Pandas braucht keine Einführung: Heute ist es das Hauptwerkzeug für die Analyse von Daten in Python. Ich arbeite als Datenanalysespezialist und trotz der Tatsache, dass ich jeden Tag Pandas benutze, bin ich immer wieder überrascht über die Vielfalt der Funktionen dieser Bibliothek. In diesem Artikel möchte ich über fünf wenig bekannte Pandas-Funktionen sprechen, die ich kürzlich gelernt habe und jetzt produktiv verwende.Für Anfänger: Pandas ist ein leistungsstarkes Toolkit für die Datenanalyse in Python mit einfachen und praktischen Datenstrukturen. Der Name stammt vom Konzept der „Paneldaten“, einem ökonometrischen Begriff, der sich auf Daten zu Beobachtungen derselben Probanden über verschiedene Zeiträume bezieht.Hier können Sie das Jupyter-Notizbuch mit Beispielen aus dem Artikel herunterladen .1. Datumsbereiche [Datumsbereiche]
Oft müssen Sie Datumsbereiche angeben, wenn Sie Daten von einer externen API oder Datenbank anfordern. Pandas werden uns nicht in Schwierigkeiten bringen. Nur für diese Fälle gibt es die Funktion data_range , die eine Reihe von Daten zurückgibt , die um Tage, Monate, Jahre usw. erhöht wurden.Angenommen, wir benötigen einen Datumsbereich pro Tag:date_from = "2019-01-01"
date_to = "2019-01-12"
date_range = pd.date_range(date_from, date_to, freq="D")
date_range
 Wir werden das Generierte von
Wir werden das Generierte von date_rangein Datumspaare "von" und "bis" umwandeln , die auf die entsprechende Funktion übertragen werden können.for i, (date_from, date_to) in enumerate(zip(date_range[:-1], date_range[1:]), 1):
date_from = date_from.date().isoformat()
date_to = date_to.date().isoformat()
print("%d. date_from: %s, date_to: %s" % (i, date_from, date_to))
1. date_from: 2019-01-01, date_to: 2019-01-02
2. date_from: 2019-01-02, date_to: 2019-01-03
3. date_from: 2019-01-03, date_to: 2019-01-04
4. date_from: 2019-01-04, date_to: 2019-01-05
5. date_from: 2019-01-05, date_to: 2019-01-06
6. date_from: 2019-01-06, date_to: 2019-01-07
7. date_from: 2019-01-07, date_to: 2019-01-08
8. date_from: 2019-01-08, date_to: 2019-01-09
