 Guten Tag, Freunde!In diesem Artikel werden einige Konzepte aus der Musiktheorie erläutert, mit denen die Web Audio API (WAA) arbeitet. Wenn Sie diese Konzepte kennen, können Sie fundierte Entscheidungen treffen, wenn Sie Audio in einer Anwendung entwerfen. Dieser Artikel macht Sie nicht zu einem erfahrenen Toningenieur, aber er hilft Ihnen zu verstehen, warum WAA so funktioniert, wie es funktioniert.
Guten Tag, Freunde!In diesem Artikel werden einige Konzepte aus der Musiktheorie erläutert, mit denen die Web Audio API (WAA) arbeitet. Wenn Sie diese Konzepte kennen, können Sie fundierte Entscheidungen treffen, wenn Sie Audio in einer Anwendung entwerfen. Dieser Artikel macht Sie nicht zu einem erfahrenen Toningenieur, aber er hilft Ihnen zu verstehen, warum WAA so funktioniert, wie es funktioniert.Audio-Schaltung
Die Essenz von WAA besteht darin, einige Operationen mit Ton in einem Audiokontext auszuführen. Diese API wurde speziell für das modulare Routing entwickelt. Die Grundoperationen mit Sound sind Audioknoten, die miteinander verbunden sind und ein Routing-Diagramm (Audio-Routing-Diagramm) bilden. Mehrere Quellen - mit unterschiedlichen Kanaltypen - werden in einem einzigen Kontext verarbeitet. Dieser modulare Aufbau bietet die notwendige Flexibilität, um komplexe Funktionen mit dynamischen Effekten zu erstellen.Audioknoten sind über Ein- und Ausgänge miteinander verbunden, bilden eine Kette, die von einer oder mehreren Quellen