothek, die über pip installiert werden kann.morph = pymorphy2.MorphAnalyzer()
for i in range(0,len(texts)):
for j in range(0,len(texts[i])):
texts[i][j] = morph.parse(texts[i][j])[0].normal_form
Ja, wir werden Informationen über die Form von Wörtern verlieren, aber in diesem Zusammenhang sind wir mehr an der Kompatibilität von Wörtern untereinander interessiert. Hier ist unsere Vorverarbeitung abgeschlossen, sie ist nicht abgeschlossen, aber es reicht aus, um zu sehen, wie der LDA-Algorithmus funktioniert.Ferner kann der oben erwähnte Punkt im Prinzip weggelassen werden, aber meiner Meinung nach sind die Ergebnisse angemessener. Auch hier gilt der Schwellenwert. Sie entscheiden beispielsweise, dass Sie eine Funktion erstellen können, die von der durchschnittlichen Länge der Dokumente und ihrer Anzahl abhängt ::counter = collections.Counter()
for t in texts:
for r in t:
counter[r]+=1
limit = len(texts)/5
too_common = [w for w in counter if counter[w] > limit]
too_common=set(too_common)
texts = [[word for word in document if word not in too_common] for document in texts]
Fahren wir direkt mit dem Training des Modells fort. Dazu müssen wir die Gensim-Bibliothek installieren, die ein paar coole Brötchen enthält. Zuerst müssen Sie alle Wörter codieren, die Dictionary-Funktion erledigt dies für uns, dann ersetzen wir die Wörter durch ihre numerischen Äquivalente. Die auskommentierte Version des LDA-Aufrufs ist länger, da sie nach jedem Dokument aktualisiert wird. Sie können mit den Einstellungen spielen und die entsprechende Option auswählen.texts=preposition_text_for_lda(my_r)
dictionary = gensim.corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
lda = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=10)
Nach der Arbeit des Programms können die Themen mit dem Befehl angezeigt werdenlda.show_topic(i,topn=30)
, wobei i die Themennummer und topn die Anzahl der Wörter im anzuzeigenden Thema ist.Jetzt ein kleiner Bonus für die Visualisierung von Themen. Dazu müssen Sie die Wordcloud-Bibliothek installieren (ähnliche Dienstprogramme befinden sich auch in matplotlib). Dieser Code visualisiert Themen und speichert sie im aktuellen Ordner.from wordcloud import WordCloud, STOPWORDS
for i in range(0,10):
a=lda.show_topic(i,topn=30)
wordcloud = WordCloud(
relative_scaling = 1.0,
stopwords = too_common
).generate_from_frequencies(dict(a))
wordcloud.to_file('society'+str(i)+'.png')
Und zum Schluss noch ein paar Beispiele für die Themen, die ich bekommen habe:
 Experimentieren Sie und Sie können noch aussagekräftigere Ergebnisse erzielen.
Experimentieren Sie und Sie können noch aussagekräftigere Ergebnisse erzielen.