9. date_from: 2019-01-09, date_to: 2019-01-10
10. date_from: 2019-01-10, date_to: 2019-01-11
11. date_from: 2019-01-11, date_to: 2019-01-12
2. Mit dem Quellindikator zusammenführen [Mit Indikator zusammenführen]
Das Zusammenführen von zwei Datensätzen ist seltsamerweise der Prozess des Kombinierens von zwei Datensätzen zu einem, dessen Zeilen basierend auf gemeinsamen Spalten oder Eigenschaften zugeordnet werden.Eines der beiden Argumente für die Zusammenführungsfunktion, die ich irgendwie übersehen habe, ist indicator. Der „Indikator“ fügt _mergedem DataFrame eine Spalte hinzu, die zeigt, woher die Zeile stammt, von links, rechts oder von beiden DataFrames. Eine Spalte _mergekann sehr nützlich sein, wenn Sie mit großen Datenmengen arbeiten, um zu überprüfen, ob die Zusammenführung korrekt ist.left = pd.DataFrame({"key": ["key1", "key2", "key3", "key4"], "value_l": [1, 2, 3, 4]})
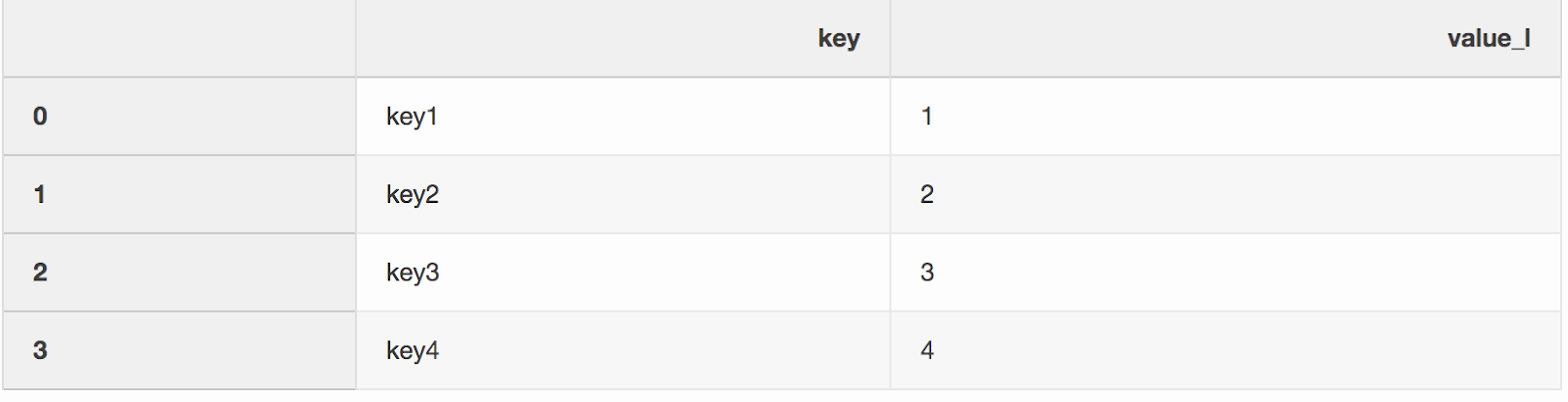
right = pd.DataFrame({"key": ["key3", "key2", "key1", "key6"], "value_r": [3, 2, 1, 6]})
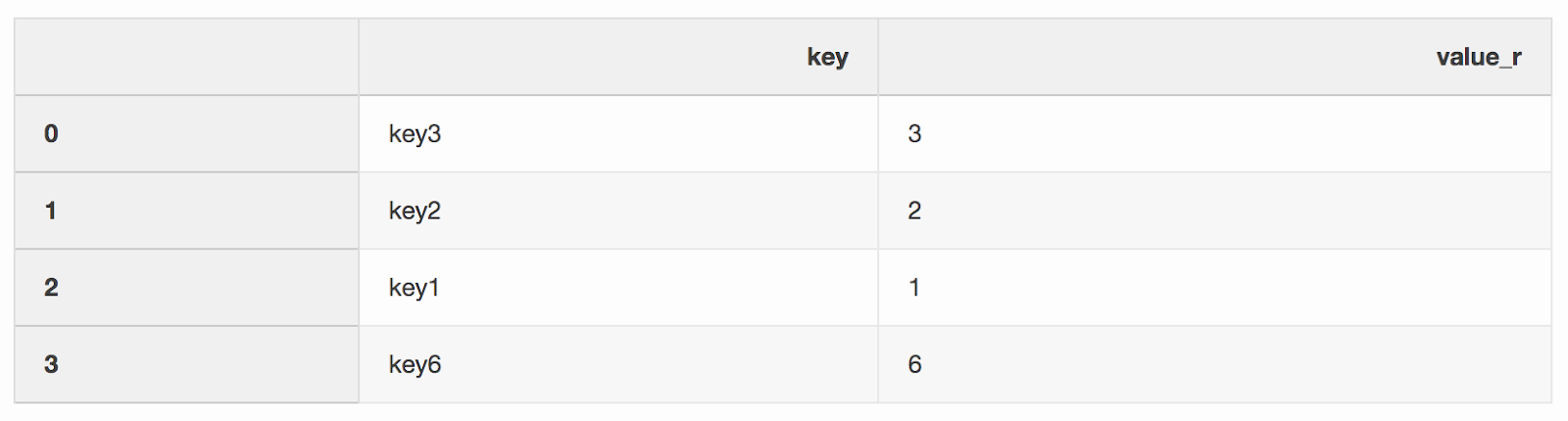