ausgeht, durch einen oder mehrere Knoten verläuft und am Ziel endet. Grundsätzlich können Sie beispielsweise auf ein Ziel verzichten, wenn Sie nur einige Audiodaten visualisieren möchten. Ein typischer Web-Audio-Workflow sieht ungefähr so aus:- Erstellen Sie einen Audiokontext
- Erstellen Sie im Kontext Quellen wie <audio>, einen Oszillator (Soundgenerator) oder einen Stream
- Erstellen Sie Effektknoten wie Hall , Biquad-Filter, Panner oder Kompressor
- Wählen Sie ein Ziel für Audio aus, z. B. Lautsprecher auf dem Computer eines Benutzers
- Stellen Sie durch Effekte eine Verbindung zwischen Quellen zu einem Ziel her

Kanalbezeichnung
Die Anzahl der verfügbaren Audiokanäle wird häufig in numerischem Format angegeben, z. B. 2.0 oder 5.1. Dies wird als Kanalbezeichnung bezeichnet. Die erste Ziffer gibt den gesamten Frequenzbereich an, den das Signal enthält. Die zweite Ziffer gibt die Anzahl der Kanäle an, die für die Niederfrequenzeffektausgänge - Subwoofer - reserviert sind .Jeder Eingang oder Ausgang besteht aus einem oder mehreren Kanälen, die gemäß einer bestimmten Audio-Schaltung aufgebaut sind. Es gibt verschiedene diskrete Kanalstrukturen wie Mono, Stereo, Quad, 5.1 usw.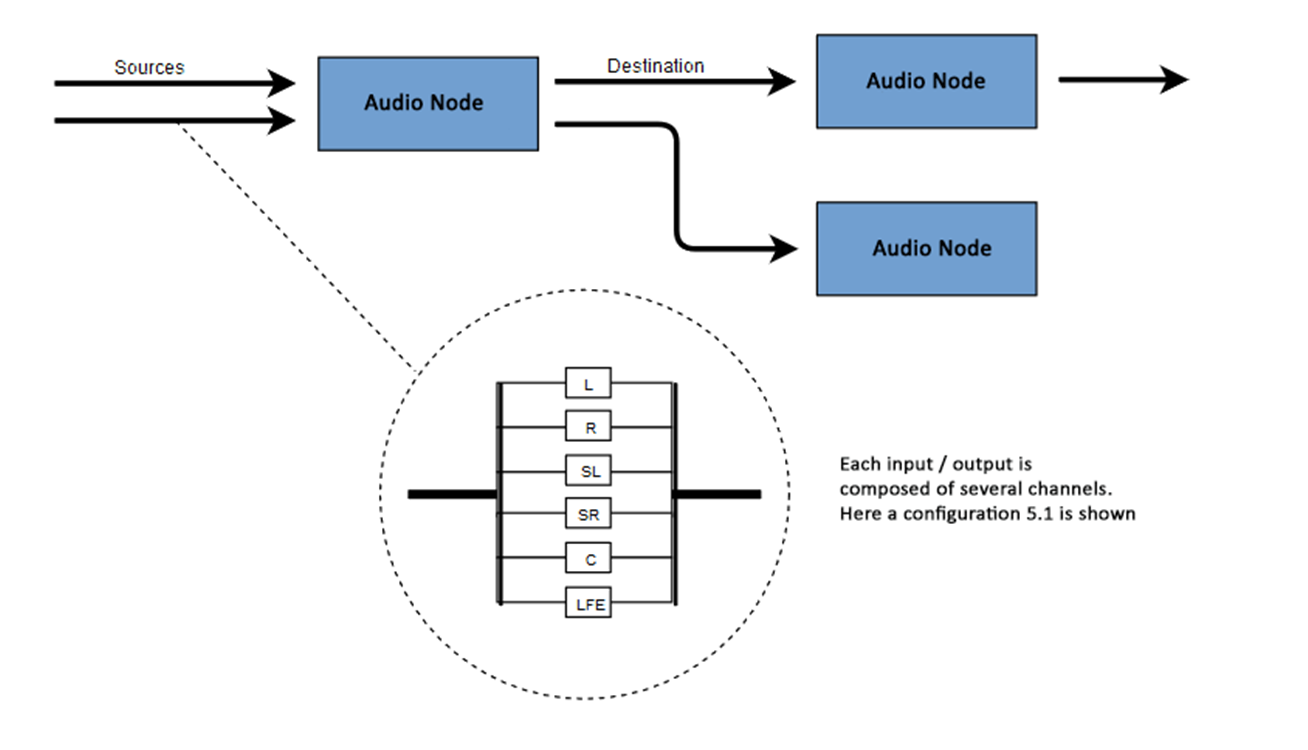 Audioquellen können auf viele Arten erhalten werden. Der Ton kann sein:
Audioquellen können auf viele Arten erhalten werden. Der Ton kann sein:- Wird von JavaScript über einen Audioknoten (z. B. einen Oszillator) generiert.
