Die Komprimierung von Standardheadern wurde in HTTP / 2 angezeigt, aber der Hauptteil der URI-, Cookie- und User-Agent-Werte kann immer noch mehrere zehn Kilobyte betragen und erfordert Tokenisierung, Suche und Vergleich von Teilzeichenfolgen. Die Aufgabe wird kritisch, wenn ein HTTP-Parser starken böswilligen Datenverkehr verarbeiten muss. Standardbibliotheken bieten umfangreiche Tools zur Verarbeitung von Zeichenfolgen, HTTP-Zeichenfolgen haben jedoch ihre eigenen Besonderheiten. Aus diesem Grund wurde der HTTP-Parser Tempesta FW entwickelt. Die Leistung ist im Vergleich zu modernen Open Source-Lösungen um ein Vielfaches höher und übertrifft die schnellste.Alexander Krizhanovsky (krizhanovsky) Gründer und Systemarchitekt Tempesta Technologies, Experte für Hochleistungsrechnen unter Linux / x86-64. Alexander wird über die Besonderheiten der Struktur von HTTP-Strings sprechen, erklären, warum Standardbibliotheken für deren Verarbeitung schlecht geeignet sind, und die Tempesta FW-Lösung vorstellen.Unter der Katze: Wie verwandelt HTTP Flood Ihren HTTP-Parser in einen Engpass, x86-64-Probleme mit Verzweigungsfehlvorhersagen, Caching und Speichermangel bei typischen HTTP-Parser-Aufgaben, Vergleich von FSM mit direkten Sprüngen, GCC-Optimierung, Auto-Vektorisierung, strspn () - und strcasecmp () - ähnliche Algorithmen für HTTP-Strings, SSE, AVX2 und Filterinjektionsangriffe mit AVX2.Bei Tempesta Technologies entwickeln wir kundenspezifische Software: Wir sind auf komplexe Bereiche im Zusammenhang mit hoher Leistung spezialisiert. Wir sind besonders stolz auf die Entwicklung des Kerns der ersten Version von WAF von Positive Technologies. Die Web Application Firewall (WAF) ist ein HTTP-Proxy: Sie befasst sich mit einer sehr gründlichen Analyse des HTTP-Verkehrs auf Angriffe (Web und DDoS). Wir haben den ersten Kern dafür geschrieben.Zusätzlich zur Beratung entwickeln wir Tempesta FW - dies ist Application Delivery Controller (ADC). Wir werden über ihn sprechen.Application Delivery Controller
Application Delivery Controller ist ein HTTP-Proxy mit erweiterten Funktionen. Ich werde jedoch über eine Funktion sprechen, die sich auf die Sicherheit bezieht - über das Filtern von DDoS- und Web-Angriffen. Ich werde auch die Einschränkungen erwähnen und die Arbeit und Funktionen anhand von Codebeispielen zeigen.
Performance
Tempesta FW ist in den Linux TCP / IP Stack-Kernel integriert. Dank dieser und einer Reihe anderer Optimierungen ist es sehr schnell - es kann 1,8 Millionen Anfragen pro Sekunde auf billiger Hardware verarbeiten. Dies ist dreimal schneller als Nginx bei der höchsten Last und auch im Vergleich zum Kernel-Bypass-Ansatz schnell .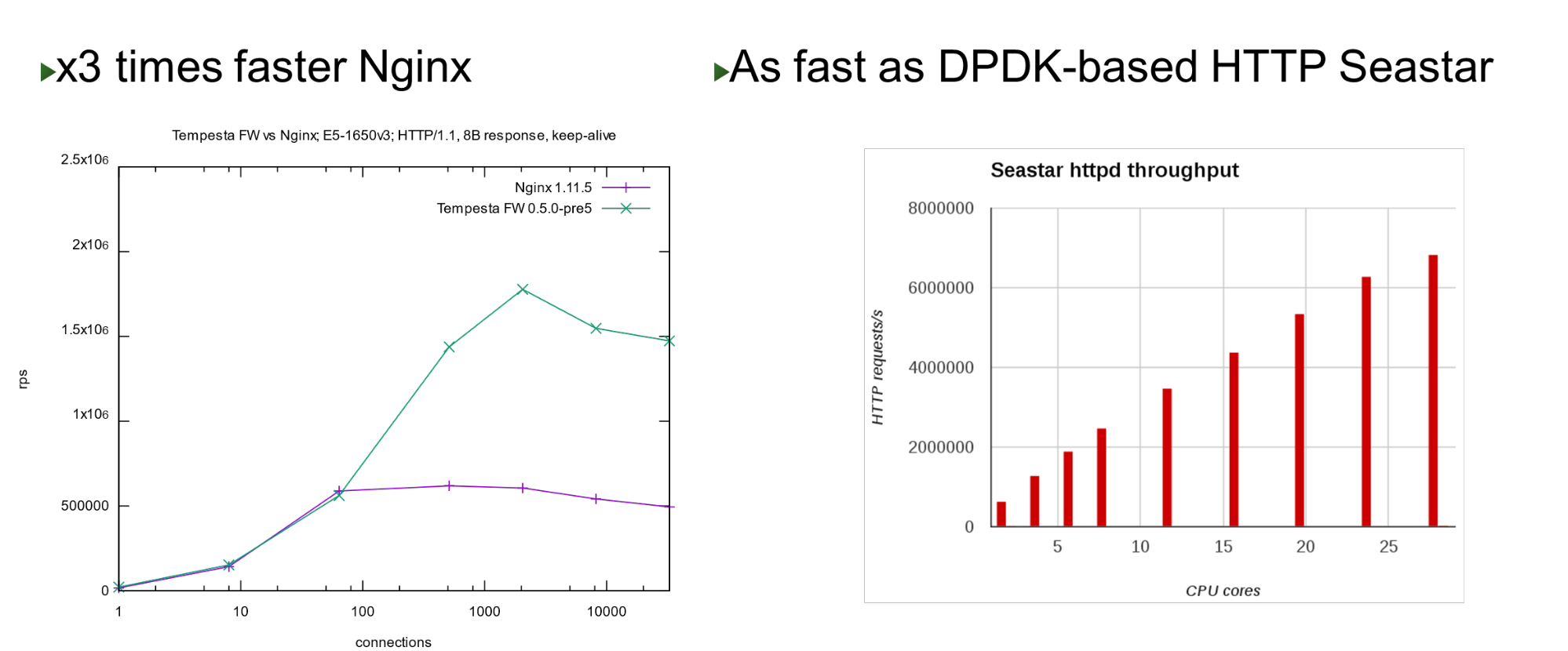 Auf einer kleinen Anzahl von Kernen zeigt es eine ähnliche Leistung wie das Seastar-Projekt, das in ScyllaDB (geschrieben in DPDK) verwendet wird.
Auf einer kleinen Anzahl von Kernen zeigt es eine ähnliche Leistung wie das Seastar-Projekt, das in ScyllaDB (geschrieben in DPDK) verwendet wird.Problem
Das Projekt wurde geboren, als wir 2013 mit der Arbeit an PT AF begannen. Diese WAF basierte auf einem beliebten Open Source HTTP-Beschleuniger. Nginx-, HAProxy-, Varnish- oder Apache-Verkehr sind gute HTTP-Beschleuniger: Sie liefern Inhalte in Ordnung, zwischenspeichern und ändern, aber keiner von ihnen ist für die Verarbeitung und Filterung von massivem Verkehr ausgelegt .Daher dachten wir, wenn es eine Firewall auf Netzwerkebene gibt, warum nicht diese Idee fortsetzen und als Firewall auf Anwendungsebene in den TCP / IP-Stack integrieren? Tatsächlich stellte sich heraus, dass Tempesta FW - eine Mischung aus HTTP-Beschleuniger und Firewall .Hinweis: Nginx wird als Beispiel im Bericht verwendet, da es sich um einen einfachen und beliebten Webserver handelt. Stattdessen könnte es einen anderen Open Source HTTP-Server geben.HTTP
Schauen wir uns unsere HTTP-Anfrage an (HTTP / (1, ~ 2)).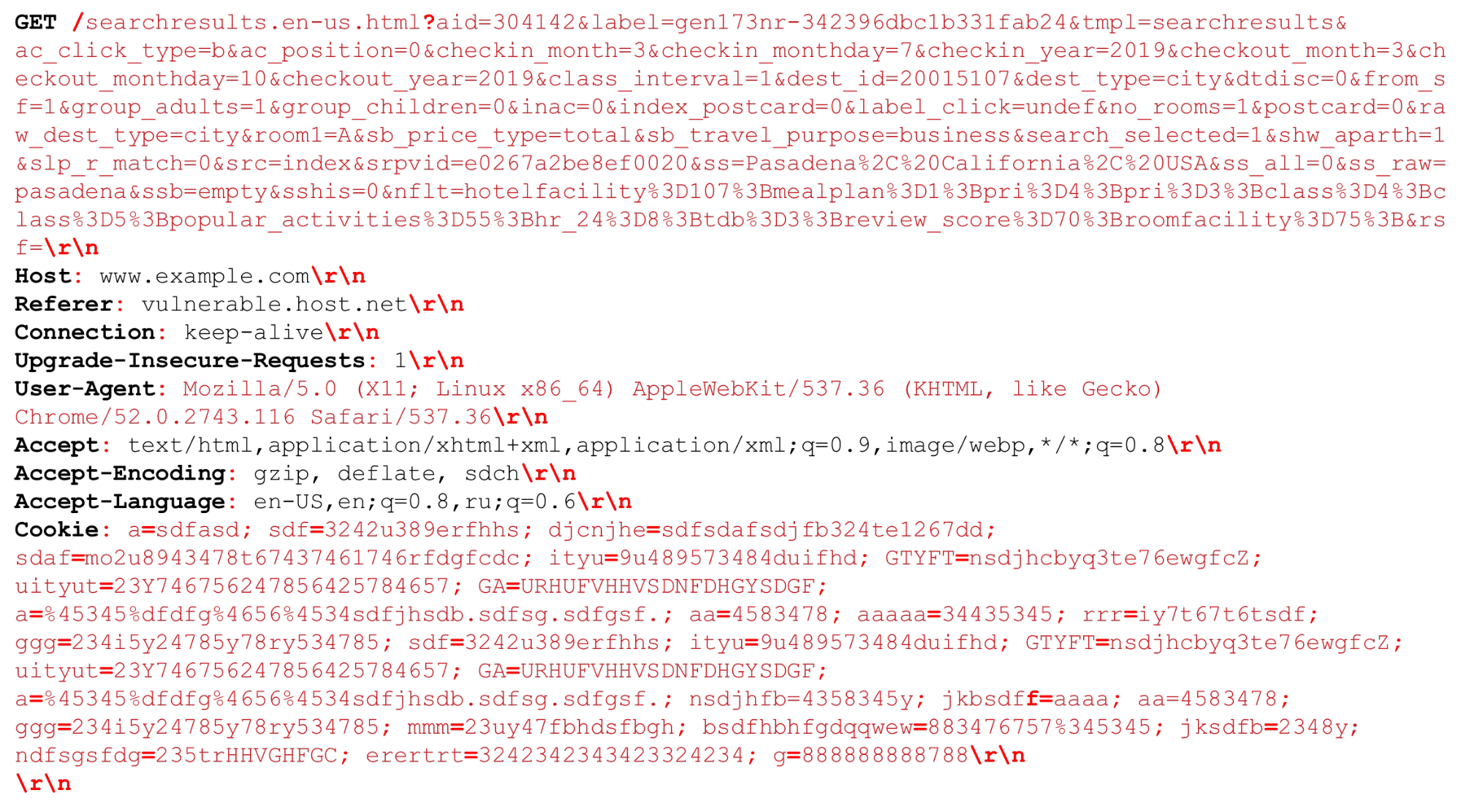 Wir können einen sehr großen URI haben. Trennzeichen , die zum Zeitpunkt der HTTP-Analyse wichtig sind, sind rot hervorgehoben . Ich werde die Merkmale hervorheben: große Zeichenfolgen von mehreren Kilobyte sowie verschiedene Trennzeichen, zum Beispiel zusätzliche "Semikolons", die wir analysieren müssen, oder die Sequenz "\ r \ n".Ein bisschen über HTTP / 2 muss auch gesagt werden.
Wir können einen sehr großen URI haben. Trennzeichen , die zum Zeitpunkt der HTTP-Analyse wichtig sind, sind rot hervorgehoben . Ich werde die Merkmale hervorheben: große Zeichenfolgen von mehreren Kilobyte sowie verschiedene Trennzeichen, zum Beispiel zusätzliche "Semikolons", die wir analysieren müssen, oder die Sequenz "\ r \ n".Ein bisschen über HTTP / 2 muss auch gesagt werden.HTTP / 2-Funktionen
HTTP / 2 ist eine Mischung aus Zeichenfolgen und Binärdaten . Bei dieser Mischung geht es mehr um die Optimierung der Bandbreite einer Verbindung als um die Einsparung von Serverressourcen.HTTP / 2 in HPACK verwendet eine dynamische Tabelle . Die erste Anforderung vom Client ist nicht optimiert, sie befindet sich nicht in der Tabelle. Sie müssen es analysieren, damit es der Tabelle hinzugefügt wird. Wenn HTTP / 2 DDoS zu Ihnen kommt, ist dies genau der Fall. Im Normalfall ist HTTP / 2 ein Binärprotokoll, Sie müssen jedoch noch Text analysieren: Namen der Textheader, Daten.Huffman-Codierung. Dies ist eine einfache Codierung, aber Huffman ist für die Komprimierung unglaublich schwer schnell zu programmieren: Die Huffman-Codierung überschreitet die Bytegrenze, Sie können keine Vektorerweiterungen verwenden und müssen nach Bytes gehen. Sie können Daten in 32 oder 16 Byte nicht schnell verarbeiten.Cookies, User-Agent, Referer, URIs können sehr groß sein . Entfernen Sie zuerst Huffman und senden Sie es dann an einen regulären HTTP-Parser, genau wie in HTTP / 1. Obwohl dies vom RFC zugelassen wird, wird nicht empfohlen, Cookies zu komprimieren, da es sich um vertrauliche Daten handelt. Sie sollten dem Angreifer keine Informationen über deren Größe geben.Langsame HTTP-Verarbeitung . Alle HTTP-Server dekodieren zuerst HTTP / 2 und senden diese Zeilen dann an den HTTP / 1-Parser, den HTTP / 1 bereits verwendet.Was ist das Problem beim HTTP / 1-Parsing?- Sie müssen die Zustandsmaschine schnell programmieren.
- Sie müssen schnell aufeinanderfolgende Zeilen verarbeiten.
Bösartiger Datenverkehr zielt auf den langsamsten (schwächsten) Teil des Prozesses ab. Wenn wir also einen Filter herstellen möchten, müssen wir auf die langsamen Teile achten, damit sie auch schnell funktionieren.Nginx-Profil
Schauen wir uns das Nginx-Profil unter der HTTP-Flut an. Deaktivieren Sie das Zugriffsprotokoll, damit das Dateisystem nicht langsamer wird. Wenn sogar eine reguläre Indexseite angefordert wird, wird der Parser oben angezeigt.Links - "Flaches Profil". Interessanterweise ist die heißeste Stelle nicht viel schwerer als die nächste, und danach fällt das Profil sanft ab. Dies bedeutet zum Beispiel, dass eine zweimalige Optimierung der ersten Funktion nicht dazu beiträgt, die Leistung signifikant zu verbessern. Aus diesem Grund haben wir nicht denselben Nginx optimiert, sondern ein neues Projekt erstellt, das die Leistung des gesamten Endes des Profils verbessert.Wie reguläre HTTP-Parser codiert werden
Normalerweise haben wir eine Schleife ( while), die entlang der Linie verläuft, und zwei Variablen: state ( state) und current data ( str_ptr).Wir treten in den Zyklus (1) ein und betrachten den aktuellen Zustand (Prüfzustand). Wir gehen zu den empfangenen Daten (Symbol 'b') über und implementieren eine Logik. Wir gehen zum zweiten Zustand über (2). Gehen Sie zum Ende
Gehen Sie zum Ende switch(3) - dies ist der zweite Übergang relativ zum Anfang unseres Codes und möglicherweise der zweite Fehler im Anweisungscache. Dann gehen wir zum Anfang while(4), essen das nächste Zeichen ... ... und suchen erneut nach dem Zustand in den Anweisungen darin
... und suchen erneut nach dem Zustand in den Anweisungen darin case 2:.Wenn einer Variablen bereits ein stateWert zugewiesen wurde2Wir könnten einfach zur nächsten Anweisung gehen. Aber stattdessen gingen sie wieder hoch und wieder runter. Wir „schneiden Kreise“ nach Code, anstatt nur nach unten zu gehen. Normale Parser generieren beispielsweise keinen Parser mit direkten Übergängen.
Nginx HTTP Parser
Ein paar Worte zum Nginx-Parser und seiner Umgebung.Nginx arbeitet mit der normalen Socket-API - die Daten, die an den Adapter gesendet werden, werden in den Benutzerbereich kopiert. Als Ergebnis haben wir einen großen Datenblock, in dem wir nach dem suchen, was wir brauchen.Nginx verwendet einen Algorithmus, der in zwei Durchgängen funktioniert: Zuerst wird nach der Länge gesucht, dann wird geprüft. Im ersten Schritt durchsucht er die Zeichenfolge nach Token und sucht nach dem ersten Token („Test“). Beim zweiten Token wird das Ende der Anforderung ( Get) überprüft und switchentsprechend der Größe des Tokens gestartet.for (p = b->pos; p < b->last; p++) {
...
switch (state) {
...
case sw_method:
if (ch == ' ') {
m = r->request_start;
switch (p - m) {
case 3:
if (ngx_str3_cmp(m, 'G', 'E', 'T', ' ')) {
...
}
if ((ch < 'A' || ch > 'Z') && ch != '_' && ch != '-')
return NGX_HTTP_PARSE_INVALID_METHOD;
break;
...
"Get" befindet sich immer im selben Datenblock . Tempesta FW arbeitet mit Nullkopie. Dies bedeutet, dass Daten eine völlig beliebige Größe haben können: jeweils 1 Byte oder 1000 Byte. Dieser "Mechanismus" passt nicht zu uns.Mal sehen, wie es switchin GCC funktioniert .Gcc
Nachschlagetabelle . Links sehen Sie ein typisches Beispiel für eine Aufzählung: Beginnen Sie mit 0, dann mit aufeinanderfolgenden Beschriftungen, 26 Konstanten und dann mit Code, der alles verarbeitet. Rechts ist der Code, den der Compiler generiert. Vergleichen Sie zunächst die Variable
Vergleichen Sie zunächst die Variable stateim EAX-Register mit einer Konstanten. Als nächstes präsentieren wir alle Beschriftungen in Form eines sequentiellen Arrays von Zeigern mit 8 Bytes (Nachschlagetabelle). Bei dieser Anweisung geben wir den Offset in diesem Array weiter - es handelt sich um eine doppelte Dereferenzierung von Zeigern. Unten rechts befindet sich der Code, zu dem wir aus dieser Tabelle gewechselt haben.Es stellt sich eine doppelte Dereferenzierung des Speichers heraus: Wenn wir geheime Daten empfangen haben, finden wir durch Bytes die Adresse im Array und gehen zu diesem Zeiger. Es ist wichtig zu wissen, dass es im Leben immer noch schlimmer ist als im Beispiel - für die Nachschlagetabelle generiert der CompilerDer Code ist im Fall eines Skripts für einen Spectre-Angriff komplizierter .Binäre Suche . Der nächste Fall betrifft switchnicht sequentielle Konstanten, sondern beliebige. Der Code ist der gleiche, aber jetzt kann GCC kein so großes Array kompilieren und Konstanten als Index des Arrays verwenden. Er wechselt zur binären Suche. Rechts sehen wir einen sequentiellen Vergleich, den Übergang zur Adresse und die Fortsetzung des Vergleichs - die binäre Suche erfolgt nach Code.Nginx HTTP-Parser. Mal sehen, was State Machine Nginx ist. Es verfügt über 9 Kilobyte Code - dies ist dreimal weniger als der Cache der ersten Ebene auf dem Computer, auf dem die Benchmarks gestartet wurden (wie bei den meisten x86-64-Prozessoren).
