Moderne Berichterstattungsberichte sind in einigen Fällen eher nutzlos, und die Methoden zu ihrer Messung sind hauptsächlich nur für Entwickler geeignet. Sie können jederzeit den Prozentsatz der Abdeckung ermitteln oder den Code anzeigen, der während der Tests nicht verwendet wurde. Was ist jedoch, wenn Sie Transparenz, Einfachheit und Automatisierung wünschen? Unter dem Schnitt - Video und Transkript eines Berichts von Artem Eroshenko von Qameta Software von der Heisenbug- Konferenz . Er stellte mehrere entwickelte einfache und elegante Lösungen vor, mit denen das Yandex.Verticals-Team die Abdeckung von Tests bewerten kann, die von Testautomatisierungsingenieuren geschrieben wurden. Artem zeigt Ihnen, wie Sie schnell herausfinden können, was abgedeckt ist, wie abgedeckt ist, welche Tests bestanden wurden, und sofort visuelle Berichte anzeigen können.Ich heiße Artyom Eroshenko EroshenkoamIch mache seit über 10 Jahren Testautomatisierung. Ich war ein Testautomatisierungsmanager, ein Toolentwicklungsteammanager, ein Toolentwickler.Im Moment bin ich Berater auf dem Gebiet der Testautomatisierung und arbeite mit mehreren Unternehmen zusammen, mit denen wir Prozesse aufbauen.Ich bin auch der Entwickler und geheime Manager von Allure Report. Wir haben kürzlich eine coole Sache behoben : Jetzt gibt es in JUnit 5 Fixtures.
Unter dem Schnitt - Video und Transkript eines Berichts von Artem Eroshenko von Qameta Software von der Heisenbug- Konferenz . Er stellte mehrere entwickelte einfache und elegante Lösungen vor, mit denen das Yandex.Verticals-Team die Abdeckung von Tests bewerten kann, die von Testautomatisierungsingenieuren geschrieben wurden. Artem zeigt Ihnen, wie Sie schnell herausfinden können, was abgedeckt ist, wie abgedeckt ist, welche Tests bestanden wurden, und sofort visuelle Berichte anzeigen können.Ich heiße Artyom Eroshenko EroshenkoamIch mache seit über 10 Jahren Testautomatisierung. Ich war ein Testautomatisierungsmanager, ein Toolentwicklungsteammanager, ein Toolentwickler.Im Moment bin ich Berater auf dem Gebiet der Testautomatisierung und arbeite mit mehreren Unternehmen zusammen, mit denen wir Prozesse aufbauen.Ich bin auch der Entwickler und geheime Manager von Allure Report. Wir haben kürzlich eine coole Sache behoben : Jetzt gibt es in JUnit 5 Fixtures.Atlas Framework
Meine Entwicklung ist das Atlas Framework . Wenn jemand 2012 mit der Automatisierung begann, als Java-Webtreiber gerade erst ihren Weg begannen, habe ich in diesem Moment eine Open-Source-Bibliothek namens HTML Elements erstellt .Html Elements hat seine Fortsetzung und sein Umdenken in der Atlas-Bibliothek, die auf Schnittstellen basiert: Es gibt keine Klassen als solche, keine Felder, eine sehr praktische, leichte und leicht erweiterbare Bibliothek. Wenn Sie es verstehen möchten, können Sie den Artikel lesen oder den Bericht lesen .Mein Bericht widmet sich dem Problem der Testautomatisierung und hauptsächlich Beschichtungen. Als Hintergrund möchte ich darauf verweisen, wie die Testprozesse in Yandex.Verticals organisiert sind.Wie funktioniert die Automatisierung in Branchen?
Das Testautomatisierungsteam von Yandex.Verticals besteht nur aus vier Personen, die vier Services automatisieren: Yandex.Avto, Work, Real Estate und Parts. Das heißt, dies ist ein kleines Team von Automaten, die viel tun. Wir automatisieren die API, das Webinterface, mobile Anwendungen und so weiter. Insgesamt haben wir ungefähr 15,5 Tausend Tests, die auf verschiedenen Ebenen durchgeführt werden.Die Stabilität der Tests im Team beträgt ungefähr 97%, obwohl einige meiner Kollegen ungefähr 99% sagen. Diese hohe Stabilität wird gerade durch kurze Tests mit sehr nativen Technologien erreicht. In der Regel dauern unsere Tests ungefähr 15 Minuten, was sehr umfangreich ist, und wir führen sie in ungefähr 800 Threads aus. Das heißt, wir haben 800 Browser, die gleichzeitig starten - ein solcher Stresstest unserer Tests. Als Eisen verwenden wir Selenoid (Aerokube). Weitere Informationen zum Testen der Automatisierung in Yandex.Verticals finden Sie in meinem Bericht von 2017, der immer noch relevant ist.Ein weiteres Merkmal unseres Teams ist, dass wir alles automatisieren , einschließlich manueller Tester, die einen großen Beitrag zur Entwicklung der Testautomatisierung leisten. Für sie organisieren wir Schulen, bringen ihnen Tests bei, lehren, wie man Tests für die API und das Webinterface schreibt, und oft helfen sie dabei, die Tests zu begleiten. Somit können die Jungs, die selbst für die Veröffentlichung verantwortlich sind, den Test bei Bedarf sofort korrigieren.In Verticals schreiben Testentwickler Tests und sind so sehr an der Testentwicklung interessiert, dass sie mit uns konkurrieren. Weitere Informationen zu diesem Prozess finden Sie im Bericht „Der vollständige Testzyklus von React-Anwendungen“., wo Alexei Androsov und Natalya Stus darüber sprechen, wie sie parallel zu unseren Java-End-to-End-Tests Unit-Tests auf Puppeteer schreiben.Testautomatisierungsingenieure schreiben auch Tests in unser Team. Aber oft entwickeln wir neue Ansätze, um sie zu optimieren. Zum Beispiel haben wir Screenshot-Tests implementiert, Tests durch Moki, Reduzierung der Tests. Im Allgemeinen ist unser Bereich hauptsächlich Softwareentwickler im Test (SDET), wir beschäftigen uns mehr mit dem Schreiben von Tests, und die Testbasis wird teilweise von uns gefüllt und von manuellen Testern unterstützt.Entwickler helfen uns auch, und das ist cool.
Das Problem, das bei diesen Prozessen auftritt, ist, dass wir nicht immer verstehen, was bereits abgedeckt ist und was nicht. Bei 15.000 Tests ist nicht immer klar, was genau wir überprüfen. Dies gilt insbesondere im Zusammenhang mit der Kommunikation mit Managern, die natürlich nicht testen, sondern überwachen und Fragen stellen. Insbesondere wenn sich die Frage stellt, ob eine bestimmte Schaltfläche in der Benutzeroberfläche oder im Ablauf getestet wurde, ist die Beantwortung schwierig, da Sie zum Testcode gehen und diese Informationen anzeigen müssen.Was wird getestet und was nicht?
Wenn Sie viele Tests in verschiedenen Sprachen haben und von Personen mit unterschiedlichem Ausbildungsgrad geschrieben wurden, stellt sich früher oder später die Frage, ob sich diese Tests überhaupt nicht überschneiden. Im Zusammenhang mit diesem Problem wird das Thema Berichterstattung besonders relevant. Ich werde drei Schlüsselthemen skizzieren:- Möglichkeiten zur effektiven Messung der Abdeckung.
- Abdeckung für API-Tests.
- Abdeckung für Webtests.
Lassen Sie uns zunächst feststellen, dass es zwei Möglichkeiten gibt, Anforderungen abzudecken: Anforderungen abdecken und Produktcode abdecken.Wie die Anforderungsabdeckung gemessen wird
Betrachten Sie die Anforderungsabdeckung am Beispiel von auto.ru. Anstelle des auto.ru-Testers würde ich Folgendes tun. Erstens würde ich googeln und sofort eine Tabelle mit speziellen Anforderungen finden. Dies ist die Grundlage für die Anforderungsabdeckung.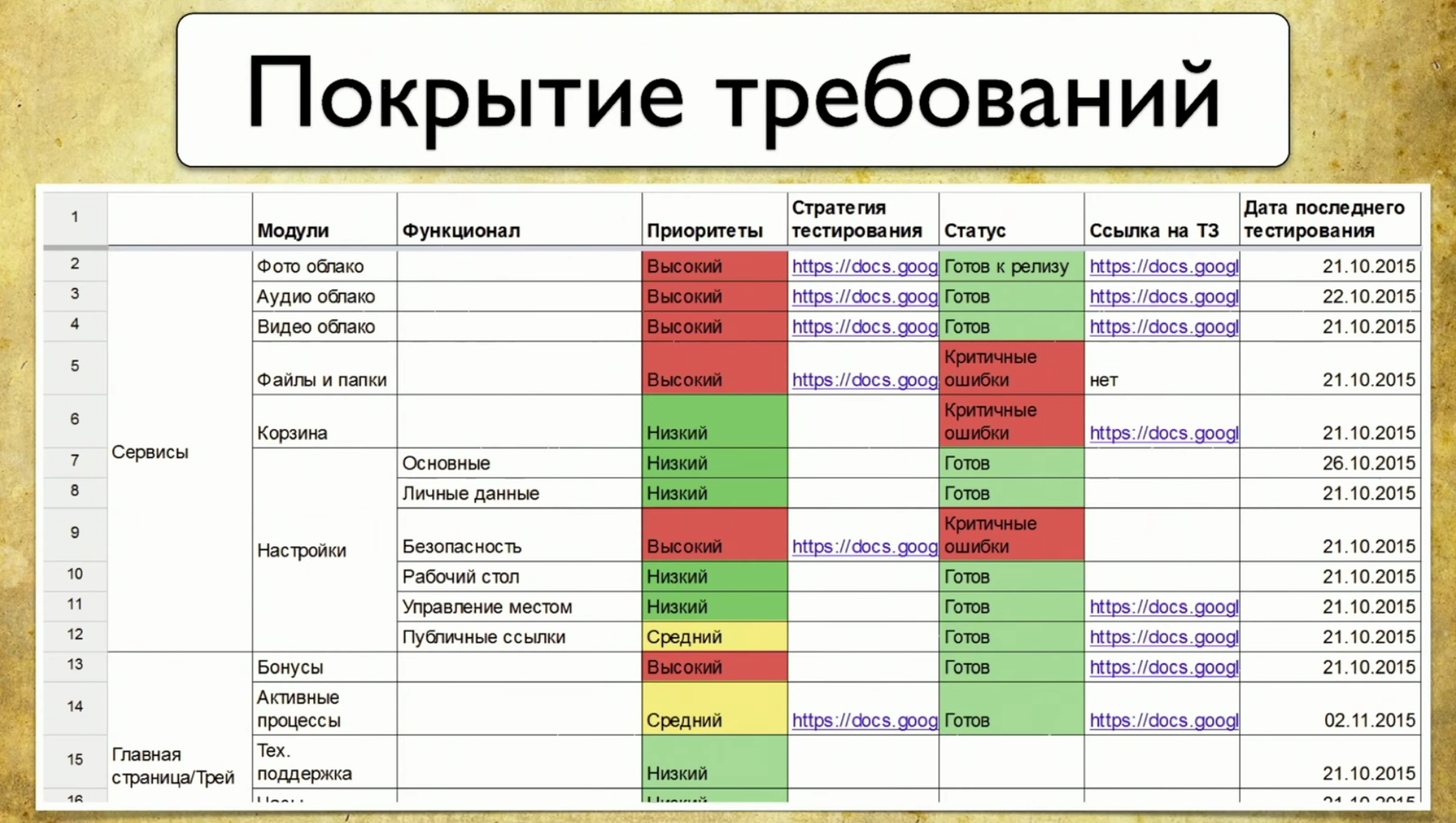 In dieser Tabelle sind die Namen der Anforderungen links angegeben. In diesem Fall: Konto, Anzeigen, Überprüfung und Zahlung, dh Überprüfung der Ankündigung. Im Allgemeinen ist dies die Abdeckung. Das Detail des linken Teils hängt von der Stufe des Testers ab. Zum Beispiel haben Ingenieure von Google 49 Arten von Beschichtungen, die auf verschiedenen Ebenen getestet werden.Die rechte Seite der Tabelle enthält die Anforderungsattribute. Wir können alles in Form von Attributen verwenden, zum Beispiel: Priorität, Abdeckung und Status. Dies kann das Datum der letzten Veröffentlichung sein.
