 Das Bild , das Sie sehen , ist von der DeepMind Website genommen und zeigt 57 Spiele , in denen ihre neueste Entwicklung Agent57 ( Überprüfung des Artikels auf Habré ) Erfolg erzielt hat. Die Nummer 57 selbst wurde nicht von der Decke genommen - genauso viele Spiele wurden 2012 ausgewählt, um eine Art Benchmark unter den Entwicklern von KI für Atari-Spiele zu werden, wonach verschiedene Forscher ihre Erfolge an diesem bestimmten Datensatz messen.In diesem Beitrag werde ich versuchen, diese Erfolge aus verschiedenen Blickwinkeln zu betrachten, um ihren Wert für angewandte Aufgaben zu bewerten und zu begründen, warum ich nicht glaube, dass dies die Zukunft ist. Nun ja, es wird viele Bilder unter dem Schnitt geben, warnte ich.In dem obigen Link schreiben Entwickler die richtigen Dinge und sagen das
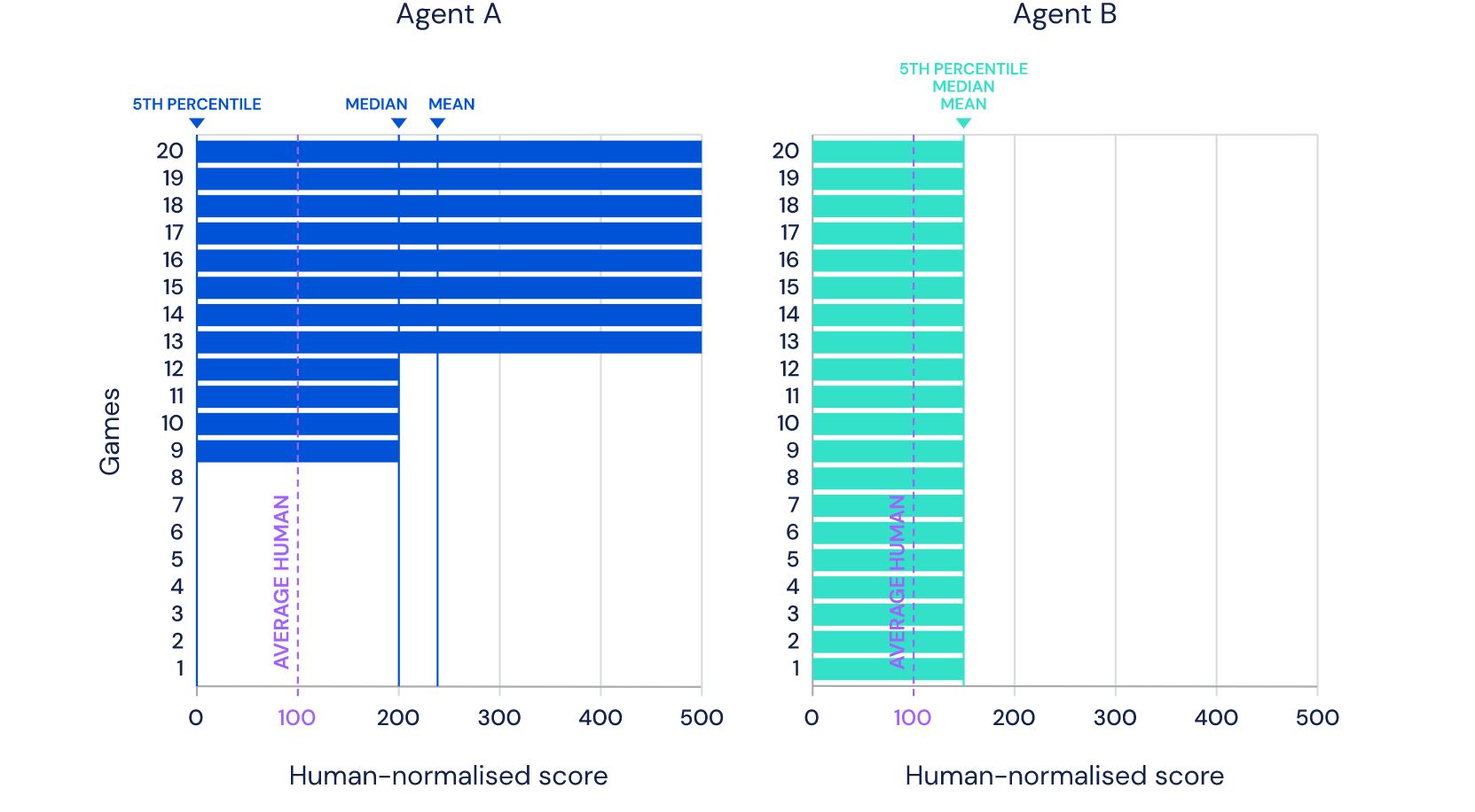
Das Bild , das Sie sehen , ist von der DeepMind Website genommen und zeigt 57 Spiele , in denen ihre neueste Entwicklung Agent57 ( Überprüfung des Artikels auf Habré ) Erfolg erzielt hat. Die Nummer 57 selbst wurde nicht von der Decke genommen - genauso viele Spiele wurden 2012 ausgewählt, um eine Art Benchmark unter den Entwicklern von KI für Atari-Spiele zu werden, wonach verschiedene Forscher ihre Erfolge an diesem bestimmten Datensatz messen.In diesem Beitrag werde ich versuchen, diese Erfolge aus verschiedenen Blickwinkeln zu betrachten, um ihren Wert für angewandte Aufgaben zu bewerten und zu begründen, warum ich nicht glaube, dass dies die Zukunft ist. Nun ja, es wird viele Bilder unter dem Schnitt geben, warnte ich.In dem obigen Link schreiben Entwickler die richtigen Dinge und sagen dasSo although average scores have increased, until now, the number of above human games has not. As an illustrative example, consider a benchmark consisting of twenty tasks. Suppose agent A obtains a score of 500% on eight tasks, 200% on four tasks, and 0% on eight tasks (mean = 240%, median = 200%), while agent B obtains a score of 150% on all tasks (mean = median = 150%). On average, agent A performs better than agent B. However, agent B possesses a more general ability: it obtains human-level performance on more tasks than agent A.