Rechts sehen wir einen sequentiellen Vergleich, den Übergang zur Adresse und die Fortsetzung des Vergleichs - die binäre Suche erfolgt nach Code.Nginx HTTP-Parser. Mal sehen, was State Machine Nginx ist. Es verfügt über 9 Kilobyte Code - dies ist dreimal weniger als der Cache der ersten Ebene auf dem Computer, auf dem die Benchmarks gestartet wurden (wie bei den meisten x86-64-Prozessoren).$ nm -S /opt/nginx-1.11.5/sbin/nginx
| grep http_parse | cut -d' ' -f 2
| perl -le '$a += hex($_) while (<>); print $a'
9220
$ getconf LEVEL1_ICACHE_SIZE
32768
$ grep -c 'case sw_' src/http/ngx_http_parse.c
84
Der Nginx-Header-Parser ngx_http_parse_header_line ()ist ein einfacher Tokenizer. Es macht nichts mit den Werten der Header und ihren Namen, sondern setzt einfach die Token der HTTP-Header in einen Hash. Wenn Sie einen Header-Wert benötigen, scannen Sie die Header-Tabelle und wiederholen Sie die Analyse.Wir müssen die Namen und Werte der Header aus Sicherheitsgründen streng überprüfen .Tempesta FW: String-Validierung von HTTP-Strings
Unsere Zustandsmaschine ist um eine Größenordnung leistungsfähiger: Wir führen eine RFC-Header-Validierung durch und verarbeiten im Parser sofort fast alles. Wenn Nginx 80 Zustände hat, dann haben wir 520, und es gibt mehr davon. Wenn wir weiterfahren switchwürden, wäre es zehnmal größer.Wir haben Zero-Copy-E / A - Blöcke unterschiedlicher Größe können Daten an verschiedenen Stellen schneiden. Verschiedene Chunks können unsere Daten schneiden. In E / A mit Nullkopie kann "GET" beispielsweise (selten) als "GET", "GE" und "T" oder "G", "E" und "T" auftreten, sodass Sie den Status zwischen Datenelementen speichern müssen . Wir entfernen praktisch die Kosten für E / A, aber im Profil fliegt es hoch - alles ist schlecht. Der große HTTP-Parser ist einer der kritischsten Stellen im Projekt.$ grep -c '__FSM_STATE\|__FSM_TX\|__FSM_METH_MOVE\|__TFW_HTTP_PARSE_' http_parser.c
520
7.64% [tempesta_fw] [k] tfw_http_parse_req
2.79% [e1000] [k] e1000_xmit_frame
2.32% [tempesta_fw] [k] __tfw_strspn_simd
2.31% [tempesta_fw] [k] __tfw_http_msg_add_str_data
1.60% [tempesta_fw] [k] __new_pgfrag
1.58% [kernel] [k] skb_release_data
1.55% [tempesta_fw] [k] __str_grow_tree
1.41% [kernel] [k] __inet_lookup_established
1.35% [tempesta_fw] [k] tfw_cache_do_action
1.35% [tempesta_fw] [k] __tfw_strcmpspn
Was tun, um diese Situation zu verbessern?FSM Direct Referrals
Als erstes verwenden wir keine Schleife, sondern direkte Übergänge durch Labels ( go to) . Normale Parser-Generatoren wie Ragel tun dies. Wir codieren jeden unserer Zustände mit einem Label in
Wir codieren jeden unserer Zustände mit einem Label in switchund einem Label in C mit demselben Namen . Jedes Mal, wenn wir gehen möchten, finden wir eine Beschriftung in switchoder greifen direkt über den Code auf denselben Status zu. Das erste Mal, wenn wir durchgehen switch, und dann drinnen gehen wir direkt zum gewünschten Etikett.Nachteil : Wenn wir in den nächsten Status wechseln möchten, müssen wir sofort bewerten, ob noch Daten verfügbar sind (da keine E / A-Kopien vorhanden sind). Zustand KörperforEs wird in jeden Zustand kopiert: Anstelle einer Bedingung in einem regulären schaltergesteuerten FSM haben wir 500 davon entsprechend der Anzahl der Zustände. Das Generieren von Code für jeden Status ist nicht großartig.Bei großen Zustandsautomaten wiederholt die AGB forbei einem großen switchInnenraum die Bedingung auch formehrmals im Code.Durch switchdirekte Übergänge ersetzen . Die nächste Optimierung besteht darin, dass wir es nicht verwenden switchund zu direkten Sprüngen zu den gespeicherten Meta-Adressen wechseln. Wir wollen sofort zum gewünschten Punkt gehen, sobald wir die Funktion betreten. Mit GCC können Sie dies tun. GCC hat eine Standarderweiterung, die helfen kann. Wir nehmen den Markennamen (hier ist er
GCC hat eine Standarderweiterung, die helfen kann. Wir nehmen den Markennamen (hier ist er from) und weisen seine Adresse einer C-Variablen über ein doppeltes kaufmännisches Und (&&) zu. Jetzt können wir eine direkte Sprunganweisung machenjmpan die Adresse dieses Etiketts mit goto.Mal sehen, was daraus wird.Direkte Konvertierungsleistung
In einer kleinen Anzahl von Zuständen ist der Generator für den direkten Übergangscode sogar etwas langsamer als normal switch. Bei großen Zustandsautomaten verdoppelt sich jedoch die Produktivität. Wenn die Zustandsmaschine klein ist, ist es besser, die übliche zu verwenden switch.$ grep -m 2 'model name\|bugs' /proc/cpuinfo
model name : Intel(R) Core(TM) i7-6500U CPU @ 2.50GHz
bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf
$ gcc --version|head -1
gcc (GCC) 8.2.1 20181105 (Red Hat 8.2.1-5)
States Switch-driven automaton Goto-driven automaton
7 header_line: 139ms header_line: 156ms
27 request_line: 210ms request_line: 186ms
406 big_header_line: 1406ms goto_big_header_line: 727ms
Hinweis: Tempesta-Code ist komplizierter als die Beispiele. GitHub hat alle Benchmarks, so dass Sie alles im Detail sehen können. Der ursprüngliche Parser-Code ist unter dem Link (Haupt-HTTP-Parser) verfügbar . Darüber hinaus gibt es in Tempesta FW kleinere Parser , die FSM einfacher verwenden.Warum direkte Übergänge langsamer sein können
In der Zustandsmaschine durchlaufen wir viel Code, so dass (erwartet) viele Fehlvorhersagen für Zweige auftreten werden. Lassen Sie uns ein "Profiling" gemäß der Vorhersage von Verzweigungsfehlern durchführen:perf record -e branch-misses -g ./http_benchmark
406 states: switch - 38% on switch(),
direct jumps - 13% on header value parsing
7,27 states: switch - <18% switch(), up to 40% for()
direct jumps – up to 46% on header & URI parsing
Auf einer großen Zustandsmaschine mit 406 Zuständen verbringen wir 38% der Zeit mit der Verarbeitung von Übergängen in switch. Auf einer Zustandsmaschine mit direkten Übergängen sind Hotspots Zeilenanalyse. Das Parsen einer Zeichenfolge in jedem Status umfasst das Überprüfen der Bedingung am Ende der Zeichenfolge: Die Bedingung forin der Statusmaschine ist aktiviert switch.perf stat -e L1-icache-load-misses ./http_benchmark
Switch-driven automaton Goto-driven automaton
big FSM code size: 29156 49202
L1-icache-load-misses: 4M 2M
Als nächstes betrachten wir die Profilerstellung beider Arten von Zustandsmaschinen nach Ereignissen, bei denen der Befehls-Cache des L1-Befehls fehlschlägt - fast 30 Kilobyte für switchund 50 Kilobyte für direkte Sprünge (mehr als der Cache der Befehle der ersten Ebene).Es scheint, dass, wenn wir nicht in den Cache passen, es für eine solche Zustandsmaschine viele Cache-Fehler geben sollte. Aber nein, sie sind 2 mal weniger. Das liegt daran, dass der Cache besser funktioniert: Wir arbeiten nacheinander mit dem Code und schaffen es, Daten aus den älteren Caches abzurufen.Der Compiler ändert die Reihenfolge des Codes
Wenn wir den Code der Zustandsmaschine programmieren go to, haben wir zuerst die Zustände, die zuerst aufgerufen werden, wenn die Daten empfangen werden: die HTTP-Methode, den URI und dann die HTTP-Header. Es erscheint logisch, dass der Code nacheinander von oben nach unten in den Prozessor-Cache geladen wird, während wir die Daten durchgehen. Das ist aber völlig falsch. Wenn Sie sich den Assembler-Code ansehen, werden Sie erstaunliche Dinge sehen. Links haben wir programmiert: Zuerst analysieren wir die Methoden
Links haben wir programmiert: Zuerst analysieren wir die Methoden GETund POSTdann irgendwo weit unterhalb der unwahrscheinlichen Methode UNLOCK. Daher erwarten wir das Parsen GETund am Anfang des Assemblers POSTund dann UNLOCK. Aber alles ist genau das Gegenteil: GETin der Mitte, POSTam Ende und UNLOCKdarüber.Dies liegt daran, dass der Compiler nicht versteht, wie Daten zu uns kommen. Er verteilt den Code gemäß seinem Bild von schönem Code. Damit er den Code in der richtigen Reihenfolge anordnen kann, müssen wir die Compiler-Barriere verwenden .Die Compiler-Barriere ist ein Assembly-Dummy, über den der Compiler nicht neu anordnet. Durch die einfache Platzierung solcher Barrieren haben wir die Produktivität um 4% verbessert .STATE(sw_method) {
...
MATCH(NGX_HTTP_GET, "GET ");
MATCH(NGX_HTTP_POST, "POST");
__asm__ __volatile__("": : :"memory");
...
METH_MOVE(Req_MethU, 'N', Req_MethUn);
METH_MOVE(Req_MethUn, 'L', Req_MethUnl);
METH_MOVE(Req_MethUnl, 'O', Req_MethUnlo);
METH_MOVE(Req_MethUnlo, 'C', Req_MethUnloc);
METH_MOVE_finish(Req_MethUnloc, 'K', NGX_HTTP_UNLOCK)
Verfassen Sie den Code auf Ihre eigene Weise
Da der Compiler die Daten nicht wie gewünscht anordnet, führen wir eine profilergesteuerte Optimierung durch (Optimierung unter der Kontrolle des Profilers). Profiler Guided Optimization (PGO) ist die Gesamtzahl der Stichproben, keine Folge von Aufrufen. Ein URI empfängt beispielsweise mehr Stichproben als eine Methodenanalyse, sodass der URI-Verarbeitungscode vor der Verarbeitung der Methode positioniert wird.Wie es funktioniert? Wir werden den Code schreiben, Benchmarks ausführen, das Ergebnis der Profilerstellung an den Compiler weitergeben und den optimalen Code für unsere Ladevorgänge generieren. Das Problem ist jedoch, dass einfach die heißesten Codeabschnitte kompiliert werden, die Zeitabhängigkeit jedoch nicht verfolgt wird. Wenn der größte URI in der Last ist, ist dies der heißeste Ort. Der URI steigt an die Spitze der Funktion, und PGO zeigt nicht an, dass der Methodenname immer vor dem URI steht. Dementsprechend funktioniert PGO nicht.Req_Method: {
if (likely(PI(p) == CHAR4_INT('G', 'E', 'T', ' '))) {
...
goto Req_Uri;
}
if (likely(PI(p) == CHAR4_INT('P', 'O', 'S', 'T'))) {
...
goto Req_UriSpace;
}
goto Req_Meth_SlowPath;
}
...
Req_Uri:
...
Req_Meth_SlowPath:
...
Was funktioniert?likely/ unlikely macros (für Linux-Kernel-Code sind GCC-Intrinsics im Benutzerbereich verfügbar __builtin_expect()). Sie sagen, welcher Code näher platziert werden soll. Beispielsweise wird wahrscheinlich berichtet, dass der Anforderungshauptteil unmittelbar dahinter sein sollte if. Wenn Sie dann den Code vorab abrufen (indem Sie den Prozessor vorab abrufen), wird dieser Code ausgewählt, und alles ist schnell. Das Bild zeigt den Beginn der Parsing-Methode, das Ende und die Barriere. Wir hatten nicht erwartet, den Code hinter der Barriere zu sehen. Es scheint, dass dies nicht sein sollte - wir haben eine Barriere errichtet.Aber was passiert in der Realität? Der Compiler sieht die
Das Bild zeigt den Beginn der Parsing-Methode, das Ende und die Barriere. Wir hatten nicht erwartet, den Code hinter der Barriere zu sehen. Es scheint, dass dies nicht sein sollte - wir haben eine Barriere errichtet.Aber was passiert in der Realität? Der Compiler sieht die likelyBedingung - es ist sehr wahrscheinlich, dass wir in den Hauptteil der Bedingung eintreten und dort zu einem bedingungslosen Sprung zum Label wechselnReq_Uri. Es stellt sich heraus, dass der Code, der nach unserem Zustand liegt, nicht im "Hot Path" verarbeitet wird. Der Compiler verschiebt den Code iftrotz der Barriere unter das Etikett dahinter , da die Hot-Code-Bedingung erfüllt ist.Dazu hat GCC keine Erweiterung: die Attribute hotund coldfür die Labels. Sie sagen, welches Etikett heiß (am wahrscheinlichsten) und welches kalt (weniger wahrscheinlich) ist. Hier sind wir uns einig, was
Hier sind wir uns einig, was GETwahrscheinlicher ist POSTund überlassen es ihm likely. Unter dieser Bedingung steigt die URI-Verarbeitung an und POSTsinkt. Alle anderen Codes für die Zustandsmaschine mit der geringsten Wahrscheinlichkeit bleiben unten, da das Etikett kalt ist.Mehrdeutig -O3
Schauen wir uns die Compiler-Optimierung an. Das erste, was mir in den Sinn kommt, ist, nicht O2, sondern O3 zu verwenden - es sollte schneller sein. Dies ist jedoch nicht der Fall - O3 generiert manchmal schlechteren Code. O3 ist eine Sammlung einiger Optimierungen . Wenn wir sie separat zu O2 hinzufügen, erhalten wir verschiedene Optionen: Einige Optimierungen helfen, andere stören. Für unseren spezifischen Code wählen wir nur die Optimierungen aus, die den Code besser generieren. Wir hinterlassen das beste Ergebnis - hier sind 1.820 Sekunden relativ zu 1.838 und 1.858.Einige Optionen sind grün hervorgehoben - dies ist die automatische Vektorisierung.
O3 ist eine Sammlung einiger Optimierungen . Wenn wir sie separat zu O2 hinzufügen, erhalten wir verschiedene Optionen: Einige Optimierungen helfen, andere stören. Für unseren spezifischen Code wählen wir nur die Optimierungen aus, die den Code besser generieren. Wir hinterlassen das beste Ergebnis - hier sind 1.820 Sekunden relativ zu 1.838 und 1.858.Einige Optionen sind grün hervorgehoben - dies ist die automatische Vektorisierung.Autovektorisierung
Ein Beispiel für einen Zyklus aus dem GCC-Handbuch .int a[256], b[256], c[256];
void foo () {
for (int i = 0; i < 256; i++)
a[i] = b[i] + c[i];
}
Wenn wir ein variables Array haben, das sich wiederholt, können wir den Zyklus optimieren - in Vektoren zerlegen. Standardmäßig ist die automatische Vektorisierung auf der dritten Optimierungsebene aktiviert. -O3 : GCC generiert Vektorcode, wo dies möglich ist. Es kann jedoch nicht der gesamte Code automatisch vektorisiert werden (auch wenn er im Prinzip vektorisiert ist).Wir können die GCC-Option aktivieren -fopt-info-vec-all, die zeigt, was vektorisiert wurde und was nicht. Wir bekommen, dass für unseren Benchmark nichts vektorisiert ist, aber der Code immer noch schlechter generiert wird. Daher funktioniert die Vektorisierung nicht immer: Manchmal verlangsamt sie den Code. Aber wir können immer sehen, was vektorisiert wurde und was nicht, und die Vektorisierung gegebenenfalls deaktivieren.Ausrichtung: Wie vergleiche ich einen String mit GET?
Wir machen einen kleinen Hack wie in Nginx: Wir analysieren Zeilen nicht nach Bytes, sondern berechnen intund vergleichen Zeilen mit ihnen.#define CHAR4_INT(a, b, c, d) ((d << 24) | (c << 16) | (b << 8) | a)
if (p == CHAR4_INT('G', 'E', 'T', ' ')))
Wir wissen, dass es int2-3 Mal langsamer wird , wenn es nicht ausgerichtet ist. Wir haben einen kleinen Benchmark geschrieben , der dies beweist.$ ./int_align
Unaligned access = 6.20482
Aligned access = 2.87012
Read four bytes = 2.45249
Versuchen Sie dann auszurichten int. Wir werden schauen, ob die Adresse intausgerichtet ist, und dann mit intBytes vergleichen , wenn nicht. (((long)(p) & 3)
? ((unsigned int)((p)[0]) | ((unsigned int)((p)[1]) << 8)
| ((unsigned int)((p)[2]) << 16) | ((unsigned int)((p)[3]) << 24))
: *(unsigned int *)(p));
Es stellt sich jedoch heraus, dass dieser Ansatz schlechter funktioniert:full request line: no difference
method only: unaligned - 214ms
aligned - 231ms
bytes - 216ms
Kurz gesagt: Es gibt einen Unterschied zwischen dem isolierten, nicht optimierbaren Benchmark-Code und dem Inline-Parser-Code, der aufgrund der großen Codemenge seine Optimierung verliert. Es gab keine Strafe bei der Profilerstellung.Hinweis: Eine ausführliche Beschreibung, warum dies in unserer Aufgabe geschieht, finden Sie auf GitHub .Warum sind HTTP-Strings für uns wichtig?
Dies ist beispielsweise eine normale URI: Wenn Sie in Bezug auf das Hotel wählerisch genug sind, gehen Sie zu Buchung und stellen Sie einige Filter ein. Erhalten Sie eine URI von mehr als einem Kilobyte.Nginx hat eine ziemlich massive Parsing-Maschine auf
Wenn Sie in Bezug auf das Hotel wählerisch genug sind, gehen Sie zu Buchung und stellen Sie einige Filter ein. Erhalten Sie eine URI von mehr als einem Kilobyte.Nginx hat eine ziemlich massive Parsing-Maschine auf switch/ case. Es funktioniert nicht sehr schnell. Darüber hinaus müssen wir im Fall von Tempesta FW den URI nicht nur analysieren, sondern auch auf Injektionen überprüfen.case sw_check_uri:
if (usual[ch >> 5] & (1U << (ch & 0x1f)))
break;
switch (ch) {
case '/':
r->uri_ext = NULL;
state = sw_after_slash_in_uri;
break;
case '.':
r->uri_ext = p + 1;
break;
case ' ':
r->uri_end = p;
state = sw_check_uri_http_09;
break;
case CR:
r->uri_end = p;
r->http_minor = 9;
state = sw_almost_done;
break;
case LF:
r->uri_end = p;
r->http_minor = 9;
goto done;
case '%':
r->quoted_uri = 1;
...