- Erstellt aus Rohdaten mit PCM (Pulse Code Modulation)
- Abgeleitet von HTML-Medienelementen (wie <video> oder <audio>)
- Abgeleitet von einem WebRTC-Medienstrom (z. B. einer Webcam oder einem Mikrofon)
Audiodaten: Was ist im Beispiel
Abtasten bedeutet, ein kontinuierliches Signal in ein diskretes (geteiltes) (analoges zu digitales) Signal umzuwandeln. Mit anderen Worten, eine kontinuierliche Schallwelle, wie beispielsweise ein Live-Konzert, wird in eine Folge von Samples umgewandelt, die es dem Computer ermöglichen, das Audio in separaten Blöcken zu verarbeiten.Audiopuffer: Frames, Samples und Kanäle
AudioBuffer akzeptiert die Anzahl der Kanäle als Parameter (1 für Mono, 2 für Stereo usw.), die Länge - die Anzahl der Sample-Frames im Puffer und die Sampling-Frequenz - die Anzahl der Frames pro Sekunde.Ein Beispiel ist ein einfacher 32-Bit-Gleitkommawert (float32), der der Wert des Audiostreams zu einem bestimmten Zeitpunkt und in einem bestimmten Kanal (links oder rechts usw.) ist. Ein Sample-Frame oder Frame ist eine Reihe von Werten aller Kanäle, die zu einem bestimmten Zeitpunkt wiedergegeben werden: Alle Abtastwerte aller gleichzeitig wiedergegebenen Kanäle (zwei für Stereo, sechs für 5.1 usw.).Die Abtastrate ist die Anzahl der Abtastwerte (oder Frames, da alle Samples in einem Frame gleichzeitig abgespielt werden), die in einer Sekunde wiedergegeben und in Hertz (Hz) gemessen werden. Je höher die Frequenz, desto besser die Klangqualität.Schauen wir uns Mono- und Stereopuffer an, die jeweils eine Sekunde lang sind und mit einer Frequenz von 44100 Hz reproduziert werden:- Der Monopuffer hat 44100 Samples und 44100 Frames. Der Wert der Eigenschaft "length" beträgt 44100
- Der Stereopuffer enthält 88.200 Samples, aber auch 44.100 Frames. Der Wert der Eigenschaft "length" ist 44100 - die Länge entspricht der Anzahl der Frames
 Wenn die Wiedergabe des Puffers beginnt, hören wir zuerst das Bild ganz links des Samples, dann das nächste Bild rechts usw. Bei Stereo hören wir beide Kanäle gleichzeitig. Sample-Frames sind unabhängig von der Anzahl der Kanäle und bieten die Möglichkeit einer sehr genauen Audioverarbeitung.Hinweis: Um die Zeit in Sekunden aus der Anzahl der Frames zu ermitteln, muss die Anzahl der Frames durch die Abtastrate dividiert werden. Teilen Sie letztere durch die Anzahl der Kanäle, um die Anzahl der Frames aus der Anzahl der Samples zu ermitteln.Beispiel:
Wenn die Wiedergabe des Puffers beginnt, hören wir zuerst das Bild ganz links des Samples, dann das nächste Bild rechts usw. Bei Stereo hören wir beide Kanäle gleichzeitig. Sample-Frames sind unabhängig von der Anzahl der Kanäle und bieten die Möglichkeit einer sehr genauen Audioverarbeitung.Hinweis: Um die Zeit in Sekunden aus der Anzahl der Frames zu ermitteln, muss die Anzahl der Frames durch die Abtastrate dividiert werden. Teilen Sie letztere durch die Anzahl der Kanäle, um die Anzahl der Frames aus der Anzahl der Samples zu ermitteln.Beispiel:let context = new AudioContext()
let buffer = context.createBuffer(2, 22050, 44100)
