Jetzt dringt die Programmierung immer tiefer in alle Lebensbereiche ein. Und vielleicht wurde es jetzt dank der sehr beliebten Python. Wenn Sie vor 5 Jahren für die Datenanalyse ein ganzes Paket verschiedener Tools verwenden mussten: C # zum Entladen (oder Stiften), Excel, MatLab, SQL und zum ständigen „Springen“, Bereinigen, Überprüfen und Abgleichen von Daten. Jetzt ersetzt Python dank einer großen Anzahl hervorragender Bibliotheken und Module in erster Näherung sicher alle diese Tools, und in Verbindung mit SQL können im Allgemeinen „Berge aufgerollt werden“.Also, was mache ich? Ich interessierte mich dafür, eine so beliebte Python zu lernen. Und der beste Weg, etwas zu lernen, ist, wie Sie wissen, das Üben. Und ich interessiere mich auch für Immobilien. Und ich bin auf ein interessantes Problem mit Immobilien in Moskau gestoßen: Moskauer Bezirke nach den durchschnittlichen Mietkosten einer durchschnittlichen Odnushka zu ordnen? Väter, dachte ich, hier haben Sie Geolokalisierung, Hochladen von der Website und Datenanalyse - eine großartige praktische Aufgabe.Inspiriert von den wunderbaren Artikeln hier auf Habré (am Ende des Artikels werde ich Links hinzufügen), fangen wir an!Die Aufgabe für uns ist es, die vorhandenen Werkzeuge in Python durchzugehen, die Technik zu zerlegen - wie man solche Probleme löst und Zeit mit Vergnügen und nicht nur mit Nutzen verbringt.- Cyan abkratzen
- Einzelner Datenrahmen
- Datenrahmenverarbeitung
- Ergebnisse
- Ein bisschen über die Arbeit mit Geodaten
Cyan abkratzen
Mitte März 2020 konnten fast 9.000 Vorschläge für die Anmietung einer 1-Zimmer-Wohnung in Moskau auf Cyan gesammelt werden. Die Website zeigt 54 Seiten. Wir werden mit Jupyter-Notebook 6.0.1, Python 3.7 arbeiten. Wir laden Daten von der Site hoch und speichern sie mithilfe der Anforderungsbibliothek in Dateien .Damit die Website uns nicht verbietet, verkleiden wir uns als Person, indem wir eine Verzögerung bei den Anfragen hinzufügen und einen Header festlegen, sodass wir von der Seite der Website aus wie eine sehr kluge Person aussehen, die Anfragen über einen Browser stellt. Vergessen Sie nicht, jedes Mal die Antwort von der Website zu überprüfen, da wir sonst plötzlich entdeckt und bereits gesperrt werden. Weitere Informationen zum Scraping von Websites finden Sie beispielsweise hier: Web Scraping mit Python .Es ist auch praktisch, Dekorateure hinzuzufügen, um die Geschwindigkeit unserer Funktionen und die Protokollierung zu bewerten. Mit der Einstellung level = logging.INFO können Sie den Typ der im Protokoll angezeigten Nachrichten angeben. Sie können das Modul auch so konfigurieren, dass das Protokoll in eine Textdatei ausgegeben wird. Für uns ist dies nicht erforderlich.Der Codedef timer(f):
def wrap_timer(*args, **kwargs):
start = time.time()
result = f(*args, **kwargs)
delta = time.time() - start
print (f' {f.__name__} {delta} ')
return result
return wrap_timer
def log(f):
def wrap_log(*args, **kwargs):
logging.info(f" {f.__doc__}")
result = f(*args, **kwargs)
logging.info(f": {result}")
