Hallo habrozhiteli! Während unsere Nachrichten in einer Druckerei gedruckt werden und sich das Büro an einem abgelegenen Ort befindet, haben wir beschlossen, einen Auszug aus Paul und Harvey Daytels Buch "Python: Künstliche Intelligenz, Big Data und Cloud Computing" zu veröffentlichen.Fallstudie: Maschinelles Lernen ohne Lehrer, Teil 2 - K Average Clustering
In diesem Abschnitt wird der vielleicht einfachste Algorithmus für maschinelles Lernen ohne Lehrer vorgestellt - Clustering nach der k-Average-Methode. Der Algorithmus analysiert unbeschriftete Proben und versucht, sie zu Clustern zu kombinieren. Lassen Sie uns erklären, dass k in der „k means-Methode“ die Anzahl der Cluster darstellt, in die Daten aufgeteilt werden sollen.Der Algorithmus verteilt die Abtastwerte unter Verwendung von Abstandsmetriken, die denen des Clustering-Algorithmus von k nächsten Nachbarn ähnlich sind, auf eine vorbestimmte Anzahl von Clustern. Jeder Cluster ist um einen Schwerpunkt gruppiert - den Mittelpunkt des Clusters. Zunächst wählt der Algorithmus k zufällige Zentroide aus den Datensatzabtastwerten aus, wonach die verbleibenden Abtastwerte auf Cluster mit dem nächstgelegenen Schwerpunkt verteilt werden. Als nächstes wird eine iterative Neuberechnung der Zentroide durchgeführt, und die Proben werden auf die Cluster verteilt, bis für alle Cluster der Abstand vom gegebenen Schwerpunkt zu den in seinem Cluster enthaltenen Proben minimiert ist. Als Ergebnis des Algorithmus wird ein eindimensionales Array von Beschriftungen erstellt, die den Cluster bezeichnen, zu dem jede Probe gehört, sowie ein zweidimensionales Array von Zentroiden, die das Zentrum jedes Clusters darstellen.Iris-Datensatz
Wir werden mit dem beliebten Iris-Datensatz arbeiten, der in scikit-learn enthalten ist. Dieser Satz wird häufig während der Klassifizierung und Clusterbildung analysiert. Obwohl das Dataset beschriftet ist, werden wir diese Beschriftungen nicht verwenden, um das Clustering zu demonstrieren. Etiketten werden dann verwendet, um zu bestimmen, wie gut der k-Durchschnittsalgorithmus die Proben gruppiert.Der Iris-Datensatz ist ein Spielzeug-Datensatz, da er nur aus 150 Proben und vier Attributen besteht. Der Datensatz beschreibt 50 Proben von drei Arten von Irisblüten - Iris setosa, Iris versicolor und Iris virginica (siehe Fotos unten). Eigenschaften der Proben: Länge des äußeren Blütenhüllens (Kelchblattlänge), Breite des äußeren Blütenhüllens (Kelchblattbreite), Länge des inneren Blütenhüllens (Blütenblattlänge) und Breite des inneren Blütenhüllens (Blütenblattbreite), gemessen in Zentimetern.14.7.1. Laden Sie den Iris-Datensatz herunter
Starten Sie IPython mit dem Befehl ipython --matplotlib und verwenden Sie dann die Funktion load_iris des Moduls sklearn.datasets, um das Bunch-Objekt mit dem Datensatz abzurufen:In [1]: from sklearn.datasets import load_iris
In [2]: iris = load_iris()
Das DESCR-Attribut des Bunch-Objekts gibt an, dass der Datensatz aus 150 Beispielen für die Anzahl der Instanzen besteht, von denen jedes vier Anzahl von Attributen aufweist. Es fehlen keine Werte im Datensatz. Die Proben werden durch ganze Zahlen 0, 1 und 2 klassifiziert, die Iris setosa, Iris versicolor bzw. Iris virginica darstellen. Wir ignorieren die Bezeichnungen und vertrauen die Bestimmung der Stichprobenklassen dem Clustering-Algorithmus mit der k-means-Methode an. Wichtige DESCR-Informationen in Fettdruck:In [3]: print(iris.DESCR)
.. _iris_dataset:
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
:Summary Statistics:
============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ====================
:Missing Attribute Values: None
:Class Distribution: 33.3% for each of 3 classes.