df_merge = left.merge(right, on='key', how='left', indicator=True)
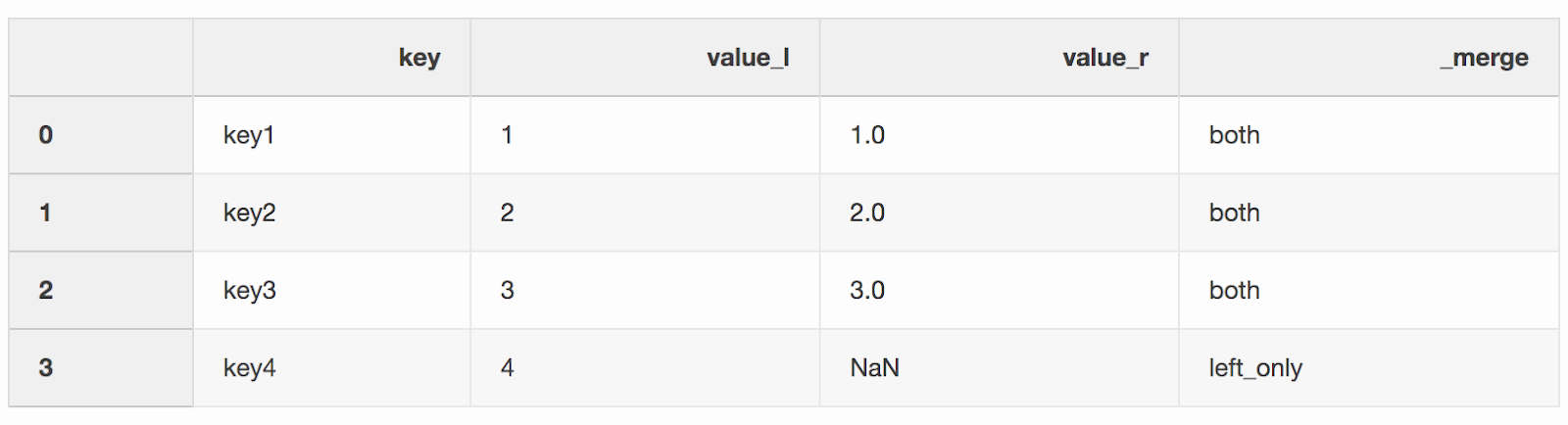 In der Spalte
In der Spalte _mergekann überprüft werden, ob die richtige Anzahl von Zeilen mit Daten aus beiden DataFrames stammt.df_merge._merge.value_counts()
both 3
left_only 1
right_only 0
Name: _merge, dtype: int64
3. Zusammenführen mit dem nächstgelegenen Wert [Nächste Zusammenführung]
Bei der Arbeit mit Finanzdaten wie Kryptowährungen und Wertpapieren kann es erforderlich sein, Quotes (Preisänderungen) mit Transaktionen zu vergleichen. Angenommen, wir möchten jeden Trade mit einem Angebot kombinieren, das einige Millisekunden vor dem Trade aktualisiert wurde. Pandas hat eine Funktion, merge_asofaufgrund derer es möglich ist, DataFrames nach dem nächsten Schlüsselwert ( timestampin unserem Fall) zu kombinieren . Datensätze mit Quotes und Deals stammen aus dem Pandas-Beispiel .DataFrame quotes("Quotes") enthält Preisänderungen für verschiedene Aktien. In der Regel gibt es viel mehr Angebote als Angebote.quotes = pd.DataFrame(
[
["2016-05-25 13:30:00.023", "GOOG", 720.50, 720.93],
["2016-05-25 13:30:00.023", "MSFT", 51.95, 51.96],
["2016-05-25 13:30:00.030", "MSFT", 51.97, 51.98],
["2016-05-25 13:30:00.041", "MSFT", 51.99, 52.00],
["2016-05-25 13:30:00.048", "GOOG", 720.50, 720.93],
["2016-05-25 13:30:00.049", "AAPL", 97.99, 98.01],
["2016-05-25 13:30:00.072", "GOOG", 720.50, 720.88],
["2016-05-25 13:30:00.075", "MSFT", 52.01, 52.03],
],
columns=["timestamp", "ticker", "bid", "ask"],
)
quotes['timestamp'] = pd.to_datetime(quotes['timestamp'])
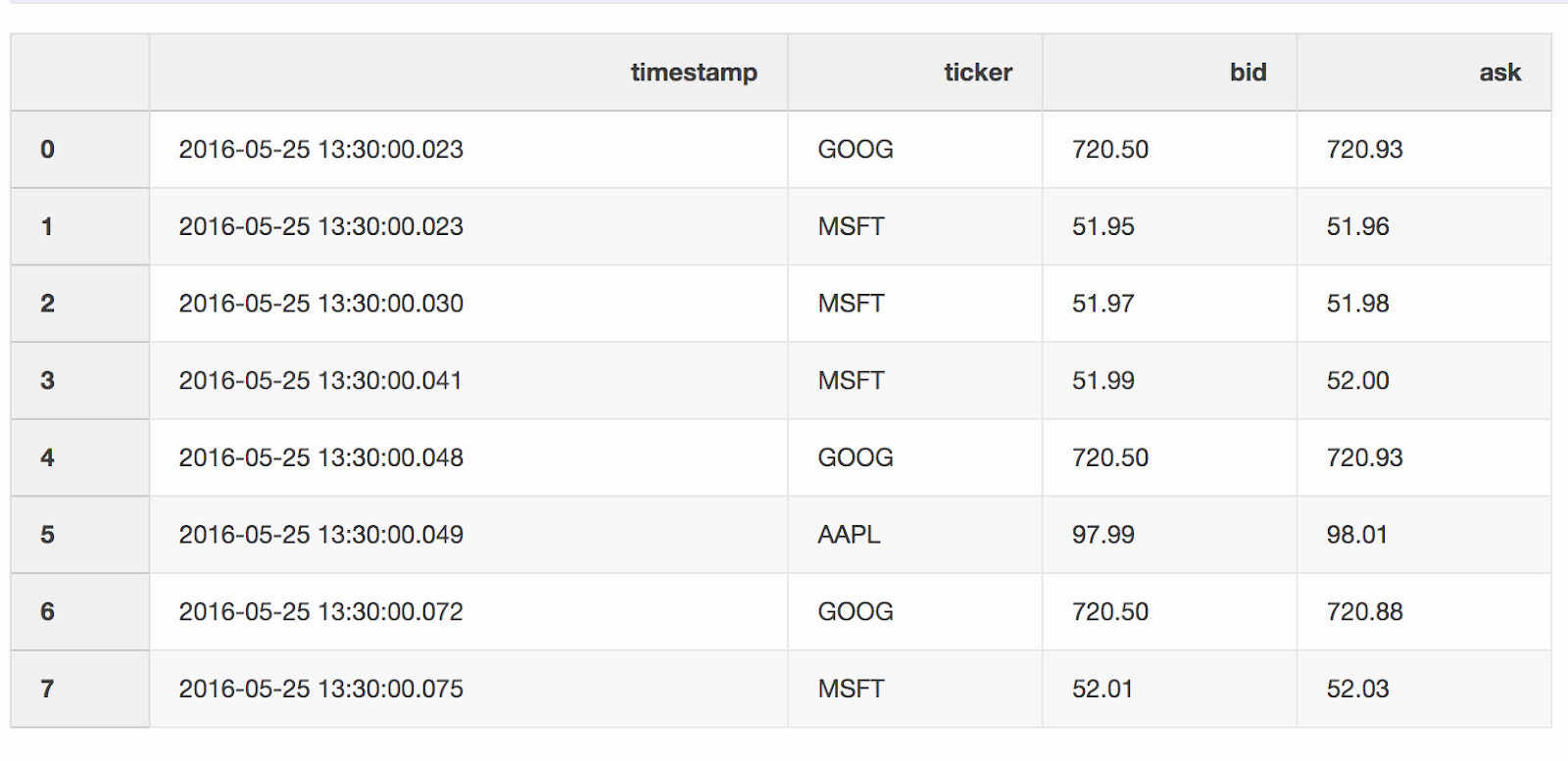 DataFrame
DataFrame tradesenthält Angebote für verschiedene Aktien.trades = pd.DataFrame(
[
["2016-05-25 13:30:00.023", "MSFT", 51.95, 75],
["2016-05-25 13:30:00.038", "MSFT", 51.95, 155],
["2016-05-25 13:30:00.048", "GOOG", 720.77, 100],
["2016-05-25 13:30:00.048", "GOOG", 720.92, 100],
["2016-05-25 13:30:00.048", "AAPL", 98.00, 100],
],
columns=["timestamp", "ticker", "price", "quantity"],
)
trades['timestamp'] = pd.to_datetime(trades['timestamp'])