In dieser Tabelle sind die Namen der Anforderungen links angegeben. In diesem Fall: Konto, Anzeigen, Überprüfung und Zahlung, dh Überprüfung der Ankündigung. Im Allgemeinen ist dies die Abdeckung. Das Detail des linken Teils hängt von der Stufe des Testers ab. Zum Beispiel haben Ingenieure von Google 49 Arten von Beschichtungen, die auf verschiedenen Ebenen getestet werden.Die rechte Seite der Tabelle enthält die Anforderungsattribute. Wir können alles in Form von Attributen verwenden, zum Beispiel: Priorität, Abdeckung und Status. Dies kann das Datum der letzten Veröffentlichung sein. Daher erscheinen einige Daten in der Tabelle. Sie können professionelle Tools verwenden, um eine Anforderungstabelle zu verwalten, z. B. TestRail.Auf der rechten Seite finden Sie Informationen zum Baum: Die Ordner geben an, welche Anforderungen wir haben und wie sie abgedeckt werden können. Es gibt Testfälle und so weiter.
Daher erscheinen einige Daten in der Tabelle. Sie können professionelle Tools verwenden, um eine Anforderungstabelle zu verwalten, z. B. TestRail.Auf der rechten Seite finden Sie Informationen zum Baum: Die Ordner geben an, welche Anforderungen wir haben und wie sie abgedeckt werden können. Es gibt Testfälle und so weiter. In den Vertikalen sieht dieser Prozess folgendermaßen aus: Ein manueller Tester beschreibt die Anforderungen und Testfälle, übergibt sie dann an die Testautomatisierung, und das automatisierte Tool schreibt Code für diese Tests. Darüber hinaus erhielten wir früher detaillierte Testfälle, in denen der manuelle Tester die gesamte Struktur beschrieb. Dann machte jemand eine Verpflichtung auf dem Github, und der Test begann vorteilhaft zu sein.Was sind die Vor- und Nachteile dieses Ansatzes? Das Plus ist, dass dieser Ansatz unsere Fragen beantwortet. Wenn der Manager fragt, was wir behandelt haben, öffne ich das Tablet und zeige, welche Funktionen abgedeckt sind. Andererseits müssen diese Anforderungen immer auf dem neuesten Stand gehalten werden und sind sehr schnell veraltet.Wenn Sie 15.000 Tests haben, ist das Betrachten von TestRail wie das Betrachten eines Sterns im Weltraum: Er explodierte lange Zeit und das Licht hat Sie gerade erreicht. Sie sehen sich den aktuellen Testfall an, der schon lange und unwiderruflich veraltet ist.Dieses Problem ist schwer zu lösen. Für uns sind dies im Allgemeinen zwei verschiedene Welten: Es gibt eine Welt der Automatisierung, die sich nach ihren eigenen Gesetzen dreht, in der jeder fehlgeschlagene Test sofort behoben wird, und es gibt eine Welt manueller Tests und Anforderungskarten. Die Wand zwischen ihnen ist undurchdringlich, es sei denn, Sie verwenden Allure Server. Wir lösen dieses Problem jetzt nur für sie.Der dritte Punkt der „Vor- und Nachteile“ ist die Notwendigkeit manueller Arbeit. In einem neuen Projekt müssen Sie eine Anforderungszuordnung neu erstellen, alle Testfälle schreiben usw. Es erfordert immer manuelle Arbeit und ist eigentlich sehr traurig.
In den Vertikalen sieht dieser Prozess folgendermaßen aus: Ein manueller Tester beschreibt die Anforderungen und Testfälle, übergibt sie dann an die Testautomatisierung, und das automatisierte Tool schreibt Code für diese Tests. Darüber hinaus erhielten wir früher detaillierte Testfälle, in denen der manuelle Tester die gesamte Struktur beschrieb. Dann machte jemand eine Verpflichtung auf dem Github, und der Test begann vorteilhaft zu sein.Was sind die Vor- und Nachteile dieses Ansatzes? Das Plus ist, dass dieser Ansatz unsere Fragen beantwortet. Wenn der Manager fragt, was wir behandelt haben, öffne ich das Tablet und zeige, welche Funktionen abgedeckt sind. Andererseits müssen diese Anforderungen immer auf dem neuesten Stand gehalten werden und sind sehr schnell veraltet.Wenn Sie 15.000 Tests haben, ist das Betrachten von TestRail wie das Betrachten eines Sterns im Weltraum: Er explodierte lange Zeit und das Licht hat Sie gerade erreicht. Sie sehen sich den aktuellen Testfall an, der schon lange und unwiderruflich veraltet ist.Dieses Problem ist schwer zu lösen. Für uns sind dies im Allgemeinen zwei verschiedene Welten: Es gibt eine Welt der Automatisierung, die sich nach ihren eigenen Gesetzen dreht, in der jeder fehlgeschlagene Test sofort behoben wird, und es gibt eine Welt manueller Tests und Anforderungskarten. Die Wand zwischen ihnen ist undurchdringlich, es sei denn, Sie verwenden Allure Server. Wir lösen dieses Problem jetzt nur für sie.Der dritte Punkt der „Vor- und Nachteile“ ist die Notwendigkeit manueller Arbeit. In einem neuen Projekt müssen Sie eine Anforderungszuordnung neu erstellen, alle Testfälle schreiben usw. Es erfordert immer manuelle Arbeit und ist eigentlich sehr traurig.Wie die Codeabdeckung gemessen wird
Eine Alternative zu diesem Ansatz ist die Codeabdeckung. Dies scheint die Lösung für unser Problem zu sein. So sieht die Abdeckung des Produktcodes aus: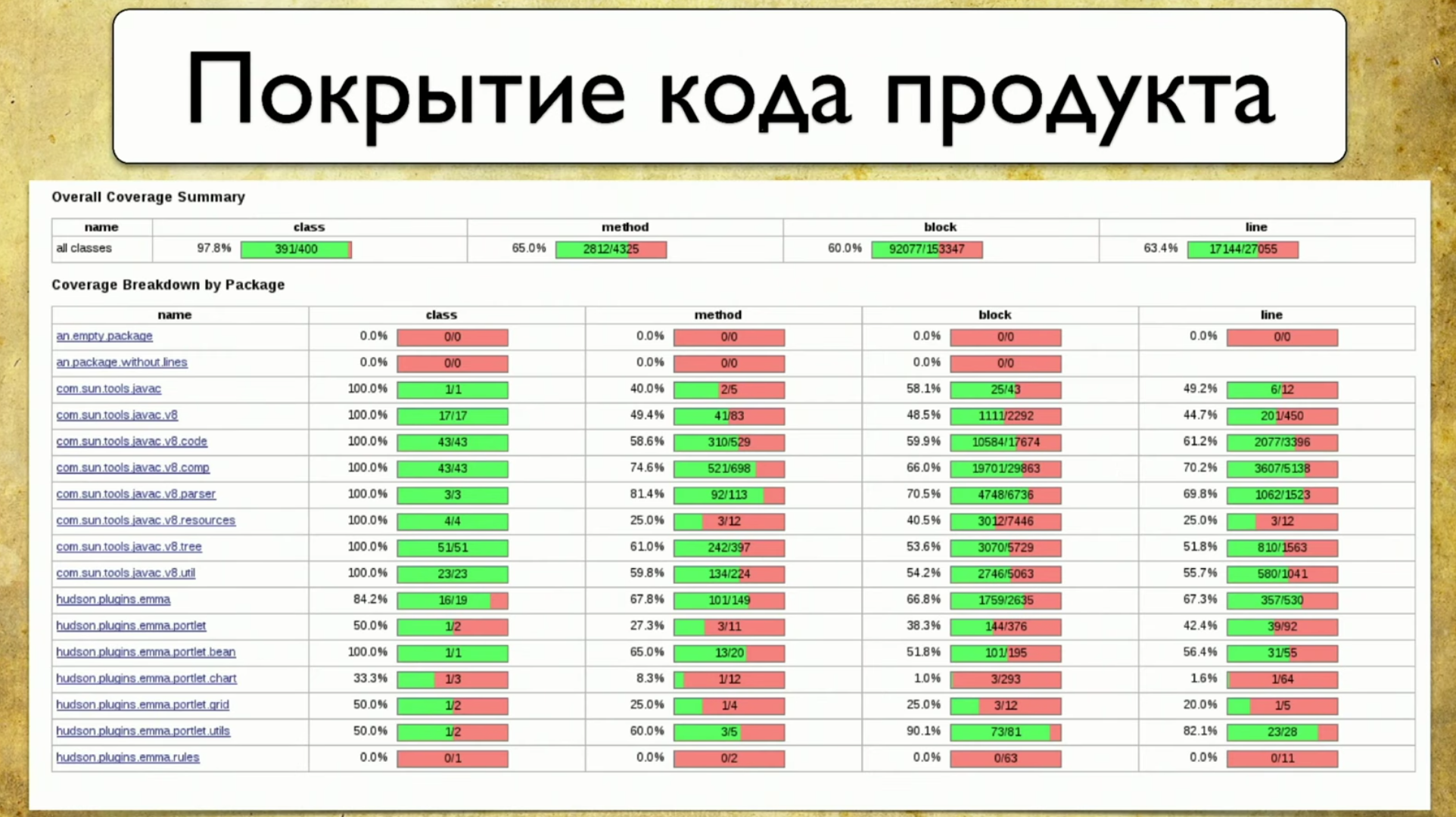 Sie spiegelt die Abdeckung der Verpackung wider, oder vielmehr einen kleinen Teil dessen, was normalerweise im Produkt enthalten ist. Das Paket ist auf der linken Seite geschrieben, wie zuvor beschrieben. Das heißt, unsere Beschichtung wird schließlich an einigen greifbaren Dingen befestigt, in diesem Fall am Paket. Die Attribute sind rechts geschrieben: Abdeckung nach Klasse, Abdeckung nach Methoden, Abdeckung nach Codeblöcken und Abdeckung nach Codezeilen.Beim Sammeln der Abdeckung muss verstanden werden, welche Codezeile der Test bestanden hat und welche nicht. Dies ist eine ziemlich einfache Aufgabe, aber in letzter Zeit sehr relevant.