return result
return wrap_log
logging.basicConfig(level=logging.INFO)
@timer
@log
def requests_site(N):
headers = ({'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.5 Safari/605.1.15'})
pages = [106 + i for i in range(N)]
n = 0
for i in pages:
s = f"https://www.cian.ru/cat.php?deal_type=rent&engine_version=2&page={i}&offer_type=flat®ion=1&room1=1&type=-2"
response = requests.get(s, headers = headers)
if response.status_code == 200:
name = f'sheets/sheet_{i}.txt'
with open(name, 'w') as f:
f.write(response.text)
n += 1
logging.info(f" {i}")
else:
print(f" {i} response.status_code = {response.status_code}")
time.sleep(np.random.randint(7,13))
return f" {n} "
requests_site(300)
Einzelner Datenrahmen
Wählen Sie zum Scraping von Seiten BeautifulSoup und lxml . Wir verwenden "schöne Suppe" einfach wegen ihres coolen Namens, obwohl sie sagen, dass lxml schneller ist.Sie können es wunderbar machen, eine Liste von Dateien aus einem Ordner mithilfe der Betriebssystembibliothek entnehmen , die benötigten Erweiterungen herausfiltern und sie durchgehen. Aber wir werden es einfacher machen, da wir die genaue Anzahl der Dateien und ihre genauen Namen kennen. Es sei denn, wir fügen mithilfe der tqdm- Bibliothek eine Dekoration in Form eines Fortschrittsbalkens hinzuDer Code
from bs4 import BeautifulSoup
import re
import pandas as pd
from dateutil.parser import parse
from datetime import datetime, date, time
def read_file(filename):
with open(filename) as input_file:
text = input_file.read()
return text
import tqdm
site_texts = []
pages = [1 + i for i in range(309)]
for i in tqdm.tqdm(pages):
name = f'sheets/sheet_{i}.txt'
site_texts.append(read_file(name))
print(f" {len(site_texts)} .")
def parse_tag(tag, tag_value, item):
key = tag
value = "None"
if item.find('div', {'class': tag_value}):
if key == 'link':
value = item.find('div', {'class': tag_value}).find('a').get('href')
elif (key == 'price' or key == 'price_meter'):
value = parse_digits(item.find('div', {'class': tag_value}).text, key)
elif key == 'pub_datetime':
value = parse_date(item.find('div', {'class': tag_value}).text)
else:
value = item.find('div', {'class': tag_value}).text
return key, value
def parse_digits(string, type_digit):
digit = 0
try:
if type_digit == 'flats_counts':
digit = int(re.sub(r" ", "", string[:string.find("")]))
elif type_digit == 'price':
digit = re.sub(r" ", "", re.sub(r"₽", "", string))
elif type_digit == 'price_meter':
digit = re.sub(r" ", "", re.sub(r"₽/²", "", string))
except:
return -1
return digit
def parse_date(string):
now = datetime.strptime("15.03.20 00:00", "%d.%m.%y %H:%M")
s = string
if string.find('') >= 0:
s = "{} {}".format(now.day, now.strftime("%b"))
s = string.replace('', s)
elif string.find('') >= 0:
s = "{} {}".format(now.day - 1, now.strftime("%b"))
s = string.replace('',s)
if (s.find('') > 0):
s = s.replace('','mar')
if (s.find('') > 0):
s = s.replace('','feb')
if (s.find('') > 0):
s = s.replace('','jan')
return parse(s).strftime('%Y-%m-%d %H:%M:%S')
def parse_text(text, index):