 Was an den Fingern bedeutet, dass, bevor alle in der "durchschnittlichen" Wertung gemessen wurden, die für einen Computer schwierigen Fälle weggewinkt wurden, aber jetzt haben sie nur sie aufgegriffen. Und so erreichten sie eine echte Überlegenheit gegenüber dem Menschen und keine Superergebnisse in computerfreundlichen Fällen.Aber schauen wir uns das Problem globaler an, um zu verstehen, ob dies der Fall ist. Was ist die Interaktion der DeepMind AI mit einem Videospiel?Ein Sternchen bezeichnet im Folgenden Entitäten, die durch einen Algorithmus erhalten wurden, der nicht mit Hilfe der KI, sondern mit Hilfe der Expertenmeinung erstellt wurde.Bevor wir die Schaltung zerlegen, schauen wir uns einen alternativen Ansatz an:
Was an den Fingern bedeutet, dass, bevor alle in der "durchschnittlichen" Wertung gemessen wurden, die für einen Computer schwierigen Fälle weggewinkt wurden, aber jetzt haben sie nur sie aufgegriffen. Und so erreichten sie eine echte Überlegenheit gegenüber dem Menschen und keine Superergebnisse in computerfreundlichen Fällen.Aber schauen wir uns das Problem globaler an, um zu verstehen, ob dies der Fall ist. Was ist die Interaktion der DeepMind AI mit einem Videospiel?Ein Sternchen bezeichnet im Folgenden Entitäten, die durch einen Algorithmus erhalten wurden, der nicht mit Hilfe der KI, sondern mit Hilfe der Expertenmeinung erstellt wurde.Bevor wir die Schaltung zerlegen, schauen wir uns einen alternativen Ansatz an:Video Zusammenfassung- + ,

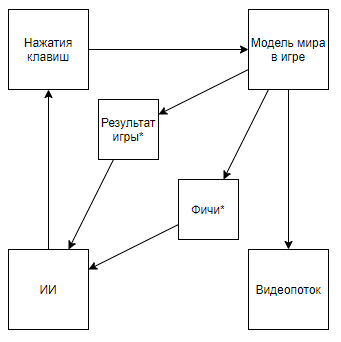 Das Schema wird so. Und wenn Sie auf den Kanal des Autors klettern, finden Sie dessen Anwendung für Retro-Spiele. Wenn wir das Schema in dieses ändern, kommen wir zu dem Schluss, dass die Geschwindigkeit und Effektivität des Trainings um Größenordnungen zunimmt, aber der wissenschaftliche und technische Wert der Erfolge einer solchen Reise nahe bei 0 liegt (und ja, ich berücksichtige den Popularisierungswert nicht).Wir können davon ausgehen, dass der springende Punkt darin besteht, dass das Video aus der Pipeline geworfen wird. Beachten Sie jedoch das folgende Schema (ich bin sicher, dass jemand etwas Ähnliches implementiert hat, aber es gibt keinen Link):Dies wird implementiert, wenn ein Experte, der die erforderlichen Funktionen kennt, einen Videostream-Parser schreibt, der Funktionen mithilfe von Schlüsselpixeln berechnet.Oder sogar ein solches Schema:Zunächst wird AI1 darauf trainiert, von einem Experten ausgewählte Funktionen aus dem Video zu extrahieren.Anschließend wird AI2 das Spielen anhand von Funktionen beigebracht, die mit AI1 aus dem Videostream extrahiert wurden. Also haben wir ein Schema, das:
Das Schema wird so. Und wenn Sie auf den Kanal des Autors klettern, finden Sie dessen Anwendung für Retro-Spiele. Wenn wir das Schema in dieses ändern, kommen wir zu dem Schluss, dass die Geschwindigkeit und Effektivität des Trainings um Größenordnungen zunimmt, aber der wissenschaftliche und technische Wert der Erfolge einer solchen Reise nahe bei 0 liegt (und ja, ich berücksichtige den Popularisierungswert nicht).Wir können davon ausgehen, dass der springende Punkt darin besteht, dass das Video aus der Pipeline geworfen wird. Beachten Sie jedoch das folgende Schema (ich bin sicher, dass jemand etwas Ähnliches implementiert hat, aber es gibt keinen Link):Dies wird implementiert, wenn ein Experte, der die erforderlichen Funktionen kennt, einen Videostream-Parser schreibt, der Funktionen mithilfe von Schlüsselpixeln berechnet.Oder sogar ein solches Schema:Zunächst wird AI1 darauf trainiert, von einem Experten ausgewählte Funktionen aus dem Video zu extrahieren.Anschließend wird AI2 das Spielen anhand von Funktionen beigebracht, die mit AI1 aus dem Videostream extrahiert wurden. Also haben wir ein Schema, das:- Verwendet einen Videostream und hat keinen direkten Zugriff auf das Modell der Welt.
- Verlässt sich nicht auf Video-Stream-Parser, die von einem Experten geschrieben wurden
- Es wird manchmal einfacher und effizienter trainiert als die Entwicklung von DeepMind
Aber ... wir kommen zur gleichen Sache. Eine solche Implementierung wird wiederum im Zusammenhang mit der Anwendung auf Retro-Spiele weder wissenschaftlichen noch technischen Wert haben, da AI1 eine lange gelöste und sehr primitive Aufgabe für moderne Bildverarbeitungsalgorithmen ist und AI2 auch sehr schnell und einfach erstellt wird bestätigt den Autor des obigen Videos .Welchen Wert haben DeepMind-Algorithmen für Atari-Spiele? Ich werde versuchen zusammenzufassen: Der Wert ist dasDeepMind-Algorithmen sind in der Lage, die optimale Verhaltensstrategie für Spiele mit einem primitiven Modell der MM-Welt unter Bedingungen zu finden, unter denen der Zustand des Weltmodells S (MM, t) mit signifikanten Verzerrungen durch eine bestimmte Verzerrungsfunktion F (S (MM, t)) dargestellt wird. Nur die Qualität der getroffenen Entscheidungen kann bewertet werden Eine Funktion, die eine Folge von F (S (MM, t)) - Werten und Algorithmusreaktionen empfängt und diese Folge von unbekannter Länge ist (das Spiel kann in einer anderen Anzahl von Schritten enden), aber Sie können das Experiment unendlich oft wiederholen .Probleme antizipieren, . S(MM, t) , , . F(S(MM, t)) , .
Versuchen wir nun, die Anwendbarkeit eines solchen Werts für die Lösung realer Probleme zu bewerten, die irgendwie mit den Tools korrelieren, nämlich einen realen Zustand mit erheblichen Verzerrungen darstellen, implizieren, dass die Umgebung auf die Aktionen des Agenten reagiert, erst nach einer langen Folge von Entscheidungen eine Bewertung abgibt und Sie ermöglichen es jedoch, das Experiment viele Male durchzuführen.Auf den ersten Blick scheint eine interessante Anwendung ein Spiel an der Börse zu sein. Selbst die Hinweise von Google, die es als einzigen Hinweis in der Praxis verraten, deuten darauf hin, dass das Thema aktuell ist.Ich werde sofort auf einen wichtigen Punkt hinweisen - fast alle Ansätze zur Marktanalyse (ohne Ansätze zur Analyse realer Objekte wie Parkplätze vor Supermärkten, Nachrichten, Erwähnungen von Aktien auf Twitter) können in zwei Typen unterteilt werden. Der erste Typ sind Ansätze, die den Markt als Zeitreihe darstellen. Zweitens als Strom von Anwendungen.Irgendwie sehen die Befürworter von Ansätzen des ersten Typs den Markt Der grundlegende Unterschied liegt jedoch nicht in den verwendeten Daten, sondern in der Tatsache, dass diejenigen, die den Markt als Zeitreihe analysieren, in der Regel ihren Einfluss auf den Markt vernachlässigen und davon ausgehen, dass ihre Transaktionen unter bestimmten Bedingungen im Tagesintervall die weitere Dynamik des Marktes nicht beeinflussen. Während die Befürworter des zweiten Ansatzes beide vernachlässigen können, weil sie glauben, dass ihr Volumen im Verhältnis zur Marktliquidität unbedeutend ist, und den Markt als Feedback-System betrachten, glauben sie, dass ihre Handlungen das Verhalten anderer Akteure beeinflussen (zum Beispiel Forschung und Ansätze im Zusammenhang mit der optimalen Ausführung von Großaufträgen, Market-Making, Hochfrequenzhandel).Nach Durchsicht der Suchergebnisse ist klar, dass alle Artikel und Beiträge, die dem Handel mit Verstärkungstraining gewidmet sind (das Thema, das den Erfolgen von DeepMind am nächsten kommt), dem ersten Ansatz gewidmet sind. Es stellt sich jedoch eine vernünftige Frage nach der Verhältnismäßigkeit der Herangehensweise an das Problem.Zeichnen wir zunächst ein Diagramm ähnlich den Atari-Spielen.Objektive Realität, . , , , , — . , , . , , , , , . , .
Es scheint, dass alles schön fällt. Und ich vermute, dass diese Ähnlichkeit auch den Hype erwärmt. Aber was ist, wenn wir das Schema ein wenig klarstellen: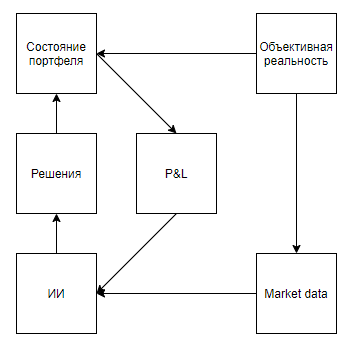
Vorwegnahme der Frage nach selbst erzeugenden Proben, , , . , , . , , . , , , , , .
Der zweite Ansatz (mit einem Strom von Anwendungen) sieht vielversprechender aus. Das sogenannte GlasEs ist oft mit Anwendungen von Robotern gefüllt, die nach Bruchteilen eines Preises des Preises suchen, an einem Platz in der Warteschlange konkurrieren und häufig nur Anwendungen erstellen, um die Nachfrage oder das Angebot erscheinen zu lassen und andere Bots zu nachteiligen Aktionen zu provozieren. Wenn Sie sich etwas einfallen lassen, scheint es so, als würden Sie einen Austauschemulator erstellen und HFT-Bots darin platzieren, die sich in Milliarden von Entscheidungen selbst lernen, mit den Klonen ihrer selbst spielen und dabei eine ideale Strategie entwickeln, die alle optimalen Gegenstrategien berücksichtigt ... Es ist schade, dass, wenn so etwas passiert, ungefähr 5 Menschen auf der ganzen Welt davon erfahren werden - die Geschäftsprinzipien von Hochfrequenzhändlern implizieren absolute Geheimhaltung und die Weigerung, selbst erfolglose Ergebnisse zu veröffentlichen, um Feinden die Möglichkeit zu geben, auf denselben Rechen zu treten.Ich denke, es lohnt sich insbesondere nicht, sich auf die Unmöglichkeit zu konzentrieren, solche Ansätze in Marketing, Personalwesen, Vertrieb, Management und anderen Bereichen anzuwenden, in denen das Objekt eine Person ist, da es für die richtige Anwendung erforderlich ist, AI zu ermöglichen, Millionen oder sogar Milliarden von Experimenten durchzuführen. Und selbst wenn viele Unternehmen eine Million Interaktionen mit einem Objekt haben, bei dem die KI eine Entscheidung treffen kann (Auswahl eines Banners, das einem potenziellen Kunden anhand seines Profils angezeigt wird, die Entscheidung, einen Mitarbeiter zu entlassen), wird niemand eine Million Experimente mit demselben Objekt erhalten Objekt, das genau das ist, was für eine qualitativ hochwertige Anwendung erforderlich ist. Es lohnt sich jedoch, sich auf Betrug und Cybersicherheit zu konzentrieren.Ich weiß es zum Glück oder leider nicht, aber in der modernen Welt basieren sehr viele Wirtschaftsbeziehungen darauf, einen kleinen Wert ohne Verpflichtungen bereitzustellen, um in Zukunft einen hohen Wert zu erwarten, was zu zahlreichen Werbegeschenkquellen und Betrugspotenzialen führt.Beispiele:- Die erste freie Fahrt mit Taxiaggregatoren
- Zahlungen von 70 US-Dollar für CPA beim Spielen, für einen Spieler, der 5 US-Dollar einbrachte
- Testen Sie 300 US-Dollar von Cloud-Anbietern und Testzeiträumen
Darüber hinaus wird das Betrugspotenzial des modernen Wirtschaftssystems durch einen geringen Schutz für Kreditkartentransaktionen unterstützt, da Händler häufig absichtlich dieselbe 3D-Sicherheit ablehnen, um die Benutzererfahrung zu vereinfachen. Für Käufer von gestohlenen Karten für einen kleinen Prozentsatz ihres Guthabens kann diese Liste daher nahezu unbegrenzt ergänzt werden.Das Hauptproblem im Kampf gegen solche Fälle liegt in der Unfähigkeit, einen Datensatz mit einem ausreichenden Volumen zu erfassen -% Betrugsvorgänge sind je nach Geschäft um 1 bis 6 Größenordnungen niedriger als der Prozentsatz guter Vorgänge. Es gibt auch ein Problem in der Flexibilität von Betrügern, die statische Algorithmen leicht umgehen und sich an Betrugsbekämpfungssysteme anpassen, die in früheren Erfahrungen geschult wurden.Und hier scheint es zu sein. Mit Algorithmen wie Agent57, die in der Sandbox gestartet wurden, können Sie den idealen Betrüger erstellen, seine Fähigkeiten ständig aktualisieren und gleichzeitig das umgekehrte Problem lösen - halten Sie den Algorithmus zur Identifizierung auf dem neuesten Stand. Aber es gibt eine Einschränkung. Gegen das in Atari-Spielen eingebettete Modell der Welt zu gewinnen, ist keineswegs dasselbe wie gegen ein Betrugsbekämpfungssystem zu gewinnen, das bereits auf der Grundlage des Verhaltens von Millionen von Spielern trainiert wurde, und viele betrügerische Aktionen stehen in keinem Verhältnis zu den vielen Aktionen eines Spielers in einem Retro-Spiel. Selbst eine so einfache Aktion wie die Eingabe eines Logins auf dem Registrierungsformular bietet beispielsweise bereits Milliarden von Optionen. Beginnend mit dem Benutzeragenten, der auf den Server übertragen werden soll, und endend mit der Anzahl der Millisekunden, die zwischen der Eingabe des zweiten und dritten Anmeldezeichens gewartet werden muss ...Im Allgemeinen sehe ich alles irgendwie. Ziemlich trostlos. Und ich hoffe wirklich, dass ich falsch liege und irgendwo habe ich etwas im Modell nicht berücksichtigt. Ich wäre dankbar, wenn ich in den Kommentaren Gegenbeispiele sehen würde.