
Die automatische Spracherkennung (STT oder ASR) hat einen langen Weg zur Verbesserung zurückgelegt und eine ziemlich lange Geschichte. Die gängige Meinung ist, dass nur große Unternehmen in der Lage sind, mehr oder weniger funktionierende "allgemeine" Lösungen zu erstellen, die unabhängig von der Datenquelle (verschiedene Stimmen, Akzente, Domänen) vernünftige Qualitätsmetriken anzeigen. Hier sind einige Hauptgründe für dieses Missverständnis:
- Hohe Anforderungen an die Rechenleistung;
- Eine große Datenmenge, die für das Training benötigt wird;
- Veröffentlichungen schreiben in der Regel nur über die sogenannten State-of-the-Art-Lösungen, die qualitativ hochwertige Indikatoren aufweisen, aber absolut unpraktisch sind.
In diesem Artikel werden wir einige Missverständnisse zerstreuen und versuchen, den Punkt der "Singularität" für die Spracherkennung leicht anzunähern. Nämlich:
- , , NVIDIA GeForce 1080 Ti;
- Open STT 20 000 ;
- , STT .
3 — , .
PyTorch, — Deep Speech 2.
:
- GPU;
- . Python PyTorch , ;
- . ;
, PyTorch "" , , (, C++ JAVA).
Open STT
20 000 . (~90%), .
, , , “” (. Google, Baidu, Facebook). , STT “” “”.
, , STT, :
.
Deep Speech 2 (2015) :
WER (word error rate, ) . : 9- 2 2D- 7 68 . , Deep Speech 2.
: , . , . STT LibriSpeech ASR (LibriSpeech) .
, Google, Facebook, Baidu 10 000 — 100 000 . , , Facebook, , , , .
. 1 2 10 ( , , STT ).
, (LibriSpeech), , - . open-source , Google, . , , STT-. , , Common Voice, .
( ) — . , STT, /, PyTorch TensorFlow. , , .
/ ( ), , :
- ( );
- (end-to-end , , ) ;
- ( — 10GB- );
- LibriSpeech, , ;
- STT , , , , ;
- , PR, “ ” “”. , , , , , ( , , , );
- - , , , , , ;
, FairSeq EspNet, , . , ?
LibriSpeech, 8 GPU US $10 000 .
— . , .
, - "" Common Voice Mozilla.
ML: - (state-of-the-art, SOTA) , .
, , , , .
, c “ ” “, ” .
, :
- - , (. Goodhart's Law);
- “” , ( , );
- , ;
- , ;
- , 95% , . . “ ” (“publish or perish”), , , , ;
, , , , . , , , . , .
, ML :
, :
- -;
- semi-supervised unsupervised (wav2vec, STT-TTS) , , ;
- end-to-end (LibriSpeech), , 1000 ( LibriSpeech);
- MFCC . . , STFT. , - SincNet.
, , , . :
STT
STT :
— "" . , ( ). , — .
, , — . — . .
, AWS NVIDIA Tesla GPU, , 5-10 GPU.
:
, [ ] x [ ]. , , : 1) 2) ? , , ;
, .
, "L-"
— . , , "". ;
. ) ; ) , ;
, , . , , Mobilenet/EfficientNet/FBNet ;
, ML : 1) : , , ; 2) Ceteris paribus: , , .. , ;
, , ( ) , . 10 20 , , , "" .
( ):
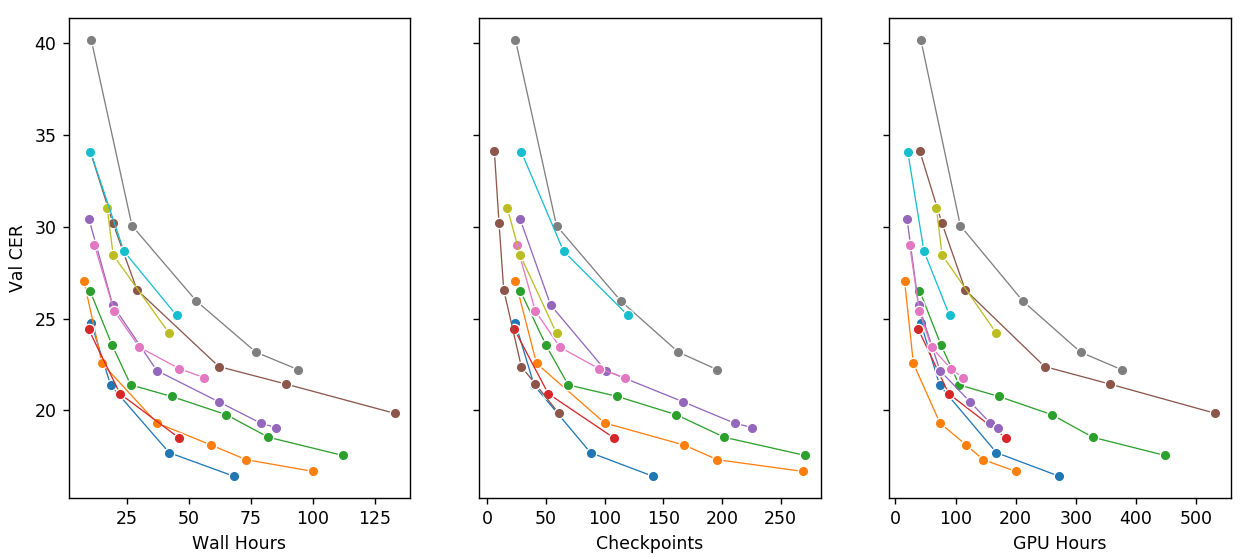
— . — . "" — Wav2Letter. DeepSpeech , 2-3 . GPU — , . , .
Deep Speech 2 Pytorch. LSTM GRU , . , . , , :
№1: .
№2: .
№3: Byte-Pair-Encoding .
. BPE , , WER ( ) . , : BPE . , BPE , .
.
№4: .
encoder-decoder. , , state-of-the-art .
, , GPU . , 500-1000 GPU , 3-4 CPU ( , ). , 2-4 , , .
№5: .
, , , 1080Ti , , , , 4 8 GPU ( GPU). , .
№6: .
, , — . , , .
curriculum learning. , , .
№7. .
, — . :
- Sequence-to-sequence ;
- Beam search — AM.
beam search KenLM 25 CPU .
:
, ( ) , , . , , .
, :
- . — . , ;
- (). . , ;
- . , , ;
- . , , ;
- . , , ;
- . , , ;
- YouTube. , , . — ;
- (e-commerce). , ;
- "Yellow pages". . , , ;
- . - . , "" . , ;
- (). , , , .
:
- Tinkoff ( , );
- (, , , , );
- Yandex SpeechKit;
- Google;
- Kaldi 0.6 / Kaldi 0.7 ( ,
vosk-api); - wit.ai;
- stt.ai;
- Azure;
- Speechmatics;
- Voisi;
— Word error rate (WER).
. ("" -> "1-"), . , WER ~1 .
2019 2020 . , . WER ~1 . , , .
Der Artikel ist schon ziemlich groß. Wenn Sie in einer detaillierteren Methodik und die Positionen der einzelnen Systeme auf jeder Domain interessiert sind, dann werden Sie eine erweiterte Version von Systemvergleich finden hier , und eine Beschreibung der Vergleichsmethode hier .