Hallo wieder! Im Vorfeld des Kurses „Software Architect“ haben wir eine Übersetzung eines weiteren interessanten Materials vorbereitet.
In den letzten Jahren hat die Popularität der Microservice-Architektur zugenommen. Es gibt viele Ressourcen, die Ihnen beibringen, wie man es richtig implementiert, aber ziemlich oft wird darüber als Silberpool gesprochen. Es gibt viele Argumente gegen die Verwendung von Microservices, aber das wichtigste davon ist, dass diese Art von Architektur mit ungewisser Komplexität behaftet ist, deren Ebene davon abhängt, wie Sie die Beziehung zwischen Ihren Services und Teams verwalten. Sie können eine Menge Literatur finden, die erklärt, warum (vielleicht) in Ihrem Fall Microservices nicht die beste Wahl sind.Wir bei letgo sind von einem Monolithen auf Microservices umgestiegen, um das Bedürfnis nach Skalierbarkeit zu befriedigen, und haben uns sofort von dessen positiven Auswirkungen auf die Arbeit von Teams überzeugt. Bei richtiger Anwendung haben Microservices uns mehrere Vorteile gebracht, nämlich:- : , . ( ..) . ( ) Users.
- : , . . , , , , . .
-
Nicht alle Microservice-Architekturen sind ereignisgesteuert. Einige Leute befürworten die synchrone Kommunikation zwischen Diensten in dieser Architektur über HTTP (gRPC, REST usw.). Bei letgo versuchen wir, diesem Muster nicht zu folgen und unsere Dienste asynchron mit Domänenereignissen zu verknüpfen . Hier sind die Gründe, warum wir dies tun:- : . , DDoS . , DDoS . , . .
(bulkheads) – , , .- : . , , , , . , , API, , , , . Users , Chat.
Auf dieser Grundlage versuchen wir bei letgo, die asynchrone Kommunikation zwischen Diensten einzuhalten, und synchron funktioniert nur in Ausnahmefällen wie Feature-MVP. Wir tun dies, weil wir möchten, dass jeder Dienst seine eigenen Entitäten basierend auf Domänenereignissen generiert, die von anderen Diensten in unserem Nachrichtenbus veröffentlicht wurden.Unserer Meinung nach hängt der Erfolg oder Misserfolg bei der Implementierung der Microservice-Architektur davon ab, wie Sie mit der inhärenten Komplexität umgehen und wie Ihre Services miteinander interagieren. Wenn Sie Code teilen, ohne die Kommunikationsinfrastruktur auf asynchron zu übertragen, wird Ihre Anwendung zu einem verteilten Monolithen.
Ereignisgesteuerte Architektur in letgo
Heute möchte ich ein Beispiel dafür geben, wie wir Domänenereignisse und asynchrone Kommunikation in letgo verwenden: Unsere Benutzerentität ist in vielen Diensten vorhanden, aber ihre Erstellung und Bearbeitung wird zunächst vom Benutzerdienst verarbeitet. In der Datenbank des Benutzerdienstes speichern wir viele Daten wie Name, E-Mail-Adresse, Avatar, Land usw. In unserem Chat-Dienst haben wir auch ein Benutzerkonzept, aber wir benötigen nicht die Daten, über die die Benutzerentität aus dem Benutzerdienst verfügt. Der Name, der Avatar und die ID des Benutzers (Link zum Profil) werden in der Liste der Dialogfelder angezeigt. Wir sagen, dass es in einem Chat nur eine Projektion der Benutzerentität gibt, die Teildaten enthält. Tatsächlich sprechen wir im Chat nicht über Benutzer, sondern nennen sie "Sprecher". Diese Projektion bezieht sich auf den Chat-Dienst und basiert auf den Ereignissen, die der Chat vom Benutzerdienst empfängt.Wir machen das gleiche mit Listings. Im Produktservice speichern wir n Bilder jeder Auflistung, aber in der Listenansicht der Dialoge zeigen wir ein Hauptbild, sodass für unsere Projektion von Produkten zum Chat nur ein Bild anstelle von n erforderlich ist.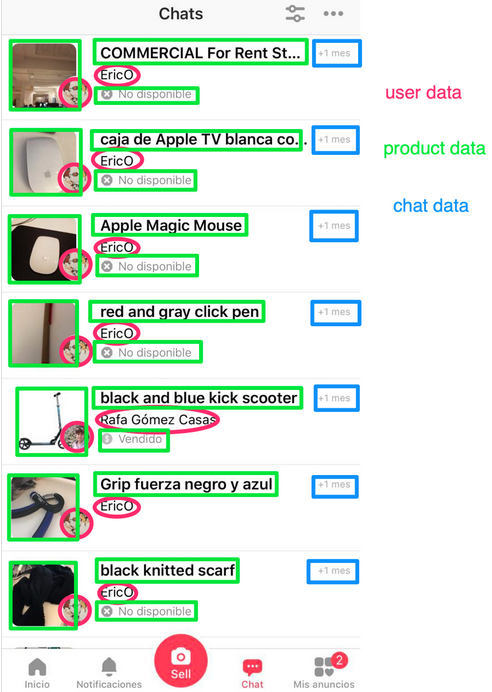 Zeigen Sie eine Liste der Dialoge in unserem Chat an. Es zeigt, welcher spezifische Dienst im Backend Informationen bereitstellt.Wenn Sie sich die Liste der Dialogfelder noch einmal ansehen, werden Sie feststellen, dass fast alle von uns angezeigten Daten nicht vom Chat-Dienst erstellt wurden, sondern dazu gehören, da die Benutzer- und Chat-Projektionen dem Chat gehören. Es gibt einen Kompromiss zwischen Zugänglichkeit und Konsistenz von Projektionen, auf den wir in diesem Artikel nicht eingehen werden, aber ich möchte nur sagen, dass es eindeutig einfacher ist, viele kleine Datenbanken als eine große zu skalieren.
Zeigen Sie eine Liste der Dialoge in unserem Chat an. Es zeigt, welcher spezifische Dienst im Backend Informationen bereitstellt.Wenn Sie sich die Liste der Dialogfelder noch einmal ansehen, werden Sie feststellen, dass fast alle von uns angezeigten Daten nicht vom Chat-Dienst erstellt wurden, sondern dazu gehören, da die Benutzer- und Chat-Projektionen dem Chat gehören. Es gibt einen Kompromiss zwischen Zugänglichkeit und Konsistenz von Projektionen, auf den wir in diesem Artikel nicht eingehen werden, aber ich möchte nur sagen, dass es eindeutig einfacher ist, viele kleine Datenbanken als eine große zu skalieren.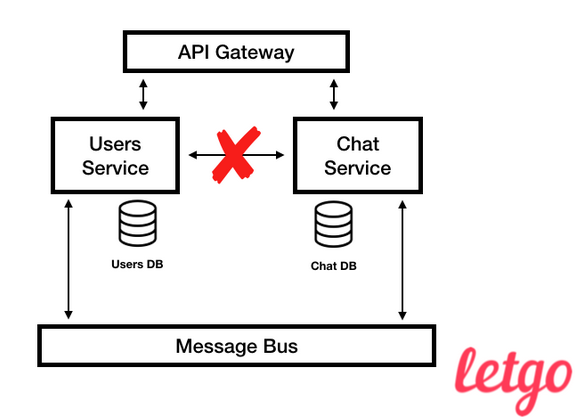 Vereinfachte Ansicht der Letgo-Architektur
Vereinfachte Ansicht der Letgo-ArchitekturAntipatterns
Einige intuitive Lösungen wurden oft zu Fehlern. Hier ist eine Liste der wichtigsten Antimuster, die wir in unserer domänenbezogenen Architektur angetroffen haben.1. Dicke EreignisseWir versuchen, unsere Domain-Events so klein wie möglich zu halten, ohne ihren Domain-Wert zu verlieren. Wir hätten vorsichtig sein müssen, wenn wir ältere Codebasen mit großen Entitäten umgestaltet und zur Ereignisarchitektur gewechselt haben. Solche Entitäten können uns zu fetten Ereignissen führen, aber da unsere Domain-Ereignisse in einen öffentlichen Auftrag umgewandelt wurden, mussten wir sie so einfach wie möglich gestalten. In diesem Fall wird das Refactoring am besten von der Seite betrachtet. Zu Beginn gestalten wir unsere Events mit der Event-Storm- Technikund überarbeiten Sie dann den Service-Code, um ihn an unsere Ereignisse anzupassen.Wir sollten auch beim Problem „Produkt und Benutzer“ vorsichtiger sein: Viele Systeme verwenden Produkt- und Benutzerentitäten, und diese Entitäten ziehen in der Regel die gesamte Logik hinter sich her, und dies bedeutet, dass alle Domänenereignisse mit ihnen verknüpft sind.2. Ereignisse als Absichten EinDomänenereignis ist per Definition ein Ereignis, das bereits aufgetreten ist. Wenn Sie etwas im Nachrichtenbus veröffentlichen, um anzufordern, was in einem anderen Dienst passiert ist, führen Sie höchstwahrscheinlich einen asynchronen Befehl aus, anstatt ein Domänenereignis zu erstellen. In der Regel beziehen wir uns auf vergangene Domain-Ereignisse: ser_registered , product_publishedusw. Je weniger ein Dienst über den anderen weiß, desto besser. Die Verwendung von Ereignissen als Befehle verknüpft Dienste und erhöht die Wahrscheinlichkeit, dass sich eine Änderung eines Dienstes auf andere Dienste auswirkt.3. Fehlende unabhängige Serialisierung oder Komprimierung. DieSysteme zur Serialisierung und Komprimierung von Ereignissen in unserem Themenbereich sollten nicht von der Programmiersprache abhängen. Sie müssen nicht einmal wissen, in welcher Sprache Verbraucherdienste geschrieben sind. Deshalb können wir zum Beispiel Java- oder PHP-Serializer verwenden. Lassen Sie Ihr Team Zeit damit verbringen, einen Serializer zu diskutieren und auszuwählen, da das Ändern in Zukunft schwierig und zeitaufwändig sein wird. Wir bei letgo verwenden JSON, es gibt jedoch viele andere Serialisierungsformate mit guter Leistung.4. Fehlende StandardstrukturAls wir damit begannen, das letgo-Backend auf eine ereignisorientierte Architektur zu portieren, einigten wir uns auf eine gemeinsame Struktur für Domänenereignisse. Es sieht ungefähr so aus:{
“data”: {
“id”: [uuid], // event id.
“type”: “user_registered”,
“attributes”: {
“id”: [uuid], // aggregate/entity id, in this case user_id
“user_name”: “John Doe”,
…
}
},
“meta” : {
“created_at”: timestamp, // when was the event created?
“host”: “users-service” // where was the event created?
…
}
}
Durch eine gemeinsame Struktur unserer Domänenereignisse können wir Dienste schnell integrieren und einige Bibliotheken mit Abstraktionen implementieren.5. FehlendeSchemaüberprüfung Während der Serialisierung hatten wir bei letgo Probleme mit Programmiersprachen ohne starke Typisierung.
{
“null_value_one”: null, // thank god
“null_value_two”: “null”,
“null_value_three”: “”,
}
Eine etablierte Testkultur, die die Serialisierung unserer Ereignisse garantiert, und ein Verständnis der Funktionsweise der Serialisierungsbibliothek tragen dazu bei, damit umzugehen. Wir bei letgo wechseln zu Avro und der Confluent Schema Registry, die uns einen einzigen Punkt zur Bestimmung der Struktur der Ereignisse unserer Domain bietet und Fehler dieser Art sowie veraltete Dokumentation vermeidet.6. Anämische DomänenereignisseWie ich bereits sagte und wie der Name schon sagt, müssen Domänenereignisse auf Domänenebene einen Wert haben. So wie wir versuchen, die Inkonsistenz von Zuständen in unseren Entitäten zu vermeiden, müssen wir dies bei Domänenereignissen vermeiden. Lassen Sie uns dies anhand des folgenden Beispiels veranschaulichen: Das Produkt in unserem System verfügt über eine Geolokalisierung mit Längen- und Breitengrad, die in zwei verschiedenen Feldern der Produkttabelle des Produktservices gespeichert sind. Alle Produkte können "verschoben" werden, daher haben wir Domain-Ereignisse, um dieses Update zu präsentieren. Zuvor hatten wir zwei Ereignisse: product_latitude_updated und product_longitude_updated , was wenig Sinn machte, wenn Sie kein Turm auf einem Schachbrett waren. In diesem Fall sind die Ereignisse product_location_updated sinnvoller.oder product_moved . Ein Turm ist eine Schachfigur. Früher hieß es Tour. Ein Turm kann sich nur vertikal oder horizontal durch eine beliebige Anzahl nicht besetzter Felder bewegen.7. Fehlende Debugging-ToolsWir bei letgo produzieren Tausende von Domain-Events pro Minute. All diese Ereignisse werden zu einer äußerst nützlichen Ressource, um zu verstehen, was in unserem System geschieht, Benutzeraktivitäten zu registrieren oder sogar den Status eines Systems zu einem bestimmten Zeitpunkt mithilfe der Ereignissuche zu rekonstruieren. Wir müssen diese Ressource geschickt nutzen, und dafür benötigen wir Tools zum Überprüfen und Debuggen unserer Ereignisse. Anfragen wie "Zeigen Sie mir alle Ereignisse, die John Doe in den letzten 3 Stunden generiert hat" können ebenfalls hilfreich sein, um Betrug aufzudecken. Zu diesem Zweck haben wir einige Tools für ElasticSearch, Kibana und S3 entwickelt.8. Fehlende EreignisüberwachungWir können Domänenereignisse verwenden, um den Zustand des Systems zu testen. Wenn wir etwas bereitstellen (was je nach Dienst mehrmals täglich geschieht), benötigen wir Tools, um den korrekten Vorgang schnell zu überprüfen. Zum Beispiel, wenn wir eine neue Version des Produktservices in der Produktion bereitstellen und eine Verringerung der Anzahl von product_published- Ereignissen feststellen20%, man kann mit Sicherheit sagen, dass wir etwas kaputt gemacht haben. Wir verwenden derzeit InfluxDB, Grafana und Prometheus, um dies mit abgeleiteten Funktionen zu erreichen. Wenn Sie sich an den Verlauf der Mathematik erinnern, werden Sie verstehen, dass die Ableitung der Funktion f (x) am Punkt x gleich der Tangente des Tangentenwinkels ist, der an diesem Punkt zum Diagramm der Funktion gezogen wird. Wenn Sie eine Funktion zum Veröffentlichen der Geschwindigkeit eines bestimmten Ereignisses in einem Themenbereich haben und daraus eine Ableitung ableiten, werden die Spitzen dieser Funktion angezeigt und Sie können Benachrichtigungen basierend darauf festlegen. Mit diesen Benachrichtigungen können Sie Ausdrücke wie "Warnen Sie mich, wenn wir 5 Minuten lang weniger als 200 Ereignisse pro Sekunde veröffentlichen" vermeiden und sich auf eine signifikante Änderung der Veröffentlichungsgeschwindigkeit konzentrieren.
Ein Turm ist eine Schachfigur. Früher hieß es Tour. Ein Turm kann sich nur vertikal oder horizontal durch eine beliebige Anzahl nicht besetzter Felder bewegen.7. Fehlende Debugging-ToolsWir bei letgo produzieren Tausende von Domain-Events pro Minute. All diese Ereignisse werden zu einer äußerst nützlichen Ressource, um zu verstehen, was in unserem System geschieht, Benutzeraktivitäten zu registrieren oder sogar den Status eines Systems zu einem bestimmten Zeitpunkt mithilfe der Ereignissuche zu rekonstruieren. Wir müssen diese Ressource geschickt nutzen, und dafür benötigen wir Tools zum Überprüfen und Debuggen unserer Ereignisse. Anfragen wie "Zeigen Sie mir alle Ereignisse, die John Doe in den letzten 3 Stunden generiert hat" können ebenfalls hilfreich sein, um Betrug aufzudecken. Zu diesem Zweck haben wir einige Tools für ElasticSearch, Kibana und S3 entwickelt.8. Fehlende EreignisüberwachungWir können Domänenereignisse verwenden, um den Zustand des Systems zu testen. Wenn wir etwas bereitstellen (was je nach Dienst mehrmals täglich geschieht), benötigen wir Tools, um den korrekten Vorgang schnell zu überprüfen. Zum Beispiel, wenn wir eine neue Version des Produktservices in der Produktion bereitstellen und eine Verringerung der Anzahl von product_published- Ereignissen feststellen20%, man kann mit Sicherheit sagen, dass wir etwas kaputt gemacht haben. Wir verwenden derzeit InfluxDB, Grafana und Prometheus, um dies mit abgeleiteten Funktionen zu erreichen. Wenn Sie sich an den Verlauf der Mathematik erinnern, werden Sie verstehen, dass die Ableitung der Funktion f (x) am Punkt x gleich der Tangente des Tangentenwinkels ist, der an diesem Punkt zum Diagramm der Funktion gezogen wird. Wenn Sie eine Funktion zum Veröffentlichen der Geschwindigkeit eines bestimmten Ereignisses in einem Themenbereich haben und daraus eine Ableitung ableiten, werden die Spitzen dieser Funktion angezeigt und Sie können Benachrichtigungen basierend darauf festlegen. Mit diesen Benachrichtigungen können Sie Ausdrücke wie "Warnen Sie mich, wenn wir 5 Minuten lang weniger als 200 Ereignisse pro Sekunde veröffentlichen" vermeiden und sich auf eine signifikante Änderung der Veröffentlichungsgeschwindigkeit konzentrieren.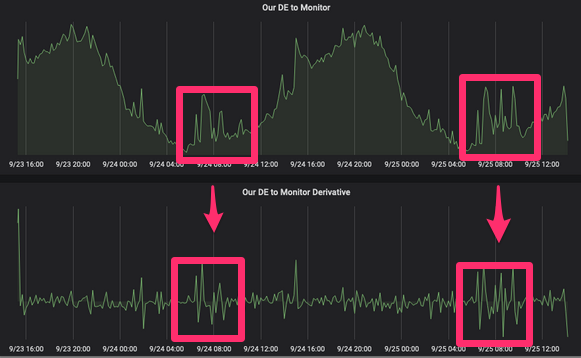 Hier ist etwas Seltsames passiert ... Oder vielleicht ist es nur eine Marketingkampagne9. Die Hoffnung, dass alles gut wirdWir versuchen, nachhaltige Systeme zu schaffen und die Kosten für ihre Wiederherstellung zu senken. Neben Infrastrukturproblemen und dem menschlichen Faktor ist der Verlust von Ereignissen eines der häufigsten Dinge, die die Ereignisarchitektur beeinflussen können. Wir brauchen einen Plan, mit dem wir den korrekten Zustand des Systems wiederherstellen können, indem wir alle verlorenen Ereignisse erneut verarbeiten. Hier basiert unsere Strategie auf zwei Punkten:
Hier ist etwas Seltsames passiert ... Oder vielleicht ist es nur eine Marketingkampagne9. Die Hoffnung, dass alles gut wirdWir versuchen, nachhaltige Systeme zu schaffen und die Kosten für ihre Wiederherstellung zu senken. Neben Infrastrukturproblemen und dem menschlichen Faktor ist der Verlust von Ereignissen eines der häufigsten Dinge, die die Ereignisarchitektur beeinflussen können. Wir brauchen einen Plan, mit dem wir den korrekten Zustand des Systems wiederherstellen können, indem wir alle verlorenen Ereignisse erneut verarbeiten. Hier basiert unsere Strategie auf zwei Punkten:- : , « , », - , . letgo Data, Backend.
- : - . , , , message bus . – , , . , user_registered Users, , MySQL, user_id . user_registered, , . , , - MySQL ( , 30 ). -, DynamoDB. , , , . , , , , .
10. Fehlende Dokumentation zu DomänenereignissenUnsere Domänenereignisse sind zu unserer öffentlichen Schnittstelle für alle Systeme im Backend geworden. So wie wir unsere REST-APIs dokumentieren, müssen wir auch Domänenereignisse dokumentieren. Jeder Mitarbeiter der Organisation sollte in der Lage sein, aktualisierte Dokumentationen für jedes von jedem Dienst veröffentlichte Domänenereignis anzuzeigen. Wenn wir Schemata zum Überprüfen von Domänenereignissen verwenden, können diese auch als Dokumentation verwendet werden.11. Widerstand gegen den Konsum eigener EreignisseSie dürfen und werden sogar dazu ermutigt, Ihre eigenen Domänenereignisse zu verwenden, um Projektionen in Ihrem System zu erstellen, die beispielsweise zum Lesen optimiert sind. Einige Teams widersetzten sich diesem Konzept, weil sie sich auf das Konzept des Konsums von Ereignissen anderer Leute beschränkten.Wir sehen uns auf dem Kurs!