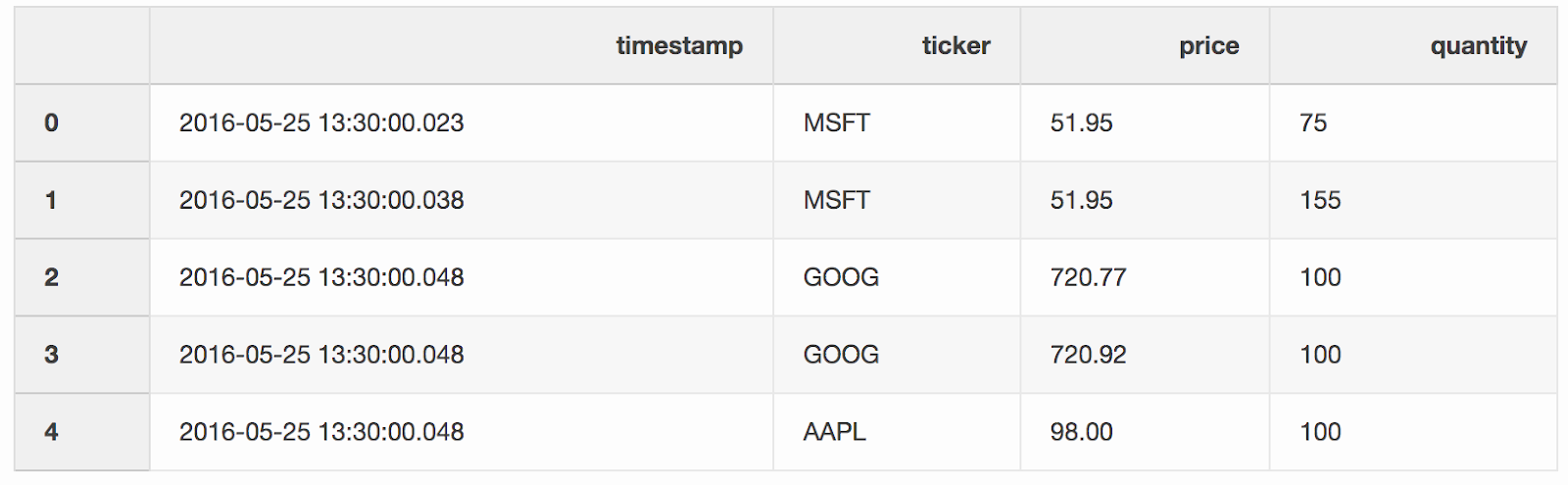 Wir führen Transaktionen und Quotes nach Tickern zusammen (ein börsennotiertes Instrument wie Aktien), sofern das
Wir führen Transaktionen und Quotes nach Tickern zusammen (ein börsennotiertes Instrument wie Aktien), sofern das timestampletzte Quote 10 ms unter der Transaktion liegt. Wenn das Angebot länger als 10 ms vor der Transaktion angezeigt wurde, lautet das Gebot (der Preis, den der Käufer zu zahlen bereit ist) und die Anfrage (der Preis, zu dem der Verkäufer bereit ist zu verkaufen) für dieses Angebot null(AAPL-Ticker in diesem Beispiel).pd.merge_asof(trades, quotes, on="timestamp", by='ticker', tolerance=pd.Timedelta('10ms'), direction='backward')

4. Erstellen eines Excel-Berichts
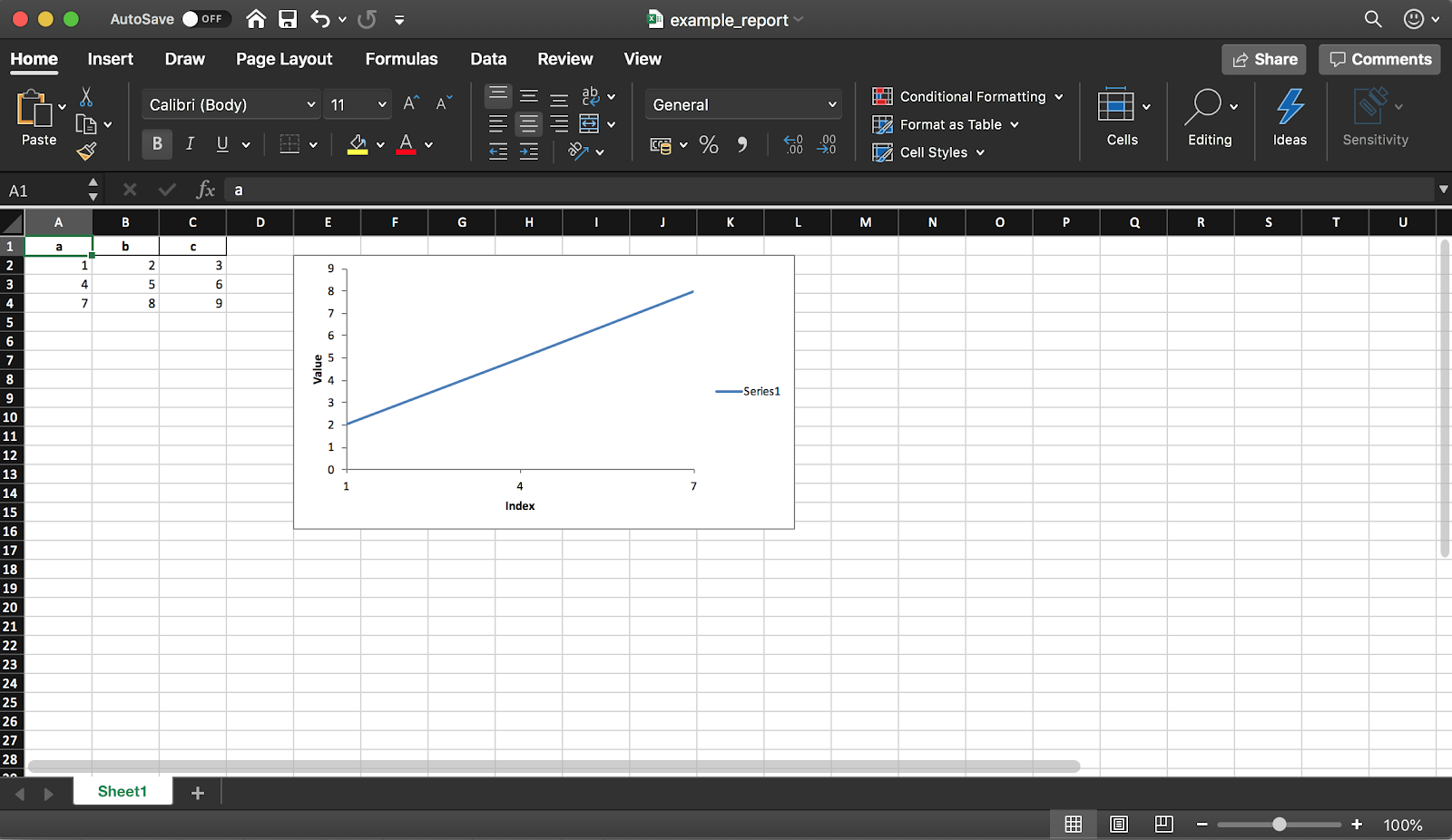 Mit Pandas (mit der XlsxWriter-Bibliothek) können Sie einen Excel-Bericht aus einem DataFrame erstellen. Dies spart Ihnen eine Menge Zeit - Sie müssen keinen DataFrame mehr in CSV exportieren und nicht mehr manuell in Excel formatieren. Alle Arten von Diagrammen usw. sind ebenfalls verfügbar .