tag_table = '_93444fe79c--wrapper--E9jWb'
tag_items = ['_93444fe79c--card--_yguQ', '_93444fe79c--card--_yguQ']
tag_flats_counts = '_93444fe79c--totalOffers--22-FL'
tags = {
'link':('c6e8ba5398--info-section--Sfnx- c6e8ba5398--main-info--oWcMk','undefined c6e8ba5398--main-info--oWcMk'),
'desc': ('c6e8ba5398--title--2CW78','c6e8ba5398--single_title--22TGT', 'c6e8ba5398--subtitle--UTwbQ'),
'price': ('c6e8ba5398--header--1df-X', 'c6e8ba5398--header--1dF9r'),
'price_meter': 'c6e8ba5398--term--3kvtJ',
'metro': 'c6e8ba5398--underground-name--1efZ3',
'pub_datetime': 'c6e8ba5398--absolute--9uFLj',
'address': 'c6e8ba5398--address-links--1tfGW',
'square': ''
}
res = []
flats_counts = 0
soup = BeautifulSoup(text)
if soup.find('div', {'class': tag_flats_counts}):
flats_counts = parse_digits(soup.find('div', {'class': tag_flats_counts}).text, 'flats_counts')
flats_list = soup.find('div', {'class': tag_table})
if flats_list:
items = flats_list.find_all('div', {'class': tag_items})
for i, item in enumerate(items):
d = {'index': index}
index += 1
for tag in tags.keys():
tag_value = tags[tag]
key, value = parse_tag(tag, tag_value, item)
d[key] = value
results[index] = d
return flats_counts, index
from IPython.display import clear_output
sum_flats = 0
index = 0
results = {}
for i, text in enumerate(site_texts):
flats_counts, index = parse_text(text, index)
sum_flats = len(results)
clear_output(wait=True)
print(f" {i + 1} flats = {flats_counts}, {sum_flats} ")
print(f" sum_flats ({sum_flats}) = flats_counts({flats_counts})")
Eine interessante Nuance war, dass die oben auf der Seite angegebene Zahl und die Gesamtzahl der auf Anfrage gefundenen Wohnungen von Seite zu Seite unterschiedlich ist. In unserem Beispiel sind diese 5.402 Angebote standardmäßig sortiert und reichen von 5343 bis 5402, wobei sie mit zunehmender Seitenzahl der Anfrage allmählich abnehmen (jedoch nicht nach der Anzahl der angezeigten Anzeigen). Darüber hinaus war es möglich, Seiten über die Grenzen der auf der Site angegebenen Anzahl von Seiten hinaus weiter zu entladen. In unserem Fall wurden nur 54 Seiten auf der Website angeboten, aber wir konnten 309 Seiten mit nur älteren Anzeigen für insgesamt 8640 Wohnungsmietanzeigen entladen.Eine Untersuchung dieser Tatsache wird außerhalb des Geltungsbereichs dieses Artikels bleiben.Datenrahmenverarbeitung
Wir haben also einen einzigen Datenrahmen mit Rohdaten zu 8640 Angeboten. Wir werden eine Oberflächenanalyse der Durchschnitts- und Durchschnittspreise in den Bezirken durchführen, den durchschnittlichen Mietpreis pro Quadratmeter der Wohnung und die Kosten der Wohnung im Bezirk „im Durchschnitt“ berechnen.Wir gehen für unsere Studie von folgenden Annahmen aus:- Fehlende Wiederholungen: Alle gefundenen Wohnungen sind wirklich existierende Wohnungen. In der ersten Phase haben wir wiederholte Wohnungen an Adresse und Quadratur eliminiert. Wenn die Wohnung jedoch eine etwas andere Quadratur oder Adresse hat, betrachten wir diese Optionen als unterschiedliche Wohnungen.
- — .
— «» ? ( ) , , , , . , , , . «» : . «» ( ) , .
