Hunderte, Tausende und in einigen Diensten drehen sich Millionen von Warteschlangen, durch die eine große Datenmenge geleitet wird, unter der Haube unseres Produkts. All dies muss auf magische Weise verarbeitet und nicht erschossen werden. In diesem Beitrag werde ich Ihnen erklären, welche architektonischen Ansätze wir zu Hause verwenden, wenn wir einen relativ bescheidenen Technologie-Stack haben und kein kleines Rechenzentrum in unserer „Speisekammer“ haben.
Was haben wir?
Einerseits haben wir also einen bekannten Technologie-Stack: Nginx, PHP, PostgreSQL, Redis. Andererseits treten jede Minute Zehntausende von Ereignissen in unserem System auf, und in der Spitze können Hunderttausende von Ereignissen erreicht werden. Um zu verdeutlichen, was diese Ereignisse sind und wie wir darauf reagieren sollen, werde ich einen kleinen Produkt-Exkurs durchführen. Anschließend werde ich Ihnen erläutern, wie wir das ereignisbasierte Automatisierungssystem entwickelt haben.ManyChat ist eine Plattform für die Marketingautomatisierung. Der Eigentümer der Facebook-Seite kann sie mit unserer Plattform verbinden und die Automatisierung der Interaktion mit seinen Abonnenten konfigurieren (dh einen Chat-Bot erstellen). Die Automatisierung besteht normalerweise aus vielen Interaktionsketten, die möglicherweise nicht miteinander verbunden sind. Innerhalb dieser Automatisierungsketten können bestimmte Aktionen mit dem Teilnehmer ausgeführt werden, z. B. das Zuweisen eines bestimmten Tags im System oder das Zuweisen / Ändern des Werts eines Felds auf der Karte eines Teilnehmers. Mit diesen Daten können Sie die Zielgruppe weiter segmentieren und eine relevantere Interaktion mit den Abonnenten der Seite aufbauen.Unsere Kunden wollten unbedingt eine ereignisbasierte Automatisierung - die Möglichkeit, die Ausführung einer Aktion anzupassen, wenn ein bestimmtes Ereignis innerhalb des Abonnenten ausgelöst wird (z. B. Tagging).Da ein Triggerereignis von verschiedenen Automatisierungsketten aus funktionieren kann, ist es wichtig, dass es für alle ereignisbasierten Aktionen auf der Clientseite einen einzigen Konfigurationspunkt gibt. Auf unserer Verarbeitungsseite sollte es einen einzigen Bus geben, der die Änderung im Kontext des Teilnehmers von verschiedenen Automatisierungspunkten aus verarbeitet.In unserem System gibt es einen gemeinsamen Bus, über den alle mit Teilnehmern auftretenden Ereignisse übertragen werden. Dies sind mehr als 500 Millionen Ereignisse pro Tag. Ihre Verarbeitung ist ziemlich heikel - dies ist ein Datensatz im Data Warehouse, sodass der Seiteninhaber die Möglichkeit hat, historisch alles zu sehen, was seinen Abonnenten passiert ist.Es scheint, dass wir zur Implementierung eines ereignisbasierten Systems bereits über alles verfügen und es ausreicht, unsere Geschäftslogik in die Verarbeitung eines gemeinsamen Ereignisbusses zu integrieren. Wir haben jedoch bestimmte Anforderungen an unser neues System:- Wir möchten keine Leistungseinbußen bei der Verarbeitung des Hauptereignisbusses erzielen
- Für uns ist es wichtig, die Reihenfolge der Nachrichtenverarbeitung im neuen System beizubehalten, da dies möglicherweise mit der Geschäftslogik des Kunden zusammenhängt, der die Automatisierung einrichtet
- Vermeiden Sie die Auswirkungen von lauten Nachbarn, wenn aktive Seiten mit einer großen Anzahl von Abonnenten die Warteschlange verstopfen und die Verarbeitung von Ereignissen "kleiner" Seiten blockieren
Wenn wir die Verarbeitung unserer Logik in die Verarbeitung eines gemeinsamen Ereignisbusses integrieren, wird die Leistung erheblich beeinträchtigt, da jedes Ereignis auf Übereinstimmung mit der konfigurierten Automatisierung überprüft werden muss. Im Rahmen des Automatisierungs-Setups können bestimmte Filter angewendet werden (z. B. die Automatisierung starten, wenn ein Ereignis nur für weibliche Kunden ausgelöst wird, die älter als 30 Jahre sind). Das heißt, wenn Ereignisse im Hauptbus verarbeitet werden, wird eine große Anzahl zusätzlicher Anforderungen an die Datenbank verarbeitet, und es wird auch eine ziemlich schwere Logik gestartet, die den aktuellen Teilnehmerkontext mit den Automatisierungseinstellungen vergleicht. Diese Option passt nicht zu uns, deshalb haben wir weiter nachgedacht.
Organisation einer Kaskade von Warteschlangen
Da unsere mit dem ereignisbasierten System verknüpfte Geschäftslogik sehr gut von der Logik zur Verarbeitung von Ereignissen vom Hauptbus zu trennen ist, entscheiden wir uns, die vom gemeinsam genutzten Bus benötigten Ereignistypen für die weitere Verarbeitung in einem separaten Datenstrom in eine separate Warteschlange zu stellen. Somit beseitigen wir das Problem, das mit einer Verschlechterung der Leistung bei der Verarbeitung des Hauptereignisbusses verbunden ist.Gleichzeitig entscheiden wir, was es cool wäre, Ereignisse in die nächste Kaskadenwarteschlange zu übertragen, um diese Ereignisse für jeden Bot in separate Warteschlangen zu stellen. So isolieren wir die Aktivität jedes Bots mit dem Rahmen seiner Runde, wodurch wir das Problem lösen können, das mit der Wirkung von lauten Nachbarn verbunden ist.Unser Datenflussdiagramm sieht nun folgendermaßen aus: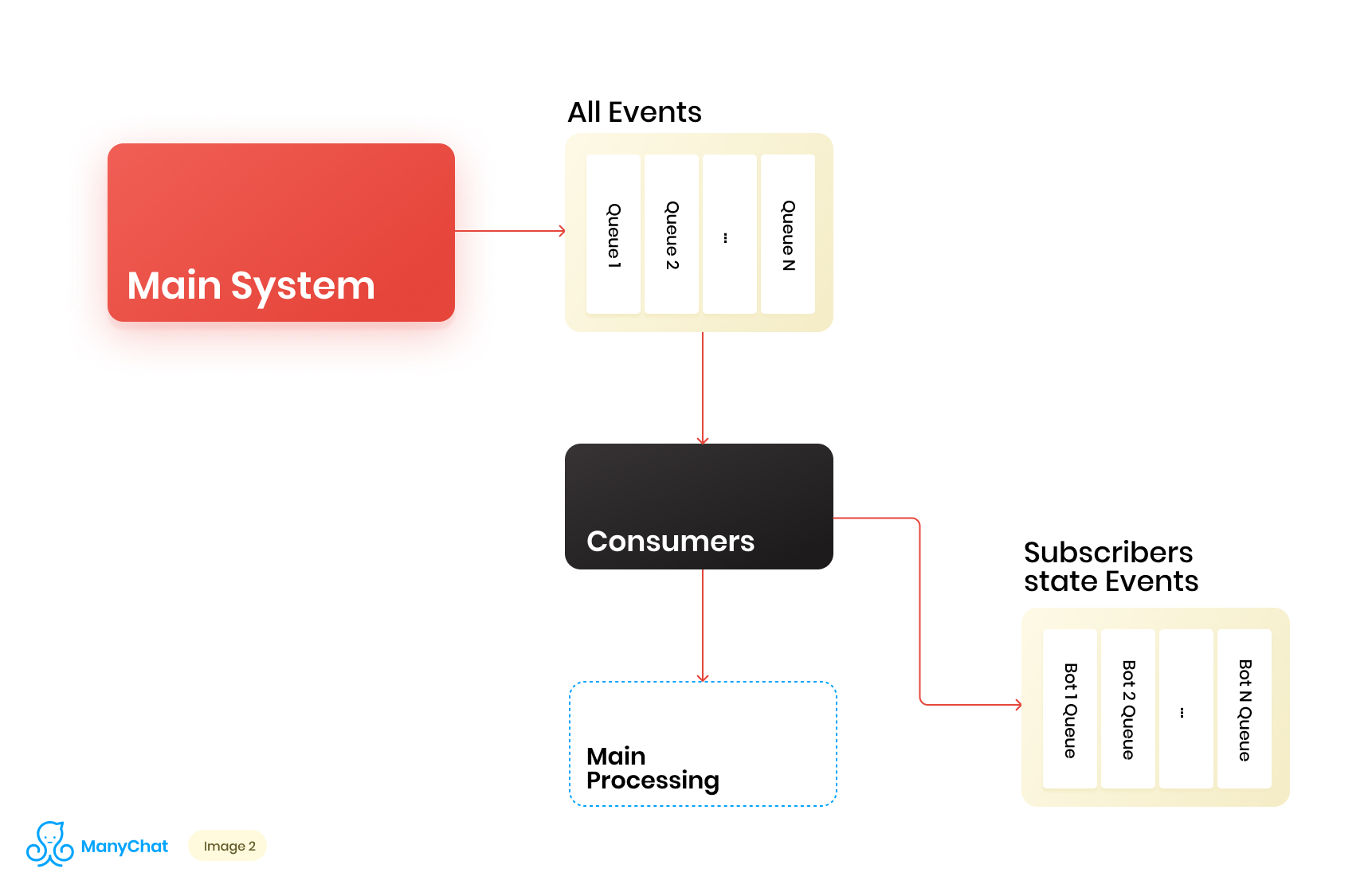 Damit dieses Schema funktioniert, müssen wir jedoch das Problem der Verarbeitung neuer Warteschlangen lösen.Auf unserer Plattform befinden sich mehr als 1 Million verbundene Seiten (Bots). Dies bedeutet, dass wir möglicherweise nur auf der Ebene der ereignisbasierten Ebene ~ 1 Million Warteschlangen in unserem Schema erhalten können. Aus technischer Sicht ist dies für uns nicht beängstigend. Als Warteschlangenserver verwenden wir Redis mit seinen Standarddatentypen wie LIST, SORTED SET und anderen. Dies bedeutet, wer jede Warteschlange ist die Standarddatenstruktur für Redis im RAM, die im laufenden Betrieb erstellt oder gelöscht werden kann, wodurch wir eine große Anzahl von Warteschlangen in unserem System einfach und flexibel betreiben können. Ich werde in einem separaten Beitrag ausführlicher auf die Verwendung von Redis als Warteschlangenserver mit technischen Details eingehen, aber jetzt kehren wir zu unserer Architektur zurück.Es ist klar, dass jeder Bot eine andere Aktivität hat und dass die Wahrscheinlichkeit, 1 Million Warteschlangen im Status "Jetzt verarbeiten müssen" zu erhalten, äußerst gering ist. Aber zu einem bestimmten Zeitpunkt ist es durchaus möglich, dass wir einige Zehntausende aktive Warteschlangen haben, die verarbeitet werden müssen. Die Anzahl dieser Warteschlangen ändert sich ständig. Diese Warteschlangen selbst ändern sich ebenfalls, einige werden vollständig subtrahiert und gelöscht, einige werden dynamisch erstellt und mit Ereignissen zur Verarbeitung gefüllt. Dementsprechend müssen wir einen effektiven Weg finden, um damit umzugehen.
Damit dieses Schema funktioniert, müssen wir jedoch das Problem der Verarbeitung neuer Warteschlangen lösen.Auf unserer Plattform befinden sich mehr als 1 Million verbundene Seiten (Bots). Dies bedeutet, dass wir möglicherweise nur auf der Ebene der ereignisbasierten Ebene ~ 1 Million Warteschlangen in unserem Schema erhalten können. Aus technischer Sicht ist dies für uns nicht beängstigend. Als Warteschlangenserver verwenden wir Redis mit seinen Standarddatentypen wie LIST, SORTED SET und anderen. Dies bedeutet, wer jede Warteschlange ist die Standarddatenstruktur für Redis im RAM, die im laufenden Betrieb erstellt oder gelöscht werden kann, wodurch wir eine große Anzahl von Warteschlangen in unserem System einfach und flexibel betreiben können. Ich werde in einem separaten Beitrag ausführlicher auf die Verwendung von Redis als Warteschlangenserver mit technischen Details eingehen, aber jetzt kehren wir zu unserer Architektur zurück.Es ist klar, dass jeder Bot eine andere Aktivität hat und dass die Wahrscheinlichkeit, 1 Million Warteschlangen im Status "Jetzt verarbeiten müssen" zu erhalten, äußerst gering ist. Aber zu einem bestimmten Zeitpunkt ist es durchaus möglich, dass wir einige Zehntausende aktive Warteschlangen haben, die verarbeitet werden müssen. Die Anzahl dieser Warteschlangen ändert sich ständig. Diese Warteschlangen selbst ändern sich ebenfalls, einige werden vollständig subtrahiert und gelöscht, einige werden dynamisch erstellt und mit Ereignissen zur Verarbeitung gefüllt. Dementsprechend müssen wir einen effektiven Weg finden, um damit umzugehen.Verarbeitung eines riesigen Pools von Warteschlangen
Wir haben also eine Reihe von Warteschlangen. Zu jedem Zeitpunkt kann es eine zufällige Menge geben. Eine wichtige Bedingung für die Verarbeitung jeder Warteschlange, die zu Beginn seines Beitrags erwähnt wurde, ist, dass Ereignisse auf jeder Seite streng nacheinander verarbeitet werden sollten. Dies bedeutet, dass zu einem bestimmten Zeitpunkt nicht jede Warteschlange von mehr als einem Mitarbeiter verarbeitet werden kann, um Wettbewerbsprobleme zu vermeiden.Das Verhältnis von Warteschlangen zu Handlern 1: 1 zu machen, ist jedoch eine zweifelhafte Aufgabe. Die Anzahl der Warteschlangen ändert sich ständig, sowohl nach oben als auch nach unten. Die Anzahl der ausgeführten Handler ist ebenfalls nicht unendlich, zumindest haben wir eine Einschränkung seitens des Betriebssystems und der Hardware, und wir möchten nicht, dass Mitarbeiter in leeren Warteschlangen untätig bleiben. Um das Problem der Interaktion zwischen Handlern und Warteschlangen zu lösen, haben wir ein Round-Robin-System implementiert, um unseren Warteschlangenpool zu verarbeiten.Und hier kam uns die Kontrolllinie zu Hilfe. Wenn das Ereignis vom gemeinsam genutzten Bus an die ereignisbasierte Warteschlange eines bestimmten Bots weitergeleitet wird, wird auch die Kennung dieser Bot-Warteschlange in die Steuerwarteschlange gestellt. In der Steuerwarteschlange werden nur die Kennungen der Warteschlangen gespeichert, die sich im Pool befinden und verarbeitet werden müssen. In der Steuerwarteschlange werden nur eindeutige Werte gespeichert, dh dieselbe Bot-Warteschlangen-ID wird nur einmal in der Steuerwarteschlange gespeichert, unabhängig davon, wie oft sie dort geschrieben wird. Auf Redis wird dies mithilfe der Datenstruktur SORTED SET implementiert.Ferner können wir eine bestimmte Anzahl von Arbeitern unterscheiden, von denen jeder von der Kontrollwarteschlange seine Kennung der Bot-Warteschlange zur Verarbeitung erhält. Somit verarbeitet jeder Mitarbeiter den Block unabhängig von der ihm zugewiesenen Warteschlange. Nach der Verarbeitung des Blocks gibt er die Kennung der verarbeiteten Warteschlange an das Steuerelement zurück und gibt sie damit an unser Round Robin zurück. Die Hauptsache ist, nicht zu vergessen, das Ganze mit Sperren zu versehen, damit zwei Arbeiter nicht dieselbe Bot-Warteschlange parallel verarbeiten können. Diese Situation ist möglich, wenn die Bot-ID in die Steuerwarteschlange eingeht, wenn sie bereits vom Worker verarbeitet wird. Für Sperren verwenden wir auch Redis als Schlüssel: Wertspeicher mit TTL.Wenn wir eine Aufgabe mit einer