Ein weiterer URI: /redir_lang.jsp?lang=foobar%0d%0aContent-Length:%200%0d%0a% 0d% 0aHTTP / 1.1% 20200% 20OK% 0d% 0aContent-Type:% 20text /html% 0d% 0aContent -Länge:% 2019% 0d% 0a% 0d% 0aShazam </html>.Es sieht aus wie das erste, hat aber eine Injektion. Sie müssen tief genug graben, um dies zu verstehen.Lassen Sie uns einen Test durchführen : Nehmen Sie den ersten URI, geben Sie wrk ein, setzen Sie ihn auf nginx und sehen Sie, dass das Parsen von nginx sehr heiß wird. Wenn bei der vorherigen regulären Indexabfrage klar war, dass sich der Parser bereits oben befindet, wird es hier noch heißer.
Wenn bei der vorherigen regulären Indexabfrage klar war, dass sich der Parser bereits oben befindet, wird es hier noch heißer.8.62% nginx [.] ngx_http_parse_request_line
2.52% nginx [.] ngx_http_parse_header_line
1.42% nginx [.] ngx_palloc
0.90% [kernel] [k] copy_user_enhanced_fast_string
0.85% nginx [.] ngx_strstrn
0.78% libc-2.24.so [.] _int_malloc
0.69% nginx [.] ngx_hash_find
0.66% [kernel] [k] tcp_recvmsg
Was ist das Besondere an HTTP-Strings? Es gibt verschiedene Trennzeichen ' : 'und ' , 'sogar das Ende der Zeilen, die entweder Doppelbyte \r\noder Einzelbyte sein können \n, was zu Beginn erläutert wurde. Es gibt keine 0-Terminierung von C-Leitungen - aus Sicherheitsgründen möchten wir genauer prüfen, was zu uns kommt. Wir haben zwei Standardfunktionen, die im Parser helfen.strspn: Überprüft das Alphabet, verfügbare Zeichen in einer Zeichenfolge, kompiliert dynamisch ein gültiges Alphabet, obwohl es zum Zeitpunkt der Kompilierung des Programms bekannt ist.strcasecmp(). Es besteht keine Notwendigkeit zu konvertieren Fall zu vergleichen xmit Foo:. In den meisten Fällen strcasecmp()ist nur Compliance / Non-Compliance erforderlich, und Sie müssen die Position in der Leitung nicht kennen.
Sie arbeiten langsam. Lassen Sie uns die Benchmarks sehen und verstehen, was mit ihnen nicht stimmt.Schnelle Parser
Es gibt mehrere Parser.Nginx ist der einfachste Parser, Parser. Er überprüft streng die RFC-Konformität. Es gibt auch PicoHTTPParser (H2O) - und Cloudflare-Parser. Sie verarbeiten Daten schneller, überspringen jedoch möglicherweise Zeichen , die vom RFC nicht zugelassen werden.PCMESTRI. Parser verwenden verschiedene Ansätze. Der erste ist der PCMESTRI-Befehl, der im Pico-Parser verwendet wird.Wir legen Bereiche in der Anleitung fest. Leider können wir entweder 16 Zeichen oder 8 Bereiche laden. Wenn der Bereich nur aus einem Zeichen besteht, wiederholen Sie einfach. Aufgrund dieser Einschränkung kann der Pico-Parser die RFC-Konformität nicht vollständig überprüfen, da der RFC an diesem Speicherort mehr als 8 Bereiche aufweist. Wir laden das Alphabet in das Register, laden die Zeichenfolge und führen die Anweisung aus. Am Ausgang sehen wir schnell, ob es einen Zufall gibt oder nicht.AVX2 - CloudFlare-Ansatz. Der CloudFlare-Parser verarbeitet mit AVX2 jeweils 32 Byte einer Zeichenfolge anstelle von 16 Byte mit einem Pico-Parser. Das Parsen ist bei CloudFlare besser, da es auf AVX2 übertragen wurde.
Wir laden das Alphabet in das Register, laden die Zeichenfolge und führen die Anweisung aus. Am Ausgang sehen wir schnell, ob es einen Zufall gibt oder nicht.AVX2 - CloudFlare-Ansatz. Der CloudFlare-Parser verarbeitet mit AVX2 jeweils 32 Byte einer Zeichenfolge anstelle von 16 Byte mit einem Pico-Parser. Das Parsen ist bei CloudFlare besser, da es auf AVX2 übertragen wurde. Wir überprüfen alle Zeichen auf ein Leerzeichen in der ASCII-Tabelle, alle Zeichen sind größer als 128 und nehmen den Bereich zwischen ihnen. Einfacher Code ist schnell.Vergleichen Sie PCMESTRI und AVX2. Für uns liegt das aktuelle Limit bei 1500. Dies ist die maximale Paketgröße, die zu uns kommt. Wir sehen, dass der AVX2-Code für Big Data viel schneller ist als der Pico-Parser. Bei kleinen Datenmengen funktioniert es jedoch langsamer, da die Anweisungen in AVX2 schwerer sind.
Wir überprüfen alle Zeichen auf ein Leerzeichen in der ASCII-Tabelle, alle Zeichen sind größer als 128 und nehmen den Bereich zwischen ihnen. Einfacher Code ist schnell.Vergleichen Sie PCMESTRI und AVX2. Für uns liegt das aktuelle Limit bei 1500. Dies ist die maximale Paketgröße, die zu uns kommt. Wir sehen, dass der AVX2-Code für Big Data viel schneller ist als der Pico-Parser. Bei kleinen Datenmengen funktioniert es jedoch langsamer, da die Anweisungen in AVX2 schwerer sind. Vergleichbar mit
Vergleichbar mitstrspn. Wenn wir uns für die Verwendung entscheiden, strspnwird es schlimmer, insbesondere bei Big Data. Im "Kampf" kann der Parser nicht verwendet werden strspn.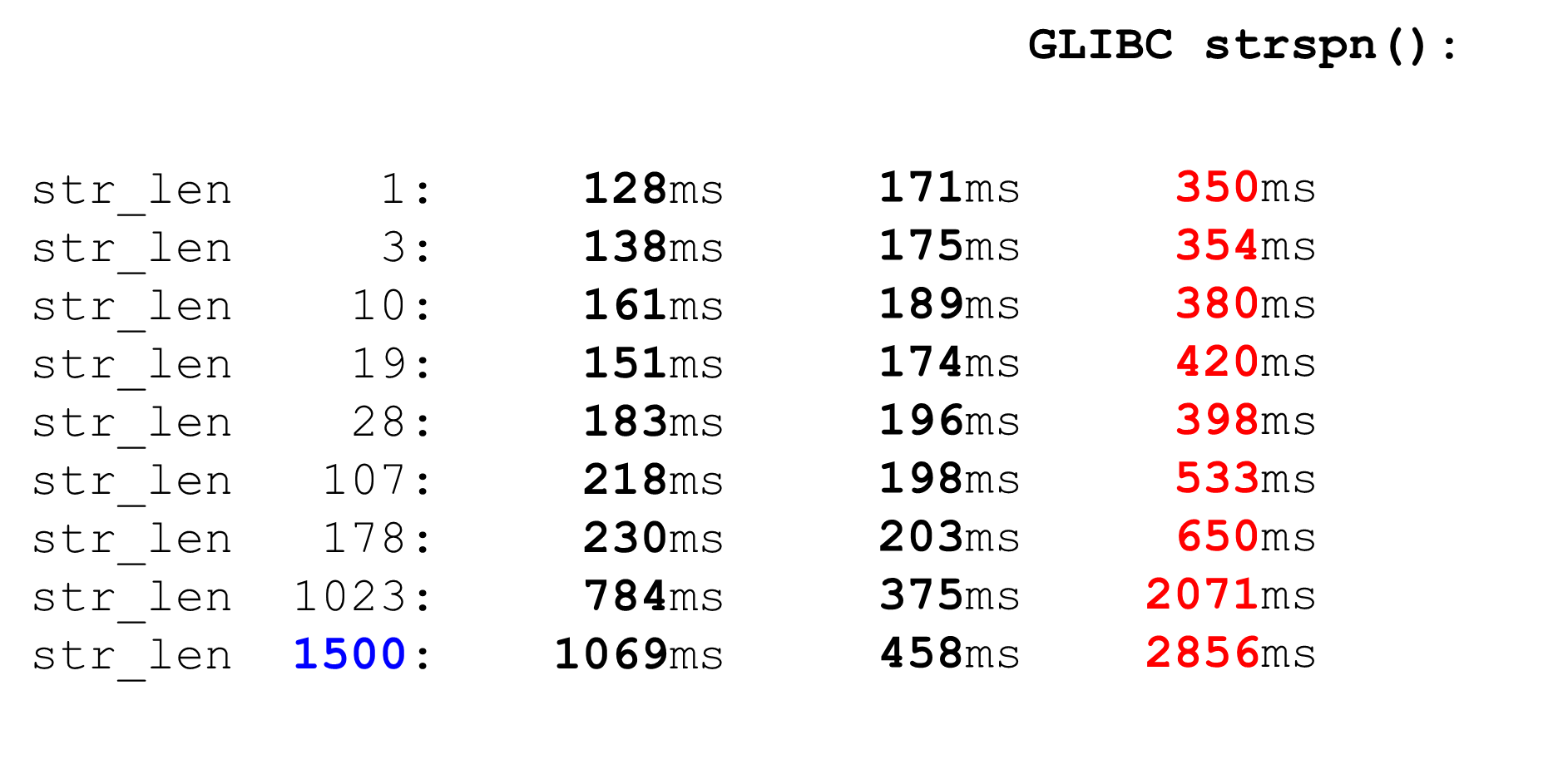
Tempesta Matcher ist schneller und genauer
Unser Speed Parser ist wie diese beiden. Bei kleinen Daten ist es so schnell wie ein Pico-Parser, bei großen CloudFlare. Es werden jedoch keine ungültigen Zeichen übersprungen. Wie ist der Parser angeordnet? Wir definieren als nginx ein Array von Bytes und überprüfen die Eingabedaten damit - dies ist der Prolog der Funktion. Hier arbeiten wir nur mit kurzen Begriffen, wir verwenden
Wie ist der Parser angeordnet? Wir definieren als nginx ein Array von Bytes und überprüfen die Eingabedaten damit - dies ist der Prolog der Funktion. Hier arbeiten wir nur mit kurzen Begriffen, wir verwenden likelysie, weil die Fehlvorhersage von Zweigen für kurze Zeilen schmerzhafter ist als für lange. Wir nehmen diesen Code auf. Wir haben wegen der letzten Zeile ein Limit von 4 - wir müssen eine ziemlich starke Bedingung schreiben. Wenn wir mehr als 4 Bytes verarbeiten, ist die Bedingung schwieriger und der Code langsamer.static const unsigned char uri_a[] __attribute__((aligned(64))) = {
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
...
