Hallo Habr! Ich möchte Ihnen sagen, wie wir einen Dienst zur Überwachung der Datenqualität geschrieben und implementiert haben. Wir haben viele Datenquellen: Daten von den Finanzmärkten, Handelsaktivitäten unserer Kunden, Kurse und vieles mehr. All dies generiert Milliarden von Datensätzen pro Tag in unseren Prozessen. Die Vollständigkeit und Konsistenz der Handelsdaten ist ein kritischer Bestandteil des Geschäfts von Exness.Wenn Sie Probleme mit der Datenqualitätssicherung haben und daran interessiert sind, wie wir dieses Problem zu Hause gelöst haben, sind Sie bei cat willkommen. Mein Name ist Dmitry. Ich arbeite in einem Team, das sowohl Rohdaten als auch die Transformation, Aggregation und Bereitstellung aller verarbeiteten Daten für alle Abteilungen des Unternehmens speichert. Unsere Daten werden von vielen Teams im Unternehmen verwendet, z. B. Business Intelligence, Betrugsbekämpfung und Finanzen. Wir stellen sie auch unseren B2B-Partnern zur Verfügung.Das Arbeiten mit Daten ist eine verantwortungsvolle und schwierige Aufgabe, da das Stoppen eines ETL-Prozesses zu einer Lähmung eines Teils des Geschäfts von Exness führen kann. Um ETL-Probleme zu lösen, verwenden wir eine Vielzahl von Tools:
Mein Name ist Dmitry. Ich arbeite in einem Team, das sowohl Rohdaten als auch die Transformation, Aggregation und Bereitstellung aller verarbeiteten Daten für alle Abteilungen des Unternehmens speichert. Unsere Daten werden von vielen Teams im Unternehmen verwendet, z. B. Business Intelligence, Betrugsbekämpfung und Finanzen. Wir stellen sie auch unseren B2B-Partnern zur Verfügung.Das Arbeiten mit Daten ist eine verantwortungsvolle und schwierige Aufgabe, da das Stoppen eines ETL-Prozesses zu einer Lähmung eines Teils des Geschäfts von Exness führen kann. Um ETL-Probleme zu lösen, verwenden wir eine Vielzahl von Tools: Herausforderungen, denen wir uns täglich stellen:
Herausforderungen, denen wir uns täglich stellen:- Täglich Millionen von Transaktionsaufzeichnungen;
- Täglich Milliarden Markteintritte (Kurse usw.);
- Die Heterogenität von Datenquellen (wie externe Quellen von Marktdaten, verschiedene Handelsplattformen);
- Genau einmalige Semantik für wichtige Daten (Finanztransaktionen) bereitstellen;
- Gewährleistung der Integrität und Vollständigkeit der Daten;
- Bereitstellung von Garantien, dass die Transaktion für die festgelegte Zeit zu allen erforderlichen Tabellen und Aggregaten hinzugefügt wird.
Um solche Garantien zu geben, musste gelernt werden, wie Abweichungen in der Qualität der Daten verfolgt, gemessen und proaktiv darauf reagiert werden können.Angesichts der Komplexität unserer Datenerfassungs- und -verarbeitungsprozesse und der hohen Geschwindigkeit der Entwicklung und Änderung von ETL-Prozessen ist es erforderlich, die Datenqualität bereits am Endpunkt zu überwachen. Wir haben normalerweise eine Clickhouse- oder PostgreSQL-Datenbank. Solche Metriken zeigen uns, wie schnell unsere Prozesse ablaufen:SELECT server,
avg(updated - close_time)
FROM trades
WHERE close_time > subtractHours(Now(), 2)
GROUP BY server
Sie helfen dabei, Duplikate in den Daten zu finden (in Clickhouse gibt es keine eindeutigen Einschränkungen):SELECT SUM(count) FROM (
SELECT
COUNT(*) AS count
FROM trades
GROUP BY order_id
HAVING count > 1
)
Sie können eine Menge Abfragen erstellen (von denen viele bereits verwendet werden), mit denen Sie die Qualität der Daten überwachen können: Vergleichen Sie die Anzahl der Zeilen in der Quelltabelle und der Zieltabelle, den Zeitpunkt des letzten Einfügens in die Tabelle, vergleichen Sie den Inhalt von zwei Abfragen und vieles mehr.Die Metriken sind Symptome. An sich geben sie nicht die Ursache des Problems an, sondern erlauben uns zu zeigen, dass es ein Problem gibt. Dies ist ein Auslöser für den Techniker, auf das Problem zu achten und die Grundursache zu identifizieren. Analogie: Wenn eine Person eine Temperatur hat, ist etwas in ihrem Körper gebrochen. Die Temperatur ist ein ausreichendes Symptom, um die Ursache des Zusammenbruchs zu verstehen und zu finden.Wir suchten nach einer vorgefertigten Lösung, mit der solche Symptommetriken für uns erfasst werden können. Unsere Anforderungen:- Unterstützung für verschiedene Datenquellen (Datenbanken, Warteschlangen, http-Anfragen);
- ;
- ( , );
- .