Sie spiegelt die Abdeckung der Verpackung wider, oder vielmehr einen kleinen Teil dessen, was normalerweise im Produkt enthalten ist. Das Paket ist auf der linken Seite geschrieben, wie zuvor beschrieben. Das heißt, unsere Beschichtung wird schließlich an einigen greifbaren Dingen befestigt, in diesem Fall am Paket. Die Attribute sind rechts geschrieben: Abdeckung nach Klasse, Abdeckung nach Methoden, Abdeckung nach Codeblöcken und Abdeckung nach Codezeilen.Beim Sammeln der Abdeckung muss verstanden werden, welche Codezeile der Test bestanden hat und welche nicht. Dies ist eine ziemlich einfache Aufgabe, aber in letzter Zeit sehr relevant.Die erste Erwähnung der Codeabdeckung erfolgte bereits 1963, doch erst jetzt sind ernsthafte Fortschritte in dieser Richtung zu verzeichnen.
Wir haben also einen Test, der mit dem System interagiert. Es spielt keine Rolle, wie er mit ihr interagiert: über das Front-End, die API oder direkt in das Back-End - wir gehen einfach davon aus, dass wir es haben.Dann sollte die Instrumentierung erfolgen. Dies ist ein Prozess, mit dem Sie verstehen können, welche Codezeilen überprüft wurden und welche nicht. Sie müssen es nicht im Detail studieren, sondern müssen nur nach dem Namen Ihres Frameworks suchen, auf das Sie schreiben, z. B. Spring , dann Instrumentierung und Berichterstattung - diese drei Wörter helfen Ihnen zu verstehen, wie dies gemacht wird.Wenn Ihre Tests überprüfen, welche Codezeile der Test getroffen hat und welche nicht, speichern sie Dateien mit Informationen darüber, welche Zeilen abgedeckt sind. Basierend auf diesen Informationen haben Sie Daten.Was sind die Vor- und Nachteile der Codeabdeckung?
Code-Abdeckung würde ich sofort ein Minus nennen . Sie werden nicht zum Manager kommen, Sie werden dieses Schild nicht zeigen und Sie werden nicht sagen, dass jeder automatisiert hat, da diese Daten nicht gelesen werden können. Er wird Sie bitten, klare Daten zurückzugeben, die Sie schnell betrachten und alles verstehen können.Code-Coverage-Bericht näher an der Entwicklung. Es kann nicht als normaler Ansatz zur Bereitstellung aller Daten für ein Team verwendet werden, wenn das gesamte Team in der Lage sein soll, diese zu überwachen. Der Vorteil dieses Ansatzes besteht darin, dass immer relevante Daten bereitgestellt werden. Sie müssen nicht viel arbeiten, alles ist für Sie automatisiert. Schließen Sie einfach die Bibliothek an, Ihre Cover beginnen sich zu entfernen - und es ist wirklich cool.Ein weiterer Vorteil dieses Ansatzes besteht darin, dass nur Anpassungen erforderlich sind. Dort gibt es nichts Besonderes zu tun - kommen Sie einfach mit einer bestimmten Anweisung, passen Sie die Abdeckung an und es funktioniert automatisch.Durch die Erfassung von Anforderungen können Sie nicht erfüllte Anforderungen identifizieren, jedoch nicht die Vollständigkeit in Bezug auf den Code bewerten. Sie haben beispielsweise mit dem Schreiben einer neuen Funktion "Autorisierung" begonnen. Geben Sie einfach die "Funktion der Autorisierung" ein und beginnen Sie, Testfälle darauf zu werfen. Sie können diese Abdeckung nicht sofort im Code sehen, selbst wenn Sie eine neue Klasse schreiben, gibt es immer noch keine Informationen - es gibt eine Lücke. Auf der anderen Seite ist dies eine Autorisierungsanforderung, auch wenn sie bereits implementiert ist. Wenn Sie die Abdeckung darauf zählen, kann dieser Teil nicht relevant sein. Er muss manuell auf dem neuesten Stand gehalten werden.Deshalb hatten wir eine Idee: Was ist, wenn wir das Beste von allen nehmen? Damit die Berichterstattung unsere Fragen beantwortete, war sie immer relevant und musste nur angepasst werden. Wir müssen die Beschichtung nur aus einem anderen Blickwinkel betrachten, dh ein anderes System als Grundlage für die Beschichtung verwenden. Stellen Sie gleichzeitig sicher, dass es vollständig automatisch erfasst wird und eine Reihe von Vorteilen bietet. Und dafür werden wir uns mit den API-Tests befassen.
Der Vorteil dieses Ansatzes besteht darin, dass immer relevante Daten bereitgestellt werden. Sie müssen nicht viel arbeiten, alles ist für Sie automatisiert. Schließen Sie einfach die Bibliothek an, Ihre Cover beginnen sich zu entfernen - und es ist wirklich cool.Ein weiterer Vorteil dieses Ansatzes besteht darin, dass nur Anpassungen erforderlich sind. Dort gibt es nichts Besonderes zu tun - kommen Sie einfach mit einer bestimmten Anweisung, passen Sie die Abdeckung an und es funktioniert automatisch.Durch die Erfassung von Anforderungen können Sie nicht erfüllte Anforderungen identifizieren, jedoch nicht die Vollständigkeit in Bezug auf den Code bewerten. Sie haben beispielsweise mit dem Schreiben einer neuen Funktion "Autorisierung" begonnen. Geben Sie einfach die "Funktion der Autorisierung" ein und beginnen Sie, Testfälle darauf zu werfen. Sie können diese Abdeckung nicht sofort im Code sehen, selbst wenn Sie eine neue Klasse schreiben, gibt es immer noch keine Informationen - es gibt eine Lücke. Auf der anderen Seite ist dies eine Autorisierungsanforderung, auch wenn sie bereits implementiert ist. Wenn Sie die Abdeckung darauf zählen, kann dieser Teil nicht relevant sein. Er muss manuell auf dem neuesten Stand gehalten werden.Deshalb hatten wir eine Idee: Was ist, wenn wir das Beste von allen nehmen? Damit die Berichterstattung unsere Fragen beantwortete, war sie immer relevant und musste nur angepasst werden. Wir müssen die Beschichtung nur aus einem anderen Blickwinkel betrachten, dh ein anderes System als Grundlage für die Beschichtung verwenden. Stellen Sie gleichzeitig sicher, dass es vollständig automatisch erfasst wird und eine Reihe von Vorteilen bietet. Und dafür werden wir uns mit den API-Tests befassen.Test Coverage API
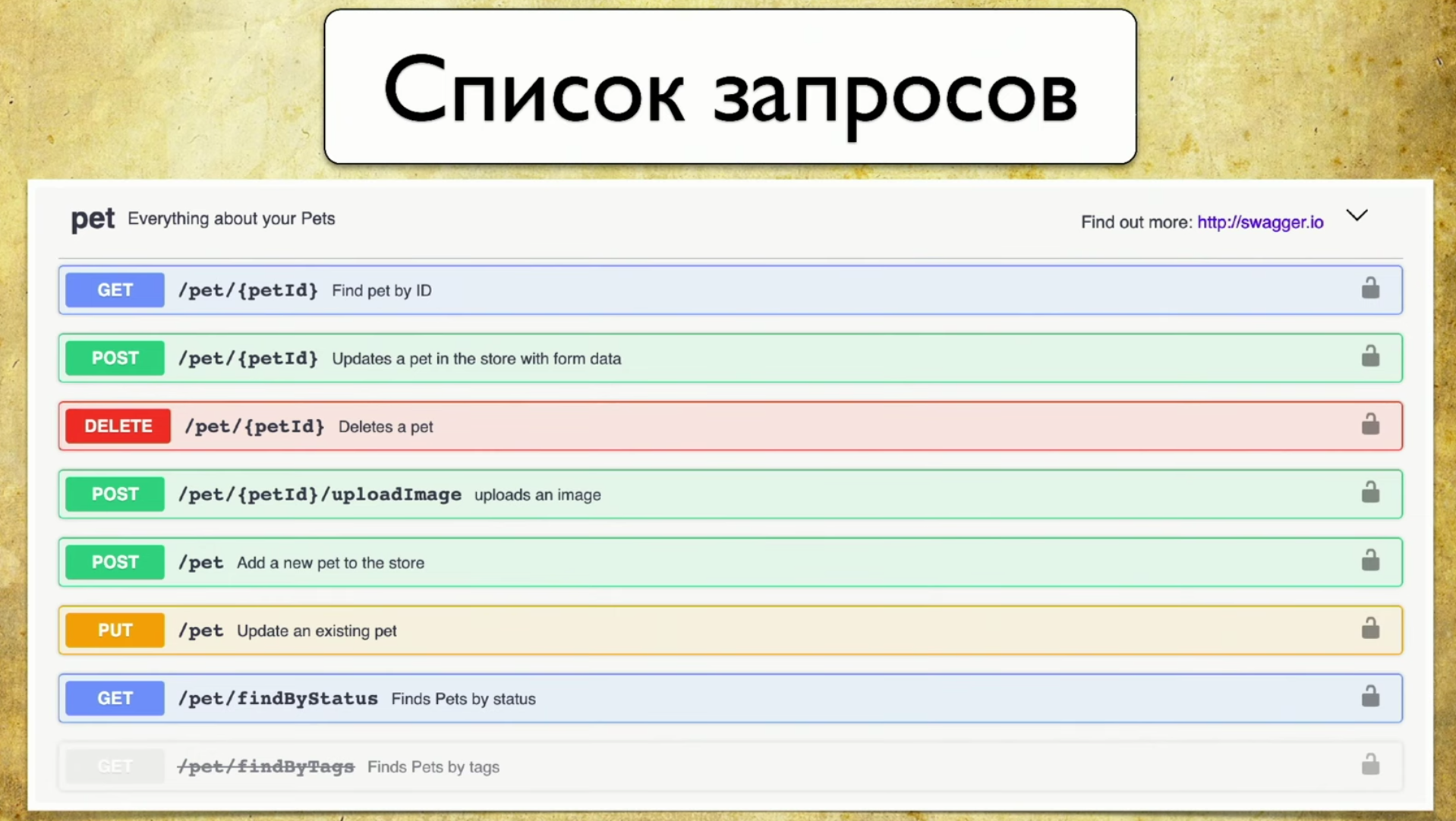
Was ist die Basis der Deckung? Dazu verwenden wir Swagger - dies ist die Dokumentations-API. Jetzt kann ich mir meine Arbeit ohne Swagger nicht vorstellen, es ist ein Werkzeug, das ich ständig zum Testen benutze. Wenn Sie Swagger nicht verwenden, empfehle ich dringend, die Website zu besuchen und sich mit ihr vertraut zu machen. Dort sehen Sie sofort ein sehr intuitives und verständliches Anwendungsbeispiel.In der Tat ist Swagger die Dokumentation, die von Ihrem Service generiert wird. Es beinhaltet:- Liste der Anfragen.
