Vor einiger Zeit habe ich eine erstaunliche Reise in die Welt des JIT-Compilers begonnen, um Orte zu finden, an denen Sie Ihre Hände hineinstecken und etwas beschleunigen können Im Laufe der Hauptarbeit hat sich ein wenig Wissen über LLVM und seine Optimierungen angesammelt. In diesem Artikel möchte ich eine Liste meiner Verbesserungen in JIT (in .NET heißt es RyuJIT zu Ehren eines Drachen oder Anime - ich habe es nicht herausgefunden) teilen, von denen die meisten bereits den Master erreicht haben und in .NET (Core) 5 verfügbar sein werden Meine Optimierungen wirken sich auf verschiedene Phasen der JIT aus, die sehr schematisch wie folgt dargestellt werden können: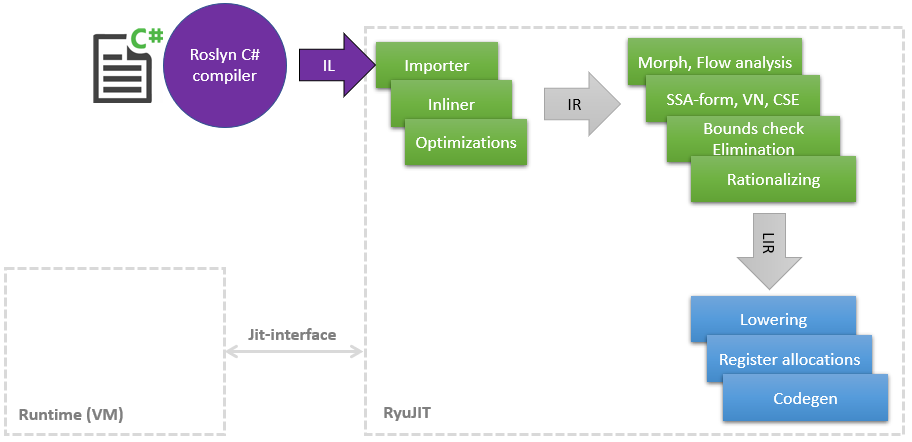 Wie aus dem Diagramm ersichtlich, ist die JIT ein separates Modul in Bezug auf die enge Jit-Schnittstelle , über die die JIT beispielsweise einige Dinge berät, ist dies möglichWirf eine Klasse in eine andere. Je später die JIT die Methode in Tier1 kompiliert, desto mehr Informationen kann die Laufzeit beispielsweise liefern, dass die
Wie aus dem Diagramm ersichtlich, ist die JIT ein separates Modul in Bezug auf die enge Jit-Schnittstelle , über die die JIT beispielsweise einige Dinge berät, ist dies möglichWirf eine Klasse in eine andere. Je später die JIT die Methode in Tier1 kompiliert, desto mehr Informationen kann die Laufzeit beispielsweise liefern, dass die static readonlyFelder durch eine Konstante ersetzt werden können, weil Die Klasse ist bereits statisch initialisiert.Beginnen wir also mit der Liste.PR # 1817 : Boxing / Unboxing-Optimierungen beim Pattern Matching
Phase: ImporterViele der neuen C # -Funktionen werden häufig durch Einfügen von Box / Unbox- CIL-Opcodes verursacht . Dies ist eine sehr teure Operation, bei der es sich im Wesentlichen um die Zuweisung eines neuen Objekts auf dem Heap handelt, bei der der Wert vom Stapel in den Heap kopiert wird und am Ende auch der GC geladen wird. Es gibt bereits eine Reihe von Optimierungen in JIT für diesen Fall, aber ich habe in C # 8 einen fehlenden Mustervergleich gefunden, zum Beispiel:public static int Case1<T>(T o)
{
if (o is int x)
return x;
return 0;
}
public static int Case2<T>(T o) => o is int n ? n : 42;
public static int Case3<T>(T o)
{
return o switch
{
int n => n,
string str => str.Length,
_ => 0
};
}
Und lassen Sie uns den asm-Codegen vor meiner Optimierung (zum Beispiel für die Int-Spezialisierung) für alle drei Methoden sehen: Und jetzt nach meiner Verbesserung:
Und jetzt nach meiner Verbesserung: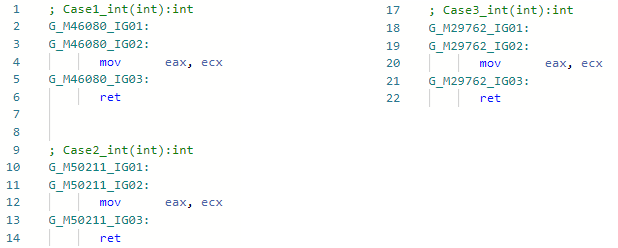 Tatsache ist, dass die Optimierung Muster von IL-Code gefunden hat
Tatsache ist, dass die Optimierung Muster von IL-Code gefunden hatbox !!T
isinst Type1
unbox.any Type2