Mit Pandas (mit der XlsxWriter-Bibliothek) können Sie einen Excel-Bericht aus einem DataFrame erstellen. Dies spart Ihnen eine Menge Zeit - Sie müssen keinen DataFrame mehr in CSV exportieren und nicht mehr manuell in Excel formatieren. Alle Arten von Diagrammen usw. sind ebenfalls verfügbar .df = pd.DataFrame(pd.np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=["a", "b", "c"])
Das folgende Codefragment erstellt eine Tabelle im Excel-Format. Kommentieren Sie die Zeile aus, um sie in einer Datei zu speichern writer.save().report_name = 'example_report.xlsx'
sheet_name = 'Sheet1'
writer = pd.ExcelWriter(report_name, engine='xlsxwriter')
df.to_excel(writer, sheet_name=sheet_name, index=False)
Wie bereits erwähnt, können Sie mithilfe der Bibliothek dem Bericht auch Diagramme hinzufügen. Sie müssen den Diagrammtyp (in unserem Beispiel linear) und den Datenbereich dafür festlegen (der Datenbereich sollte sich in der Excel-Tabelle befinden).
workbook = writer.book
worksheet = writer.sheets[sheet_name]
chart = workbook.add_chart({'type': 'line'})
chart.add_series({
'categories': [sheet_name, 1, 0, 3, 0],
'values': [sheet_name, 1, 1, 3, 1],
})
chart.set_x_axis({'name': 'Index', 'position_axis': 'on_tick'})
chart.set_y_axis({'name': 'Value', 'major_gridlines': {'visible': False}})
worksheet.insert_chart('E2', chart)
writer.save()
5. Speichern Sie Speicherplatz
Die Arbeit an einer großen Anzahl von Datenanalyseprojekten hinterlässt normalerweise Spuren in Form einer großen Menge verarbeiteter Daten aus verschiedenen Experimenten. Die SSD auf dem Laptop füllt sich ziemlich schnell. Mit Pandas können Sie Daten komprimieren, während Sie Daten auf der Festplatte speichern und sie dann erneut aus einem komprimierten Format lesen.Erstellen Sie einen großen DataFrame mit Zufallszahlen.df = pd.DataFrame(pd.np.random.randn(50000,300))
 Wenn Sie es als CSV speichern, belegt die Datei fast 300 MB auf Ihrer Festplatte.
Wenn Sie es als CSV speichern, belegt die Datei fast 300 MB auf Ihrer Festplatte.df.to_csv('random_data.csv', index=False)
Ein Argument compression='gzip'reduziert die Dateigröße auf 136 MB.df.to_csv('random_data.gz', compression='gzip', index=False)
Eine komprimierte Datei wird wie eine normale Datei gelesen, sodass wir keine Funktionalität verlieren.df = pd.read_csv('random_data.gz')
Fazit
Diese kleinen Tricks haben die Produktivität meiner täglichen Arbeit mit Pandas erhöht. Ich hoffe, Sie haben aus diesem Artikel etwas über nützliche Funktionen gelernt, mit denen Sie auch produktiver werden können.Was ist dein Lieblingstrick bei Pandas?