if (likely(len <= 4)) {
switch (len) {
case 0:
return 0;
case 4:
c3 = uri_a[s[3]];
case 3:
c2 = uri_a[s[2]];
case 2:
c1 = uri_a[s[1]];
case 1:
c0 = uri_a[s[0]];
}
return (c0 & c1) == 0 ? c0 : 2 + (c2 ? c2 + c3 : 0);
}
Hauptschleife und großer Schwanz. Im Hauptverarbeitungszyklus teilen wir die Daten auf: Wenn sie lang genug sind, verarbeiten wir jeweils 128, 64, 32 oder 16 Bytes. Es ist sinnvoll, jeweils 128 zu verarbeiten: Parallel dazu verwenden wir mehrere Prozessorkanäle (mehrere Pipelines) und einen superskalaren Prozessor.for ( ; unlikely(s + 128 <= end); s += 128) {
n = match_symbols_mask128_c(__C.URI_BM, s);
if (n < 128)
return s - (unsigned char *)str + n;
}
if (unlikely(s + 64 <= end)) {
n = match_symbols_mask64_c(__C.URI_BM, s);
if (n < 64)
return s - (unsigned char *)str + n;
s += 64;
}
if (unlikely(s + 32 <= end)) {
n = match_symbols_mask32_c(__C.URI_BM, s);
if (n < 32)
return s - (unsigned char *)str + n;
s += 32;
}
if (unlikely(s + 16 <= end)) {
n = match_symbols_mask16_c(__C.URI_BM128, s);
if (n < 16)
return s - (unsigned char *)str + n;
s += 16;
}
Schwanz. Das Ende der Funktion ähnelt dem Anfang. Wenn wir weniger als 16 Bytes haben, verarbeiten wir 4 Bytes in einer Schleife und am Ende nicht mehr als 3 Bytes.while (s + 4 <= end) {
c0 = uri_a[s[0]];
c1 = uri_a[s[1]];
c2 = uri_a[s[2]];
c3 = uri_a[s[3]];
if (!(c0 & c1 & c2 & c3)) {
n = s - (unsigned char *)str;
return !(c0 & c1) ? n + c0 : n + 2 + (c2 ? c2 + c3 : 0);
}
s += 4;
}
c0 = c1 = c2 = 0;
switch (end - s) {
case 3:
c2 = uri_a[s[2]];
case 2:
c1 = uri_a[s[1]];
case 1:
c0 = uri_a[s[0]];
}
n = s - (unsigned char *)str;
return !(c0 & c1) ? n + c0 : n + 2 + c2;
Wir laden Bitmasken und Daten - dies ist der Hauptalgorithmus des Hauptteils der Funktion. Wir präsentieren eine ASCII-Tabelle (wie im Bild) mit 16 Zeilen und 8 Spalten. Zuerst codieren wir unsere Tabellenzeilen im ersten Register des BM-URI: der ersten und zweiten Zeile.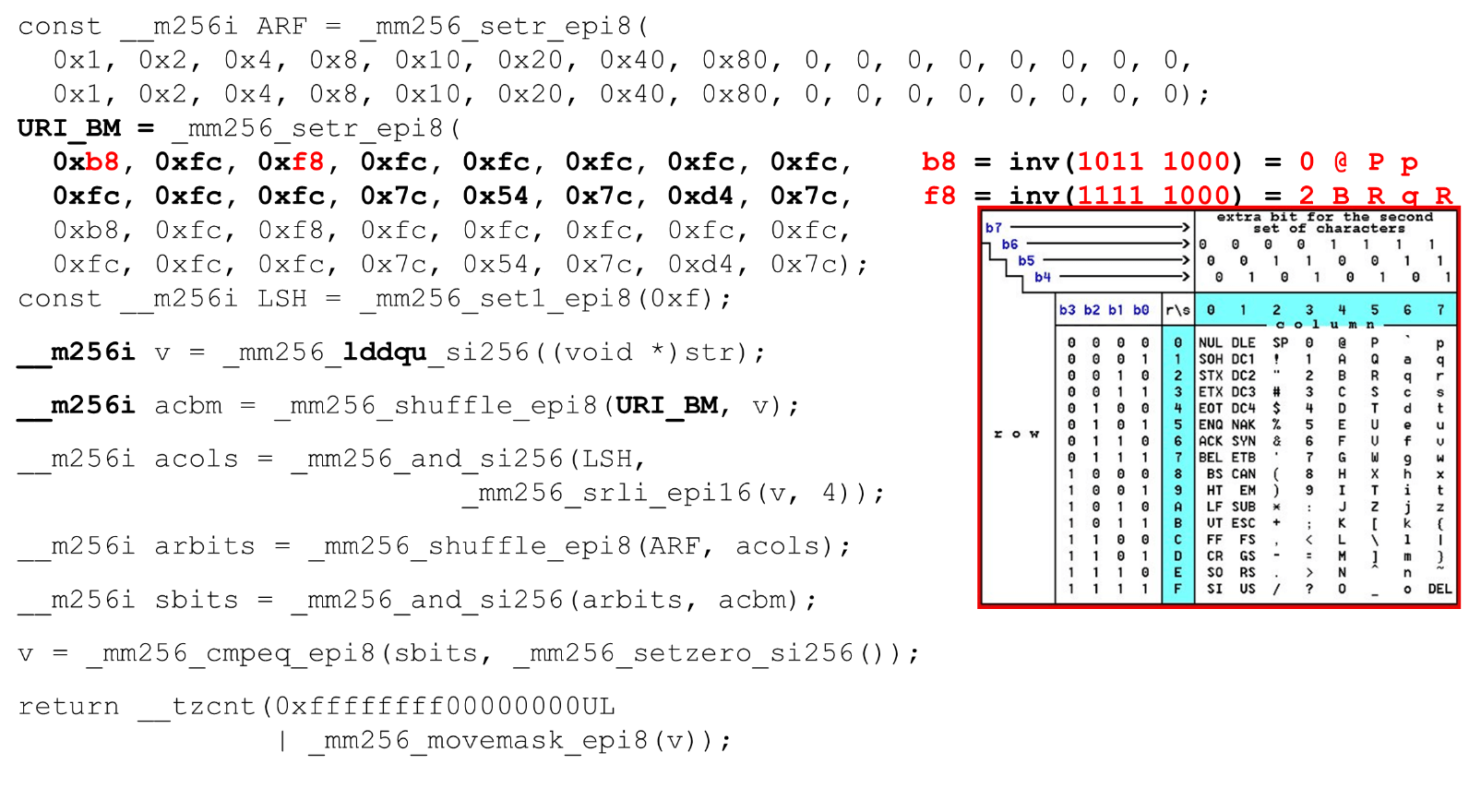 Die tatsächlichen Symbole, die wir zulassen, sind
Die tatsächlichen Symbole, die wir zulassen, sind 0 @ P pund 2 B R q R. Sie sind wie folgt codiert: b8 = inv(1011 1000) = 0 @ P p, f8 = inv(1111 1000) = 2 B R q R.Wir codieren in umgekehrter Reihenfolge: Wir beginnen bei 0, das erste Dienstzeichen ist nicht zulässig, und dann sind Einheiten zulässig.Legen Sie die ASCII-Bitmasken fest. Zum Beispiel kommt eine Zeile herein "pr": Das erste Zeichen aus der ersten Zeile ist ASCII, das zweite aus der zweiten Zeile. Wir führen die shuffle-Anweisung aus, die unsere codierten Tabellenzeilen in der Reihenfolge dieser Zeichen in der Eingabe mischt. Spalten-ID für die Eingabe. Als nächstes platzieren wir die Spalten der ASCII-Tabelle in einem anderen Register. Dann „kreuzen“ wir die Register von Spalten und Zeilen und erhalten eine Entsprechung: unser Charakter oder nicht.Da die Spalten die höchstwertigen 4 Bits vom Byte sind, verschieben wir uns nach links. AVX hat einen Offset von nur 2 Bytes. Verschieben Sie also zuerst das Byte und dann n mit unserer Maske, um nur signifikante Bits zu erhalten.
Spalten-ID für die Eingabe. Als nächstes platzieren wir die Spalten der ASCII-Tabelle in einem anderen Register. Dann „kreuzen“ wir die Register von Spalten und Zeilen und erhalten eine Entsprechung: unser Charakter oder nicht.Da die Spalten die höchstwertigen 4 Bits vom Byte sind, verschieben wir uns nach links. AVX hat einen Offset von nur 2 Bytes. Verschieben Sie also zuerst das Byte und dann n mit unserer Maske, um nur signifikante Bits zu erhalten. Anordnen von ASCII-Spalten Führen Sie den zweiten Shuffle aus und bewegen Sie die Spalte an die gewünschten Positionen. In beiden Fällen das Eingabebyte aus der letzten Spalte, sodass wir an der ersten und zweiten Position dieselbe Spalte erhalten.