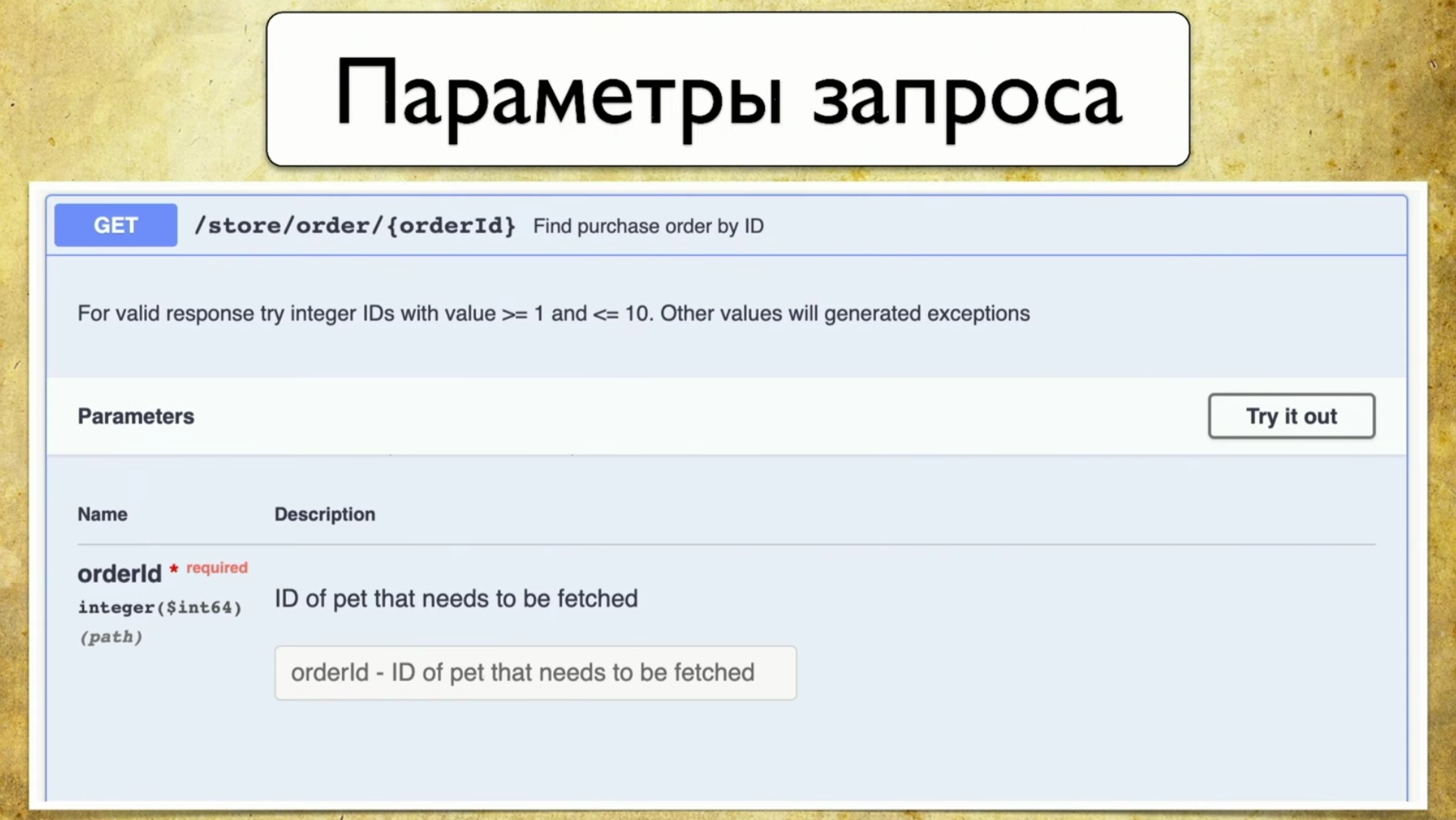
- Parameter anfordern: Es ist nicht erforderlich, den Entwickler zu ziehen und nach den Parametern zu fragen.
- Antwortcodes

Das Funktionsprinzip von Swagger ist die Erzeugung. Es spielt keine Rolle, welches Framework Sie verwenden. Angenommen , Spring oder Go Server, Sie verwenden die Swagger Codegen- Komponente und generieren swagger.json . Dies ist eine Spezifikation, auf deren Grundlage dann eine schöne Benutzeroberfläche gezeichnet wird.Für uns ist es wichtig, dass swagger.json verwendet wird : Die Unterstützung ist für alle weit verbreiteten Sprachen verfügbar.Wir haben die Open API-Spezifikation swagger.json . Es sieht so aus: Anfragen sehen ungefähr so aus: Zusammenfassung, Beschreibung, Antwortcodes und ein "Handle" (Pfad: / users). Es gibt auch Informationen über den Abfrageparameter: Alles ist strukturiert, es gibt einen Benutzer-ID-Parameter, es befindet sich in dem Pfad, in dem es erforderlich ist, eine solche Beschreibung und eine Typ-Ganzzahl.
Anfragen sehen ungefähr so aus: Zusammenfassung, Beschreibung, Antwortcodes und ein "Handle" (Pfad: / users). Es gibt auch Informationen über den Abfrageparameter: Alles ist strukturiert, es gibt einen Benutzer-ID-Parameter, es befindet sich in dem Pfad, in dem es erforderlich ist, eine solche Beschreibung und eine Typ-Ganzzahl. Es gibt Antwortcodes, die auch dokumentiert sind:
Es gibt Antwortcodes, die auch dokumentiert sind: Und uns kam die Idee: Wir haben einen Service, den Swagger generiert, und wir wollten denselben Swagger in den Tests behalten, damit wir sie später vergleichen können. Mit anderen Worten, wenn die Tests ausgeführt werden, erzeugen sie genau den gleichen Swagger. Wir werfen ihn auf den Swagger Diff. Wir verstehen, welche Parameter, Handles, Statuscodes wir überprüft haben und so weiter. Dies ist die gleiche Instrumentierung, die gleiche Abdeckung, nur schließlich in den Anforderungen, die wir verstehen.
Und uns kam die Idee: Wir haben einen Service, den Swagger generiert, und wir wollten denselben Swagger in den Tests behalten, damit wir sie später vergleichen können. Mit anderen Worten, wenn die Tests ausgeführt werden, erzeugen sie genau den gleichen Swagger. Wir werfen ihn auf den Swagger Diff. Wir verstehen, welche Parameter, Handles, Statuscodes wir überprüft haben und so weiter. Dies ist die gleiche Instrumentierung, die gleiche Abdeckung, nur schließlich in den Anforderungen, die wir verstehen.Aber was ist, wenn Sie ein Diff bauen?
Wir haben uns der Swagger Diff- Bibliothek zugewandt, die wir dafür brauchen. Das Funktionsprinzip sieht ungefähr so aus : Sie haben Version 1.0, mit API-Version 1.1 generieren beide swagger.json , dann werfen Sie sie auf Swagger diff und sehen das Ergebnis.Das Ergebnis sieht ungefähr so aus: Sie haben Informationen, dass es zum Beispiel einen neuen Stift gibt. Sie haben auch Informationen darüber, was gelöscht wird. Dies bedeutet, dass es Zeit ist, die Tests zu entfernen. Sie sind nicht mehr relevant. Mit dem Erscheinen von Informationen über Änderungen ändern sich auch die Parameter, sodass es offensichtlich ist, dass Ihre Tests in diesem Moment fallen werden.Diese Idee hat uns gefallen und wir haben begonnen, sie umzusetzen. Als wir uns dazu entschlossen haben: Wir haben einen "Referenz" -Swagger, der aus dem Entwicklercode generiert wird, wir haben auch API-Tests, die unseren Swagger generieren, und wir werden zwischen ihnen unterscheiden.Wir führen also Tests für den Dienst durch: Wir haben Rest Assured , das selbst auf die Dienste über die API zugreift. Und wir instrumentieren es. Es gibt einen Ansatz: Sie können Filter erstellen , die Anforderung wird an sie gesendet - und die Informationen über die Anforderung werden in Form von swagger.json direkt für sich selbst gespeichert .Hier ist der gesamte Code, den wir schreiben mussten, es gab 69-70 Zeilen - dies ist ein sehr einfacher Code.
Sie haben Informationen, dass es zum Beispiel einen neuen Stift gibt. Sie haben auch Informationen darüber, was gelöscht wird. Dies bedeutet, dass es Zeit ist, die Tests zu entfernen. Sie sind nicht mehr relevant. Mit dem Erscheinen von Informationen über Änderungen ändern sich auch die Parameter, sodass es offensichtlich ist, dass Ihre Tests in diesem Moment fallen werden.Diese Idee hat uns gefallen und wir haben begonnen, sie umzusetzen. Als wir uns dazu entschlossen haben: Wir haben einen "Referenz" -Swagger, der aus dem Entwicklercode generiert wird, wir haben auch API-Tests, die unseren Swagger generieren, und wir werden zwischen ihnen unterscheiden.Wir führen also Tests für den Dienst durch: Wir haben Rest Assured , das selbst auf die Dienste über die API zugreift. Und wir instrumentieren es. Es gibt einen Ansatz: Sie können Filter erstellen , die Anforderung wird an sie gesendet - und die Informationen über die Anforderung werden in Form von swagger.json direkt für sich selbst gespeichert .Hier ist der gesamte Code, den wir schreiben mussten, es gab 69-70 Zeilen - dies ist ein sehr einfacher Code. Das Lustige ist, dass wir den nativen Client für Swagger verwendet haben, genau dort geschrieben. Wir mussten nicht einmal unsere Binärdateien erstellen, sondern haben nur die Swagger-Spezifikation ausgefüllt.
Das Lustige ist, dass wir den nativen Client für Swagger verwendet haben, genau dort geschrieben. Wir mussten nicht einmal unsere Binärdateien erstellen, sondern haben nur die Swagger-Spezifikation ausgefüllt. Wir haben viele .json-Dateien, mit denen wir etwas tun mussten - sie haben einen Swagger-Aggregator geschrieben. Dies ist ein sehr einfaches Programm, das nach folgendem Prinzip arbeitet:
Wir haben viele .json-Dateien, mit denen wir etwas tun mussten - sie haben einen Swagger-Aggregator geschrieben. Dies ist ein sehr einfaches Programm, das nach folgendem Prinzip arbeitet:- Sie erfüllt eine neue Anfrage, wenn sie nicht in unserer Datenbank enthalten ist, fügt sie hinzu.
- Sie erfüllt die Anfrage, er hat einen neuen Parameter - fügt hinzu.
- Gleiches gilt für Statuscodes.
Auf diese Weise erhalten wir Informationen zu allen von uns verwendeten Stiften, Parametern und Statuscodes. Außerdem können Sie hier Daten erfassen, mit denen diese Anforderungen ausgeführt wurden: Benutzername, Anmeldungen usw. Wir haben noch nicht herausgefunden, wie diese Informationen verwendet werden sollen, da alles bei uns generiert wird. Sie können jedoch nachvollziehen, mit welchen Parametern bestimmte Anforderungen aufgerufen wurden.Wir waren also fast einen Steinwurf vom Sieg entfernt, aber als Ergebnis haben wir Swagger Diff abgelehnt, weil es in einem etwas anderen Konzept funktioniert - im Konzept des Differentials.
Swagger Diff sagt, was sich geändert hat, nicht was abgedeckt ist, aber wir wollten das Ergebnis der Berichterstattung anzeigen. Es gibt viele zusätzliche Daten, es werden Informationen zu Beschreibung, Zusammenfassung und anderen Metainformationen gespeichert, aber wir haben diese Informationen nicht. Und wenn wir Diff machen, schreiben sie uns, dass "dieser Stift keine Beschreibung hat", aber nicht existiert.Eigener Bericht
Wir haben unsere Implementierung vorgenommen und sie funktioniert wie folgt: Wir haben viele Dateien, die aus Autotests stammen, wir haben die Swagger-Service-API und wir erstellen darauf basierend einen Bericht.Ein einfacher Bericht sieht folgendermaßen aus: Oben sehen Sie Informationen darüber, wie viele Stifte (349) insgesamt vorhanden sind und welche Informationen vollständig abgedeckt sind (jeder Parameter, Statuscode usw.). Sie können Ihre eigenen Kriterien auswählen, z. B. mehrere Parameter abdecken.Hier gibt es auch Informationen, dass 40% teilweise abgedeckt sind - dies bedeutet, dass wir bereits Tests für diese Stifte haben, aber einige Dinge sind noch nicht abgedeckt, und Sie müssen dort genau hinschauen. Eine leere Abdeckung wird ebenfalls berücksichtigt.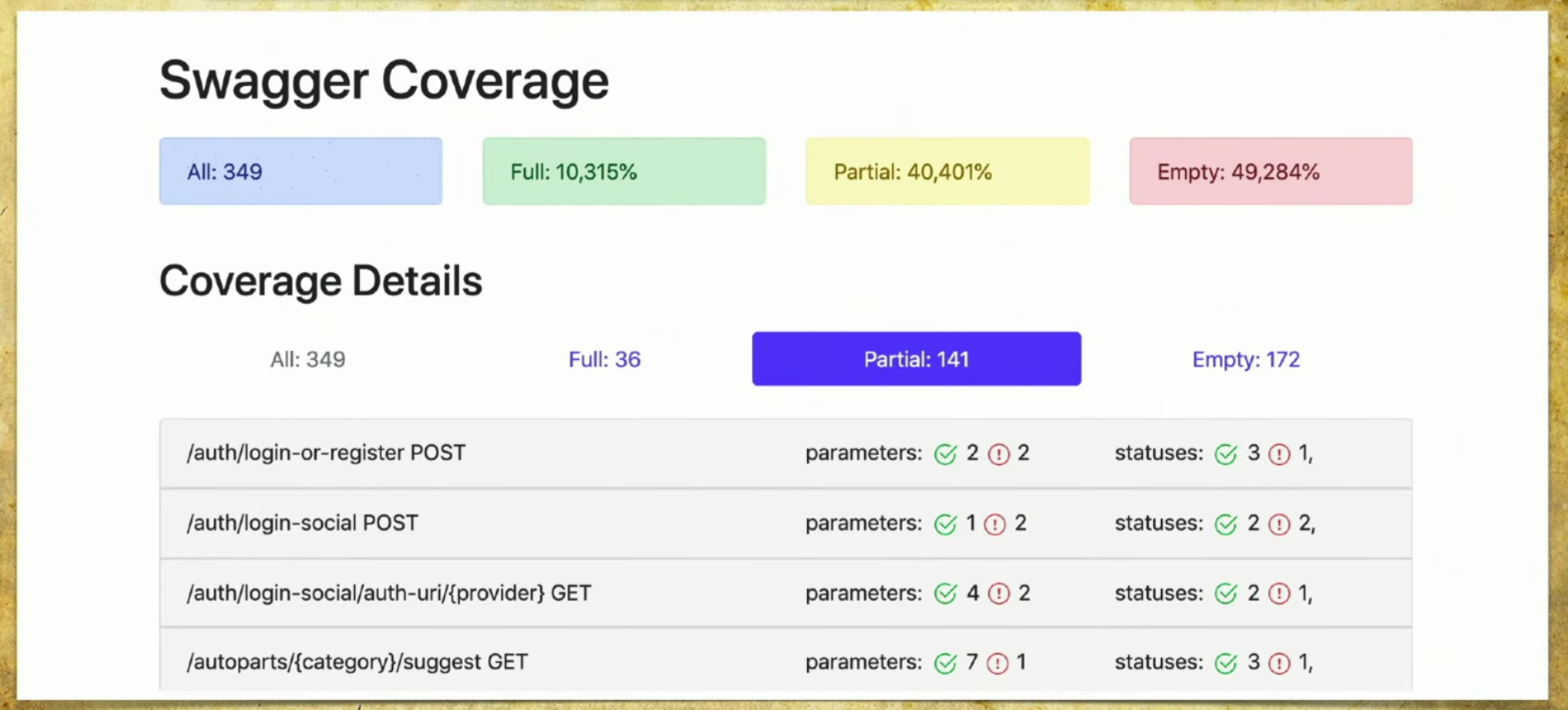 Lassen Sie uns die Registerkarten durchgehen. Dies ist eine vollständige Abdeckung , wir sehen alle Parameter, die wir haben, die abgedeckt sind, Statuscodes und so weiter.
Lassen Sie uns die Registerkarten durchgehen. Dies ist eine vollständige Abdeckung , wir sehen alle Parameter, die wir haben, die abgedeckt sind, Statuscodes und so weiter.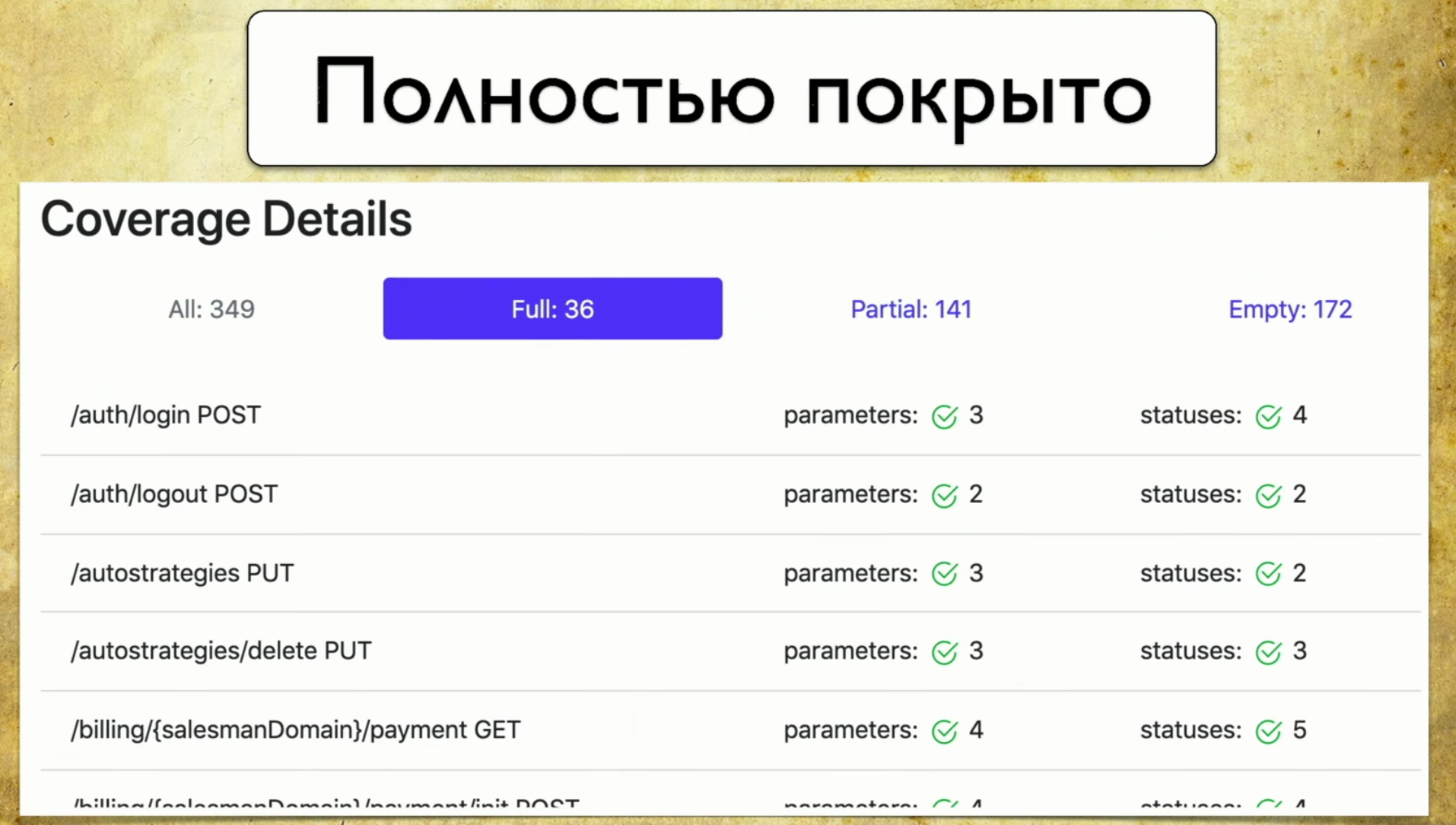 Dann haben wir eine teilweise Abdeckung . Wir sehen, dass im Login-Social-Handle ein Parameter behandelt wird und zwei nicht. Und wir können es erweitern und sehen, welche spezifischen Parameter und Statuscodes abgedeckt sind. Und in diesem Moment wird es für den Entwickler sehr praktisch: Die Versionen der Anwendung rollen sehr schnell, und wir können oft einige Parameter vergessen.
Dann haben wir eine teilweise Abdeckung . Wir sehen, dass im Login-Social-Handle ein Parameter behandelt wird und zwei nicht. Und wir können es erweitern und sehen, welche spezifischen Parameter und Statuscodes abgedeckt sind. Und in diesem Moment wird es für den Entwickler sehr praktisch: Die Versionen der Anwendung rollen sehr schnell, und wir können oft einige Parameter vergessen. Mit diesem Tool können Sie immer in guter Form sein und verstehen, was wir teilweise behandelt haben, welcher Parameter vergessen wurde und so weiter.Last - Ruhm der Schande, wir müssen es noch tun. Wenn Sie auf diese Seite schauen und dort leer sehen: 172 - Ihre Hände fallen, und dann beginnen Sie, Handprüfern das Schreiben von Autotests beizubringen, das ist der Punkt.
Mit diesem Tool können Sie immer in guter Form sein und verstehen, was wir teilweise behandelt haben, welcher Parameter vergessen wurde und so weiter.Last - Ruhm der Schande, wir müssen es noch tun. Wenn Sie auf diese Seite schauen und dort leer sehen: 172 - Ihre Hände fallen, und dann beginnen Sie, Handprüfern das Schreiben von Autotests beizubringen, das ist der Punkt.
Welchen Nutzen haben wir bei der Einführung unserer Lösung erzielt?