Am Anfang des Artikels habe ich die Technologien aufgelistet, die wir in ETL verwenden. Wie Sie sehen, unterstützen wir Open-Source-Lösungen! Ein Beispiel: Wir verwenden die spaltenorientierte Clickhouse-Datenbank als Haupt-Data Warehouse. Unser Team hat mehrmals Änderungen am Clickhouse-Quellcode vorgenommen (hauptsächlich zur Behebung von Fehlern). Als Werkzeuge für die Arbeit mit Metriken und Zeitreihen verwenden wir: Ökosystem-Influxdb, Prometheus- und Victoria-Metriken, Zabbix.Zu unserer Überraschung stellte sich heraus, dass es kein vorgefertigtes und praktisches Tool zur Überwachung der Datenqualität gibt, das in die von uns ausgewählten Technologien passt. Oder sahen wir schlecht aus?Ja, zabbix kann benutzerdefinierte Skripte und Telegraf ausführenSie können lernen, wie SQL-Abfragen ausgeführt und ihre Ergebnisse in Metriken umgewandelt werden. Dies erforderte jedoch eine ernsthafte Fertigstellung und funktionierte nicht sofort so, wie wir es wollten. Aus diesem Grund haben wir unseren eigenen Service (Daemon) geschrieben, um die Datenqualität zu überwachen. Treffen Sie Nerven!Nervenmerkmale
Ideologisch kann der Nerv mit folgendem Satz beschrieben werden:Dies ist ein Dienst, der geplante, heterogene, angepasste Aufgaben zum Sammeln numerischer Werte ausführt und die Ergebnisse als Metriken für verschiedene Metriksammelsysteme darstellt.
Hauptmerkmale des Programms:- Unterstützung für verschiedene Arten von Aufgaben: Query, CompareQueries usw.;
- Die Möglichkeit, Ihre Aufgabentypen in Python als Laufzeit-Plugin zu schreiben;
- Arbeiten Sie mit verschiedenen Arten von Ressourcen: Clickhouse, Postgres usw.;
- Modelldatenmetriken wie bei prometheus
metric_name{label="value"} 123.3 ;
- pull prometheus;
- : crontab-style;
- WEB UI ;
- yaml ;
- Twelve-Factor App.
Aufgabe und Ressource sind die grundlegenden Einheiten für die Konfiguration und Arbeit mit Nerven. Aufgabe - eine typisierte periodische Aktion, durch die wir Metriken erhalten. Ressource - Ein Objekt, das Konfiguration und Logik enthält, die für die Arbeit mit einer bestimmten Datenquelle spezifisch sind. Mal sehen, wie Nerven mit einem Beispiel funktionieren.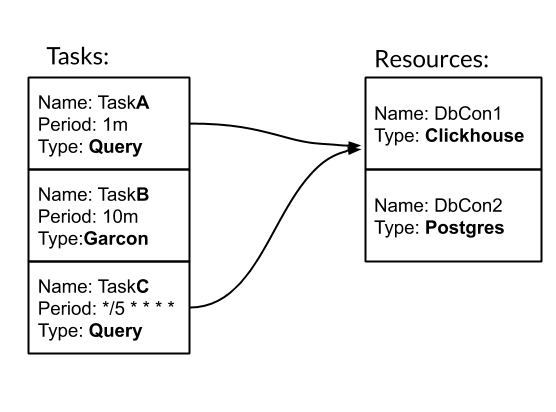 Wir haben drei Aufgaben. Zwei davon sind vom Typ Abfrage - SQL-Abfrage. Eines ist vom Typ Garcon - dies ist eine maßgeschneiderte Aufgabe, die an einen unserer Dienste geht. Die Häufigkeit der Aufgabe kann durch einen Zeitraum festgelegt werden. Zum Beispiel bedeutet 10 m einmal alle zehn Minuten. Oder im Crontab-Stil "* / 5 * * * *" - jede fünfte volle Minute. Aufgaben TaskA und TaskC sind der DbCon1-Ressource zugeordnet, die vom Typ Clickhouse ist. Mal sehen, wie die Konfiguration aussehen wird:
Wir haben drei Aufgaben. Zwei davon sind vom Typ Abfrage - SQL-Abfrage. Eines ist vom Typ Garcon - dies ist eine maßgeschneiderte Aufgabe, die an einen unserer Dienste geht. Die Häufigkeit der Aufgabe kann durch einen Zeitraum festgelegt werden. Zum Beispiel bedeutet 10 m einmal alle zehn Minuten. Oder im Crontab-Stil "* / 5 * * * *" - jede fünfte volle Minute. Aufgaben TaskA und TaskC sind der DbCon1-Ressource zugeordnet, die vom Typ Clickhouse ist. Mal sehen, wie die Konfiguration aussehen wird:tasks:
- name: TaskA
type: Query
resources: DbCon1
period: 1m
config:
query: SELECT COUNT(*) FROM ticks
gauge: metric_count{table="ticks"}
- name: TaskB
type: Garcon
period: 10m
config:
url: "http://hostname:9003/api/v1/orders/backups/"
gauge: backup_ago
- name: TaskC
type: Query
period: "*/5 * * * *"
resources: DbCon1
config:
query: SELECT now() - toDateTime(time_msc/1000)
FROM deals WHERE trade_server= 'Real'
ORDER BY deal DESC LIMIT 1
gauge: orders_lag
resources:
- name: DbCon1
type: Clickhouse
config:
host: clickhouse.env
port: 9000
user: readonly
password: "***"
database: data
results:
common_labels:
env="prod"
task_types_paths:
- "./tasks"
Der Pfad "./tasks" ist der Pfad zu benutzerdefinierten Aufgaben. Insbesondere wird dort der Garcon-Aufgabentyp definiert. In diesem Artikel werde ich den Moment des Erstellens meiner Aufgabentypen weglassen.Durch das Starten des Nervendienstes mit einer solchen Konfiguration kann in der WEB-Benutzeroberfläche überwacht werden, wie Aufgaben erfüllt werden: Und at /metrics-Metriken für die Erfassung sind verfügbar:
Und at /metrics-Metriken für die Erfassung sind verfügbar: Abfrageaufgabentyp, der in unserem Team am häufigsten verwendet wird. Aus diesem Grund haben wir die Funktionen für die Arbeit mit GROUP BY und Vorlagen erweitert. Diese Mechanismen ermöglichen es, viele Informationen über Daten mit jeweils einer Anforderung zu
Abfrageaufgabentyp, der in unserem Team am häufigsten verwendet wird. Aus diesem Grund haben wir die Funktionen für die Arbeit mit GROUP BY und Vorlagen erweitert. Diese Mechanismen ermöglichen es, viele Informationen über Daten mit jeweils einer Anforderung zu erfassen : Die TradesLag-Task erfasst die maximale Verzögerung für jeden Handelsserver, um alle fünf Minuten einen geschlossenen Auftrag in die Handelstabelle aufzunehmen, wobei nur Aufträge berücksichtigt werden, die in den letzten zwei Stunden geschlossen wurden.Ein paar Worte zur Implementierung. Nerve ist eine Multithread-Python3 ~ 3k LoC-Anwendung, die einfach über Docker ausgeführt werden kann und durch eine Aufgabenkonfiguration ergänzt wird.
erfassen : Die TradesLag-Task erfasst die maximale Verzögerung für jeden Handelsserver, um alle fünf Minuten einen geschlossenen Auftrag in die Handelstabelle aufzunehmen, wobei nur Aufträge berücksichtigt werden, die in den letzten zwei Stunden geschlossen wurden.Ein paar Worte zur Implementierung. Nerve ist eine Multithread-Python3 ~ 3k LoC-Anwendung, die einfach über Docker ausgeführt werden kann und durch eine Aufgabenkonfiguration ergänzt wird.Was ist passiert
Mit Nerven haben wir bekommen, was wir wollten. Im Moment haben neben unserem Team auch andere Teams in Exness Interesse an ihm gezeigt. Es werden ungefähr 40 Aufgaben mit einer Häufigkeit von 30 Sekunden pro Tag ausgeführt. Nerve sammelt ungefähr 500 Metriken über unsere Daten. Das Hinzufügen neuer Metriken dauert 5-10 Minuten. Der gesamte Arbeitsfluss mit Metriken sieht folgendermaßen aus: Nerv → Prometheus → Victoria-Metriken → Grafana-Dashboards → Warnungen in PagerDuty.Mit Nerven haben wir auch angefangen, Geschäftsmetriken zu sammeln: Wir wählen regelmäßig Rohereignisse im Handelssystem aus, um die Handelsbedingungen zu bewerten.Vielen Dank, Chabrowsk-Bürger, dass Sie meinen Artikel bis zum Ende gelesen haben. Ich sehe Ihre Frage voraus: Wo ist der Link zu Github? Die Antwort lautet: Wir haben noch keine Nerven in Open Source gepostet. Dies erfordert zusätzliche Arbeiten von unserer Seite, um die Dokumentation zu verbessern und einige Funktionen fertigzustellen. Wenn dieser Artikel von der Community gut aufgenommen wird, gibt dies uns einen zusätzlichen Anreiz, unsere Entwicklung mit Ihnen zu teilen!Gut zu allen!