Anordnen von ASCII-Spalten Führen Sie den zweiten Shuffle aus und bewegen Sie die Spalte an die gewünschten Positionen. In beiden Fällen das Eingabebyte aus der letzten Spalte, sodass wir an der ersten und zweiten Position dieselbe Spalte erhalten.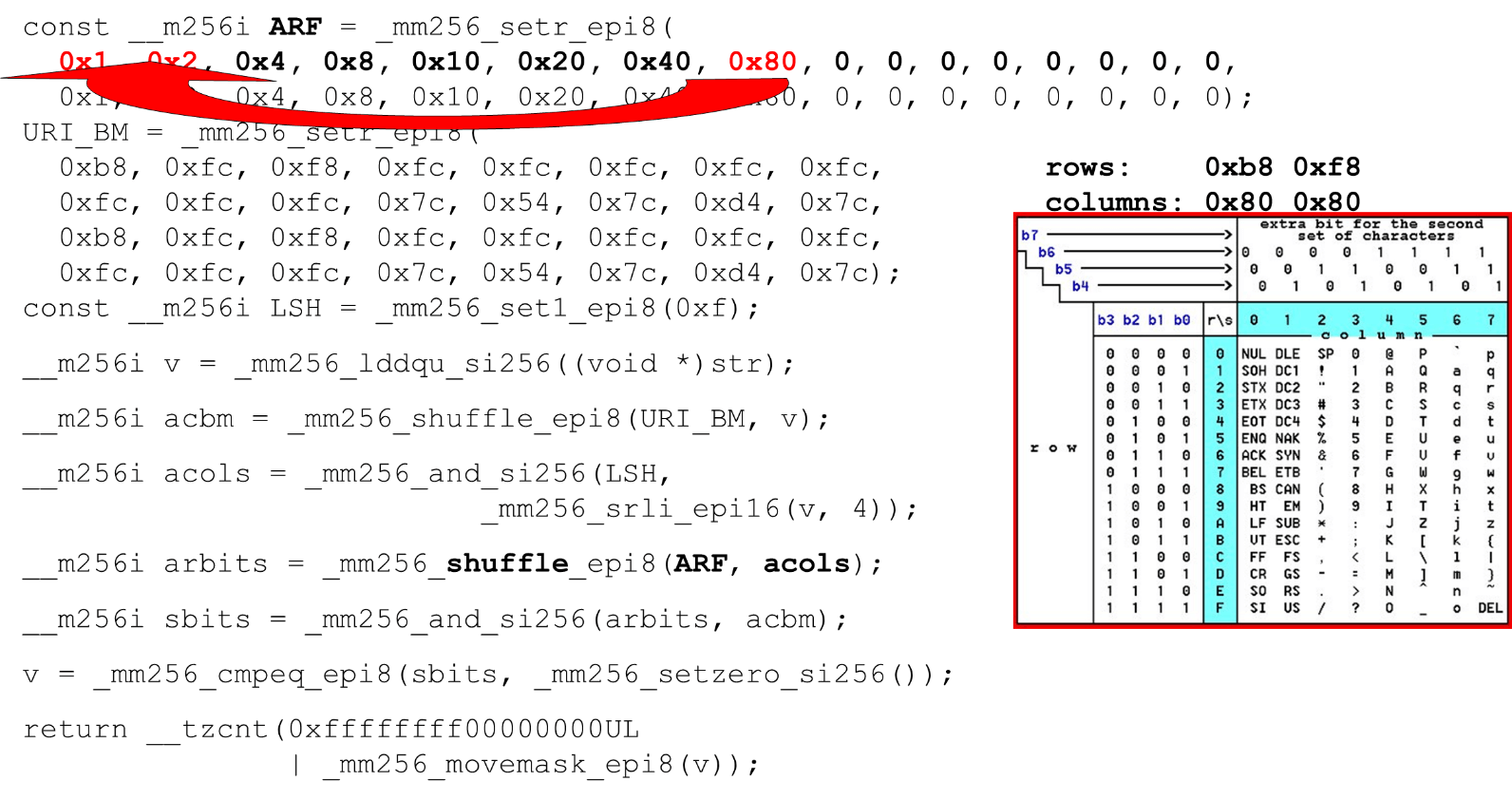 Schnittpunkt von Spalten und Zeilen von Masken . Wir tun dies
Schnittpunkt von Spalten und Zeilen von Masken . Wir tun dies and("kreuzen" die Spalten mit Spalten) und wir erhalten, dass die Eingabedaten gültig sind - das Ergebnisandvom Schnittpunkt von Spalten und Zeilen ist nicht Null. Zählen Sie die Anzahl der Nullen am Ende. Wir sammeln alles aus dem Vektor in
Zählen Sie die Anzahl der Nullen am Ende. Wir sammeln alles aus dem Vektor in intund geben es an die Ausgabe zurück - ganz einfach.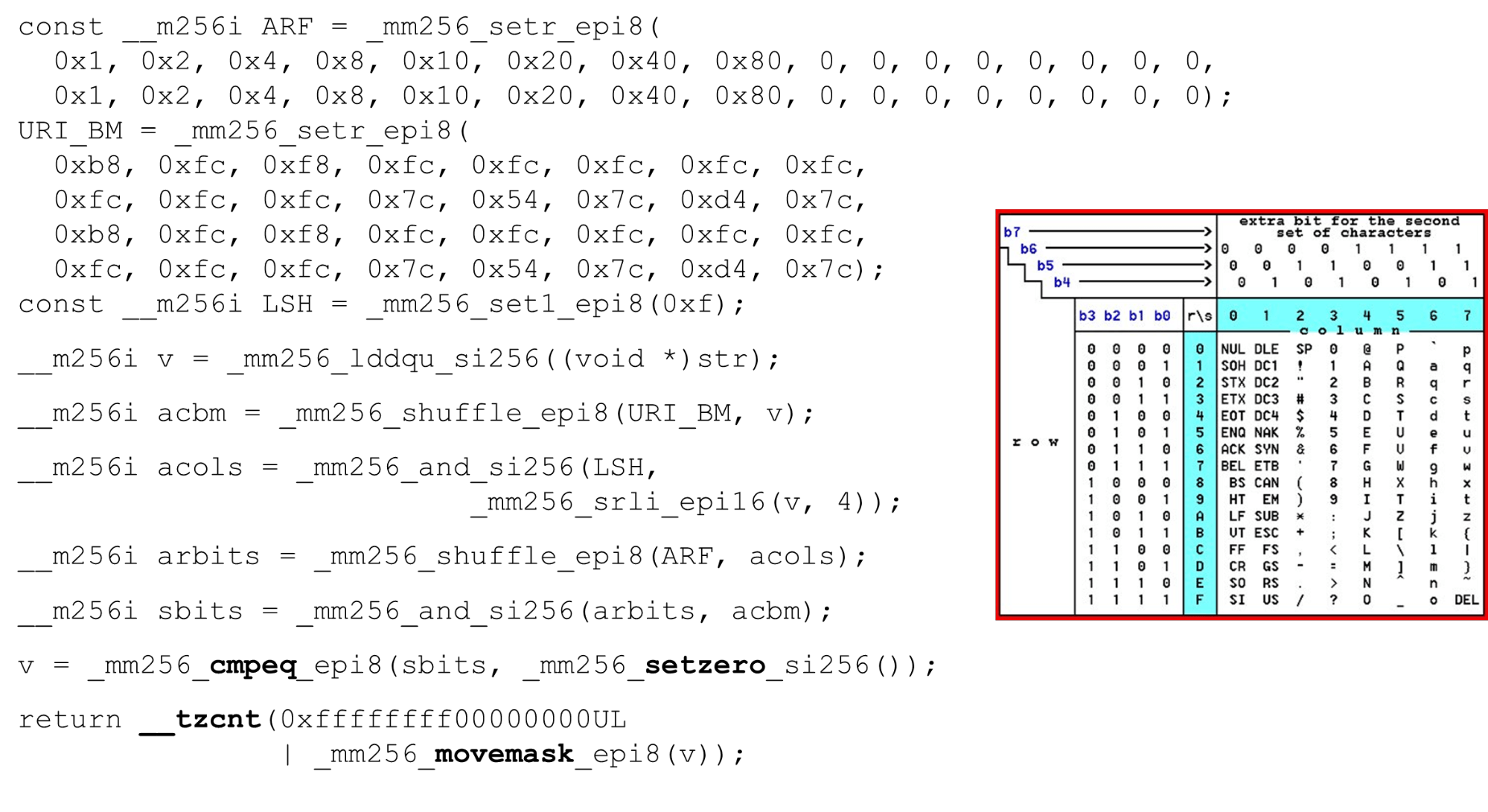 Passen Sie die Alphabete an. Wenn wir mit der ASCII-Tabelle arbeiten, erhalten wir eine günstige Funktion: Wir verwenden statische Tabellen, aber nichts hindert uns daran, den Benutzer zu fragen, welches Alphabet für URIs, Namen und Werte verschiedener Header verfügbar ist. Die HTTP-URI-Anforderung und der Header verwenden 8 Alphabete (Plus oder Minus), um eine HTTP-Anforderung zu analysieren. Diese Tabellen können in denselben Code geladen und in einem vom Benutzer angegebenen Alphabet, einem gültigen URI, verglichen werden . Wenn nicht, ist es anders.