Zuerst haben wir begonnen, Tests aussagekräftiger zu schreiben. Wir verstehen, dass wir testen, und gleichzeitig haben wir zwei Strategien. Erstens automatisieren wir etwas, das nicht vorhanden ist, wenn manuelle Tester kommen und sagen, dass es für einen bestimmten Dienst wichtig ist, dass eine Anforderung mindestens einmal ausgeführt wird, und öffnen Empty.Die zweite Option - wir vergessen nicht die Schwänze. Wie gesagt, die APIs werden sehr schnell veröffentlicht, es kann einige Veröffentlichungen zwei- oder dreimal am Tag geben. Dort werden ständig einige Parameter hinzugefügt: In fünftausend Tests ist es unmöglich zu verstehen, was überprüft wird und was nicht. Daher ist dies die einzige Möglichkeit, eine Teststrategie bewusst zu wählen und zumindest etwas zu tun.Der dritte Gewinn ist ein vollautomatischer Prozess. Wir haben den Ansatz ausgeliehen und die Automatisierung funktioniert: Wir müssen nichts tun, alles wird automatisch gesammelt.Entwicklungsideen
Erstens möchte ich den zweiten Bericht wirklich nicht behalten, aber ich möchte ihn in die Swagger-Benutzeroberfläche integrieren. Dies ist mein Lieblingsbericht zur „Photoshop Edition“: ein Chip, den ich in letzter Zeit entwickelt habe. Hier gibt es sofort Informationen zu den Parametern, die wir getestet haben und die nicht. Und es wäre cool, diese Informationen sofort mit Swagger zu geben. Zum Beispiel kann das Front-End selbst sehen, welche Parameter nicht getestet wurden, Prioritäten setzen und entscheiden, dass sie zwar nicht in die Entwicklung einbezogen werden müssen, aber nicht bekannt ist, wie gut sie funktionieren. Oder das Backend schreibt einen neuen Stift, sieht Rot und tritt Tester so, dass alles grün ist. Das ist ganz einfach, wir gehen in diese Richtung.Die zweite Idee ist, andere Tools zu unterstützen. Tatsächlich möchte ich keine Filter für bestimmte Implementierungen schreiben: für Java, Python und so weiter. Es besteht die Idee, eine Art Proxy zu erstellen, der alle Anforderungen über sich selbst weiterleitet und Swagger-Informationen für sich selbst speichert. Somit verfügen wir über eine universelle Bibliothek, die unabhängig von Ihrer Sprache verwendet werden kann.Die dritte Entwicklungsidee ist die Integration in Allure Report. Ich sehe das so:
Zum Beispiel kann das Front-End selbst sehen, welche Parameter nicht getestet wurden, Prioritäten setzen und entscheiden, dass sie zwar nicht in die Entwicklung einbezogen werden müssen, aber nicht bekannt ist, wie gut sie funktionieren. Oder das Backend schreibt einen neuen Stift, sieht Rot und tritt Tester so, dass alles grün ist. Das ist ganz einfach, wir gehen in diese Richtung.Die zweite Idee ist, andere Tools zu unterstützen. Tatsächlich möchte ich keine Filter für bestimmte Implementierungen schreiben: für Java, Python und so weiter. Es besteht die Idee, eine Art Proxy zu erstellen, der alle Anforderungen über sich selbst weiterleitet und Swagger-Informationen für sich selbst speichert. Somit verfügen wir über eine universelle Bibliothek, die unabhängig von Ihrer Sprache verwendet werden kann.Die dritte Entwicklungsidee ist die Integration in Allure Report. Ich sehe das so: Wenn der Parameter „getestet“ wird, sagt uns dies in der Regel nicht immer, wie er getestet wird. Und ich möchte auf diesen Parameter zeigen und die spezifischen Schritte des Tests sehen.
Wenn der Parameter „getestet“ wird, sagt uns dies in der Regel nicht immer, wie er getestet wird. Und ich möchte auf diesen Parameter zeigen und die spezifischen Schritte des Tests sehen.Web Testing Coverage
Der nächste Punkt, über den ich sprechen möchte, ist die Berichterstattung über Webtests. Die Abdeckung basiert auf der Site, die Sie testen, und schreibt Tests auf der Site. Sie können es jedoch zu einer Webschnittstelle für Ihre Berichterstattung machen. Zum Beispiel sieht es so aus: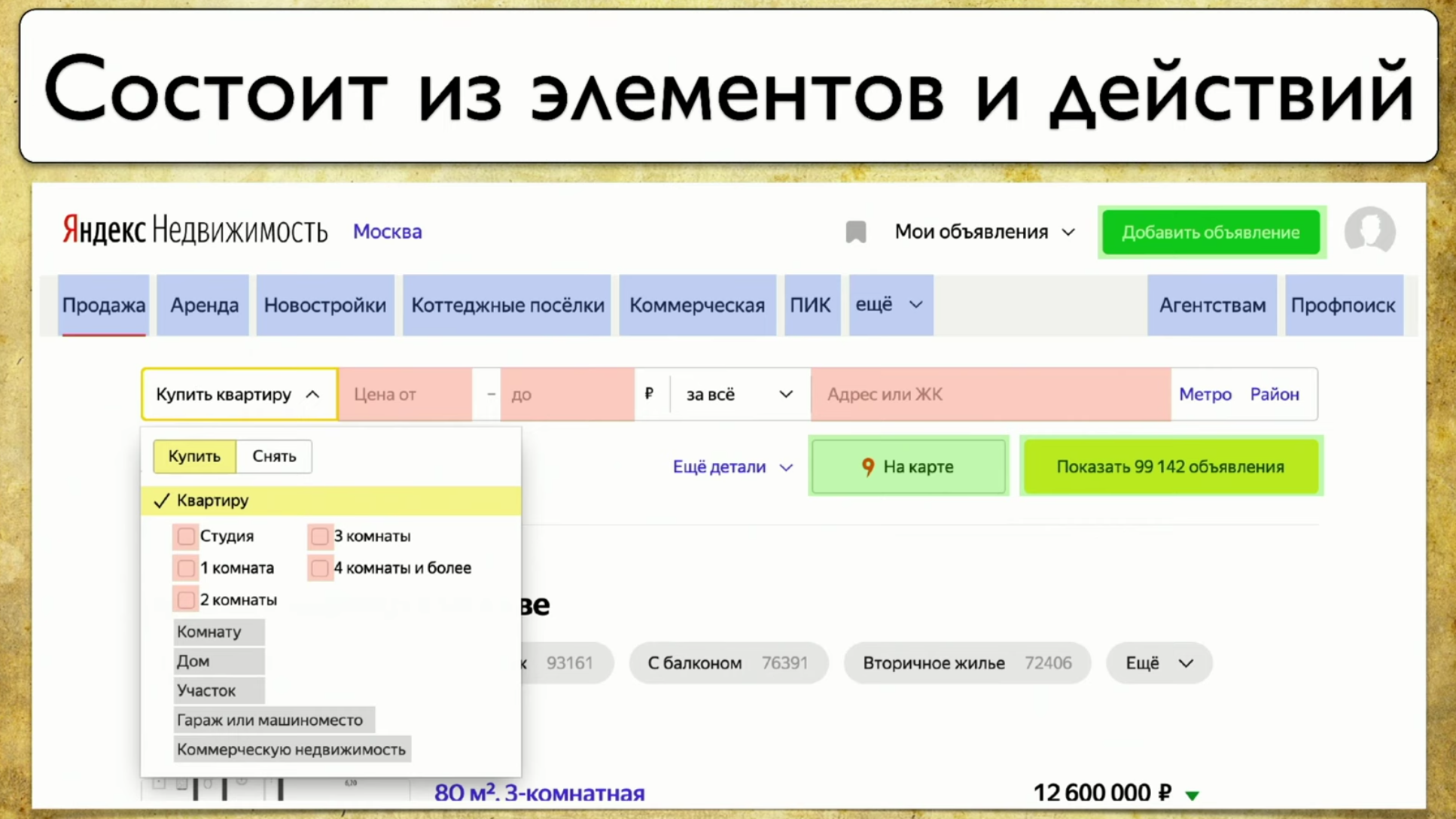 Wenn Sie sich Ihre Site ansehen, sind dies einige Elemente und Möglichkeiten, mit ihnen zu interagieren. Dies ist eine vollständige Beschreibung: "Ein Element ist eine Möglichkeit, mit ihm zu interagieren." Sie können auf den Link klicken, Sie können den Text kopieren, Sie können etwas in die Eingabe treiben. Die Site als Ganzes besteht aus Elementen und Arten ihrer Interaktion:
Wenn Sie sich Ihre Site ansehen, sind dies einige Elemente und Möglichkeiten, mit ihnen zu interagieren. Dies ist eine vollständige Beschreibung: "Ein Element ist eine Möglichkeit, mit ihm zu interagieren." Sie können auf den Link klicken, Sie können den Text kopieren, Sie können etwas in die Eingabe treiben. Die Site als Ganzes besteht aus Elementen und Arten ihrer Interaktion: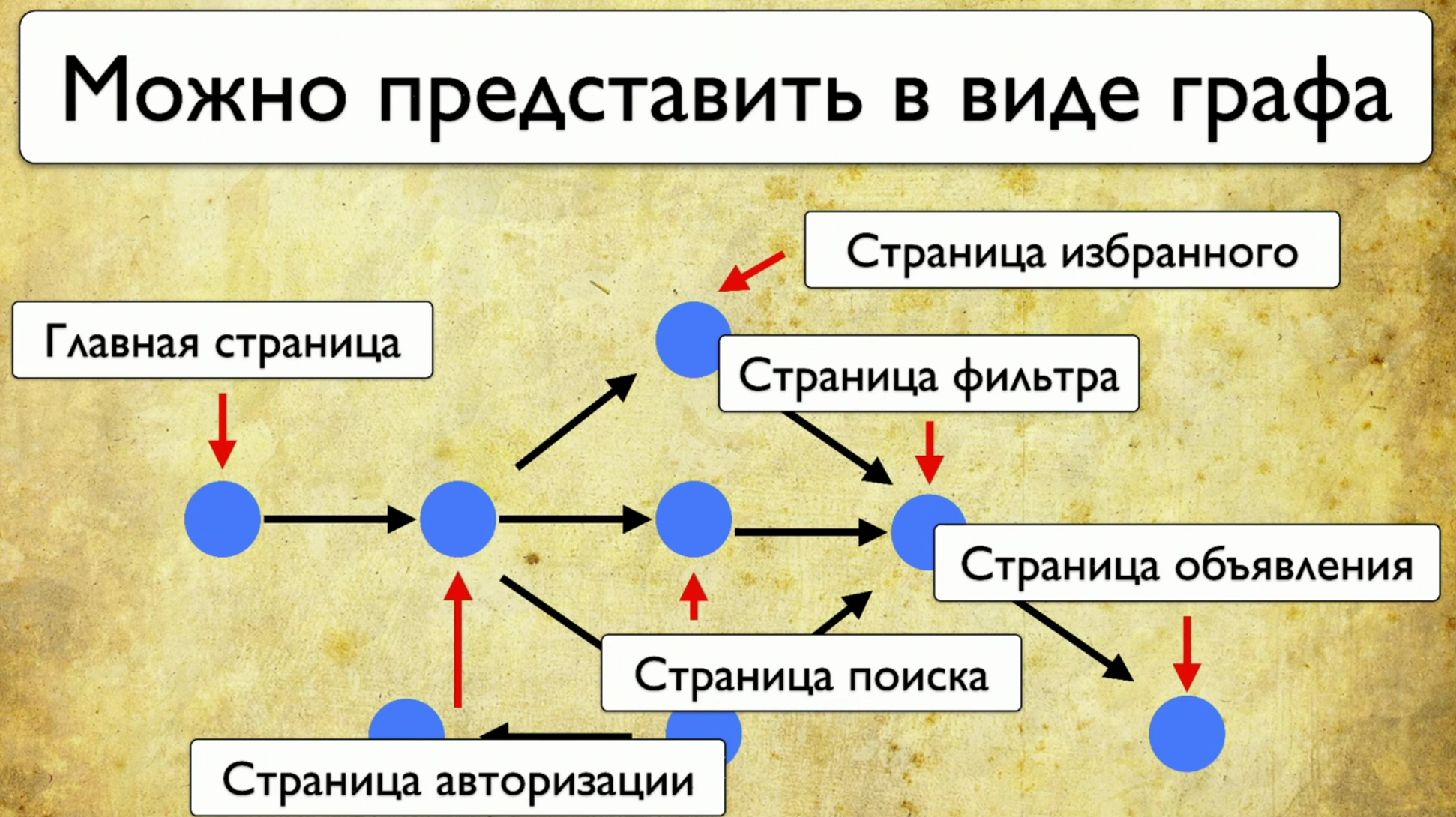 Wie Tests ablaufen: Sie beginnen an einem bestimmten Punkt, füllen dann beispielsweise ein Formular aus, z. B. ein Autorisierungsformular, und verteilen sich dann auf andere Seiten, dann auf ein anderes und enden .Wenn der Manager fragt, ob eine bestimmte Schaltfläche getestet wird, diese Frage jedoch schwer zu beantworten ist: Sie müssen den Code öffnen oder zu TestRail gehen, dann möchte ich diese Lösung für das Problem sehen:
Wie Tests ablaufen: Sie beginnen an einem bestimmten Punkt, füllen dann beispielsweise ein Formular aus, z. B. ein Autorisierungsformular, und verteilen sich dann auf andere Seiten, dann auf ein anderes und enden .Wenn der Manager fragt, ob eine bestimmte Schaltfläche getestet wird, diese Frage jedoch schwer zu beantworten ist: Sie müssen den Code öffnen oder zu TestRail gehen, dann möchte ich diese Lösung für das Problem sehen: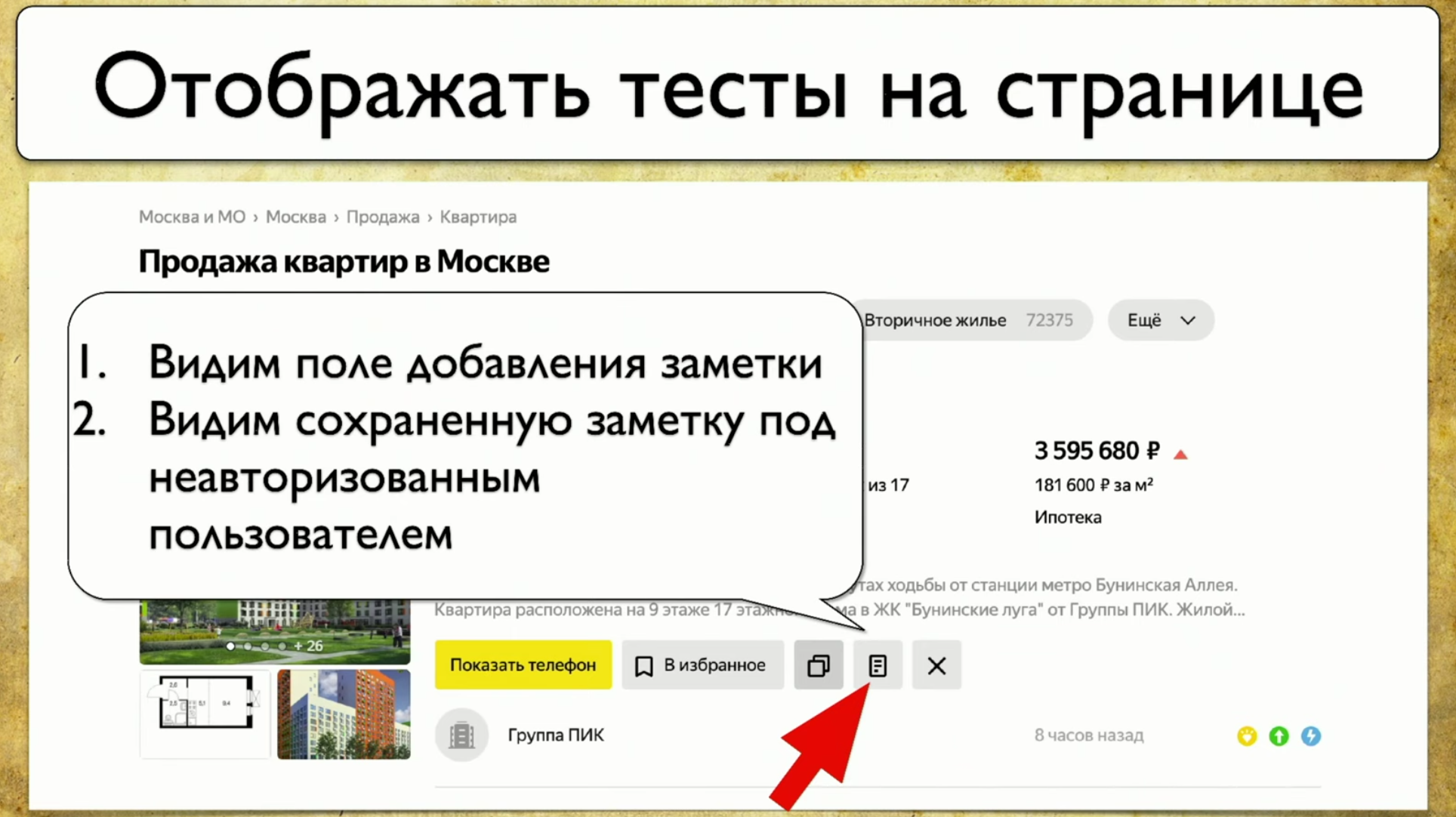 Ich möchte auf dieses Element zeigen und alle Tests sehen, die wir haben zu diesem Artikel. Wenn es so ein Instrument gäbe, würde ich mich freuen. Als wir über diese Idee nachdachten, haben wir uns zuerst Yandex.Metrica angesehen. Sie haben ungefähr die gleiche Funktionalität wie eine Link Map. Gute Idee.Unter dem Strich werden sie genau so hervorgehoben, als ob sie bereits die Informationen liefern, die wir benötigen. Sie sagen: "Hier haben wir diesen Link 14 Mal passiert", was in der Übersetzung in die Testsprache bedeutet: "14 Tests wurden in diesem Link getestet" und irgendwie durchlaufen. Aber dieser rote Link hat bis zu 120 Tests gemacht, was für interessante Tests!Sie können alle Arten von Trends zeichnen, Metainformationen hinzufügen, aber was passiert, wenn wir alles nehmen und aus der Sicht des Testens zeichnen? Wir haben also eine Aufgabe: auf ein Element zu zeigen und eine Notiz mit einer Liste von Tests zu erhalten.
Ich möchte auf dieses Element zeigen und alle Tests sehen, die wir haben zu diesem Artikel. Wenn es so ein Instrument gäbe, würde ich mich freuen. Als wir über diese Idee nachdachten, haben wir uns zuerst Yandex.Metrica angesehen. Sie haben ungefähr die gleiche Funktionalität wie eine Link Map. Gute Idee.Unter dem Strich werden sie genau so hervorgehoben, als ob sie bereits die Informationen liefern, die wir benötigen. Sie sagen: "Hier haben wir diesen Link 14 Mal passiert", was in der Übersetzung in die Testsprache bedeutet: "14 Tests wurden in diesem Link getestet" und irgendwie durchlaufen. Aber dieser rote Link hat bis zu 120 Tests gemacht, was für interessante Tests!Sie können alle Arten von Trends zeichnen, Metainformationen hinzufügen, aber was passiert, wenn wir alles nehmen und aus der Sicht des Testens zeichnen? Wir haben also eine Aufgabe: auf ein Element zu zeigen und eine Notiz mit einer Liste von Tests zu erhalten. Um dies zu implementieren, müssen Sie auf das Symbol klicken und dann eine Notiz schreiben. Dies ist unser ganzer Test. Wir verwenden Atlas bei uns, und die Integration ist bisher nur damit verbunden.Atlas sieht ungefähr so aus:
Um dies zu implementieren, müssen Sie auf das Symbol klicken und dann eine Notiz schreiben. Dies ist unser ganzer Test. Wir verwenden Atlas bei uns, und die Integration ist bisher nur damit verbunden.Atlas sieht ungefähr so aus:SearchPage.open ();
SearchPage.offersList().should(hasSizeGreaterThan(0));
Wir möchten, dass mindestens ein Ergebnis angezeigt wird, andernfalls werden wir es nicht testen. Dann bewegen wir den Cursor auf das Element und klicken darauf.searchPage.offer(FIRST).moveCursor();
searchPage.offer(FIRST).actionBar().note().click();
Dann speichern wir in der Eingabe User_Text und senden es.searchPage.offer(FIRST).addNoteInput().sendKeys(USER_TEXT);
searchPage.offer(FIRST).saveNote().click();
Danach überprüfen wir, ob der Text genau der ist, der hätte sein sollen. searchPage.offer(FIRST).addNoteInput().should(hasValue(USER_TEXT));
Tests werden im Browser ausgeführt. Atlas ist ein Proxy für diesen Test. Wir wenden hier den gleichen Ansatz an, den jeder beim Sammeln der Abdeckung verwendet: Erstellen wir einen Locator mit .json. Wir speichern dort Informationen über alle Seitenöffnungen, alle Iterationen mit Elementen, wer gesendet hat, wer den Schlüssel gesendet hat, wer geklickt hat, welche IDs usw. - wir führen ein vollständiges Protokoll.Dann haben wir dieses Protokoll zu Allure in Form von jedem Test befestigen, und wenn wir eine Menge haben locators.json , erzeugen wir meta.json . Das Schema ist für alle Elemente gleich.Wir haben ein Plugin für Google Chrome. Wir wollten eine Entscheidung in Form eines Plugins treffen. Ich habe speziell einen Kurven-Screenshot gemacht, damit ein wichtiges Detail auf dem Folienpfad zu locators.json sichtbar ist . Wenn Sie jetzt einen Bericht erstellt haben, gibt es für heute eine Abdeckungskarte. Wenn Sie den Bericht der letzten zwei Wochen hier einfügen, wird eine Abdeckungskarte für den Zeitraum vor zwei Wochen angezeigt. Du hast eine Zeitmaschine!Wenn Sie dieses Plugin einstecken, wird jedoch eine nicht so benutzerfreundliche Oberfläche gezeichnet.
