Vor einigen Monaten haben wir EXPLAIN.tensor.ru angekündigt , einen öffentlichen Dienst zum Parsen und Visualisieren von Abfrageplänen für PostgreSQL.In der Vergangenheit haben Sie es bereits mehr als 6.000 Mal verwendet, aber eine der praktischen Funktionen könnte unbemerkt bleiben - dies sind strukturelle Hinweise , die ungefähr so aussehen: Hören Sie sie sich an und Ihre Anfragen werden „glatt und seidig“. :)Aber im Ernst, viele der Situationen, die die Anfrage langsam und „gefräßig“ in Bezug auf Ressourcen machen, sind typisch und können an der Struktur und den Daten des Plans erkannt werden .In diesem Fall muss nicht jeder einzelne Entwickler selbst nach einer Optimierungsoption suchen, sondern verlässt sich ausschließlich auf seine Erfahrung. Wir können ihm sagen, was hier passiert, was der Grund sein könnte und wie er mit der Lösung umgehen soll . Was wir getan haben.
Hören Sie sie sich an und Ihre Anfragen werden „glatt und seidig“. :)Aber im Ernst, viele der Situationen, die die Anfrage langsam und „gefräßig“ in Bezug auf Ressourcen machen, sind typisch und können an der Struktur und den Daten des Plans erkannt werden .In diesem Fall muss nicht jeder einzelne Entwickler selbst nach einer Optimierungsoption suchen, sondern verlässt sich ausschließlich auf seine Erfahrung. Wir können ihm sagen, was hier passiert, was der Grund sein könnte und wie er mit der Lösung umgehen soll . Was wir getan haben. Schauen wir uns diese Fälle genauer an - wie sie bestimmt werden und zu welchen Empfehlungen sie führen.Um einen besseren Einblick in das Thema zu erhalten, können Sie zuerst den entsprechenden Block aus meinem Bericht zu PGConf.Russia 2020 anhören und dann eine detaillierte Analyse jedes Beispiels durchführen:
Schauen wir uns diese Fälle genauer an - wie sie bestimmt werden und zu welchen Empfehlungen sie führen.Um einen besseren Einblick in das Thema zu erhalten, können Sie zuerst den entsprechenden Block aus meinem Bericht zu PGConf.Russia 2020 anhören und dann eine detaillierte Analyse jedes Beispiels durchführen:# 1: Index "Untersortierung"
Wann entsteht
Zeigen Sie die letzte Rechnung für den Kunden "LLC Bell" an.Wie man erkennt
-> Limit
-> Sort
-> Index [Only] Scan [Backward] | Bitmap Heap Scan
Empfehlungen
Verwenden Sie den Index zum Sortieren von Feldern .Beispiel:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, (random() * 1000)::integer fk_cli;
CREATE INDEX ON tbl(fk_cli);
SELECT
*
FROM
tbl
WHERE
fk_cli = 1
ORDER BY
pk DESC
LIMIT 1;
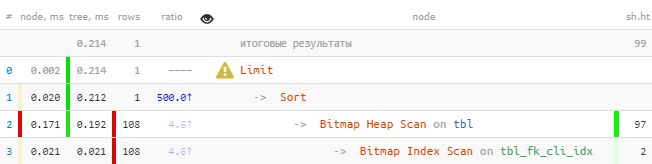 [siehe EXPLAIN.tensor.ru] Siekönnen sofort feststellen, dass der Index mehr als 100 Einträge abgezogen hat, die dann sortiert wurden und dann der einzige übrig war.Wir reparieren:
[siehe EXPLAIN.tensor.ru] Siekönnen sofort feststellen, dass der Index mehr als 100 Einträge abgezogen hat, die dann sortiert wurden und dann der einzige übrig war.Wir reparieren:DROP INDEX tbl_fk_cli_idx;
CREATE INDEX ON tbl(fk_cli, pk DESC);
 [siehe EXPLAIN.tensor.ru]Selbst bei einer solchen primitiven Stichprobe - 8,5-mal schneller und 33-mal weniger Messwerte . Der Effekt wird umso sichtbarer, je mehr „Fakten“ Sie für jeden Wert haben
[siehe EXPLAIN.tensor.ru]Selbst bei einer solchen primitiven Stichprobe - 8,5-mal schneller und 33-mal weniger Messwerte . Der Effekt wird umso sichtbarer, je mehr „Fakten“ Sie für jeden Wert haben fk.Ich stelle fest, dass ein solcher Index als "Präfix" nicht schlechter als der vorherige für andere Abfragen funktioniert fk, bei denen pkes keine Sortierung und keine Sortierung gab (mehr dazu finden Sie in meinem Artikel über das Auffinden ineffizienter Indizes ). Insbesondere wird ein expliziter Fremdschlüssel in diesem Bereich normal unterstützt .# 2: Indexschnittpunkt (BitmapAnd)
Wann entsteht
Zeigen Sie alle Verträge für den Kunden LLC Kolokolchik, die im Auftrag von NAO Buttercup abgeschlossen wurden.Wie man erkennt
-> BitmapAnd
-> Bitmap Index Scan
-> Bitmap Index Scan
Empfehlungen
Erstellen Sie einen zusammengesetzten Index für die Felder aus der Quelle oder erweitern Sie eines der vorhandenen Felder aus der zweiten.Beispiel:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, (random() * 100)::integer fk_org
, (random() * 1000)::integer fk_cli;
CREATE INDEX ON tbl(fk_org);
CREATE INDEX ON tbl(fk_cli);
SELECT
*
FROM
tbl
WHERE
(fk_org, fk_cli) = (1, 999);
 [siehe EXPLAIN.tensor.ru]Richtig:
[siehe EXPLAIN.tensor.ru]Richtig:DROP INDEX tbl_fk_org_idx;
CREATE INDEX ON tbl(fk_org, fk_cli);
 [siehe EXPLAIN.tensor.ru]Hier ist die Verstärkung geringer, da Bitmap Heap Scan an sich sehr effektiv ist. Aber immer noch 7-mal schneller und 2,5-mal weniger Messwerte .
[siehe EXPLAIN.tensor.ru]Hier ist die Verstärkung geringer, da Bitmap Heap Scan an sich sehr effektiv ist. Aber immer noch 7-mal schneller und 2,5-mal weniger Messwerte .# 3: Indexverknüpfung (BitmapOr)
Wann entsteht
Zeigen Sie die ersten 20 ältesten "eigenen" oder nicht zugewiesenen Anwendungen für die Verarbeitung und ihre Priorität an.Wie man erkennt
-> BitmapOr
-> Bitmap Index Scan
-> Bitmap Index Scan
Empfehlungen
Verwenden Sie UNION [ALL] , um Unterabfragen für jeden der ODER-Bedingungsblöcke zu kombinieren.Beispiel:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, CASE
WHEN random() < 1::real/16 THEN NULL
ELSE (random() * 100)::integer
END fk_own;
CREATE INDEX ON tbl(fk_own, pk);
SELECT
*
FROM
tbl
WHERE
fk_own = 1 OR
fk_own IS NULL
ORDER BY
pk
, (fk_own = 1) DESC
LIMIT 20;
 [siehe EXPLAIN.tensor.ru]Richtig:
[siehe EXPLAIN.tensor.ru]Richtig:(
SELECT
*
FROM
tbl
WHERE
fk_own = 1
ORDER BY
pk
LIMIT 20
)
UNION ALL
(
SELECT
*
FROM
tbl
WHERE
fk_own IS NULL
ORDER BY
pk
LIMIT 20
)
LIMIT 20;
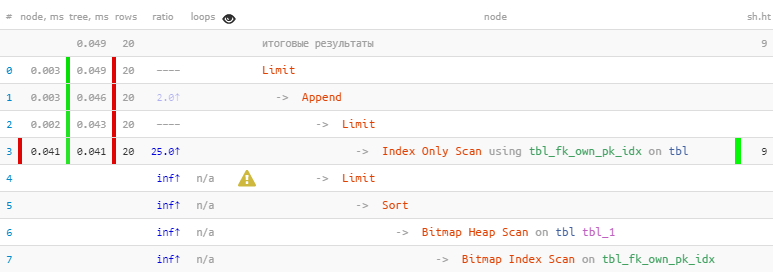 [siehe EXPLAIN.tensor.ru]Wir haben die Tatsache ausgenutzt, dass alle 20 erforderlichen Datensätze sofort im ersten Block empfangen wurden, sodass der zweite mit dem „teureren“ Bitmap-Heap-Scan nicht einmal durchgeführt wurde - infolgedessen 22-mal schneller 44 mal weniger Messwerte !
[siehe EXPLAIN.tensor.ru]Wir haben die Tatsache ausgenutzt, dass alle 20 erforderlichen Datensätze sofort im ersten Block empfangen wurden, sodass der zweite mit dem „teureren“ Bitmap-Heap-Scan nicht einmal durchgeführt wurde - infolgedessen 22-mal schneller 44 mal weniger Messwerte !Eine detailliertere Geschichte über diese Optimierungsmethode anhand spezifischer Beispiele finden Sie in den Artikeln von PostgreSQL Antipatterns: schädliche JOIN- und OR- und PostgreSQL-Antipatterns: eine Geschichte über die iterative Verfeinerung der Suche nach Namen oder „Optimierung hin und zurück“ .
Eine verallgemeinerte Version der geordneten Auswahl durch mehrere Schlüssel (und nicht nur durch ein const / NULL-Paar) wird im SQL HowTo- Artikel betrachtet : Wir schreiben eine while-Schleife direkt in die Abfrage oder "Elementary Three-Way" .
# 4: Lesen Sie viel Unnötiges
Wann entsteht
In der Regel tritt es auf, wenn Sie einen anderen Filter an einer vorhandenen Anforderung befestigen möchten."Und du hast nicht das gleiche, aber mit Perlmuttknöpfen ?" Film "Diamond Hand"
Wenn Sie beispielsweise die obige Aufgabe ändern, werden die ersten 20 ältesten „kritischen“ Anwendungen für die Verarbeitung angezeigt, unabhängig von ihrem Zweck.Wie man erkennt
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& 5 × rows < RRbF -- >80%
&& loops × RRbF > 100 -- 100
Empfehlungen
Erstellen Sie einen [mehr] benutzerdefinierten Index mit einer WHERE-Klausel oder fügen Sie zusätzliche Felder in den Index ein.Wenn die Filterbedingung für Ihre Aufgaben "statisch" ist, dh die Liste der Werte in Zukunft nicht erweitert wird, ist es besser, einen WHERE-Index zu verwenden. Verschiedene Boolesche / Enum-Status passen gut in diese Kategorie.
Wenn die Filterbedingung unterschiedliche Werte annehmen kann , ist es besser, den Index mit diesen Feldern zu erweitern - wie in der obigen Situation mit BitmapAnd.
Beispiel:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, CASE
WHEN random() < 1::real/16 THEN NULL
ELSE (random() * 100)::integer
END fk_own
, (random() < 1::real/50) critical;
CREATE INDEX ON tbl(pk);
CREATE INDEX ON tbl(fk_own, pk);
SELECT
*
FROM
tbl
WHERE
critical
ORDER BY
pk
LIMIT 20;
 [siehe EXPLAIN.tensor.ru]Richtig:
[siehe EXPLAIN.tensor.ru]Richtig:CREATE INDEX ON tbl(pk)
WHERE critical;
 [siehe EXPLAIN.tensor.ru]Wie Sie sehen, ist die Filterung vollständig aus dem Plan verschwunden und die Anforderung ist fünfmal schneller geworden .