Beim Importieren und Informationen über Typen konnte ich diese Opcodes einfach ignorieren und kein Boxing-Anboxing einfügen. Die gleiche Optimierung habe ich übrigens auch in Mono implementiert . Im Folgenden ist im Header der Optimierungsbeschreibung ein Link zu Pull-Request enthalten.PR # 1157 typeof (T) .IsValueType ⇨ wahr / falsch
Phase: ImporterHier habe ich JIT geschult, um Type.IsValueType nach Möglichkeit sofort durch eine Konstante zu ersetzen . Dies ist ein Minuspunkt der Herausforderung und der Fähigkeit, in Zukunft ganze Bedingungen und Zweige auszuschneiden. Ein Beispiel:void Foo<T>()
{
if (!typeof(T).IsValueType)
Console.WriteLine("not a valuetype");
}
Sehen wir uns den Codegen für die Foo <int> -Spezialisierung vor der Verbesserung an: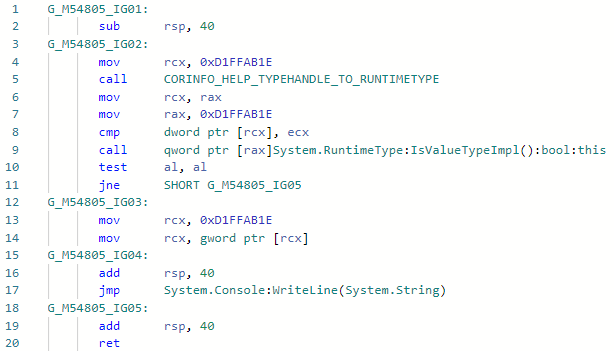 Und nach der Verbesserung:
Und nach der Verbesserung: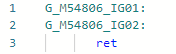 Dasselbe kann bei Bedarf mit anderen Type-Eigenschaften durchgeführt werden.
Dasselbe kann bei Bedarf mit anderen Type-Eigenschaften durchgeführt werden.PR # 1157 typeof(T1).IsAssignableFrom(typeof(T2)) ⇨ true/false
Phase: ImporterFast das Gleiche - jetzt können Sie in generischen Methoden nach Hierarchien suchen, ohne befürchten zu müssen, dass dies nicht optimiert ist, zum Beispiel:void Foo<T1, T2>()
{
if (!typeof(T1).IsAssignableFrom(typeof(T2)))
Console.WriteLine("T1 is not assignable from T2");
}
Auf die gleiche Weise wird es durch eine Konstante ersetzt true/falseund die Bedingung kann vollständig gelöscht werden. Bei solchen Optimierungen gibt es natürlich einige Eckfälle, die Sie immer berücksichtigen sollten: System .__ Freigegebene Generika, Arrays, Co (ntr) -Variabilität, Nullables, COM-Objekte usw. von Canon.PR # 1378 "Hello".Length ⇨ 5
Phase: ImporterTrotz der Tatsache, dass die Optimierung so offensichtlich und einfach wie möglich ist, musste ich viel schwitzen, um sie in JIT-e zu implementieren. Die Sache ist, dass JIT nichts über den Inhalt des Strings wusste, er sah String-Literale ( GT_CNS_STR ), wusste aber nichts über den spezifischen Inhalt des Strings. Ich musste ihm helfen, indem ich mich an VM wandte (um das oben erwähnte JIT-Interface zu erweitern), und die Optimierung selbst besteht im Wesentlichen aus ein paar Codezeilen . Abgesehen von den offensichtlichen Fällen gibt es eine ganze Reihe von Benutzerfällen, wie zum Beispiel: str.IndexOf("foo") + "foo".Lengthzu den nicht offensichtlichen, an denen Inlining beteiligt ist (ich erinnere Sie daran: Roslyn befasst sich nicht mit Inlining, daher wäre diese Optimierung darin wie alles andere unwirksam), ein Beispiel:bool Validate(string str) => str.Length > 0 && str.Length <= 100;
bool Test() => Validate("Hello");
Schauen wir uns den Codegen für Test an ( Validieren ist inline):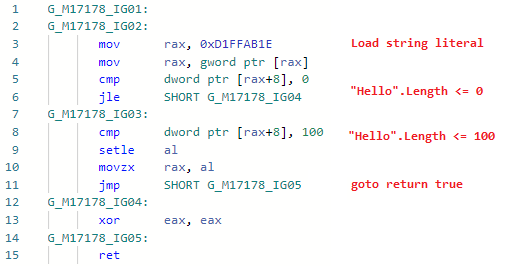 und jetzt den Codegen nach dem Hinzufügen der Optimierung:
und jetzt den Codegen nach dem Hinzufügen der Optimierung: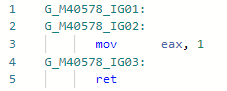 d.h. Inline die Methode, ersetzen Sie die Variablen durch String-Literale, ersetzen Sie .Length von Literalen durch echte String-Längen, falten Sie die Konstanten, löschen Sie den toten Code. Übrigens, da JIT jetzt den Inhalt einer Zeichenfolge überprüfen kann, haben sich Türen für andere Optimierungen in Bezug auf Zeichenfolgenliterale geöffnet. Die Optimierung selbst wurde in der Ankündigung der ersten Vorschau von .NET 5.0 erwähnt: devblogs.microsoft.com/dotnet/announcing-net-5-0-preview-1 im Abschnitt Verbesserungen der Codequalität in RyuJIT .
d.h. Inline die Methode, ersetzen Sie die Variablen durch String-Literale, ersetzen Sie .Length von Literalen durch echte String-Längen, falten Sie die Konstanten, löschen Sie den toten Code. Übrigens, da JIT jetzt den Inhalt einer Zeichenfolge überprüfen kann, haben sich Türen für andere Optimierungen in Bezug auf Zeichenfolgenliterale geöffnet. Die Optimierung selbst wurde in der Ankündigung der ersten Vorschau von .NET 5.0 erwähnt: devblogs.microsoft.com/dotnet/announcing-net-5-0-preview-1 im Abschnitt Verbesserungen der Codequalität in RyuJIT .PR # 1644: Optimierung gebundener Prüfungen.
Phase: Eliminierung von GrenzprüfungenFür viele ist es kein Geheimnis, dass jedes Mal, wenn Sie über einen Index auf ein Array zugreifen, die JIT eine Überprüfung für Sie einfügt, dass das Array nicht darüber hinausgeht, und in diesem Fall eine Ausnahme auslöst - im Fall einer fehlerhaften Logik konnten Sie dies nicht Um einen zufälligen Speicher zu lesen, erhalten Sie einen Wert und fahren Sie fort.int Foo(int[] array, int index)
{
return array[index];
}
Eine solche Überprüfung ist nützlich, kann jedoch die Leistung erheblich beeinträchtigen: Erstens wird eine Vergleichsoperation hinzugefügt und Ihr Code wird unverzweigt, und zweitens wird Ihrer Methode ein Ausnahmeaufrufcode mit allen Konsequenzen hinzugefügt. In vielen Fällen kann die JIT diese Überprüfungen jedoch entfernen, wenn sie sich selbst beweisen kann, dass der Index niemals darüber hinausgeht oder dass es bereits eine andere Überprüfung gibt und Sie keine weitere hinzufügen müssen - Eliminierung von Bounds (Range) Checks. Ich habe mehrere Fälle gefunden, in denen er sie nicht bewältigen und korrigieren konnte (und in Zukunft plane ich weitere Verbesserungen dieser Phase).var item = array[index & mask];