Hinweis: Bei digitalem Audio sind 44100 Hz oder 44,1 kHz die Standardabtastfrequenz. Aber warum 44,1 kHz?Erstens, weil der Bereich der hörbaren Frequenzen (vom menschlichen Ohr unterscheidbare Frequenzen) zwischen 20 und 20.000 Hz variiert. Nach dem Satz von Kotelnikov sollte die Abtastfrequenz die höchste Frequenz im Signalspektrum mehr als verdoppeln. Daher sollte die Abtastfrequenz größer als 40 kHz sein.Zweitens müssen die Signale mit einem Tiefpassfilter gefiltert werden.Andernfalls kommt es zu einer Überlappung der spektralen „Schwänze“ (Frequenzwechsel, Frequenzmaskierung, Aliasing), und die Form des rekonstruierten Signals wird verzerrt. Idealerweise sollte ein Tiefpassfilter Frequenzen unter 20 kHz (ohne Dämpfung) durchlassen und Frequenzen über 20 kHz fallen lassen. In der Praxis ist ein gewisses Übergangsband (zwischen dem Durchlassband und dem Unterdrückungsband) erforderlich, in dem die Frequenzen teilweise gedämpft sind. Eine einfachere und wirtschaftlichere Möglichkeit hierfür ist die Verwendung eines Änderungsfilters. Bei einer Abtastfrequenz von 44,1 kHz beträgt das Übergangsband 2,05 kHz.Im obigen Beispiel erhalten wir einen Stereopuffer mit zwei Kanälen, der in einem Audiokontext mit einer Frequenz von 44100 Hz (Standard) und einer Länge von 0,5 Sekunden (22050 Bilder / 44100 Hz = 0,5 s) wiedergegeben wird.let context = new AudioContext()
let buffer = context.createBuffer(1, 22050, 22050)
In diesem Fall erhalten wir einen Monopuffer mit einem Kanal, der in einem Audiokontext mit einer Frequenz von 44100 Hz wiedergegeben wird. Er wird auf 44100 Hz überabtastet (und die Frames auf 44100 erhöht) und 1 Sekunde lang (44100 Frames / 44100 Hz = 1 s).Hinweis: Das Audio-Resampling („Resampling“) ist dem Ändern der Größe („Resizing“) von Bildern sehr ähnlich. Angenommen, wir haben ein 16x16-Bild, möchten diesen Bereich jedoch mit einer Größe von 32x32 füllen. Wir ändern die Größe. Das Ergebnis ist von geringerer Qualität (je nach Zoom-Algorithmus kann es verschwommen oder zerrissen sein), aber es funktioniert. Resampled Audio ist dasselbe: Wir sparen Platz, aber in der Praxis ist es unwahrscheinlich, dass eine hohe Klangqualität erzielt wird.Planare und gestreifte Puffer
WAA verwendet ein planares Pufferformat. Der linke und der rechte Kanal interagieren wie folgt:LLLLLLLLLLLLLLLLRRRRRRRRRRRRRRRR ( , 16 )
In diesem Fall arbeitet jeder Kanal unabhängig von den anderen.Eine Alternative ist die Verwendung eines alternativen Formats:LRLRLRLRLRLRLRLRLRLRLRLRLRLRLRLR ( , 16 )
Dieses Format wird häufig für die MP3-Decodierung verwendet.WAA verwendet nur das planare Format, da es für die Tonverarbeitung besser geeignet ist. Das planare Format wird alternierend konvertiert, wenn Daten zur Wiedergabe an die Soundkarte gesendet werden. Beim Decodieren von MP3s wird das Inverse konvertiert.Audiokanäle
Verschiedene Puffer enthalten eine unterschiedliche Anzahl von Kanälen: von einfachem Mono (ein Kanal) und Stereo (linker und rechter Kanal) bis zu komplexeren Sets wie Quad und 5.1 mit einer unterschiedlichen Anzahl von Samples in jedem Kanal, die einen satteren (satteren) Klang liefern. Kanäle werden normalerweise durch Abkürzungen dargestellt:Aufmischen und Abmischen