Wenn Sie jetzt einen Bericht erstellt haben, gibt es für heute eine Abdeckungskarte. Wenn Sie den Bericht der letzten zwei Wochen hier einfügen, wird eine Abdeckungskarte für den Zeitraum vor zwei Wochen angezeigt. Du hast eine Zeitmaschine!Wenn Sie dieses Plugin einstecken, wird jedoch eine nicht so benutzerfreundliche Oberfläche gezeichnet. Jedes Element wird von einer Reihe von Tests durchlaufen: Es ist klar, dass 40 Tests "Wohnung kaufen" durchlaufen, der Header einzeln getestet wird, es ist cool und die Option "Wohnung" wird ebenfalls angezeigt. Sie erhalten eine vollständige Abdeckungskarte.Wenn Sie mit der Maus über ein Element fahren, werden die Daten erfasst und Ihre tatsächlichen Tests von Ihrem tms, Allure Board usw. gedruckt. Das Ergebnis sind vollständige Informationen darüber, was wie getestet wird.Bitte beachten Sie, dass Sie bei jedem Test direkt im Allure-Bericht fehlschlagen können.
Jedes Element wird von einer Reihe von Tests durchlaufen: Es ist klar, dass 40 Tests "Wohnung kaufen" durchlaufen, der Header einzeln getestet wird, es ist cool und die Option "Wohnung" wird ebenfalls angezeigt. Sie erhalten eine vollständige Abdeckungskarte.Wenn Sie mit der Maus über ein Element fahren, werden die Daten erfasst und Ihre tatsächlichen Tests von Ihrem tms, Allure Board usw. gedruckt. Das Ergebnis sind vollständige Informationen darüber, was wie getestet wird.Bitte beachten Sie, dass Sie bei jedem Test direkt im Allure-Bericht fehlschlagen können. Wenn Sie etwas öffnen, werden neue Selektoren geladen: Wenn Sie Tests haben, die diese Selektoren durchlaufen, und Sie etwas mit der Site gemacht haben, wird das gesamte Bild verarbeitet und angezeigt.
Wenn Sie etwas öffnen, werden neue Selektoren geladen: Wenn Sie Tests haben, die diese Selektoren durchlaufen, und Sie etwas mit der Site gemacht haben, wird das gesamte Bild verarbeitet und angezeigt.Was ist der Gewinn?
Sobald wir diesen einfachen Ansatz implementiert hatten, begannen wir hauptsächlich zu verstehen, was wir in Tests getestet hatten.
Jetzt kann jeder nach einem "Thread" suchen, der zum Skript führt. Sie gehen beispielsweise davon aus, dass Sie die Zahlung testen müssen. Die Zahlung erfolgt offensichtlich über die Zahlungsschaltfläche: Klicken Sie auf - alle Tests, die über die Zahlungsschaltfläche ausgeführt werden, werden angezeigt. Das ist wunderbar! Sie gehen in eines von ihnen und sehen sich das Skript an.Außerdem verstehen Sie, was zuvor getestet wurde. Wir generieren eine statische Datei, Sie können den Pfad dazu angeben und angeben, welche Tests vor zwei Wochen durchgeführt wurden. Wenn der Manager angibt, dass ein Fehler in der Produktion vorliegt, und fragt, ob wir diese oder jene Funktionalität vor einigen Wochen getestet haben, nehmen Sie den Allure-Bericht, z. B., dass Sie ihn nicht getestet haben.Ein weiterer Gewinn ist die Überprüfung nach dem Testen der Automatisierung. Vorher hatten wir eine Überprüfung vor dem Testen der Automatisierung. Jetzt können Sie Ihre Tests genau so durchführen, wie Sie sie sehen. Wenn Sie einen Test durchführen möchten - erledigt, einen Zweig genommen, Allure gestartet, den Link zum Plug-In zu einem manuellen Tester entfernt und nach den Tests gefragt haben. Dies ist genau der Prozess, mit dem Sie die Agile-Strategie stärken können: Der Teamleiter führt eine Codeüberprüfung durch, und manuelle Tester führen Ihre Tests (Skripte) durch.Ein weiterer Vorteil dieses Ansatzes sind die häufig verwendeten Elemente. Wenn wir diesen Block überschreiben, in dem es 87 Tests gibt, fallen alle. Sie beginnen zu verstehen, wie schwach Ihre Tests sind. Und wenn der Block "Preis von" umgestürzt wird, ist es in Ordnung, ein Test wird fallen, eine Person wird ihn korrigieren. Wenn Sie den Block mit 87 Tests ändern, sinkt die Abdeckung erheblich, da 87 Tests nicht bestanden werden und kein Ergebnis überprüft wird. Dieser Block benötigt mehr Aufmerksamkeit. Dann müssen Sie dem Entwickler mitteilen, dass dieser Block eine ID haben muss, denn wenn er verlässt, fällt alles auseinander.
Und wenn der Block "Preis von" umgestürzt wird, ist es in Ordnung, ein Test wird fallen, eine Person wird ihn korrigieren. Wenn Sie den Block mit 87 Tests ändern, sinkt die Abdeckung erheblich, da 87 Tests nicht bestanden werden und kein Ergebnis überprüft wird. Dieser Block benötigt mehr Aufmerksamkeit. Dann müssen Sie dem Entwickler mitteilen, dass dieser Block eine ID haben muss, denn wenn er verlässt, fällt alles auseinander.Wie können Sie sich weiterentwickeln?
Sie können beispielsweise den Weg verfolgen, Unterstützung für andere Tools zu entwickeln, z. B. für Selenide. Ich möchte sogar nicht ein bestimmtes Selenide unterstützen, sondern eine Treiberimplementierung, mit der Sie Locators unabhängig vom verwendeten Tool erfassen können. Dieser Proxy gibt Informationen aus und zeigt sie dann an.Eine andere Idee ist es, das aktuelle Testergebnis anzuzeigen. Zum Beispiel ist es praktisch, ein solches Bild sofort einem manuellen Tester zu übergeben: Sie müssen nicht überlegen, welche Tests fehlgeschlagen sind, da Sie auf die Website gehen, auf den Test klicken und ihn von Hand bestehen können, ohne andere Tests zu überprüfen. Dies ist einfach. Sie können diese Informationen von Allure abrufen und hier zeichnen.Sie können auch die Gesamtpunktzahl hinzufügen, da jeder Grafiken liebt, weil ich mich mit doppelten Tests befassen möchte, die einander sehr ähnlich sind, deren zentraler Teil derselbe ist und deren Anfang und Ende sich etwas geändert haben.
Sie müssen nicht überlegen, welche Tests fehlgeschlagen sind, da Sie auf die Website gehen, auf den Test klicken und ihn von Hand bestehen können, ohne andere Tests zu überprüfen. Dies ist einfach. Sie können diese Informationen von Allure abrufen und hier zeichnen.Sie können auch die Gesamtpunktzahl hinzufügen, da jeder Grafiken liebt, weil ich mich mit doppelten Tests befassen möchte, die einander sehr ähnlich sind, deren zentraler Teil derselbe ist und deren Anfang und Ende sich etwas geändert haben. Ich möchte auch sofort die Anzahl der doppelten Selektoren sehen. Wenn es hoch ist, müssen Sie auf dieser Seite Refactoring durchführen und Tests ausführen, da sie sonst in ein zu großes Bündel fallen. Gleiches gilt für die Anzahl der Elemente, mit denen wir interagiert haben. Dies ist ein häufiges Symptom. Sobald Sie jedoch mit der Seite interagieren, wird die Abbildung aufgrund neuer Elemente und der Gesamtzahl der Testfälle übersprungen. Sie müssen also eine Art Analyse hinzufügen. Dies ist nicht überflüssig.Sie können auch die Verteilung der Tests nach Ebenen hinzufügen, da Sie nicht nur sehen möchten, dass wir diese Tests haben, sondern auch alle Arten von Tests, die auf dieser Seite aufgeführt sind, möglicherweise sogar manuelle Tests.Wenn es also Java-Tests und Tests auf Puppeteer gibt, die ein anderes Team schreibt, können wir uns eine bestimmte Seite ansehen und sofort sagen, wo sich unsere Tests überschneiden. Das heißt, wir werden mit ihnen dieselbe Sprache sprechen, und wir müssen diese Informationen nicht Stück für Stück sammeln. Wenn wir ein Tool haben, das alles in der Weboberfläche anzeigt, scheint die Aufgabe, Tests in Java und Puppeteer zu vergleichen, nicht mehr unlösbar.Lassen Sie uns abschließend über die allgemeine Strategie sprechen. Wir haben bereits darüber gesprochen, welche Arten der Bedeckung zwei genannt werden, und haben eine dritte Art der Beschichtung entwickelt, die wir als Ergebnis verwendet haben. Also haben wir dieses Problem einfach aus einem anderen Blickwinkel betrachtet.
Ich möchte auch sofort die Anzahl der doppelten Selektoren sehen. Wenn es hoch ist, müssen Sie auf dieser Seite Refactoring durchführen und Tests ausführen, da sie sonst in ein zu großes Bündel fallen. Gleiches gilt für die Anzahl der Elemente, mit denen wir interagiert haben. Dies ist ein häufiges Symptom. Sobald Sie jedoch mit der Seite interagieren, wird die Abbildung aufgrund neuer Elemente und der Gesamtzahl der Testfälle übersprungen. Sie müssen also eine Art Analyse hinzufügen. Dies ist nicht überflüssig.Sie können auch die Verteilung der Tests nach Ebenen hinzufügen, da Sie nicht nur sehen möchten, dass wir diese Tests haben, sondern auch alle Arten von Tests, die auf dieser Seite aufgeführt sind, möglicherweise sogar manuelle Tests.Wenn es also Java-Tests und Tests auf Puppeteer gibt, die ein anderes Team schreibt, können wir uns eine bestimmte Seite ansehen und sofort sagen, wo sich unsere Tests überschneiden. Das heißt, wir werden mit ihnen dieselbe Sprache sprechen, und wir müssen diese Informationen nicht Stück für Stück sammeln. Wenn wir ein Tool haben, das alles in der Weboberfläche anzeigt, scheint die Aufgabe, Tests in Java und Puppeteer zu vergleichen, nicht mehr unlösbar.Lassen Sie uns abschließend über die allgemeine Strategie sprechen. Wir haben bereits darüber gesprochen, welche Arten der Bedeckung zwei genannt werden, und haben eine dritte Art der Beschichtung entwickelt, die wir als Ergebnis verwendet haben. Also haben wir dieses Problem einfach aus einem anderen Blickwinkel betrachtet.Einerseits gibt es eine Berichterstattung, die seit 1963 eingestellt wurde, andererseits gibt es manuelle Tester, die es gewohnt sind, in einer realeren Welt als Code zu leben. Es bleibt nur, diese beiden Ansätze zu kombinieren.
Interessenten können sich jederzeit unserer Community anschließen. Hier sind zwei Repositories unserer Jungs, die sich mit dem Coverage-Problem befassen: