 Hallo, mein Name ist Andrey Schukin. Ich helfe großen Unternehmen bei der Migration von Diensten und Systemen in die CROC Cloud. Zusammen mit Kollegen aus Southbridge, die Kubernetes-Kurse im Slerm-Schulungszentrum durchführen, haben wir kürzlich ein Webinar für unsere Kunden durchgeführt.Ich habe mich entschlossen, Materialien aus einem ausgezeichneten Vortrag von Pavel Selivanov zu nehmen und einen Beitrag für diejenigen zu schreiben, die gerade erst mit Cloud-Provisioning-Tools arbeiten und nicht wissen, wo sie anfangen sollen. Daher werde ich über den Stapel von Technologien sprechen, die in unserer Schulung und Produktion von CROC Cloud verwendet werden. Lassen Sie uns über moderne Ansätze für das Infrastrukturmanagement sprechen, über eine Reihe von Packer-, Terraform- und Ansible-Komponenten sowie über das Kubeadm-Tool, mit dem wir installieren werden.Unter dem Schnitt wird viel Text und Konfigurationen sein. Da es viel Material gibt, habe ich die Post-Navigation hinzugefügt. Wir haben auch ein kleines Repository vorbereitet, in dem wir alles aufbewahren, was wir für unsere Schulungsbereitstellung benötigen.Geben Sie keine Hühnernamen.Gebackene Kuchen sind gesünder als gebratene.Wir starten den Ofen. PackerTerraform - Infrastruktur als CodeStarten Sie die Terraform-Clusterstruktur KubernetesKubeadmRepository mit allen Dateien
Hallo, mein Name ist Andrey Schukin. Ich helfe großen Unternehmen bei der Migration von Diensten und Systemen in die CROC Cloud. Zusammen mit Kollegen aus Southbridge, die Kubernetes-Kurse im Slerm-Schulungszentrum durchführen, haben wir kürzlich ein Webinar für unsere Kunden durchgeführt.Ich habe mich entschlossen, Materialien aus einem ausgezeichneten Vortrag von Pavel Selivanov zu nehmen und einen Beitrag für diejenigen zu schreiben, die gerade erst mit Cloud-Provisioning-Tools arbeiten und nicht wissen, wo sie anfangen sollen. Daher werde ich über den Stapel von Technologien sprechen, die in unserer Schulung und Produktion von CROC Cloud verwendet werden. Lassen Sie uns über moderne Ansätze für das Infrastrukturmanagement sprechen, über eine Reihe von Packer-, Terraform- und Ansible-Komponenten sowie über das Kubeadm-Tool, mit dem wir installieren werden.Unter dem Schnitt wird viel Text und Konfigurationen sein. Da es viel Material gibt, habe ich die Post-Navigation hinzugefügt. Wir haben auch ein kleines Repository vorbereitet, in dem wir alles aufbewahren, was wir für unsere Schulungsbereitstellung benötigen.Geben Sie keine Hühnernamen.Gebackene Kuchen sind gesünder als gebratene.Wir starten den Ofen. PackerTerraform - Infrastruktur als CodeStarten Sie die Terraform-Clusterstruktur KubernetesKubeadmRepository mit allen DateienGeben Sie Hühnern keine Namen
 Es gibt viele verschiedene Konzepte des Infrastrukturmanagements. Einer von ihnen heißt Haustiere vs. Rinder, das heißt "Haustiere gegen Vieh". Dieses Konzept beschreibt zwei gegensätzliche Ansätze für die Infrastruktur.Stellen Sie sich vor, wir haben einen Lieblingshund. Wir kümmern uns um sie, bringen ihn zum Tierarzt, kämmen das Fell aus und im Allgemeinen ist es unter vielen anderen Hunden einzigartig für uns.In einem anderen Fall haben wir einen Hühnerstall. Wir kümmern uns auch um Hühner, füttern, erhitzen und versuchen, die angenehmsten Bedingungen zu schaffen. Trotzdem sind Hühner für uns eine eher gesichtslose Ressource, die ihre Funktion der Eiablage erfüllt, und wir bezeichnen sie bestenfalls als "das schwarze Pulver, das immer Zement pickt". Wenn das Huhn aufhört, Eier zu legen oder seine Pfote bricht, wird es uns höchstwahrscheinlich einfach eine köstliche Brühe zum Mittagessen liefern. Tatsächlich kümmern wir uns nicht um das Schicksal eines einzelnen Huhns, sondern um den Hühnerstall als Ganzes als Produktionslinie.In der IT wurde ein ähnlicher Ansatz angewendet, sobald Tools erschienen, die die Einstiegsschwelle für Ingenieure senkten und die Bereitstellung und Wartung komplexer Cluster in einem vollautomatischen Modus ermöglichten.Zuvor hatten wir eine kleine Anzahl von Servern, die überwacht, manuell optimiert und auf jede mögliche Weise gepflegt wurden. Bei der Überwachung wurden Protokolle von den Servern Cthulhu, Aylith und Dagon geflasht. Traditionen.Dann drang die Virtualisierung fest in unser Leben ein und die Namen aus den Werken von Lovecraft und Star Trek machten dem nützlicheren „vlg-vlt-vault01.company.ru“ Platz. Es gibt viele Server, aber wir haben die Dienste immer noch mehr oder weniger manuell erhöht, um die Probleme auf jedem Computer bei Bedarf zu beseitigen.Jetzt stimmt der Ansatz zur Wartung der Infrastruktur vollständig mit der Programmierung überein. Wir fügen eine weitere Abstraktionsebene hinzu und kümmern uns nicht mehr um einzelne Knoten. Jeder hat einen gesichtslosen Index anstelle eines Namens, und im Falle eines Problems wird die virtuelle Maschine einfach beendet und steigt aus dem Arbeitsschnappschuss auf. Es gibt Tools, mit denen Sie diesen Ansatz implementieren können. In unserem Fall ist das erste Tool die CROC Cloud, das zweite Terraform.