[siehe EXPLAIN.tensor.ru]Wie Sie sehen, ist die Filterung vollständig aus dem Plan verschwunden und die Anforderung ist fünfmal schneller geworden .# 5: spärlicher Tisch
Wann entsteht
Verschiedene Versuche, eine eigene Warteschlange für Verarbeitungsaufgaben zu erstellen, wenn eine große Anzahl von Aktualisierungen / Löschungen von Datensätzen in der Tabelle zu einer großen Anzahl von "toten" Datensätzen führt.Wie man erkennt
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& loops × (rows + RRbF) < (shared hit + shared read) × 8
-- 1KB
&& shared hit + shared read > 64
Empfehlungen
Führen Sie VACUUM [FULL] manuell durch oder erzielen Sie ausreichend häufige Autovakuumtests durch Feinabstimmung der Parameter, auch für eine bestimmte Tabelle .In den meisten Fällen werden diese Probleme durch schlecht strukturierte Abfragen beim Aufrufen aus der Geschäftslogik verursacht, wie sie beispielsweise in PostgreSQL Antipatterns: Kampf gegen Horden von „Toten“ beschrieben werden .
Aber Sie müssen verstehen, dass selbst VACUUM FULL möglicherweise nicht immer hilft. In solchen Fällen sollten Sie sich mit dem Algorithmus aus dem DBA- Artikel vertraut machen : Wenn VACUUM erfolgreich ist, bereinigen wir die Tabelle manuell .
# 6: Lesen aus der Mitte des Index
Wann entsteht
Es scheint, dass sie nicht viel und alles nach Index gelesen haben und nichts extra gefiltert haben - aber trotzdem wurden deutlich mehr Seiten gelesen, als wir möchten.Wie man erkennt
-> Index [Only] Scan [Backward]
&& loops × (rows + RRbF) < (shared hit + shared read) × 8
-- 1KB
&& shared hit + shared read > 64
Empfehlungen
Sehen Sie sich die Struktur des verwendeten Index und die in der Anforderung angegebenen Schlüsselfelder genau an - höchstwahrscheinlich ist ein Teil des Index nicht angegeben . Höchstwahrscheinlich müssen Sie einen ähnlichen Index erstellen, jedoch ohne Präfixfelder, oder lernen, wie Sie deren Werte durchlaufen .Beispiel:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, (random() * 100)::integer fk_org
, (random() * 1000)::integer fk_cli;
CREATE INDEX ON tbl(fk_org, fk_cli);
SELECT
*
FROM
tbl
WHERE
fk_cli = 999
LIMIT 20;
 [siehe EXPLAIN.tensor.ru] Allesscheint in Ordnung zu sein, auch nach Index, aber irgendwie verdächtig - für jeden der 20 gelesenen Datensätze musste ich 4 Datenseiten subtrahieren, 32 KB pro Datensatz - ist es nicht fett? Ja, und der Name des Index ist suggestiv. Wir reparieren:
[siehe EXPLAIN.tensor.ru] Allesscheint in Ordnung zu sein, auch nach Index, aber irgendwie verdächtig - für jeden der 20 gelesenen Datensätze musste ich 4 Datenseiten subtrahieren, 32 KB pro Datensatz - ist es nicht fett? Ja, und der Name des Index ist suggestiv. Wir reparieren:tbl_fk_org_fk_cli_idxCREATE INDEX ON tbl(fk_cli);
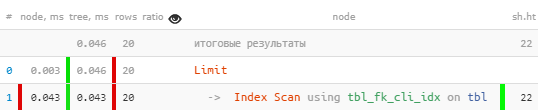 [siehe EXPLAIN.tensor.ru]Plötzlich - 10 Mal schneller und 4 Mal weniger gelesen !
[siehe EXPLAIN.tensor.ru]Plötzlich - 10 Mal schneller und 4 Mal weniger gelesen !Weitere Beispiele für Situationen ineffizienter Verwendung von Indizes finden Sie im DBA- Artikel : Suchen Sie nach nutzlosen Indizes .
# 7: CTE × CTE
Wann entsteht
In der Abfrage haben wir "fette" CTEs aus verschiedenen Tabellen eingegeben und dann beschlossen, zwischen ihnen zu wechselnJOIN .Der Fall ist relevant für Versionen unter Version 12 oder Anfragen von WITH MATERIALIZED.Wie man erkennt
-> CTE Scan
&& loops > 10
&& loops × (rows + RRbF) > 10000
-- CTE
Empfehlungen
Analysieren Sie die Anfrage sorgfältig - wird hier überhaupt CTE benötigt ? Wenn dies trotzdem der Fall ist , wenden Sie in hstore / json das "Zerreißen" gemäß dem in PostgreSQL Antipatterns beschriebenen Modell an : Schlagen Sie das Wörterbuch mit einem starken JOIN an .# 8: Swap to Disk (Temp geschrieben)
Wann entsteht
Die einmalige Verarbeitung (Sortierung oder Eindeutigkeit) einer großen Anzahl von Datensätzen passt nicht in den dafür zugewiesenen Speicher.Wie man erkennt
-> *
&& temp written > 0
Empfehlungen
Wenn die von der Operation verwendete Speichermenge den eingestellten Wert des Parameters work_mem nicht wesentlich überschreitet , sollten Sie ihn anpassen. Sie können sofort in der Konfiguration für alle, aber Sie können SET [LOCAL]für eine bestimmte Anfrage / Transaktion durch.Beispiel:SHOW work_mem;
SELECT
random()
FROM
generate_series(1, 1000000)
ORDER BY
1;
 [siehe EXPLAIN.tensor.ru]Richtig:
[siehe EXPLAIN.tensor.ru]Richtig:SET work_mem = '128MB';
 [siehe EXPLAIN.tensor.ru]Wenn aus offensichtlichen Gründen nur Speicher und keine Festplatte verwendet wird, wird die Anforderung viel schneller ausgeführt. Gleichzeitig wird auch ein Teil der Last von der Festplatte entfernt.Aber Sie müssen verstehen, dass das Zuweisen von viel Speicher immer auch nicht funktioniert - es wird nicht für alle ausreichen.
[siehe EXPLAIN.tensor.ru]Wenn aus offensichtlichen Gründen nur Speicher und keine Festplatte verwendet wird, wird die Anforderung viel schneller ausgeführt. Gleichzeitig wird auch ein Teil der Last von der Festplatte entfernt.Aber Sie müssen verstehen, dass das Zuweisen von viel Speicher immer auch nicht funktioniert - es wird nicht für alle ausreichen.# 9: irrelevante Statistiken
Wann entsteht
Sie haben viel auf einmal in die Datenbank gegossen, aber es nicht geschafft, sie zu vertreiben ANALYZE.Wie man erkennt
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& ratio >> 10
Empfehlungen
Mach dasselbe ANALYZE.Diese Situation wird in PostgreSQL Antipatterns ausführlicher beschrieben: Statistiken sind allgegenwärtig .
# 10: "etwas ist schief gelaufen"
Wann entsteht
Es wurde erwartet, dass eine Sperre durch eine konkurrierende Anforderung auferlegt wird, oder es gab nicht genügend CPU- / Hypervisor-Hardwareressourcen.Wie man erkennt
-> *
&& (shared hit / 8K) + (shared read / 1K) < time / 1000
-- RAM hit = 64MB/s, HDD read = 8MB/s
&& time > 100ms -- ,
Empfehlungen
Verwenden Sie ein externes System, um den Server auf Sperren oder abnormalen Ressourcenverbrauch zu überwachen . Über unsere Version der Organisation dieses Prozesses für Hunderte von Servern haben wir bereits hier und hier gesprochen .