:Creator: R.A. Fisher
:Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov)
:Date: July, 1988
...
Überprüfen der Anzahl der Proben, Merkmale und Zielwerte
Die Anzahl der Muster und Attribute finden Sie im Formattribut des Datenarrays, und die Anzahl der Zielwerte finden Sie im Formattribut des Zielarrays:In [4]: iris.data.shape
Out[4]: (150, 4)
In [5]: iris.target.shape
Out[5]: (150,)
Das Array target_names enthält die Namen der numerischen Beschriftungen des Arrays. Der Ausdruck target - dtype = '<U10' bedeutet, dass seine Elemente Zeichenfolgen mit einer maximalen Länge von 10 Zeichen sind:In [6]: iris.target_names
Out[6]: array(['setosa', 'versicolor', 'virginica'], dtype='<U10')
Das Array feature_names enthält eine Liste von Zeichenfolgennamen für jede Spalte im Datenarray:In [7]: iris.feature_names
Out[7]:
['sepal length (cm)',
'sepal width (cm)',
'petal length (cm)',
'petal width (cm)']
14.7.2. Iris-Datensatzforschung: Deskriptive Statistik in Pandas
Wir verwenden die DataFrame-Auflistung, um den Iris-Datensatz zu untersuchen. Wie beim California Housing-Dataset legen wir die Pandas-Parameter fest, um die Spaltenausgabe zu formatieren:In [8]: import pandas as pd
In [9]: pd.set_option('max_columns', 5)
In [10]: pd.set_option('display.width', None)
Erstellen Sie eine DataFrame-Auflistung mit dem Inhalt des Datenarrays, wobei Sie den Inhalt des Arrays feature_names als Spaltennamen verwenden:In [11]: iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
Fügen Sie dann für jedes Beispiel eine Spalte mit dem Namen der Ansicht hinzu. Die Listentransformation im folgenden Snippet verwendet jeden Wert im Zielarray, um nach dem entsprechenden Namen im Array target_names zu suchen:In [12]: iris_df['species'] = [iris.target_names[i] for i in iris.target]
Wir werden Pandas verwenden, um mehrere Proben zu identifizieren. Wenn pandas rechts neben dem Spaltennamen \ ausgibt, bedeutet dies wie zuvor, dass die unten angezeigten Spalten in der Ausgabe verbleiben:In [13]: iris_df.head()
Out[13]:
sepal length (cm) sepal width (cm) petal length (cm) \
0 5.1 3.5 1.4
1 4.9 3.0 1.4
2 4.7 3.2 1.3
3 4.6 3.1 1.5
4 5.0 3.6 1.4
petal width (cm) species
0 0.2 setosa
1 0.2 setosa
2 0.2 setosa
3 0.2 setosa
4 0.2 setosa
Wir berechnen einige Indikatoren für deskriptive Statistiken für numerische Spalten:In [14]: pd.set_option('precision', 2)
In [15]: iris_df.describe()
Out[15]:
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
count 150.00 150.00 150.00 150.00
mean 5.84 3.06 3.76 1.20
std 0.83 0.44 1.77 0.76
min 4.30 2.00 1.00 0.10
25% 5.10 2.80 1.60 0.30
50% 5.80 3.00 4.35 1.30
75% 6.40 3.30 5.10 1.80
max 7.90 4.40 6.90 2.50
Durch Aufrufen der Beschreibung in der Spalte "Spezies" wird bestätigt, dass sie drei eindeutige Werte enthält. Wir wissen im Voraus, dass die Daten aus drei Klassen bestehen, zu denen die Stichproben gehören, obwohl dies beim maschinellen Lernen ohne Lehrer nicht immer der Fall ist.In [16]: iris_df['species'].describe()
Out[16]:
count 150
unique 3
top setosa
freq 50
Name: species, dtype: object
14.7.3. Pairplot-Datensatzvisualisierung
Wir werden die Eigenschaften in diesem Datensatz visualisieren. Eine Möglichkeit, Informationen zu Ihren Daten zu extrahieren, besteht darin, zu sehen, wie die Attribute miteinander in Beziehung stehen. Ein Datensatz hat vier Attribute. Wir werden nicht in der Lage sein, ein Korrespondenzdiagramm eines Attributs mit drei anderen in einem Diagramm zu erstellen. Trotzdem ist es möglich, ein Diagramm zu erstellen, in dem die Entsprechung zwischen den beiden Merkmalen dargestellt wird. Fragment [20] verwendet die Pairplot-Funktion der Seaborn-Bibliothek, um eine Tabelle mit Diagrammen zu erstellen, in der jedes Feature einem der anderen Features zugeordnet ist:In [17]: import seaborn as sns
In [18]: sns.set(font_scale=1.1)
In [19]: sns.set_style('whitegrid')
In [20]: grid = sns.pairplot(data=iris_df, vars=iris_df.columns[0:4],
...: hue='species')
...:
Hauptargumente:- eine DataFrame-Sammlung mit einem Datensatz, der in einem Diagramm dargestellt ist;
- vars - eine Sequenz mit den Namen der Variablen, die im Diagramm dargestellt sind. Für eine DataFrame-Auflistung enthält sie Spaltennamen. In diesem Fall werden die ersten vier Spalten des DataFrame verwendet, die die Länge (Breite) der äußeren Blütenhülle bzw. die Länge (Breite) der inneren Blütenhülle darstellen.
- Der Farbton ist eine Spalte der DataFrame-Auflistung, mit der die Farben der im Diagramm dargestellten Daten bestimmt werden. In diesem Fall sind die Daten je nach Art der Iris farbig.
Der vorherige Pairplot-Aufruf erstellt die folgende 4 × 4-Diagrammtabelle: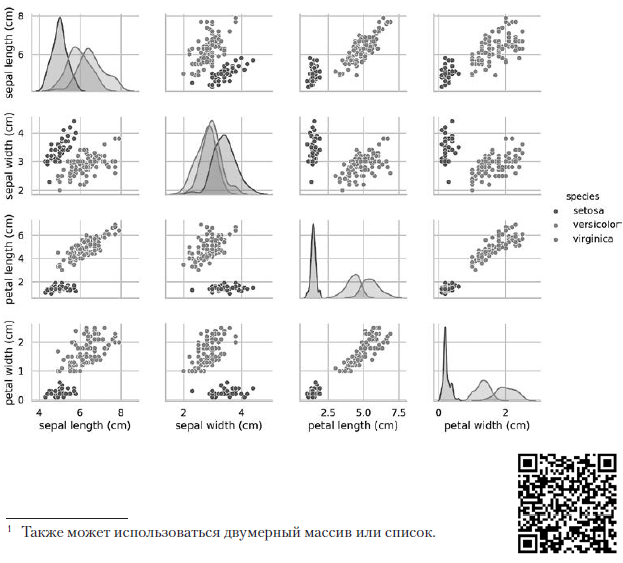 Die Diagramme in der Diagonale, die von links oben nach rechts unten führt, zeigen die Verteilung des in dieser Spalte angezeigten Attributs mit einem Wertebereich (von links nach rechts) und die Anzahl der Stichproben mit diesen Werten (von oben nach unten). . Nehmen Sie die Verteilung der Länge der äußeren Blütenhülle:
Die Diagramme in der Diagonale, die von links oben nach rechts unten führt, zeigen die Verteilung des in dieser Spalte angezeigten Attributs mit einem Wertebereich (von links nach rechts) und die Anzahl der Stichproben mit diesen Werten (von oben nach unten). . Nehmen Sie die Verteilung der Länge der äußeren Blütenhülle: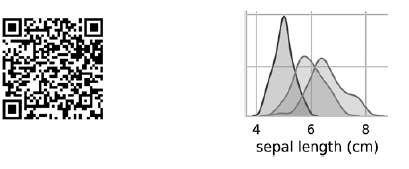 Der am höchsten schattierte Bereich zeigt an, dass der Bereich der Länge des äußeren Blütenhüllens (entlang der x-Achse) für die Art Iris setosa ungefähr 4–6 cm beträgt, und für die meisten Iris