Es gibt viele verschiedene Konzepte des Infrastrukturmanagements. Einer von ihnen heißt Haustiere vs. Rinder, das heißt "Haustiere gegen Vieh". Dieses Konzept beschreibt zwei gegensätzliche Ansätze für die Infrastruktur.Stellen Sie sich vor, wir haben einen Lieblingshund. Wir kümmern uns um sie, bringen ihn zum Tierarzt, kämmen das Fell aus und im Allgemeinen ist es unter vielen anderen Hunden einzigartig für uns.In einem anderen Fall haben wir einen Hühnerstall. Wir kümmern uns auch um Hühner, füttern, erhitzen und versuchen, die angenehmsten Bedingungen zu schaffen. Trotzdem sind Hühner für uns eine eher gesichtslose Ressource, die ihre Funktion der Eiablage erfüllt, und wir bezeichnen sie bestenfalls als "das schwarze Pulver, das immer Zement pickt". Wenn das Huhn aufhört, Eier zu legen oder seine Pfote bricht, wird es uns höchstwahrscheinlich einfach eine köstliche Brühe zum Mittagessen liefern. Tatsächlich kümmern wir uns nicht um das Schicksal eines einzelnen Huhns, sondern um den Hühnerstall als Ganzes als Produktionslinie.In der IT wurde ein ähnlicher Ansatz angewendet, sobald Tools erschienen, die die Einstiegsschwelle für Ingenieure senkten und die Bereitstellung und Wartung komplexer Cluster in einem vollautomatischen Modus ermöglichten.Zuvor hatten wir eine kleine Anzahl von Servern, die überwacht, manuell optimiert und auf jede mögliche Weise gepflegt wurden. Bei der Überwachung wurden Protokolle von den Servern Cthulhu, Aylith und Dagon geflasht. Traditionen.Dann drang die Virtualisierung fest in unser Leben ein und die Namen aus den Werken von Lovecraft und Star Trek machten dem nützlicheren „vlg-vlt-vault01.company.ru“ Platz. Es gibt viele Server, aber wir haben die Dienste immer noch mehr oder weniger manuell erhöht, um die Probleme auf jedem Computer bei Bedarf zu beseitigen.Jetzt stimmt der Ansatz zur Wartung der Infrastruktur vollständig mit der Programmierung überein. Wir fügen eine weitere Abstraktionsebene hinzu und kümmern uns nicht mehr um einzelne Knoten. Jeder hat einen gesichtslosen Index anstelle eines Namens, und im Falle eines Problems wird die virtuelle Maschine einfach beendet und steigt aus dem Arbeitsschnappschuss auf. Es gibt Tools, mit denen Sie diesen Ansatz implementieren können. In unserem Fall ist das erste Tool die CROC Cloud, das zweite Terraform.Gebackene Kuchen sind gesünder als gebraten
 Im Infrastrukturmanagement gibt es einen Kontrast zwischen den beiden Ansätzen Fried vs. Gebacken, das heißt "gebraten gegen gebacken".Der Fried-Ansatz impliziert, dass Sie über ein Vanilla-Betriebssystem-Image verfügen, z. B. CentOS 7. Nach der Bereitstellung des Betriebssystems verwenden wir das Konfigurationsverwaltungssystem, um das System in den Zielstatus zu versetzen. Zum Beispiel mit Ansible, Chef, Puppet oder SaltStack.Alles funktioniert gut, besonders wenn es nicht sehr viele Server gibt. Wenn eine massive Bereitstellung erforderlich ist, sind wir mit Leistungsproblemen konfrontiert. Hunderte von Servern verschlingen synchron Netzwerkressourcen, CPU, RAM und IOPS, während viele neue Pakete gerollt werden. Darüber hinaus kann sich dieser Vorgang ziemlich lange verzögern. Kurz gesagt, die Schaltung ist absolut betriebsbereit, aber unter dem Gesichtspunkt der Minimierung von Ausfallzeiten bei Unfällen nicht so interessant.Der Baked-Ansatz impliziert, dass Sie vorgefertigte "gebackene" Betriebssystem-Images haben, auf denen Sie bereits alle erforderlichen Pakete installiert, die Konfiguration und alles andere konfiguriert haben. Bei der Ausgabe haben wir eine abstrakte Snapshot-Vorlage, die für die Ausführung einiger Funktionen geschärft wurde. Das Bereitstellen der Infrastruktur aus solchen gebackenen Images nimmt erheblich weniger Zeit in Anspruch und reduziert Ausfallzeiten auf ein Minimum. Eine sehr ähnliche Ideologie wird in mehrschichtigen Docker-Bildern verwendet, in denen niemand unnötig in die Hände stößt. Den Container genagelt - einen neuen aufgehoben.
Im Infrastrukturmanagement gibt es einen Kontrast zwischen den beiden Ansätzen Fried vs. Gebacken, das heißt "gebraten gegen gebacken".Der Fried-Ansatz impliziert, dass Sie über ein Vanilla-Betriebssystem-Image verfügen, z. B. CentOS 7. Nach der Bereitstellung des Betriebssystems verwenden wir das Konfigurationsverwaltungssystem, um das System in den Zielstatus zu versetzen. Zum Beispiel mit Ansible, Chef, Puppet oder SaltStack.Alles funktioniert gut, besonders wenn es nicht sehr viele Server gibt. Wenn eine massive Bereitstellung erforderlich ist, sind wir mit Leistungsproblemen konfrontiert. Hunderte von Servern verschlingen synchron Netzwerkressourcen, CPU, RAM und IOPS, während viele neue Pakete gerollt werden. Darüber hinaus kann sich dieser Vorgang ziemlich lange verzögern. Kurz gesagt, die Schaltung ist absolut betriebsbereit, aber unter dem Gesichtspunkt der Minimierung von Ausfallzeiten bei Unfällen nicht so interessant.Der Baked-Ansatz impliziert, dass Sie vorgefertigte "gebackene" Betriebssystem-Images haben, auf denen Sie bereits alle erforderlichen Pakete installiert, die Konfiguration und alles andere konfiguriert haben. Bei der Ausgabe haben wir eine abstrakte Snapshot-Vorlage, die für die Ausführung einiger Funktionen geschärft wurde. Das Bereitstellen der Infrastruktur aus solchen gebackenen Images nimmt erheblich weniger Zeit in Anspruch und reduziert Ausfallzeiten auf ein Minimum. Eine sehr ähnliche Ideologie wird in mehrschichtigen Docker-Bildern verwendet, in denen niemand unnötig in die Hände stößt. Den Container genagelt - einen neuen aufgehoben.Wir starten den Ofen. Packer
 In unserer Infrastruktur verwenden wir mehrere Hashicorp-Produkte, von denen sich einige als äußerst erfolgreich erwiesen haben. Beginnen wir unsere Magie mit dem Vorbereiten und Backen eines Bildes mit dem Packer-Tool.Packer verwendet eine JSON-Vorlage, dh Vorlagendateien, die eine Beschreibung dessen enthalten, was als "gebackene" virtuelle Maschine (VM) abgerufen werden muss. Nach dem Erstellen der Vorlage wird die Datei an Packer übertragen und die erforderlichen Berechtigungen zum Erstellen des Servers in der Cloud werden konfiguriert.Mit Packer können Sie VMs lokal in KVM, VirtualBox, Vagrant, AWS, GCP, Alibaba Cloud, OpenStack usw. anheben. Es ist praktisch, mit Packer in der CROC Cloud zu arbeiten, da AWS-Schnittstellen implementiert werden, dh alle Tools, für die geschrieben wurde AWS, arbeiten Sie mit der CROC Cloud.Nach dem Festlegen der erforderlichen Vorlagen löst Packer VM CROC in der Cloud aus, wartet auf den Start und der „Provider“ betritt den Work-Provisioner: ein Dienstprogramm, das die Image-Vorbereitung abschließen muss. In unserem Fall ist dies Ansible, obwohl Packer mit anderen Optionen arbeiten kann.Wenn die VM bereit ist, erstellt Packer ihr Image und platziert es in der CROC Cloud, sodass andere VMs von demselben Image aus gestartet werden können.
In unserer Infrastruktur verwenden wir mehrere Hashicorp-Produkte, von denen sich einige als äußerst erfolgreich erwiesen haben. Beginnen wir unsere Magie mit dem Vorbereiten und Backen eines Bildes mit dem Packer-Tool.Packer verwendet eine JSON-Vorlage, dh Vorlagendateien, die eine Beschreibung dessen enthalten, was als "gebackene" virtuelle Maschine (VM) abgerufen werden muss. Nach dem Erstellen der Vorlage wird die Datei an Packer übertragen und die erforderlichen Berechtigungen zum Erstellen des Servers in der Cloud werden konfiguriert.Mit Packer können Sie VMs lokal in KVM, VirtualBox, Vagrant, AWS, GCP, Alibaba Cloud, OpenStack usw. anheben. Es ist praktisch, mit Packer in der CROC Cloud zu arbeiten, da AWS-Schnittstellen implementiert werden, dh alle Tools, für die geschrieben wurde AWS, arbeiten Sie mit der CROC Cloud.Nach dem Festlegen der erforderlichen Vorlagen löst Packer VM CROC in der Cloud aus, wartet auf den Start und der „Provider“ betritt den Work-Provisioner: ein Dienstprogramm, das die Image-Vorbereitung abschließen muss. In unserem Fall ist dies Ansible, obwohl Packer mit anderen Optionen arbeiten kann.Wenn die VM bereit ist, erstellt Packer ihr Image und platziert es in der CROC Cloud, sodass andere VMs von demselben Image aus gestartet werden können.Base.json-Struktur
Am Anfang der Datei befindet sich ein Abschnitt, in dem Variablen deklariert werden:Spoiler"variables" : {
"source_ami_name": "{{env SOURCE_AMI_NAME}}",
"ami_name": "{{env AMI_NAME}}",
"instance_type": "{{env INSTANCE_TYPE}}",
"kubernetes_version": "{{env KUBERNETES_VERSION}}",
"docker_version": "{{env DOCKER_VERSION}}",
"subnet_id": "",
"availability_zone": "",
},
Der Hauptsatz dieser Variablen wird aus der Datei settings.json festgelegt. Und diese Variablen, die sich häufig ändern, können bequemer über die Konsole festgelegt werden, wenn Sie Packer starten und ein neues Image erstellen.Das Folgende ist der Abschnitt Builder:Spoiler"builders" : [
{
"type": "amazon-ebs",
"region": "croc",
"skip_region_validation": true,
"custom_endpoint_ec2": "https://api.cloud.croc.ru",
"source_ami": "",
"source_ami_filter": {
"filters": {
"name": "{{user `source_ami_name`}}"
"state": "available",
"virtualization-type": "kvm-virtio"
},
...
Zielwolken und die VM-Startmethode werden hier beschrieben. Bitte beachten Sie, dass in diesem Fall der Typ amazon-ebs deklariert ist, für den Betrieb von Packer mit der CROC Cloud jedoch die entsprechende Adresse in custom_endpoint_ec2 festgelegt ist. Unsere Infrastruktur verfügt über eine API, die fast vollständig mit Amazon Web Services kompatibel ist. Wenn Sie also vorgefertigte Entwicklungen für diese Plattform haben, müssen Sie zum größten Teil nur einen benutzerdefinierten API-Einstiegspunkt angeben - in unserem Beispiel api.cloud.croc.ru .Es ist erwähnenswert, den Abschnitt source_ami_filter separat zu erwähnen. Hier wird das Ausgangsimage der VM eingestellt, in dem die notwendigen Änderungen vorgenommen werden. Packer benötigt jedoch eine AMI für dieses Bild, d. H. Seine zufällige Kennung. Da diese Kennung selten im Voraus bekannt ist und sich mit jedem Update ändert, wird die Quell-AMI nicht als spezifischer Wert, sondern als Variable source_ami_filter festgelegt. In diesem Fall ist der bestimmende Parameter des Filters der Name des Bildes. Dieser Name wird in den Variablen über die Datei settings.json festgelegt.Als nächstes werden die VM-Einstellungen definiert: Der Instanztyp, der Prozessor, die Speichergröße, der zugewiesene Speicherplatz usw. werden angegeben:Spoiler"instance_type": "{{user `instance_type`}}",
"launch_block_device_mappings": [
{
"device_name": "disk1",
"volume_type": "io1",
"volume_size": "8",
"iops": "1000",
"delete_on_termination": "true"
}
],
In base.json sind die Parameter für die Verbindung zu dieser VM aufgeführt:Spoiler"availability_zone": "{{user `availability_zone`}}",
"subnet_id": "{{user `subnet_id`}}",
"associate_public_ip_address": true,
"ssh_username": "ec2-user",
"ami_name": "{{user `ami_name`}}"
Es ist wichtig, den Parameter subnet_id hier zu beachten. Es muss manuell festgelegt werden, da ohne Angabe des VM-Subnetzes in der CROC Cloud keine Erstellung möglich ist.Ein weiterer Parameter, der einer vorherigen Vorbereitung bedarf, ist Associate_public_ip_address. Sie müssen eine weiße IP-Adresse auswählen, da nach dem Erstellen des VM Packer die erforderlichen Einstellungen über Ansible vorgenommen werden. In diesem Fall stellt Ansible über SSH eine Verbindung zur VM her, für die eine weiße IP-Adresse oder ein VPN erforderlich ist.Der letzte Abschnitt sind die Provisioner:Spoiler"provisioners": [
{
"type": "ansible",
"playbook_file": "playbook.yml",
"extra_arguments": [
"--extra-vars",
"kubernetes_version={{user `kubernetes_version`}}",
"--extra-vars",
"docker_version={{user `docker_version`}}"
]
}
]
Dies sind die Anbieter, dh die Dienstprogramme, mit denen Packer den Server konfiguriert. In diesem Fall wird ein Ansible-Typ-Provider verwendet. Der folgende Parameter ist playbook_file, der die Ansible-Rollen und die Hosts definiert, auf die die angegebenen Rollen angewendet werden. Im Folgenden werden zusätzliche Optionen extra_arguments vorgestellt, mit denen beim Starten von Ansible Versionen von Kubernetes und Docker übertragen werden.CROC Cloud-Vorbereitung
 Zusätzlich zu unseren Konfigurationsdateien müssen wir einige Dinge von der Seite des Cloud-Kontrollfelds aus tun, damit die ganze Magie funktioniert. Wir müssen eine weiße IP auswählen und ein funktionierendes Subnetz erstellen, das wir bei der Bereitstellung verwenden werden.
Zusätzlich zu unseren Konfigurationsdateien müssen wir einige Dinge von der Seite des Cloud-Kontrollfelds aus tun, damit die ganze Magie funktioniert. Wir müssen eine weiße IP auswählen und ein funktionierendes Subnetz erstellen, das wir bei der Bereitstellung verwenden werden.- Klicken Sie auf Adresse markieren. Der Packer findet die gewünschte weiße IP-Adresse selbstständig.
- Klicken Sie auf Subnetz erstellen und geben Sie ein Subnetz und eine Maske an.
- Kopieren Sie die Subnetz-ID.
- Fügen Sie diesen Wert in den Parameter subnet_id des Packer-Startbefehls ein.
 Führen Sie dann Packer aus. Er findet das ursprüngliche VM-Image, stellt es in der CROC-Cloud bereit und führt die Ansible-Rolle darauf aus. Die neue VM ist in der CROC Cloud im Abschnitt "Instanzen" zu sehen.
Führen Sie dann Packer aus. Er findet das ursprüngliche VM-Image, stellt es in der CROC-Cloud bereit und führt die Ansible-Rolle darauf aus. Die neue VM ist in der CROC Cloud im Abschnitt "Instanzen" zu sehen.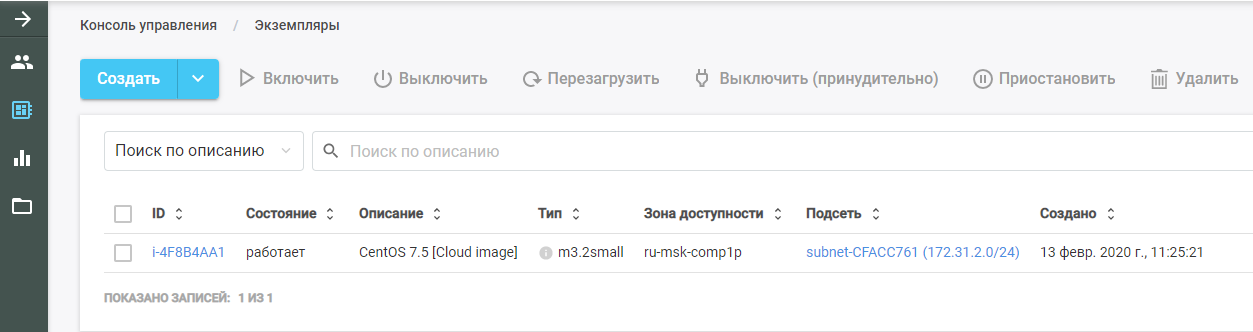
 Nach Abschluss der Arbeiten entfernt Packer die VM aus der Cloud und hinterlässt an ihrer Stelle ein fertiges Image, das im Abschnitt "Vorlagen" zu finden ist. Aus diesem Image wird die gesamte Kubernetes-Infrastruktur erstellt.
Nach Abschluss der Arbeiten entfernt Packer die VM aus der Cloud und hinterlässt an ihrer Stelle ein fertiges Image, das im Abschnitt "Vorlagen" zu finden ist. Aus diesem Image wird die gesamte Kubernetes-Infrastruktur erstellt.Ansible
Wie bereits erwähnt, wird der Playbook-Parameter in den Parametern des Ansible-Anbieters übergeben. Die Datei playbook.yml selbst sieht folgendermaßen aus:- hosts: all
become: true
roles:
| - base
Die Datei überträgt an Ansible, dass auf allen Hosts die Rolle der Basis erfüllt werden muss. Wenn andere Rollen vorhanden sind, können Sie sie derselben Datei wie eine Liste hinzufügen.Mit der Basiserolle können Sie mit einem einzigen Befehl einen vorgefertigten Cluster abrufen. Die Datei main.yml zeigt, was genau diese Rolle bewirkt:- Fügt der Systemvorlage ein Docker-Repository hinzu.
- Fügt das Kubernetes-Repository zur Systemvorlage hinzu.
- Installiert die erforderlichen Pakete.
- Erstellt ein Verzeichnis zum Konfigurieren des Docker-Dämons.
- Konfiguriert den Computer gemäß der Konfigurationsdatei daemon.json.j2.
- Lädt den Kernel br_netfilter.
- Enthält die erforderlichen Optionen für br_netfilter.
- Enthält Docker- und Kubelet-Komponenten.
- Führt Docker in VM aus.
- Führt einen Befehl aus, der die Docker-Images herunterlädt, die für die Funktion von Kubernetes erforderlich sind.
In diesem Fall werden die installierten Pakete in der Datei main.yml aus dem Verzeichnis vars festgelegt. In unserem Fall installieren wir das Docker-CE-Paket sowie die drei Pakete, die für die Funktion von Kubernetes erforderlich sind: kubelet, kubeadm und kubectl.Terraform - Infrastruktur als Code
 Terraform ist ein sehr funktionales Tool von HashiCorp für die Cloud-Orchestrierung. Es verfügt über eine eigene spezifische HCL-Sprache, die häufig in anderen Produkten des Unternehmens verwendet wird, z. B. in HashiCorp Vault und Consul.Das Grundprinzip ähnelt allen Konfigurationsmanagementsystemen. Sie geben einfach den Zielzustand im gewünschten Format an und das System berechnet den Algorithmus, wie dies erreicht werden kann. Eine andere Sache ist, dass Terraform im Gegensatz zu demselben Ansible, das in komplexen Playbooks als Black Box fungiert, einen Plan für zukünftige Aktionen in einer für die Analyse geeigneten Form erstellen kann. Dies ist wichtig bei der Planung komplexer Infrastrukturänderungen. Führen Sie nach dem Planen der erforderlichen Aktionen den Befehl terraform apply aus, und Terraform stellt die in den Dateien beschriebene Infrastruktur bereit.Wie Packer unterstützt dieses Tool AWS, GCP, Alibaba Cloud, Azure, OpenStack, VMware usw.
Terraform ist ein sehr funktionales Tool von HashiCorp für die Cloud-Orchestrierung. Es verfügt über eine eigene spezifische HCL-Sprache, die häufig in anderen Produkten des Unternehmens verwendet wird, z. B. in HashiCorp Vault und Consul.Das Grundprinzip ähnelt allen Konfigurationsmanagementsystemen. Sie geben einfach den Zielzustand im gewünschten Format an und das System berechnet den Algorithmus, wie dies erreicht werden kann. Eine andere Sache ist, dass Terraform im Gegensatz zu demselben Ansible, das in komplexen Playbooks als Black Box fungiert, einen Plan für zukünftige Aktionen in einer für die Analyse geeigneten Form erstellen kann. Dies ist wichtig bei der Planung komplexer Infrastrukturänderungen. Führen Sie nach dem Planen der erforderlichen Aktionen den Befehl terraform apply aus, und Terraform stellt die in den Dateien beschriebene Infrastruktur bereit.Wie Packer unterstützt dieses Tool AWS, GCP, Alibaba Cloud, Azure, OpenStack, VMware usw.Wir beschreiben das Projekt
Das Terraform-Verzeichnis enthält eine Reihe von Dateien mit der Erweiterung .tf. Diese Dateien beschreiben die Komponenten der Infrastruktur, mit der wir arbeiten werden. Teilen Sie das Projekt in Funktionsmodule auf. Eine solche Struktur erleichtert die Steuerung der Versionierung und das Zusammensetzen jedes Projekts aus vorgefertigten praktischen Blöcken. Für unsere Option ist folgende Struktur geeignet:- main.tf
- network.tf
- security_groups.tf
- master.tf
- master.tpl
Main.tf-Dateistruktur
Beginnen wir mit der Datei main.tf, in der der Zugriff auf die Cloud konfiguriert ist. Insbesondere werden mehrere Parameter angekündigt, die Terraform für die Verwendung mit der CROC Cloud konfigurieren:provider "aws" {
endpoints {
ec2 = "https://api.cloud.croc.ru"
}
Darüber hinaus beschreibt die Datei, dass Terraform unabhängig einen privaten Schlüssel erstellen und seinen öffentlichen Teil auf alle Server hochladen muss. Der private Schlüssel selbst wird am Ende von Terraform ausgegeben:resource "tls_private_key" "ssh" {
algorithm = "RSA"
}
resource "aws_key_pair" "kube" {
key_name = "terraform"
public_key = "${tls_private_key.ssh.public_key_openssh}"
}
output "ssh" {
value = "${tls_private_key.ssh.private_key_pem}"
}
Die Struktur der Datei network.tf
Diese Datei beschreibt die Netzwerkkomponenten, die zum Starten der VM erforderlich sind:Spoilerdata "aws_availability_zones" "az" {
state = "available"
}
resource "aws_vpc" "kube" {
cidr_block = "${var.vpc_cidr}"
}
resource "aws_eip" "master" {
count = "1"
vpc = true
}
resource "aws_subnet" "private" {
vpc_id = "${aws_vpc.kube.id}"
count = "${length(data.aws_availability_zones.az.names)}"
cidr_block = "${var.private_subnet_cidr_list[count.index]}"
availability_zone = "${data.aws_availability_zones.az.names[count.index]}"
}
Terraform verwendet zwei Arten von Komponenten:- Ressource - was muss geschaffen werden;
- Daten - was Sie brauchen, um zu bekommen.
In diesem Fall gibt der Datenparameter an, dass Terraform die Verfügbarkeitszonen der angegebenen Cloud erhalten soll, die sich im verfügbaren Zustand befinden.Die erste Parameterressource beschreibt die Erstellung einer virtuellen privaten Cloud, und der nächste Parameter beschreibt die Erstellung einer elastischen IP-Adresse. Für den Kubernetes-Cluster bestellen wir diese IP-Adresse über Terraform.Darüber hinaus wird in jeder der Barrierefreiheitszonen und im Moment, in dem CROC über zwei Cloud-Dienste verfügt, ein eigenes Subnetz erstellt. Eine Ressource vom Typ aws_subnet wird deklariert und die ID des erstellten aws_vpc wird als Teil dieses Parameters übergeben. Da die ID dieser Ressource jedoch noch unbekannt ist, geben wir den Parameter aws_vpc.kube.id an, der auf die erstellte Ressource verweist und den Wert aus dem ID-Feld ersetzt.Da die Anzahl der erstellten Subnetze durch die Anzahl der Cloud-Verfügbarkeitszonen bestimmt wird und sich diese Anzahl im Laufe der Zeit ändern kann, wird dieser Parameter über die Längenvariable (data.aws_availability_zones.az.names) festgelegt, d. H. Die Länge der Liste der über den Datenparameter empfangenen Zugriffszonen.Die letzten beiden Parameter sind cidr_block (das zugewiesene Subnetz) und die Verfügbarkeitszone, in der dieses Subnetz erstellt wird. Der letzte Parameter wird auch über eine Variable festgelegt, die einen Wert aus der Datenliste gemäß dem Index der von [count.index] deklarierten Schleife übernimmt .Security_groups.tf Dateistruktur
Sicherheitsgruppen sind eine Art Firewall für Clouds, die nicht in der VM selbst, sondern in der Cloud erstellt werden kann. In diesem Fall beschreibt die Firewall zwei Regeln.Die erste Regel erstellt eine Sicherheitsgruppe namens kube. Diese Sicherheitsgruppe wird benötigt, um den gesamten ausgehenden Datenverkehr von Kubernetes-Knoten zuzulassen und den Knoten den freien Zugriff auf das Internet zu ermöglichen. Eingehender Verkehr zu Kubernetes-Knoten aus den Subnetzen der Knoten selbst ist ebenfalls zulässig. Somit können Kubernetes-Knoten ohne Einschränkungen untereinander arbeiten.Die zweite Regel erstellt die Sicherheitsgruppe ssh. Es ermöglicht eine SSH-Verbindung von einer beliebigen IP-Adresse zu Port 22 der Kubernetes-Cluster-VM:Spoilerresource "aws_security_group" "kube" {
vpc_id = "${aws_vpc.kube.id}"
name = "kubernetes"
# Allow all outbound
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
# Allow all internal
ingress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["${var.vpc_cidr}"]
}
}
resource "aws_security_group" "ssh" {
vpc_id = "${aws_vpc.kube.id}"
name = "ssh"
# Allow all inbound
ingress {
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
}
Hauptknoten. Master.tf-Dateistruktur
Die Datei master.tf beschreibt die Erstellung mehrerer Vorlagen und Instanzen. Insbesondere wird eine Kubernetes-Masterinstanz erstellt.Die Variable ami legt den AMI des Quellabbilds für die VM fest. Im Folgenden werden der VM-Typ und das Subnetz beschrieben, in dem sie erstellt wird. Beim Definieren eines Subnetzes wird erneut ein Zyklus verwendet, um VMs in jeder Verfügbarkeitszone zu erstellen.Als Nächstes werden die verwendeten Sicherheitsgruppen und der in der Datei main.tf angegebene Schlüssel deklariert. Das Feld user_data enthält die Ausführung einer Reihe von Cloud-Init-Skripten, deren Ergebnisse in der VM implementiert werden:Spoilerresource "aws_instance" "master" {
count = "1"
ami = "${var.kubernetes_ami}"
instance_type = "c3.large"
disable_api_termination = false
instance_initiated_shutdown_behavior = "terminate"
source_dest_check = false
subnet_id = "${aws_subnet.private.*.id[count.index % length(data.aws_availability_zones.az.names)]}"
associate_public_ip_address = true
vpc_security_group_ids = [
"${aws_security_group.ssh.id}",
"${aws_security_group.kube.id}",
]
key_name = "${aws_key_pair.kube.key_name}"
user_data = "${data.template_cloudinit_config.master.rendered}"
monitoring = "true"
}
Hauptknoten. Cloud init
Cloud-init ist ein Tool, das Canonical entwickelt. Sie können bestimmte Befehle in einer Cloud-Infrastruktur automatisch ausführen, nachdem Sie eine VM gestartet haben. Terraform verfügt über Mechanismen zur Integration mithilfe von Vorlagen .Da es unmöglich ist, alles Notwendige in der VM zu "backen", muss sie nach dem Start je nach Typ entweder dem Kubernetes-Cluster beitreten oder den Kubernetes-Cluster initialisieren. In der Cloud-Init-Dateivorlage mit dem Namen master.tpl werden mehrere Aktionen ausgeführt.1. Konfigurationsdateien für Kubeadm werden aufgezeichnet:#cloud-config
write_files:
- path: etc/kubernetes/kubeadm.conf
owner: root:root
content:
...
2. Eine Reihe von Befehlen wird ausgeführt:- Die IP-Adresse des Assistenten wird in die generierte Konfigurationsdatei geschrieben.
- Der Master im Kubernetes-Cluster wird mit dem Befehl kubeadm init initialisiert.
- Im Kubernetes-Cluster wird das Calico-Overlay-Netzwerk mit dem Befehl kubectl apply installiert.
runcmd:
- sed -i "s/CONTROL_PLANE_IP/$(curl http://169.254.169.254/latest/meta-data-local-ipv4)/g" /etc/kubernetes/kubeadm.conf
- kubeadm init --config /etc/kubernetes/kubeadm.conf
- mkdir -p $HOME/.kube
- sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
- sudo chown $(id -u):$(id -g) $HOME/.kube/config
- kubectl apply -f https://docs.projectcalico.org/v3.8/manifests/calico.yaml
Nach dem Ausführen der Befehle beim Starten der VM wird ein funktionierender Kubernetes-Cluster von einem Masterknoten abgerufen. Die verbleibenden Knoten werden diesem Masterknoten beitreten.Gewöhnliche Knoten. node.tf
Die Datei node.tf ähnelt der Datei master.tf. Hier werden auch Ressourcen erstellt, die in diesem Fall als Knoten bezeichnet werden. Der einzige Unterschied besteht darin, dass der Masterknoten in einer einzelnen Instanz erstellt wird und die Anzahl der erstellten Arbeitsknoten über die Variable node_count festgelegt wird:resource "aws_instance" "node" {
count = "${var.nodes_count}"
ami = "${var.kubernetes_ami}"
instance_type = "c3.large"
Die Cloud-Init-Datei für Arbeitsknoten führt nur einen Befehl aus - kubeadm join. Dieser Befehl hängt den fertigen Computer mithilfe des von uns gesendeten Autorisierungstokens an den Kubernetes-Cluster an.Starten Sie Terraform
Beim Start verwendet Terraform mehrere Module:- AWS-Modul
- Vorlagenmodul;
- TLS-Modul, das für die Schlüsselgenerierung verantwortlich ist.
Diese Module müssen auf dem lokalen Computer installiert sein:terraform init terraform/
Zusammen mit diesem Befehl wird das Verzeichnis angezeigt, in dem sich alle erforderlichen Dateien befinden. Bei der Initialisierung lädt Terraform alle angegebenen Module herunter. Anschließend müssen Sie den Befehl terraform plan ausführen:terraform plan -var-file terraform/vars/dev.tfvars terraform/
Bitte beachten Sie, dass zusätzlich zu dem Verzeichnis mit den Terraform-Dateien die var-Datei angezeigt wird, die die Werte der in den Terraform-Dateien verwendeten Variablen enthält. Das vars-Verzeichnis kann mehrere .tfvars-Dateien enthalten, mit denen Sie verschiedene Arten von Infrastrukturen mit einem Satz Terraform-Dateien verwalten können.Die Datei dev.tfvars selbst enthält die folgenden wichtigen Variablen:- Kubernetes_version (installierbare Version von Kubernetes);
- Kubernetes_ami (AMI-Image, das Packer erstellt hat).
Führen Sie nach dem Festlegen der erforderlichen Werte für die Variablen den Befehl terraform plan aus. Anschließend zeigt Terraform eine Liste der Aktionen an, die erforderlich sind, um den in den Terraform-Dateien beschriebenen Status zu erreichen.Wenden Sie nach dem Überprüfen dieser Liste die vorgeschlagenen Änderungen an:terraform apply -auto-approve -var-file terraform/vars/dev.tfvars terraform/Der Befehl terraform plan unterscheidet sich durch das Vorhandensein eines Schlüssels - Auto-Approve -, sodass die vorgenommenen Änderungen nicht mehr bestätigt werden müssen. Sie können diesen Schlüssel weglassen, aber dann muss jede Aktion manuell bestätigt werden.Kubernetes-Clusterstruktur
 Der Kubernetes-Cluster besteht aus einem Masterknoten, der Verwaltungsfunktionen ausführt, und Arbeitsknoten, auf denen im Cluster installierte Anwendungen ausgeführt werden.Auf dem Masterknoten sind vier Komponenten installiert, die den Betrieb dieses Systems sicherstellen:
Der Kubernetes-Cluster besteht aus einem Masterknoten, der Verwaltungsfunktionen ausführt, und Arbeitsknoten, auf denen im Cluster installierte Anwendungen ausgeführt werden.Auf dem Masterknoten sind vier Komponenten installiert, die den Betrieb dieses Systems sicherstellen:- ETCD, d. H. Kubernetes-Datenbank
- API-Server, über den wir Informationen in Kubernetes speichern und Informationen daraus abrufen;
- Controller Manager
- Planer
Auf den Arbeitsknoten sind zwei zusätzliche Komponenten installiert:- Kube-Proxy (verantwortlich für die Generierung von Netzwerkregeln im Kubernetes-Cluster);
- Kubelet (verantwortlich für das Senden des Befehls an den Docker-Dämon zum Ausführen von Anwendungen im Kubernetes-Cluster).
Zwischen den Knoten funktioniert das Calico-Netzwerk-Plug-In.Cluster-Workflow-Diagramm
, Kubernetes replicaset.
- API-, ETCD. .
- API- .
- Controller-manager API- , «», .
- Scheduler . ETCD API-.
- Kubelet API- Docker .
- Docker .
- Kubelet API- , .
, Kubernetes , . , , YAML-. , , API-. .
Kubeadm
 Das letzte erwähnenswerte Element ist Kubeadm. Das Bereitstellen eines neuen Kubernetes-Clusters ist immer ein mühsamer Prozess. In jeder Phase besteht das Risiko von Fehlern aufgrund des menschlichen Faktors, und viele Aufgaben sind einfach sehr routinemäßig und langwierig. Beispiel: Gießen von Zertifikaten für die TLS-Verschlüsselung zwischen Knoten und Aktualisieren dieser Zertifikate. Hier helfen Dienstprogramme für die grundlegende Vorlagenautomatisierung. Der Trick von Kubeadm ist, dass es offiziell für die Arbeit mit Kubernetes zertifiziert ist.Es ermöglicht Ihnen:
Das letzte erwähnenswerte Element ist Kubeadm. Das Bereitstellen eines neuen Kubernetes-Clusters ist immer ein mühsamer Prozess. In jeder Phase besteht das Risiko von Fehlern aufgrund des menschlichen Faktors, und viele Aufgaben sind einfach sehr routinemäßig und langwierig. Beispiel: Gießen von Zertifikaten für die TLS-Verschlüsselung zwischen Knoten und Aktualisieren dieser Zertifikate. Hier helfen Dienstprogramme für die grundlegende Vorlagenautomatisierung. Der Trick von Kubeadm ist, dass es offiziell für die Arbeit mit Kubernetes zertifiziert ist.Es ermöglicht Ihnen:- Installieren, konfigurieren und führen Sie alle wichtigen Clusterkomponenten aus
- Zertifikate verwalten, einschließlich drehen und neue ausschreiben;
- Verwalten von Clusterkomponentenversionen (Upgrade und Downgrade).
Gleichzeitig ist Kubeadm kein vollständiges Kubernetes-Clusterverwaltungssystem, sondern eine Art Baustein, mit dem Sie Kubernetes auf dem Knoten konfigurieren können, auf dem das Kubeadm-Dienstprogramm ausgeführt wird. Dies bedeutet, dass ein Orchestrierungssystem benötigt wird, das alle erforderlichen VMs ausführt, konfiguriert und Kubeadm auf allen Knoten ausführt. Für diese Zwecke wird Terraform verwendet.Repository mit allen Dateien
Hier platzieren wir alle Dateien und Konfigurationen an einem Ort, damit es für Sie bequemer ist. Wenn Sie keine private Cloud zur Hand haben, aber alle diese Schritte selbst ausführen und die Bereitstellung in der Praxis testen möchten, schreiben Sie uns an cloud@croc.ru.Wir geben Ihnen eine Demoversion für Tests und beraten Sie in allen Fragen.Und bald wird es einen neuen Slurm geben , in dem Sie Ihren eigenen Cluster erstellen können. Der CROC-Gutscheincode bietet 10% Rabatt.Für diejenigen, die bereits mit Kubernetes arbeiten, gibt es einen Fortgeschrittenenkurs . Der Rabatt ist der gleiche.Kollegen, Habraparser bricht das Markup des Codes. Bitte nehmen Sie die Quelle von GitHub über den obigen Link.