Wir benötigen:price_per_month - monatlichen Preis Miete in RubelQuadrat -okrug Gebiet - Bezirk, die in dieser Studie die gesamte Adresse nicht interessant für uns istprice_meter - Mietpreis pro 1 QuadratmeterDer Codedf['price_per_month'] = df['price'].str.strip('/.').astype(int)
new_desc = df["desc"].str.split(",", n = 3, expand = True)
df["square"]= new_desc[1].str.strip(' ²').astype(int)
df["floor"]= new_desc[2]
new_address = df['address'].str.split(',', n = 3, expand = True)
df['okrug'] = new_address[1].str.strip(" ")
df['price_per_meter'] = (df['price_per_month'] / df['square']).round(2)
df = df.drop(['index','metro', 'price_meter','link', 'price','desc','address','pub_datetime','floor'], axis='columns')
Jetzt "kümmern" wir uns manuell um die Emissionen gemäß den Zeitplänen. Schauen wir uns zur Visualisierung der Daten drei Bibliotheken an: matplotlib , seaborn und plotly .Histogramme von Daten . Mit Matplotlib können Sie schnell und einfach alle Diagramme für die Datengruppen anzeigen, die uns interessieren. Mehr brauchen wir nicht. Die folgende Abbildung, nach der nur ein Vorschlag in Mitino nicht als qualitative Bewertung der durchschnittlichen Wohnung dienen kann, wird gestrichen. Ein weiteres interessantes Bild im südlichen Verwaltungsgebiet: Die meisten Angebote (mehr als 500 Einheiten) mit einem Mietwert von weniger als 1000 Rubel und einem Anstieg der Angebote (fast 300 Einheiten) um 1700 Rubel pro Quadratmeter. In Zukunft können Sie sehen, warum dies geschieht - stöbern Sie in anderen Indikatoren für diese Wohnungen.Nur eine Codezeile gibt dort Histogramme für gruppierte Datensätze:hists = df['price_per_meter'].hist(by=df['okrug'], figsize=(16, 14), color = "tab:blue", grid = True)
 Die Streuung der Werte . Im Folgenden werden die Diagramme mit allen drei Bibliotheken dargestellt. seaborn ist standardmäßig schöner und heller, aber Sie können die Werte sofort anzeigen, wenn Sie mit der Maus darüber fahren. Dies ist sehr praktisch, um die Werte der "Ausreißer" auszuwählen, die wir löschen möchten.matplotlib
Die Streuung der Werte . Im Folgenden werden die Diagramme mit allen drei Bibliotheken dargestellt. seaborn ist standardmäßig schöner und heller, aber Sie können die Werte sofort anzeigen, wenn Sie mit der Maus darüber fahren. Dies ist sehr praktisch, um die Werte der "Ausreißer" auszuwählen, die wir löschen möchten.matplotlibfig, axes = plt.subplots(nrows=4,ncols=3,figsize=(15,15))
for i, (name, group) in enumerate(df_copy.groupby('okrug')):
axes = axes.flatten()
axes[i].scatter(group['price_per_meter'],group['square'], color ='blue')
axes[i].set_title(name)
axes[i].set(xlabel=' 1 ..', ylabel=', 2')
fig.tight_layout()
 Seaboarn
Seaboarnsns.pairplot(vars=["price_per_meter","square"], data=df_copy, hue="okrug", height=5)
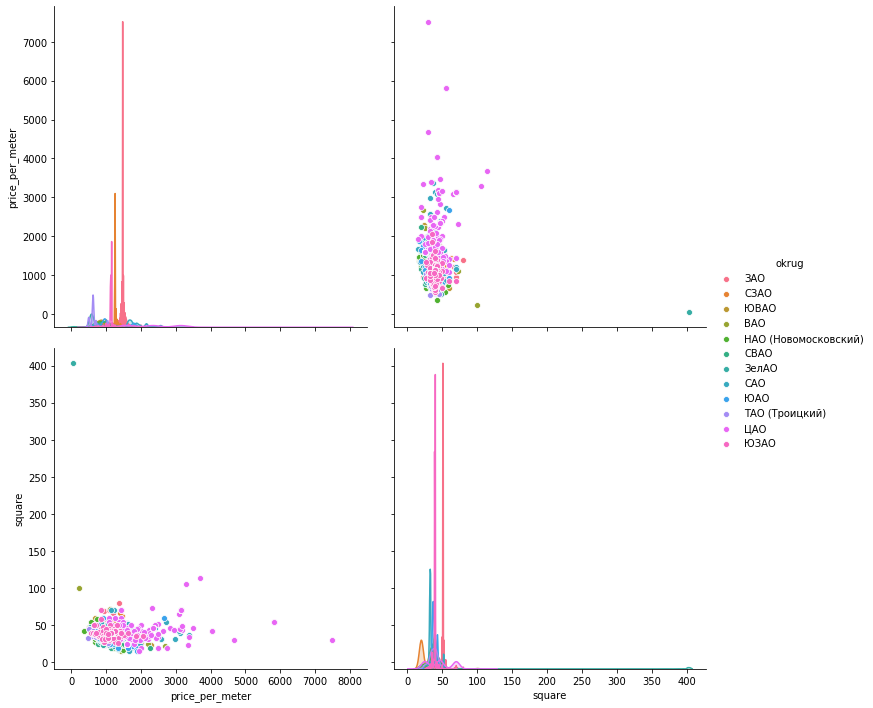 plotlyich glaube , es genug Beispiel für ein Viertel sein.
plotlyich glaube , es genug Beispiel für ein Viertel sein.import plotly.express as px
for i, (name, group) in enumerate(df_copy.groupby('okrug')):
fig = px.scatter(group, x="price_per_meter", y="square", facet_col="okrug",
width=400, height=400)
fig.update_layout(
margin=dict(l=20, r=20, t=20, b=20),
paper_bgcolor="LightSteelBlue",
)
fig.show()
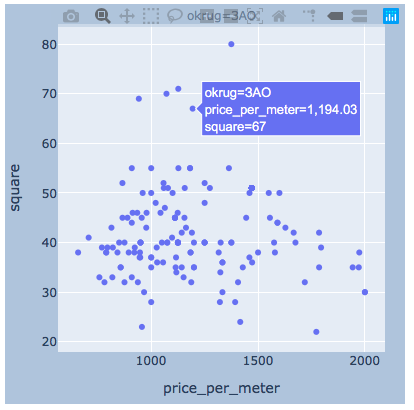
Ergebnisse
Nachdem wir die Daten bereinigt und die Emissionen fachmännisch beseitigt haben, haben wir 8602 „saubere“ Angebote.Als nächstes berechnen wir die Hauptstatistik anhand der Daten: Durchschnitt, Median, Standardabweichung. Wir erhalten die folgende Bewertung der Moskauer Bezirke, wenn die durchschnittlichen Mietkosten für eine durchschnittliche Wohnung sinken: Sie können schöne Histogramme zeichnen, indem Sie beispielsweise die Durchschnitts- und Medianpreise im Bezirk vergleichen:
Sie können schöne Histogramme zeichnen, indem Sie beispielsweise die Durchschnitts- und Medianpreise im Bezirk vergleichen: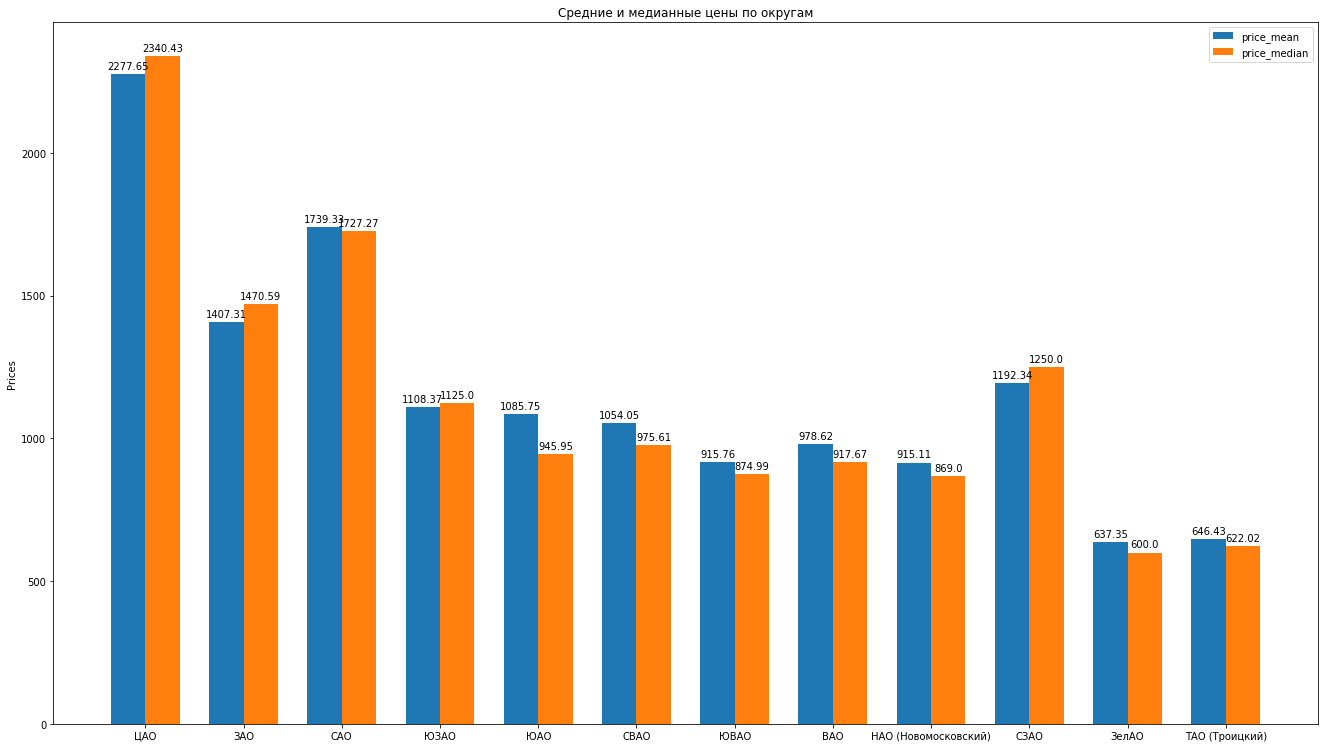 Was kann das noch? sagen über die Struktur von Vorschlägen für Mietwohnungen basierend auf Daten:
Was kann das noch? sagen über die Struktur von Vorschlägen für Mietwohnungen basierend auf Daten:- , , , . “” , ( ). , , , , , , “” . , , .
- . . « ». , «» — . . . , , , , , - , , . . .
- , “” , . , , — .
Ein separates, unglaublich interessantes und schönes Kapitel ist das Thema Geodaten, die Anzeige unserer Daten in Bezug auf die Karte. Sie können zum Beispiel in den Artikeln sehr detailliert und detailliert nachsehen:Visualisierung der Wahlergebnisse in Moskau auf einer Karte im Jupyter NotebookLikbez auf kartografischen Projektionen mitOpenStreetMap- Bildern als Quelle für GeodatenKurz gesagt, OpenStreetMap ist unser Alles, praktische Werkzeuge sind: Geopandas , Cartoframes (sie sagen, es ist bereits gestorben?) und Folium , das wir verwenden werden.So sehen unsere Daten auf einer interaktiven Karte aus.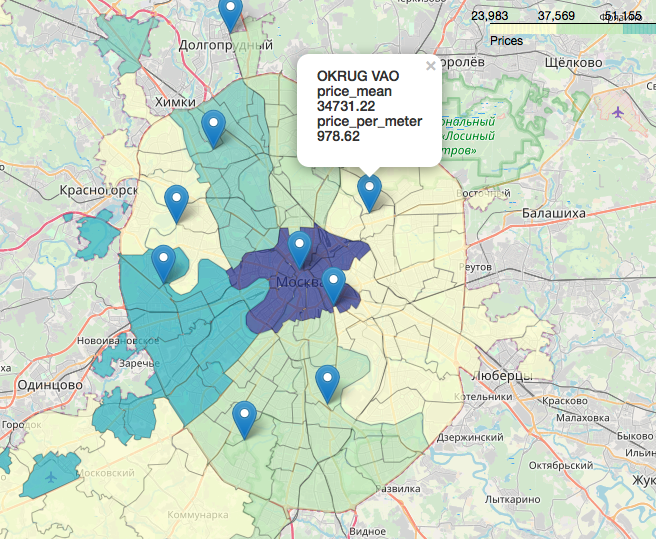 Materialien, die sich bei der Arbeit an dem Artikel als nützlich erwiesen haben:Ich hoffe du warst interessiert wie ich.Danke fürs Lesen. Konstruktive Kritik ist willkommen.Quellen und Datensätze werden auf der GitHub veröffentlicht hier .
Materialien, die sich bei der Arbeit an dem Artikel als nützlich erwiesen haben:Ich hoffe du warst interessiert wie ich.Danke fürs Lesen. Konstruktive Kritik ist willkommen.Quellen und Datensätze werden auf der GitHub veröffentlicht hier .