setosa-Proben liegen die Werte in der Mitte dieses Bereichs (ungefähr 5 cm). Der ganz rechts schattierte Bereich zeigt an, dass der Bereich der Länge des äußeren Blütenhüllens (entlang der x-Achse) für die Art Iris virginica ungefähr 4–8,5 cm beträgt und für die meisten Iris virginica-Proben die Werte zwischen 6 und 7 cm liegen.In anderen Diagrammen zeigt die Spalte die Datenstreudiagramme anderer Merkmale relativ zum Merkmal entlang der x-Achse. In der ersten Spalte zeigt in den ersten drei Diagrammen die y-Achse die Breite der äußeren Blütenhülle, die Länge der inneren Blütenhülle und die Breite der inneren Blütenhülle, und die x-Achse zeigt die Länge der äußeren Blütenhülle.Wenn dieser Code ausgeführt wird, wird auf dem Bildschirm ein Farbbild angezeigt, das die Beziehung zwischen verschiedenen Arten von Iris auf der Ebene einzelner Zeichen zeigt. Interessanterweise sind in allen Diagrammen die blauen Punkte von Iris setosa deutlich von den orangefarbenen und grünen Punkten anderer Arten getrennt. Dies deutet darauf hin, dass Iris Setosa tatsächlich eine separate Klasse ist. Sie können auch feststellen, dass die beiden anderen Arten manchmal verwechselt werden können, was durch überlappende orangefarbene und grüne Punkte angezeigt wird. Zum Beispiel zeigt das Diagramm der Breite und Länge des äußeren Blütenhüllens, dass sich die Punkte von Iris versicolor und Iris virginica vermischen. Dies deutet darauf hin, dass es schwierig sein wird, zwischen diesen beiden Arten zu unterscheiden, wenn nur Messungen des äußeren Blütenhüllens verfügbar sind.
Der am höchsten schattierte Bereich zeigt an, dass der Bereich der Länge des äußeren Blütenhüllens (entlang der x-Achse) für die Art Iris setosa ungefähr 4–6 cm beträgt, und für die meisten Iris setosa-Proben liegen die Werte in der Mitte dieses Bereichs (ungefähr 5 cm). Der ganz rechts schattierte Bereich zeigt an, dass der Bereich der Länge des äußeren Blütenhüllens (entlang der x-Achse) für die Art Iris virginica ungefähr 4–8,5 cm beträgt und für die meisten Iris virginica-Proben die Werte zwischen 6 und 7 cm liegen.In anderen Diagrammen zeigt die Spalte die Datenstreudiagramme anderer Merkmale relativ zum Merkmal entlang der x-Achse. In der ersten Spalte zeigt in den ersten drei Diagrammen die y-Achse die Breite der äußeren Blütenhülle, die Länge der inneren Blütenhülle und die Breite der inneren Blütenhülle, und die x-Achse zeigt die Länge der äußeren Blütenhülle.Wenn dieser Code ausgeführt wird, wird auf dem Bildschirm ein Farbbild angezeigt, das die Beziehung zwischen verschiedenen Arten von Iris auf der Ebene einzelner Zeichen zeigt. Interessanterweise sind in allen Diagrammen die blauen Punkte von Iris setosa deutlich von den orangefarbenen und grünen Punkten anderer Arten getrennt. Dies deutet darauf hin, dass Iris Setosa tatsächlich eine separate Klasse ist. Sie können auch feststellen, dass die beiden anderen Arten manchmal verwechselt werden können, was durch überlappende orangefarbene und grüne Punkte angezeigt wird. Zum Beispiel zeigt das Diagramm der Breite und Länge des äußeren Blütenhüllens, dass sich die Punkte von Iris versicolor und Iris virginica vermischen. Dies deutet darauf hin, dass es schwierig sein wird, zwischen diesen beiden Arten zu unterscheiden, wenn nur Messungen des äußeren Blütenhüllens verfügbar sind.Das ausgegebene Pairplot ergibt eine Farbe
Wenn Sie das Argument hue key entfernen, verwendet die Pairplot-Funktion nur eine Farbe, um alle Daten auszugeben, da sie nicht weiß, wie zwischen den Ansichten in der Ausgabe unterschieden werden kann:In [21]: grid = sns.pairplot(data=iris_df, vars=iris_df.columns[0:4])
Wie aus dem folgenden Diagramm ersichtlich ist, sind in diesem Fall die Diagramme auf der Diagonale Histogramme mit den Verteilungen aller Werte dieses Attributs, unabhängig vom Typ. Beim Studium von Diagrammen scheint es nur zwei Cluster zu geben, obwohl wir wissen, dass der Datensatz drei Typen enthält. Wenn die Anzahl der Cluster nicht im Voraus bekannt ist, können Sie sich an einen Experten auf dem Fachgebiet wenden, der mit den Daten gut vertraut ist. Ein Experte kann wissen, dass ein Datensatz drei Arten von Daten enthält. Diese Informationen können nützlich sein, wenn Sie maschinelles Lernen mit Daten durchführen.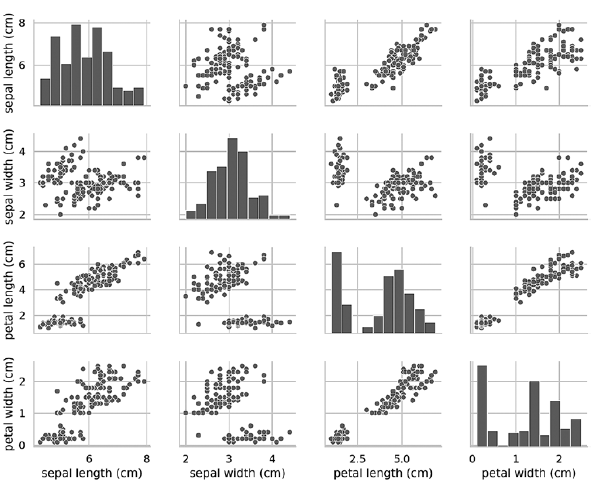 Pairplot-Diagramme eignen sich gut für eine kleine Anzahl von Features oder eine Teilmenge von Features, sodass die Anzahl der Zeilen und Spalten begrenzt ist, und für eine relativ kleine Anzahl von Mustern, sodass Datenpunkte sichtbar sind. Mit zunehmender Anzahl von Merkmalen und Mustern werden die Datenstreudiagramme zu klein, um die Daten zu lesen. In großen Datenmengen können Sie eine Teilmenge von Features im Diagramm und möglicherweise eine zufällig ausgewählte Teilmenge von Mustern zeichnen, um sich ein Bild von den Daten zu machen.»Weitere Informationen zum Buch finden Sie auf der Website des Herausgebers
Pairplot-Diagramme eignen sich gut für eine kleine Anzahl von Features oder eine Teilmenge von Features, sodass die Anzahl der Zeilen und Spalten begrenzt ist, und für eine relativ kleine Anzahl von Mustern, sodass Datenpunkte sichtbar sind. Mit zunehmender Anzahl von Merkmalen und Mustern werden die Datenstreudiagramme zu klein, um die Daten zu lesen. In großen Datenmengen können Sie eine Teilmenge von Features im Diagramm und möglicherweise eine zufällig ausgewählte Teilmenge von Mustern zeichnen, um sich ein Bild von den Daten zu machen.»Weitere Informationen zum Buch finden Sie auf der Website des Herausgebers