Passen Sie die Alphabete an. Wenn wir mit der ASCII-Tabelle arbeiten, erhalten wir eine günstige Funktion: Wir verwenden statische Tabellen, aber nichts hindert uns daran, den Benutzer zu fragen, welches Alphabet für URIs, Namen und Werte verschiedener Header verfügbar ist. Die HTTP-URI-Anforderung und der Header verwenden 8 Alphabete (Plus oder Minus), um eine HTTP-Anforderung zu analysieren. Diese Tabellen können in denselben Code geladen und in einem vom Benutzer angegebenen Alphabet, einem gültigen URI, verglichen werden . Wenn nicht, ist es anders.Anschläge
Einige Fälle, in denen dies nützlich sein kann.SSRF-Angriff mit BlackHat'17 („Eine neue Ära der SSRF“): http://foo@evil.com:80@google.com/- Ein unwahrscheinliches kaufmännisches Und-Symbol. In einigen Anwendungen wird es verwendet, in anderen nicht. Wenn Sie es jedoch nicht verwenden, können Sie es vom gültigen Alphabet ausschließen, und der Angriff wird blockiert.RCE-Angriff: «effektiv ist die Ausführung von Befehlsinjektionsangriffen wie», BSides'16 : User-Agent: ...;echo NAELBD$((26+58))$echo(echo NAELBD)NAELBD.... Der User-Agent ist ein statischer Header, es gibt jedoch Fälle eines RCE-Angriffs, wenn einige shellmit atypischen Zeichen für den User-Agent versehen sind. Wir schützen uns bis auf das Dollarzeichen.Relativer Pfad überschreiben . Der letzte Fall war der von Google im Jahr 2016. Geschweifte Klammern, Doppelpunkte, kamen zur URI .../gallery?q=%0a{}*{background:red}/..//apis/howto_guide.html. Dies sind unwahrscheinliche Zeichen, die aus dem Alphabet ausgeschlossen werden können.strcasecmp ()
Dies ist ein ziemlich trivialer Code. Wir vergleichen auch Zeichenfolgen mit 32 Bytes, jeweils zwei Arrays.__m256i CASE = _mm256_set1_epi8(0x20);
__m256i A = _mm256_set1_epi8('A' – 0x80);
__m256i D = _mm256_set1_epi8('Z' - 'A' + 1 – 0x80);
__m256i sub = _mm256_sub_epi8(str1, A);
__m256i cmp_r = _mm256_cmpgt_epi8(D, sub);
__m256i lc = _mm256_and_si256(cmp_r, CASE);
__m256i vl = _mm256_or_si256(str1, lc);
__m256i eq = _mm256_cmpeq_epi8(vl, str2);
return ~_mm256_movemask_epi8(eq);
Wir geben dem Register nur eine Zeile, weil wir in der zweiten die Konstanten in unserem Parser in Kleinbuchstaben programmiert haben. Da wir signifikante Vergleiche haben, subtrahieren wir 128 von jedem Byte (ein Trick von Hacker's Delight).Wir vergleichen auch den Bereich eines gültigen Zeichens: Ob wir uns für diese Zeichenfolge registrieren können oder nicht, ist es ein Buchstabe oder nicht. Zum Zeitpunkt der Überprüfung können wir anstelle von zwei Vergleichen von a bis z nur einen Vergleich verwenden (ein Trick von Hacker's Delight) und zu einer Konstanten wechseln.Leistung strcasecmp ()
Tempesta ist viel schneller als GLIBC, sogar die neue Version (18 oder 19). Der Code strcasecmp()verwendet auch AVX, jedoch nicht die zweite Version. AVX2 ist schneller, daher verfügt Tempesta über schnelleren Code.
Linux-Kernel-FPU
Wir verwenden Vektorprozessor-Erweiterungen - diese sind im Kernel verfügbar. Vektoranweisungen werden vom FPU-Prozessormodul verarbeitet. Dies ist nicht das Hauptprozessormodul, nicht die Hauptregister, aber ziemlich umfangreich.Daher gibt es unter Linux eine Optimierung. Wenn wir vom Kernel in den Benutzerbereich und zurück wechseln, speichern wir nicht den Kontext der FPU-Register (XMM, YMM, ZMM): Wir ändern nur den Kontext der Register des Hauptprozessormoduls. Es wird angenommen, dass der Betriebssystemkern nicht mit der Vektorerweiterung des Prozessors funktioniert. Wenn Sie es beispielsweise benötigen, kann die Kryptografie dies tun, muss jedoch den Kontext des FPU-Registers verwenden fpu_beginund fpu_endspeichern und wiederherstellen:__kernel_fpu_begin_bh();
memcpy_avx(dst, src, n);
__kernel_fpu_end_bh();
Hierbei handelt es sich um native Makros, die den Status des Prozessormoduls speichern und wiederherstellen , das für Vektorregister verantwortlich ist. Dies sind ziemlich langsame Ressourcen.AVX und SSE
Vor den Benchmarks zum Speichern und Wiederherstellen des FPU-Kontexts einige Worte zu Vektoroperationen. Warum ist es manchmal sinnvoll, mit Assembler zu arbeiten? Manchmal generiert GCC suboptimalen Code. Das Problem ist, dass bei älteren Prozessormodellen der Übergang von SSE zu AVX erhebliche Nachteile mit sich bringt. GCC hat einen neuen Schlüssel vzeroupper- verwenden Sie ihn, damit dieser Befehl nicht generiert wird vzeroupper, wodurch die Register gelöscht und diese Strafe beseitigt werden.Sie müssen diese Anweisung nur verwenden, wenn Sie mit altem Code arbeiten, der von einem Dritten für SSE kompiliert wurde. Dies ist nicht unser Fall und wir können diese Anweisungen sicher wegwerfen.FPU
Wir haben Auto-Vektorisierung im Prozessor. Dies bedeutet, dass in jedem Benutzerbereichscode Vektoroperationen vorhanden sind. Zwei beliebige Prozesse im System verwenden Vektorprozessorerweiterungen. Wenn Ihr Prozess zum Kernel und zurück wechselt, verschwenden Sie keine Zeit damit, den Vektorstatus des Prozessors zu sparen und wiederherzustellen. Wenn Sie jedoch von einem Benutzerbereich zu einem anderen wechseln (Kontextwechsel), funktioniert neben der Tatsache, dass dort Caches der ersten Ebene deaktiviert sind, auch das Kontextwechselmodul auf FPU begin / end schlecht. Die Operation ist ziemlich teuer - ein Mikrobenchmark.Bei Mikrobenchmarks ist immer alles dramatisch, aber die Operation ist sehr teuer. Wechseln Sie daher im Benutzerbereich den Kontext für eine lange Zeit. Im Kernel gibt es keine Kontextumschaltung, daher ist alles schnell. Wir speichern und stellen den Vektorprozessor nur einmal für einen ausreichend großen Satz von Paketen wieder her.
Zwei beliebige Prozesse im System verwenden Vektorprozessorerweiterungen. Wenn Ihr Prozess zum Kernel und zurück wechselt, verschwenden Sie keine Zeit damit, den Vektorstatus des Prozessors zu sparen und wiederherzustellen. Wenn Sie jedoch von einem Benutzerbereich zu einem anderen wechseln (Kontextwechsel), funktioniert neben der Tatsache, dass dort Caches der ersten Ebene deaktiviert sind, auch das Kontextwechselmodul auf FPU begin / end schlecht. Die Operation ist ziemlich teuer - ein Mikrobenchmark.Bei Mikrobenchmarks ist immer alles dramatisch, aber die Operation ist sehr teuer. Wechseln Sie daher im Benutzerbereich den Kontext für eine lange Zeit. Im Kernel gibt es keine Kontextumschaltung, daher ist alles schnell. Wir speichern und stellen den Vektorprozessor nur einmal für einen ausreichend großen Satz von Paketen wieder her.Intelpocalypse
Am Anfang habe ich eine Nachschlagetabellenoption zur Optimierung des Switch-Codes gezeigt: Ein langer Prozess, enum, kompiliere die Switch-Tabelle in ein Array und folge der doppelten Dereferenzierung des Zeigers, der über dieses Array springt. Dies ist ein Szenario für einen Spectre-Angriff, bei dem die spekulative Ausführung ausgenutzt wird.Google hat einen guten Artikel darüber, wie die doppelte Dereferenzierung von Zeigern in modernen Compilern derzeit (seit Anfang 2018) angeordnet ist. Es funktioniert nicht sehr gut. Wenn früher im Register eine Adresse gespeichert wurde und wir zu dieser Adresse gegangen sind, haben wir jetzt einen anderen Code.jmp *%r11
call l1
l0: pause
lfence
jmp l0
l1: mov %r11, (%rsp)
ret
Wie funktioniert es? Wir "rufen" die Funktion auf l1 auf, der Prozess geht zu diesem Label und wir machen einen Hack: als ob wir von einer Funktion zurückkehren (was nicht der Fall ist), aber wir schreiben die Rücksprungadresse neu. Wenn wir den Befehl ausführen call, platzieren wir die Rücksprungadresse, die aktuelle Adresse, auf dem Stapel, schreiben sie mit dem erforderlichen Inhalt des Registers neu und gehen zu l1. Aber der Prozessor sieht, wenn sein Prefetcher läuft, dass es eine Funktion und dann eine Barriere gibt. Dementsprechend wird alles langsam sein - es wirft das Prefetching aus und wir beseitigen die Spectre-Schwachstelle. Der Code ist langsam, die Leistung sinkt um 15%.Der nächste relativ neue Angriff ist Meltdown.. Es ist nur für User-Space-Prozesse spezifisch. Sehr schmerzhaft ist das Lesen des Kernelspeichers aus dem Benutzerbereich. Der Angriff wird durch die Kernel Pate Table Isolation (KPTI) verhindert, die standardmäßig in neuen Kerneln kompiliert wird. KPTI ist jedoch sehr teuer und führt zu einer Leistungsverschlechterung von bis zu 30-40% ( gemessen von MariaDB ).Dies liegt an der Tatsache, dass Sie keine verzögerte TLB-Optimierung mehr haben: Der Adressraum des Kernels und des Prozessors ist vollständig in verschiedenen Seitentabellen getrennt (zuvor hat der verzögerte TLB den Kernelraum der Seitentabelle jedes Prozesses zugeordnet). Dies ist schmerzhaft für den Benutzerbereich, nicht jedoch für Tempesta FW, das vollständig im Kernel funktioniert.Einige nützliche Links:Saint HighLoad++ . , 6 -- ( , Saint HighLoad++) , web .
PHP Russia: 13 , . — KnowledgeConf, ++ TechLead Conf — . , , .