Der Kanarienvogel ist ein kleiner Vogel, der ständig singt. Diese Vögel reagieren empfindlich auf Methan und Kohlenmonoxid. Selbst durch eine geringe Konzentration überschüssiger Gase in der Luft verlieren sie das Bewusstsein oder sterben ab. Goldminenarbeiter und Bergleute nahmen Vögel als Beute: Während die Kanarienvögel singen, können Sie arbeiten. Wenn Sie die Klappe halten, befindet sich Benzin in der Mine und es ist Zeit zu gehen. Bergleute opferten einen kleinen Vogel, um lebend aus den Minen herauszukommen. Eine ähnliche Praxis hat sich in der IT wiedergefunden. Zum Beispiel bei der Standardaufgabe, eine neue Version eines Dienstes oder einer Anwendung für die Produktion bereitzustellen, mit vorherigem Testen. Die Testumgebung kann zu teuer sein, automatisierte Tests decken nicht alles ab, was wir möchten, und es ist riskant, die Qualität zu testen und zu opfern. In solchen Fällen hilft der Canary Deployment-Ansatz, wenn in einer neuen Version ein Teil des realen Produktionsverkehrs gestartet wird. Der Ansatz hilft dabei, die neue Version sicher für die Produktion zu testen und kleine Dinge für einen großen Zweck zu opfern. Genauer gesagt, wie der Ansatz funktioniert, was nützlich ist und wie er implementiert werden kann, wird Andrey Markelov (Andrey_V_Markelov) am Beispiel einer Implementierung bei Infobip.Andrey Markelov , ein führender Software-Ingenieur bei Infobip, entwickelt seit 11 Jahren Java-Anwendungen in den Bereichen Finanzen und Telekommunikation. Er entwickelt Open Source-Produkte, nimmt aktiv an der Atlassian Community teil und schreibt Plugins für Atlassian-Produkte. Evangelist Prometheus, Docker und Redis.
Eine ähnliche Praxis hat sich in der IT wiedergefunden. Zum Beispiel bei der Standardaufgabe, eine neue Version eines Dienstes oder einer Anwendung für die Produktion bereitzustellen, mit vorherigem Testen. Die Testumgebung kann zu teuer sein, automatisierte Tests decken nicht alles ab, was wir möchten, und es ist riskant, die Qualität zu testen und zu opfern. In solchen Fällen hilft der Canary Deployment-Ansatz, wenn in einer neuen Version ein Teil des realen Produktionsverkehrs gestartet wird. Der Ansatz hilft dabei, die neue Version sicher für die Produktion zu testen und kleine Dinge für einen großen Zweck zu opfern. Genauer gesagt, wie der Ansatz funktioniert, was nützlich ist und wie er implementiert werden kann, wird Andrey Markelov (Andrey_V_Markelov) am Beispiel einer Implementierung bei Infobip.Andrey Markelov , ein führender Software-Ingenieur bei Infobip, entwickelt seit 11 Jahren Java-Anwendungen in den Bereichen Finanzen und Telekommunikation. Er entwickelt Open Source-Produkte, nimmt aktiv an der Atlassian Community teil und schreibt Plugins für Atlassian-Produkte. Evangelist Prometheus, Docker und Redis.Über Infobip
Dies ist eine globale Telekommunikationsplattform, mit der Banken, Einzelhändler, Online-Shops und Transportunternehmen Nachrichten per SMS, Push, Brief und Sprachnachrichten an ihre Kunden senden können. In einem solchen Geschäft sind Stabilität und Zuverlässigkeit wichtig, damit Kunden Nachrichten rechtzeitig erhalten.Infobip IT-Infrastruktur in Zahlen:- 15 Rechenzentren auf der ganzen Welt;
- 500 einzigartige Dienste in Betrieb;
- 2500 Instanzen von Diensten, das ist viel mehr als Teams;
- 4,5 TB monatlicher Verkehr;
- 4,5 Milliarden Telefonnummern;
Das Geschäft wächst und damit die Anzahl der Veröffentlichungen. Wir führen täglich 60 Releases durch , weil Kunden mehr Funktionen und Fähigkeiten wünschen. Das ist aber schwierig - es gibt viele Dienste, aber nur wenige Teams. Sie müssen schnell Code schreiben, der in der Produktion fehlerfrei funktionieren soll.Veröffentlichungen
Eine typische Veröffentlichung bei uns geht so. Zum Beispiel gibt es die Dienste A, B, C, D und E, die jeweils von einem separaten Team entwickelt werden.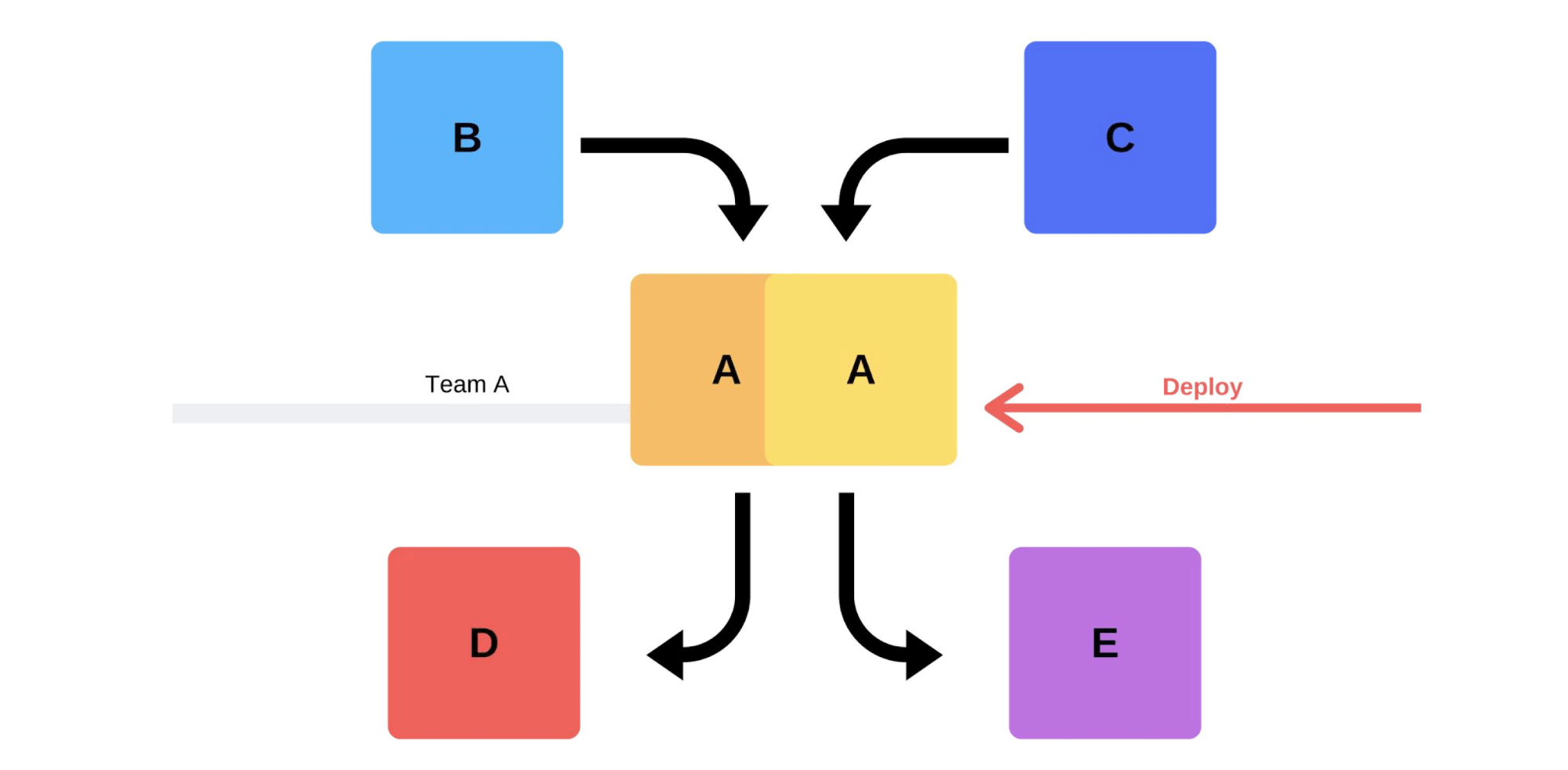 Irgendwann beschließt das Serviceteam A, eine neue Version bereitzustellen, aber die Serviceteams B, C, D und E sind sich dessen nicht bewusst. Es gibt zwei Möglichkeiten, wie Serviceteam A ankommt.Führt eine inkrementelle Freigabe durch: Zuerst wird eine Version ersetzt, dann die zweite.
Irgendwann beschließt das Serviceteam A, eine neue Version bereitzustellen, aber die Serviceteams B, C, D und E sind sich dessen nicht bewusst. Es gibt zwei Möglichkeiten, wie Serviceteam A ankommt.Führt eine inkrementelle Freigabe durch: Zuerst wird eine Version ersetzt, dann die zweite. Es gibt jedoch eine zweite Option: Das Team findet zusätzliche Kapazitäten und Maschinen , stellt eine neue Version bereit und wechselt dann den Router. Die Version beginnt mit der Produktion.
Es gibt jedoch eine zweite Option: Das Team findet zusätzliche Kapazitäten und Maschinen , stellt eine neue Version bereit und wechselt dann den Router. Die Version beginnt mit der Produktion. In jedem Fall treten nach der Bereitstellung fast immer Probleme auf, auch wenn die Version getestet wird. Sie können es mit Ihren Händen testen, es kann automatisiert werden, Sie können es nicht testen - es treten auf jeden Fall Probleme auf. Der einfachste und korrekteste Weg, sie zu lösen, besteht darin, auf die Arbeitsversion zurückzusetzen. Nur dann können Sie mit dem Schaden, den Ursachen und deren Behebung umgehen.Was wollen wir also?Wir brauchen keine Probleme. Wenn Kunden sie schneller finden als wir, wird dies unseren Ruf beeinträchtigen. Deshalb müssen wir Probleme schneller finden als Kunden . Indem wir proaktiv sind, minimieren wir den Schaden.Gleichzeitig wollen wir die Bereitstellung beschleunigenso dass dies schnell, einfach, von selbst und ohne Stress vom Team geschieht. Ingenieure, DevOps-Ingenieure und Programmierer müssen geschützt werden - die Veröffentlichung der neuen Version ist stressig. Ein Team ist kein Verbrauchsmaterial, wir bemühen uns, die Humanressourcen rational einzusetzen .
In jedem Fall treten nach der Bereitstellung fast immer Probleme auf, auch wenn die Version getestet wird. Sie können es mit Ihren Händen testen, es kann automatisiert werden, Sie können es nicht testen - es treten auf jeden Fall Probleme auf. Der einfachste und korrekteste Weg, sie zu lösen, besteht darin, auf die Arbeitsversion zurückzusetzen. Nur dann können Sie mit dem Schaden, den Ursachen und deren Behebung umgehen.Was wollen wir also?Wir brauchen keine Probleme. Wenn Kunden sie schneller finden als wir, wird dies unseren Ruf beeinträchtigen. Deshalb müssen wir Probleme schneller finden als Kunden . Indem wir proaktiv sind, minimieren wir den Schaden.Gleichzeitig wollen wir die Bereitstellung beschleunigenso dass dies schnell, einfach, von selbst und ohne Stress vom Team geschieht. Ingenieure, DevOps-Ingenieure und Programmierer müssen geschützt werden - die Veröffentlichung der neuen Version ist stressig. Ein Team ist kein Verbrauchsmaterial, wir bemühen uns, die Humanressourcen rational einzusetzen .Bereitstellungsprobleme
Der Clientverkehr ist unvorhersehbar . Es ist unmöglich vorherzusagen, wann der Client-Verkehr minimal sein wird. Wir wissen nicht, wo und wann Kunden ihre Kampagnen starten werden - vielleicht heute Abend in Indien und morgen in Hongkong. Angesichts des großen Zeitunterschieds garantiert eine Bereitstellung auch um 2 Uhr morgens nicht, dass die Kunden nicht darunter leiden.Anbieterprobleme . Boten und Anbieter sind unsere Partner. Manchmal treten Abstürze auf, die bei der Bereitstellung neuer Versionen zu Fehlern führen.Verteilte Teams . Die Teams, die die Client-Seite und das Backend entwickeln, befinden sich in verschiedenen Zeitzonen. Aus diesem Grund können sie sich oft nicht einigen.Rechenzentren können auf der Bühne nicht wiederholt werden. Es gibt 200 Racks in einem Rechenzentrum - um dies in der Sandbox zu wiederholen, funktioniert es nicht einmal ungefähr.Ausfallzeiten sind nicht erlaubt! Wir haben ein akzeptables Maß an Zugänglichkeit (Fehlerbudget), wenn wir beispielsweise 99,99% der Zeit arbeiten, und die verbleibenden Prozentsätze sind „das Recht, Fehler zu machen“. Es ist unmöglich, eine 100% ige Zuverlässigkeit zu erreichen, aber es ist wichtig, Ausfallzeiten und Ausfallzeiten ständig zu überwachen.Klassische Lösungen
Schreiben Sie Code ohne Fehler . Als ich ein junger Entwickler war, kamen Manager mit der Bitte auf mich zu, ohne Fehler zu veröffentlichen, aber das ist nicht immer möglich.Schreiben Sie Tests . Tests funktionieren, aber manchmal ist es überhaupt nicht das, was das Unternehmen will. Geld verdienen ist keine Testaufgabe.Test auf der Bühne . In den 3,5 Jahren meiner Arbeit bei Infobip habe ich noch nie einen Bühnenzustand gesehen, der zumindest teilweise mit der Produktion zusammenfällt. Wir haben sogar versucht, diese Idee zu entwickeln: Zuerst hatten wir eine Bühne, dann eine Vorproduktion und dann eine Vorproduktion. Aber das half auch nicht - sie stimmten nicht einmal in Bezug auf die Macht überein. Mit Stage können wir grundlegende Funktionen garantieren, aber wir wissen nicht, wie es unter Last funktionieren wird.Die Veröffentlichung erfolgt durch den Entwickler.Dies ist eine gute Vorgehensweise: Selbst wenn jemand den Namen eines Kommentars ändert, wird er sofort zur Produktion hinzugefügt. Dies hilft, Verantwortung zu entwickeln und die vorgenommenen Änderungen nicht zu vergessen.Es gibt auch zusätzliche Schwierigkeiten. Für einen Entwickler ist dies stressig - verbringen Sie viel Zeit damit, alles manuell zu überprüfen.Vereinbarte Veröffentlichungen . Diese Option bietet normalerweise die Verwaltung: "Lassen Sie uns vereinbaren, dass Sie jeden Tag neue Versionen testen und hinzufügen." Das funktioniert nicht: Es gibt immer ein Team, das auf alle anderen wartet oder umgekehrt.
Wir haben sogar versucht, diese Idee zu entwickeln: Zuerst hatten wir eine Bühne, dann eine Vorproduktion und dann eine Vorproduktion. Aber das half auch nicht - sie stimmten nicht einmal in Bezug auf die Macht überein. Mit Stage können wir grundlegende Funktionen garantieren, aber wir wissen nicht, wie es unter Last funktionieren wird.Die Veröffentlichung erfolgt durch den Entwickler.Dies ist eine gute Vorgehensweise: Selbst wenn jemand den Namen eines Kommentars ändert, wird er sofort zur Produktion hinzugefügt. Dies hilft, Verantwortung zu entwickeln und die vorgenommenen Änderungen nicht zu vergessen.Es gibt auch zusätzliche Schwierigkeiten. Für einen Entwickler ist dies stressig - verbringen Sie viel Zeit damit, alles manuell zu überprüfen.Vereinbarte Veröffentlichungen . Diese Option bietet normalerweise die Verwaltung: "Lassen Sie uns vereinbaren, dass Sie jeden Tag neue Versionen testen und hinzufügen." Das funktioniert nicht: Es gibt immer ein Team, das auf alle anderen wartet oder umgekehrt.Rauchtests
Ein weiterer Weg, um unsere Bereitstellungsprobleme zu lösen. Lassen Sie uns sehen, wie Rauchtests im vorherigen Beispiel funktionieren, wenn Team A eine neue Version bereitstellen möchte.Zunächst stellt das Team eine Instanz für die Produktion bereit. Nachrichten von Mocks an die Instanz simulieren den realen Verkehr, sodass er dem normalen täglichen Verkehr entspricht. Wenn alles in Ordnung ist, wechselt das Team die neue Version zum Benutzerverkehr.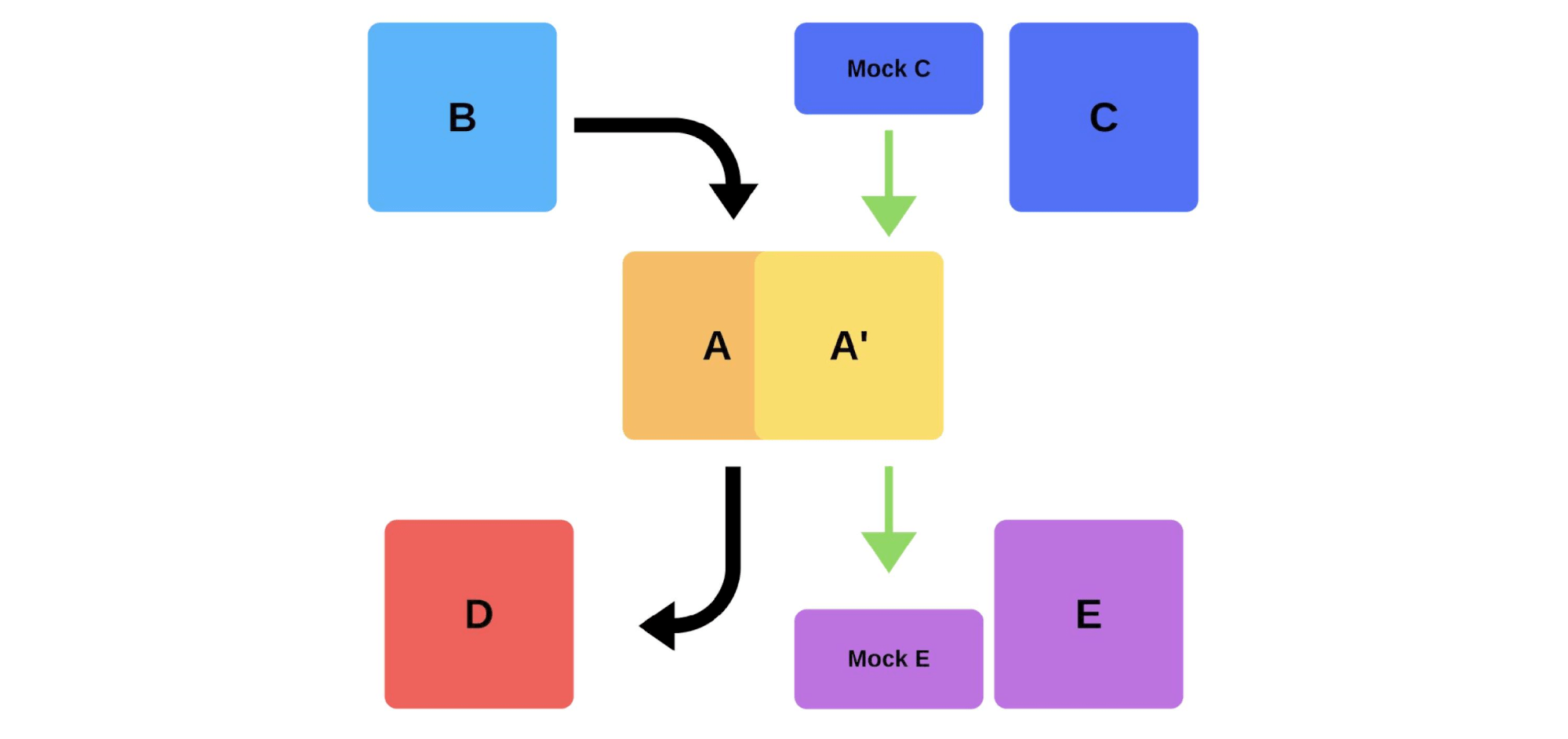 Die zweite Möglichkeit besteht darin, mit zusätzlichem Eisen zu arbeiten. Das Team testet es für die Produktion, wechselt es dann und alles funktioniert.
Die zweite Möglichkeit besteht darin, mit zusätzlichem Eisen zu arbeiten. Das Team testet es für die Produktion, wechselt es dann und alles funktioniert. Nachteile von Rauchtests:
Nachteile von Rauchtests:- Tests können nicht vertraut werden. Wo kann man den gleichen Verkehr wie für die Produktion bekommen? Sie können gestern oder vor einer Woche verwenden, aber es stimmt nicht immer mit dem aktuellen überein.
- Es ist schwer zu pflegen. Sie müssen Testkonten unterstützen und diese vor jeder Bereitstellung ständig zurücksetzen, wenn aktive Datensätze an das Repository gesendet werden. Dies ist schwieriger als das Schreiben eines Tests in Ihre Sandbox.
Der einzige Bonus hier ist, dass Sie die Leistung überprüfen können .Kanarische Veröffentlichungen
Aufgrund der Mängel bei Rauchtests haben wir begonnen, kanarische Freisetzungen zu verwenden.Eine ähnliche Praxis wie Bergleute, die Kanarienvögel zur Anzeige des Gasgehalts in der IT verwendeten. Wir starten ein bisschen echten Produktionsverkehr mit der neuen Version , während wir versuchen, das Service Level Agreement (SLA) einzuhalten. SLA ist unser „Recht, Fehler zu machen“, das wir einmal im Jahr (oder für einen anderen Zeitraum) anwenden können. Wenn alles gut geht, fügen Sie mehr Verkehr hinzu. Wenn nicht, werden wir die vorherigen Versionen zurückgeben.
Implementierung und Nuancen
Wie haben wir kanarische Veröffentlichungen implementiert? Beispielsweise sendet eine Gruppe von Kunden Nachrichten über unseren Service.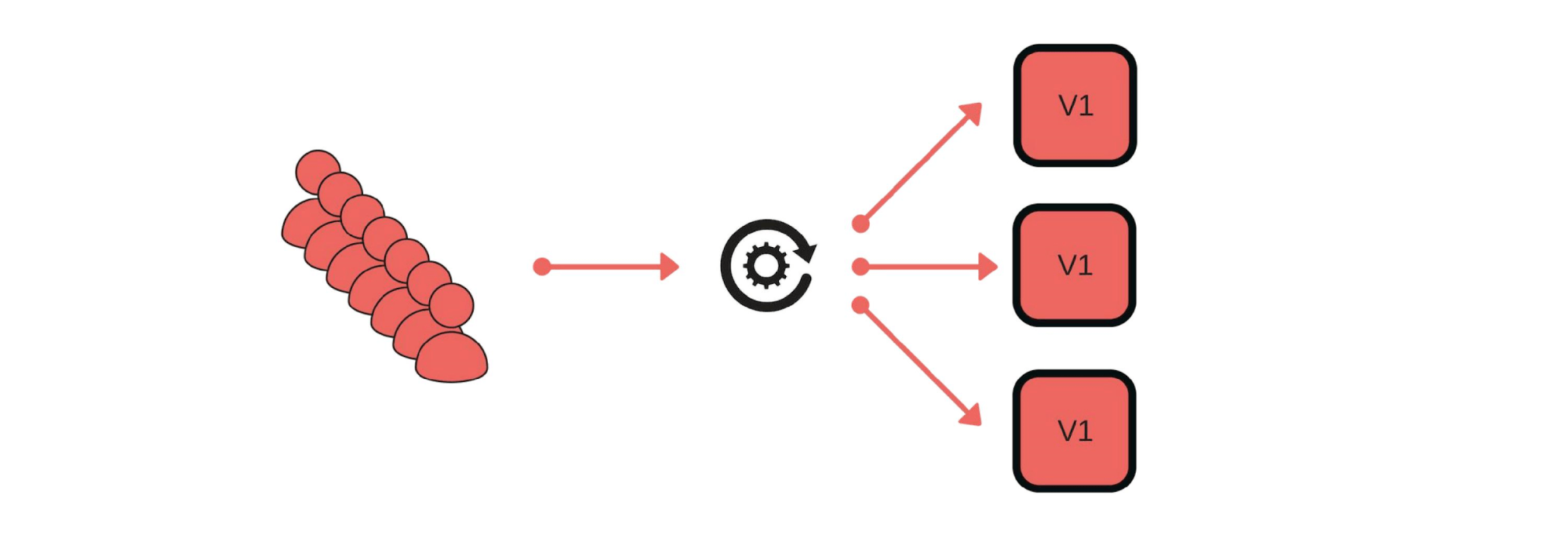 Die Bereitstellung sieht folgendermaßen aus: Entfernen Sie einen Knoten unter dem Balancer (1), ändern Sie die Version (2) und starten Sie separat Datenverkehr (3).
Die Bereitstellung sieht folgendermaßen aus: Entfernen Sie einen Knoten unter dem Balancer (1), ändern Sie die Version (2) und starten Sie separat Datenverkehr (3). Im Allgemeinen ist jeder in der Gruppe glücklich, auch wenn ein Benutzer nicht glücklich ist. Wenn alles in Ordnung ist - ändern Sie alle Versionen.
Im Allgemeinen ist jeder in der Gruppe glücklich, auch wenn ein Benutzer nicht glücklich ist. Wenn alles in Ordnung ist - ändern Sie alle Versionen. Ich werde schematisch zeigen, wie es in den meisten Fällen nach Microservices aussieht.Es gibt Service Discovery und zwei weitere Services: S1N1 und S2. Der erste Dienst (S1N1) benachrichtigt die Dienstermittlung beim Start, und die Dienstermittlung merkt sich dies. Der zweite Dienst mit zwei Knoten (S2N1 und S2N2) benachrichtigt die Diensterkennung ebenfalls beim Start.
Ich werde schematisch zeigen, wie es in den meisten Fällen nach Microservices aussieht.Es gibt Service Discovery und zwei weitere Services: S1N1 und S2. Der erste Dienst (S1N1) benachrichtigt die Dienstermittlung beim Start, und die Dienstermittlung merkt sich dies. Der zweite Dienst mit zwei Knoten (S2N1 und S2N2) benachrichtigt die Diensterkennung ebenfalls beim Start.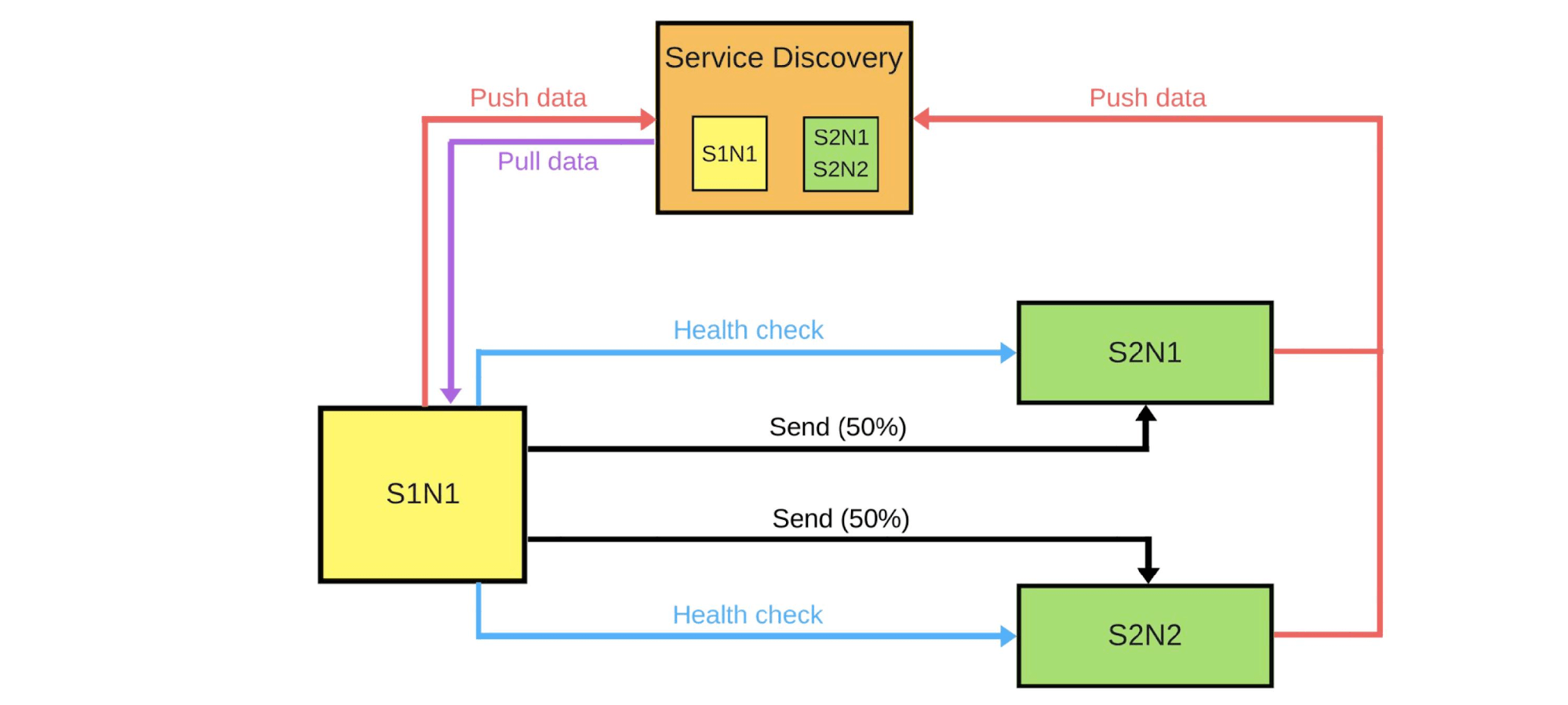 Der zweite Dienst für den ersten arbeitet als Server. Der erste fordert Informationen zu seinen Servern von Service Discovery an, und wenn er sie empfängt, sucht er sie und überprüft sie („Integritätsprüfung“). Wenn er prüft, wird er ihnen Nachrichten senden.Wenn jemand eine neue Version des zweiten Dienstes bereitstellen möchte, teilt er Service Discovery mit, dass der zweite Knoten ein kanarischer Knoten ist: Es wird weniger Datenverkehr an ihn gesendet, da er jetzt bereitgestellt wird. Wir entfernen den kanarischen Knoten unter dem Balancer und der erste Dienst sendet keinen Verkehr an ihn.
Der zweite Dienst für den ersten arbeitet als Server. Der erste fordert Informationen zu seinen Servern von Service Discovery an, und wenn er sie empfängt, sucht er sie und überprüft sie („Integritätsprüfung“). Wenn er prüft, wird er ihnen Nachrichten senden.Wenn jemand eine neue Version des zweiten Dienstes bereitstellen möchte, teilt er Service Discovery mit, dass der zweite Knoten ein kanarischer Knoten ist: Es wird weniger Datenverkehr an ihn gesendet, da er jetzt bereitgestellt wird. Wir entfernen den kanarischen Knoten unter dem Balancer und der erste Dienst sendet keinen Verkehr an ihn.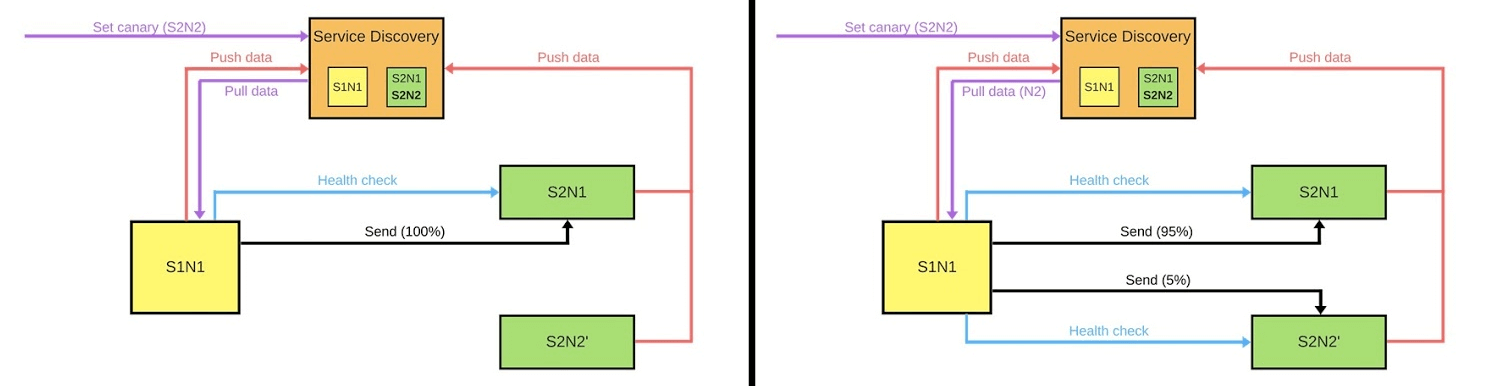 Wir ändern die Version und Service Discovery weiß, dass der zweite Knoten jetzt kanarisch ist - Sie können ihn weniger belasten (5%). Wenn alles in Ordnung ist, ändern Sie die Version, geben Sie die Last zurück und arbeiten Sie daran.Um all dies umzusetzen, brauchen wir:
Wir ändern die Version und Service Discovery weiß, dass der zweite Knoten jetzt kanarisch ist - Sie können ihn weniger belasten (5%). Wenn alles in Ordnung ist, ändern Sie die Version, geben Sie die Last zurück und arbeiten Sie daran.Um all dies umzusetzen, brauchen wir:- Balancieren;
- , , , ;
- , , ;
- — (deployment pipeline).
 Dies ist das erste, woran wir denken sollten. Es gibt zwei Ausgleichsstrategien.Die einfachste Option ist, wenn ein Knoten immer kanarisch ist . Dieser Knoten erhält immer weniger Datenverkehr und wir beginnen mit der Bereitstellung. Bei Problemen werden wir ihre Arbeit mit dem Einsatz und während des Einsatzes vergleichen. Wenn beispielsweise 2-mal mehr Fehler auftreten, hat sich der Schaden 2-mal erhöht.Der kanarische Knoten wird während des Bereitstellungsprozesses festgelegt . Wenn die Bereitstellung endet und wir den Status des kanarischen Knotens entfernen, wird das Verkehrsgleichgewicht wiederhergestellt. Mit weniger Autos erhalten wir eine ehrliche Verteilung.
Dies ist das erste, woran wir denken sollten. Es gibt zwei Ausgleichsstrategien.Die einfachste Option ist, wenn ein Knoten immer kanarisch ist . Dieser Knoten erhält immer weniger Datenverkehr und wir beginnen mit der Bereitstellung. Bei Problemen werden wir ihre Arbeit mit dem Einsatz und während des Einsatzes vergleichen. Wenn beispielsweise 2-mal mehr Fehler auftreten, hat sich der Schaden 2-mal erhöht.Der kanarische Knoten wird während des Bereitstellungsprozesses festgelegt . Wenn die Bereitstellung endet und wir den Status des kanarischen Knotens entfernen, wird das Verkehrsgleichgewicht wiederhergestellt. Mit weniger Autos erhalten wir eine ehrliche Verteilung.Überwachung
Der Eckpfeiler der kanarischen Veröffentlichungen. Wir müssen genau verstehen, warum wir dies tun und welche Metriken wir sammeln möchten.Beispiele für Metriken, die wir aus unseren Diensten erfassen.- , . , . , .
- (latency). , .
- (throughput).
- .
- 95% .
- -: . , , .
Beispiele für Metriken in den gängigsten Überwachungssystemen.Zähler Dies ist ein zunehmender Wert, zum Beispiel die Anzahl der Fehler. Es ist einfach, diese Metrik zu interpolieren und das Diagramm zu studieren: Gestern gab es 2 Fehler und heute 500, dann ist etwas schiefgegangen.Die Anzahl der Fehler pro Minute oder pro Sekunde ist der wichtigste Indikator, der mit dem Zähler berechnet werden kann. Diese Daten geben einen klaren Überblick über den Fernbetrieb des Systems. Betrachten Sie ein Beispiel für ein Diagramm der Anzahl der Fehler pro Sekunde für zwei Versionen eines Produktionssystems. In der ersten Version gab es nur wenige Fehler. Die Prüfung hat möglicherweise nicht funktioniert. In der zweiten Version ist alles viel schlimmer. Wir können mit Sicherheit sagen, dass es Probleme gibt, daher müssen wir diese Version zurücksetzen.Spur.Metriken ähneln dem Zähler, aber wir zeichnen Werte auf, die entweder zunehmen oder abnehmen können. Beispiel: Ausführungszeit für Abfragen oder Größe der Warteschlange.Die Grafik zeigt ein Beispiel für die Antwortzeit (Latenz). Die Grafik zeigt, dass die Versionen ähnlich sind, Sie können mit ihnen arbeiten. Bei genauem Hinsehen fällt jedoch auf, wie sich die Menge ändert. Wenn sich die Ausführungszeit von Anforderungen erhöht, wenn Benutzer hinzugefügt werden, ist sofort klar, dass es Probleme gibt - dies war zuvor nicht der Fall.
In der ersten Version gab es nur wenige Fehler. Die Prüfung hat möglicherweise nicht funktioniert. In der zweiten Version ist alles viel schlimmer. Wir können mit Sicherheit sagen, dass es Probleme gibt, daher müssen wir diese Version zurücksetzen.Spur.Metriken ähneln dem Zähler, aber wir zeichnen Werte auf, die entweder zunehmen oder abnehmen können. Beispiel: Ausführungszeit für Abfragen oder Größe der Warteschlange.Die Grafik zeigt ein Beispiel für die Antwortzeit (Latenz). Die Grafik zeigt, dass die Versionen ähnlich sind, Sie können mit ihnen arbeiten. Bei genauem Hinsehen fällt jedoch auf, wie sich die Menge ändert. Wenn sich die Ausführungszeit von Anforderungen erhöht, wenn Benutzer hinzugefügt werden, ist sofort klar, dass es Probleme gibt - dies war zuvor nicht der Fall. Zusammenfassung Einer der wichtigsten Indikatoren für das Geschäft sind Perzentile. Die Metrik zeigt, dass unser System in 95% der Fälle so funktioniert, wie wir es möchten. Wir können uns abfinden, wenn es irgendwo Probleme gibt, weil wir die allgemeine Tendenz verstehen, wie gut oder schlecht alles ist.
Zusammenfassung Einer der wichtigsten Indikatoren für das Geschäft sind Perzentile. Die Metrik zeigt, dass unser System in 95% der Fälle so funktioniert, wie wir es möchten. Wir können uns abfinden, wenn es irgendwo Probleme gibt, weil wir die allgemeine Tendenz verstehen, wie gut oder schlecht alles ist.Werkzeuge
ELK Stack . Sie können Canary mit Elasticsearch implementieren - wir schreiben Fehler hinein, wenn Ereignisse auftreten. Rufen Sie einfach die API auf, Sie können jederzeit Fehler erhalten und diese mit vorherigen Segmenten vergleichen : GET /applg/_cunt?q=level:errr.Prometheus. Er zeigte sich gut in Infobip. Sie können mehrdimensionale Metriken implementieren, da Beschriftungen verwendet werden.Wir können verwenden level, instance, service, sie in einem einzigen System zu kombinieren. Mit offsetihm können Sie beispielsweise den Wert einer Woche mit nur einem Befehl anzeigen GET /api/v1/query?query={query}, wobei {query}:rate(logback_appender_total{
level="error",
instance=~"$instance"
}[5m] offset $offset_value)
Versionsanalyse
Es gibt verschiedene Versionsstrategien.Siehe Metriken nur für kanarische Knoten. Eine der einfachsten Optionen: Eine neue Version bereitstellen und nur die Arbeit studieren. Wenn der Ingenieur zu diesem Zeitpunkt beginnt, die Protokolle zu studieren und die Seiten ständig nervös neu zu laden, unterscheidet sich diese Lösung nicht von den anderen.Ein Kanarienknoten wird mit jedem anderen Knoten verglichen . Dies ist ein Vergleich mit anderen Instanzen, die mit vollem Datenverkehr ausgeführt werden. Wenn zum Beispiel bei kleinem Verkehr die Dinge schlechter oder nicht besser sind als in realen Fällen, stimmt etwas nicht.Ein Kanarienknoten wird in der Vergangenheit mit sich selbst verglichen. Die für Kanarienvogel zugewiesenen Knoten können mit historischen Daten verglichen werden. Wenn zum Beispiel vor einer Woche alles in Ordnung war, können wir uns auf diese Daten konzentrieren, um die aktuelle Situation zu verstehen.Automatisierung
Wir möchten Ingenieure von manuellen Vergleichen befreien, daher ist es wichtig, die Automatisierung zu implementieren. Der Bereitstellungs-Pipeline-Prozess sieht normalerweise folgendermaßen aus:- wir starten;
- Entfernen Sie den Knoten unter dem Balancer.
- setze den kanarischen Knoten;
- Schalten Sie den Balancer bereits mit begrenztem Datenverkehr ein.
- vergleichen Sie.
 An dieser Stelle implementieren wir einen automatischen Vergleich . Wie es aussehen kann und warum es besser ist, als nach der Bereitstellung zu überprüfen, betrachten wir das Beispiel von Jenkins.Dies ist die Pipeline nach Groovy.
An dieser Stelle implementieren wir einen automatischen Vergleich . Wie es aussehen kann und warum es besser ist, als nach der Bereitstellung zu überprüfen, betrachten wir das Beispiel von Jenkins.Dies ist die Pipeline nach Groovy.while (System.currentTimeMillis() < endCanaryTs) {
def isOk = compare(srv, canary, time, base, offset, metrics)
if (isOk) {
sleep DEFAULT SLEEP
} else {
echo "Canary failed, need to revert"
return false
}
}
Hier im Zyklus legen wir fest, dass wir den neuen Knoten für eine Stunde vergleichen. Wenn der kanarische Prozess den Prozess noch nicht beendet hat, rufen wir die Funktion auf. Sie berichtet, dass alles in Ordnung ist oder nicht : def isOk = compare(srv, canary, time, base, offset, metrics).Wenn alles in Ordnung ist - sleep DEFAULT SLEEPzum Beispiel für eine Sekunde, und fahren Sie fort. Wenn nicht, beenden wir - die Bereitstellung ist fehlgeschlagen.Beschreibung der Metrik. Mal sehen, wie eine Funktion compaream Beispiel von DSL aussehen könnte .metric(
'errorCounts',
'rate(errorCounts{node=~"$canaryInst"}[5m] offset $offset)',
{ baseValue, canaryValue ->
if (canaryValue > baseValue * 1.3) return false
return true
}
)
Angenommen, wir vergleichen die Anzahl der Fehler und möchten die Anzahl der Fehler pro Sekunde in den letzten 5 Minuten wissen.Wir haben zwei Werte: Basis- und Kanarienknoten. Der Wert des Kanarischen Knotens ist der aktuelle. Basic - baseValueist der Wert eines anderen nicht kanarischen Knotens. Wir vergleichen die Werte miteinander gemäß der Formel, die wir basierend auf unseren Erfahrungen und Beobachtungen festlegen. Wenn der Wert canaryValueschlecht ist, ist die Bereitstellung fehlgeschlagen, und wir führen ein Rollback durch.Warum ist das alles notwendig?Der Mensch kann nicht Hunderte und Tausende von Metriken überprüfenvor allem, um es schnell zu machen. Ein automatischer Vergleich hilft bei der Überprüfung aller Metriken und macht Sie schnell auf Probleme aufmerksam. Die Benachrichtigungszeit ist entscheidend: Wenn in den letzten 2 Sekunden etwas passiert ist, ist der Schaden nicht so groß wie vor 15 Minuten. Bis jemand ein Problem bemerkt, Support schreibt und wir Kunden verlieren können, um den Support zurückzusetzen.Wenn der Prozess gut verlaufen ist und alles in Ordnung ist, werden alle anderen Knoten automatisch bereitgestellt. Ingenieure tun derzeit nichts. Erst wenn sie Kanarienvogel betreiben, entscheiden sie, welche Metriken sie benötigen, wie lange sie den Vergleich durchführen und welche Strategie sie verwenden möchten. Wenn es Probleme gibt, rollen wir den Kanarischen Knoten automatisch zurück, arbeiten an früheren Versionen und beheben die gefundenen Fehler. Anhand von Metriken können sie den Schaden der neuen Version leicht finden und erkennen.
Wenn es Probleme gibt, rollen wir den Kanarischen Knoten automatisch zurück, arbeiten an früheren Versionen und beheben die gefundenen Fehler. Anhand von Metriken können sie den Schaden der neuen Version leicht finden und erkennen.Hindernisse
Dies umzusetzen ist natürlich nicht einfach. Zunächst brauchen wir ein gemeinsames Überwachungssystem . Ingenieure haben ihre eigenen Metriken, Support und Analysten haben unterschiedliche, und das Geschäft hat den dritten Platz. Ein gemeinsames System ist eine gemeinsame Sprache, die von Unternehmen und Entwicklung gesprochen wird.In der Praxis muss die Stabilität von Metriken überprüft werden . Die Überprüfung hilft zu verstehen, welche Mindestmetriken zur Qualitätssicherung erforderlich sind .Wie erreicht man das? Verwenden Sie den Kanarischen Dienst nicht zum Zeitpunkt der Bereitstellung . Wir fügen der alten Version einen bestimmten Dienst hinzu, der zu jedem Zeitpunkt in der Lage ist, jeden zugewiesenen Knoten zu übernehmen und den Datenverkehr ohne Bereitstellung zu reduzieren. Nach dem Vergleich: Wir untersuchen Fehler und suchen nach dieser Linie, wenn wir Qualität erreichen.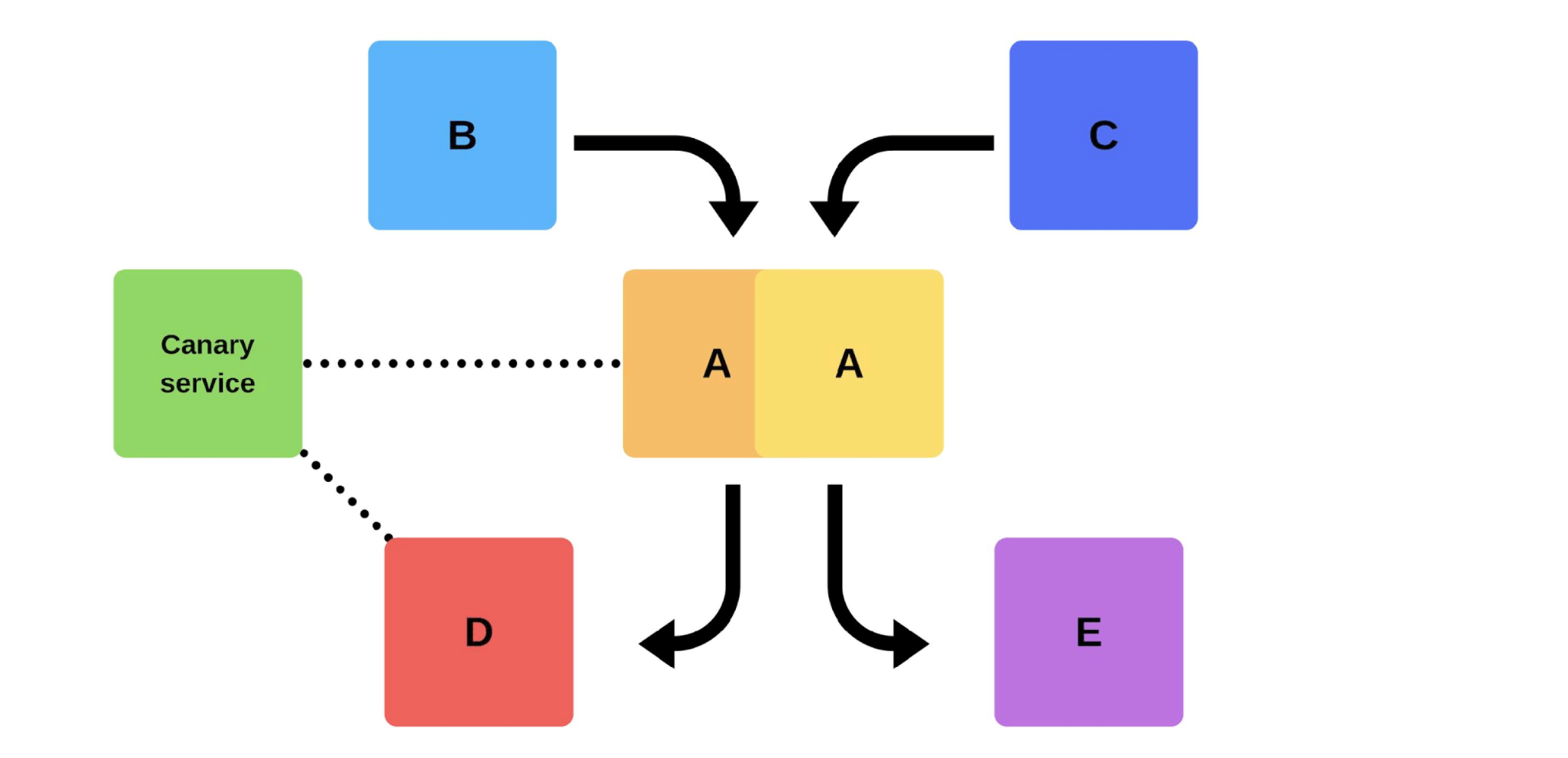
Welchen Nutzen haben wir aus kanarischen Veröffentlichungen?
Minimiert den Prozentsatz des Schadens durch Fehler. Die meisten Bereitstellungsfehler treten aufgrund von Inkonsistenzen bei einigen Daten oder Prioritäten auf. Solche Fehler sind viel kleiner geworden, weil wir das Problem in den ersten Sekunden lösen können.Optimierte die Arbeit von Teams. Anfänger haben ein „Recht, einen Fehler zu machen“: Sie können ohne Angst vor Fehlern in der Produktion eingesetzt werden, eine zusätzliche Initiative erscheint, ein Anreiz zur Arbeit. Wenn sie etwas zerbrechen, ist es nicht kritisch und die falsche Person wird nicht gefeuert.Automatisierte Bereitstellung . Dies ist nicht mehr wie zuvor ein manueller Prozess, sondern ein wirklich automatisierter. Aber es dauert länger.Hervorgehobene wichtige Metriken. Das gesamte Unternehmen, angefangen bei Unternehmen und Ingenieuren, versteht, was in unserem Produkt wirklich wichtig ist, welche Metriken beispielsweise den Abfluss und den Zustrom von Benutzern messen. Wir steuern den Prozess: Wir testen Metriken, führen neue ein und sehen, wie die alten funktionieren, um ein System aufzubauen, das Geld produktiver macht.Wir haben viele coole Praktiken und Systeme, die uns helfen. Trotzdem bemühen wir uns, Profis zu sein und unsere Arbeit effizient zu erledigen, unabhängig davon, ob wir ein System haben, das uns hilft oder nicht.— TechLead Conf. , , — .
TechLead Conf 8 9 . , , — , .