Wenn die Anzahl der Kanäle am Ein- und Ausgang nicht übereinstimmt, mischen Sie nach oben oder unten. Das Mischen wird durch die AudioNode.channelInterpretation-Eigenschaft gesteuert:Visualisierung
Die Visualisierung basiert auf dem Empfang von Audioausgabedaten, z. B. Daten zur Amplitude oder Frequenz, und deren anschließender Verarbeitung mithilfe einer beliebigen Grafiktechnologie. WAA verfügt über einen AnalyzerNode, der das durchgelassene Signal nicht verzerrt. Gleichzeitig können Daten aus Audio extrahiert und weiter übertragen werden, z. B. an & ltcanvas>.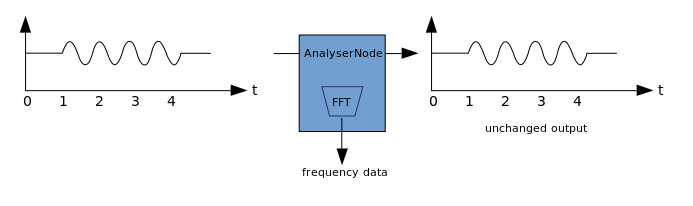 Die folgenden Methoden können zum Extrahieren von Daten verwendet werden:
Die folgenden Methoden können zum Extrahieren von Daten verwendet werden:- AnalyzerNode.getFloatByteFrequencyData () - kopiert die aktuellen Frequenzdaten in das Float32Array
- AnalyzerNode.getByteFrequencyData () - kopiert die aktuellen Frequenzdaten in ein Uint8Array (vorzeichenloses Byte-Array)
- AnalyserNode.getFloatTimeDomainData() — Float32Array
- AnalyserNode.getByteTimeDomainData() — Uint8Array
Mit der Audio-Räumlichkeit (verarbeitet von PannerNode und AudioListener) können Sie die Position und Richtung des Signals an einem bestimmten Punkt im Raum sowie die Position des Hörers simulieren.Die Position des Panners wird mit rechtshändigen kartesischen Koordinaten beschrieben. Für die Bewegung wird der Geschwindigkeitsvektor verwendet, der zur Erzeugung des Doppler-Effekts erforderlich ist . Für die Richtung wird der Richtungskegel verwendet. Dieser Kegel kann bei multidirektionalen Schallquellen sehr groß sein. Die Position des Hörers wird wie folgt beschrieben: Bewegung - unter Verwendung des Geschwindigkeitsvektors, der Richtung, in der sich der Kopf des Hörers befindet - unter Verwendung von zwei Richtungsvektoren, vorne und oben. Das Einrasten erfolgt an der Oberseite des Kopfes und der Nase des Hörers im rechten Winkel.
Die Position des Hörers wird wie folgt beschrieben: Bewegung - unter Verwendung des Geschwindigkeitsvektors, der Richtung, in der sich der Kopf des Hörers befindet - unter Verwendung von zwei Richtungsvektoren, vorne und oben. Das Einrasten erfolgt an der Oberseite des Kopfes und der Nase des Hörers im rechten Winkel.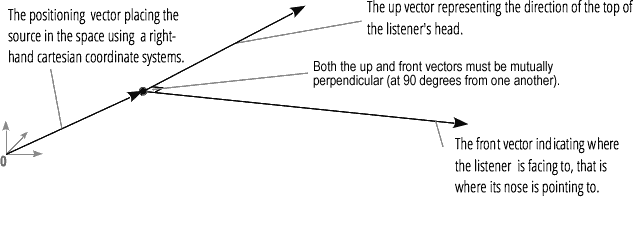
Kreuzung und Verzweigung
Eine Verbindung beschreibt einen Prozess, bei dem ein ChannelMergerNode mehrere Eingangs-Monoquellen empfängt und diese zu einem einzigen mehrkanaligen Ausgangssignal kombiniert.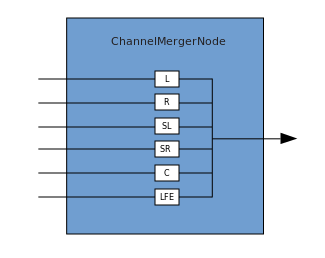 Die Verzweigung ist der umgekehrte Prozess (implementiert über ChannelSplitterNode).
Die Verzweigung ist der umgekehrte Prozess (implementiert über ChannelSplitterNode).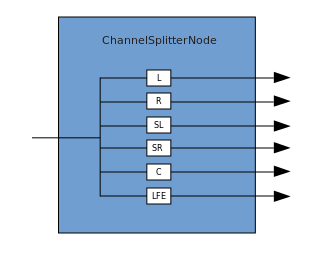 Ein Beispiel für die Arbeit mit WAA finden Sie hier . Der Quellcode für das Beispiel ist hier . Hier ist ein Artikel darüber, wie alles funktioniert.Vielen Dank für Ihre Aufmerksamkeit.
Ein Beispiel für die Arbeit mit WAA finden Sie hier . Der Quellcode für das Beispiel ist hier . Hier ist ein Artikel darüber, wie alles funktioniert.Vielen Dank für Ihre Aufmerksamkeit.