Flant hat eine Reihe von Open Source-Entwicklungen, hauptsächlich für Kubernetes, und Loghouse ist eine der beliebtesten. Dies ist unser zentrales Protokollierungswerkzeug in K8s, das vor mehr als 2 Jahren eingeführt wurde. Wie wir kürzlich in einem Artikel über die Protokolle erwähnt haben , musste es verfeinert werden, und seine Relevanz nahm im Laufe der Zeit zu. Heute freuen wir uns, Ihnen eine neue Version von loghouse vorstellen zu können - v0.3.0 . Details über sie - unter dem Schnitt.
Wie wir kürzlich in einem Artikel über die Protokolle erwähnt haben , musste es verfeinert werden, und seine Relevanz nahm im Laufe der Zeit zu. Heute freuen wir uns, Ihnen eine neue Version von loghouse vorstellen zu können - v0.3.0 . Details über sie - unter dem Schnitt.Nachteile
Wir haben die ganze Zeit in vielen Kubernetes-Clustern Loghouse verwendet, und im Allgemeinen passt diese Lösung sowohl zu uns selbst als auch zu den verschiedenen Kunden, auf die wir auch Zugriff gewähren.Die Hauptvorteile sind die einfache und intuitive Benutzeroberfläche, die Fähigkeit, SQL-Abfragen auszuführen, die gute Komprimierung und der geringe Ressourcenverbrauch beim Einfügen von Daten in die Datenbank sowie der geringe Overhead während der Speicherung.Die schmerzhaftesten Probleme im Blockhaus während des Betriebs:- Verwendung von Partitionstabellen, die durch eine Zusammenführungstabelle verbunden sind;
- Fehlen eines Puffers, der Protokollstöße glätten würde;
- Veraltetes und potenziell gefährdetes Webpanel-Juwel
- veraltet fließend ( loghouse-fließend: spätestens wegen eines problematischen Gemset nicht gestartet).
Darüber hinaus hat sich auf GitHub eine beträchtliche Anzahl von Problemen angesammelt , die ich auch gerne lösen würde.Wesentliche Änderungen im Blockhaus 0.3.0
Tatsächlich haben wir genügend Änderungen gesammelt, aber wir werden die wichtigsten hervorheben. Sie können in 3 Hauptgruppen unterteilt werden:- Verbesserung der Protokollspeicherung und des Datenbankschemas;
- verbesserte Protokollsammlung;
- das Auftreten der Überwachung.
1. Verbesserungen bei der Protokollspeicherung und beim Datenbankdesign
Schlüsselinnovationen:- Die Protokollspeicherschemata wurden geändert, der Übergang zur Arbeit mit einer einzelnen Tabelle und die Ablehnung von Partitionstabellen wurden abgeschlossen .
- Der Grundreinigungsmechanismus in ClickHouse der neuesten Versionen gebaut hat damit begonnen , angewendet werden .
- Jetzt können Sie eine externe ClickHouse-Installation auch im Cluster-Modus verwenden.
Vergleichen Sie die Leistung der alten und neuen Schaltungen in einem realen Projekt. Hier ist ein Beispiel für die Suche nach eindeutigen URLs in den Anwendungsprotokollen der beliebten Online-Ressource dtf.ru :SELECT
string_fields.values[indexOf(string_fields.names, 'path')] AS path,
count(*) AS count
FROM logs
WHERE (namespace = 'kube-nginx-ingress') AND ((string_fields.values[indexOf(string_fields.names, 'vhost')]) LIKE '%foobar.baz%') AND (date = '2020-02-29')
GROUP BY string_fields.values[indexOf(string_fields.names, 'path')]
ORDER BY count DESC
LIMIT 20
Die Auswahl erfolgt über zig Millionen Datensätze. Das alte Schema hat in 20 Sekunden funktioniert: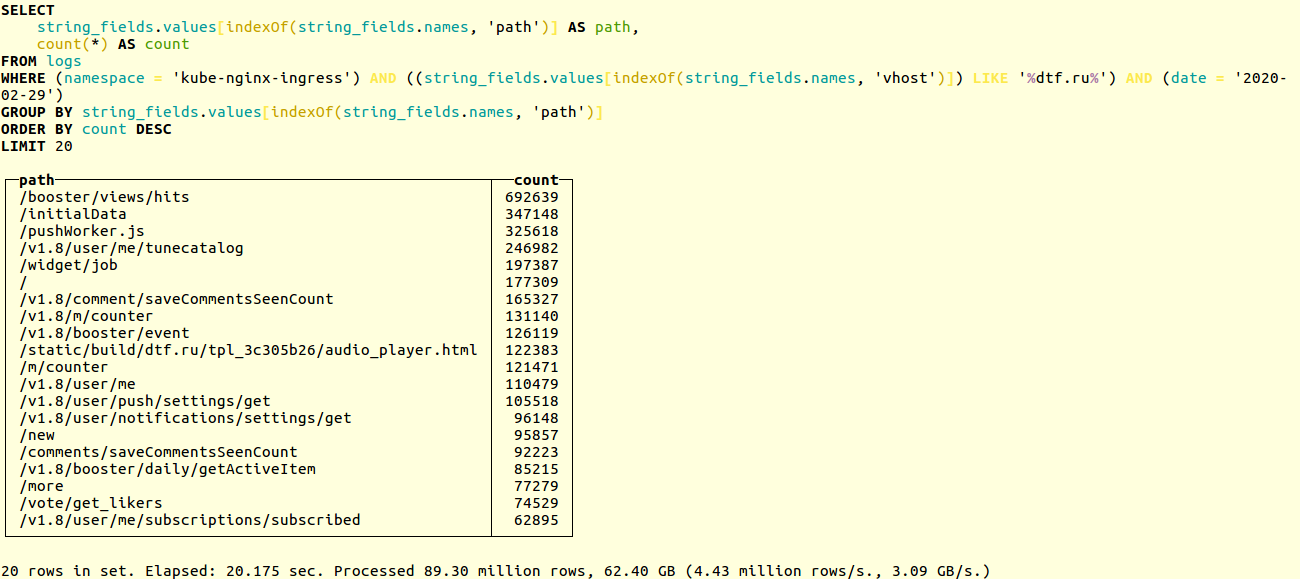 Neu - in 14:
Neu - in 14: Wenn Sie unser Helm-Diagramm verwenden , wird die Datenbank beim Aktualisieren des Blockhauses automatisch in das neue Format migriert. Andernfalls müssen Sie die Migration manuell durchführen. Der Vorgang ist in der Dokumentation beschrieben . Kurz gesagt, laufen Sie einfach:
Wenn Sie unser Helm-Diagramm verwenden , wird die Datenbank beim Aktualisieren des Blockhauses automatisch in das neue Format migriert. Andernfalls müssen Sie die Migration manuell durchführen. Der Vorgang ist in der Dokumentation beschrieben . Kurz gesagt, laufen Sie einfach:DO_DB_DEPLOY=true rake create_logs_tables
Darüber hinaus haben wir begonnen, TTL für ClickHouse-Tabellen zu verwenden . Auf diese Weise können Sie automatisch Daten aus der Datenbank löschen, die älter als das angegebene Zeitintervall sind:CREATE TABLE logs
(
....
)
ENGINE = MergeTree()
PARTITION BY (date)
ORDER BY (timestamp, nsec, namespace, container_name)
TTL date + toIntervalDay(14)
SETTINGS index_granularity = 32768;
Beispiele für Datenbankschemata und Konfigurationen für ClickHouse, einschließlich eines Beispiels für die Arbeit mit dem CH-Cluster, finden Sie in der Dokumentation .Verbesserte Protokollsammlung
Schlüsselinnovationen:- Es wurde ein Puffer hinzugefügt , der Bursts glättet, wenn eine große Anzahl von Protokollen angezeigt wird.
- Implementierung der Möglichkeit , Protokolle direkt von der Anwendung an das Loghouse zu senden : über TCP und UDP im JSON-Format.
Die Blockhausbatterie im Blockhaus ist eine neue Tabelle logs_buffer, die dem Datenbankschema hinzugefügt wurde. Diese Tabelle befindet sich im Speicher, d.h. im RAM gespeichert (hat einen speziellen Puffertyp ); Sie sollte die Last auf der Basis glätten. Vielen Dank für den Tipp zum Hinzufügen.Sovigod!Das implementierte Senden von Protokollen direkt von der Anwendung an loghouse ermöglicht es Ihnen, dies auch über netcat zu tun:echo '{"log": {"level": "info", "msg": "hello world"}}' | nc fluentd.loghouse 5170
Diese Protokolle können in dem Namespace angezeigt werden, in dem Loghouse im Stream installiert ist net: Die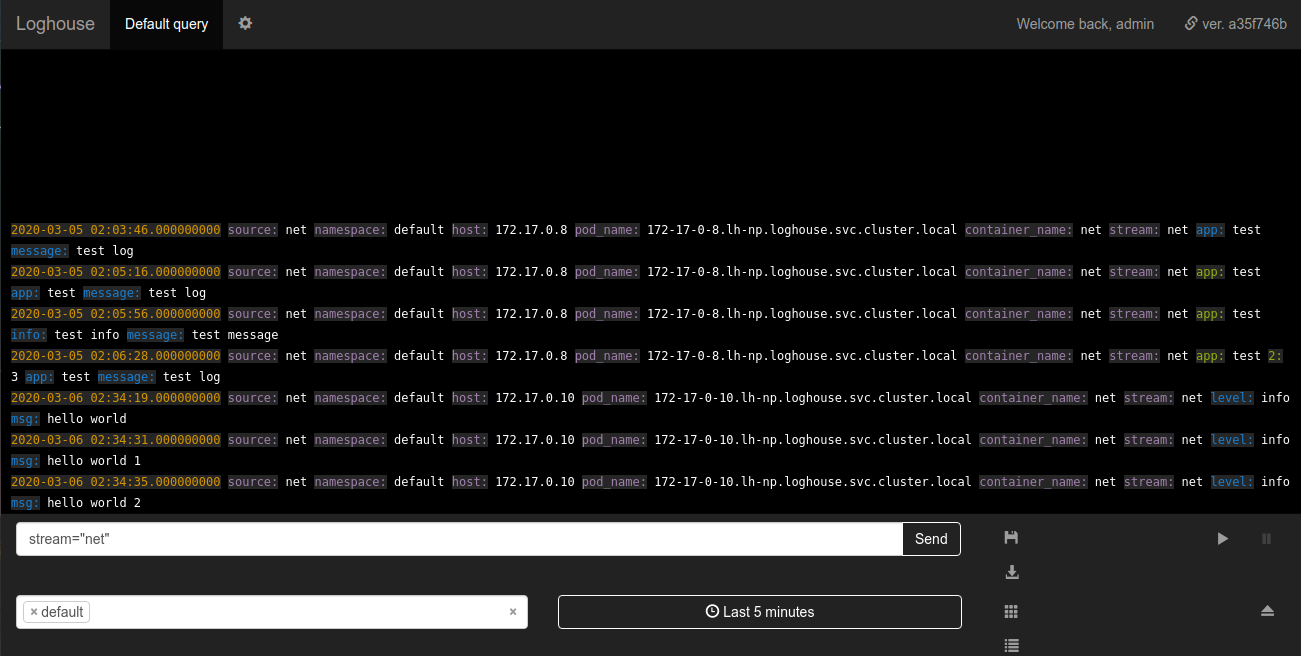 Anforderungen an die zu sendenden Daten sind minimal: Die Nachricht muss ein gültiger JSON mit einem Feld sein
Anforderungen an die zu sendenden Daten sind minimal: Die Nachricht muss ein gültiger JSON mit einem Feld sein log. Das Feld logkann wiederum entweder eine Zeichenfolge oder ein verschachtelter JSON sein.Überwachung des Protokollierungssubsystems
Eine wichtige Verbesserung war die Überwachung von Fluentd durch Prometheus. Jetzt wird das Blockhaus mit einem Panel für Grafana geliefert, in dem alle grundlegenden Metriken angezeigt werden, z.- Anzahl der fließenden Arbeitnehmer;
- Anzahl der an ClickHouse gesendeten Ereignisse;
- freie Puffergröße in Prozent.
Der Panel-Code für Grafana ist in der Dokumentation zu sehen .Das Panel für ClickHouse basiert auf einem fertigen Produkt - von f1yegor , wofür wir uns beim Autor bedanken .Wie Sie sehen können, zeigt das Bedienfeld die Anzahl der Verbindungen zu ClickHouse, die Verwendung des Puffers, die Aktivität der Hintergrundaufgaben und die Anzahl der Zusammenführungen an. Dies reicht aus, um den Status des Systems zu verstehen: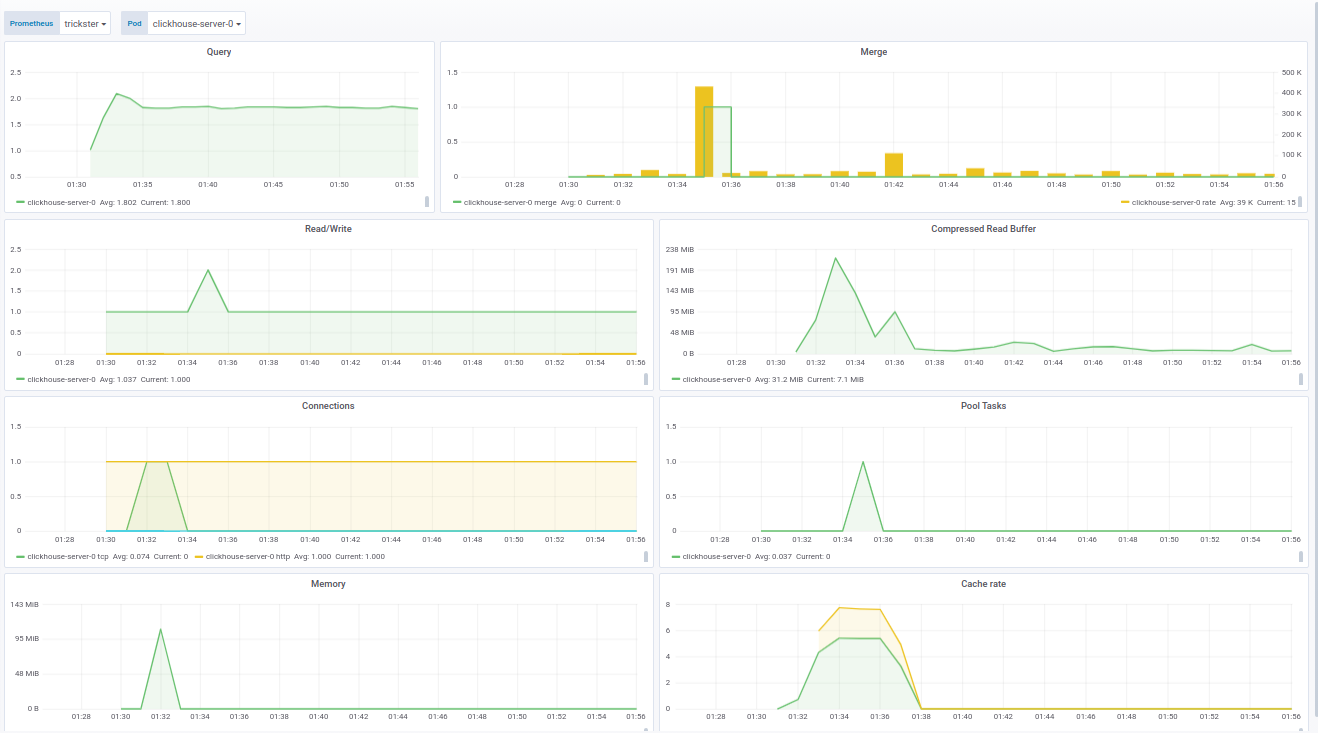 Das Feld für fluentd zeigt die aktiven Instanzen von fluentd an. Dies ist besonders wichtig für diejenigen, die keine Protokolle verlieren möchten / können:
Das Feld für fluentd zeigt die aktiven Instanzen von fluentd an. Dies ist besonders wichtig für diejenigen, die keine Protokolle verlieren möchten / können: Zusätzlich zum Status der Pods zeigt das Bedienfeld die Last in der Warteschlange zum Senden von Protokollen an ClickHouse an. Sie können wiederum nachvollziehen, ob ClickHouse die Last verarbeitet oder nicht. In Fällen, in denen das Protokoll nicht verloren gehen kann, wird dieser Parameter ebenfalls kritisch.Beispiele für Panels sind für unsere Lieferung von Prometheus Operator geschärft, können jedoch leicht über die Variablen in den Einstellungen geändert werden.Schließlich haben wir im Rahmen der Blockhausüberwachung ein aktuelles Docker-Image mit clickhouse_exporter 0.1.0 zusammengestellt, das von Percona Labs veröffentlicht wurde, da der Autor des ursprünglichen clickhouse_exporter sein Repository verlassen hat.
Zusätzlich zum Status der Pods zeigt das Bedienfeld die Last in der Warteschlange zum Senden von Protokollen an ClickHouse an. Sie können wiederum nachvollziehen, ob ClickHouse die Last verarbeitet oder nicht. In Fällen, in denen das Protokoll nicht verloren gehen kann, wird dieser Parameter ebenfalls kritisch.Beispiele für Panels sind für unsere Lieferung von Prometheus Operator geschärft, können jedoch leicht über die Variablen in den Einstellungen geändert werden.Schließlich haben wir im Rahmen der Blockhausüberwachung ein aktuelles Docker-Image mit clickhouse_exporter 0.1.0 zusammengestellt, das von Percona Labs veröffentlicht wurde, da der Autor des ursprünglichen clickhouse_exporter sein Repository verlassen hat.Zukunftspläne
- Ermöglichen Sie die Bereitstellung eines ClickHouse-Clusters in Kubernetes.
- Arbeiten Sie mit der Auswahl der Protokolle asynchron und entfernen Sie sie aus dem Ruby-Teil des Backends.
- Ruby- , .
- , Go.
- .
Es ist schön zu sehen, dass das Loghouse-Projekt sein Publikum gefunden hat, nicht nur Sterne in GitHub (600+) gewonnen hat, sondern auch echte Benutzer dazu ermutigt hat, über ihre Erfolge und Probleme zu sprechen.Nachdem wir vor mehr als zwei Jahren ein Blockhaus gegründet hatten, waren wir uns seiner Aussichten nicht sicher und erwarteten, dass der Markt und / oder die Open Source-Community die besten Lösungen anbieten würden. Heute sehen wir jedoch, dass dies ein praktikabler Weg ist, den wir selbst immer noch für viele Kubernetes-Cluster mit Service wählen und verwenden.Wir freuen uns auf jede Unterstützung bei der Verbesserung und Entwicklung des Blockhauses. Wenn Sie etwas im Blockhaus vermissen - schreiben Sie in die Kommentare. Natürlich freuen wir uns auch, auf GitHub aktiv zu sein .PS
Lesen Sie auch in unserem Blog: