Hallo liebe Khabrovites, in diesem kleinen Beispiel möchte ich zeigen, wie Sie eine Seite analysieren können, deren Daten mithilfe von Javascript-Widgets geladen werden. Selbst wenn die Seite in diesem Beispiel einfach zu speichern ist, können Sie aufgrund dieser Widgets nicht alle erforderlichen Fotos daraus analysieren. In diesem Fall verwende ich cian.ru als Beispiel , das eine eigene API hat , die ich nicht verwenden werde, sondern Selenium. Ich arbeite nicht bei cian.ru, ich benutze diese Seite nur als Beispiel. Der Code im Parser ist einfach und für Anfänger konzipiert.
Eine kurze Einführung - als ich mir in meiner Freizeit Beispiele für Reparaturen in cian.ru ansah, dachte ich, es wäre schön, die Fotos zu speichern, die ich mochte, aber das manuelle Speichern würde lange dauern, außerdem ist dies nicht unsere Methode, also habe ich beschlossen, dies zu schreiben Parser.
Der Parser ist in Python3 aus der Distribution von Anaconda , Selenium und Chromedriver Binary geschrieben, die ich separat von diesen Links installiert habe. (Und natürlich muss der Google Chrome-Browser auf dem System installiert sein. )
Unten ist der vollständige Parser-Code, dann werde ich die Hauptpunkte separat analysieren.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
import chromedriver_binary
import urllib
import time
print('start...')
site = "https://www.cian.ru/sale/flat/222059642/"
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
driver.get(site)
i = 0
while True:
try:
url = driver.find_element_by_xpath("//div[contains(@class, 'fotorama__active')]/img").get_attribute('src')
except NoSuchElementException:
break
i += 1
print(i, url)
driver.find_element_by_xpath("//div[@class='fotorama__arr fotorama__arr--next']").click()
name = url.split('/')[-1]
urllib.request.urlretrieve(url, name)
time.sleep(2)
print('done.')
https://www.cian.ru/sale/flat/222059642/ . driver get. , Headless Chrome, .. webdriver.Chrome() --headless, , , chrome_options , .
site = "https://www.cian.ru/sale/flat/222059642/"
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
driver.get(site)
, , , .. "next".
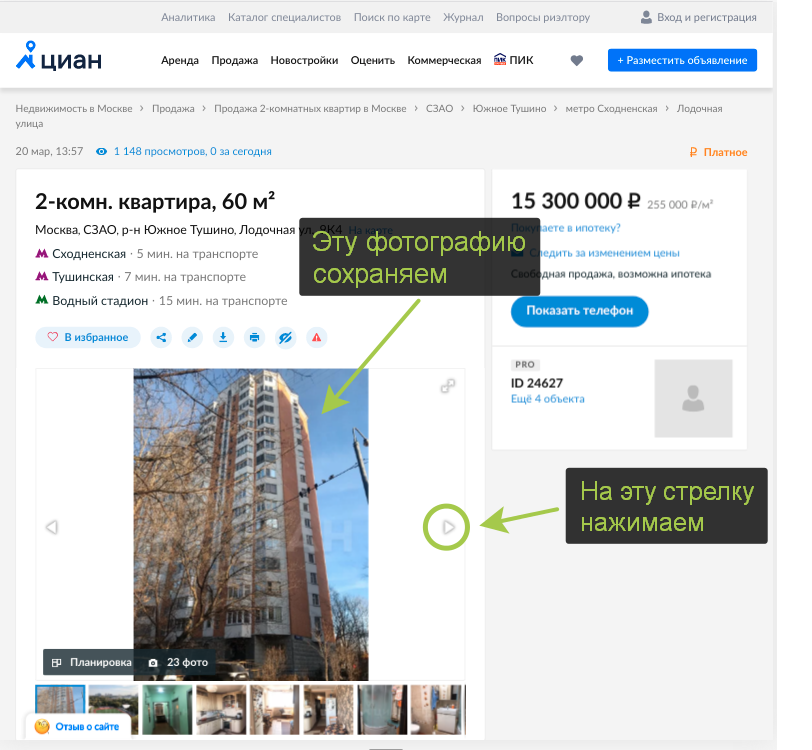
url , try/except NoSuchElementException, , Selenium .
try:
url = driver.find_element_by_xpath("//div[contains(@class, 'fotorama__active')]/img").get_attribute('src')
except NoSuchElementException:
break
.
driver.find_element_by_xpath("//div[@class='fotorama__arr fotorama__arr--next']").click()
urllib.
name = url.split('/')[-1]
urllib.request.urlretrieve(url, name)
, . ( Selenium)
time.sleep(2)
Selenium, , , - .
.