Bot-Warteschlangen-ID aus der Steuerwarteschlange übernehmen, setzen wir eine TTL-Sperre für die genommene Warteschlange und beginnen mit der Verarbeitung. Wenn der andere Verbraucher die Aufgabe mit der Warteschlange übernimmt, die bereits aus der Steuerwarteschlange verarbeitet wird, kann er nicht sperren, die Aufgabe an die Steuerwarteschlange zurückgeben und die nächste Aufgabe empfangen. Nachdem der Verbraucher die Bot-Warteschlange verarbeitet hat, hebt er die Sperre auf und wechselt zur Steuerungswarteschlange für die nächste Aufgabe.Das endgültige Schema lautet wie folgt:
Wenn das Ereignis vom gemeinsam genutzten Bus an die ereignisbasierte Warteschlange eines bestimmten Bots weitergeleitet wird, wird auch die Kennung dieser Bot-Warteschlange in die Steuerwarteschlange gestellt. In der Steuerwarteschlange werden nur die Kennungen der Warteschlangen gespeichert, die sich im Pool befinden und verarbeitet werden müssen. In der Steuerwarteschlange werden nur eindeutige Werte gespeichert, dh dieselbe Bot-Warteschlangen-ID wird nur einmal in der Steuerwarteschlange gespeichert, unabhängig davon, wie oft sie dort geschrieben wird. Auf Redis wird dies mithilfe der Datenstruktur SORTED SET implementiert.Ferner können wir eine bestimmte Anzahl von Arbeitern unterscheiden, von denen jeder von der Kontrollwarteschlange seine Kennung der Bot-Warteschlange zur Verarbeitung erhält. Somit verarbeitet jeder Mitarbeiter den Block unabhängig von der ihm zugewiesenen Warteschlange. Nach der Verarbeitung des Blocks gibt er die Kennung der verarbeiteten Warteschlange an das Steuerelement zurück und gibt sie damit an unser Round Robin zurück. Die Hauptsache ist, nicht zu vergessen, das Ganze mit Sperren zu versehen, damit zwei Arbeiter nicht dieselbe Bot-Warteschlange parallel verarbeiten können. Diese Situation ist möglich, wenn die Bot-ID in die Steuerwarteschlange eingeht, wenn sie bereits vom Worker verarbeitet wird. Für Sperren verwenden wir auch Redis als Schlüssel: Wertspeicher mit TTL.Wenn wir eine Aufgabe mit einer Bot-Warteschlangen-ID aus der Steuerwarteschlange übernehmen, setzen wir eine TTL-Sperre für die genommene Warteschlange und beginnen mit der Verarbeitung. Wenn der andere Verbraucher die Aufgabe mit der Warteschlange übernimmt, die bereits aus der Steuerwarteschlange verarbeitet wird, kann er nicht sperren, die Aufgabe an die Steuerwarteschlange zurückgeben und die nächste Aufgabe empfangen. Nachdem der Verbraucher die Bot-Warteschlange verarbeitet hat, hebt er die Sperre auf und wechselt zur Steuerungswarteschlange für die nächste Aufgabe.Das endgültige Schema lautet wie folgt: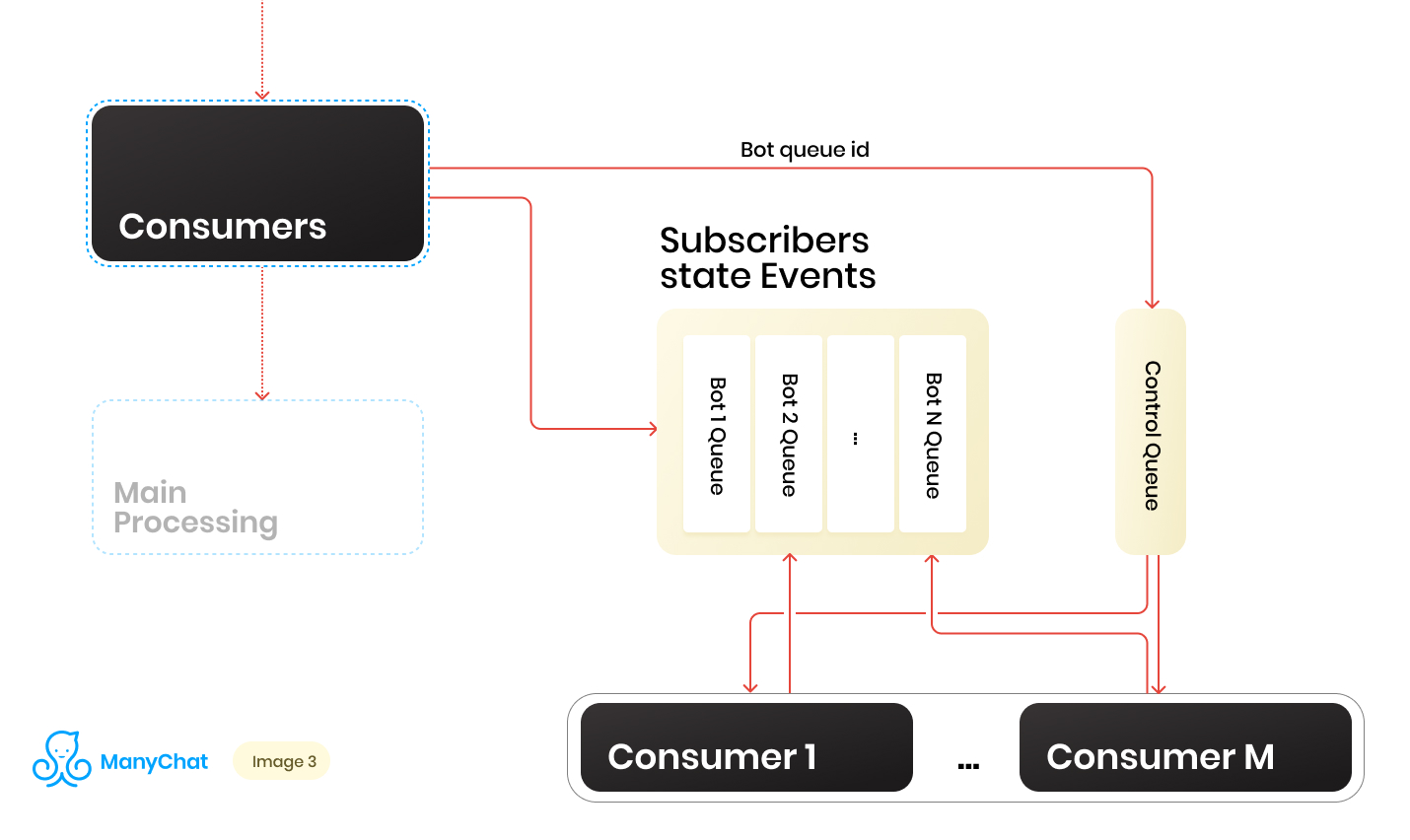 Als Ergebnis haben wir mit dem aktuellen Schema die wichtigsten identifizierten Probleme gelöst:
Als Ergebnis haben wir mit dem aktuellen Schema die wichtigsten identifizierten Probleme gelöst:- Leistungsabfall im Hauptereignisbus
- Verstoß gegen die Ereignisbehandlung
- Die Wirkung von lauten Nachbarn
Wie gehe ich mit dynamischer Last um?
Das Schema funktioniert, aber darin haben wir eine feste Anzahl von Verbrauchern für eine dynamische Anzahl von Warteschlangen. Offensichtlich werden wir bei diesem Ansatz bei der Verarbeitung von Warteschlangen jedes Mal durchhängen, wenn ihre Anzahl stark zunimmt. Es scheint schön für unsere Mitarbeiter zu sein, bei Bedarf dynamisch zu starten oder zu löschen. Es wäre auch schön, wenn dies die Einführung von neuem Code nicht wesentlich erschweren würde. In solchen Momenten juckt es die Hände sehr, Ihren Prozessmanager zu schreiben. In Zukunft haben wir genau das getan, aber diese Geschichte ist anders.Wir überlegten, warum wir nicht noch einmal alle bekannten und vertrauten Werkzeuge verwenden sollten. Also haben wir unsere interne API erhalten, die an einem Standardpaket von NGINX + PHP-FPM funktioniert. Infolgedessen können wir unseren festen Pool von Mitarbeitern durch APIs ersetzen und NGINX + PHP-FPM die Mitarbeiter selbst auflösen und verwalten lassen. Es reicht aus, zwischen der Kontrollwarteschlange und unserer internen API nur einen Kontrollkonsumenten zu haben, der Warteschlangenkennungen an unsere API sendet Verarbeitung, und die Warteschlange selbst wird in dem von PHP-FPM ausgelösten Worker verarbeitet.Das neue Schema war wie folgt: Es sieht gut aus, aber unser Kontrollkonsument arbeitet in einem Thread und unsere API arbeitet synchron. Dies bedeutet, dass der Verbraucher jedes Mal hängen bleibt, während PHP-FPM eine Warteschlange schleift. Das passt nicht zu uns.
Es sieht gut aus, aber unser Kontrollkonsument arbeitet in einem Thread und unsere API arbeitet synchron. Dies bedeutet, dass der Verbraucher jedes Mal hängen bleibt, während PHP-FPM eine Warteschlange schleift. Das passt nicht zu uns.Unsere API asynchron machen
Was aber, wenn wir eine Aufgabe an unsere API senden und sie dort die Geschäftslogik dreschen lassen könnten und unser Kontrollkonsument der nächsten Aufgabe in der Kontrollwarteschlange folgt, wonach sie zurück in die API gezogen wird, und so weiter. Gesagt, getan.Die Implementierung dauert einige Codezeilen, und der Proof of Concept sieht folgendermaßen aus:class Api {
public function actionDoSomething()
{
$data = $_POST;
$this->dropFPMSession();
}
protected function dropFPMSession()
{
ignore_user_abort(true);
ob_end_flush();
flush();
@session_write_close();
fastcgi_finish_request();
}
}
In der dropFPMSession () -Methode unterbrechen wir die Verbindung mit dem Client und geben ihm eine Antwort von 200, wonach wir jede schwere Logik in der Nachbearbeitung ausführen können. Der Kunde ist in unserem Fall der Kontrollverbraucher. Für ihn ist es wichtig, Aufgaben schnell aus der Steuerwarteschlange in die Verarbeitung auf der API zu verteilen und zu wissen, dass die Aufgabe die API erreicht hat.Mit diesem Ansatz haben wir eine Reihe von Kopfschmerzen beseitigt, die mit der dynamischen Steuerung der Verbraucher und ihrer automatischen Skalierung verbunden sind.Weiter skalierbar
Infolgedessen bestand die Architektur unseres Subsystems aus drei Schichten: Datenschicht, Prozesse und interne API. Gleichzeitig durchlaufen Informationen alle Datenströme darüber, zu welchem Bot das verarbeitete Ereignis / die verarbeitete Aufgabe gehört. Natürlich können wir unsere Schlüssel- / Bot-ID zum Sharding verwenden und gleichzeitig unser System horizontal skalieren.Wenn wir uns unsere Architektur als solide Einheit vorstellen, sieht sie folgendermaßen aus: Nachdem wir die Anzahl solcher Einheiten erhöht haben, können wir einen dünnen Balancer vor sie stellen, der unsere Ereignisse / Aufgaben abhängig vom Sharding-Schlüssel in die erforderlichen Einheiten wirft.
Nachdem wir die Anzahl solcher Einheiten erhöht haben, können wir einen dünnen Balancer vor sie stellen, der unsere Ereignisse / Aufgaben abhängig vom Sharding-Schlüssel in die erforderlichen Einheiten wirft. Somit erhalten wir einen großen Spielraum für die horizontale Skalierung unseres Systems.Bei der Implementierung der Geschäftslogik sollten Sie das Thread-Sicherheitskonzept nicht vergessen, da Sie sonst unerwartete Ergebnisse erzielen können.Ein solches Schema mit Kaskaden von Warteschlangen und der Entfernung schwerer Geschäftslogik in die asynchrone Verarbeitung wird seit mehr als zwei Jahren in mehreren Teilen des Systems verwendet. Die Last während dieser Zeit für jedes der Subsysteme hat sich verzehnfacht, und die vorgeschlagene Implementierung ermöglicht es uns, einfach und schnell zu skalieren. Gleichzeitig arbeiten wir weiter an unserem Hauptstapel, ohne ihn mit neuen Tools / Sprachen zu erweitern und ohne ihn zu erhöhen, wodurch die Einführung und Unterstützung neuer Tools überflüssig wird.
Somit erhalten wir einen großen Spielraum für die horizontale Skalierung unseres Systems.Bei der Implementierung der Geschäftslogik sollten Sie das Thread-Sicherheitskonzept nicht vergessen, da Sie sonst unerwartete Ergebnisse erzielen können.Ein solches Schema mit Kaskaden von Warteschlangen und der Entfernung schwerer Geschäftslogik in die asynchrone Verarbeitung wird seit mehr als zwei Jahren in mehreren Teilen des Systems verwendet. Die Last während dieser Zeit für jedes der Subsysteme hat sich verzehnfacht, und die vorgeschlagene Implementierung ermöglicht es uns, einfach und schnell zu skalieren. Gleichzeitig arbeiten wir weiter an unserem Hauptstapel, ohne ihn mit neuen Tools / Sprachen zu erweitern und ohne ihn zu erhöhen, wodurch die Einführung und Unterstützung neuer Tools überflüssig wird.