Bei der komplexen Verarbeitung großer Datenmengen (verschiedene ETL-Prozesse : Importe, Konvertierungen und Synchronisation mit einer externen Quelle) ist es häufig erforderlich, sich vorübergehend an etwas Volumenreiches zu erinnern und es sofort zu verarbeiten .Eine typische Aufgabe dieser Art klingt normalerweise so: „Hier hat die Buchhaltungsabteilung die zuletzt erhaltenen Zahlungen von der Kundenbank hochgeladen. Wir müssen sie schnell auf die Website hochladen und mit den Konten verknüpfen.“Wenn jedoch das Volumen dieses „Etwas“ in Hunderten von Megabyte und des Dienstes gemessen wird Dies sollte weiterhin mit der Basis im 24x7-Modus funktionieren. Es gibt viele Nebenwirkungen, die Ihr Leben ruinieren werden.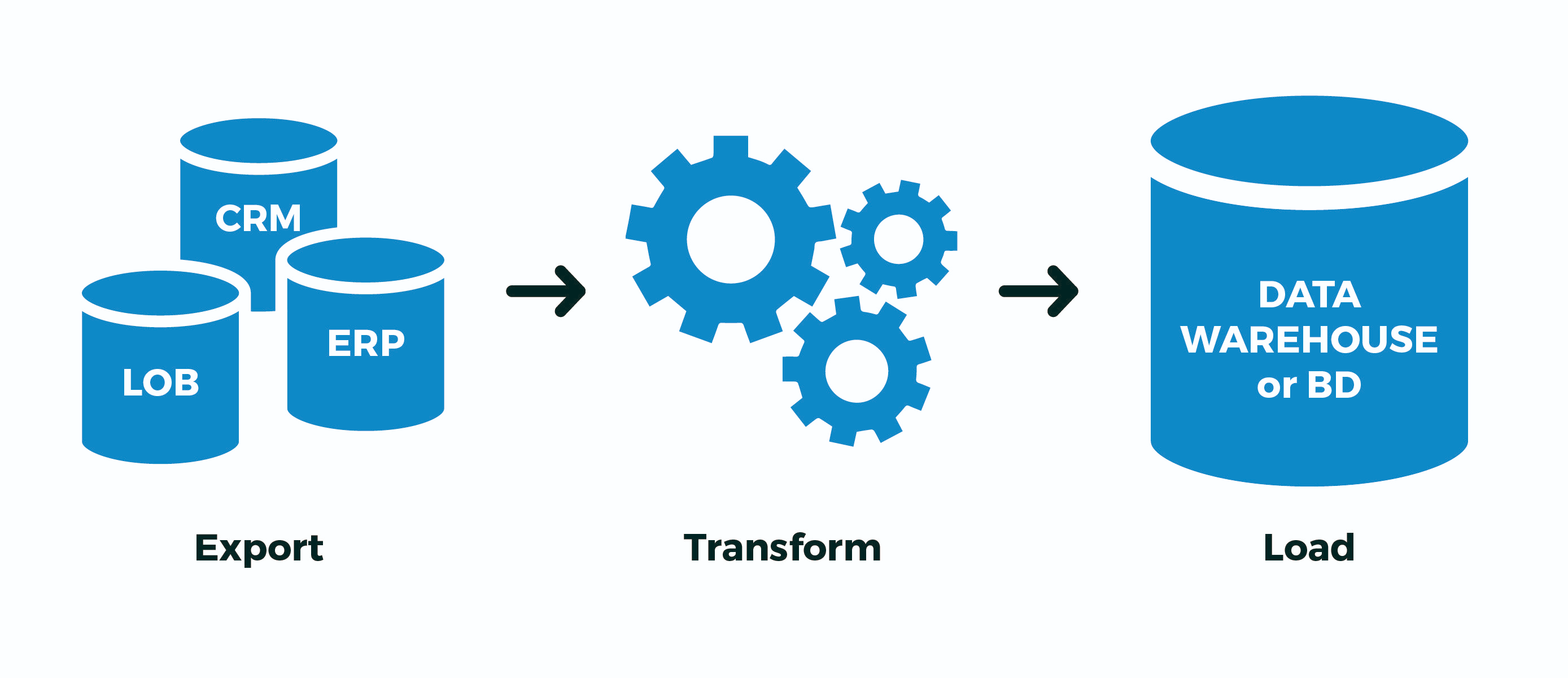 Um mit ihnen in PostgreSQL (und nicht nur darin) fertig zu werden, können Sie einige Optimierungsoptionen verwenden, mit denen Sie schneller und mit weniger Ressourcen verarbeiten können.
Um mit ihnen in PostgreSQL (und nicht nur darin) fertig zu werden, können Sie einige Optimierungsoptionen verwenden, mit denen Sie schneller und mit weniger Ressourcen verarbeiten können.1. Wohin versenden?
Lassen Sie uns zunächst entscheiden, wo wir die Daten hochladen können, die wir „verarbeiten“ möchten.1.1. Temporäre Tabellen (VORÜBERGEHENDE TABELLE)
Im Prinzip sind temporäre Tabellen für PostgreSQL dieselben wie alle anderen. Aberglauben wie „alles wird dort nur im Speicher gespeichert, aber es kann enden“ sind falsch . Es gibt jedoch einige signifikante Unterschiede.Eigener Namespace für jede Verbindung zur Datenbank
Wenn zwei Verbindungen gleichzeitig hergestellt werden sollen CREATE TABLE x, wird definitiv jemand einen Fehler mit nicht eindeutigen DB-Objekten erhalten.Wenn jedoch beide versuchen, etwas auszuführen , tun dies normalerweise beide und jeder erhält seine eigene Kopie der Tabelle. Und es wird nichts gemeinsam zwischen ihnen geben.CREATE TEMPORARY TABLE x"Selbstzerstörung" mit Unterbrechung
Wenn Sie die Verbindung schließen, werden alle temporären Tabellen automatisch gelöscht, sodass DROP TABLE xes keinen Sinn macht, sie manuell auszuführen , außer ...Wenn Sie pgbouncer im Transaktionsmodus durcharbeiten , geht die Datenbank weiterhin davon aus, dass diese Verbindung noch aktiv ist, und diese temporäre Die Tabelle existiert noch.Daher führt ein Versuch, es von einer anderen Verbindung zu pgbouncer neu zu erstellen, zu einem Fehler. Dies kann jedoch durch Ausnutzen umgangen werden . Es ist zwar besser, dies nicht zu tun, da Sie dann "plötzlich" die Daten herausfinden können, die vom "Vorbesitzer" übrig geblieben sind. Stattdessen ist es viel besser, das Handbuch zu lesen und zu sehen, dass beim Erstellen der Tabelle die Möglichkeit besteht, diese hinzuzufügenCREATE TEMPORARY TABLE IF NOT EXISTS xON COMMIT DROP - Das heißt, wenn die Transaktion abgeschlossen ist, wird die Tabelle automatisch gelöscht.Nichtreplikation
Da nur ein bestimmter Join gehört, werden temporäre Tabellen nicht repliziert. Dadurch entfällt jedoch die Notwendigkeit, Daten in Heap + WAL doppelt zu schreiben , sodass INSERT / UPDATE / DELETE viel schneller ist.Da die temporäre Tabelle jedoch immer noch eine „fast normale“ Tabelle ist, kann sie auch nicht auf dem Replikat erstellt werden. Zumindest für den Moment, obwohl es den entsprechenden Patch schon lange gibt.1.2. Nicht protokollierte Tabellen (UNLOGGED TABLE)
Aber was tun, wenn Sie beispielsweise einen umständlichen ETL-Prozess haben, der nicht innerhalb einer einzelnen Transaktion implementiert werden kann, und pgbouncer immer noch im Transaktionsmodus haben ?Oder der Datenstrom ist so groß, dass nicht genügend Bandbreite pro Verbindung vorhanden ist aus der Datenbank (gelesen, ein Prozess auf der CPU)? ..Oder ein Teil der Operationen läuft asynchron in verschiedenen Verbindungen? ..Es gibt nur eine Option - vorübergehend eine nicht temporäre Tabelle erstellen . Wortspiel, ja. Also:- erstellte "seine" Tabellen mit maximal zufälligen Namen, um mit niemandem zu kreuzen
- Extrahieren : Daten von einer externen Quelle in sie gegossen
- Transformieren : transformiert, ausgefüllt mit Schlüsselbindungsfeldern
- Laden : Fertige Daten in Zieltabellen gegossen
- "meine" Tabellen gelöscht
Und jetzt - eine Fliege in der Salbe. Tatsächlich erfolgt das gesamte Schreiben in PostgreSQL zweimal - zuerst in der WAL , dann im Hauptteil der Tabelle / des Index. All dies geschieht, um ACID und die korrekte Sichtbarkeit von Daten zwischen COMMITverschachtelten und ROLLBACKverschachtelten Transaktionen zu unterstützen.Das brauchen wir aber nicht! Wir haben den gesamten Prozess oder erfolgreich bestanden oder nicht . Es spielt keine Rolle, wie viele Zwischentransaktionen darin enthalten sind - wir sind nicht daran interessiert, den Prozess von der Mitte aus fortzusetzen, insbesondere wenn nicht klar ist, wo er sich befand.Zu diesem Zweck haben die PostgreSQL-Entwickler Version 9.1 eingeführt, z. B. nicht journalisierte (UNLOGGED) Tabellen :. , , (. 29), . , ; . , . , , .
Kurz gesagt, es wird viel schneller sein , aber wenn der Datenbankserver "abstürzt", wird es unangenehm sein. Aber wie oft passiert dies und weiß Ihr ETL-Prozess, wie er nach der „Revitalisierung“ der Datenbank „von der Mitte“ korrekt geändert werden kann?Wenn nicht, und der obige Fall ähnelt Ihrem - verwenden Sie dieses Attribut , fügen Sie es UNLOGGEDjedoch niemals in reale Tabellen ein Daten, von denen Sie lieb sind.1.3. ON COMMIT {REIHEN LÖSCHEN | FALLEN}
Dieses Design ermöglicht es beim Erstellen einer Tabelle, das automatische Verhalten beim Beenden der Transaktion festzulegen.Über das ich oben schon geschrieben habe, generiert es , aber die Situation ist interessanter - hier wird es generiert . Da die gesamte Infrastruktur zum Speichern der Meta-Beschreibung der temporären Tabelle genau der üblichen entspricht, führt das ständige Erstellen und Löschen temporärer Tabellen zu einer starken "Schwellung" der Systemtabellen pg_class, pg_attribute, pg_attrdef, pg_depend, ... Stellen Sie sich nun vor, Sie haben einen Worker in der Zeile Durch das Herstellen einer Verbindung zur Datenbank, die jede Sekunde eine neue Transaktion öffnet, wird die temporäre Tabelle erstellt, gefüllt, verarbeitet und gelöscht. Der Müll in den Systemtabellen sammelt sich übermäßig an, und dies ist eine zusätzliche Bremse bei jedem Vorgang.ON COMMIT DROPDROP TABLEON COMMIT DELETE ROWSTRUNCATE TABLEIm Allgemeinen nicht! In diesem Fall ist es viel effizienter CREATE TEMPORARY TABLE x ... ON COMMIT DELETE ROWS, es aus dem Transaktionszyklus herauszunehmen. Dann ist die Tabelle zu Beginn jeder neuen Transaktion bereits vorhanden (Aufruf speichern CREATE), aber dank (wir haben auch den Anruf gespeichert) leer , TRUNCATEals die vorherige Transaktion abgeschlossen wurde.1.4. WIE ... EINSCHLIESSLICH ...
Ich erwähnte am Anfang, dass einer der typischen Anwendungsfälle für temporäre Tabellen verschiedene Arten von Importen sind - und der Entwickler kopiert müde die Liste der Felder der Zieltabelle in die Deklaration seiner temporären Tabellen ...Aber Faulheit ist der Motor des Fortschritts! Daher kann das Erstellen einer neuen Tabelle „am Modell“ viel einfacher sein:CREATE TEMPORARY TABLE import_table(
LIKE target_table
);
Da Sie dieser Tabelle dann viele Daten hinzufügen können, wird die Suche in dieser Tabelle niemals schnell gehen. Aber dagegen gibt es eine traditionelle Lösung - Indizes! Und ja, eine temporäre Tabelle kann auch Indizes enthalten .Da die gewünschten Indizes häufig mit den Indizes der Zieltabelle übereinstimmen, können Sie einfach schreiben . Wenn Sie auch -Werte benötigen (um beispielsweise die Primärschlüsselwerte einzugeben), können Sie diese verwenden . Nun, oder einfach - - es werden Standardeinstellungen, Indizes, Einschränkungen kopiert ... Aber hier müssen Sie verstehen, dass die Daten länger ausgefüllt werden , wenn Sie sofort eine Importtabelle mit Indizes erstellt habenLIKE target_table INCLUDING INDEXESDEFAULTLIKE target_table INCLUDING DEFAULTSLIKE target_table INCLUDING ALLals wenn Sie zuerst alles füllen und dann die Indizes rollen - sehen Sie als Beispiel, wie pg_dump das macht .Alles in allem RTFM !2. Wie schreibe ich?
Ich werde einfach sagen - benutze COPY-stream anstelle von "Packs" INSERT, manchmal Beschleunigung . Sie können sogar direkt aus einer vorgenerierten Datei.3. Wie gehe ich damit um?
Lassen Sie unsere Einführung also ungefähr so aussehen:- Sie haben in Ihrer Datenbank eine Platte mit Kundendaten für 1M-Datensätze
- Jeden Tag sendet Ihnen der Kunde ein neues vollständiges „Bild“.
- Aus Erfahrung wissen Sie, dass sich von Zeit zu Zeit nicht mehr als 10.000 Datensätze ändern
Ein klassisches Beispiel für eine solche Situation ist die KLADR-Datenbank - es gibt viele Adressen, aber bei jedem wöchentlichen Hochladen von Änderungen (Umbenennung von Siedlungen, Straßenverbänden, Erscheinen neuer Häuser) gibt es landesweit nur sehr wenige.3.1. Vollständiger Synchronisationsalgorithmus
Nehmen wir zur Vereinfachung an, Sie müssen die Daten nicht einmal umstrukturieren. Bringen Sie die Tabelle einfach in die richtige Form, dh:- lösche alles was nicht mehr ist
- Aktualisieren Sie alles, was bereits war, und Sie müssen aktualisieren
- füge alles ein, was nicht war
Warum lohnt es sich in dieser Reihenfolge, Operationen durchzuführen? Denn so wächst die Größe der Tabelle minimal ( denken Sie an MVCC! ).LÖSCHEN VON dst
Nein, natürlich können Sie nur zwei Operationen ausführen:- delete (
DELETE) überhaupt - füge alles aus einem neuen Bild ein
Gleichzeitig wird die Tabelle dank MVCC genau doppelt so groß ! Erhalten Sie + 1M Bilddatensätze in der Tabelle aufgrund eines 10K-Updates - mittelmäßige Redundanz ...TRUNCATE dst
Ein erfahrener Entwickler weiß, dass die gesamte Platte recht billig gereinigt werden kann:- clear (
TRUNCATE) die ganze Tabelle - füge alles aus einem neuen Bild ein
Die Methode ist effektiv, manchmal durchaus anwendbar , aber es gibt ein Problem ... Wir werden 1 Million Datensätze einfügen, sodass wir es uns nicht leisten können, die Tabelle die ganze Zeit leer zu lassen (wie dies ohne das Umschließen einer einzelnen Transaktion geschehen wird).Was bedeutet:- Wir starten eine lange Transaktion
TRUNCATElegt AccessExclusive -Lock fest- Wir machen die Einfügung für eine lange Zeit, und alle anderen zu diesem Zeitpunkt können nicht einmal
SELECT
Etwas ist schlecht ...ALTER TABLE ... RENAME ... / DROP TABLE ...
Füllen Sie optional alles in eine separate neue Tabelle aus und benennen Sie sie dann einfach in die alte um. Ein paar böse kleine Dinge:- AccessExclusive auch , wenn auch wesentlich kürzer
- Alle Abfragepläne / Statistiken dieser Tabelle werden zurückgesetzt. ANALYZE muss ausgeführt werden
- Alle Fremdschlüssel (FK) brechen auf dem Tisch
Es gab einen WIP-Patch von Simon Riggs, der vorschlug, eine ALTEROperation zum Ersetzen des Tabellenkörpers auf Dateiebene durchzuführen, ohne die Statistik und FK zu berühren, aber das Quorum nicht sammelte.LÖSCHEN, AKTUALISIEREN, EINFÜGEN
Wir stoppen also bei einer nicht blockierenden Version von drei Operationen. Fast drei ... Wie geht das am effektivsten?
BEGIN;
CREATE TEMPORARY TABLE tmp(
LIKE dst INCLUDING INDEXES
) ON COMMIT DROP;
COPY tmp FROM STDIN;
DELETE FROM
dst D
USING
dst X
LEFT JOIN
tmp Y
USING(pk1, pk2)
WHERE
(D.pk1, D.pk2) = (X.pk1, X.pk2) AND
Y IS NOT DISTINCT FROM NULL;
UPDATE
dst D
SET
(f1, f2, f3) = (T.f1, T.f2, T.f3)
FROM
tmp T
WHERE
(D.pk1, D.pk2) = (T.pk1, T.pk2) AND
(D.f1, D.f2, D.f3) IS DISTINCT FROM (T.f1, T.f2, T.f3);
INSERT INTO
dst
SELECT
T.*
FROM
tmp T
LEFT JOIN
dst D
USING(pk1, pk2)
WHERE
D IS NOT DISTINCT FROM NULL;
COMMIT;
3.2. Nachbearbeitung importieren
In demselben KLADER müssen alle geänderten Datensätze zusätzlich nachbearbeitet werden - normalisieren, Schlüsselwörter hervorheben und zu den erforderlichen Strukturen bringen. Aber woher wissen Sie, was sich genau geändert hat , ohne den Synchronisationscode zu komplizieren, idealerweise ohne ihn überhaupt zu berühren?Wenn zum Zeitpunkt der Synchronisierung nur Ihr Prozess Schreibzugriff hat, können Sie einen Trigger verwenden, der alle Änderungen für uns erfasst:
CREATE TABLE kladr(...);
CREATE TABLE kladr_house(...);
CREATE TABLE kladr$log(
ro kladr,
rn kladr
);
CREATE TABLE kladr_house$log(
ro kladr_house,
rn kladr_house
);
CREATE OR REPLACE FUNCTION diff$log() RETURNS trigger AS $$
DECLARE
dst varchar = TG_TABLE_NAME || '$log';
stmt text = '';
BEGIN
IF TG_OP = 'UPDATE' THEN
IF NEW IS NOT DISTINCT FROM OLD THEN
RETURN NEW;
END IF;
END IF;
stmt = 'INSERT INTO ' || dst::text || '(ro,rn)VALUES(';
CASE TG_OP
WHEN 'INSERT' THEN
EXECUTE stmt || 'NULL,$1)' USING NEW;
WHEN 'UPDATE' THEN
EXECUTE stmt || '$1,$2)' USING OLD, NEW;
WHEN 'DELETE' THEN
EXECUTE stmt || '$1,NULL)' USING OLD;
END CASE;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
Jetzt können wir Trigger auferlegen (oder durch aktivieren ALTER TABLE ... ENABLE TRIGGER ...), bevor wir mit der Synchronisation beginnen :CREATE TRIGGER log
AFTER INSERT OR UPDATE OR DELETE
ON kladr
FOR EACH ROW
EXECUTE PROCEDURE diff$log();
CREATE TRIGGER log
AFTER INSERT OR UPDATE OR DELETE
ON kladr_house
FOR EACH ROW
EXECUTE PROCEDURE diff$log();
Und dann extrahieren wir leise aus den Protokolltabellen alle erforderlichen Änderungen und führen sie über zusätzliche Handler aus.3.3. Verwandte Sets importieren
Oben haben wir Fälle betrachtet, in denen die Datenstrukturen von Quelle und Empfänger übereinstimmen. Was aber, wenn das Entladen von einem externen System ein anderes Format hat als die Speicherstruktur in unserer Datenbank?Nehmen Sie als Beispiel die Speicherung von Kunden und deren Konten, die klassische Viele-zu-Eins-Option:CREATE TABLE client(
client_id
serial
PRIMARY KEY
, inn
varchar
UNIQUE
, name
varchar
);
CREATE TABLE invoice(
invoice_id
serial
PRIMARY KEY
, client_id
integer
REFERENCES client(client_id)
, number
varchar
, dt
date
, sum
numeric(32,2)
);
Das Entladen von einer externen Quelle erfolgt jedoch in Form von "All in One":CREATE TEMPORARY TABLE invoice_import(
client_inn
varchar
, client_name
varchar
, invoice_number
varchar
, invoice_dt
date
, invoice_sum
numeric(32,2)
);
Offensichtlich können Kundendaten auf diese Weise dupliziert werden, und der Hauptdatensatz ist das „Konto“:0123456789;;A-01;2020-03-16;1000.00
9876543210;;A-02;2020-03-16;666.00
0123456789;;B-03;2020-03-16;9999.00
Geben Sie für das Modell einfach unsere Testdaten ein, aber denken Sie daran - COPYeffizienter!INSERT INTO invoice_import
VALUES
('0123456789', '', 'A-01', '2020-03-16', 1000.00)
, ('9876543210', '', 'A-02', '2020-03-16', 666.00)
, ('0123456789', '', 'B-03', '2020-03-16', 9999.00);
Zuerst wählen wir die „Schnitte“ aus, auf die sich unsere „Fakten“ beziehen. In unserem Fall beziehen sich Konten auf Kunden:CREATE TEMPORARY TABLE client_import AS
SELECT DISTINCT ON(client_inn)
client_inn inn
, client_name "name"
FROM
invoice_import;
Um Konten korrekt mit Kunden-IDs zu verknüpfen, müssen wir diese Kennungen zuerst herausfinden oder generieren. Fügen Sie Felder für sie hinzu:ALTER TABLE invoice_import ADD COLUMN client_id integer;
ALTER TABLE client_import ADD COLUMN client_id integer;
Wir werden die Methode zum Synchronisieren von Tabellen mit der oben beschriebenen kleinen Korrektur verwenden - wir werden nichts in der Zieltabelle aktualisieren oder löschen, da das Importieren von Clients "nur anhängen" ist:
UPDATE
client_import T
SET
client_id = D.client_id
FROM
client D
WHERE
T.inn = D.inn;
WITH ins AS (
INSERT INTO client(
inn
, name
)
SELECT
inn
, name
FROM
client_import
WHERE
client_id IS NULL
RETURNING *
)
UPDATE
client_import T
SET
client_id = D.client_id
FROM
ins D
WHERE
T.inn = D.inn;
UPDATE
invoice_import T
SET
client_id = D.client_id
FROM
client_import D
WHERE
T.client_inn = D.inn;
Eigentlich alles - invoice_importjetzt haben wir das Kommunikationsfeld ausgefüllt, client_idmit dem wir das Konto einfügen werden.