Hier in diesem Code sage ich JIT, dass & maskder Index von oben im Wesentlichen auf einen Wert begrenzt ist mask, d. H. Wenn der Wert maskund die Länge des Arrays JIT bekannt sind , können Sie keine gebundene Prüfung einfügen. Gleiches gilt für%, (& x >> y) Operationen. Ein Beispiel für die Verwendung dieser Optimierung in aspnetcore .Wenn wir wissen, dass unser Array beispielsweise 256 oder mehr Elemente enthält, kann unser unbekannter Indexer vom Bytetyp, egal wie sehr er es versucht, niemals außerhalb der Grenzen austreten. PR: github.com/dotnet/coreclr/pull/25912PR # 24584: x / 2 ⇨ x * 0.5
Phase: MorphC dieser PR und begann meinen erstaunlichen Sprung in die Welt der JIT-Optimierungen. Die Operation "Division" ist langsamer als die Operation "Multiplikation" (und wenn für ganze Zahlen und allgemein - eine Größenordnung). Funktioniert für Konstanten, die nur der Zweierpotenz entsprechen, Beispiel:static float DivideBy2(float x) => x / 2;
Codegen vor der Optimierung: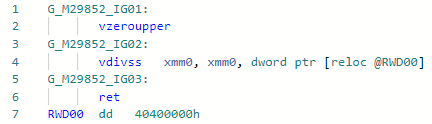 und danach:
und danach: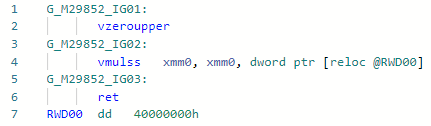 Wenn wir diese beiden Anweisungen für Haswell vergleichen, wird alles klar:
Wenn wir diese beiden Anweisungen für Haswell vergleichen, wird alles klar:vdivss (Latency: 10-20, R.Throughput: 7-14)
vmulss (Latency: 5, R.Throughput: 0.5)
Darauf folgen Optimierungen, die sich noch in der Codeüberprüfungsphase befinden, und nicht die Tatsache, dass sie akzeptiert werden.PR # 31978: Math.Pow(x, 2) ⇨ x * x
Phase: Importer Hier istalles einfach: Anstatt pow (f) für einen recht beliebten Fall aufzurufen, können Sie ihn bei konstantem Grad 2 (also auch für 1, -1, 0 kostenlos) zu einem einfachen x * x erweitern. Sie können alle anderen Grade erweitern, müssen jedoch auf die Implementierung des "Fast Math" -Modus in .NET warten, in dem die IEEE-754-Spezifikation aus Gründen der Leistung vernachlässigt werden kann. Beispiel:static float Pow2(float x) => MathF.Pow(x, 2);
Codegen vor der Optimierung: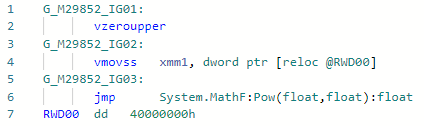 und danach:
und danach: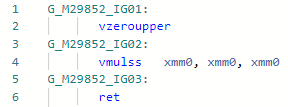
PR # 33024: x * 2 ⇨ x + x
Phase: AbsenkenAuch eine recht einfache Mikro- (Nano-) Piphol-Optimierung ermöglicht es Ihnen, mit 2 zu multiplizieren, ohne die Konstante in das Register zu laden.static float MultiplyBy2(float x) => x * 2;
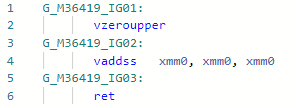
Codegen vor der Optimierung: Nachher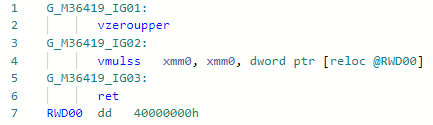 :
: Im Allgemeinen ist der Befehl in Bezug
Im Allgemeinen ist der Befehl in Bezug mul(ss/sd/ps/pd)auf Latenz und Durchsatz dieselbe wie add(ss/sd/ps/pd), aber die Notwendigkeit, die Konstante „2“ zu laden, kann die Arbeit etwas verlangsamen. Hier, im obigen Beispiel des Codegens, habe ich vaddssalles im Rahmen eines Registers gemacht.PR # 32368: Optimierung von Array.Length / c (oder% s)
Phase: MorphEs ist einfach so passiert, dass das Längenfeld von Array ein vorzeichenbehafteter Typ ist und das Teilen und der Rest durch eine Konstante von einem vorzeichenlosen Typ (und nicht nur einer Zweierpotenz) viel effizienter ist. Vergleichen Sie einfach diesen Codegen: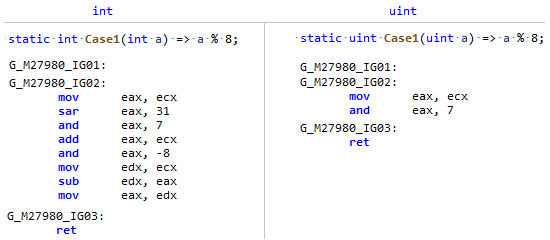 Meine PR erinnert JIT nur daran
Meine PR erinnert JIT nur daran Array.LengthObwohl signifikant, kann die Länge des Arrays NIEMALS (es sei denn, Sie sind Anarchist ) kleiner als Null sein. Dies bedeutet, dass Sie es als vorzeichenlose Zahl betrachten und einige Optimierungen wie für uint anwenden können.PR # 32716: Optimierung einfacher Vergleiche in verzweigungslosem Code
Phase: FlussanalyseDies ist eine weitere Klasse von Optimierungen, die mit Basisblöcken anstelle von Ausdrücken innerhalb eines Blocks arbeitet. Hier ist JIT etwas konservativ und bietet Raum für Verbesserungen, zum Beispiel cmove-Einsätze, wo dies möglich ist. Ich habe mit einer einfachen Optimierung für diesen Fall begonnen:x = condition ? A : B;
Wenn A und B Konstanten sind und der Unterschied zwischen ihnen beispielsweise Eins ist, können condition ? 1 : 2wir, da wir wissen, dass die Vergleichsoperation an sich 0 oder 1 zurückgibt, den Sprung durch add ersetzen. In Bezug auf RyuJIT sieht es ungefähr so aus: Ich empfehle, die Beschreibung der PR selbst zu sehen, ich hoffe, dass dort alles klar beschrieben ist.
empfehle, die Beschreibung der PR selbst zu sehen, ich hoffe, dass dort alles klar beschrieben ist.Nicht alle Optimierungen sind gleichermaßen nützlich.
Optimierungen erfordern eine ziemlich hohe Gebühr:* Erhöhen = Komplexität des vorhandenen Codes für Support und Lesen* Mögliche Fehler: Das Testen von Compiler-Optimierungen ist wahnsinnig schwierig und leicht, etwas zu übersehen und eine Art Segfault von Benutzern zu erhalten.* Langsame Kompilierung* Vergrößerung des JIT-BinarsWie Sie bereits verstanden haben, werden nicht alle Ideen und Prototypen von Optimierungen akzeptiert, und es muss nachgewiesen werden, dass sie das Recht auf Leben haben. Eine der akzeptierten Möglichkeiten, dies in .NET zu beweisen, besteht darin, das Dienstprogramm jit-utils auszuführen, mit dem AOT eine Reihe von Bibliotheken (alle BCL und Corelib) kompiliert und den Assembler-Code für alle Methoden vor und nach Optimierungen vergleicht. So sieht dieser Bericht nach Optimierung aus"str".Length. Neben dem Bericht gibt es auch einen bestimmten Personenkreis (z. B. jkotas ), der auf einen Blick die Nützlichkeit bewerten und alles aus der Höhe ihrer Erfahrung und ihres Verständnisses heraus hacken kann, welche Stellen in .NET ein Engpass sein können und welche nicht. Und noch etwas: Beurteilen Sie die Optimierung nicht anhand des Arguments „Niemand schreibt“, „es wäre besser, nur in Roslyn eine Warnung anzuzeigen“ - Sie wissen nie, wie Ihr Code aussehen wird, wenn JIT alles Mögliche einfügt und Konstanten ausfüllt.